A Functional Data Analysis Approach for the Detection of Air Pollution Episodes and Outliers: A Case Study in Dublin, Ireland

 ,
,  , ,
, ,  ,
,
Abstract
:1. Introduction
2. Methods
2.1. Case Study—A Sub-Urban Air Quality Monitoring Station in Dublin, Ireland
2.2. Analysis Methods
2.2.1. Classical Analysis
2.2.2. Statistical Process Control
2.2.3. Functional Data Analysis
- Extract, with replacement, a new sample of the original.
- Estimate the study parameter through the statistic of this new sample.
- Obtain the empirical distribution of the statistic.
2.2.4. Functional Strengths
- It is not necessary to know anything in advance about the distribution of the data.
- The analysis of the time sets as a unit. The sample analysed is structure in complete time units like days or years. Individually distributed values are not taken into account.
- Analysis of homogeneity. Outliers are defined differently; data which do not exceed the limit but which constantly have small deviations should be classified as outliers.
- Trend analysis. With these techniques, besides detect outliers, also it is possible to analyse situations where there are no outliers but small deviations from the normal data behaviour are observed.
- Complete analysis of the time spectrum. In classic studies, generally, the analyses are based on specific values measured in a determined set of points. The FDA, on the other hand, made it possible to work with the entire time spectrum of a continuous mode.
