1. Introduction
Nowadays, portfolio optimization has been one of the most important topics in asset management, which mainly focuses on how to allocate investors’ wealth among different assets. The classical mean-variance portfolio selection theory was first introduced by Markowitz [
1] and was limited to the single-period investment situation. As far as we know, the multiperiod portfolio optimization problem is deemed to be one of the most significant extensions of the pioneering work of Markowitz [
1], and it has received considerable attention in recent years (e.g., Li and Ng [
2], Leippold et al. [
3], Wei and Ye [
4], Yao et al. [
5], Chen et al. [
6], Cui et al. [
7], Liu and Chen [
8], Zhou et al. [
9] and so on). Most of the existing studies mainly assume that the investors only focus on their own performance and formulate the corresponding investment strategy accordingly. Obviously, this assumption is more consistent with the investment behavior of individual investors. However, in the real financial market, the institutional investors (e.g., fund managers and insurance companies) not only focus on their own performance but also tend to compare the performance gap between themselves and competitors/benchmarks. Some researchers also point out that the above investment approach is sensible in that fund investors expect their portfolios to maintain a performance level that is close to a desirable benchmark(e.g., Roll [
10] and Zhao [
11]). To describe the above investment behavior, we propose a multiperiod portfolio optimization problem, in which the investors consider the relative performance for the given benchmark.
However, Zhao [
11] considered the maximization of the relative performance of the gap between the investors’ own wealth and the benchmark and neglected the maximization of the performance of the investors’ own wealth. Espinosa and Touzi [
12] proposed a more general approach to measure the relative performance, which can not only consider the utility of the gap between the investors’ own wealth and the benchmark but also consider that of their own wealth. In addition to this, the work of Zhao [
11] merely considered the terminal performance while ignoring the intermediate performance. What is more, Zhu et al. [
13] noted that the investment bankruptcies that occur in the earlier periods are larger than those that occur in the later periods. That is, the intermediate performance of the portfolio can not be ignored. To address this problem, Costa and Nabholz [
14] considered a generalized mean-variance model with consideration of the intertemporal restrictions (i.e., the investors have restrictions on the intermediate expectations and intermediate variances of the portfolio). Under this generalized mean-variance criterion, the investors not only consider the terminal performance but also consider the intermediate performance of their portfolio. For other kinds of the generalized mean-variance portfolio optimization problems, readers may refer to Costa and Araujo [
15], Costa and de Oliveira [
16], Cui et al. [
17] and Zhou et al. [
18]. Motivated by the works of Costa and Nabholz [
14] and Espinosa and Touzi [
12], we construct a generalized mean-variance portfolio optimization model with intertemporal restrictions and the investors who are also concerned about the relative performance compared to the given benchmark.
Similar to the classical multiperiod mean-variance portfolio optimization problems, our proposed generalized model is also a time-inconsistent optimization problem, in that the variance measure does not satisfy the expected iterated property. That is, the proposed model can not be solved directly by using the traditional dynamic programming approach. As far as we know, the precommitment and time-consistent strategies are the two most representative strategies for these multiperiod mean-variance portfolio optimization problems. Li and Ng [
2] first derived the precommitment strategy by using the embedding scheme. Since then, this approach has been widely applied to the different portfolio optimizations (e.g., Leippold et al. [
3], Celikyurt and Özekici [
19], Yao et al. [
20] and Zhou et al. [
9]). However, some researchers have noted that this strategy does not satisfy the time-consistency. This cause is that, the precommitment strategy is made at the initial time, and it not only depends on the current wealth but also relies on the initial capital. In this situation, the optimal strategy at time
does not agree with that at time
, where
, that is, the global and local objectives are not consistent. To address this problem, Björk and Murgoci [
21] derived the time-consistent strategy by using a game approach. The proposed solution methodology treats these time-inconsistent problems as a noncooperative game, in which the strategies at different time points are made by the different players who seek to maximize their own utilities. Then, Nash equilibrium of these strategies is applied to define the time-consistent strategy for the original optimization problem. Compared with the precommitment strategy, the time-consistent strategy might be adopted by the investors who are more rational and sophisticated, since the decision-makers take possible future revisions into account (e.g., Basak and Chabakauri [
22], Wu and Chen [
23]), Cui et al. [
24] and so on). For this research topic, readers may refer to Basak and Chabakauri [
22], Bensoussan et al. [
25], Björk and Murgoci [
26], Wu and Chen [
23], Zhou et al. [
27] and Wang and Chen [
28] and so on. Actually, most of the existing researches on the time-consistent strategies for the multi-period portfolio optimization problems are only concerned with the capital pool with both risky assets and one risk-free asset. In the real applications, it is not difficult to identify a case in which some investors only invest in risky assets. Although Zhou et al. [
27] derived the time-consistent strategy for the classical multiperiod mean-variance portfolio optimization with and without the risk-free asset, these authors are still limited to the framework of the classical mean-variance model without considering the benchmark orientation and intertemporal restrictions. In this paper, we mainly aim to investigate the time-consistent strategy for a generalized multiperiod mean-variance portfolio optimization with and without a risk-free asset.
