4.1. Forecast-Based Sources
Our driving idea for constructing a solar source is that the curve
essentially depends on the type of the day, referring to the sort of weather this day enjoys. Mathematically, we refine the model in (1) into:
The notation
refers to the type of the day which defines the weather conditions observed/predicted for that day. We assume
where
is the set of day types, finite and hopefully not too large. In the experiments of
Section 5 we consider models where the number of day types ranges from 2 to 16.
For any , we assume that there is a sequence of distributions , for such that the clear sky index is a random variable following the distribution .
For a given day
d of type
, it is then possible to characterize the global irradiance
using a model for
and i.i.d. sequences
, drawn from distributions
, with:
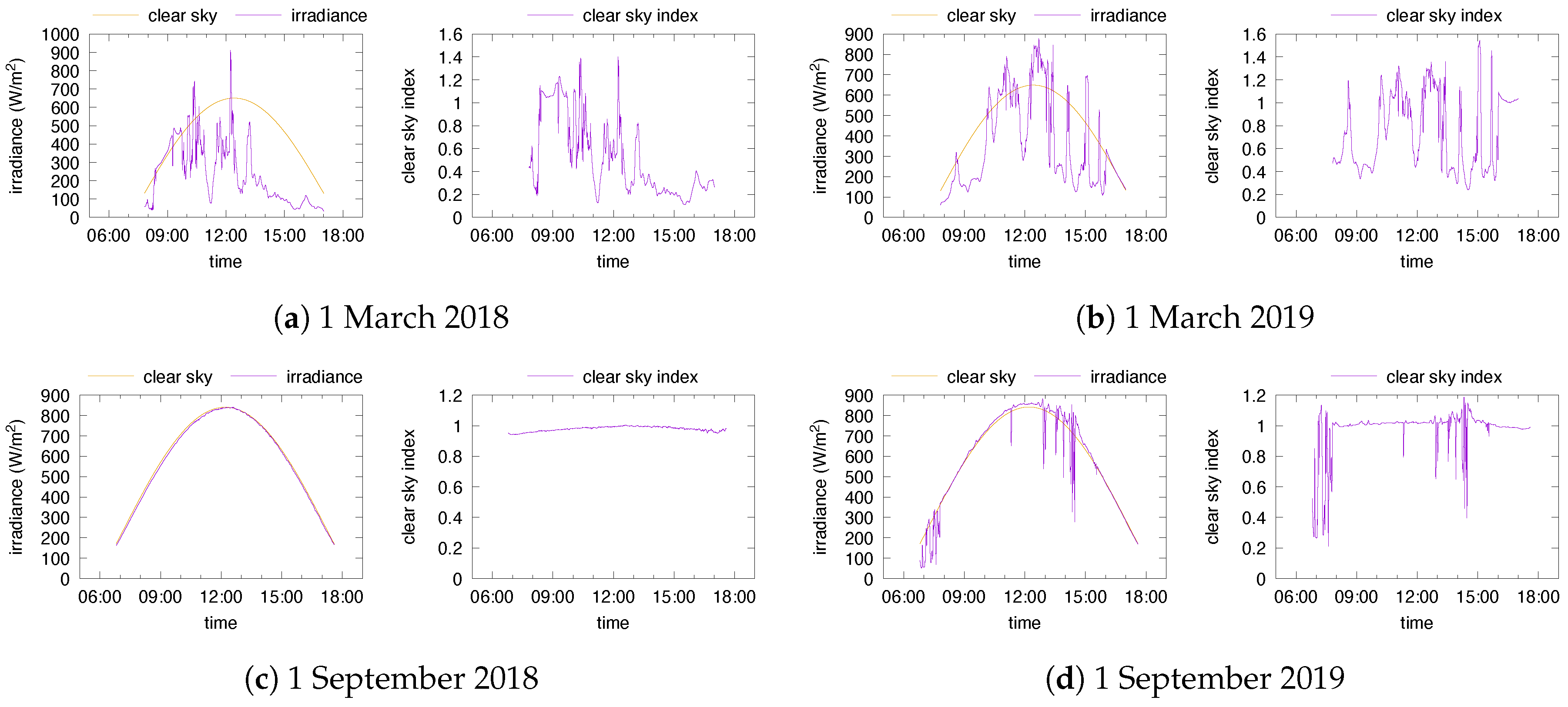
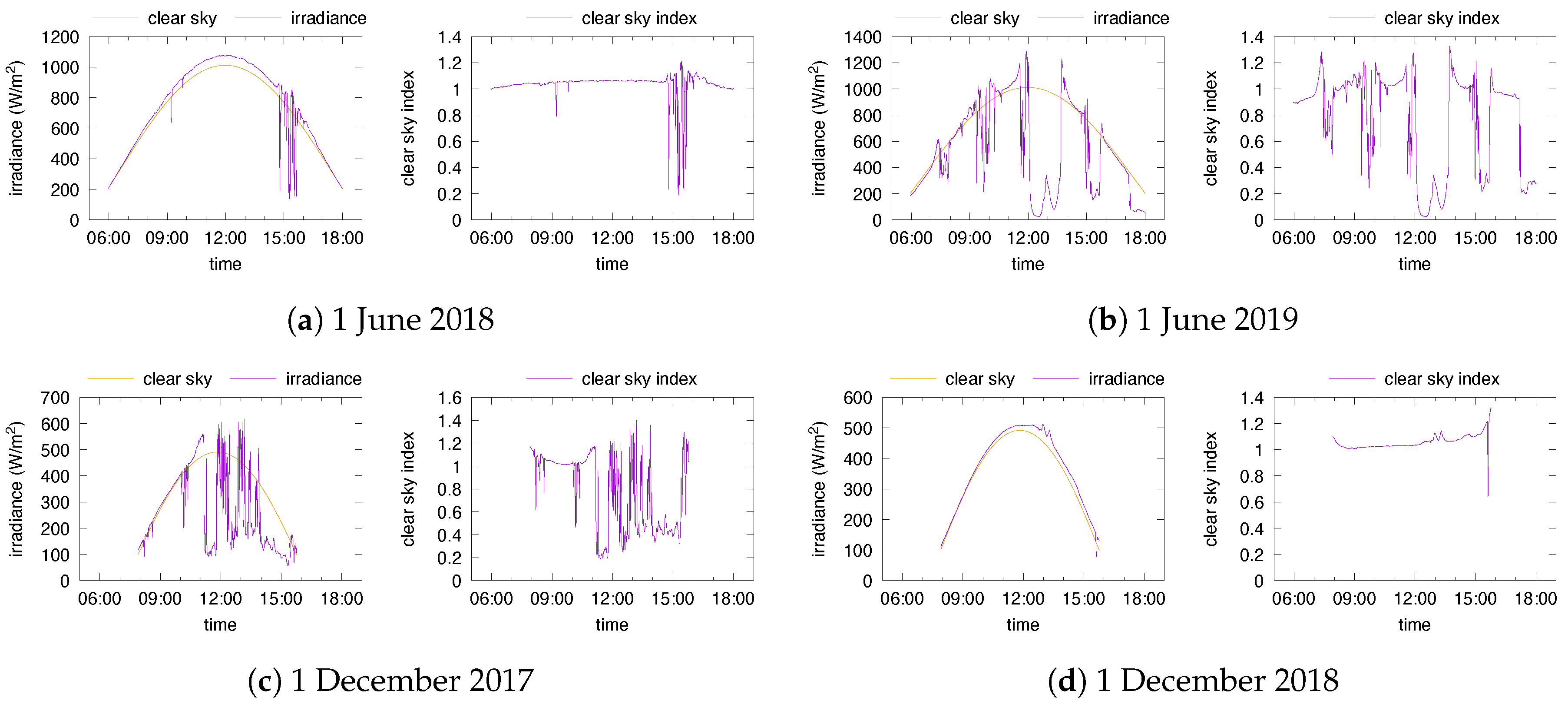
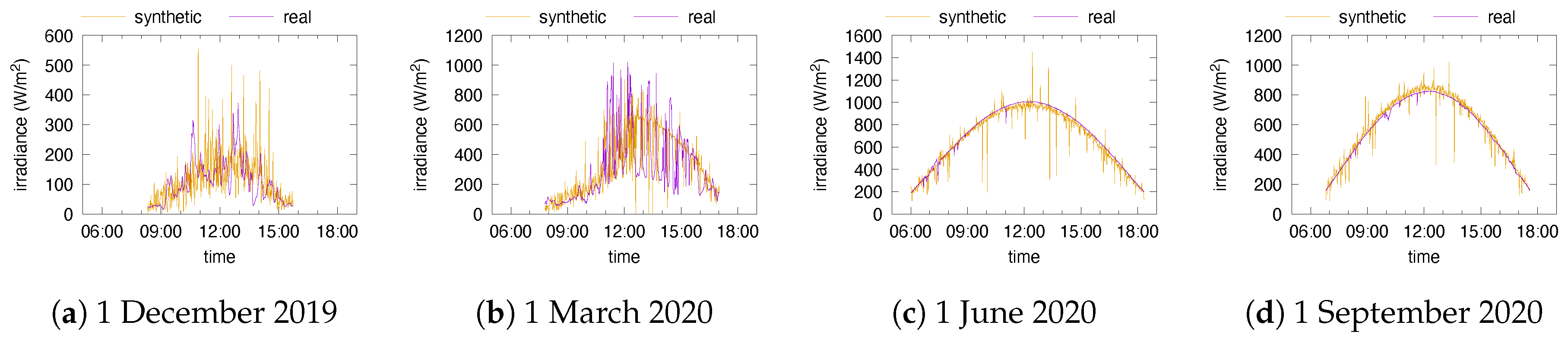
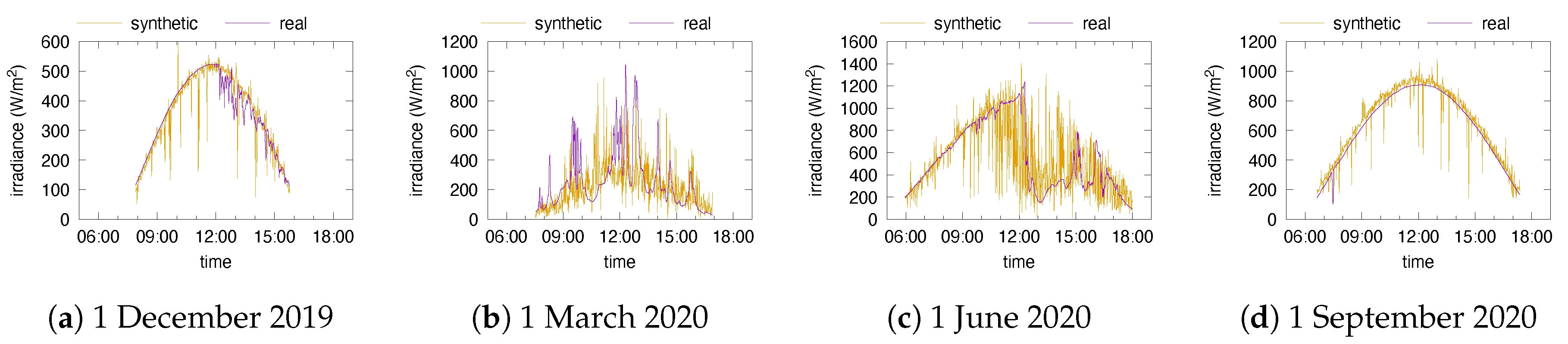
In order to classify the days in the type set
, we start from per-minute irradiance data for two locations, Portland (Oregon, US; see [
20]) and Golden (Colorado, US; see [
21]) for a 3-year period of time. In addition to the global irradiance, the data [
20,
21] report predictions of the clear sky irradiance using Bird’s model [
11]. We rely on these predictions of
to compute the clear sky index
according to (5). The subsequent step is to identify which features of days will be used for the classification.
The type of the day can be seen as a description of the weather forecast for that day. In its simplest expression, a day can be seen as “sunny” or “cloudy”, but much more detailed descriptions can be envisaged: hourly conditions may be available/predicted and a finer categorization of the sky condition may be done. When identifying the day type, one can rely on the average value of the clear sky index over the entire day, or on the average values obtained over a number of intervals partitioning the day’s duration. Partitioning the whole duration of the day in fixed intervals throughout the year is not adequate, since the quantity
is measured only during daylight time. We will therefore consider that daylight time is split in a number
I of equally sized intervals, seen as “phases” of the day, during which the distribution of
is assumed to be constant. This refines the model in (6) into:
where
m is a minute during daylight time,
is the interval number of minutes
m in day
d and
are
independent sequences of i.i.d. random variables. We limit the value of
I to 12 in our experiments. Consequently, the shortest days in the year in Portland with ∼433 min would have eleven 36-min long intervals and one 37-min long interval. In Golden, with ∼461 min, the shortest days in the year would have seven 38-min long intervals and five 39-min long ones. (Slight variations exist over the years; these figures are those seen in the training and testing data).
