A Novel Forward-Backward Algorithm for Solving Convex Minimization Problem in Hilbert Spaces

Abstract
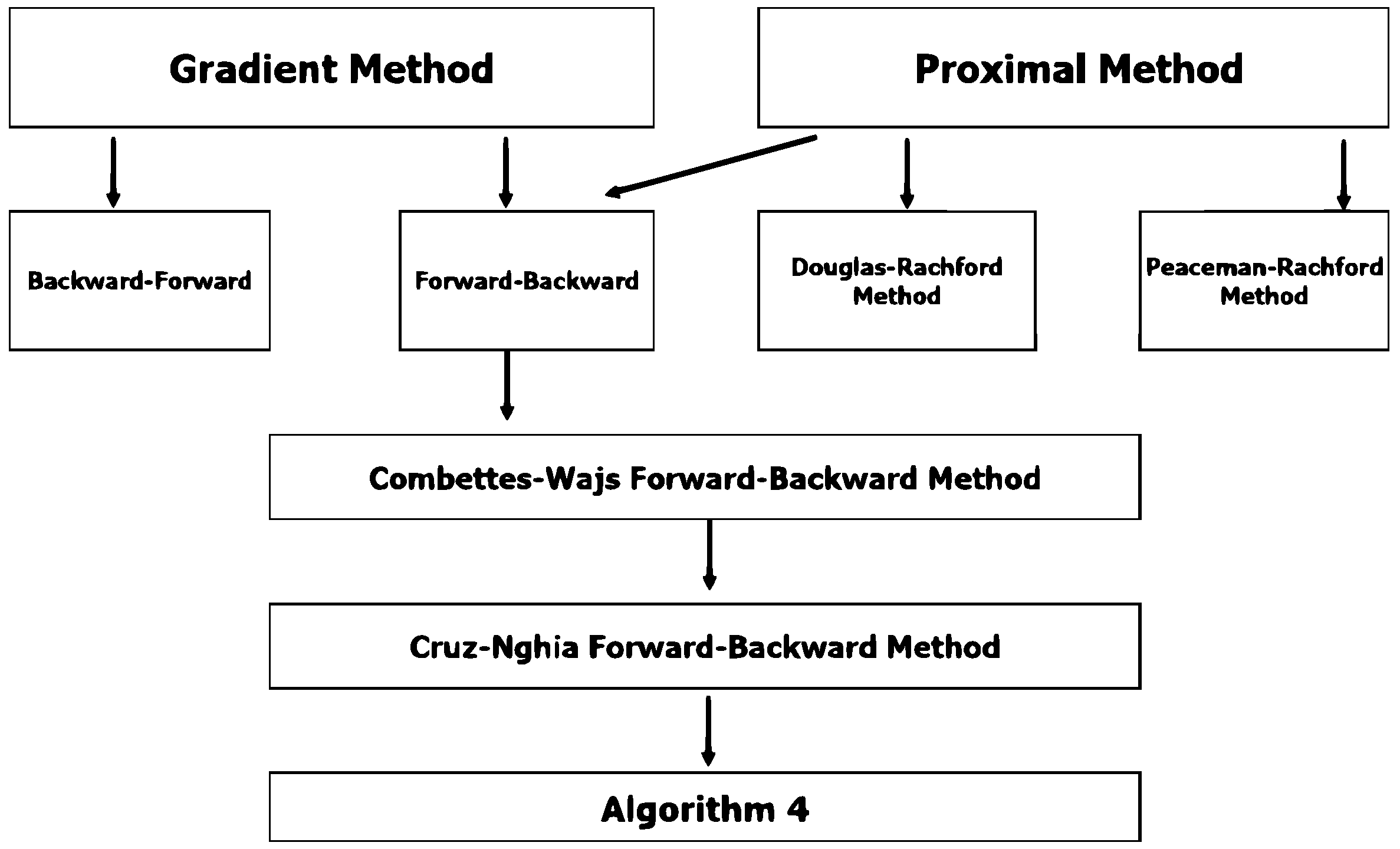
:1. Introduction
| Algorithm 1 ([16]). Given and letting for :
|
| Algorithm 2 ([16]). Fix and let For , calculate |
| Algorithm 3.Fixand, and let. For, calculate: |
2. Preliminaries
3. Main Results
| Algorithm 4.Step 0.Given, andLet. Step 1.Calculate: Step 2.Calculate: |
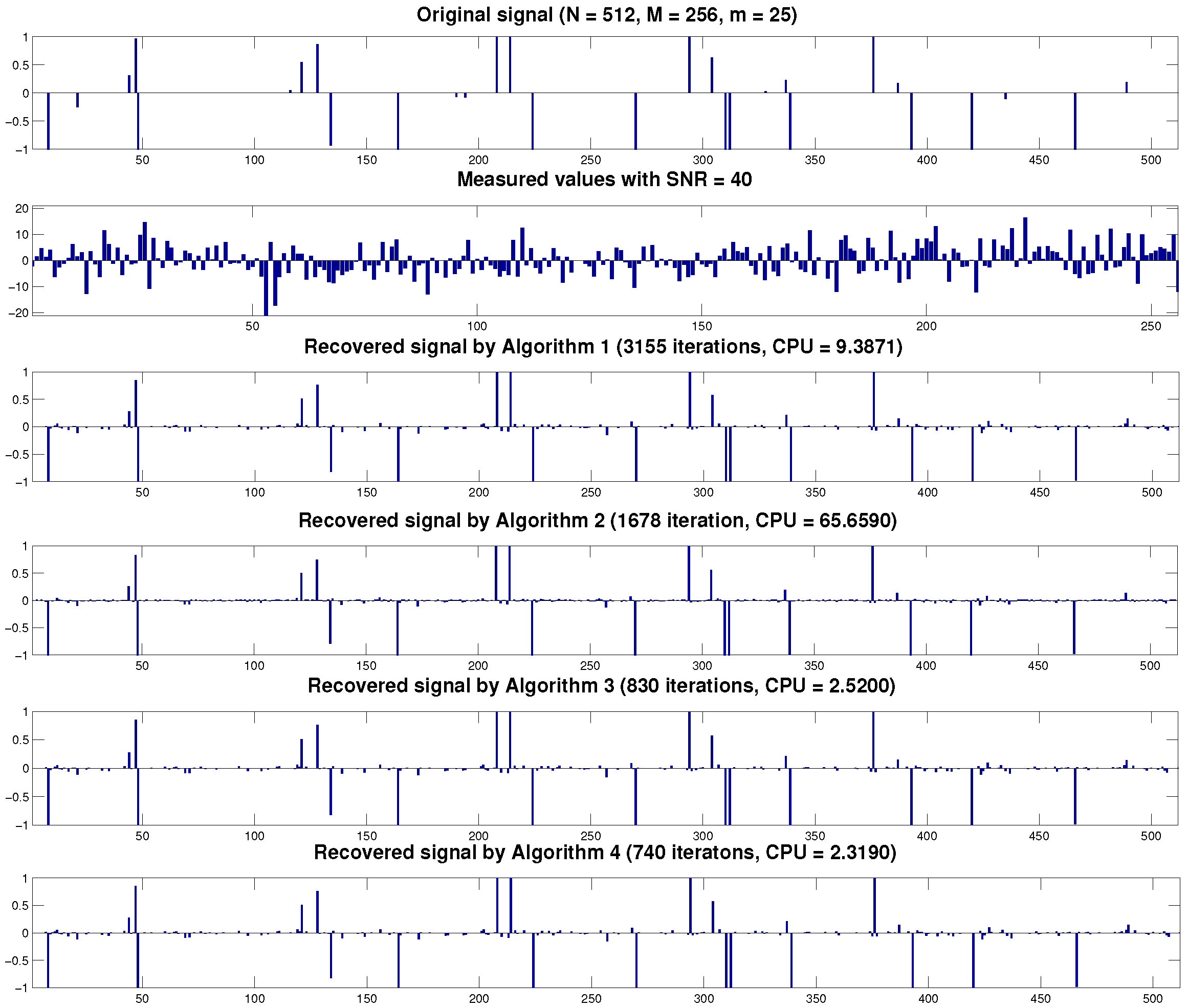
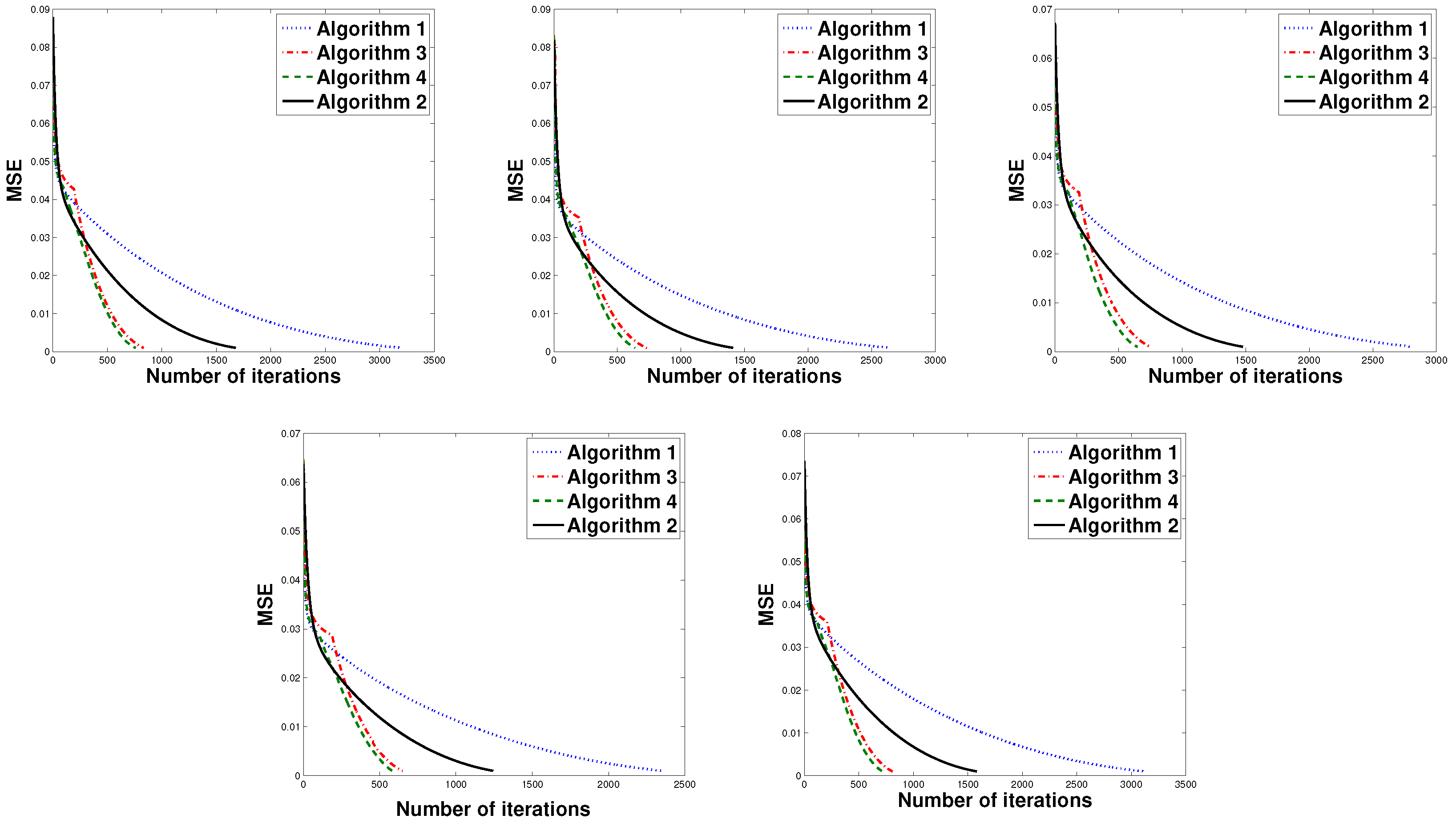
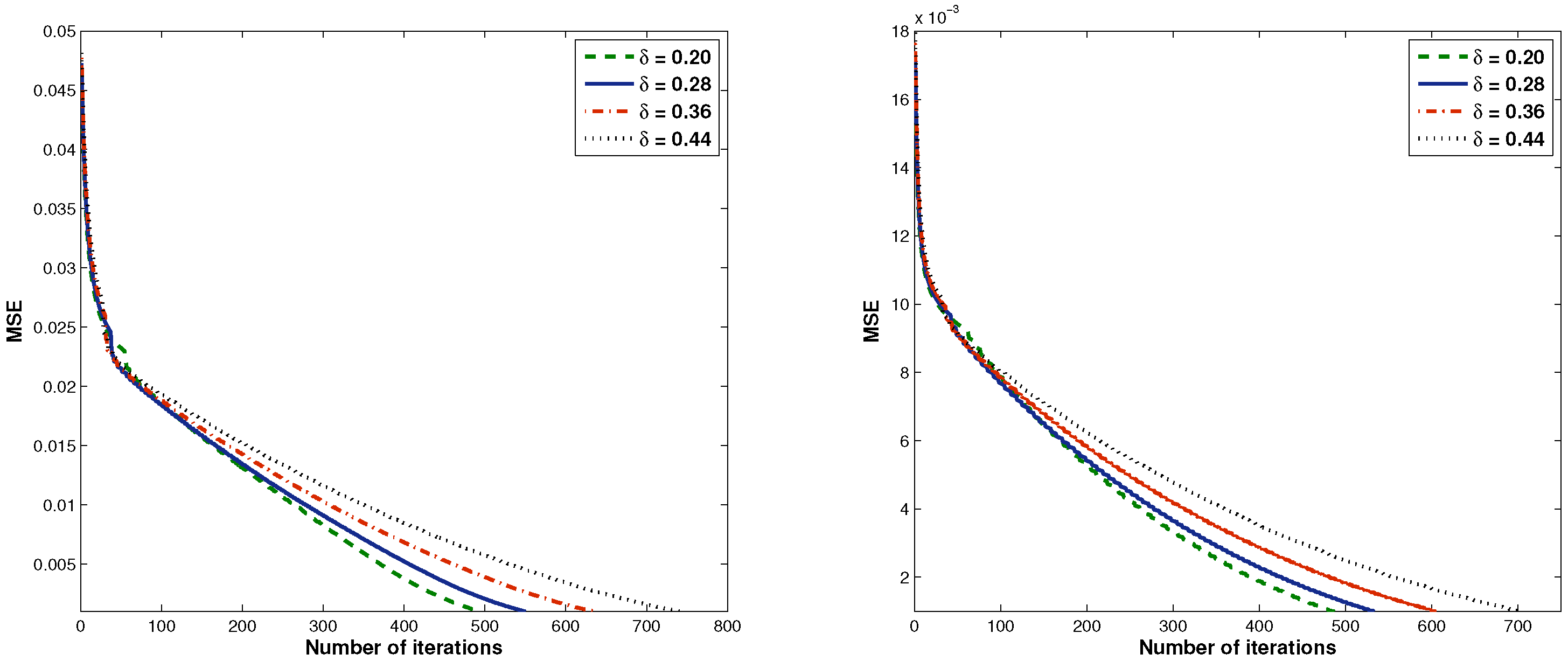
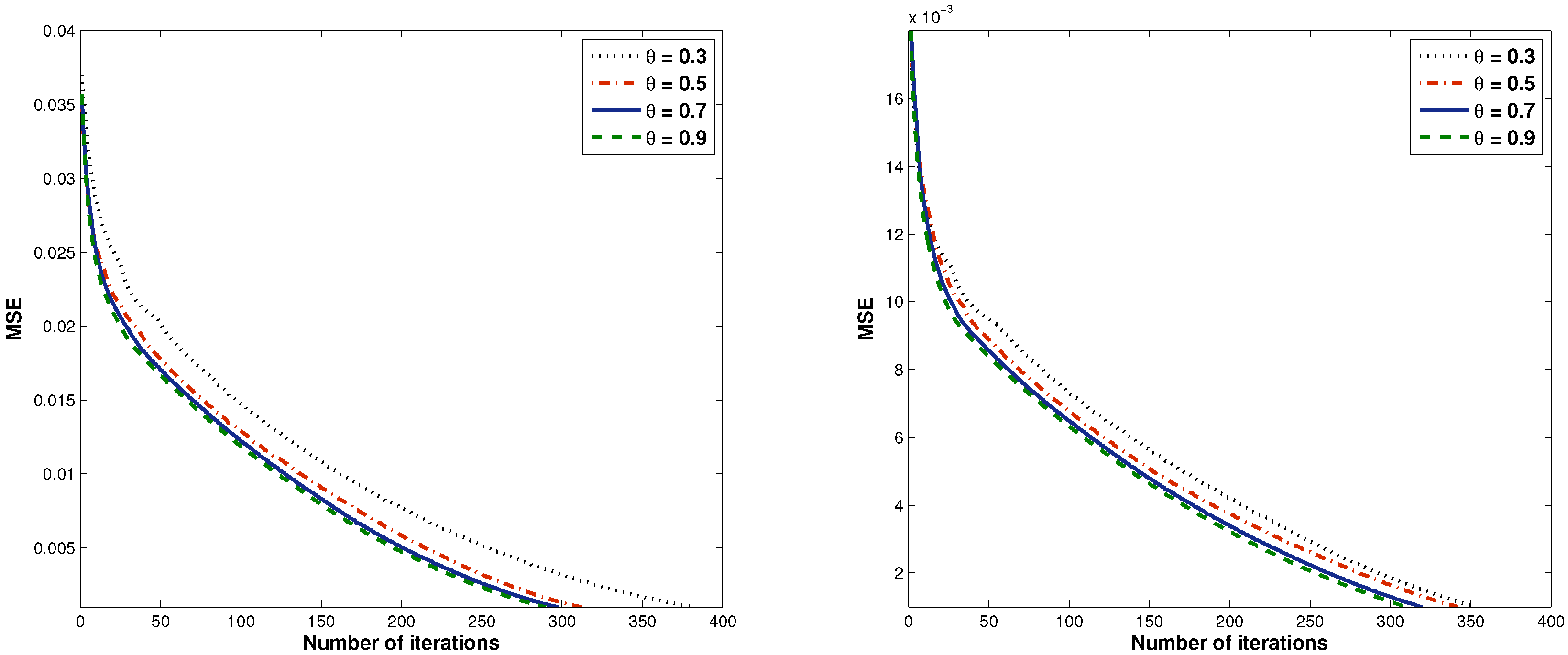
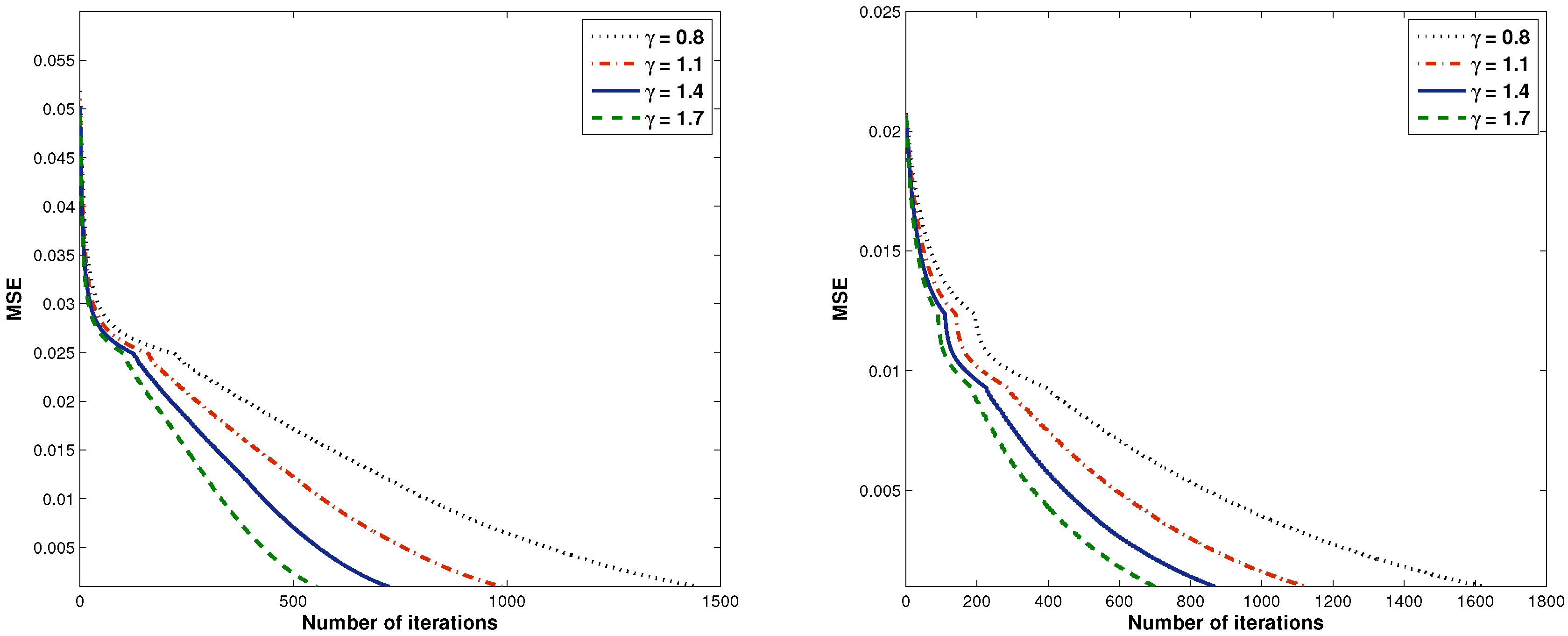
4. Numerical Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dunn, J.C. Convexity, monotonicity, and gradient processes in Hilbert space. J. Math. Anal. Appl. 1976, 53, 145–158. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Xiu, N. Convergence of the gradient projection method for generalized convex minimization. Comput. Optim. Appl. 2000, 16, 111–120. [Google Scholar] [CrossRef]
- Xu, H.K. Averaged mappings and the gradient-projection algorithm. J. Optim. Theory Appl. 2011, 150, 360–378. [Google Scholar] [CrossRef]
