1. Introduction
Speech emotion recognition (SER) is an active area of research and a better way to communicate using among human–computer interaction (HCI). Speech signals play an important role in various real-time HCI applications, such as clinical studies, audio surveillance, lies detection, games, call centers, entertainment, and many more. However, the existing SER techniques still have some limitations, which include robust feature selection and advanced machine learning methods, for an efficient system. Thus, researchers are still working to find a significant solution in order to choose the right features and advance the artificial intelligence (AI) based classification techniques. Similarly, the background noise in a real-world voice could also be dramatically effective on the machine learning system [
1,
2]. Nevertheless, the development of a decent speech-based emotion recognition system can easily increase the user experience in different areas with the HCI, such as AI cyber security and mobile health (mHealth) [
3]. The AI model has better potential than classical model to recognize the emotional state of the speaker from their signals during speech and shows a considerable impact on the SER in order to imitate these emotions [
4]. Deep learning and the AI performed a significant improvement in the mobile health assistance field as well as increased their performance [
5,
6]. Nowadays, the researchers utilize the deep learning approaches in order to solve the recognition problems, such as voice recognition, emotion recognition, gesture recognition, face recognition, and image recognition [
7,
8,
9]. The main advantage of the utilization of deep learning approaches is the automatic selection of the features. The suggested model adjusts the weights in the convolution operation according to the input data, and it finds the important and the task-specific attributes [
10,
11].
Recently, the researchers have introduced a various number of deep neural networks (DNNs) techniques to model the emotions recognition in the speech data. These models are fundamentally different in nature. For example, one group designed a DNN model that detects significant cues from raw audio samples [
2], and another group utilized a particular representation of an audio recording to provide input for the model [