To estimate day types, we use the Scikit-learn Python module [
26] and more specifically KMeans, its implementation of the K-means clustering. We split the collected data into two sets: the first one (the training dataset) spans a period of two years, from October 2017 until September 2019, and the second one (the testing dataset) spans a period of a full year from October 2019 until September 2020. We cluster the training data (data in the first set) using a number of features
I ranging from 1 until 12 (each feature is the average clear sky index over a time interval), and we consider a number of clusters
ranging from 2 until 16. We therefore obtain 180 distinct clustering results, one for each configuration. For each clustering result, we predict the types of the days present in the second set, the testing dataset, based on the clusters identified in the training set. To do so, we simply select the cluster whose centroid is closest to the vector of features attached to the day to be classified. To test the models presented in
Section 2 (and in particular (5)), we generate synthetic sources of energy that mimic the days present in the testing dataset. The interval where the current minute lies is determined using sunrise/sunset data and the splitting of daylight time into equal intervals. Using the day type and the interval number, we generate samples from the distributions
, one sample per minute, and obtain the global irradiance with (7).
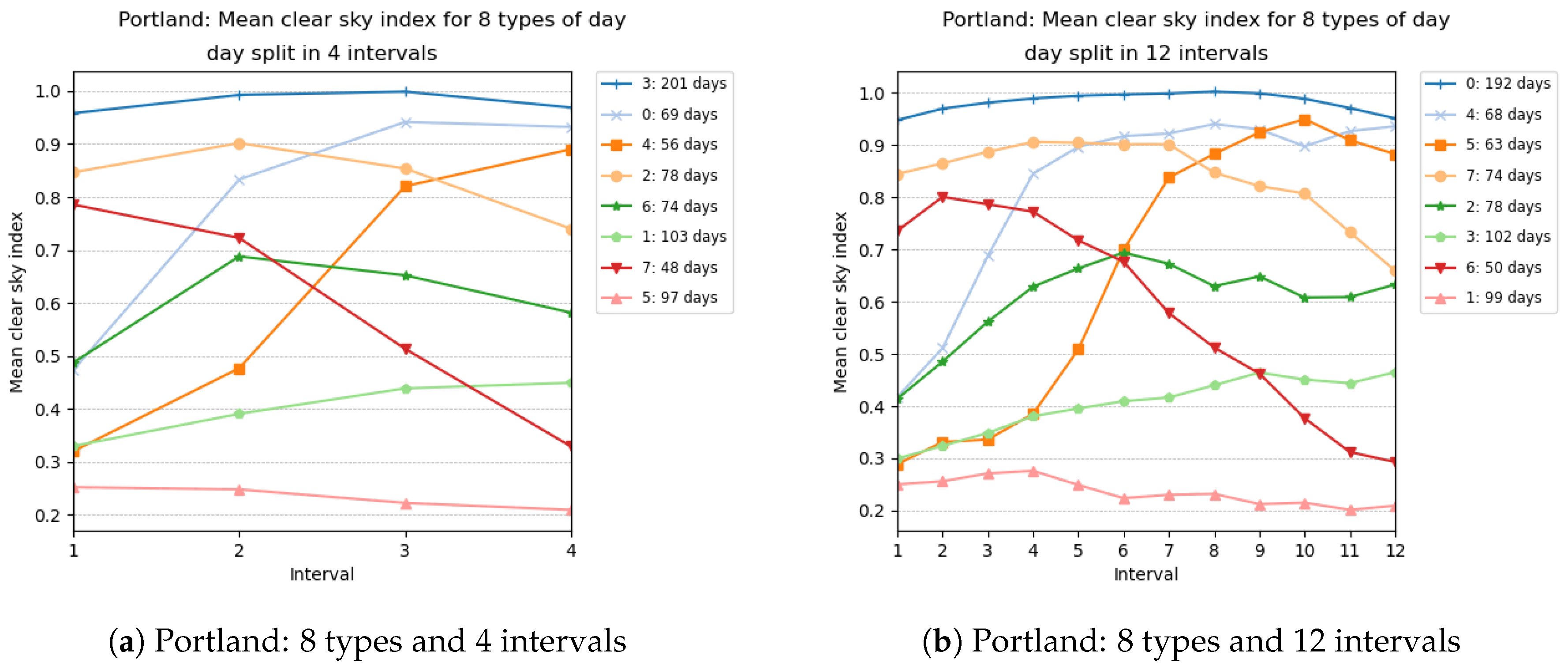
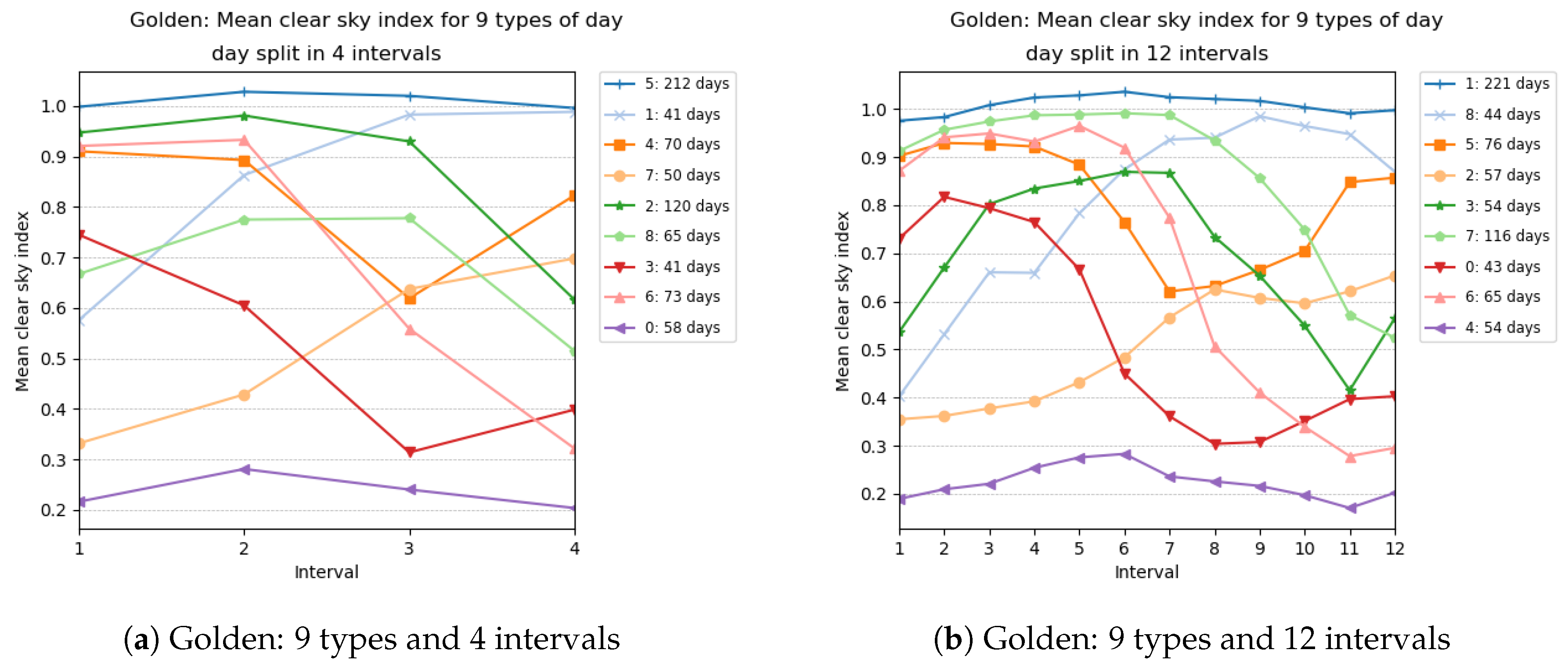
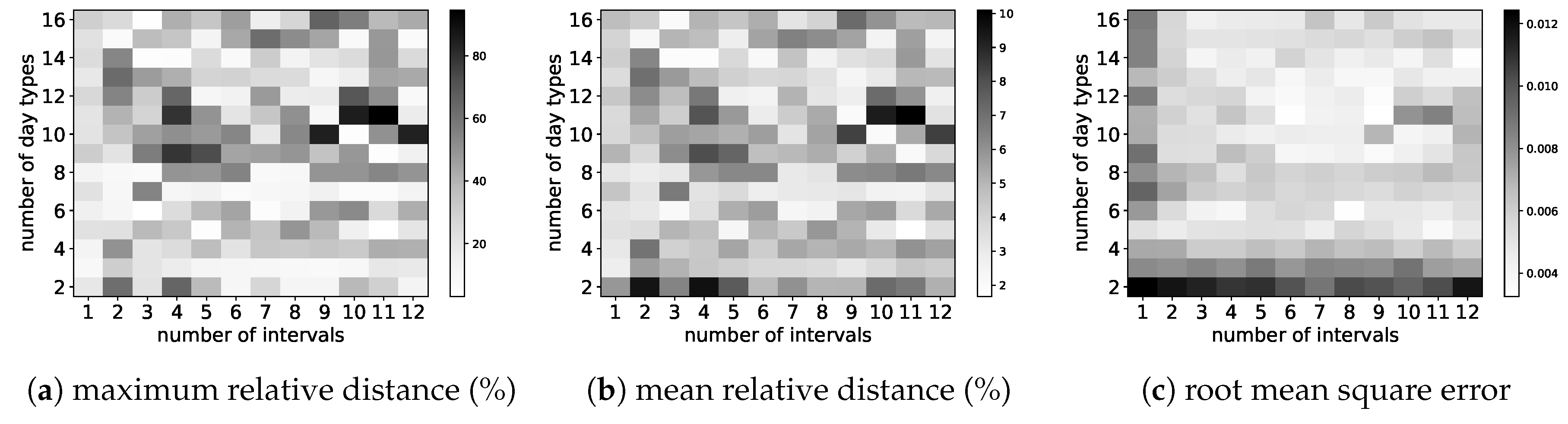
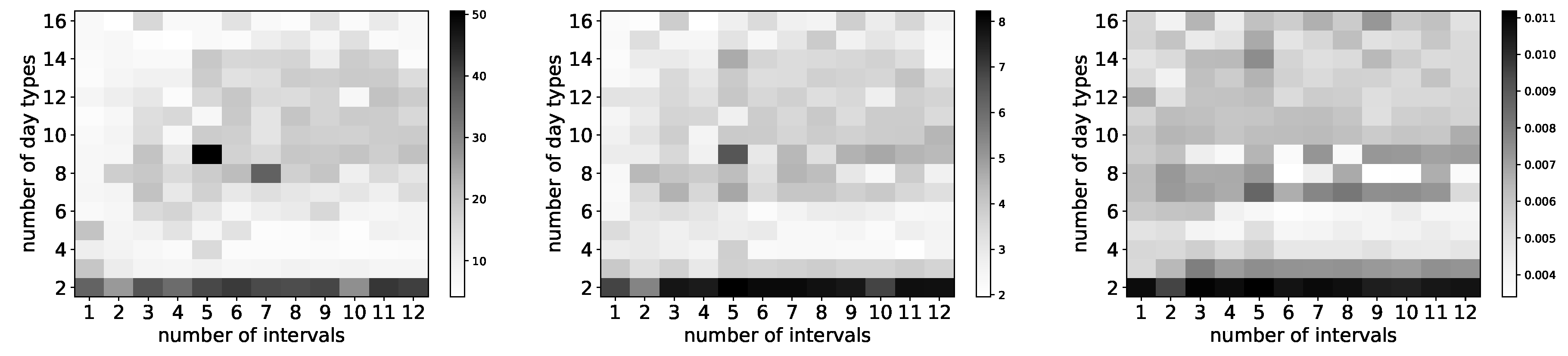
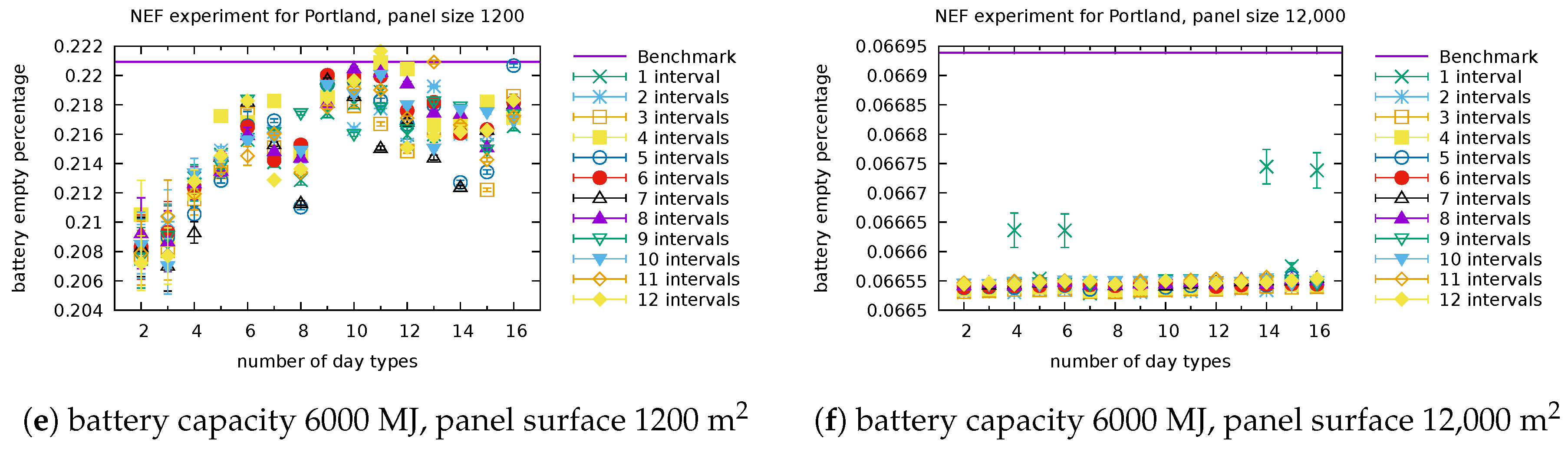
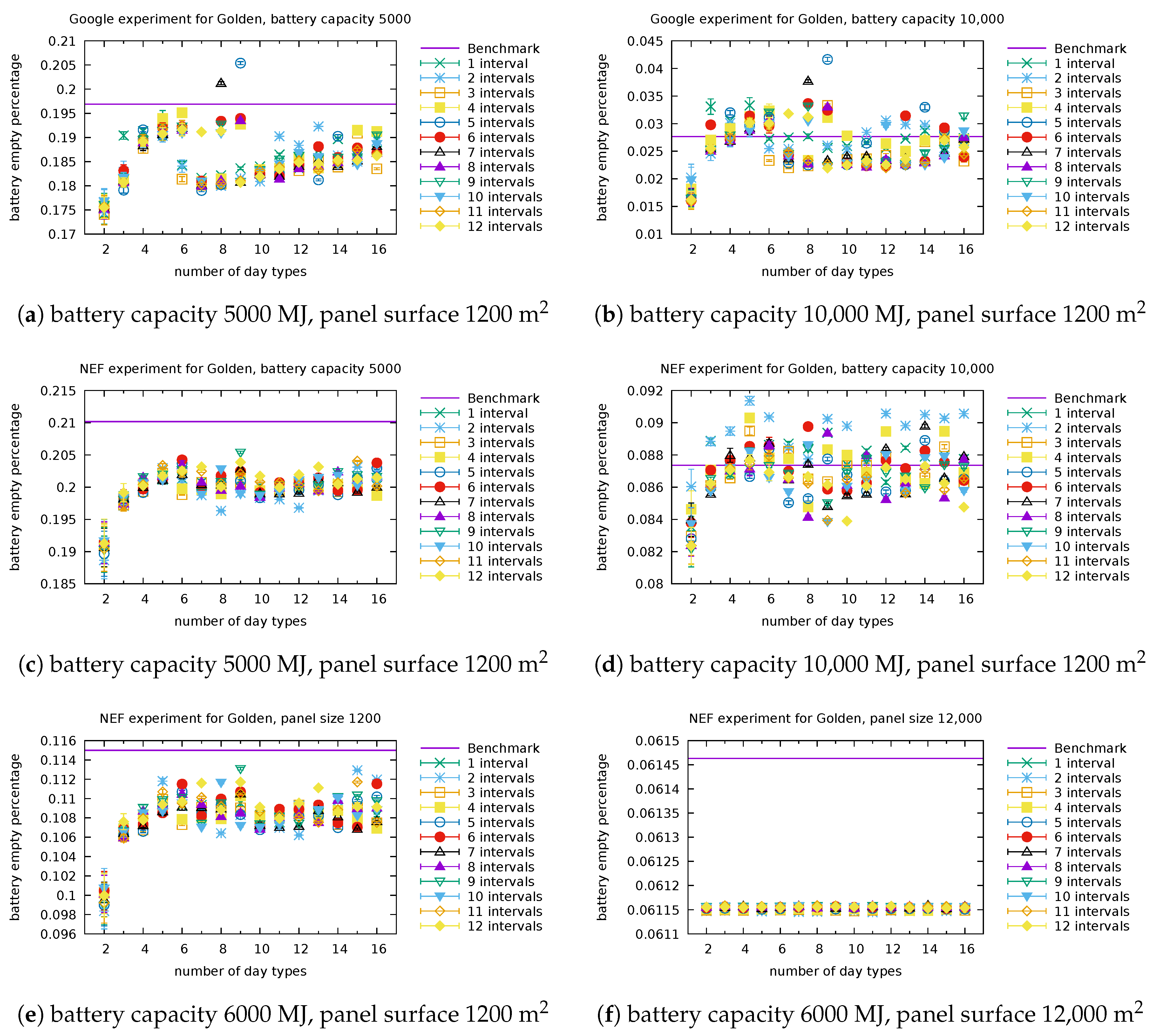
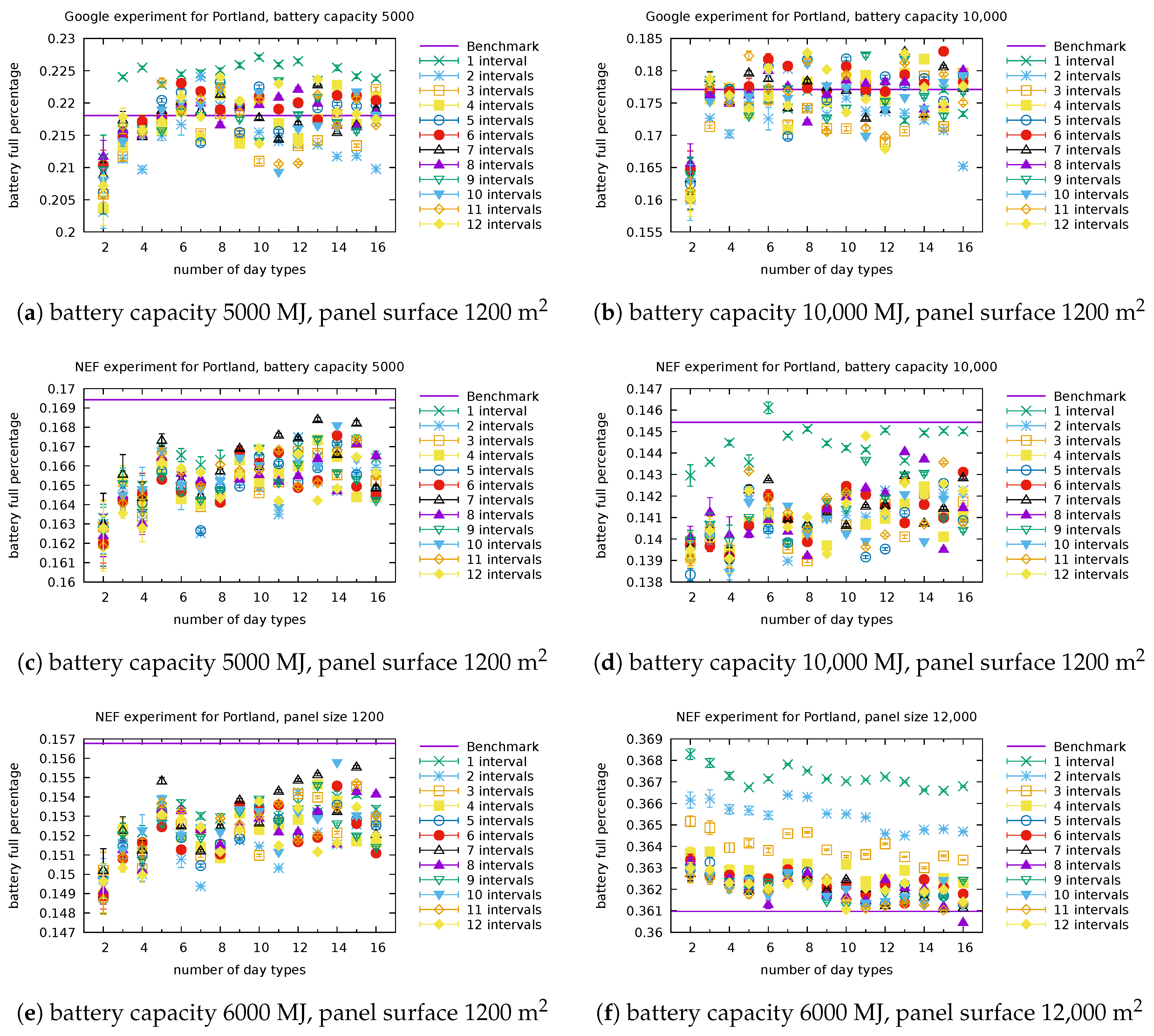
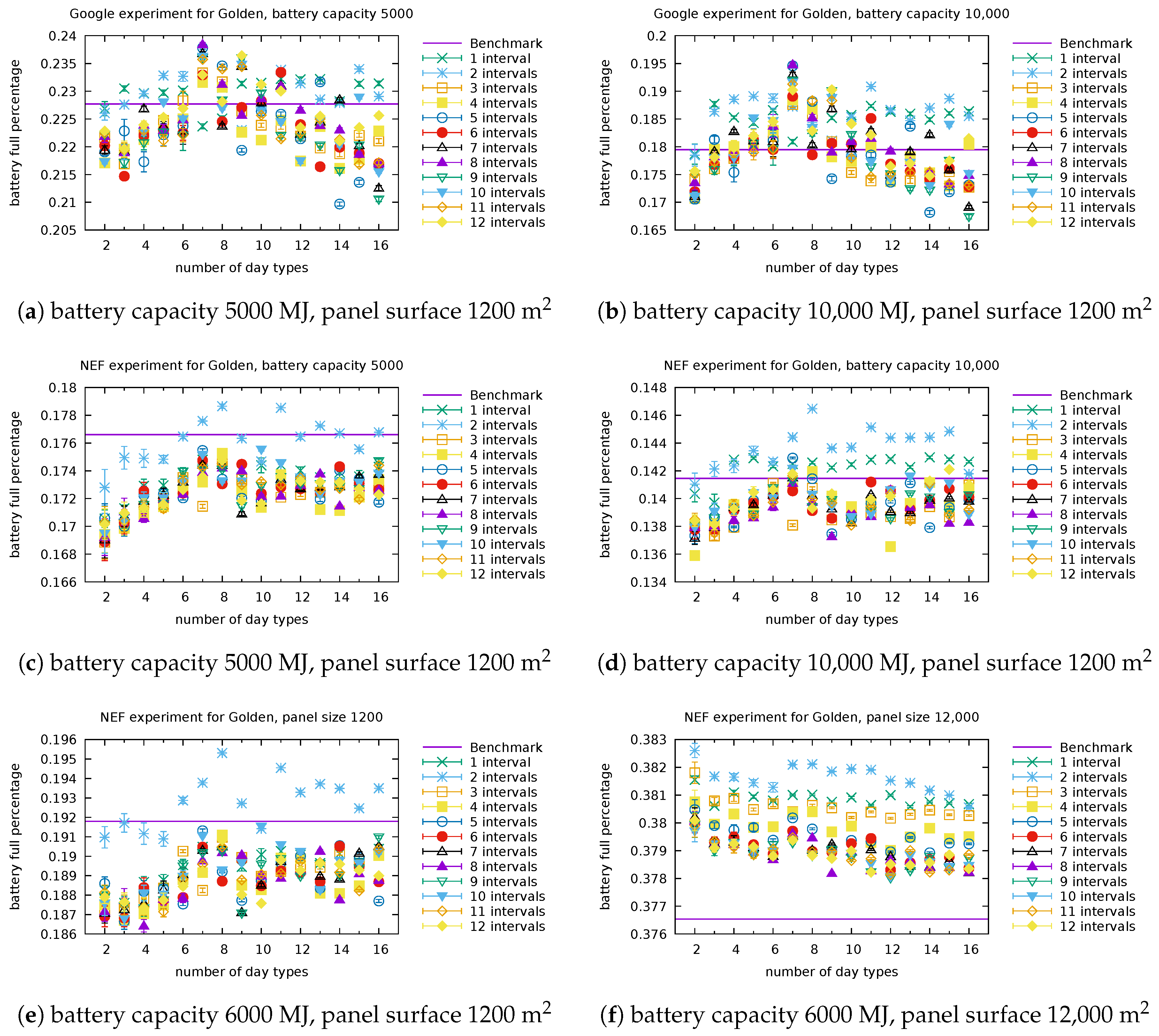
We illustrate in
Figure 4 and
Figure 5 the types obtained for selected numbers of clusters (in other words, selected sizes of
) and selected number of intervals. Each graphic in these figures reports the centroids of the clusters obtained. The numbering of the clusters changes at each run, but by looking at the centroids obtained, it is often possible to map the clusters obtained with different number of intervals. For instance, the cluster (type) numbered 3 in
Figure 4a has a centroid with coordinates close to 1, which represents days where the clear sky index is close to 1 all day long. Such clear sky days are grouped in cluster 0 in
Figure 4b, whose centroid has coordinates close to 1. Similarly, type 0 in
Figure 5a can be mapped to type 4 in
Figure 5b and represents days with heavy clouds.