Along the aforementioned lines of research, we propose a generalized mean-variance portfolio optimization with consideration of both the intertemporal restrictions and the benchmark orientation. We use a generalized approach provided by Espinosa and Touzi [
12] to measure the relative performance of the portfolio in which the investors’ own performance and the relative performance compared to the benchmark are both considered. We derive the time-consistent strategy for the proposed model with and without the risk-free asset, by using the backward induction approach, which can be regarded as a suitable investment strategy for the rational and sophisticated investors. We find that the time-consistent strategies for the above investment situations are both feedback strategies. Finally, we also provide some numerical simulations to show the evolution process of the proposed time-consistent strategy. These simulations indicate that the proposed time-consistent strategy can not only change the risk of investment existed in the intermediate time period but also imitate the return of benchmark process.
Different from the existing literature, this paper has three contributions. (a) We extend the work of Zhao [
11] to a generalized mean-variance criterion, where the intertemporal restrictions are considered in the proposed model. The proposed model not only can cover many classical models, but also can depict the behavior of investors imitating the benchmark process. (b) Compared with Zhao [
11], we focus on both the investors’ own performance and the performance relative to the given benchmark. The investors can weigh their own wealth value and the gap between their wealth value and the benchmark. (c) We derive the corresponding time-consistent strategy for the proposed model when there exists a risk-free asset or not, while the most of existing studies always ignore the latter condition. The results show that the time-consistent strategies are both feedback strategies. The difference is that, when there exists a risk-free asset, the time-consistent strategy is a feedback strategy about the benchmark process; when there does not exist a risk-free asset, the time-consistent strategy is a double feedback strategy on both the benchmark process and the wealth process.
The remainder of this paper is organized as follows. In
Section 2, we introduce the assumption of investment market, and then construct a generalized multiperiod mean-variance portfolio optimization model. In
Section 3, we first give the definition of time-consistent strategy and the solution methodology. Further, we derive the time-consistent strategy for the proposed model with and without the risk-free asset. In
Section 4, we carry out some numerical simulations to show the results derived from
Section 3. Finally, some concluding remarks are summarized.
2. Generalized Multiperiod Mean-Variance Portfolio Optimization Considering Benchmark
In this section, we assume that the investors will join the capital market taking along with the initial wealth
. The investors can invest their wealth into one risk-free asset and
n risky assets within time horizon
T. We suppose that the risk-free asset with a deterministic return
and the
i-th risky asset with a random return
at the time period
t, where
and
. Let
be the wealth at the time period
t and
be the amount invested in the i-th risky asset at the beginning of the time period
t, then the amount invested in the risk-free asset can be expressed as
,
. Based on the above assumption, the wealth dynamic process can be expressed as
where
denotes the vector of excess rates of returns, and
,
.