12]. In order to make a robust and a significant model, the researchers utilized different types of feature combinations using diverse network strategies. Nowadays, deep learning and artificial intelligence methods are dominant toward extracting hidden cues and to recognize lines, curves, dots, shapes, and colors, because they utilize various types of convolution operations [
13]. Thus, the researchers have utilized the modest end-to-end models for the emotion recognition, which include convolution neural networks (CNNs), recurrent neural networks (RNNs), long short-term memory (LSTM), and deep belief networks (DBNs) [
14,
15]. These models extract high-level salient features from the speech signals that achieved a better recognition rate compared to the low-level features [
8,
13]. The researchers have used a deep learning model for an efficient SER, but the level of accuracy and the recognition rate are still quite low due to the data scariness and the worst model configuration. The current CNN approaches lack the ability to increase the accuracy of the emotion recognition in the SER domain. Furthermore, the researchers have utilized the RNN and the LSTM in order to learn the long-term dependencies and recognize the emotions. Nevertheless, these techniques have not revealed any significant changes in accuracy, but they increased the cost computation and training time of the whole model [
16]. The SER domain still has many issues that need to be solved with an efficient and significant framework that recognizes the spatial emotion cues as well as the sequential cues.
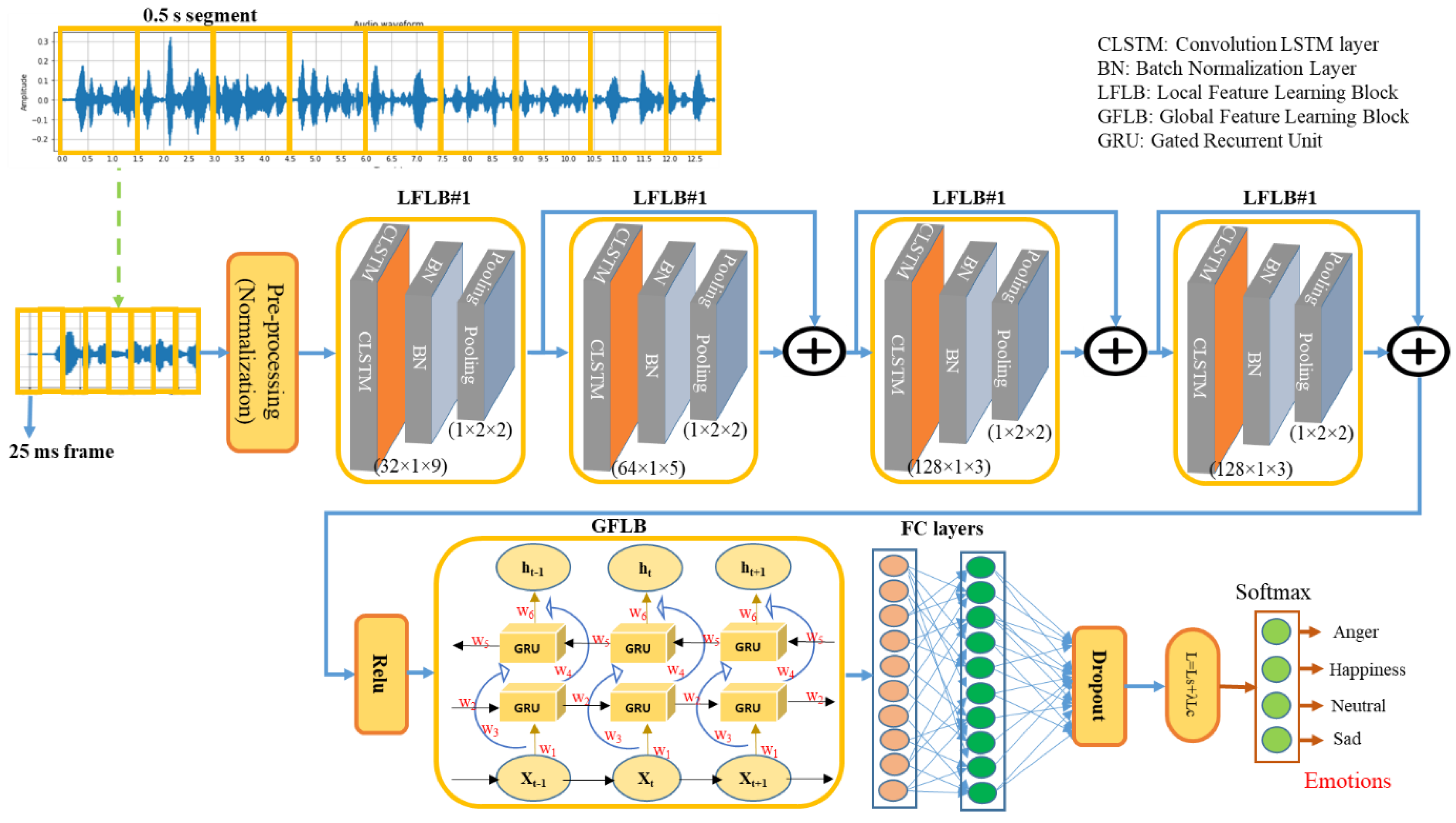
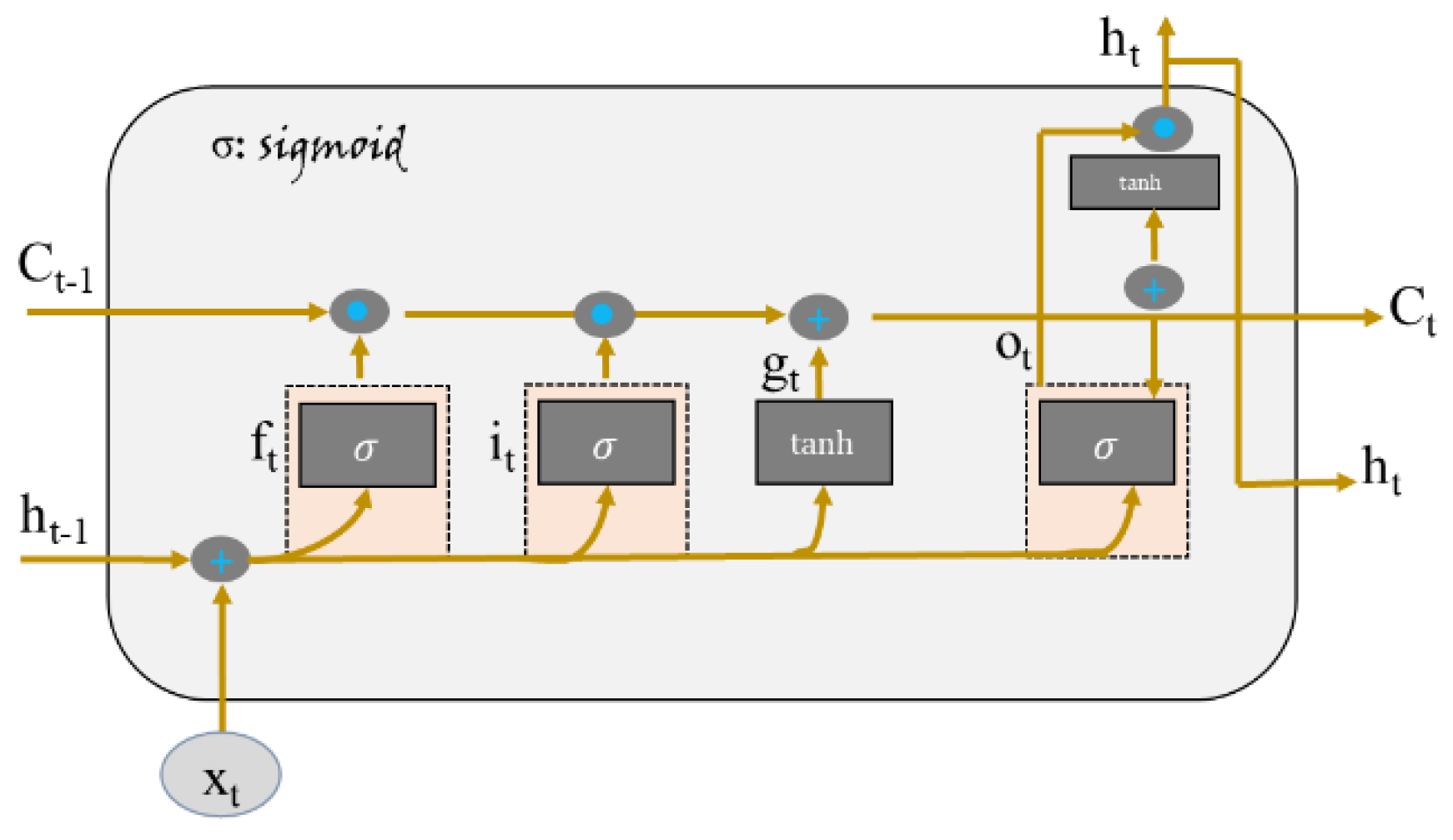
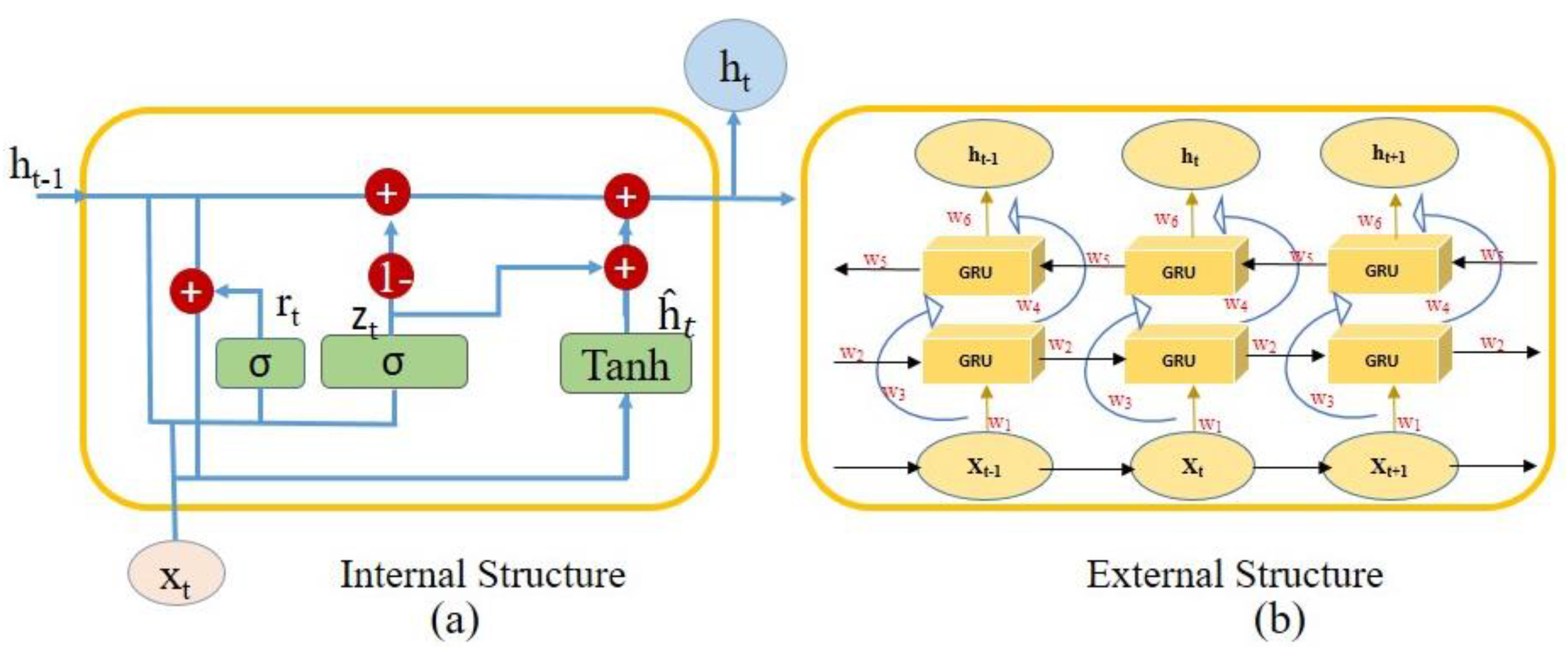
In contrast, we addressed the low-accuracy issues and proposed a novel framework for the emotion recognition that utilized speech signals. We designed a system which recognized the local hidden emotional cues in the raw speech signal by utilizing the hierarchical ConvLSTM blocks [
17]. We adopted two types of sequential learning in this framework. The first type is the ConvLSTM, which learns the local features using input-to-state, and the second is state-to-state transition using a convolution operation, which learns the global features using input sequences by a stacked BiGRU network. Furthermore, we utilized the center loss function for the final classification, which ensured the prediction performance and improved the recognition rate. For the evaluations of the proposed system, we utilized two benchmark databases that included the interactive emotional dyadic motion capture (IEMOCAP) dataset [