As for the distributions
,
,
, we use the empirical distributions of the clear sky index of the days in cluster
in the training set and view them as the ground truth for the day type
. For illustration purposes, we display in
Figure 6 the distributions
when there are
types of days and the day is partitioned into
intervals (this implies that there are actually three distinct distributions for each day type).
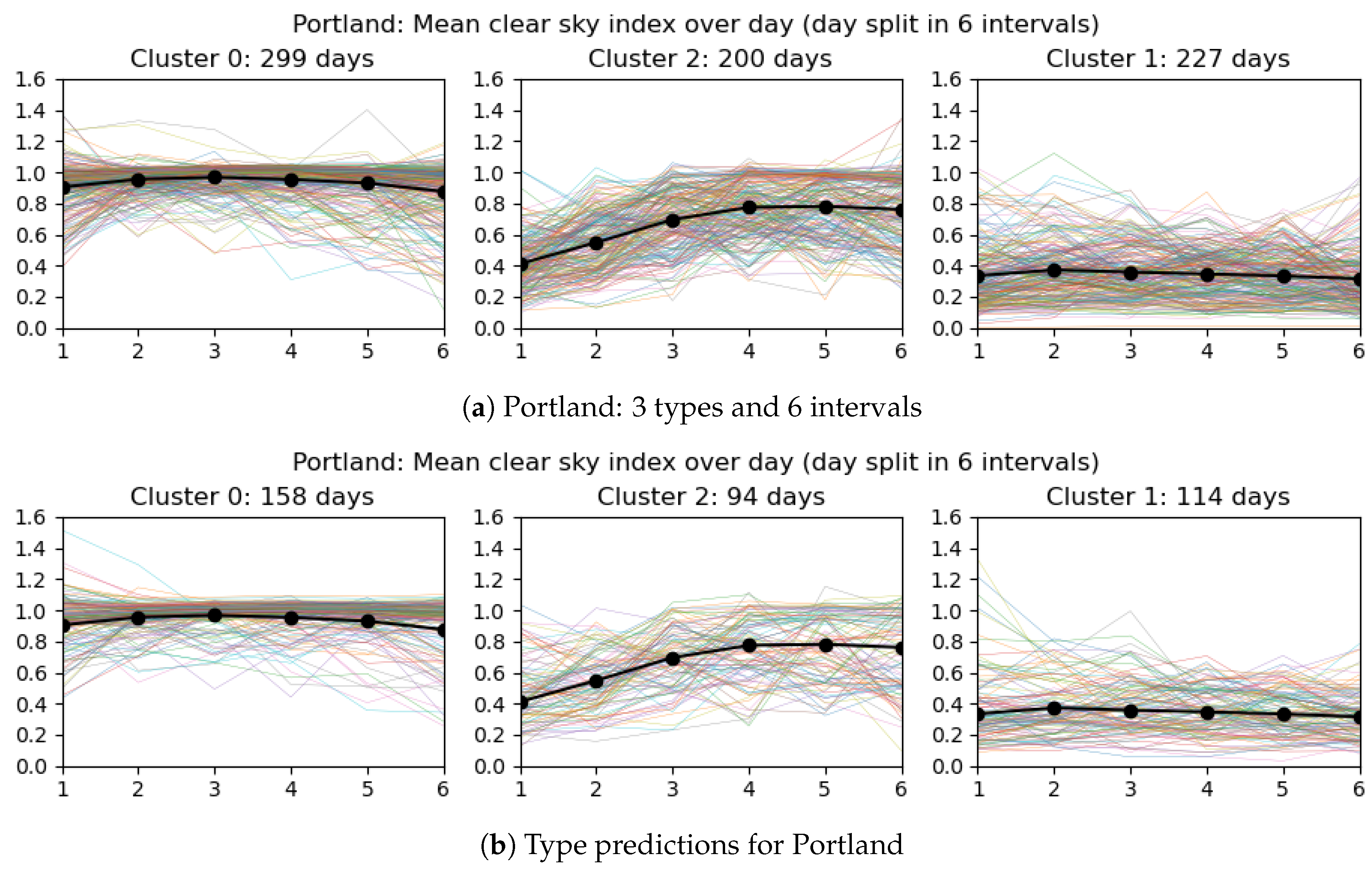
Once clusters have been identified, we predict the types of the days present in the testing set (which will be used in the experiments). We illustrate in
Figure 7 the predictions obtained for Portland when there are three day types (clusters) and the day is split into six intervals. In the practical use of the model, the data of next day are obviously not known exactly. A proxy for it is given by weather predictions. Assuming that some hourly prediction of cloudiness is available from the weather service, the representative values for each interval can be determined, to serve as the basis for the day type prediction. If hourly predictions are not available, coarser information can be used in conjunction with a model with fewer intervals.