In addition, we assume that the investors’ decision-making will refer to the return process of a given benchmark (i.e., stock index and investment fund, etc.), since the investors always hope that the performance of their portfolio can outperform that of this benchmark, or the investors want to replicate the return process of the benchmark according to their own portfolio. Let the return of the benchmark be
, and let
denote the wealth of this benchmark at the time period
t, where
. Then, the wealth process of this benchmark can be expressed as
In this paper, we assume that the investors not only consider their own wealth but also consider the relative wealth compared to this benchmark. Additionally, we use a generalized mean-variance utility to measure the relative performance of the portfolio, that is, the intertemporal restrictions are considered in this optimization problem. Therefore, we can construct the following multiperiod portfolio optimization model:
Note that
,
and
denote the two weights for the expectation
and variance
at each time period
t (
), which can be regarded as the trade-off parameters between maximizing the investment return and minimizing the investment risk. For the real investors, how to determine the above two weights mainly depends on their preferences for the return and risk. Typically, the investors will first fix one of the above two weights, and then adjust another one according to their preferences, e.g., for the given weight
, when the investors are more risk-averse, they will choose a larger weight
at the time period
t,
. In addition, as shown in Zhu et al. [
13], the number of investment bankruptcies that occur in the earlier periods is larger than those that occur in the later periods, this also lead to the investors will give a larger weight
for the earlier risk restrictions in the corresponding optimization objective, that is, for these risk-averse investors, the weight
might be a decrease function on the time period
t ( in fact, the form of
depends on the investor’s preference, which can be described by some linear and nonlinear functions; note that, in
Section 4, we assume that the weight
decreases exponentially with the time period
t),
. Further,
denotes the weight for the mean-variance objective
at the time period
t,
. In this paper, we assume that
is a 0-1 variable, where
denotes that the investors will consider the intertemporal restriction at the time period
t and
indicates that the intertemporal restriction is not considered at the time period
t,
. As shown in Model (
3), the investors not only consider their own investment performance but also consider the relative performance compared to this benchmark, where
denotes the sensitivity of the investors to the performance of this benchmark at time period
t,
. Furthermore, Model (
3) can be rewritten as
Let
and
,
. Suppose that
are statistically independent random vectors (i.e.,
and
are independent for
if
). However, the benchmark return
is dependent with random vector
,
. Let
,
,
,
,
,
,
and
,
. Here, we assume that
and
are both positive definite matrices,
. In addition, for convenience, we define that
and
for
. Since the variance measure does not have the expected iterated property, then Model (
4) is a time-inconsistent optimization problem. In the following, we will derive the time-consistent solution of Model (
4) by using the backward induction approach.
3. Time-Consistent Strategy for the Generalized Portfolio Optimization Problem
As far as we know, Li and Ng [
2] first applied the embedding scheme to solve the classical multi-period mean-variance portfolio optimization problem. However, the optimal investment strategy shown in Li and Ng [
2] has been criticized for not satisfying time consistency. Similarly, Model (
4) is a time-inconsistent problem, which cannot be directly solved by using the dynamic programming approach. Inspired by Björk and Murgoci [
21], in the following, we will investigate the time-consistent strategy for Model (
4) under the two investment situations: (i) there exists a risk-free asset and
n risky assets in the capital pool; and (ii) there only exist
n risky assets in the capital pool.
To this end, we should provide the definition of the time-consistent strategy first. Similar to Björk and Murgoci [
21], we regarded this investment decision-making process as a noncooperative game and assume that there exists a decision-maker, called as “decision-maker
k”, for each point of the time period
k. Then, we can define the corresponding sub-objective as follows.
According to the Definition 2.2 presented in Björk and Murgoci [
21], the time-consistent strategy for Model (
4) can be defined as follows.
Definition 1. Consider a fixed control law . For , we letwhere is an arbitrarily control value. Then, is called as a time-consistent strategy if for all , it satisfies the following conditions In addition, if time-consistent strategy exists, the corresponding value function is defined as Definition 1 shows that the solution methodology of the time-consistent strategy is essentially a backward induction approach. According to the above definition of time consistent strategy presented in Definition 1, the recursive formula of the above value function can be derived.
Proposition 1. The value function satisfies the following recursive formula.where Based on Proposition 1, in the following, we will investigate the time-consistent solution of the optimization problem (
4) with and without a risk-free asset.
3.1. Time-Consistent Strategy for the Generalized Portfolio Optimization with Multiple Risky Assets and a Risk-Free Asset
In this section, we will discuss the time-consistent strategy for this generalized model with both n risky assets and a risk-free asset. According to Definition 1 and Proposition 1, we can derive the corresponding time-consistent strategy and value function by using the backward induction approach, and the main conclusions are as follows.
Theorem 1. When there exists a risk-free asset and n risky assets, for the multiperiod mean-variance portfolio optimization problem (4), the time-consistent strategy can be described asand the corresponding value function and are given by Here, we define that and for . In addition, the above parameters (i.e., , , , , , and , where and ) satisfy the following iteration formulas:as well as the boundary conditions From Theorem 1, we can find that, when the performance of the benchmark is considered into the investment decision-making, the corresponding time-consistent strategy depends on the current wealth of the benchmark compared to the results shown in Zhou et al. [
18]. That is, the proposed time-consistent strategy (
9) is a feedback strategy, while the time-consistent strategy provided by Zhou et al. [
18] is a nonfeedback one. Additionally, Model (
4) is a generalized one that can recover some classical models presented in the existing studies. In the following, we will discuss the time-consistent strategies under some special settings, the details are as follows.