18] and ryerson audio visual database of emotional speech and song (RAVDESS) [
19] dataset, which obtained a 75% recognition rate and an 80% recognition rate, respectively. We compared the proposed SER system with other baselines in the experimental section, which clearly designates the robustness and the significance of the proposed system. The summarized contributions of the proposed framework are demonstrated below.
We proposed a novel one-dimensional (1D) architecture for SER using the ConvLSTM layers, which find the spatial and the semantic correlation between the speech segments. We adopted an input-to-state and a state-to-state transition strategy that utilized a hierarchical connection that learns the spatial local cues by utilizing the convolution operation. Our model extracts the spatiotemporal hierarchical emotional cues by proposing several ConvLSTM blocks that are called the local features learning blocks (LFLBs). According to the best of our knowledge, this is the up-to-date invasion of AI and deep learning in SER domain.
The sequence learning is very important to adjust the relevant global features’ weights in order to find the correlation and the long-term contextual dependencies in the input features, which ensure the improvement of the feature extraction and the recognition performance. That’s why we adaptively adjust the GRUs network with the ConvLSTM in order to compute the weights of the global features, since the global feature weights are re-adjusting from the local and the global features. According our knowledge, this is the first time that the GRUs network is seamlessly integrated with the ConvLSTM mechanism for the SER using raw speech signals.
We introduced a center loss function, which learns and finds the center of the feature vector of each class and defines the distance among the features and their consistent class center. The usage of the center loss with softmax loss improves the recognition result with a high performance. We proved that the center loss is easily optimized and increased the performance of deep learning model. To the best of our knowledge, this is the first time that the center loss is used with the ConvLSTM in the SER domain.
