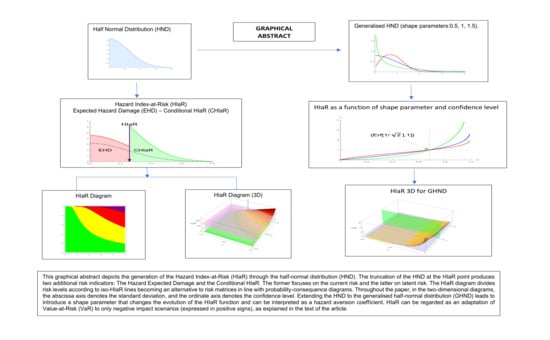
1. Introduction
The probability–severity risk analysis usually estimates the risk levels of different scenarios through the product between the probability and the size of hazards impacts in the framework of risk matrices or continuous probability–consequence diagrams (CPCDs). The current research aims to go a step further by building up a model that adapts the financial risk measures Value-at-Risk (VaR) and Conditional Value-at-Risk (CVaR), the latter also denominated expected short-fall to the probability–severity analysis by taking the half-normal distribution as its central methodological pillar. We call it the “Truncated Risk Model” (TR model) because it admits the substitution of the half-normal distribution by any other truncated probability distribution that fits the scenarios under study. In concordance with the contents of risk matrices, the indicators we present focus on downside risk strictly. Thus, they only capture negative impacts, although, for convenience, we express them in positive units. The uniqueness of the signs makes a truncated probability distribution the appropriate tool for expressing the random nature. Indeed, truncated probability distributions are widely used in risk analysis. In the field of finance, among many other works, Aharony et al. [
1] applied a truncated normal distribution to corporate bankruptcies. Truncations are also central in the Collins and Gbur [
2] study on limited liability through the lenses of safety-first rules. Ergashev et al. [
3] used them in a paper on operational risk modelling. Chen et al. [
4] employed the half-normal distribution in an estimation of the general Bayesian VaR. De Roon and Karehnke [
5] built a transformation of the half-normal distribution, the denominated smooth half-normal, that they apply to VaR and CVaR, among other indicators. Beyond the financial world, truncated distributions are frequently used also in the analysis of natural risk phenomena. Jawitz [
6] studied truncated distributions from the perspective of hydrologic problems. Li et al. [
7] presented an application to flood frequencies. Lasar and Dolsek [
8] analysed seismic risk through truncated distributions. Other applications of truncated distributions can also be found in the fields of engineering [
9] and biology [
10], including medicine. In this respect, we apply the half-normal distribution for its direct connection with the usual presentations of VaR and CVaR through the normal distribution. An extension to the generalised half-normal distribution is also part of the TR model, allowing to complement the scale parameter of the half-normal case with a shape parameter. The generalised half-normal distribution (GHN), proposed by Cooray and Ananda [
11], incorporates a shape parameter to the original half-normal distribution, adding flexibility to its analytical capacity. Pescim et al. [
12] related the generalised half-normal to beta distribution. The empirical applications of these two papers have focused on lifetime and health data.
Risk matrices are widely used in risk analysis despite their limitations. As known, risk matrices identify risk levels by combining the likelihood of hazards with the severity of their impacts, usually through a product. However, the design of risk matrices requires careful attention. The main limitation of risk matrices is that they cannot eliminate residual ambiguity in the classification of risks completely. Risk analysis literature has discussed the applicability of risk matrices and the guidelines for their design. Hopkin [
13], in his handbook on risk management, dealt with the implementation of risk matrices in this field. Cox [
14] reviewed the inconsistencies that risk matrices may present and developed an axiomatic system for their rational construction. Among the inconsistencies, Cox ([
14], p. 507) pointed out that risk matrices may transgress the principle of translation invariance for coherent risk measures [
15]. This transgression is not due to the risk indicator but to the structure of risk matrices. Departing from Cox’s axioms, Li et al. [
16] built a method (the Sequential Updating Approach) for minimising wrong risk pairs in risk matrices. Aven [
17] depicted the limitations of risk matrices, pointing out that they are a tool for describing risk but cannot be taken as a risk analysis method ([
17] p. 143). The same author [
18] pledged to broaden the plain likelihood-severity content of risk matrices by adding the knowledge dimension of risk. Levine [
19] explored the improvements that logarithmic scales can introduce into risk matrices. Baybutt [
20] underlined the importance of calibrating risk matrices and proposed a set of rules to avoid pitfalls in this process. The TR model built in this paper overcomes the limitations of risk matrices, and, at the same time, incorporates risk indicators that can be interpreted in line with the widely accepted risk measures VaR and CVaR but without being constrained to financial analysis. The ambiguities in rankings can be overcome by substituting the rectangular structure of risk matrices in the delimitation of risk categories by continuous iso-risk lines, namely lines that denote the same risk level. This change of indicators leads to a switch from risk matrices to continuous risk combinations.
Continuous combinations have been less studied in the risk literature. An appropriate denomination for them, according to Duijm ([
21], p. 29), is “continuous probability–consequence diagrams” (CPCDs). The continuous probability–consequence diagrams (CPCD) constitute an alternative to risk matrices, switching from the discrete scales of risk matrices to continuous scales based on iso-risk lines. Ale et al. [
22] reviewed the origins and evolution of probability–consequence diagrams as an instrument of risk analysis. Duijm [
21], after clarifying that risk matrices are part of probability–consequence diagrams ([
21], p. 22), as a discrete version of them, developed an in-depth analysis of the comparison between risk matrices and CPCDs, namely between the discrete and continuous versions of probability–severity risk analysis. This author pointed out that, in CPCDs, “it is possible to discriminate between hazards that, in a discrete matrix, would be assigned to the same cell” ([
21], p. 29). Thus, the incorporation of continuity is central for improving the analysis. Ni et al. [
23] developed continuous divisions of risk matrices comparing the effects of different arithmetic combinations between probability and severity. Laine et al. [
24] compared risk matrices and CPCDs in the framework of risk management of pollution at sea. This paper uses the denomination “probability–consequence diagrams” for their continuous version, i.e., for CPCDs, presenting them as a generalisation of risk matrices for continuous scales of measurement ([
24], p. 89). The dominant risk estimator in risk matrices is the product between the probability of the hazard and the size of its impact. This measure is extended to CPCDs. Estimating the risk level in this way reduces the estimation of each hazard to single values of its probability and impact size, instead of representing its random behaviour through a continuous probability distribution. A way to overcome this limitation, explored in
Section 3 and
Section 4, consists of adapting to CPCDs the financial risk measures VaR and CVaR. Hull ([
25], pp. 305–328) offered a synthetic approach to both measures and their main properties. Alexander [
26] presented a comprehensive study of these indicators.
In this line, the TR model extends the denomination of CPCDs to the probability–consequence combinations, based on VaR and CVaR, that it builds up through the half-normal distribution. Among other strong points, VaR and CVaR have the advantage of their links with the properties of coherent risk measures enunciated by Artzner et al. [
15] (monotonicity, translation invariance, positive homogeneity, and subadditivity). As known, CVaR systematically fulfils the four properties, while VaR, in certain circumstances, fails subadditivity. However, VaR fulfils subadditivity for normally distributed returns ([
26], p. 39; [
27], p. 135) and in other more general cases as well [
28].