Remark 1. When the investors only consider the performance of terminal wealth (i.e., if and , and for ), then the time-consistent strategy (9) can be reduced aswhere and are shown as follows. Remark 1 shows that the investors only consider the performance of terminal wealth, and the intertemporal expectations and variances are ignored in here. Compared with (
9) and (
14), we can find that the latter only considers the terminal risk aversion coefficient
, while the former considers both the intertemporal and terminal risk aversion coefficients.
Remark 2. When the investors do not consider the performance of the benchmark process (i.e., for ), then the time-consistent strategy (9) can be reduced as Remark 2 shows that, the investors’ decision only considers the performance of the assets they want to invest in, while the performance of the benchmark is ignored here. However, the intertemporal restrictions are embedded into this time-consistent strategy. In this case, the time-consistent strategy (
16) is a nonfeedback strategy, which is consistent with the result shown in Zhou et al. [
18].
Remark 3. When the investors do not consider the performance of the benchmark and also ignore the impact of the intertemporal restrictions(i.e., if and , and , for ), the time-consistent strategy (9) is Under this special setting presented in Remark 3, Model (
4) is degenerated into the classical multiperiod mean-variance model, and then the time-consistent strategy (
17) is consistent with the result shown in Björk and Murgoci [
21].
3.2. Time-Consistent Strategy for the Generalized Portfolio Optimization with Only Risky Assets
Section 3.1 investigates the time-consistent strategy for the generalized portfolio optimization with both
n risky assets and a risk-free asset. This condition is also the common investment assumption found in previous studies. However, in some situations, the investors might only treat the risky assets as the investment targets. Therefore, it is necessary to investigate the time-consistent solution of Model (
4) when the capital pool only contains
n risky assets. Mathematically, we merely require to add an additional condition
to Model (
4). In this assumption, Model (
4) can be written as follows.
where
.
According to Definition 1 and Proposition 1, we can derive the time-consistent strategy for Model (
18), the details see Theorem 2.
Theorem 2. When there exists only risky assets, the time-consistent strategy and the corresponding value function for Model (18) can be expressed as follows:where Here, we define that , and for . In addition, the above parameters (, , , , , , , , and , and ), which satisfy the following iteration equations:where is a positive definite matrix. Additionally, the above iteration equations satisfy the following boundary conditions As shown in Theorem 2, when there are only risky assets in the capital pool, the time-consistent strategy (
19) is dependent on both the benchmark process
and wealth process
compared to the time-consistent strategy (
9). That is, the time-consistent strategy (
19) is a double feedback strategy on both benchmark process
and wealth process
, while the time-consistent strategy (
9) is only a feedback strategy on the benchmark process
.
Remark 4. When the investors only consider the performance of terminal wealth (i.e., if and , and for ), the time-consistent strategy (19) can be reduced as Therefore, the above parameters (i.e., , and , t = 0, 1, …, T − 2), which satisfy the following iteration equations.as well as the boundary conditions Similarly, the time-consistent strategy (
24) only concerns the terminal risk aversion coefficient
, while the time-consistent strategy (
19) both consider the intertemporal and terminal risk aversion coefficients. In addition, compared with Remark 1, when there exist
n risky assets in the capital pool, the time-consistent strategy (
24) is a double feedback one on current benchmark process
and wealth process
.
Remark 5. When the investors do not consider the performance of the benchmark process (i.e., for ), the time-consistent strategy (19) can be reduced asHere, we also define that , and for . Therefore, the above parameters (i.e., and , t = 0, 1, …, T − 2), which satisfy the following iteration equationswhere , and the boundary conditions of the above parameters can be expressed as As shown in Remark 5, we can find that the time-consistent strategy (
27) is a feedback strategy on current wealth
compared to the time-consistent strategy (
16). This is the largest difference between the time-consistent strategies with and without the risk-free asset.
Remark 6. When the investors do not consider the performance of the benchmark and ignore the impact of the intertemporal restrictions(i.e., if and , and for ), the time-consistent strategy (19) can be reduced as The above parameters (i.e., and , t = 0, 1, …, T − 2), which satisfy the following iteration equations.as well as the boundary conditions Remark 6 shows that, the investors only concern the performance of the terminal wealth, and also do not consider the relative performance compared to the benchmark. In this case, this conclusion is coincident with the results in Zhou et al. [
27].