- Guler, O. On the convergence of the proximal point algorithm for convex minimization. SIAM J. Control Optim. 1991, 29, 403–419. [Google Scholar] [CrossRef]
- Martinet, B. Brvév communication. Règularisation d’inèquations variationnelles par approximations successives. Revue franaise d’informatique et de recherche opèrationnelle. Sèrie rouge. 1970, 4, 154–158. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends Optim.. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Rockafellar, R.T. Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 1976, 14, 877–898. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Hong, W.C. Electric load forecasting by complete ensemble empirical mode decomposition adaptive noise and support vector regression with quantum-based dragonfly algorithm. Nonlinear Dyn. 2019, 98, 1107–1136. [Google Scholar] [CrossRef]
- Kundra, H.; Sadawarti, H. Hybrid algorithm of cuckoo search and particle swarm optimization for natural terrain feature extraction. Res. J. Inf. Technol. 2015, 7, 58–69. [Google Scholar] [CrossRef] [Green Version]
- Cholamjiak, W.; Cholamjiak, P.; Suantai, S. Convergence of iterative schemes for solving fixed point problems for multi-valued nonself mappings and equilibrium problems. J. Nonlinear Sci. Appl. 2015, 8, 1245–1256. [Google Scholar] [CrossRef] [Green Version]
- Cholamjiak, P.; Suantai, S. Viscosity approximation methods for a nonexpansive semigroup in Banach spaces with gauge functions. Global Optim. 2012, 54, 185–197. [Google Scholar] [CrossRef]
- Cholamjiak, P. The modified proximal point algorithm in CAT (0) spaces. Optim. Lett. 2015, 9, 1401–1410. [Google Scholar] [CrossRef]
- Cholamjiak, P.; Suantai, S. Weak convergence theorems for a countable family of strict pseudocontractions in banach spaces. Fixed Point Theory Appl. 2010, 2010, 632137. [Google Scholar] [CrossRef] [Green Version]
- Shehu, Y.; Cholamjiak, P. Another look at the split common fixed point problem for demicontractive operators. RACSAM Rev. R. Acad. Cienc. Exactas Fis. Nat. Ser. A Mat. 2016, 110, 201–218. [Google Scholar] [CrossRef]