The research developed in this paper relies on the interactions of the concepts of truncated probability distributions, risk matrices, probability–consequence diagrams, VaR, and CVaR. Risk matrices have their strong point in their communication capacity and the weakest point in their limitations for ranking medium-risk, i.e., yellow, scenarios correctly. CPCDs generate coherent risk rankings, but their analytical capacity depends on the risk measure they incorporate. In other words, a ranking may be correct for a specific risk measure, but this measure may be perfectible. Estimating the risk level through the product between probability and severity restrains the potential for exploring the main risk features of the studied scenarios. VaR and CVaR are risk measures with a higher analytical capacity. However, they have not been adapted to the comparison between probability and severity, which is the primary goal of risk matrices and CPCDs. The fact that the probability–severity approach only deals with negative scenarios makes truncated probability distributions an excellent tool for their study. Risk analysis, including VaR, has widely used these distributions. However, research in academic text databases (Google Scholar, ABI inform, Science Direct, and others) does not show evidence of their adaptation to the probability–severity analysis. To sum up, this synthesis of the risk analysis literature raises the following research question: How can the half-normal distribution improve risk analysis based on the interaction between probability and severity by adapting VaR and CVaR to CPCDs?
The paper is structured as follows.
Section 2 defines the Hazards Index-at-Risk (HIaR) and studies its main properties. This index constitutes an adaptation of the VaR to the CPCDs through the half-normal distribution.
Section 3 builds HIaR diagrams, comparing them with risk matrices.
Section 4 focuses on the study of the Expected Hazards Damage (EHD), which extends HiaR to the expected loss, again through the half-normal distribution.
Section 5 compares the TR model with traditional risk matrices, centring the functional relationships between EHD and the expected loss as estimated in risk matrices.
Section 6 studies the conditional HIaR (CHIaR), underlining the difference between active and latent risks that it helps to identify.
Section 7 presents a subjective approach to the previous topics. The extension of the TR model to the generalised half-normal distribution, focusing on the interpretation and role of its shape parameter, is shown in
Section 8.
Section 9 discusses the results of this paper, and
Section 10 summarises its conclusions. The two appendices present, respectively, a summary of the main properties of the half-normal distribution and obtainment of the expected hazards damage for the generalised half-normal distribution.
Mathematica is the software used in the preparation of our paper.
2. Defining the Hazards Index-at-Risk
The TR model initiated in this section starts by adapting VaR to CPCDs without constraining its results to the financial consequences of risk. For this reason, monetary units are put aside systematically. The model centres on a generic asset (A) that may be damaged by the hazards (H) generated by the risk under study (R). The integrity of the asset concerning risk impacts, i.e., hazards, is represented by the asset’s safety index (SF). Namely,
stands for the safety index of asset A in the face of risk R. To avoid working with negative units, the TR model expresses the risk impacts in positive points that, next, subtracts from the current value of the safety index to obtain its new value. The initial value of the safety index is normalised at 100 points. Hazards reduce this value and even may turn it into a negative one. In this case, the damage caused by hazards goes beyond their impacts on the asset.
Scheme 1 depicts these interactions.
Let us recall that VaR is defined as the maximum loss that an institution faces in the next period with a certain probability,
p. This means, in other words, that the institution does not expect a higher loss than the VaR with probability
1 − p (confidence level). For the case of banks, the usual choice is 1% probability (i.e., 99% confidence level) for ten days. VaR is also used in corporate risk with longer horizons and lower confidence levels. A normal distribution of gains is the most usual in VaR calculations, although other distributions are also applied. This distribution includes gains and losses as negative gains ([
25] p. 305). The TR model displays a setting where only negative impacts, namely losses, are possible. These losses consist of reductions in the safety index. To incorporate them into the TR model, we define the risk rate
