1. Introduction
Problem description and motivation: Multi-agent scheduling has attracted an ever-increasing research interest due to its extensive applications (see the book of Agnetis et al. [
1]). Among the common four problem-versions (including lexical-, positive-combination-, constrained-, and Pareto-scheduling, as shown in Li and Yuan [
2]) for a given group of criteria for multiple agents, Pareto-scheduling has the most important practical value, since it reflects the effective tradeoff between the actual and (usually) conflicting requirements of different agents.
Our considered problem is formally stated as follows. Assume that two agents (A and B) compete to process their own sets of independent and non-preemptive jobs on a single machine. The set of the jobs from agent is with . For convenience, we call a job from agent X an X-job. All jobs are available at time zero, and are scheduled consecutively without idle time due to the regularity of the objective functions as shown later. Each job has a processing time and a weight . In addition, each B-job has also a common due date d. We assume that all parameters , and d are known integers.
Let
be a schedule. We use
to denote the completion time of job
in
. The objective function of agent A is the total weighted completion time, denoted by
, while the objective function of agent B is the total weighted late work, denoted by
. Here, the late work
of job
indicates the amount processed after the due date
d, specifically,
Following Hariri et al. (1995) [
3], job
is said to be
early,
partially early, and
late in
, if
,
, and
, respectively.
Falling into the category of Pareto-scheduling, the problem studied in this paper aims at generating all Pareto-optimal points (PoPs) and the corresponding Pareto-optimal schedules (PoSs) (the definitions of PoPs and PoSs will be given in
Section 2) of all jobs with regard to
and
). Using the notations in Agnetis et al. [
1], our studied scheduling problem can be denoted by
. For this problem, we will devise some efficient approximate algorithms.
Our considered scheduling model arises from many practical scenarios. For example, in a factory, two concurrent projects (A and B), each containing a certain amount of activities with distinct importance, have to share a limited resource. The former focuses on the mean completion time of its activities. In contrast, the latter requires its activities to be completed before the due date as much as possible, since, otherwise, the shortcomings of some key technical forces after the due date will occur and result in irretrievable loss. It is necessary to model the goal of project B as the weighted late work, that is, minimizing the parts left unprocessed before the due date. In addition, two projects naturally have to negotiate to seek a trade-off method of utilizing the common resource.
For another example, in a distribution center, two categories (A- and B-) goods are stored in a warehouse, in which the former comprises common goods and the latter comprises fresh goods with a shelf life. It is hoped that the shipping preparations for the A-goods will be completed as soon as possible. However, due to their limited shelf life, if they are transported after a certain time, the B-goods will not be fresh enough when they reach the customers. Therefore, it is reasonable to respectively model the goals of A-goods and B-goods by minimizing the total weighted completion time and the total weighted late work, and seek an efficient transportation method.
Related works and our contribution: Numerous works have addressed multi-agent scheduling problems in the literature. With the aim of this paper, we only summarize briefly some related results. Wan et al. [
4] provided a strongly polynomial-time algorithm for the two-agent Pareto-scheduling problem on a single machine to minimize the number of the tardy
A-jobs and the maximum cost of the
B-jobs. Later, Wan et al. [
5] investigated two Pareto-scheduling problems on a single machine with two competing agents and a linear-deterioration processing time:
and
, where
is the total earliness of the A-jobs and
is the maximum earliness of the X-jobs. For these two problems, they respectively proposed a polynomial-time algorithm. Gao and Yuan [
6] showed that the following two Pareto-scheduling problems with a positional due index and precedence constraints are both polynomially solvable:
and
, where
indicates the maximum cost of the X-jobs. He et al. [
7] extensively considered the versions of the problems in Gao and Yuan [
6] with deteriorating or shortening processing times and without positional due indices and precedence constraints, and devised polynomial-time algorithms. Yuan et al. [
8] showed the single-machine preemptive problem
can be solved in a polynomial time, where
indicates the maximum lateness of the X-jobs. Wan [
9] investigated the single-machine two-agent scheduling problem to minimize the maximum costs with position-dependent jobs, and developed a polynomial-time algorithm.
