1. Introduction
Over the last two decades, there has been an increasing interest in functional data analysis in econometrics, biometrics, chemometrics, and medical research, as well as other fields. Due to the infinite-dimensional nature of functional data, the classical methods for functional data are no longer applicable. There has been a large amount of work in function data analysis; see Ramsay and Silverman [
1], Cardot et al. [
2], Yao et al. [
3], Lian and Li [
4], Fan et al. [
5], Feng and Xue [
6], Kong et al. [
7], and Yu et al. [
8]. Some methods and theories on partial functional linear models have been proposed. For example, based on a two-stage nonparametric regression calibration method, Zhang et al. [
9] discussed a partial functional linear model. Shin [
10] proposed new estimators of the parameters and coefficient function of partial functional linear model. Lu et al. [
11] considered quantile regression for the functional partially linear model. Yu et al. [
12] proposed a prediction procedure for the partial functional linear quantile regression model. However, the aforementioned articles have a significant limitation. That is, they assumed that response variables are independence variables. However, in many fields, such as economics, finance, and environmental studies, sometimes response variables are dependence spatial variables. Therefore, it is of practical interest to develop more flexible approaches using a broader family of data.
There has been considerable work on dependence spatial variables. One useful approach in dealing with spatial dependence is the spatial autoregressive model, which adds a weighted average of nearby values of the dependent variable to the base set of explanatory variables. Theories and methods based on parametric spatial autoregressive models have been extensively studied in Cliff and Ord [
13], Anselin [
14], and Cressie [
15]. Lee [
16] proposed the quasi-maximum likelihood estimation. Then, Su and Jin [
17] extended the quasi-likelihood estimation method to partially linear spatial autoregressive models. Koch and Krisztin [
18] developed the B-splines and genetic-algorithms method for partially linear spatial autoregressive models. Chen et al. [
19] proposed a new estimation method based on the kernel estimation method. Du et al. [
20] considered partially linear additive spatial autoregressive models, proposed the instrumental variable estimation method, and established the asymptotic normality for the parametric component.
It is a good idea to develop more flexible approaches using a broader family of data, where the limitation can, in principle, be easily solved by proposing a new model. Thus, in this paper, based on spatial variables and functional data, we combine the spatial autoregressive model and the partial functional linear model, and propose a partial functional linear spatial autoregressive model.
Let
be a real-valued dependence spatial variable corresponding to the
ith observation,
be a
p-dimensional vector of associated explanatory variables, for
.
be zero mean random functions belonging to
, and be independent and identically distributed,
. For simplicity, we suppose throughout that
. The partial functional linear spatial autoregressive model is given by
where
is the
th element of a given
non-stochastic spatial weighting matrix
, such that
for all
,
is a specified
spatial weight matrix. The definition of spatial weight matrix
is based on the geographic arrangement of the observations or contiguity. More generally,
matrices can be specified based on geographical distance decay, economic distance, and the structure of a social network.
is a vector of
p-dimensional unknown parameters,
is a square integrable unknown slope function on [0, 1], and
are independent and identically distributed random errors with zero mean and finite variance
.
There are many methods which can be used to deal with functional data, such as the functional principal component method, spline methods, and the rough penalty method. Functional principal component analysis (FPCA) can analyse an infinite dimensional problem by a finite dimensional one—therefore, FPCA is popular and widely used by researchers. Dauxois et al. [
21] investigated the asymptotic theory of FPCA. Cardot et al. [
22] applied FPCA to estimate the slope function of the functional linear model. Hall and Horowitz [
23] and Hall and Hosseini-Nasab [
24] showed the optimal convergence rates of slope function based on the FPCA technique.