- Suparatulatorn, R.; Cholamjiak, P.; Suantai, S. On solving the minimization problem and the fixed-point problem for nonexpansive mappings in CAT (0) spaces. Optim. Methods Softw. 2017, 32, 182–192. [Google Scholar] [CrossRef]
- Combettes, P.L.; Wajs, V.R. Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 2005, 4, 1168–1200. [Google Scholar] [CrossRef] [Green Version]
- Bello Cruz, J.Y.; Nghia, T.T. On the convergence of the forward-backward splitting method with line searches. Optim. Methods Softw. 2016, 31, 1209–1238. [Google Scholar] [CrossRef] [Green Version]
- Bauschke, H.H.; Borwein, J.M. Dykstra’s alternating projection algorithm for two sets. J. Approx. Theory. 1994, 79, 418–443. [Google Scholar] [CrossRef]
- Chen, G.H.G.; Rockafellar, R.T. Convergence rates in forward-backward splitting. SIAM J. Optim. 1997, 7, 421–444. [Google Scholar] [CrossRef] [Green Version]
- Cholamjiak, W.; Cholamjiak, P.; Suantai, S. An inertial forward–backward splitting method for solving inclusion problems in Hilbert spaces. J. Fixed Point Theory Appl. 2018, 20, 42. [Google Scholar] [CrossRef]