While most results on Pareto-scheduling concentrate on devising exact algorithms to obtain the Pareto frontier, there are also some methods (such as [
10,
11,
12,
13,
14]) of developing approximate algorithms to generate the approximate Pareto frontier. Dabia et al. [
10] adopted the trimming technique to derive the approximate Pareto frontier for some multi-objective scheduling problems. Yin et al. [
15] considered two just-in-time (JIT) scheduling problems with two competing agents on unrelated parallel machines, in which the one agent’s criterion is to maximize the weighted number of its JIT jobs, and another agent’s criterion is either to maximize its maximum gains from its JIT jobs or to maximize the weighted number of its JIT jobs. They showed that the two problems are both unary NP-hard when the machine number is not fixed, and proposed either a polynomial-time algorithm or a fully polynomial-time approximation scheme (FPTAS) when the machine number is a constant. Yin et al. [
16] also considered similar problems in the setting of a two-machine flow shop, and provided two pseudo-polynomial-time exact algorithms to find the Pareto frontier. Chen et al. [
17] studied a multi-agent Pareto-scheduling problem in a no-wait flow shop setting, in which each agent’s criterion is to maximize its own weighted number of JIT jobs. They showed that it is unary NP-hard when the number of agents is arbitrary, and presented pseudo-polynomial time algorithms and an
-approximation algorithm when the number of agents is fixed.
From the perspective of methodology, as a type of optimization problem, the multi-agent scheduling problem’s solution algorithms potentially allow for exploiting the optimal robot path planning by a gravitational search algorithm (Purcaru et al. [
18]) and optimization based on phylogram analysis (Soares et al. [
19]).
In the prophase work (Zhang and Yuan [