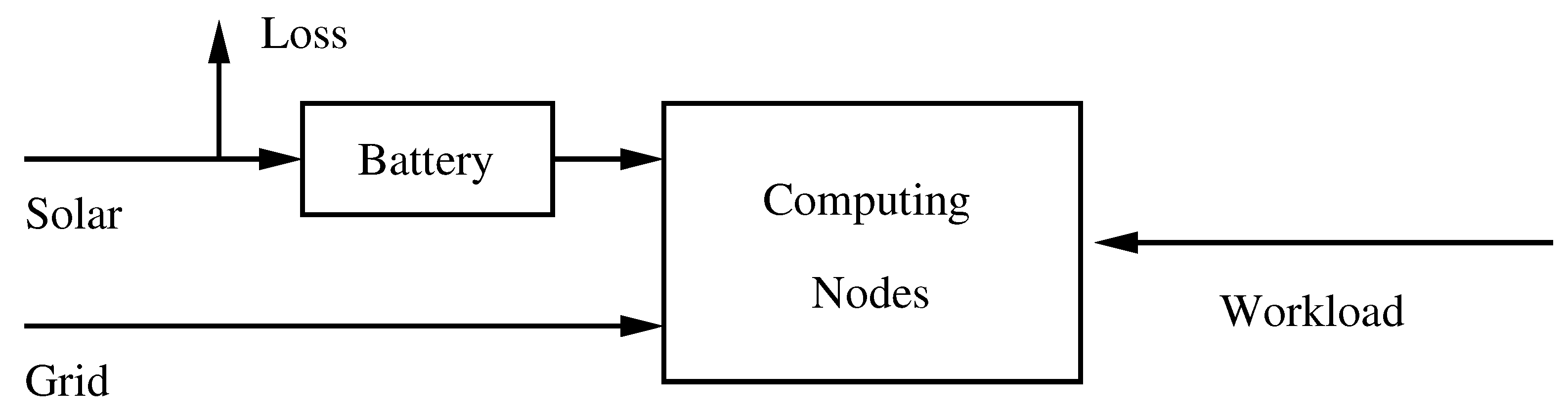
4.2. Energy Consumers
The solar energy collected by photovoltaic sources and stored in batteries is used to power a computing cluster. To simulate the energy consumption of a computing cluster, we rely on traces of two real clusters. The first cluster, called NEF [
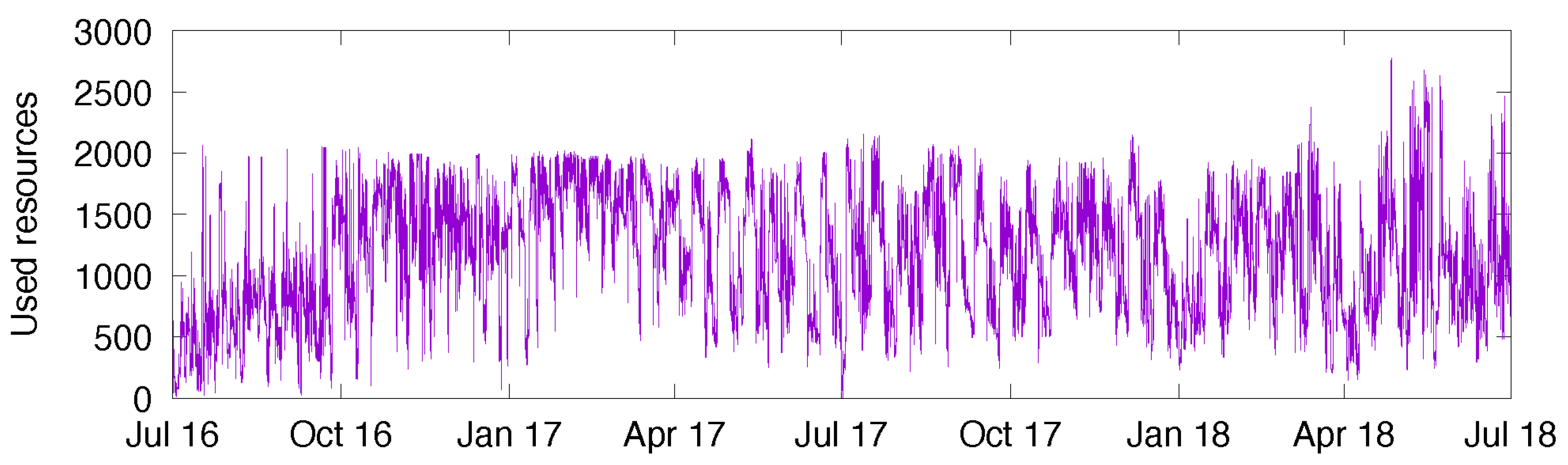
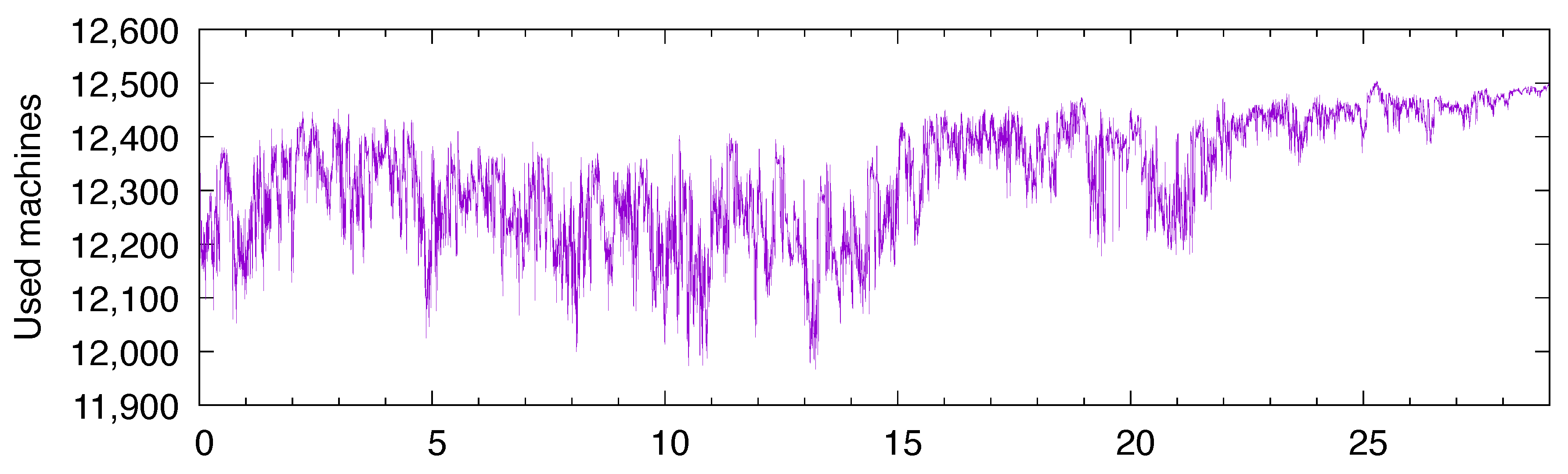
27], is used internally at Inria for research purposes. The workload trace that we have covers the workload experienced over a period of two years (from July 2016 until June 2018—this trace was captured by Inria’s IT staff in July 2018 and we got exclusive rights to use it after screening by Inria’s General Data Protection Regulation officer). The second cluster is part of a larger Google computing cluster, used mostly internally by Google employees, but it also runs jobs for clients. The detailed workload description can be found in [
25]. This trace covers a period of 29 days in May 2011. For each of the clusters, we first computed the number of resources/machines used over time, and then integrated that number every minute (since our solar model has the minute as its unit of time). The energy consumption per minute is a function of this integrated workload; see (4).
Figure 8 depicts the workload of NEF, and
Figure 9 depicts that of the Google cluster.
To suit our experiments, we had to pre-process these traces in order to give them the same order of magnitude. To begin with, the Google trace clearly fluctuated between around 11,900 and around 12,500 resources. With this fluctuation being small relative to the total, the datacenter might be seen as having an almost constant consumption. In order to give more variability to the trace, we have subtracted the baseline value 11,900. As a result, the workload fluctuates between 0 and 600 approximately. In comparison, the NEF trace fluctuates between 0 and 2000 most of the time.
The global characteristics of these traces are summarized in
Table 2. Observe that the unit used is relevant for the minute-based model.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