as the relative change in the initial value of the safety index produced by a hazard. The risk rate systematically expresses a reduction in the safety index. Losses are calculated as the product of the initial value of the safety index by the current value of the risk rate. Formally, the loss at the moment
and the value of the safety index after this loss
are
The TR model assumes that the risk rate follows a half-normal probability distribution because it can take only positive signs under the assumptions previously introduced. Since losses are expressed as the product between the constant initial value of the safety index and this rate, they follow a half-normal distribution as well.
Appendix A summarises the main properties of the half-normal probability distribution used in this paper.
We define HIaR as the maximum potential reduction that the safety index can suffer in the next period with a probability equal to or lower than the maximum reasonable probability of the hazard occurrence. HIaR shares with VaR the property of being quantiles. Alexander ([
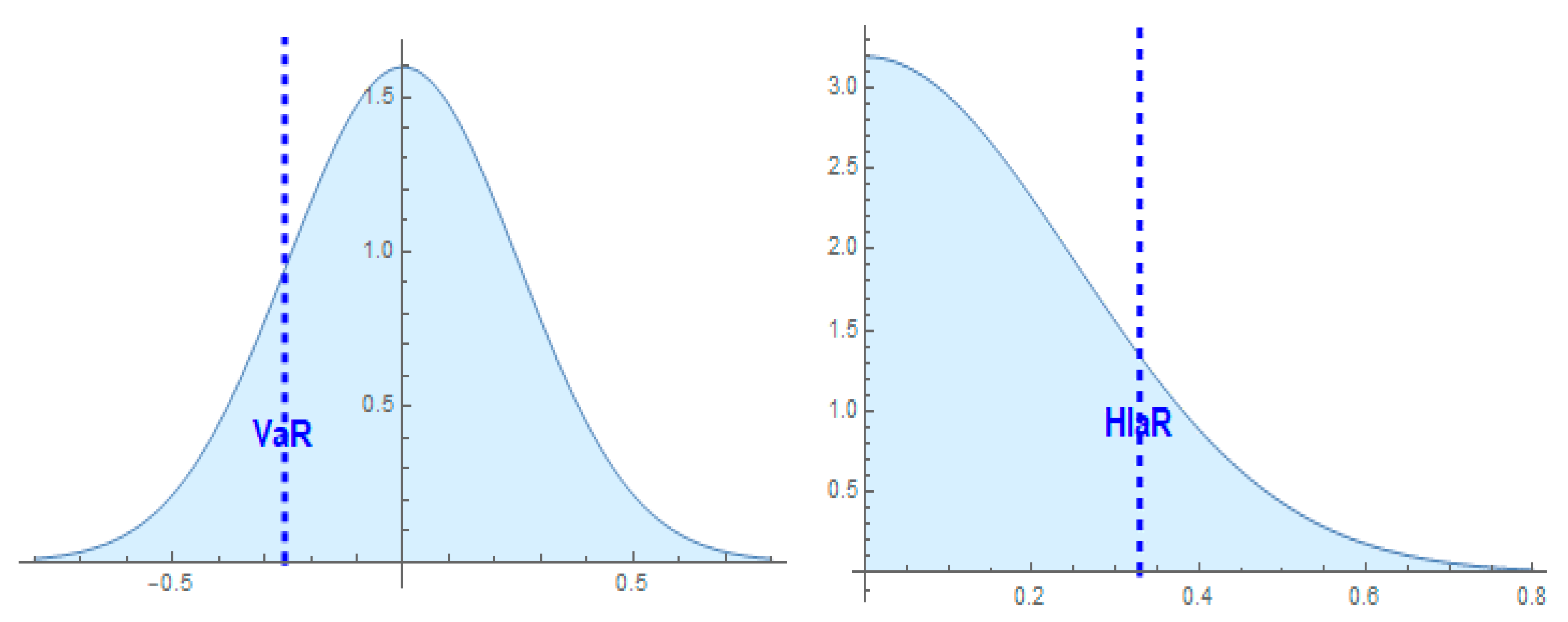
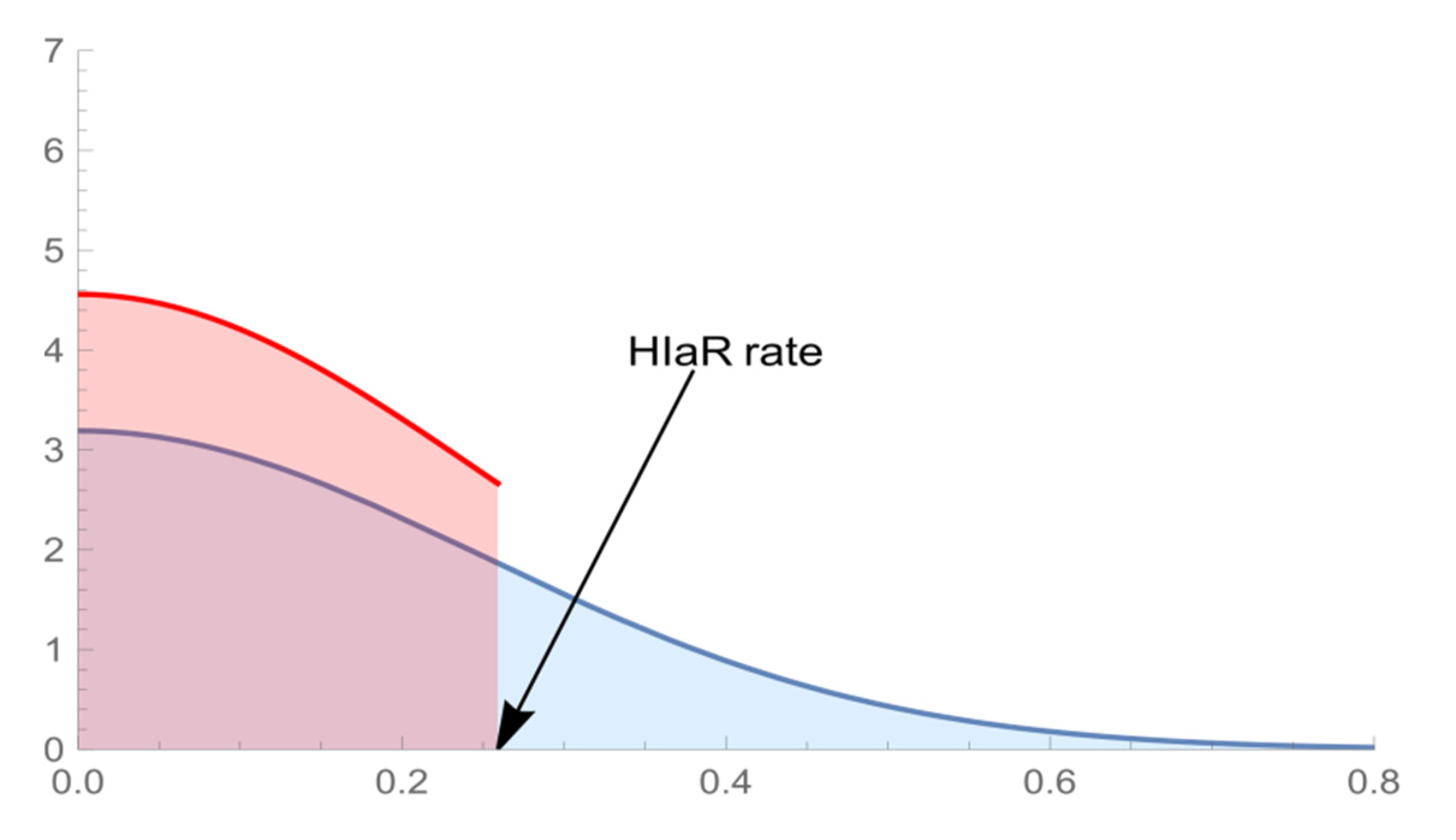
26], p. 13) introduced VaR by writing “Value at risk is a loss that we are fairly sure that will not be exceeded if the current portfolio is held over some period of time”. Paralleling this definition, HIaR can be conceived as the hazards impact that the analyst is reasonably sure will not be exceeded.
The comparison between the areas of corresponding probability distributions at the left-hand side and at the right-hand side of the quantiles (VaR and HIaR) clarify the meanings, especially the meaning of the confidence levels associated with VaR and HIaR. The area under the probability density function on the left-hand side of VaR expresses the probability of losing more than VaR. The area on the right-hand side of HIaR measures the probability of suffering damage greater than HIaR. Therefore, the corresponding confidence levels are referred to as opposite areas. As known, the confidence level for VaR is measured by the area on its right-hand side.
Conversely, the confidence level for HIaR is measured by the area on its left-hand side. Associating HIaR with the probability expected by the analyst, the area on its left-hand side expresses the maximum expected probability of the occurrence of the hazards. In contrast, the area on its right-hand side expresses the probability of experiencing damage greater than HIaR, i.e., it can be regarded as the surprise probability. For this reason, the probability of having damage equal to or lower than HIaR is a confidence level.
Figure 1 represents the comparison between VaR and HIaR. The probability of facing damage greater than HIaR, which generates the CHIaR, is the centre of the analysis presented in
Section 6.
Calculation of HIaR requires estimation of the standard deviation of the risk rate and deciding the confidence level. The standard deviation can indistinctively be referred to as the half-normal distribution or its equivalent value for the normal distribution due to the univocal relationship that exists between both (see
Appendix A, Equation (A5)). The formulas that follow incorporate the standard deviation of the equivalent normal distribution. As known, the half-normal probability distribution function is as follows:
Designating by
the value of risk rate
that matches the standard deviation
and the confidence level
, we can write the following:
Calculating this integral, we obtain
and solve it for
:
stands for the inverse of the error function of the confidence level, i.e., the inverse of the following:
which is calculated through numerical methods.
At this point, HIaR is obtained straightforwardly by multiplying
by the initial value of the safety index:
Since the notation stands for the risk rate that, once multiplied by the initial value of the safety index, generates HIaR, it can be the denominated HIaR rate.
In that the former refers to expected values while the latter expresses actual values. Comparing their dependent variables,
stands for an actual loss whereas HIaR stands for an expected loss. It stems from Equation (6) that the expected value of the HIaR rate is proportional to the standard deviation. Thus, designating by
the expected HIaR rate for standard deviation 1 and confidence level
, we have the following:
where
which is the value of
for
and the corresponding
.
Thus, HIaR can be expressed as follows:
Switching to the logarithmic scale in Equations (9) and (11), we can immediately separate the effects of the standard deviation and the confidence level.
The expression of the HIaR rate shown in (6) conveys that the HIaR rate turns out to be the product of two effects:
- (a)
The severity effect that associates the HIaR rate to the severity of the hazards impact.