20]), we proved that the constrained scheduling problem of minimizing the total late work of agent A’s jobs with equal due dates subject to the makespan of agent B’s jobs not exceeding a given upper bound, is NP-hard even if agent B has only one job. It implies the NP-hardness of our considered problem in this paper. Thus we limit the investigation to devising pseudo-polynomial-time exact algorithms and an approximation algorithm to generate the approximate Pareto frontier.
In addition, in our recent work (Zhang et al. [
21]), we considered several three-agent scheduling problems under different constraints on a single machine, in which the three agents’ criteria are to minimize the total weighted completion time, the weighted number of tardy jobs, and the total weighted late work. Among those problems, there are two questions related to this paper:
, which is solved in
, and
, which is solved in
. The notation
represents that the jobs of the first agent have inversely agreeable processing times and weights, i.e., the smaller the processing time for a job, the greater its weight, and the notation
represents that the jobs of agent
B have inversely agreeable due dates and weights.
and
are the upper bounds on the criteria
and
, respectively. In contrast to Zhang et al. [
21], in this article we remove the constraint
and turn to the optimization problem of
B-jobs having a common due date.
The remainder of the paper is organized as follows. In
Section 2, some preliminaries are provided. In
Section 3 and
Section 4, we present two dynamic programming algorithms and an FPTAS. In
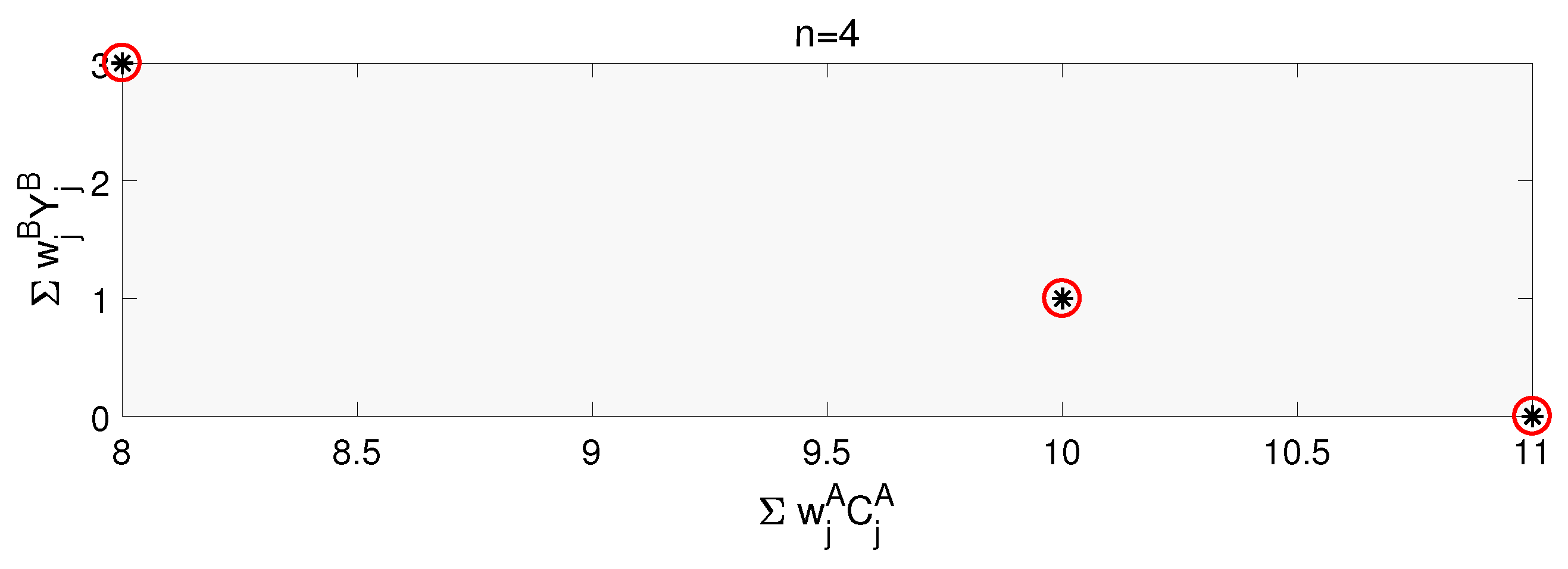
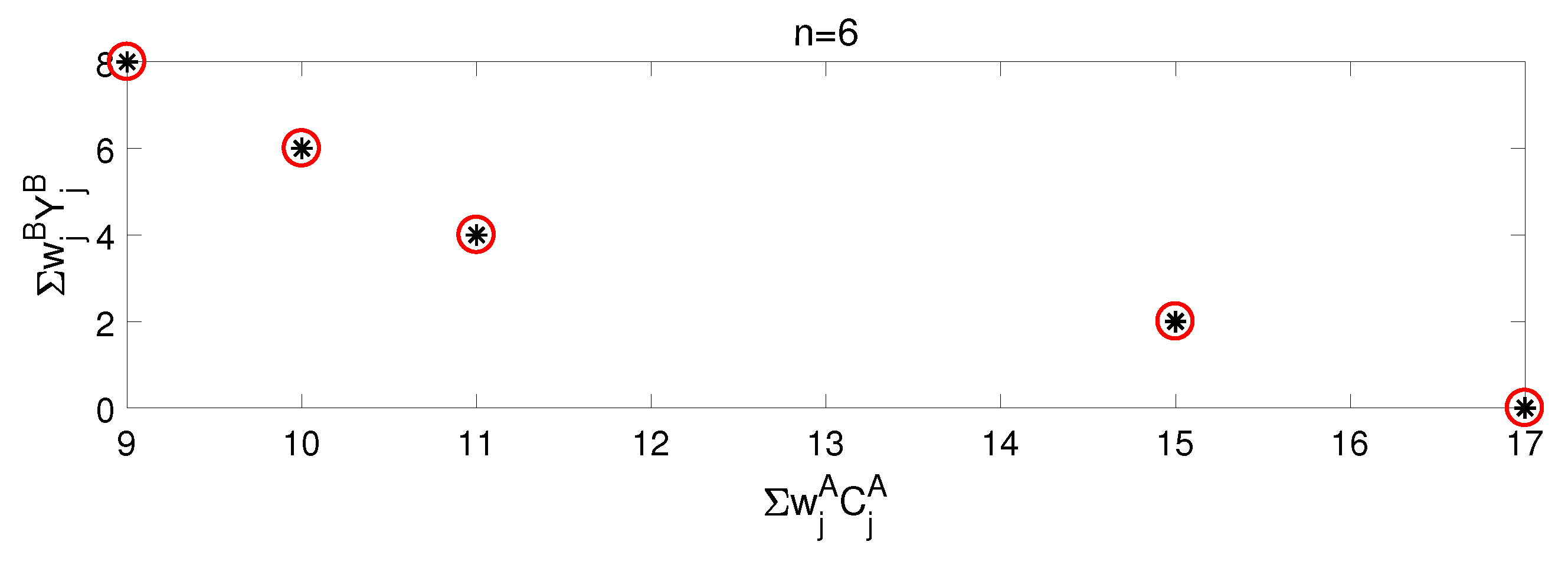
Section 5, some numeral tests are undertaken to show the algorithms’ efficiency.
Section 6 concludes the paper and suggests the future research direction.
2. Preliminaries
For self-consistency, in this section we describe some notions and properties related to Pareto-scheduling, and we present other useful notations in the description of the algorithms in the following sections.
Definition 1. Consider two m-vectors and .