- Dong, Q.; Jiang, D.; Cholamjiak, P.; Shehu, Y. A strong convergence result involving an inertial forward–backward algorithm for monotone inclusions. J. Fixed Point Theory Appl. 2017, 19, 3097–3118. [Google Scholar] [CrossRef]
- Combettes, P.L.; Pesquet, J.C. Proximal Splitting Methods in Signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Springer: New York, NY, USA, 2011; pp. 185–212. [Google Scholar]
- Cholamjiak, P. A generalized forward-backward splitting method for solving quasi inclusion problems in Banach spaces. Numer. Algorithms 2016, 71, 915–932. [Google Scholar] [CrossRef]
- Tseng, P. A modified forward–backward splitting method for maximal monotone mappings. SIAM J. Control. Optim. 2000, 38, 431–446. [Google Scholar] [CrossRef]
- Cholamjiak, P.; Thong, D.V.; Cho, Y.J. A novel inertial projection and contraction method for solving pseudomonotone variational inequality problems. Acta Appl. Math. 2019, 1–29. [Google Scholar] [CrossRef]
- Gibali, A.; Thong, D.V. Tseng type methods for solving inclusion problems and its applications. Calcolo 2018, 55, 49. [Google Scholar] [CrossRef]
- Thong, D.V.; Cholamjiak, P. Strong convergence of a forward–backward splitting method with a new step size for solving monotone inclusions. Comput. Appl. Math. 2019, 38, 94. [Google Scholar] [CrossRef]
- Suparatulatorn, R.; Khemphet, A. Tseng type methods for inclusion and fixed point problems with applications. Mathematics 2019, 7, 1175. [Google Scholar] [CrossRef] [Green Version]
- Bauschke, H.H.; Combettes, P.L. Convex Analysis and Monotone Operator Theory in Hilbert Spaces; Springer: Berlin/Heidelberg, Germany, 2011; Volume 408. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m-Sparse Signal | Method | N = 512, M = 256 | |
|---|---|---|---|
| CPU | Iter | ||
| m = 10 | Algorithm 1 | 2.4095 | 1150 |
| Algorithm 2 | 22.1068 | 608 | |
| Algorithm 3 | 0.9103 | 399 | |
| Algorithm 4 | 0.7775 | 326 | |
| m = 20 | Algorithm 1 | 7.2877 | 2073 |
| Algorithm 2 | 41.1487 | 1106 | |
| Algorithm 3 | 1.5127 | 589 | |
| Algorithm 4 | 1.3803 | 516 | |
| m = 25 | Algorithm 1 | 10.2686 | 2463 |
| Algorithm 2 | 50.6234 | 1310 | |
| Algorithm 3 | 1.9321 | 706 | |
| Algorithm 4 | 1.7597 | 611 | |
| m = 30 | Algorithm 1 | 13.4585 | 2825 |
| Algorithm 2 | 57.5277 | 1477 | |