We tested our system on two standard corpora, which include the IEMOCAP [
18] and the RAVDESS [
19] emotional speech corpus, in order to evaluate the effectiveness and the significance of the model. We secured a 75% recognition rate and an 80% recognition rate for the IEMOCAP and RAVDESS corpora. The experimental result indicated the robustness and the simplicity of the proposed system and showed the applicability for actual application.
The rest of the article is divided as follows.
Section 2 highlights the associated SER literature, and the proposed framework for emotion recognition is shown in
Section 3. Detailed documentation of the practical results, experimentations, discussion, and comparison with baseline SER methods are presented in
Section 4. The conclusion for this paper and the direction for future work is presented in
Section 5.
2. Related Works
In the literature, the majority of the researchers used CNNs, RNNs, DNNs, and LSTM architecture to develop an efficient system for emotion recognition that utilized speech data [
20] or some researchers used a combination of them [
2,
21]. The combined architecture of the CNN and the LSTM extracted the hidden patterns as well as recognized the long-term contextual dependencies in the speech segments and learns the temporal cues [
22]. The selection and the identification of the robust and the significant features is a challenging task for emotion recognition in the speech data that can be utilized for efficient model training. In this advanced era, researchers have used various approaches in order to improve the recognition accuracy and to solve the problems of the existing SER methods. In Reference [
23], the authors utilized the CNN approach for the SER using the raw speech data. The CNN model processes the input signals to detect the noises, and it selects the specific regions of the audio sample for the emotion recognition, which achieved better results at that time [
6]. In Reference [
20], the authors utilized the predefined features, which included the eGeMaps [
24] with a self-attention module, using global windowing techniques for the features extraction in order to recognize the emotional state of the speaker. Similarly, Reference [
25] used a combination of the predefined features sets, which included the eGeMaps [
24] and the ComParE [
26], for the SER task. The authors enhanced the level of accuracy with these predefined features sets as well as increased the cost computations of the overall model. The authors utilized the Berlin emotion dataset (EMO-DB) [
27] corpus in Reference [
28] for the emotion recognition that utilized the time disturbed CNN layer and obtained highly favorable results over the state-of-the-art model of that time. The authors converted the speech signals into spectrograms by applying a short-term Fourier transform algorithm and fed it as an input into the time-distributed CNN model. A similar approach has been used in Reference [
29] that utilizes speech data and recognizes emotions through spectrograms by applying the CNN model. The authors utilized a kernel shape filter in the convolution operation of the pre-trained CNN Alex-Net [
30] model, which secures a satisfactory recognition rate on the EMO-DB [
27] dataset. Nowadays, internet of things (IoT) has become popular in different fields such as privacy-preserving [
31], stock traders using deep learning [
32], and Q-learning approach for market forecasting [
33].
However, the authors in Reference [
22] developed an advanced two-dimensional (2D) CNN-LSTM model for an emotion recognition system that recognized the spatial and the temporal information in the speech data using log-Mel spectrograms. In Reference [
34], the authors proposed an SER model and enhanced the recognition rate by utilizing a data augmentation approach that is based on a generative adversarial network (GAN) [
35]. The authors produced synthetic spectrograms in order by applying the proposed technique using the IEMOCAP [
18] emotional speech corpus. In the recent era, another proficient method was proposed in Reference [
36], which extracted the Mel frequency cepstral coefficients (MFCCs) for the model training and reduced the features using a fuzzy c-mean clustering algorithm [
37,
38]. The authors developed several classification techniques, such as support vector machine (SVM), an artificial neural network (ANN), and k-nearest neighbors (KNN) in order to enhance the recognition accuracy of the existing SER methods. Similarly, the authors used text files and audio files of the IEMOCAP [
18] dataset in order to develop a multi-model approach for the SER and in [
39] developed a hybrid approach, deep learning, and machine learning combined in order to classify the emotional state of the speaker [
6]. The authors used a semi-CNN for the feature learning, the SVM was utilized for the classification, and they performed speaker-dependent experiments and speaker-independent experiments to recognize emotions in speech signals. Furthermore, in Reference [
39], the authors used the traditional machine learning method using the modulation spectral features (MSFs) and the prosodic features and classified them by multi-class linear discriminant analysis (LDA) classifier [
40]. With the combination of these features, which the authors achieved an 85.8% accuracy with the testing set of the EMO-DB [
27] corpus. Moreover, the researchers used the SVM classifier with different type features [
41] that included the extracted timber and the MFCCs features [
14] and the extracted Fourier parameter and the MFCCs features, and they classified them by the SVM classifier that achieved 83.93% and 73.3% accuracy respectively, on the EMO-DB [
27] dataset.
With the development of the technologies, the researchers also applied the new techniques for the feature selection and the extraction. For example, Shegokar and Sircar [
42] used the continuous wavelet transform (CWT) method for the RAVDESS [
19] dataset in order to select the features and then classify them accordingly by the SVM classifier. In Reference [
43], the authors proposed a multi-task learning model for the emotion recognition using the RAVDESS [
19] speech dataset, and they achieved a 57.14% recognition rate for four classes, which included anger, neutral emotions, sadness, and happiness. Similarly, Zeng et al. [
44] used the same learning strategy and dataset in order to enhance the recognition rate by utilizing deep learning and the multi-task residual network, and in Reference [
45], they fine-tuned a pre-trained VGG-16 [
46] model for the same task in order to classify the speech spectrograms. In the above literature, the researchers have developed many techniques in order to improve the prediction performance of the SER, but the recognition rates are still low. In this study, we developed an efficient and a significant SER system using hierarchical ConvLSTM blocks in order to extract the hidden emotional cues and then feed into a sequential model for the extraction of the temporal features. Finally, we produced the probabilities of the classes by using the center loss and the softmax loss, which ensure and increase the final classification results. A detailed description of the proposed framework is demonstrated in the upcoming part.