(i) We say that dominates , denoted by , if for .
(ii) We say that strictly dominates , denoted by , if and .
(iii) Given a constant , we say that -dominates , denoted by , if and only if for .
Definition 2. Given two agents’ criteria and , a feasible schedule σ is called Pareto-optimal and the corresponding objective vector is called a Pareto-optimal point, if no other feasible schedule π satisfies . All the Pareto-optimal points form the Pareto frontier, denoted by .
Let be the set of the objective vectors of all feasible schedules, and be a subset of .
Definition 3. A vector is called non-dominated in , if there exists no other vector such that .
It is not difficult to see that, for the above definitions, the latter is an extension of the former, and especially when is exactly equal to , all the non-dominated vectors in compose the Pareto-optimal frontier. The following lemma establishes the relationship between sets and a subset .
Lemma 1. For any set with , if is the set including all the non-dominated vectors in , then .
Proof. By Definition 2, for each Pareto-optimal point , there is no other vector such that , and naturally, such a fact also holds for the set , since . Then, it follows that by the definition of the set . Next we show that . If not, we pick up one vector from . Again by Definition 2, there is some vector such that . Nevertheless, this is impossible, since leads to no existence of such a vector in by the assumption of and Definition 3. Thus . □
From Lemma 1, to generate the Pareto frontier , an alternative is to first determine a set with , and then delete the dominated vectors in . Throughout the reminder of this paper, such a subset is called an intermediate set. Obviously, is also an intermediate set.
Definition 4. For a given constant , a -approximate Pareto frontier, denoted by , is a set of the objective vectors satisfying, for any , there exists at least one objective vector such that .
Definition 5. A family of algorithms is called afully polynomial-time approximation scheme(FPTAS) if, for each , generates a -approximate Pareto frontier with a running time in the polynomial in the instance size and .
Besides those already mentioned in
Section 1, the following notations will also be used later:
indicates the set of the first j jobs in , namely, .
indicates that job immediately precedes in schedule , where .
indicates the starting time of job in .
indicates the total processing time of all X-jobs.
indicates the total processing time of all jobs, and .
indicates the total weight of all X-jobs.
indicates the total weight of all jobs, and .
indicates the maximum processing time of the X-jobs, namely, .
indicates the maximum weight of the X-jobs, namely, .
3. An Exact Algorithm
In this section a dynamic programming algorithm for problem is presented. For description convenience, for a given schedule , the job set is divided into the following four subsets: , , , and . Obviously, such a partition of the job set is well defined for a given schedule.
The following lemma establishes the structural properties of the Pareto-optimal schedule.
Lemma 2. For each Pareto-optimal point of problem , there is a Pareto-optimal schedule σ such that
(i) .
(ii) the jobs in are sequenced in the non-increasing order of their weights and the jobs in are sequenced arbitrarily.
(iii) the jobs in and are sequenced according to the weighted shortest processing time (WSPT) rule.
Proof. In Lemma 2, statement (i) can easily be observed, since the jobs in are late and this will not result in any increase in their total late work when moving them to the end of the schedule, and as many A-jobs as possible can be positioned before the B-jobs in , provided that the last job in is not late. The left two statements in Lemma 2 can easily be proved by an interchange argument and the detail is omitted here. □
Lemma 2 allows us only to consider the feasible schedules simultaneously satisfying the conditions (i)-(iii). To this end, we re-number the
jobs in
in the WSPT order and the
B-jobs in the maximum weight first (MW) order so that
Such a sorting takes time.
According to Lemma 1, the algorithm to be described adopts the strategy of first finding the intermediate set dynamically and then deleting the dominated points in it. It is necessary to mention that in the proposed algorithm we appropriately relax the conditions to find a modestly larger intermediate set. For briefly describing the dynamic programming algorithm, we introduce the following terminologies and notations.
an -schedule is defined to be a schedule for satisfying (i) , where among the four mutually disjointed subschedules , the A-jobs are included in and , and the B-jobs are included in and ; (ii) no idle time exists between the jobs in each subschedule, but this is not necessarily so between two subschedules. Moreover, the idle time between and is supposed to be long enough; (iii) the jobs in each subschedule are sequenced in the increasing order of their indices.
an -schedule is defined to be an -schedule for with no idle time existing between subschedules and , where and .
a vector is introduced to denote a state of , in which , and Y, respectively, stand for the end point of , the start point of , the end point of , the total weighted completion time of the A-jobs of , and the total weighted late work of the B-jobs of . Note that a state of at least corresponds to some -schedule.
denotes the set of all the states of .
denotes the set obtained from by deleting the vectors , for which there is another vector with , and .