| Algorithm 3 | 2.1781 | 751 | |
| Algorithm 4 | 2.0341 | 669 | |
| Given: σ = 100, θ = 0.1, γ = 1.9 | ||||
|---|---|---|---|---|
| δ | N = 512, M = 256 m = 20 | N = 1024, M = 512 m = 20 | ||
| CPU | Iter | CPU | Iter | |
| 0.20 | 3.2934 | 495 | 12.6411 | 487 |
| 0.28 | 3.4913 | 550 | 14.9438 | 533 |
| 0.36 | 3.4361 | 635 | 16.5947 | 605 |
| 0.44 | 4.4041 | 743 | 20.6721 | 703 |
| Given: σ = 100, δ = 0.1, γ = 1.9 | ||||
|---|---|---|---|---|
| θ | N = 512, M = 256 m = 20 | N = 1024, M = 512 m = 20 | ||
| CPU | Iter | CPU | Iter | |
| 0.3 | 4.0185 | 382 | 13.4732 | 354 |
| 0.5 | 4.2358 | 312 | 22.2328 | 342 |
| 0.7 | 7.5081 | 298 | 27.8198 | 320 |
| 0.9 | 21.7847 | 290 | 85.3605 | 311 |
| Given: σ = 100, θ = 0.1, δ = 0.1 | ||||
|---|---|---|---|---|
| γ | N = 512, M = 256 m = 20 | N = 1024, M = 512 m = 20 | ||
| CPU | Iter | CPU | Iter | |
| 0.8 | 13.9690 | 1450 | 38.2790 | 1624 |
| 1.1 | 7.8978 | 988 | 23.3411 | 1124 |
| 1.4 | 5.1804 | 724 | 17.6275 | 866 |
| 1.7 | 3.8323 | 554 | 13.6241 | 700 |
| Given: δ = 0.1, θ = 0.1, γ = 1.9 | ||||
|---|---|---|---|---|