4. Experimental Evaluation and Discussion
In this section, we experimentally proved our proposed recognition approach for speech emotions using the speech signals and experimentally assessed them utilizing various matrices of accuracy, such as weighted and un-weighted accuracy, precision, recall, and F1_score. We evaluated the proposed SER approach over different benchmarks, which included the IEMOCAP [
18] and the RAVDESS [
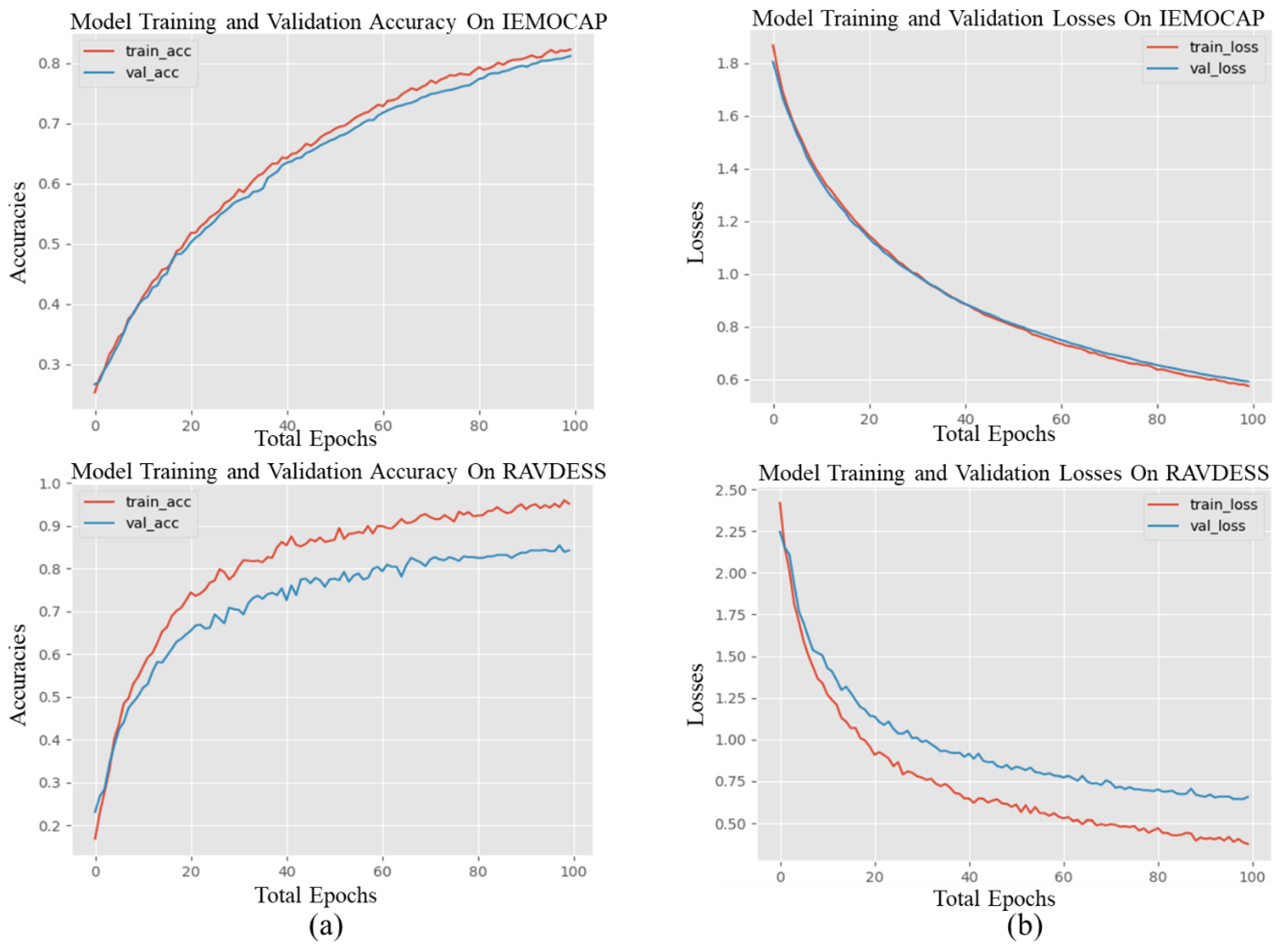
19] speech corpora. We deeply assessed the prediction performance of the proposed approach with different accuracies, matrices that included class-wise balance accuracies, overall accuracy, and a confusion matrix among the actual emotions and the predicted emotions. The performance of the proposed emotion recognition system is compared with the state-of-the-art systems. The model performance, the training, the validation accuracies, and losses graph of both datasets are presented in
Figure 4. The detailed investigational consequences with the discussion and the comparisons with baseline state-of-the-art methods of each dataset are explained in separate sections.
In this study, we tried different types of AI and deep learning architecture with a sequence learning module and without a sequential module in order to select an efficient approach, which can easily recognize the depth of emotion in the speech signals. After extensive experimentations, we proposed this framework for the SER, which ensures a high-level performance with a better prediction rate using the different classes. For the convenience of the readers, we conducted an ablation study in order to select the best model and investigate further with a different number of emotions. A detailed description and results for the different AI and the deep learning architecture and their results in the form of un-weighted accuracy are illustrated in
Table 1, which utilize the IEMOCAP [
18] and the RAVDESS [
19] emotional speech corpora.