In this paper, we consider the estimating problem of the model (1). Based on FPCA and the instrumental variable estimation techniques, we obtain the estimators of the parameters and slope function of model (1) with the two-stage least squares method. Under some mild conditions, the rate of convergence and asymptotic normality of the resulting estimators are established. Finally, some simulation studies are carried out to assess the finite sample performance of the proposed method. The results are encouraging and show that all estimators perform well in finite samples. Overall, simulation experiments lend support to our asymptotic results.
The rest of the paper proceeds as follows. In
Section 2, functional principal component analysis and the instrumental variable estimation method is proposed to estimate the partial functional linear spatial autoregressive regression model. In
Section 3, the asymptotic properties are given. Some simulation studies are described in
Section 4. Lastly, we conclude the paper in
Section 5 with some future work.
2. Estimation Procedures
First, we introduce FPCA. Denote the covariance function of
by
. Then, by Mercer’s Theorem, we can obtain the spectral decomposition as
, where
are the eigenvalues of the linear operator associated with
, and
are the corresponding eigenfunctions. By the Karhunen-Loève expansion,
can be represented as
where the coefficients
are uncorrelated random variables with mean zero and variances
, also called the functional principal component scores. Expanded on the orthonormal eigenbasis
, the slope function can be written as
. Based on the above FPCA, model (1) can be well-approximated by
where
represents the
inner product,
, and
m is sufficiently large.
The approximate model (2) naturally suggests the idea of principal components regression. However, in practice,
are unknown and must be replaced by estimates in order to estimate
and
. For this purpose, we consider the empirical version of
, which is given by
where
are pairs of eigenvalues and eigenfunctions for the covariance operator associated with
and
We take
as the estimator of
.
Replacing
by
, model (2) can be written as
Let
,
,
,
and
,
,
, model (3) can be written as matrix notation
Let
denote the projection matrix onto the space spanned by
, and we obtain
Let
,
, applying the two-stage least squares procedure proposed by Kelejian and Prucha [
25], we propose the following estimator
where
and
is matrix of instrumental variables. Moreover,
Consequently, we use as the estimator of .
Similar to Zhang and Shen [
26], we next construct the instrument variables
. In the first step, the following instrumental variables are obtained
where
and
are obtained by simply regressing
on pseudo regressor variables
. In the second step, we use
to obtain the estimators
and
, and then we can construct the instrumental variables
To implement our estimation method, we need to choose
m. Here, truncation parameter
m is selected by AIC criterion. Specifically, we minimize
where
with
and
being the estimated value.
3. Asymptotic Properties
In this section, we discuss the asymptotic normality of and the rate of convergence of . For convenience and simplicity, we let c denote a positive constant that may be different at each appearance. The following assumptions will be maintained throughout the paper.
Assumption 1. The matrix is nonsingular with .
Assumption 2. The row and column sums of the matrices and are bounded uniformly in absolute value for any .
Assumption 3. For matrix , there exists a constant such that is a positive, semidefinite matrix.
Assumption 4. in probability for some positive definite matrix, where ,
Assumption 5. For matrix , there exists a constant such that is a positive semidefinite matrix.
Assumption 6. The random vector Z has bounded fourth moments.
Assumption 7. For any , there exists an , such that For each integer , is bounded uniformly in k.
Assumption 8. is twice continuously differentiable on with probability 1 and , denotes the second derivative of .
Assumption 9. There exists some canstants and , such that and for .
Assumption 10. For truncation parameter m, we assume that .
Assumptions 1–3 impose restrictions on the spatial weighting matrix, and these restrictions are imposed for the spatial regression models (see Lee [
16]; Zhang and Shen [
26]; Du et al. [
20]). Let the weighting matrix
, where
is a
D-dimensional unit matrix,
,
is the
-dimensional unit vector, and ⊗ is a Kronecker product, then weighting matrix
can satisfy Assumptions 1–3. Assumption 4 is used to represent the asymptotic covariance matrix of
Assumption 5 is required to ensure the identifiability of parameter
Assumption 6 is the usual condition for the proofs of asymptotic properties of the estimators. Assumptions 7–9 are regularity assumptions for functional linear models (see Hall and Hosseini-Nasab [
24]), where a Gaussian process with H
lder continuous sample paths satisfies Assumption 7. Assumption 10 usually appears in functional linear regression (see Feng and Xue [
6]; Shin [
10]; Hall and Horowitz [
23]).