4. Numerical Analysis
In this section, we will provide some numerical simulations to show the results presented in
Section 3. Suppose that
and
. We randomly select four stocks from American financial market, where the stock codes are AIG, GE, INTC and PEP. Further, we regard the S&P 500 index as the benchmark process. The monthly returns from January 2000 to December 2018 are applied to estimate the parameters of the risky assets, which is downloaded from Yahoo Finance (
https://finance.yahoo.com/). The detailed estimations are given as follows.
In this section, we treat 3-month Treasury bill as the risk-free asset, the annual returns can be downloaded from Federal Reserve Economic Data (
https://fred.stlouisfed.org/series/TB3MS). We use the mean of the historical returns from January 2000 to December 2018 as the return of the risk-free asset, that is,
. In the following, we will investigate the evolution process of the time-consistent strategy and discuss the impact of the intertemporal restrictions and benchmark orientation on the time-consistent strategy. In order to better show the evolution of investment strategy, we choose a relatively large investment horizon
T in the following simulations, that is,
. In fact, we can explore the evolution of the investment strategy for any given investment horizon
T, the corresponding results have been omitted for space reasons. To this end, we will show the evolution processes of the time-consistent strategies under different settings. The details are given as follows.
Case I. The proposed time-consistent strategy considers all the intertemporal restrictions, and it also relies on the benchmark origination. Since the weight is a 0–1 variable, the above situation means that , . In addition, we assume that the investors consider their own wealth value (i.e., ) and the gap between their own wealth value and the benchmark (i.e., ) equally important, that is, for ;
Case II. The proposed time-consistent strategy does not intertemporal restrictions, and it only depends on the benchmark origination. In this case, the investors only consider the performance of the terminal wealth and the intermediate performance of the portfolio is ignored here, that is, if and . Similar to Case I, we assume that for ;
Case III. The proposed time-consistent strategy considers all the intertemporal restrictions, however it has nothing to do with the benchmark process. Similar to Case I, we can find that for . Additionally, in this case, the investors only consider the performance of their own wealth, that is, for .
Zhu et al. [
13] showed that the number of investment bankruptcies that occur in the earlier periods is larger than those that occur in the later periods. In this situation, we should give a larger penalty for the earlier intertemporal restrictions in the mathematical formulation. That is, the investors have a higher risk aversion coefficient at the beginning of the investment period. In order to discuss the impacts of the intertemporal restrictions on the time-consistent strategies, a reasonable weight function
should be given first. As shown in Zhou et al. [
27], we can find that, the time-consistent strategy for the traditional multiperiod mean-variance model, i.e., the time consistent strategy (
17), can be derived by optimizing the following single-period problem with the time-varying risk aversion coefficient
,
.
Further, if the risk-free rate is a number that doesn’t change over time, that is,
, the time-vary risk aversion coefficient
can be written as
,
. Motivated by the above time-vary risk aversion coefficient
, in this paper, we arbitrarily assume that the investors’ risk aversion coefficient changes exponentially, i.e.,
for
, where
q is a fixed parameter. Compared with the traditional time-consistent strategy (
17), the proposed time-consistent strategies have considered the role of the intertemporal restrictions, that is, the investors who adopt the proposed strategies might be more risk-averse than that in Model (
38). To this end, we let
q and
satisfy the relationship that
. In the following, we will discuss the evolution process of the time-consistent strategy under the following two investment situations: (i) there exists a risk-free asset and 4 risky assets in the capital pool; (ii) there only exist 4 risky assets in the capital pool.
4.1. The Time-Consistent Strategy with Both Risky Assets and a Risk-Free Asset
In this section, we will discuss the evolution of the time-consistent strategy with both risky assets and a risk-free asset. Using the monthly return of risky assets from May 2002 to December 2018 as the investment sample, we can derive the corresponding path of the time-consistent strategy. The details see
Figure 1,
Figure 2,
Figure 3 and
Figure 4.