- (b)
The probability effect, , that expresses the influence of the confidence level on the HIaR rate because it can be interpreted as the normalised HIaR rate for i.e., .
These effects parallel the traditional approach of risk matrices, where the impact size measures the severity effect and the estimated occurrence probability directly expresses the probability effect. In the TR model, both effects are filtered through the HIaR formula shown in Equation (6). Their product with the safety index in (11) simply means a change of scale. It stems from Equation (6) that the HIaR rate is proportional to the severity effect. Centring on the probability effect, we observe that it is a monotonously increasing function of that approaches zero when approaches zero as well. It equates 1 when equates (0.6827 approximately) and approaches positive infinity when approaches 1. Thus, the probability effect is lower than 1 for between zero and and greater than 1 for probabilities between and 1. The consequence of these properties for the HIaR rate is that the probability effect reduces HiaR for probabilities lower than and increases this rate for probabilities higher than .
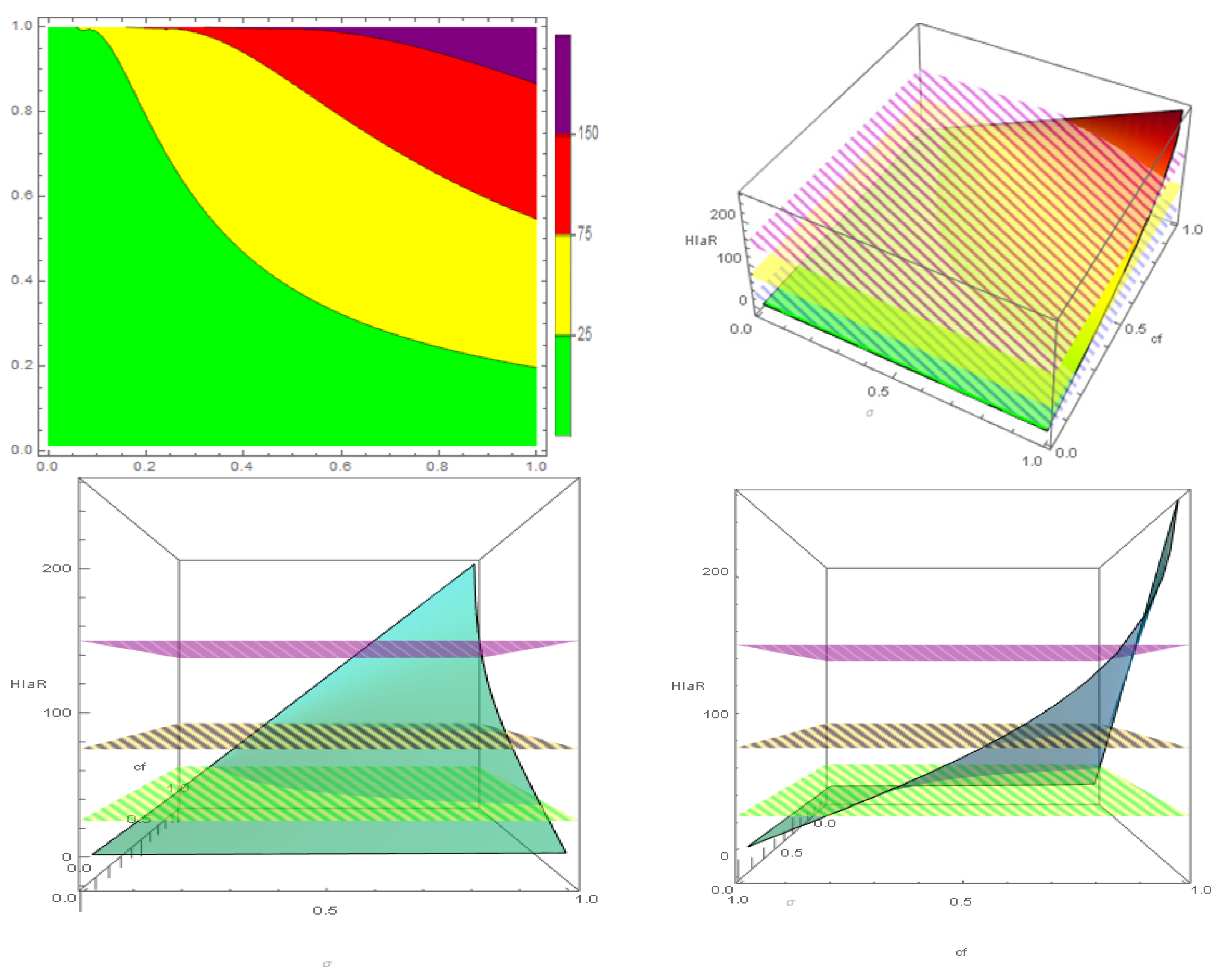
Figure 2 shows the evolution of HIaR as an increasing function of the standard deviation and the confidence level. The colours are scaled according to the traditional risk matrices convention: green for low risk, yellow for medium risk, and red for high risk, with added purple for very high risk. The right-hand-side plot includes a plane, denoted by grey lines, set up at 100 HIaR points to visualise the probability–severity combinations that express damage greater than the initial value of the safety index.