3. Results and Discussion
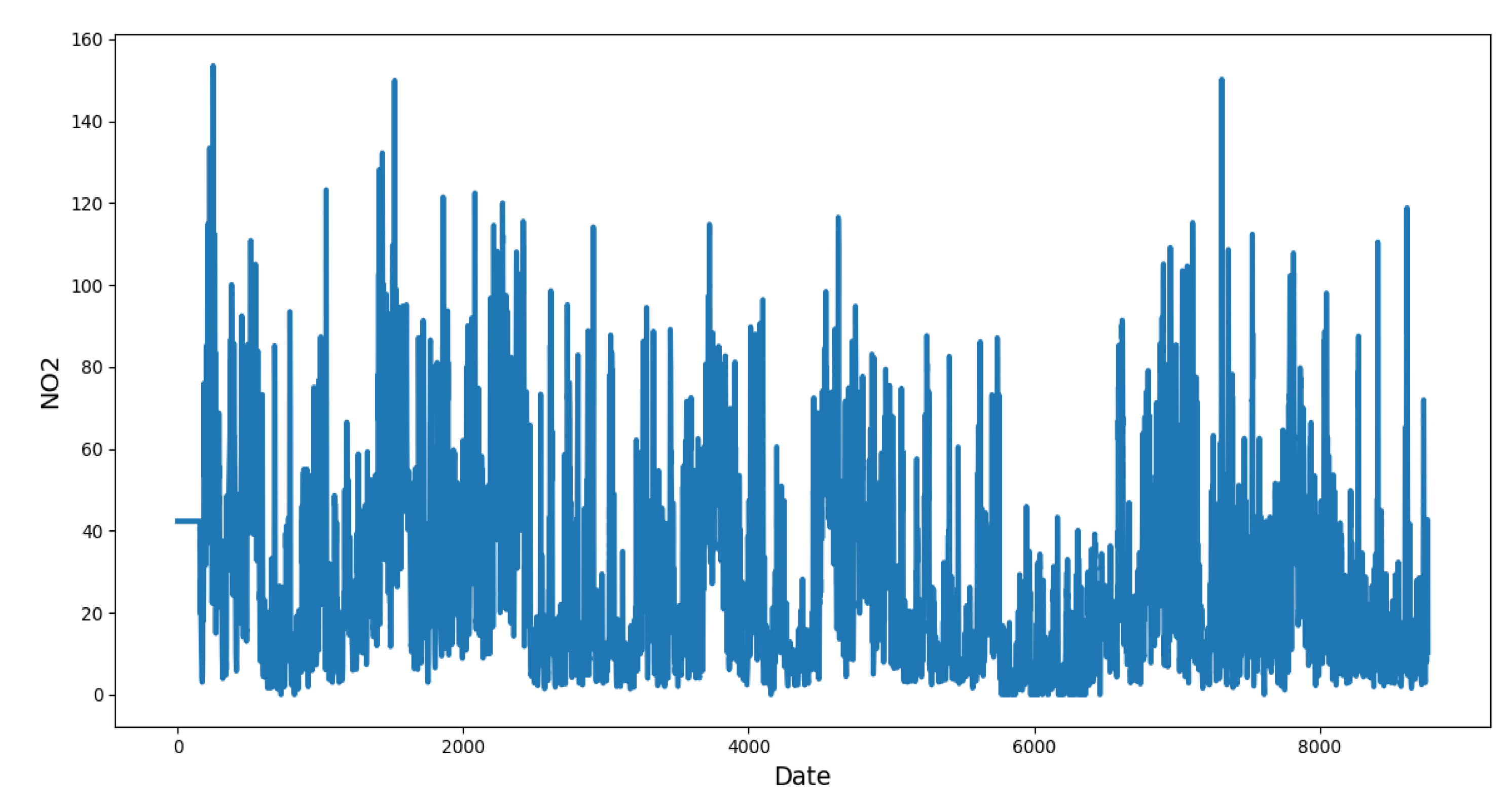
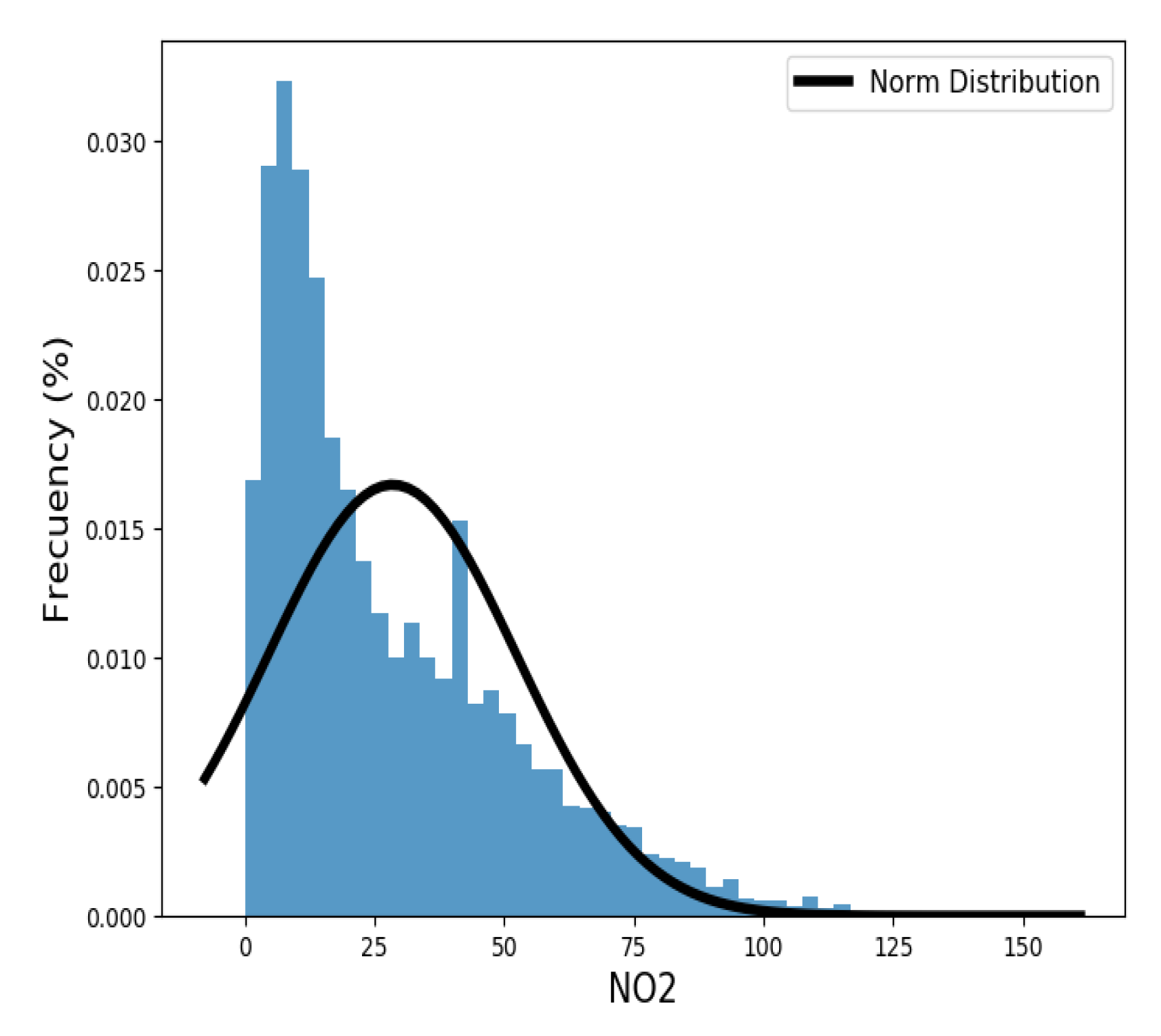
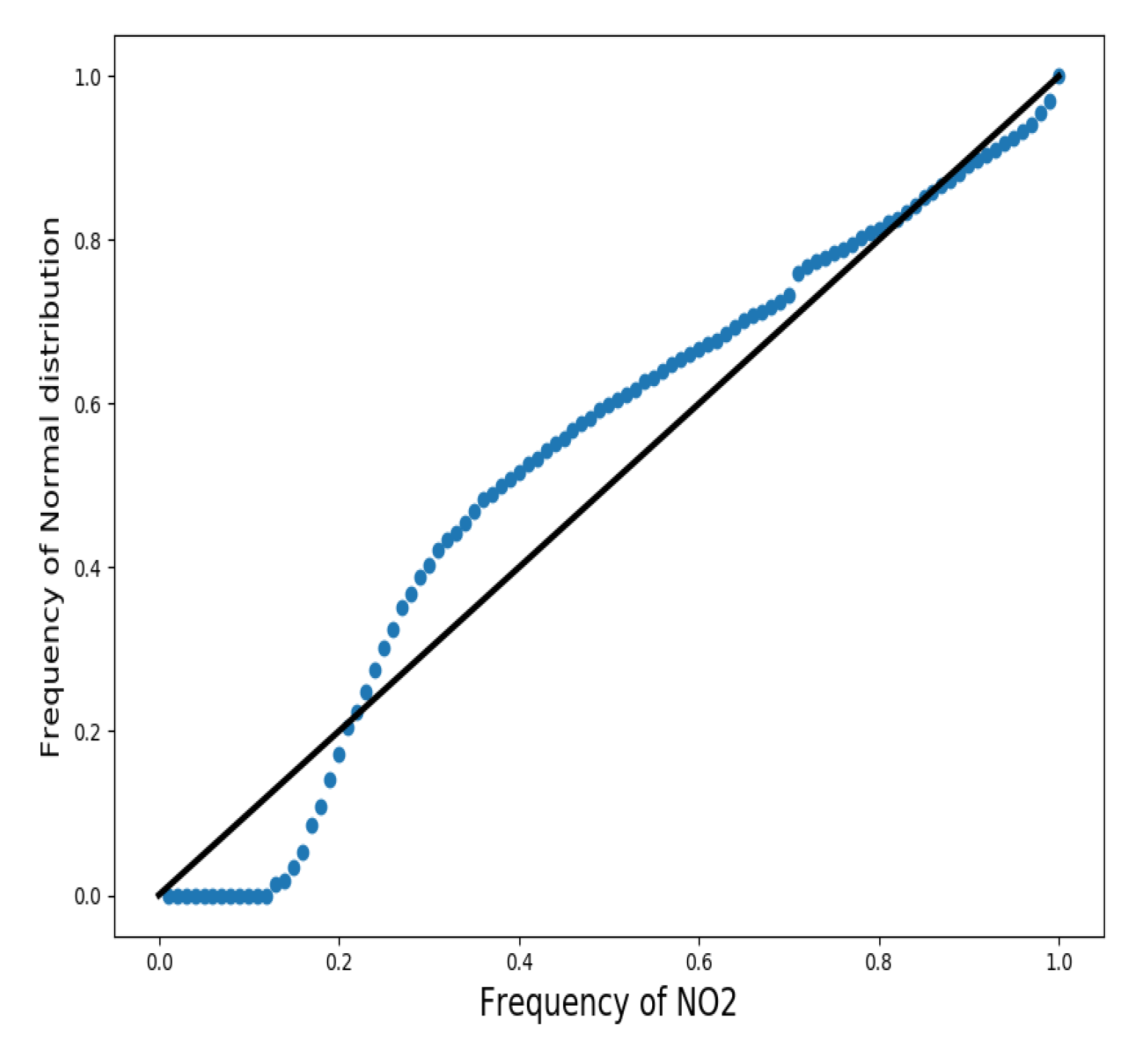
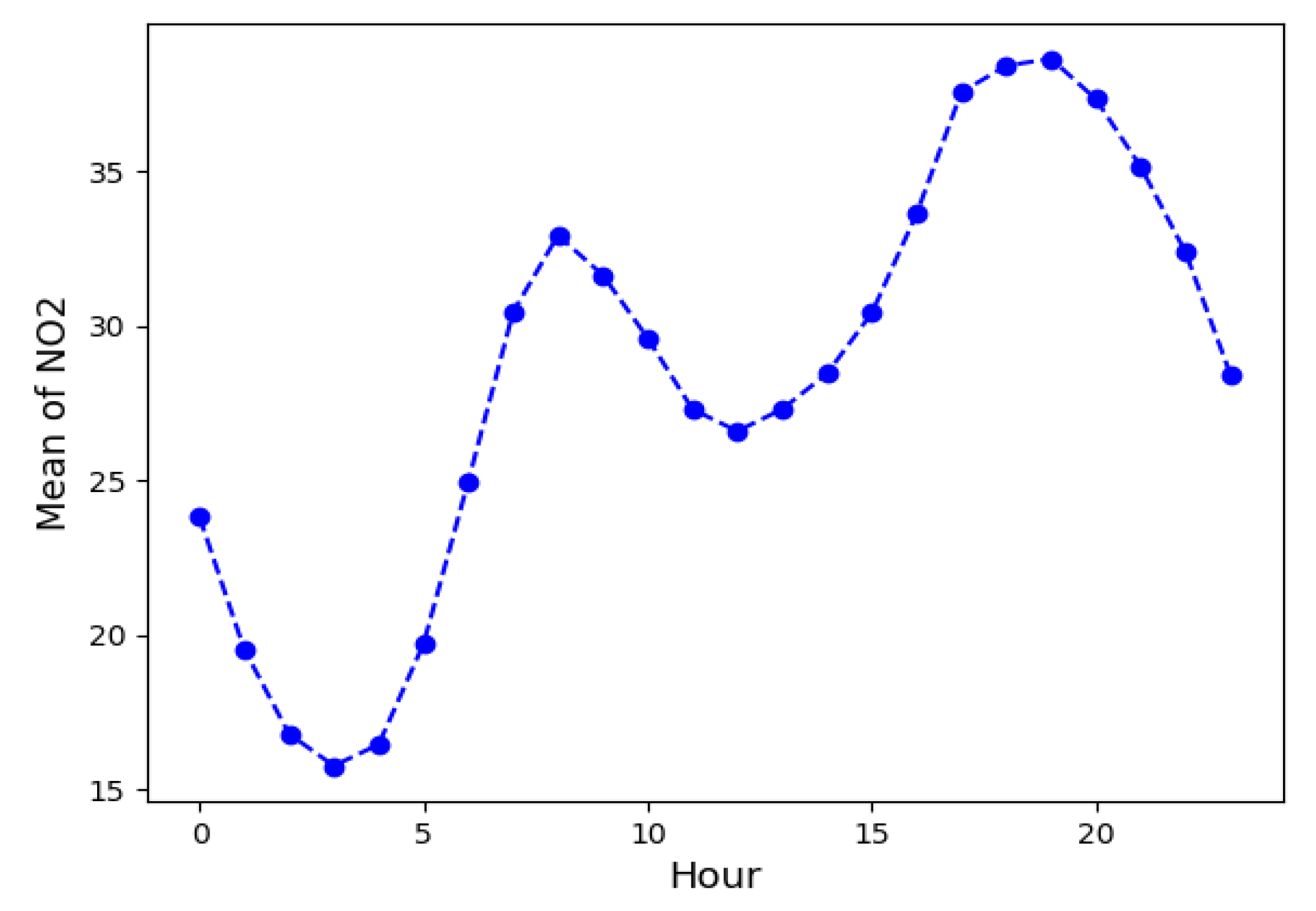
3.1. Classical Analysis
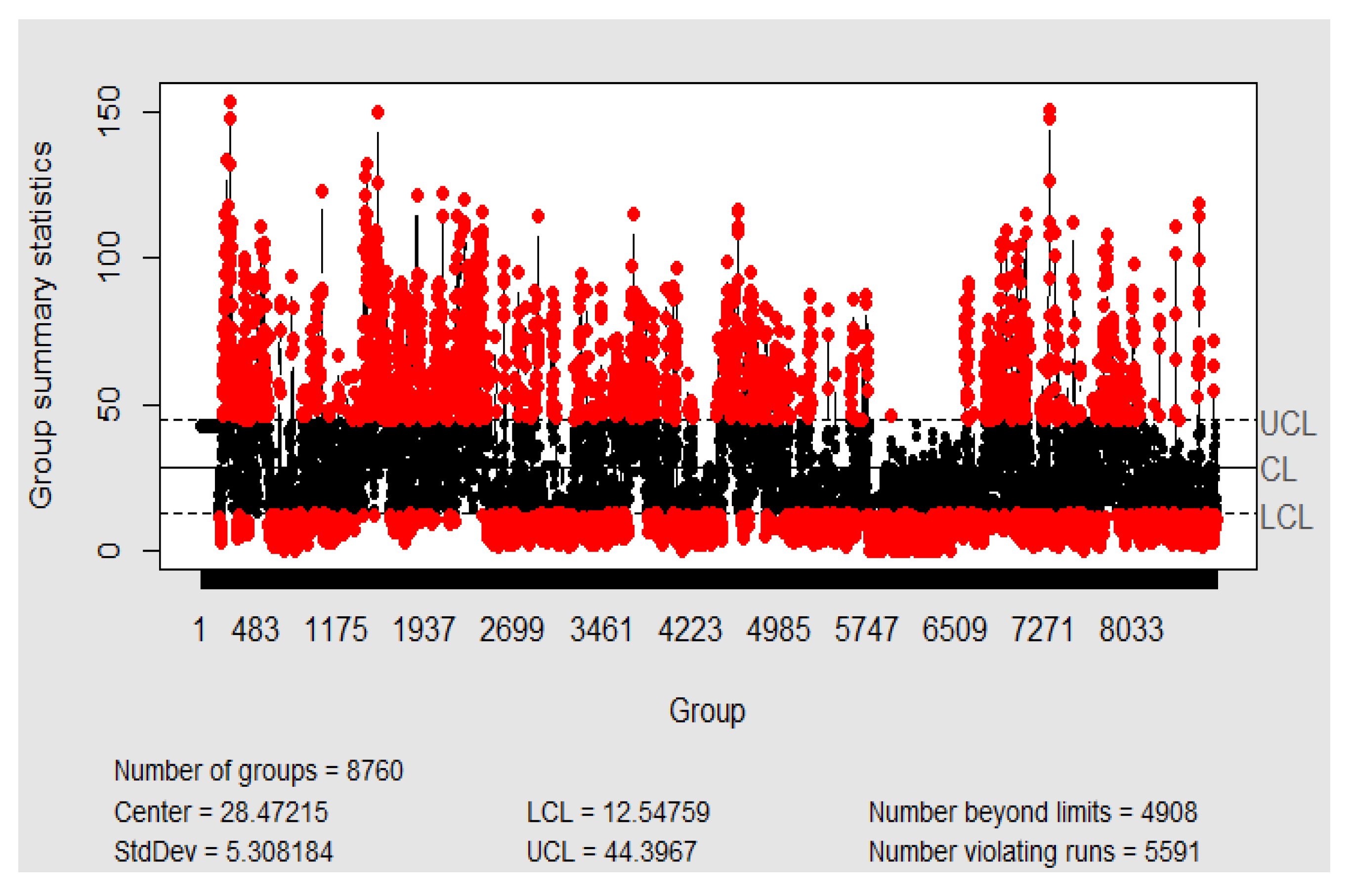
3.2. Statistical Process Control
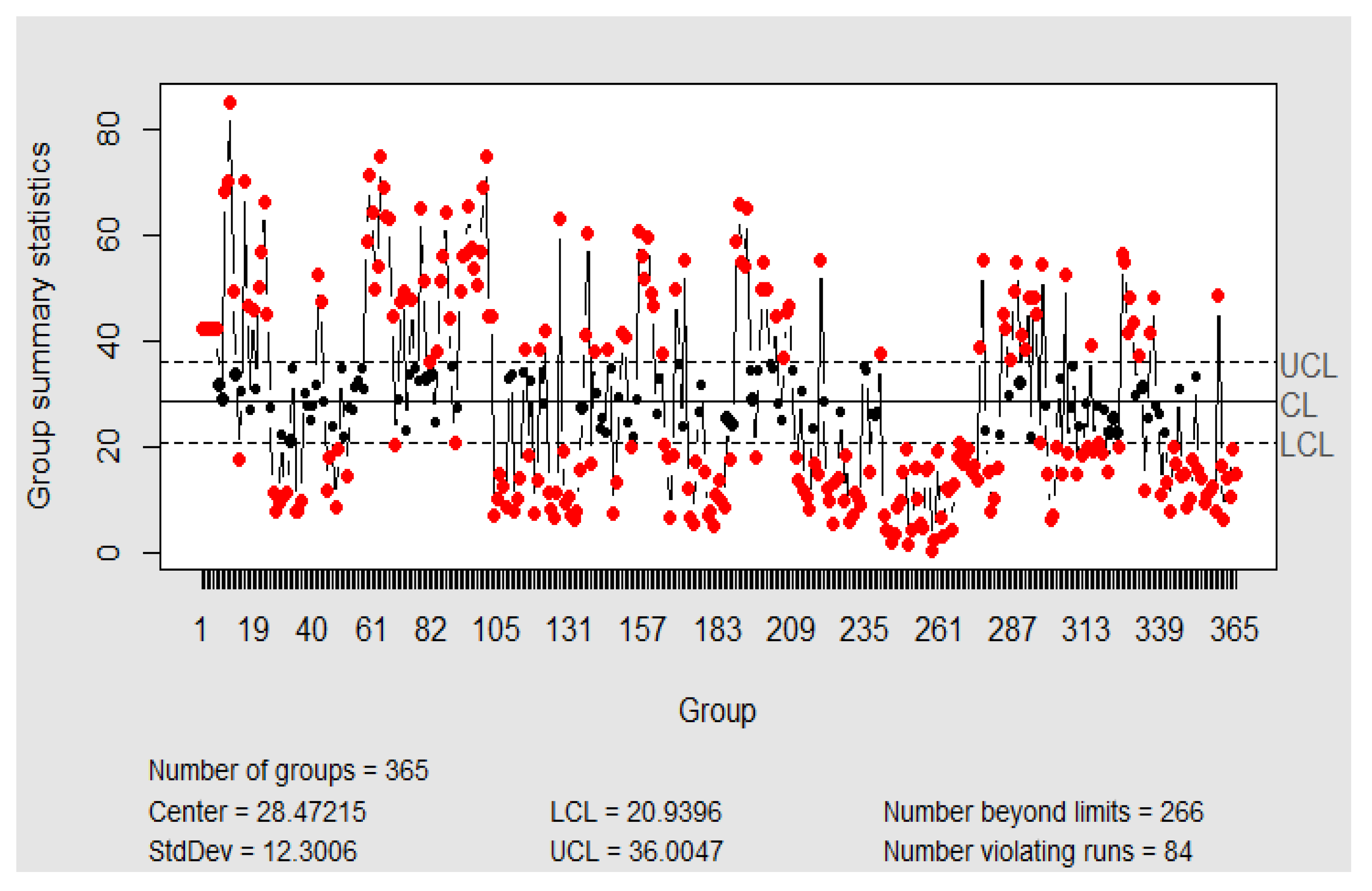
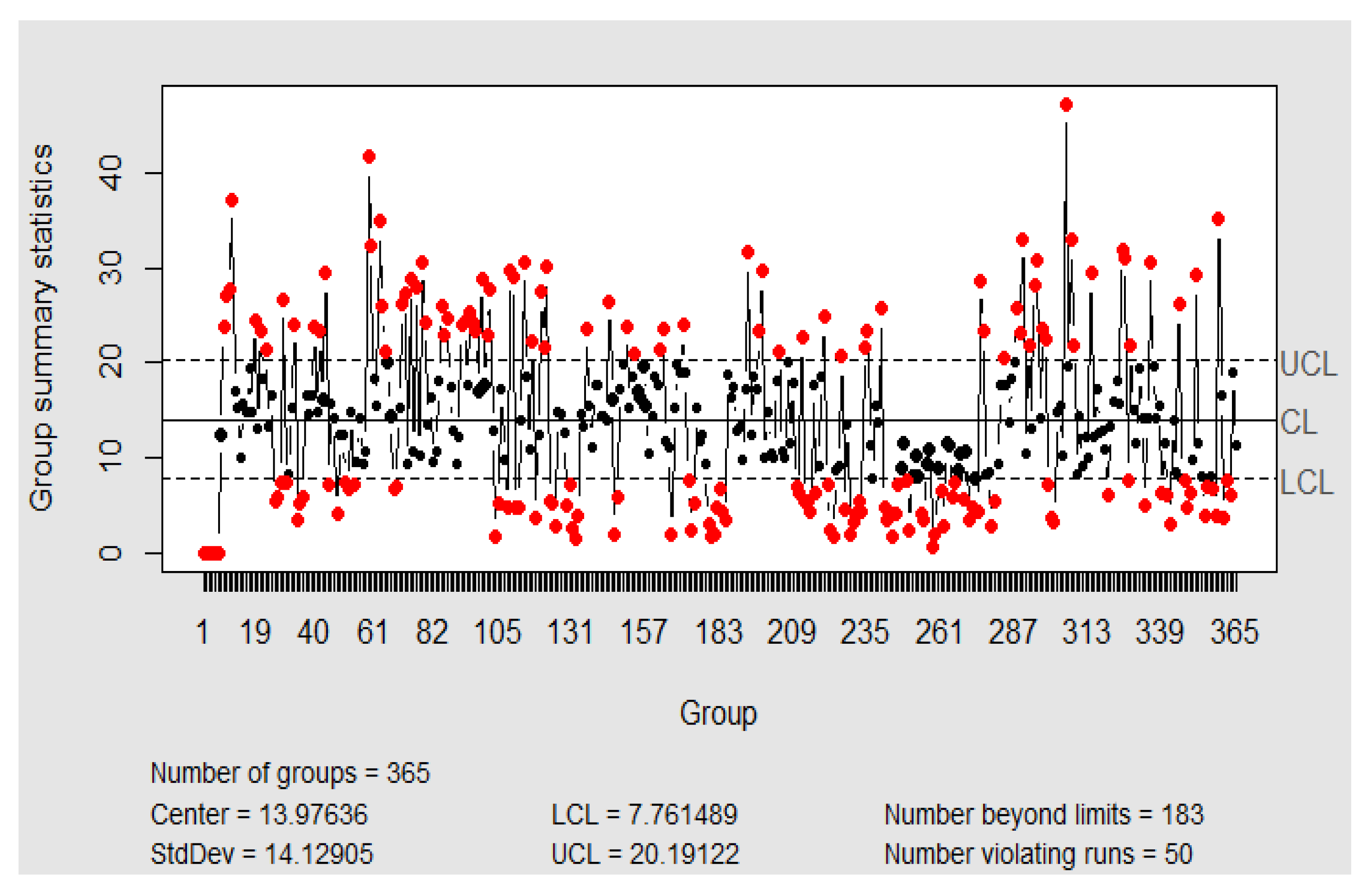
3.2.1. Control I-MR Charts with Individual Mean
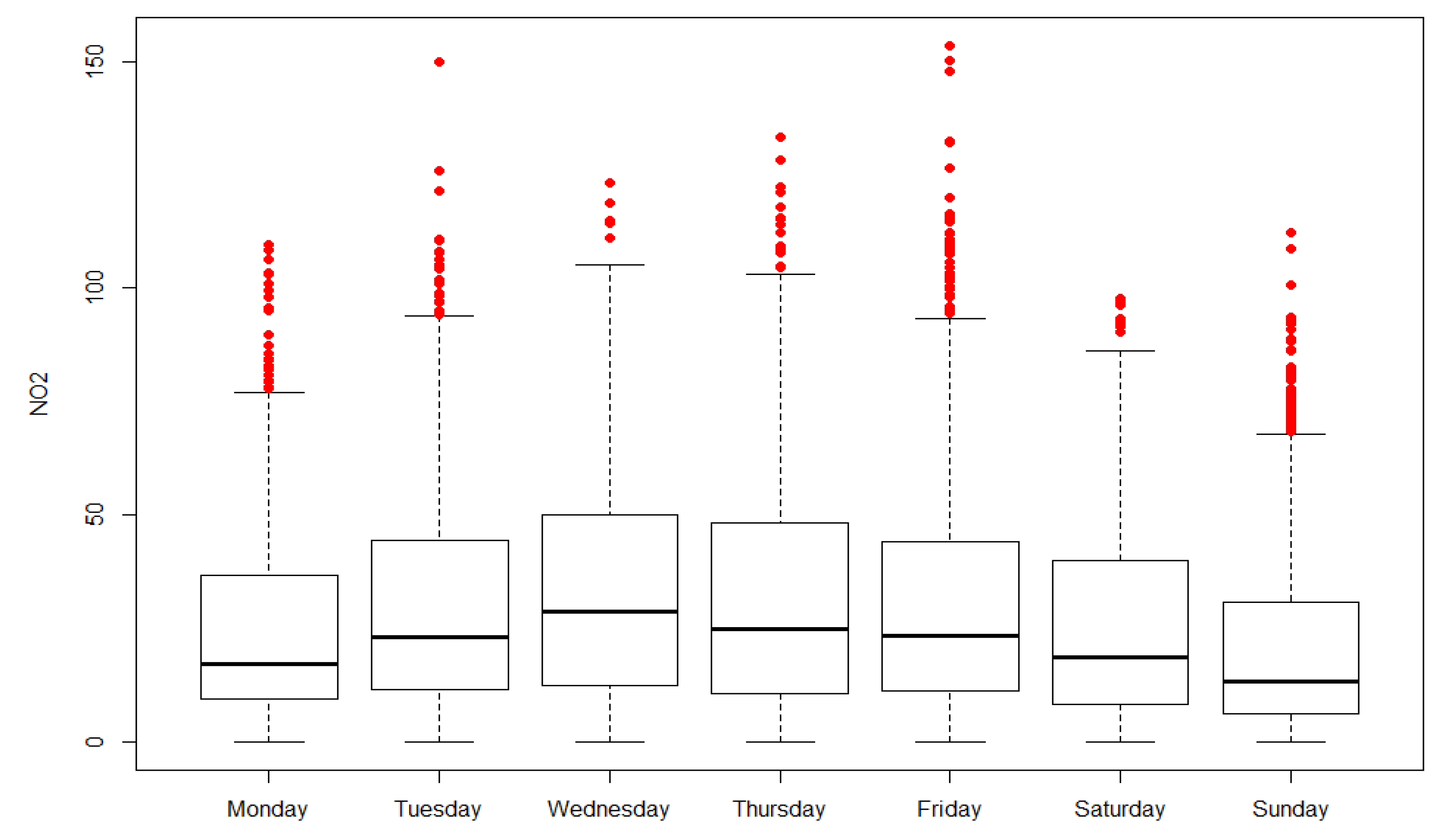