Suppose that
and
. We will compare the time-consistent strategy with and without intertemporal restrictions (i.e., Case I and Case II) to show the impact of the intertemporal restrictions on the time-consistent strategy. As shown in
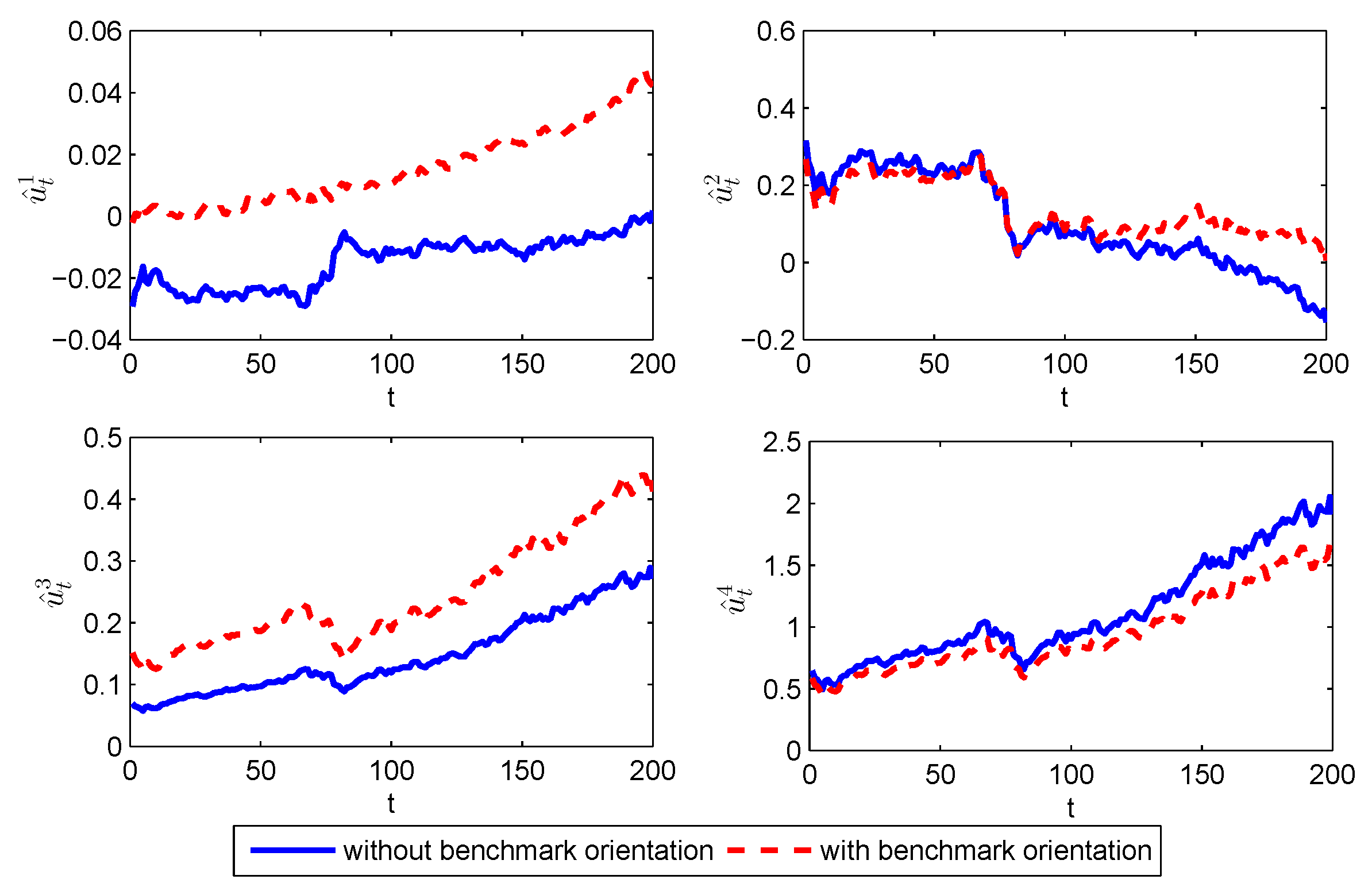
Figure 1, when the intertemporal restrictions are considered in the investment decision, the investors will shrink investment position (i.e., shrinking the long position
,
and
, meanwhile, shrinking the short position
) invested in the risky assets compared to the investment strategy without considering intertemporal restrictions. This means that the amount invested in risk-free asset (
) will be increased for the fixed time period, indicating that the investors will adopt a conservative strategy to reduce the investment risk in the earlier periods. Additionally, with the increase in the time period, the position difference of the time-consistent strategies with and without intertemporal restrictions is decreases.