Let , and let be the set of the non-dominated vectors in .
To solve problem , we have to first compute and then obtain the Pareto-frontier . This can be realized by dynamically computing the sets for all the possible choices of the tuple . Note that each -schedule can be obtained either by adding job to some -schedule, or by adding job to some -schedule. Therefore, we can informally describe our dynamic programming algorithm as follows.
Initially, set and if . Then we recursively generate all the state sets from the previously-generated sets and . Specifically,
For each state
with
, add two states
and
to the set
, with
and
These two states respectively correspond to the newly obtained -schedules by scheduling job immediately following the subschedule and immediately following the subschedule , in some schedule that corresponds to the state . Note that the first case occurs only when is satisfied.
For each state
, also add two two states
and
to the set
, with
and
These two states respectively correspond to the newly obtained -schedules by scheduling job immediately preceding the subschedule and immediately following the subschedule , in some schedule that corresponds to the state . Note that the first case occurs only when is satisfied.
Note that, if in the above state-generation procedures we replace sets and with sets and , then the resulting set of new states, denoted by , may be different from . Recall that, when deleting those dominated vectors in the sets and , the newly obtained sets are respectively denoted by and , which will be shown to be identical in the following lemma.
Lemma 3. .
Proof. Since and , it follows that by the generation procedure of the new states as described previously. If , then naturally . In the following, suppose that . We next show that each state is dominated by a state , namely, .
Let be an -schedule corresponding to . According to the above discussion, there are four possibilities of deriving from some schedule , which is assumed to correspond to the state in or .
Case 1. is obtained from
by scheduling job
directly after subschedule
. Then
with
, and there is a state
such that
, and
. Let
be an
-schedule corresponding to
, and let
be the
-schedule obtained from
by scheduling
directly after schedule
. Let
be the state corresponding to
. Note that the above operation to get
is feasible since
. Then we have
Combining with the fact that
, we have
Case 2. is obtained from
by scheduling
directly after schedule
. Then
, and there is a state
such that
, and
. Let
be an
-schedule corresponding to
, and let
be the
-schedule obtained from
by scheduling
directly after schedule
. Let
be the state corresponding to
. Then we have
Combining with the fact that
, we have
Case 3. is obtained from by scheduling directly before schedule . Note that in this case, the condition must be satisfied. Then , and there is a state such that , and . Let be an -schedule corresponding to , and let be the -schedule obtained from by scheduling directly before schedule . Let be the state corresponding to . The above operation to obtain is feasible. In fact, , which means there are enough spaces for to be scheduled in. In the following we will illustrate that the condition is satisfied.
Claim 1.If , then .
Suppose to the contrary that , then is partially early or late in , implying that are all late in , i.e., there is no job in , which further suggests that . What is more, since , the jobs are also late in , which also indicates that and . From , , , and we know that contradicts . Thus, . Claim 1 follows.
If
, then
. From Claim 1 we have
, i.e.,
, which is a contradiction. Thus the condition
is satisfied and the operation to get
is feasible. Then we have
Combining with the fact that
, we have
Next we prove that . In fact, if , then . If , then from Claim 1 we know that , and then . Thus we have .
Case 4. is obtained from
by scheduling
directly after schedule
. Then
, and there is a state
such that
, and
. Let
be an
-schedule corresponding to
, and let
be the
-schedule obtained from
by scheduling
directly after schedule
. Let
be the state corresponding to
. Then we have
Combining with the fact that
, we have
The result follows. □
Theorem 1. Algorithm 1 solves the Pareto-frontier scheduling problem in time.
| Algorithm 1: For problem |
![Mathematics 08 02070 i001]() |
Proof. The correctness of Algorithm 1 is guaranteed by Lemma 2, Lemma 1, and Lemma 3. Here we only analyze its time complexity. The initialization step takes time, which is dominated by the final time complexity of Algorithm 1. In the implementation of Algorithm 1, we guarantee that . Note that and , then each state set contains states. Moreover, is obtained by performing at most two (constant) operations on the states in for , . Note that the upper bounds of and are given by and , respectively. Thus, the overall running time of Algorithm 1 is . □
4. An FPTAS
In this section, for problem , we first give another dynamic programming algorithm, and then turn it into an FPTAS by the trimming technique. As for Algorithm 1, we first introduce the following terminologies and notations.