3. HIaR Diagrams vs. Risk Matrices
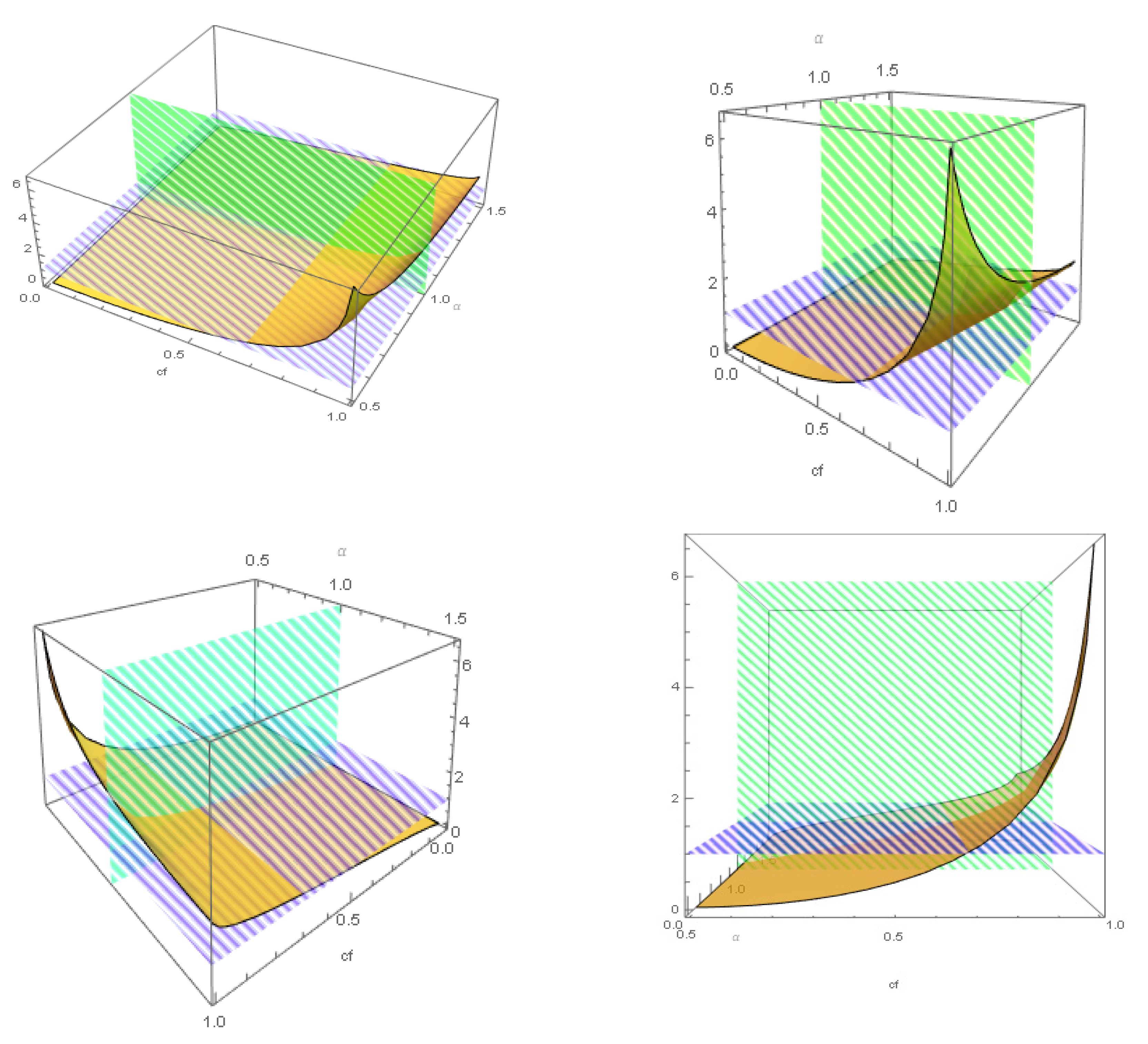
The conceptual centre of risk matrices consists of estimating the risk levels of the potential hazards under analysis by interacting the probability and severity of their impacts. Often, the numerical values of the probability and the impact level are outcomes of informed but subjective decision-makers’ criteria. The most common estimation of risk levels consists of the product between probability and severity. Next, the expected impacts are gathered into homogeneous categories that receive a similar treatment in the organization’s risk policy. The different risk categories are determined according to the values of probabilities and impacts that managers regard as appropriate for becoming boundaries between the risk categories. The horizontal and vertical boundaries generate the characteristic grid shape of risk matrices. Despite their intuitive appeal, risk matrices cannot achieve a complete homogeneous classification of risk levels as pointed out in the Introduction section. CPCDs are also based on the interaction between probability and severity. Frequently, CPCDs estimate risk levels as the product between both parameters. In this case, the difference between CPCDs and risk matrices consists of the different structures of their diagrams, although they share the same method for estimating risk levels. The HIaR diagrams built up in this section constitute a variant of CPCDs. Equal to CPCDs, HIaR diagrams divide risk zones through continuous iso-risk lines, now iso-HIaR lines. HIaR diagrams incorporate not only the intuition but also the rigour of VaR into CPCD analysis.
A central feature of risk matrices is their division in action zones denoted by different risk categories. In this respect, a risk category is constituted by the values of risk levels that deserve a similar course of action. Any risk matrix is divided at least into three action zones. Each zone recommends a different kind of action. For instance, “wait-and-see”, “short-term-management”, and “structural change”. The TR model replaces the rectangular delimitation of action zones used in risk matrices by introducing iso-HIaR lines as the boundaries of action zones. An iso-HIAR line consists of the combination of confidence levels and standard deviations that generate the same value of HIAR. Designating by the constant value of HIaR that determines the iso-HIaR line , by substituting in (11) HIaR by and for its expression according to (10), we obtain the function that determines the pairs of and that generate the iso-HIaR line for .
Any HIaR diagram needs defining boundary Hia R levels, which become the boundaries that delimit the action zones. The HIaR rate shown in (6) is proven to be a useful tool for deciding the boundaries of the HIaR diagram because it can be interpreted as the percentage that HIaR represents on the safety index, namely the percentage of the safety index that HIaR would destroy in the case of being real. Then, HIaR boundaries can be decided according to the HIaR rates that justify a change in the action zone, according to the analysts’ criteria. HIaR matrices may complement HIaR diagrams. A HIaR matrix consists of displaying in matrix form the HIaR values that match the chosen combinations of standard deviations, shown in the upper row, and the confidence levels shown in the left-hand-side column. Due to this discrete structure, a HIaR matrix is not appropriate for separating iso-risk zones.
Table 1 shows the HIaR matrix for the given standard deviations and confidence levels. These HIaR values can be interpreted as percentages. For instance, for a standard deviation of 0.25 (severity) and a confidence level (probability) of 0.25, the expected damage in the safety index is 7.97%. However, if severity equates 0.75 and probability equates 0.95, then the expected damage goes beyond the current value of the safety index (100 points) reaching 147% of it, which means that the damage exceeds 47% of the value embedded in the safety index. At the same time, the first column shows the probability effect, i.e.,
.
Figure 3 shows the HIaR diagram as a two-dimensional plot and three three-dimensional plots. Their data are the same as that generated by the HIaR matrix in
Table 1. As
Figure 2 and
Figure 3 include four risk levels denoted by green (low risk), yellow (medium risk), red (high risk), and purple (extreme risk) colours. The boundary levels are set up at 25 points for starting the yellow level, 75 for starting the red level, and 150 for starting the purple level. The three three-dimensional plots display the figure from three different points of view on behalf of clarity. In them, iso-HiaR planes have substituted iso-HiaR lines. Throughout the paper, in the two-dimensional diagrams, the abscissa axis denotes the standard deviation and the ordinate axis denotes the confidence level.
4. The Expected Hazards Damage
HIaR would become incomplete without connecting it to the expected loss in case of a hazard taking place. We define the Expected Hazards Damage (
EHD) as the expected loss due to the risk under analysis, i.e., the expected loss if the hazard becomes real. Recalling that HIaR expresses maximum loss in the safety index (
SF) under the estimated probability
, the
EHD can be written as follows:
where
adjusts the probability of the half-normal distribution to the area between zero and
.
Solving the integral in Equation (12), we obtain the following:
Paralleling the breaking down of the HIaR between the probability effect and the severity effect, this equation extends this decomposition to EHD. Now, continues being the severity effect, while becomes the probability effect.
It stems from Equation (12) that
EHD consists of the mathematical expectation of the probability distribution of the hazards impacts that do not exceed the maximum expected impact, i.e., do not exceed HIaR. Thus, this distribution is a half-normal truncated at the HIaR point. Equation (12) shows this property by truncating the half-normal distribution of the risk rate
at the HIaR rate
.