Using the parameters shown in
Figure 2, i.e.,
and
, we will compare the time-consistent strategy with and without benchmark orientation (i.e., Case I and Case III), so as to show the impact of the benchmark on the time-consistent strategy. As shown in
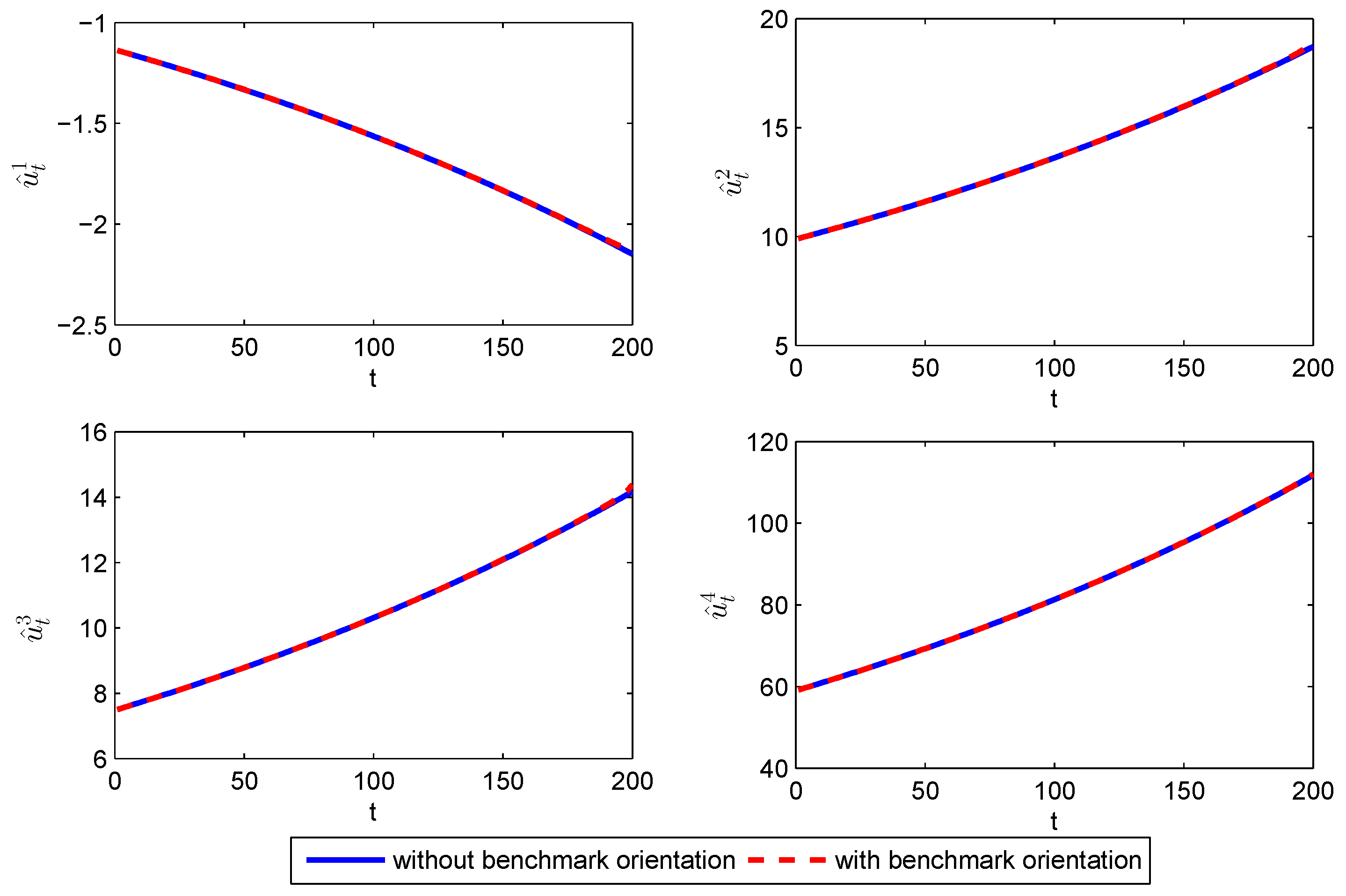
Figure 2, we can find that the time-consistent strategies with and without benchmark orientation almost are coincident. In other words, the benchmark has little impact on the time-consistent strategy when the risk aversion coefficient of the investors is small.
As shown in
Figure 3, when the investors have a larger risk aversion coefficient
, the benchmark process leads to a significant impact on the time-consistent strategy, especially for the investment strategy in the later periods. In this situation, the investors might tend to choose a conservative investment strategy to imitate the return of the benchmark process.