An -schedule is defined to be an ABAB-schedule for with no idle time existing between subschedules , and , where and .
A vector is introduced to denote a state of , in which and Y, respectively, stand for the end point of , the end point of , the end point of , the total weight of the jobs in , the index of the last B-job in , the total weighted completion time of the A-jobs of , and the total weighted late work of the B-jobs of . Note that a state of at least corresponds to some -schedule.
denotes the set of all the states of .
denotes the set obtained from by deleting the vectors , for which there is another vector with .
Let , and let be the set of the non-dominated vectors in .
Clearly, is an intermediate set. Similarly to the discussion for Algorithm 1, we can generate all the for all the possible choices of the tuple dynamically in the following way.
Initially, set and if . Then we recursively generate all the state sets from the previously generated sets and . Specifically,
For each state
with
, add two states
and
to the set
, with
These two states respectively correspond to the newly obtained -schedules by scheduling job immediately following the subschedule and immediately following the subschedule , in some schedule that corresponds to the state . Note that the first case occurs only when is satisfied.
For each state
, also add two two states
and
to the set
, with
and
These two states respectively correspond to the newly obtained -schedules by scheduling job immediately after and immediately following the subschedule , in some schedule that corresponds to the state . Note that the first case occurs only when is satisfied.
Note that, if in the above state-generation procedures we replace sets and with sets and , then the resulting set of new states, denoted by , may be different from . Recall that, when deleting those dominated vectors in the sets and , the newly obtained sets are respectively denoted by and , which will be shown to be identical in the following lemma, and its proof is similar to that of Lemma 3.
Lemma 4. .
Theorem 2. Algorithm 2 solves in time.
| Algorithm 2: For solving |
![Mathematics 08 02070 i002]() |
Proof. The correctness of Algorithm 2 is guaranteed by the discussion above. Next we only analyze its time complexity. The initialization step takes time, which is dominated by the final time complexity of Algorithm 2. In the implementation of Algorithm 2, we guarantee that . Note that and , and , then each state set contains states. Moreover, is obtained by performing at most two (constant) operations on the states in for , . Thus, the overall running time of Algorithm 2 is . □
Next we turn Algorithm 2 into an FPTAS in the following way. Set
,
,
,
,
and
. Set
for
,
for
,
for
,
for
and
for
. For
and
,
is obtained from
by the following operation: for any two states
and
in
, if
and
fall into the same box
for
,
,
,
and
with
, remaining the first one. Note that it takes
time to partition the boxes. Moreover, we define
and let
be the set of non-dominated vectors in
.
Theorem 3. Algorithm 3 is an FPTAS for solving .
| Algorithm 3: For solving |
![Mathematics 08 02070 i003]() |
Proof. By induction on , We prove that, for any state , there is a state such that , , , , and .
This is obviously true for . Inductively suppose that it holds up to . Next we show that it also holds for z. Recall that each state is derived from some state in or . Let be an -schedule corresponding to , and let be a schedule corresponding to the state . Using the induction hypothesis, there is a state in or such that , and . Let be an -schedule or -schedule corresponding to , and if it is feasible, let be the -schedule obtained from by performing the same operation that we perform on to get . Let be the state corresponding to . Furthermore, there is a state in the same box with such that , , , , and . There are four possible ways to get from .
Case 1. is obtained from
by scheduling
directly after schedule
. Note that in this case, the condition
must be satisfied. Then
, and the operation to get
is feasible since
. Then we have
Combining with the fact that
, we have
Case 2. is obtained from
by scheduling
directly after schedule
. Then
, and
is clearly a feasible schedule. Then we have
Combining with the fact that
, we have
Case 3. is obtained from
by scheduling
directly after schedule
. Note that in this case, the condition
must be satisfied. Then
, and the operation to get
is feasible since
. Then we have
Combining with the fact that
, we have
Case 4. is obtained from
by scheduling
directly after schedule
. Then
, and
is clearly a feasible schedule. Then we have
Combining with the fact that
, we have
Thus, for each state in , there is a state in such that and .
Next we analyze its time complexity. The initialization step takes time, which is dominated by the final time complexity of Algorithm 3. In the implementation of Algorithm 3, we guarantee that . Note that there are distinct boxes and , then there are at most different states in . Moreover, is obtained by performing at most two (constant) operations on the states in for , . Thus, the overall running time of Algorithm 3 is . □








{kind=link}
{kind=link}
{kind=link}