Table 1 presents the recognition results of the different deep learning architectures utilizing the ConvLSTM layer using speech signals. In the ablation study, we proposed the best model or architecture for a selected task in order to process for further investigation. In this study, we can see the different results in order to evaluate our data, and we selected the best model, and we further processed them. First, we utilized only the ConvLSTM with a fully connected layer and recognized the emotions using softmax. The results of this model were not convincing, so we then applied a residual learning strategy with a skip connection and the result slightly increased. In skip connection, we concatenate the early layer or block output with later layer or block by utilizing an addition of essential connections. In this strategy, for essential connection, we made a straight up connection between early and later layers or blocks. Furthermore, we adjusted the global weight with the ConvLSTM for the long-term contextual dependences in order to efficiently identify the sentiments in long dialogue sequences. We applied a bi-directional LSTM and a bi-Directional GRUs network in order to re-adjust the global weights with the learned features. The recognition rates were increased with this sequential learning model. We selected the GRUs model for sequential leaning, because it is quite good for partial data and the results of the GRUs were better and more convenient for this task, which is illustrated in
Table 1.
4.1. The Results of the IEMOCAP (Interactive Emotional Dyadic Capture)
IEMOCAP [
18] is an emotional and acted corpus of audio speech data, which has eight different emotions that are collected in five sessions with ten (10) professional actors. Each session used two actors, which included one male actor and one female, in order to record the diverse expressions, such as anger, happiness, sadness, neutral emotions, and surprise. These expert actors recorded 12-hour audiovisual data with a sixteen kHz sampling rate. All the emotions in this dataset are pre-scripted, and the actors just read with different expressions and categorized them in the scripted and the improvised versions. We evaluated our model using four emotions, which are frequently used in the literature, and compared our model with an existing state-of-the-art SER model. The detailed overview of selected four emotions is illustrated in
Table 2.
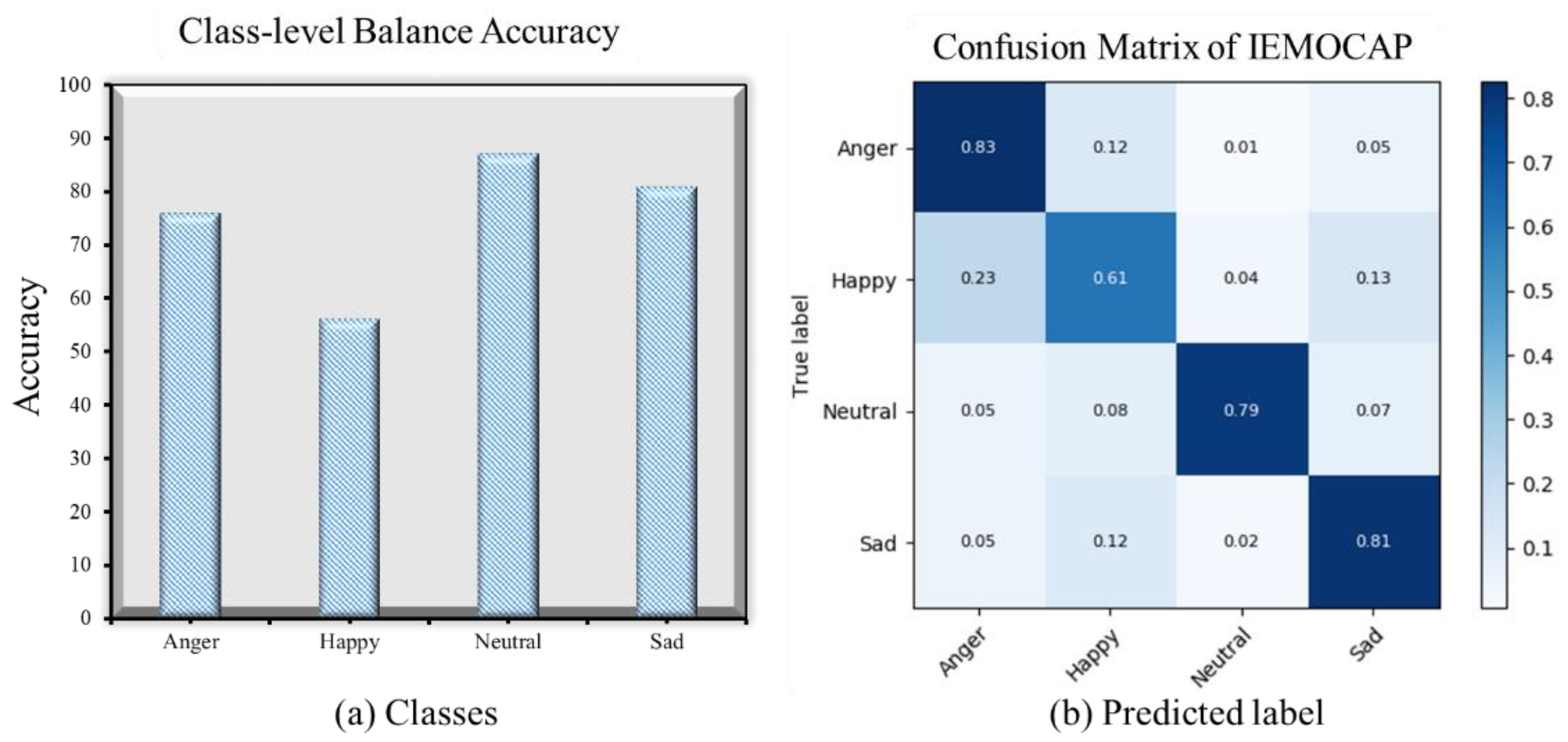
We conducted extensive experiments on the IEMOCAP corpus utilizing the five-fold cross-validation technique in order to evaluate the proposed system, and tested the prediction performance on the unseen data. We are using 20% of the data for the model testing or validation and 80% of the data for the model training in each fold. For the model prediction performance, we used different evaluation matrices, which included the weighted, un-weighted, F1_score, class-wise balance accuracy, and the confusion matrix, in order to show the strength of the proposed system for the selected task. The class-wise results represent the balance accuracy in each class of recognition—how the model accurately recognizes each class. The weighted and un-weighted accuracy shows the actual and the predicted ratio among the dataset and the classes. Similarly, the F1_score shows the balance among the precision and the recall or the harmonic mean between these in each class. Finally, we constructed the confusion matrix in order to show the confusion among the actual emotions and the predicted emotions for further investigation. In the confusion matrix, the diagonal values show the actual prediction performance, and the confusion among other classes are shown in the corresponding rows. The classification report, the confusion matrix, and the class-wise balance accuracy of the IEMOCAP dataset are illustrated in
Table 3 and
Figure 5.