The following Theorem 1 shows the asymptotic property of the estimator of the parameter vector
Theorem 1. Under the Assumptions 1–10, thenwhere and “” denotes convergence in distribution. Proof of Theorem 1. By the definition of
, we have
First, consider
. Recall that when
it has
where
,
,
.
By the properties of projection matrix and Assumption 3, we have
By straightforward algebra, one has
. In addition, based on Assumption 3,
Therefore, we have . Similarly, we have
Combining the convergence rates of
,
and
, we have
Now, we consider
. Obviously,
where
By
1 of
et al. [
27], we have
By
of
et al. [
7] with the help of Assumptions 7–9, we have
By Assumptions 7 and 9, one has
By Assumptions 9–10, one has
Combining this with Assumption 4, we have
Thus, we can get Similarly, we have
Invoking the central limit theorem and Slutsky’s theorem, we have
□
Rate of convergence of the slope function is given in the following theorem.
Theorem 2. Under the Assumptions 1–10, then The proof of Theorem 2 follows the proof of Theorem 2 of
[
10], so we omitted it here.
4. Simulation Study
In this section, we conduct simulation studies to assess the finite sample performance of the proposed estimation method. The data
are generated from the following model
where
,
,
and
are independent and following uniform distributions on
and [0, 1] respectively, for
,
,
,
.
We suppose the functional predictors can be expressed as
, where
are independently distributed as the normal with mean 0 and variance
,
. For the actual observations, we assume that they are realizations of
at an equally spaced grid of 100 points in [0, 1]. As we have said in
Section 2, the truncation parameters
m are selected by AIC criterion in our simulation. Similar to Lee [
16] and Case [
28], we focus on the spatial scenario with
R number of districts,
q members in each district, and with each neighbor of a member in a district given equal weight, that is,
, where
,
is the
q-dimensional unit vector, and ⊗ is a Kronecker product. Some simulation studies are examined with different values of
R for 50 and 70,
q for 2, 5, and 8, and
for 0.25 and 1. For comparison, three different values
are considered, which represent spatial dependence of the responses from weak to strong.
= 0.2 represents weak spatial dependence, and
= 0.5 represents mild spatial dependence, whereas
= 0.7 represents relatively strong spatial dependence.
Throughout the simulations, for different scalar parameters
,
and
, we use the average bias, standard deviation (SD) as a measure of parametric estimation accuracy. The performance of the estimator of the slope function
is assessed using the square root of average squared errors (RASE), defined as
where
are the regular grid points at which the function
is evaluated. In our simulation,
is used.