To evaluate whether the time-consistent strategy that considers the benchmark can imitate the return of the benchmark or not, we will give a more intuitive simulation to verify this conclusion. In addition to the condition of Case I, we also suppose that
, then the return of the portfolio at the different time periods can be derived. As shown in
Figure 4, we can find that the return of the benchmark has almost the same trend as that of the proposed portfolio. This results indicate that, when the investors have the larger risk aversion coefficients, the proposed time-consistent strategy can indeed imitate the return of the benchmark.
4.2. The Time-Consistent Strategy with Only Risky Assets
In this section, we will discuss the evolution of the time-consistent strategy with only risky assets. Similar to
Section 4.1, we can derive the corresponding path of the time-consistent strategy. The details see
Figure 5,
Figure 6,
Figure 7 and
Figure 8.
Suppose that
and
. We will compare the time-consistent strategy with and without intertemporal restrictions (i.e., Case I and Case II). As shown in
Figure 5, when the intertemporal restrictions are considered in the investment decision, the investors will shrink investment position (i.e., shrinking the short position
and the long position
, meanwhile, increasing the long position
and
) invested in the risky assets compared to the investment strategy without considering intertemporal restrictions. Unlike the time-consistent strategy with both multiple risky assets and a risk-free asset (e.g., the investors can reduce the portfolio risk by increasing the amount investment in the risk-free asset), when there are only risky assets, the investors can only reduce the investment risk that existed in the earlier periods by adjusting the investment position among the risky assets. Similarly, with the increase in the time period, the position difference of the time-consistent strategies with and without intertemporal restrictions is decreases.
Similar to
Figure 2 and
Figure 3, we also suppose that
and
. In the following, we will compare the time-consistent strategies with and without benchmark orientation (i.e., Case I and Case III) to show the impact of the benchmark on the time-consistent strategy.
Figure 6 and
Figure 7 show that the benchmark will lead to a significant impact on the time-consistent strategy regardless of whether the investors have small risk aversion coefficients or large risk aversion coefficients. Additionally, comparing
Figure 2 and
Figure 3 and
Figure 6 and
Figure 7, we can find that, the benchmark has a larger impact on the time-consistent strategy with only risky assets compared to that on the time-consistent strategy with both a risk-free asset and multiple risky assets.
In addition to the condition of Case I, we also suppose that
. As shown in
Figure 8, we can find that the return of the benchmark and the return of the proposed portfolio have almost the same trend, which is consistent with the conclusion shown in
Figure 4. This result indicates that, when the investors have the larger risk aversion coefficient, the proposed time-consistent strategy can also imitate the return of the benchmark.
5. Conclusions
In this paper, we investigate a generalized multiperiod mean-variance portfolio optimization with consideration of benchmark orientation and intertemporal restrictions. Since the proposed model is a time-inconsistent problem, we cannot directly solve it by using the traditional dynamic programming approach. Although this problem can be solved indirectly by the embedding scheme, this approach cannot guarantee that the derived strategy (i.e., precommitment strategy) satisfies the time-consistency. Thus, the precommitment strategy has been criticized for lacking rationality by some researchers. In this paper, we adopt a game approach to solve the proposed model, in which the investment decision-making process is deemed to be a noncooperative game. We assume that there exist T players who stand in the different time periods; they all aim to maximize their own generalized mean-variance sub-objectives. Then, the Nash equilibrium solution of this game problem is defined as the time-consistent strategy for the proposed model. In this framework, we derive the time-consistent strategies for the proposed model with and without a risk-free asset by using the backward induction approach. We find that the time-consistent strategy, when there exists a risk-free asset in the capital pool, is feedback one on the benchmark process; when the capital pool with only risky assets, the time-consistent strategy is double feedback one on both benchmark process and wealth process. Finally, we also provide some numerical simulations to show the conclusions derived in this study. These results indicate that, the proposed time-consistent strategy not only can reduce the risk existed in the intermediate process of investment but also can imitate the return of benchmark process.
Apparently, the above game approach can be extended to many time-inconsistent dynamic optimization problems. More importantly, this approach can provide a more suitable strategy for sophisticated decision-makers, since it takes possible future revisions into account. Roughly speaking, the current work can be further extended from the following two aspects. First, this paper assumes that the risk aversion coefficient is independent with current wealth; however, in some cases, the risk aversion coefficient of investors also depends on their level of wealth. Intuitively, the greater the wealth of investors, the less risk averse they are likely to be. Therefore, the case when the risk aversion depends dynamically on current wealth is worth to be investigated in the further work. Second, we can introduce the Markov chain into our proposed model to investigate the time-consistent strategy under the regime switching environment.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