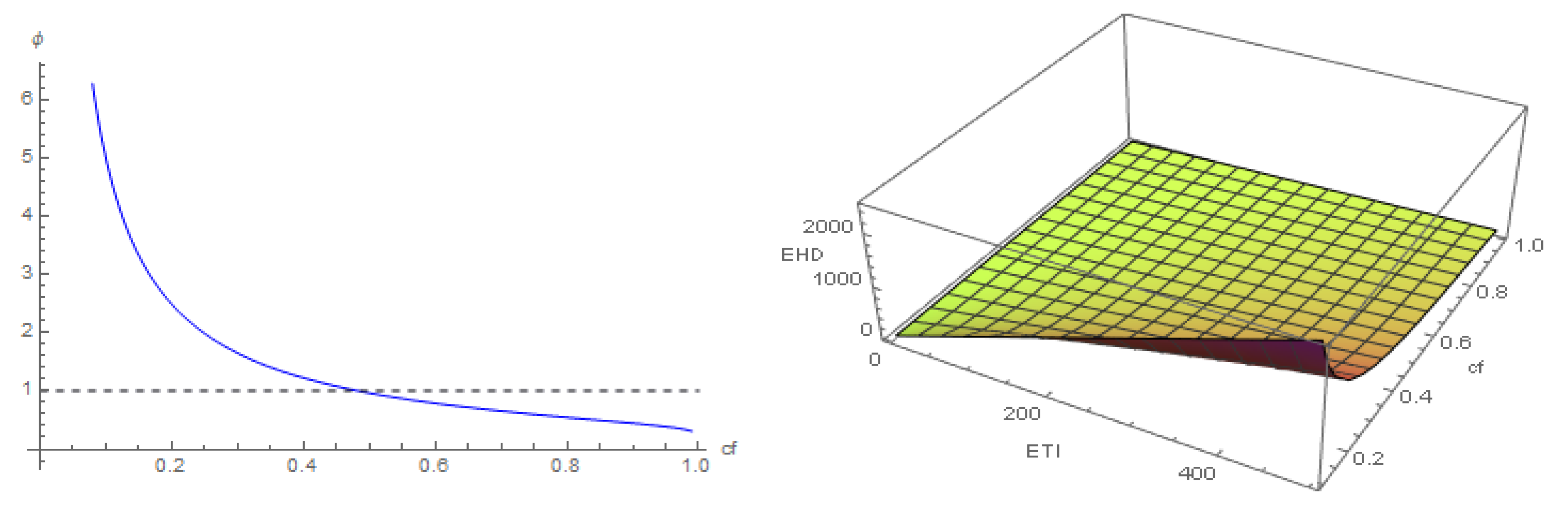
Figure 4 illustrates this property. The left-hand side of
Figure 5 shows the EHD plot expressing EHD as a function of
and
. Its right-hand side shows the EHD diagrams.
EHD can be expressed as a function of
HIaR, which clarifies the relationship between both. Solving (11) for
and substituting
according to (10), we obtain
and substituting (14) into (13), we obtain
which shows that the relationship between
EHD and
HIaR is ruled by the function of the
HIaR–
EHD connector
:
that has the confidence level as the unique independent variable.
Figure 6 illustrates the relationship between EHD and HIaR.
6. On Active and Latent Risks: Conditional HIaR
This section delves into the comparative analysis between the maximum expected probability and the surprise probability introduced in
Section 2 when considering damage greater than HIaR. The evolution from the HIAR to the analysis of the expected values associated with it requires precise interpretation of the probability that determines the HIaR, henceforth, the HIaR probability. The binary approach of traditional risk matrices incorporates two probabilities exclusively: the one associated with the occurrence of the hazard and the one that discards the idea that the hazard will take place. In contrast, this paper centres its analysis on a continuous distribution, the half-normal. Obtaining HIaR through the half-normal distribution reveals the existence of three relevant levels of the expected value: the total potential risk, the expected active risk, and the latent risk.
The total potential risk consists of the expected value that stems from the whole probability distribution. Thus, it consists of the mathematical expectation of the potential hazard that the risk under analysis may generate. However, not necessarily, the entire potential risk constitutes an active threat. One part of it may be active, and the rest may be latent. The central feature of the latent part of the risk is that, under the current circumstances, it does not show any sign that it will produce any hazard on the horizon of the analysis. The expected active risk consists of the expected value of hazards that goes from zero to the HIaR probability, i.e., from a null probability to its maximum expected value. Finally, the latent risk is the expected value of the latent part of risk placed on the right-hand side of the HIaR probability. This latent risk is congruent with the risk associated with CVaR and placed on the left-hand side of VaR.
The previous analysis has focused on the area between the origin and the confidence level of the half-normal distribution. The whole area of distribution and the area on the right-hand side of the confidence level complement its information. The total area under distribution can be interpreted as the total mathematical expectation (
TME) of a hazard with volatility of the case under analysis. For the half-normal distribution, the unique variable of this area is the standard deviation:
Solving the integral in Equation (20), we obtain the following:
Since is equal to 0.7979, the TME approximately equates to 80% of the standard deviation multiplied by the initial value of the index.
The right-hand-side area expresses the discarded impact, more specifically, the impact that analysts estimate that will not take place and, for this reason, discard it from the study. Paralleling EHD, the expected value on the right-hand side of the distribution leads to the Conditional HiaR (
CHIaR), which means the potential impact excluded from the analysis:
Solving the integral in Equation (22), we obtain the following:
CHIaR can be regarded as the source of unexpected hazards known as black swans. CHIaR has a parallel meaning with CVaR because the former focuses on damage when the HIaR barrier is crossed and the latter focuses on losses when the VaR barrier is crossed.
TME,
EHD, and
CHIaR fulfil the following properties: when the confidence level approaches 1,
EHD approaches
TME and
CHIaR approaches zero.
TME, in turn, is the weighted average of
EHD and
CHIaR with
and
as weighting coefficients.
Figure 8 displays the probability distributions of total risk, active risk, and latent risk.
7. A Subjective Approach to Risk Analysis through the Half-Normal Distribution
The relevant contribution of subjective probabilities to decision-making reasoning is widely acknowledged. Their use in risk analysis is part of this contribution as well. Karni [
29] systematised their axiomatic foundations. Andersen et al. [
30] studied the joint estimation of subjective probabilities and risk attitudes. Wintle et al. [
31] dealt with the numerical translation of verbal probabilities. Aven and Reiners [
32] presented an in-depth analysis of the interpretation of probabilities in risk analysis with particular emphasis on the meaning and use of subjective probabilities. Goerlandt and Reiners [
33] applied subjective probabilities to probability–consequence diagrams. Flage et al. [
34] developed a critical perspective on the use of subjective probabilities in risk analysis, showing how incorporating probability bounds may improve the performance of the analysis. Langdalen et al. [
35] dealt with the identification of hidden assumptions in risk studies focusing on the subjective nature of risk assessment.
This section aims to show how the analytical framework created by the TR model can be used also as a tool for subjective reasoning in risk analysis. In this way, generic risk perceptions can be turned into a set of linked variables, the coherence of which can be discussed through the lenses of the logic relationships embedded in the model. In concrete, this section presents an algorithm that, departing from subjective assumptions of the maximum downwards associated with the total risk and the active risk, delivers the values of the standard deviation, the confidence level, and the HIaR embedded in the assumed downwards. The algorithm proceeds as follows:
- (1)
The hypothesis for the maximum downward coefficient of total risk leads to obtainment of the standard deviation by applying a property of binomial trees. In effect, binomial trees used in option pricing (Cox, Ross, and Rubinstein [
36]) relate in approximate terms the upward and downward coefficients with the standard deviation. For the downward coefficient
, the relationship for one-time period is as follows:
Based on this relationship, the analyst may obtain the standard deviation after estimating the maximum downward that s/he may expect in the safety index. This estimation includes the active and the latent risk, i.e., it refers to the total risk.