IEMOCAP [
18] is a challenging dataset in the field of speech emotion recognition, which has different emotions, and most emotions overlap, so the recognition rate is therefore very low according to the literature. Our system shows a significant improvement with the recognition accuracy of each class as well as with the overall model prediction performance. The system recognized anger, sadness, and neutral emotions with more than a 75% rate and happiness with a 61% rate, which is better than the state-of-the-art methods.
Figure 5a shows the class-wise balance recognition accuracy of the proposed system over the IEMOCAP speech corpus. The x-axis direction indicates the whole classes, and the y-axis shows each class’ recognition results. Similarly,
Figure 5b shows the confusion matrix of the IEMOCAP corpus, which illustrates the confusion between the actual emotions and the predicted emotions. The x-axis direction shows the actual label, and the y-axis direction shows the predicted labels of the system. The recall values represent the actual recognition rate in the confusion matrix, which are shown diagonally. The comparative analysis of the proposed SER system is represents in
Table 4.
The confusion rate among the other classes is shown in the corresponding rows of each emotion in the confusion matrix. Utilizing this dataset, we compared our proposed system with the different CNN and classical models, and it showed results that outperformed, which are shown in
Table 4.
Table 4 represents the comparative analysis of the proposed system over the baseline method [
61]. In the recent literature, 71.25% reported high accuracy using the 2D-CNN approach, and the current result of the 1D-CNN approach is 52.14% according to Reference [
22]. Our proposed system increased the level of accuracy by 3.75% from the recent deep learning approach and more than 20% from the 1D baseline model [
22], because the existing model used low-level features, and our system hierarchically learned high-level discriminative spatiotemporal features. The high recognition rates in 2019 were 66% and 67% using the IEMOCAP emotional speech dataset, and in 2020, it was 71.25%, which is still lower and needs to improve for real-time applications. In contrast, we focused on accuracy and developed a novel 1D deep learning model that uses ConvLSTM and the GRUs to acquire high discriminative features from the raw speech signals and recognize them consequently. Due to this significant improvement, we claim that our system is a recent success of deep learning and the most suitable for real-world problem monitoring.
4.2. Results of the RAVDESS (Ryerson Audiovisual Database of Emotional Speech and Song)
RAVDESS [
19] is an acted British linguistic emotional speech database, which is broadly utilized in the emotion recognition systems in speech and songs. The RAVDESS dataset consists of 24 professional actors, which includes 12 male actors and 12 female actors, to record the pre-scripted text using different emotions. The suggested dataset has eight (8) different types of speech emotions, which includes anger, fear, sadness, and happiness. In this dataset, the number of audio files is similar in all the classes except for neutral, which has less audio files than the other classes. All the emotions were recorded using a 48 kHz sampling rate, and the average length of an audio is 3.5 seconds. In contrast, we used this dataset for our proposed model testing and training in order to estimate the prediction concert. A detailed description of the suggested dataset is illustrated in
Table 5.