3.2.2. Control Charts with Daily Rational Subgroups
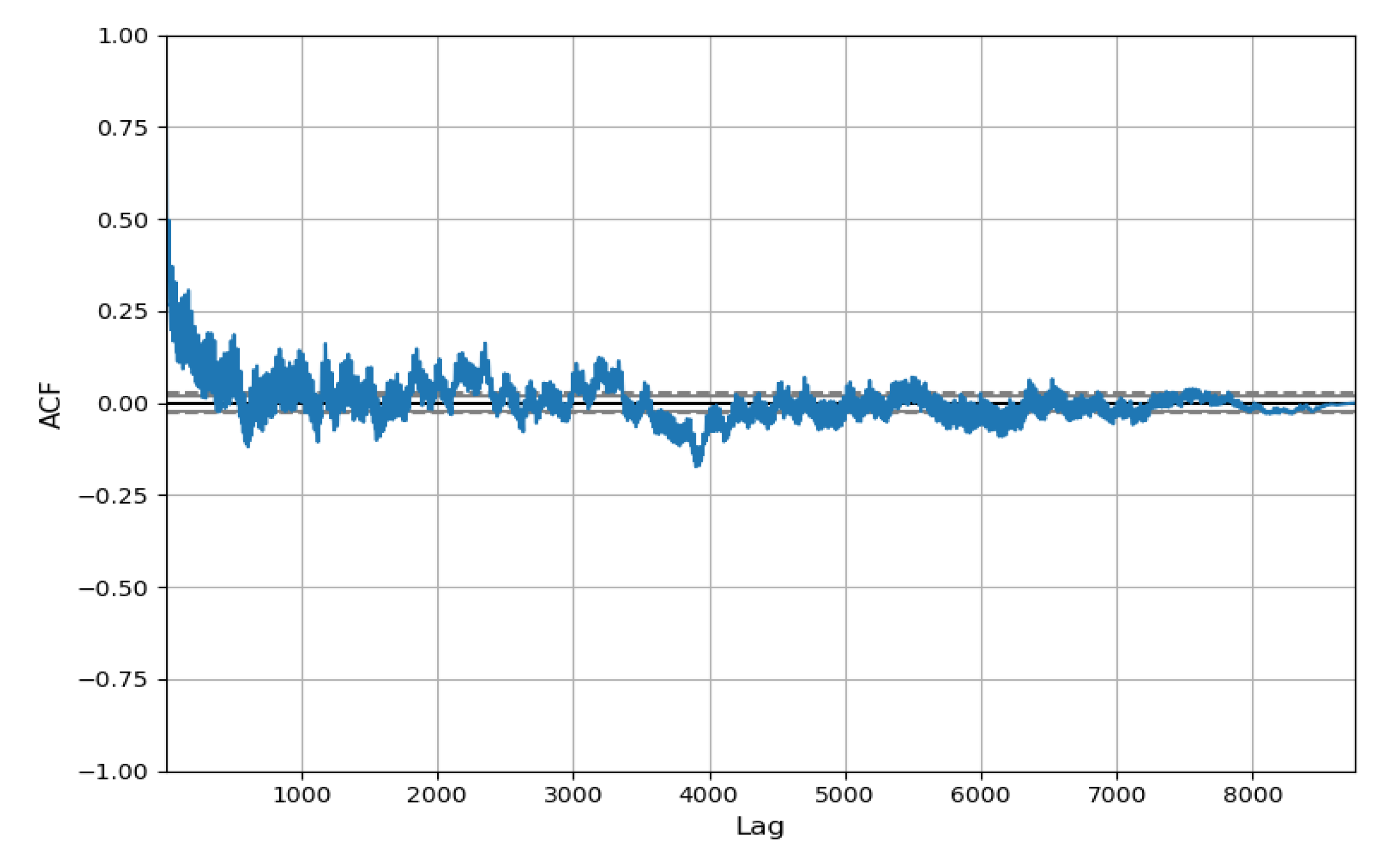
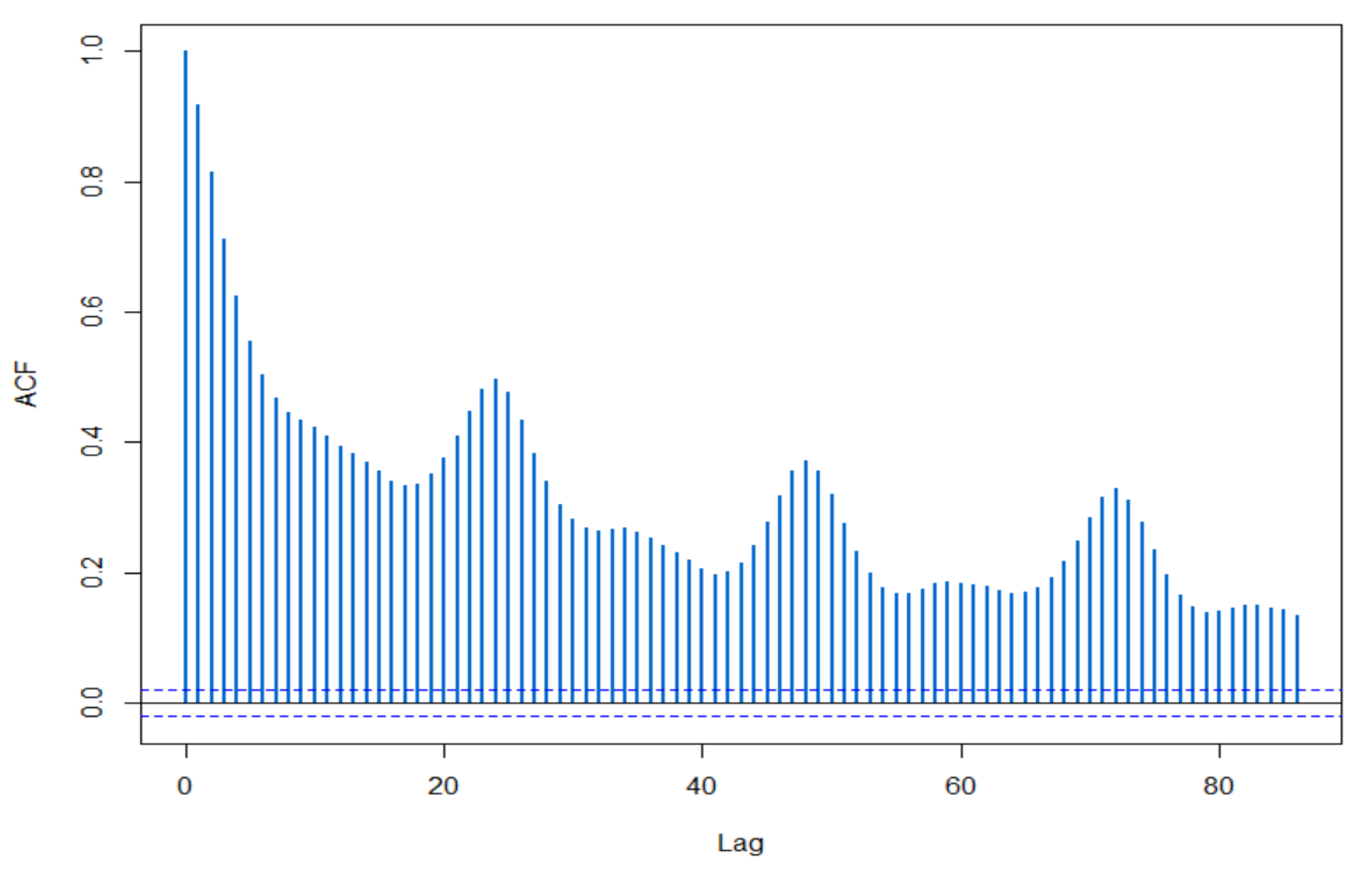
3.2.3. Trend Analysis
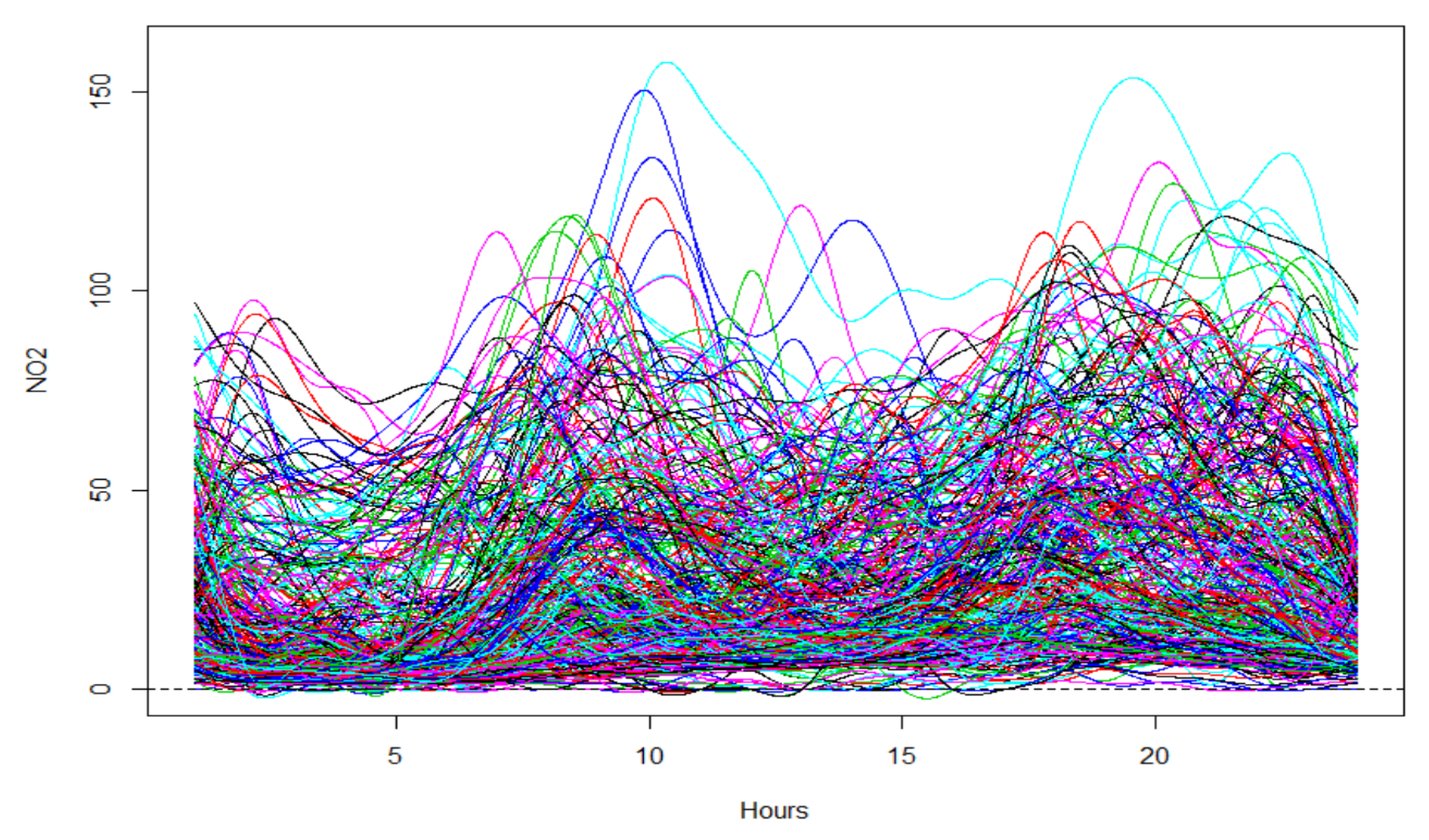
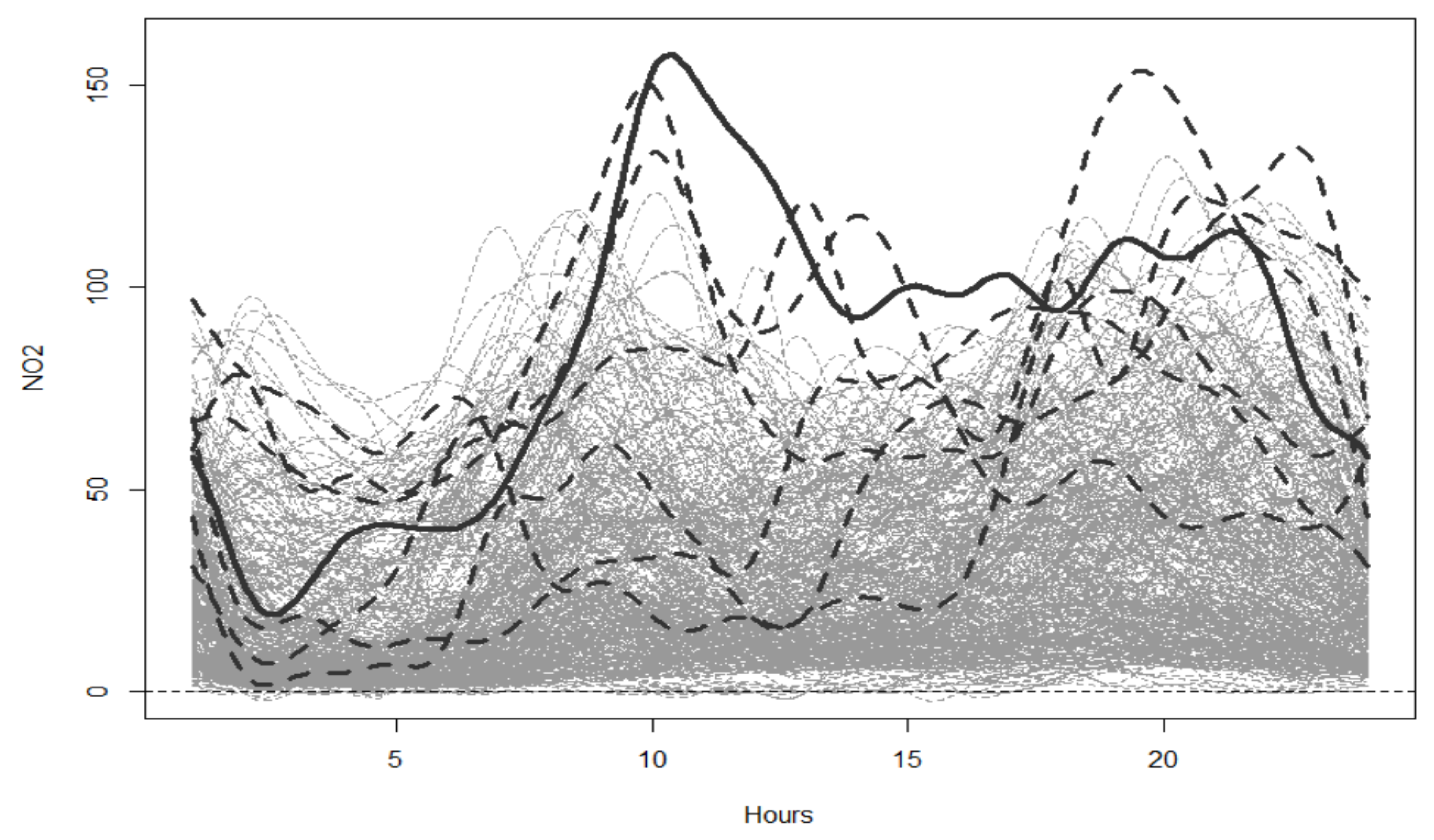
3.3. Functional Analysis of NO2 in Dublin
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- García Nieto, P. Parametric study of selective removal of atmospheric aerosol by coagulation, condensation and gravitational settling. Int. J. Environ. Health Res. 2001, 11, 151–162. [Google Scholar] [CrossRef] [PubMed]
- Akkoyunku, A.; Ertürk, F. Evaluation of air pollution trends in Istanbul. Int. J. Environ. Health Res. 2003, 18, 388–398. [Google Scholar]
- Karaca, F.; Alagha, O.; Ertürk, F. Statistical characterization of atmospheric PM10 and PM2.5 concentrations at a non-impacted suburban site of Istanbul, Turkey. Chemosphere 2005, 59, 183–190. [Google Scholar] [CrossRef] [PubMed]
- García Nieto, P. Study of the evolution of aerosol emissions from coal-fired power plants due to coagulation, condensation, and gravitational settling and health impact. J. Environ. Manag. 2006, 79, 372–382. [Google Scholar] [CrossRef] [PubMed]
- RCPCH. Every Breath We Take: The Lifelong Impact of Air Pollution; Royal College of Physicians: London, UK, 2016; Available online: https://www.rcplondon.ac.uk/projects/outputs/every-breath-we-take-lifelongimpact-air-pollution (accessed on 7 February 2020).