- (2)
By introducing a hypothesis for the maximum downward coefficient of the active risk
the analyst identifies the subjective
HIaR embedded in this downward coefficient. Since
HIaR represents the maximum expected reduction in the safety index, the relationship between
,
, and
is
- (3)
To unveil the confidence level that stems from the obtained values of HIaR and the standard deviation, we calculate, first, the value of the HIaR rate from Equation (11). Next, substituting it into Equation (10), we obtain the confidence level.
Summarising, through subjective estimations of the downward coefficients for the total risk and the active risk (
and
), the analyst obtains the set
and starts revising its coherence from his/her criteria and the information available for similar settings. The aim of this algorithm is not to substitute an in-depth analysis of subjective reasoning but to provide a first approach to turning subjective perceptions into a quantitative setting in a straightforward manner grounded on analytical tools.
Scheme 2 presents a conceptual map of this algorithm.
8. Exploring the Generalised Half-Normal Distribution
Many probability distributions have been applied to risk analysis. Although this paper has centred on the half-normal distribution, the essence of its methodological proposition has consisted of developing CPCDs through a right-truncated probability distribution applied on a hazards rate. The half-normal distribution brings the advantage of depending only on its scale parameter (
), but at the same time, this property limits its capacity for studying scenarios that would be better modelled by changing the shape of the distribution. The generalised half-normal distribution (
GHN), proposed by Cooray and Ananda [
11], incorporates a shape parameter to the original half-normal distribution, adding flexibility to its analytical capacity. This section explores the main changes that switching from the half-normal to its generalised counterpart produces on the previous results of this paper, focusing on HIaR mainly. The probability density function of the generalised half-normal distribution ([
11], p. 1125) is as follows:
if
and 0 otherwise.
In (29),
stands for the shape parameter and
stands for the location parameter, substituting the Greek letter theta
used by Cooray and Ananda on behalf of homogeneity with the half-normal distribution notations previously used in this paper and in other papers quoted in the
Section 1 and in the Appendix. The properties of the generalised half-normal distribution, including its statistical moments, are presented by Cooray and Ananda [
11].
Next, we focus on the applicability of the generalised half-normal to HIaR. The basic results for EHD are presented in
Appendix B. The HIaR rate for the generalised half-normal
fulfils the following condition:
which parallels (4) for the original half-normal. Calculating this integral and solving it for
, we obtain the values of the HIaR rate for
,
, and
:
Taking (10) into account, this equation can be written as follows:
As for the notations,
denotes the generalised HIaR rate for the generalised half-normal distribution, henceforth generalised HIaR rate, while
continues designating the same rate for the ordinary half-normal distribution. Both rates become equal for
(Pescim et al. [
12], p. 946). The parameters
,
, and
remain implicit in
, the complete notation of which would be
.
The generalised HIaR rate, as its ordinary counterpart, embeds the severity effect and the probability effect. The former
remains unchanged. The latter equates the HIaR rate for
powered at the inverse of the shape parameter
. The comparison between the probability effects of the generalised and the ordinary half-normal distribution explains the changes that the shape parameter introduces in the generalised HIaR rate.
Table 2 summarises these changes. The first step of this comparison consists of realising that a confidence level,
, equal to
(0.6827 approximately) neutralises the
impact because it equates
to 1. When
and, thus,
, a shape parameter lower than 1 increases the probability effect, while
increases it because now we have
. The effects for
are the opposite.
The study of the ratio between the HIaR rates for the generalised and the ordinary half-normal distribution, henceforth denoted by
, enlightens the role of the shape parameter. The expression of this ratio is as follows:
which, in turn, consists of the ratio of both probability effects, that, recalling (10) and (32), can be written as follows:
Thus,
expresses the percentage in which
changes the probability effect and, at the same time, the HIaR rate. Interestingly, high
values compensate the low probability effect associated with very low probabilities. Often, academic papers on risk analysis have pointed out that scenarios with high severity and low probability should be rated riskier than scenarios with lower severity and higher probability that present the same value of the risk indicator. In this respect, Duijim [
21] (p. 27) defined the hazard aversion as “the attitude that a low probability-large consequence event is assigned a higher risk value than a high probability-low consequence event, even when the expected loss for both events is the same”. The capacity of the shape parameter of the generalised half-normal distribution for weighting the probability effect opens the way for increasing its impact of HIaR and EHD in case of low probabilities by assigning to the shape parameter the function of a hazard aversion coefficient in the case of low probabilities and high impacts. The development of this topic needs further research.
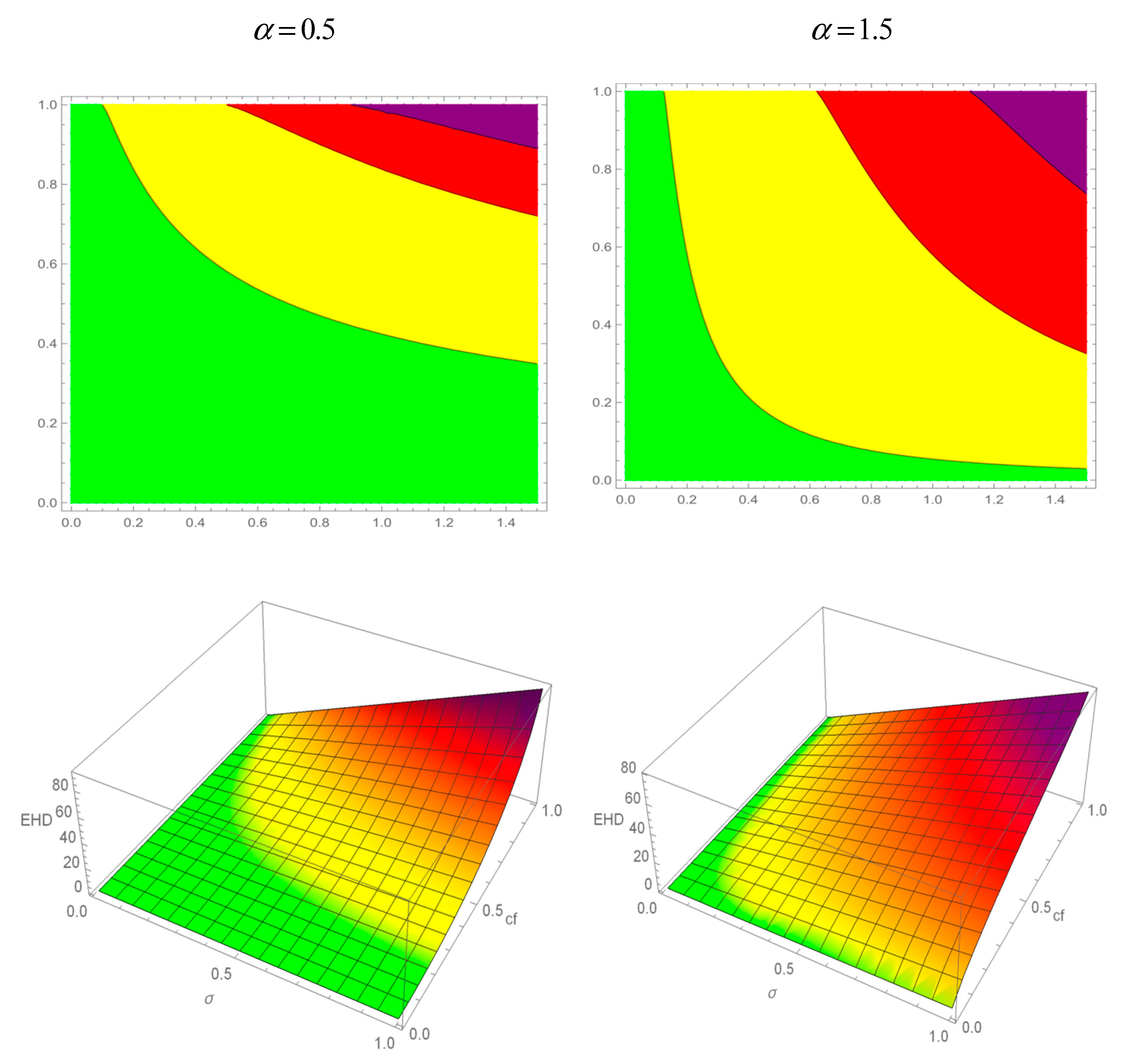
Table 3 displays the values of
for different values of
(columns) and
(rows). Among other data, it shows that, for a 5% probability (cf),
equal to 2 increases the probability effect and the HIaR ratio at the same time, multiplying it by 3.993.