Nowadays, the RAVDESS [
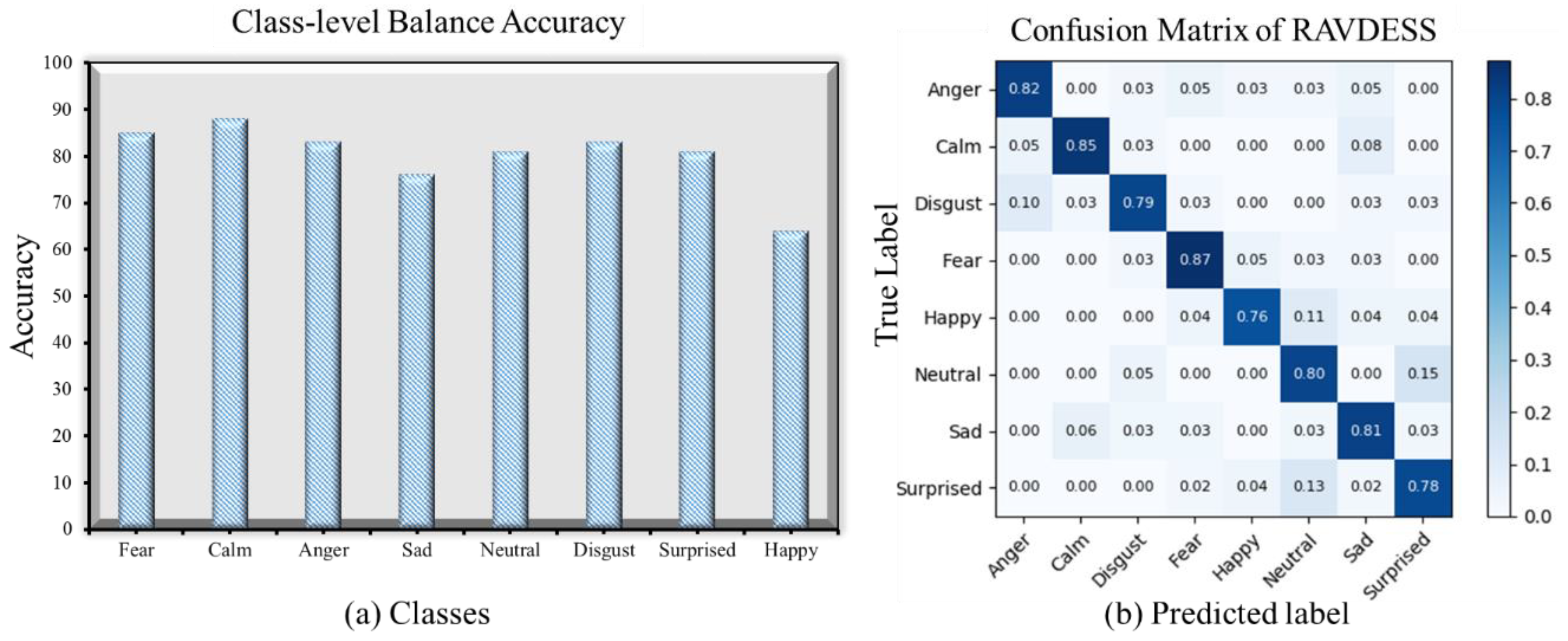
19] dataset is widely used for the emotional speech and song recognition systems in order to check the significance and the effectiveness. In contrast, we utilized this dataset and evaluated our proposed system using a 5-fold cross-validation technique. The prediction performance was evaluated through different accuracy matrices, such as a classification report, class-wise accuracy, and a confusion matrix. The classification report shows each category precision, recall, and F1_score, and the class-wise balance accuracy represents the actual prediction accuracy of each class using the suggested dataset. Similarly, we constructed the confusion matrix of the RAVDESS dataset in order to deeply analyze the performance of the actual and the predicted emotions for further investigation. For the model comparison, we used the weighted and un-weighted precision matrix that is frequently utilized in the related works for the comparative analysis. A detailed description and a visual evaluation, which includes the classification report, class-wise accuracy, and the confusion matrix of the proposed SER system, are illustrated in
Table 6 and
Figure 6 using the RAVDESS emotional speech dataset.
RAVDESS [
19] is a new speech dataset that is used the most in order to recognize emotions in speech and songs. The level of accuracy of the speech emotion recognition system on this data is still low, and the researchers have developed various techniques in order to increase the accuracy for commercial use. In contrast, we targeted the accuracy of the existing system and proposed a novel deep learning architecture that utilizes ConvLSTM and a bi-directional GRUs network. Our system extracts the deep local and the global features from the raw audio signals through a hierarchal manner that can easily improve the accuracy and ensure the prediction performance. With the use of this architecture, we increased the level of accuracy, which shows the significance of the proposed SER system. A detailed classification report of the system using the RAVDESS corpus is shown in
Table 6, which indicated the precision, the recall, the weighted, and the un-weighted accuracy of each class. Furthermore, the class-wise balance accuracy of the system is presented in
Figure 6a, which shows each class recognition rate. The x-axis shows the class label, and the y-axis shows each class recognition rate. Similarly,
Figure 6b illustrates the confusion matrix, which shows the confusion between the actual emotions and the predicted emotions, for example, the system predicts how many emotions are correctly and incorrectly predicted in each class. The actual predicted emotions are represented diagonally in the confusion matrix, and the incorrectly predicted emotions are shown in the corresponding rows of each class. The overall performance of the proposed system is better than the state-of-the-art methods. We compared our system with different baseline state-of-the-art SER systems that are based on the traditional and the deep learning approaches in order to display the effectiveness and the strength of the proposed method over these baseline system. The comparative analysis of the proposed SER model on the RAVDESS dataset is illustrated in
Table 7.
Table 7 represents the recent statistics of the existing speech emotion recognition model and the proposed SER model using the RAVDESS emotional speech dataset as well as their comparison. The researchers used different deep learning and classical approaches to create an efficient SER system, which accurately predicts different emotions. In the last year, the highest recognition rate that was reported in 2019 for RAVDESS corpus was 75.79%, and in the most recent year, 2020, the highest recorded rate was 79.01%, which still needs further improvement. Due to this limitation, we proposed a unique deep learning methodology in this study and increased the level of accuracy up to 80% using a one-dimensional CNN model. Our system recognized emotions from raw speech signals and classified them accordingly, with high accuracy. Our system is the most suitable for industrial applications, because we used a 1D network to recognize the emotional state of an individual’s speech patterns while speaking, which does not need to convert the speech signals into other forms, such as speech spectrograms and log Mel spectrograms. Due to this pretty structure, our proposed system outperformed the results of IEMOCAP and RAVDESS speech corpora, which proved its strength to monitor real-time emotions for real-world problems. According to the best of our knowledge, this is a recent success of deep learning that utilizes a one-dimensional CNN strategy with the ConvLSTM layer in the speech recognition domain.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}