| σ | N = 512, M = 256 m = 20 | N = 1024, M = 512 m = 20 | ||
| CPU | Iter | CPU | Iter | |
| 5 | 4.7055 | 680 | 11.7794 | 496 |
| 30 | 6.2280 | 843 | 11.3827 | 453 |
| 55 | 4.4271 | 634 | 14.2537 | 532 |
| 80 | 3.9635 | 606 | 16.5507 | 596 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suantai, S.; Kankam, K.; Cholamjiak, P. A Novel Forward-Backward Algorithm for Solving Convex Minimization Problem in Hilbert Spaces. Mathematics 2020, 8, 42. https://doi.org/10.3390/math8010042
Suantai S, Kankam K, Cholamjiak P. A Novel Forward-Backward Algorithm for Solving Convex Minimization Problem in Hilbert Spaces. Mathematics. 2020; 8(1):42. https://doi.org/10.3390/math8010042
Chicago/Turabian StyleSuantai, Suthep, Kunrada Kankam, and Prasit Cholamjiak. 2020. "A Novel Forward-Backward Algorithm for Solving Convex Minimization Problem in Hilbert Spaces" Mathematics 8, no. 1: 42. https://doi.org/10.3390/math8010042
APA StyleSuantai, S., Kankam, K., & Cholamjiak, P. (2020). A Novel Forward-Backward Algorithm for Solving Convex Minimization Problem in Hilbert Spaces. Mathematics, 8(1), 42. https://doi.org/10.3390/math8010042