Figure 9 represents the evolution of the generalised HIaR ratio for
, which is, at the same time, the evolution of the probability effect for the generalised HIaR ratio. The vertical plane is set up at
, while the horizontal plane is set up at
(0.6827). The intersection between
(yellow surface) and the vertical plane shows the line of
because, as stated,
equates
for
. The crossing between
and the horizontal plane shows how
evolves from values lower than 1 to values higher than 1 because
equates both
and
to 1.
Beyond these applications, the generalised half-normal distribution offers an interesting potential for its use in the analysis of VaR, CVaR, and CPCDs when fat tails and skew become a central point in the analysis, paralleling the developments of the generalised normal distribution made, among others, by Stoyanov et al. [
37] and Chen et al. [
38].
9. Discussion
Truncated probability distributions embed the essential features for analysing risky scenarios that may produce only negative impacts on the assets related to them. Among these distributions, the half-normal turns out to be the straightforward option for adapting VaR and CVaR to the probability–severity risk analysis performed through CPCDs, which overcome the misclassifications due to the rectangular structure of risk matrices. In effect, the iso-risk lines that separate the risk categories in CPCDs open the way for expressing them through risk indicators based on VaR and CVaR. Switching from the product between probability and severity to VaR and CVaR heightens the information level generated by the analysis. At the same time, it requires adapting VaR and CVaR to a setting characterised by truncated probability distributions. We have called the Truncated Risk (TR) model the outcome of adapting VaR and CVaR to CPCDs.
The methodology of the TR model has departed from defining the safety index and the hazards index analysed through the half-normal distribution. The former is referred to as a generic asset and represents the percentage of not being damaged by hazards. The latter expresses the impact of hazards on the safety index. Since the hazards index only captures negative impacts, although expressed in a positive sign, its random behaviour must be expressed through a truncated probability distribution. In this paper, we have opted for the half-normal distribution as the most straightforward issue. As a risk analysis tool, the half-normal distribution shows the advantage of depending on its standard deviation exclusively, namely, its scale parameter. Thus, for any risk setting that can be represented by a half-normal distribution reasonably, the standard deviation can be taken as an indicator of the severity of hazards. The probability of each hazard is now expressed through the maximum expected probability of the hazard occurrence, which turns out to be the confidence level associated with this probability. As a logical outcome, the probability on the right-hand side of the expected one becomes the surprise probability. It is, in other words, the probability that, in subjective terms, expresses the degree of the analyst believing that the hazard will not take place. The generalised half-normal distribution amplifies the analysis by including a shape parameter that adds flexibility to the model.
As shown, the two central risk indicators of the TR model, HIaR and EHD, can be interpreted as the product between a probability effect and a severity effect. Thus, they hold the original message of risk matrices. The comparison between both approaches enlightens the changes in the probability–severity analysis proposed in this paper. Instead of obtaining the estimated total impact (ETI) as a direct product between probability (p) and impact severity (IS), the TR model filters the information through the half-normal distribution. Now, this distribution embeds all possible impacts and their probabilities. The volatility drives the severity of the impacts because it determines the shape of the half-normal distribution. The probability of the traditional approach is replaced by the confidence level or the half-normal distribution. The HIaR shares with the traditional impact size (IS) the fact of expressing the maximum damage expected by the analyst because it expresses the maximum expected impact under the maximum expected probability. The primary difference between the traditional impact size and HIaR lies in the fact that the traditional impact size is a unique value associated with the hazard in any circumstance in which the hazard becomes real. At the same time, HIaR is based on a probability distribution, not necessarily the half-normal.
EHD is the concept that replaces the traditional total expected impact. In this way, the analysis gains flexibility because the single value of the estimated impact is now replaced by a tripled of values, which includes the total possible mathematical expectation (TME), the EHD, and its complement: the CHIaR. Thus, this approach induces decision-makers to make plans to face not only the expected (HIaR and EHD) but also the unexpected through CHIaR. As a clarification, it is worth pointing out that EHD does not have an equivalent measure in the framework of VaR analysis. HIaR parallels VaR, while CHIaR parallels CVaR, but the mathematical expectation of potential losses lower than VaR is not a standard risk indicator in financial analysis. Nevertheless, in the context of risk analysis through the half-normal distribution, EHD has become central for linking the VaR analysis developed in this paper with the traditional probability–severity approach of risk matrices.
Section 7 has presented a subjective, although analytical, approach to the TR model that stresses its side as a thinking tool for enabling analysts to find the risk parameters hidden on their subjective expectations on downside risk. The extension of the analysis to the generalised half-normal distribution has shown the property of the shape coefficient in modifying the probability effect increasing the weight of lower probabilities and decreasing the weight of the higher ones or in producing the opposite effect, depending on the choice of the shape parameter. The properties of the shape parameter justify interpreting it as the hazard aversion coefficient. Risk aversion and hazard aversion are different indicators: the former determines the required risk premium, while the latter rules by assigning risk levels in the combinations of the probability and severity of different hazards. It is, in particular, relevant for assigning higher risk levels to hazards of high impact and low probability when they are compared with low impact and high probability hazards. Besides, the introduction of the generalised half-normal distribution has shown how the TR model can be adapted to a truncated probability distribution different from the half-normal that has guided its development.
This paper has the limitation of having centred the analysis in the half-normal distribution. Its extension to the generalised half-normal has shown how more complex probability distributions may incorporate additional features than the ones of the half-normal. The risk measures that this paper has adapted to the probability–severity analysis, VaR and CVaR, have been extended also in the financial mathematics literature from the normal distribution to other probability distributions that may fit better to specific cases, fat tails in particular. These extensions take also into account the limitations of VaR in the face of subadditivity. In addition, interweaving the point of view of truncated distributions with some of the advances in risk management mentioned in the Introduction section, such as considering the knowledge dimension of risk, may contribute as well to widening the scope of the analysis presented in this paper.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