The sample size is
. We use 1000 Monte Carlo runs for estimation assessment, and then summarize the results in
Table 1,
Table 2 and
Table 3 and
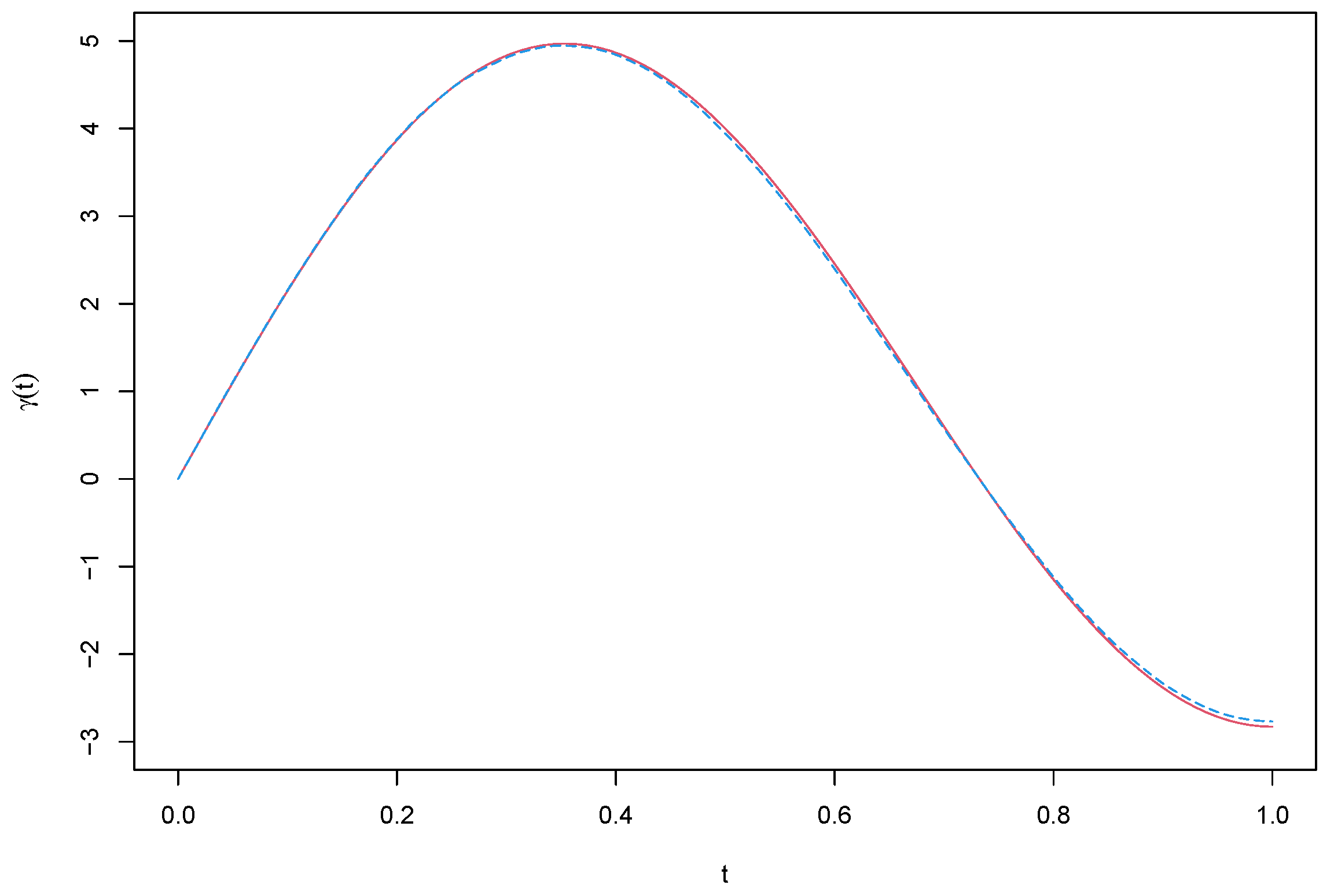
Figure 1 and
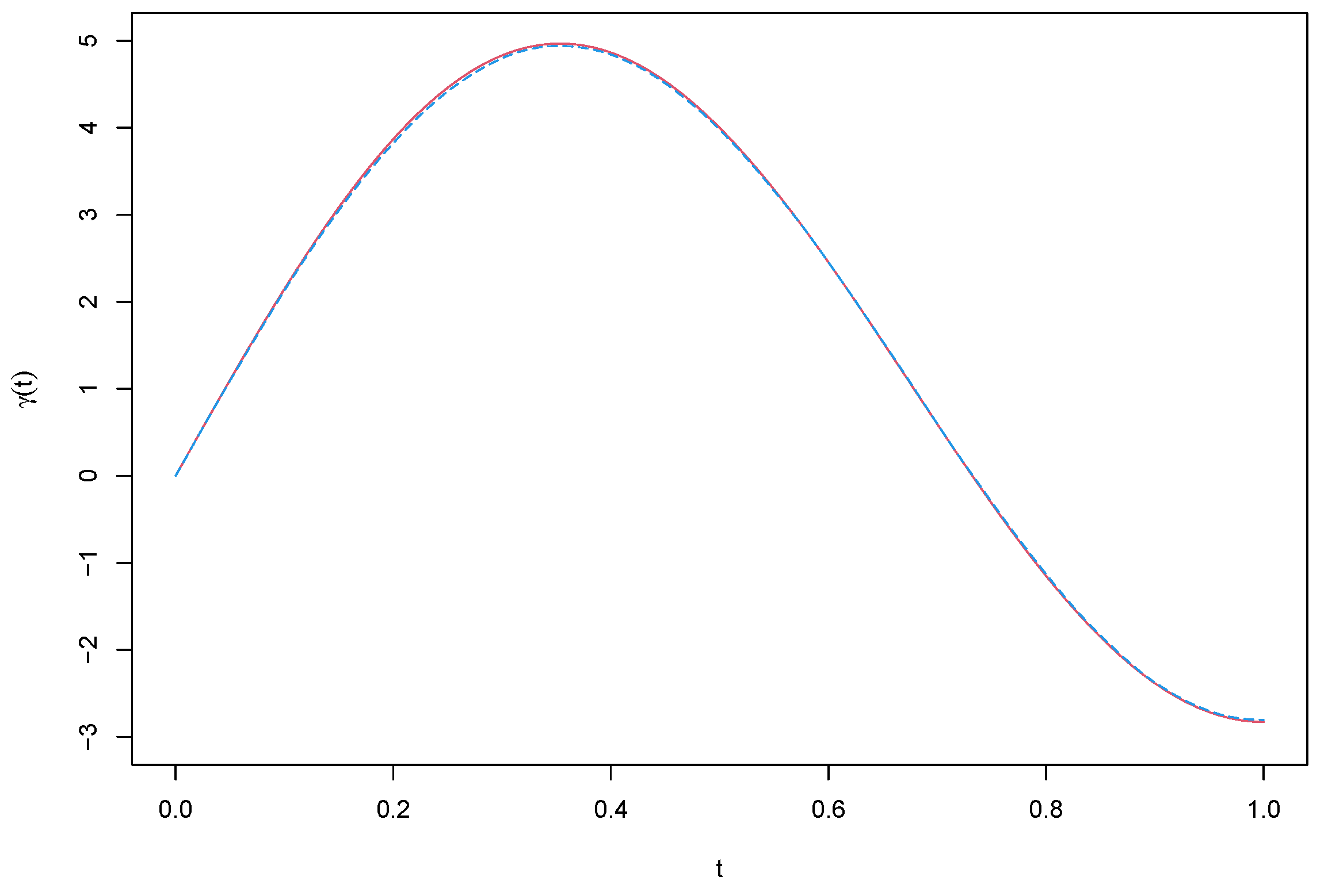
Figure 2.
Table 1,
Table 2 and
Table 3 list average Bias and SD of the estimators of
,
, and
, and average RASE of the estimator of
in the 1000 replications.
Figure 1 and
Figure 2 present the average estimate curves of
.
From
Table 1,
Table 2 and
Table 3 and
Figure 1 and
Figure 2 we can see that: (1) The biases of
,
and
are fairly small for almost all cases. (2) The standard deviation of
,
and
decrease as either
R or
q increases. (3) The RASEs of
are small for all cases and decrease as sample size
n increases or
decreases, and it can be concluded that the estimate curves fit better to the corresponding true line, which coincides with what was discovered from
Figure 1 and
Figure 2. Overall, the simulation results suggest that the proposed estimation procedure is effective for the partial functional linear spatial autoregressive model.






{kind=link}
{kind=link}