- WHO. Review of Evidence on Health Aspects of Air Pollution—REVIHAAP Project; World Health Organization: Geneva, Switzerland, 2013; Available online: http://www.euro.who.int/__data/assets/pdf_file/0004/193108/REVIHAAP-Final-technical-report.pdf (accessed on 7 February 2020).
- Kumar, P.; Druckman, A.; Gallagher, J.; Gatersleben, B.; Allison, S.; Eisenman, T.S.; Hoang, U.; Hama, S.; Tiwari, A.; Sharma, A.; et al. The nexus between air pollution, green infrastructure and human health. Environ. Int. 2019, 133, 105181. [Google Scholar] [CrossRef] [PubMed]
- EPA. United States Environmental Protection Agency. 2019. Available online: https://www.epa.gov/ (accessed on 19 December 2019).
- AQEG. Trends in Primary Nitrogen Dioxide in the UK; Air Quality Expert Group, 2007. Available online: https://uk-air.defra.gov.uk/assets/documents/reports/aqeg/primary-no-trends.pdf (accessed on 7 February 2020).
- EPA. Ireland’s Transboundary Gas Emissions; Environmental Protection Agency: Washington, DC, USA, 2018. Available online: http://www.epa.ie/pubs/reports/air/airemissions/Irelands%20Air%20Pollutant%20Emissions%202016.pdf (accessed on 7 February 2020).
- Costa, S.; Ferreira, J.; Silveira, C.; Costa, C.; Lopes, D.; Relvas, H.; Borrego, C.; Roebeling, P.; Miranda, A.I.; Teixeira, J.P. Integrating Health on Air Quality Assessment—Review Report on Health Risks of Two Major European Outdoor Air Pollutants: PM and NO2. J. Toxicol. Environ. Heal. Part B 2014, 17, 307–340. [Google Scholar] [CrossRef]
- Cooper, C.; Alley, F. Air Pollut. Control; Waveland Press: New York, NY, USA, 2002. [Google Scholar]
- Lutgens, F.; Tarbuck, E. The Atmosphere: An Introduction to Meteorology; Prentice Hall: New York, NY, USA, 2001. [Google Scholar]
- Jeanjean, A.; Gallagher, J.; Monks, P.; Leigh, R. Ranking current and prospective NO2 pollution mitigation strategies: An environmental and economic modelling investigation in Oxford Street, London. Environ. Pollut. 2017, 225, 587–597. [Google Scholar] [CrossRef] [Green Version]
- Cuevas, A.; Fraiman, R. A plug-in approach to support estimation. Ann. Stat. 1997, 25, 2300–2312. [Google Scholar]
- Matías, J.; Ordóñez, C.; Taboada, J.; Rivas, T. Functional support vector machines and generalized linear models for glacier geomorphology analysis. Int. J. Comput. Math. 2009, 86, 275–285. [Google Scholar]
- Martínez, J.; Garcia Nieto, P.; Alejano, L.; Reyes, A. Detection of outliers in gas emissions from urban areas using functional data analysis. J. Hazard. Mater. 2011, 186, 144–149. [Google Scholar]
- Martínez, J.; Saavedra, A.; García Nieto, P.; Piñeiro, J.; Iglesias, C.; Taboada, J.; Sancho, J.; Pastor, J. Air quality parameters outliers detection using functional data analysis in the Langreo urban area (Northern Spain). Appl. Math. Comput. 2014, 241, 1–10. [Google Scholar]
- Sancho, J.; Iglesias, C.; Piñeiro, J.; Martínez, J.; Pastor, J.; Araújo, M.; Taboada, J. Study of water quality in a spanish river based on statistical process control and functional data analysis. Math. Geosci. 2016, 48, 163–186. [Google Scholar]
- Dombeck, D.; Graziano, M.; Tank, D. Functional clustering of neurons in motor cortex determined by cellular resolution imaging in awake behaving mice. J. Neurosci. 2009, 29, 13751–13760. [Google Scholar]
- Wu, D.; Huang, S.; Xin, J. Dynamic compensation for an infrared thermometer sensor using least-squares support vector regression (LSSVR) based functional link artificial neural networks (FLANN). Meas. Sci. Technol. 2008, 19, 105202.1–105202.6. [Google Scholar]
- Ordoñez, C.; Martínez, J.; Cos Juez, J.; Sánchez Lasheras, F. Comparison of GPS observations made in a forestry setting using functional data analysis. Int. J. Comput. Math. 2011, 89, 402–408. [Google Scholar]
- Ordóñez, C.; Martínez, J.; Saavedra, A.; Mourelle, A. Intercomparison Exercise for Gases Emitted by a Cement Industry in Spain: A Functional Data Approach. J. Air Waste Manag. Assoc. (1995) 2011, 61, 135–141. [Google Scholar] [CrossRef] [Green Version]
- Sancho, J.; Pastor, J.; Martínez, J.; García, M. Evaluation of Harmonic Variability in Electrical Power Systems through Statistical Control of Quality and Functional Data Analysis. Procedia Eng. 2013, 63, 295–302. [Google Scholar] [CrossRef] [Green Version]
- Fraiman, R.; Muniz, R. Trimmed means for functional data. Test 2001, 10, 419–440. [Google Scholar]
- Piñeiro, J.; Martínez, J.; García Nieto, P.; Alonso, J.; Díaz, C.; Taboada, J. Analysis and detection of outliers in water quality parameters from different automated monitoring stations in the Miño river basin (NW Spain). Ecol. Eng. 2013, 60, 60–66. [Google Scholar]
- Sancho, J.; Martínez, J.; Pastor, J.; Taboada, J.; Piñeiro, J.; García Nieto, P. New methodology to determine air quality in urban areas based on runs rules for functional data. Atmos. Environ. 2014, 83, 185–192. [Google Scholar]
- Grubbs, F.E. Procedures for Detecting Outlying Observations in Samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Jäntschi, L. A test detecting the outliers for continuous distributions based on the cumulative distribution function of the data being tested. Symmetry 2019, 11, 835. [Google Scholar] [CrossRef] [Green Version]
- EPA. Air Quality in Ireland 2018; Environmental Protection Agency: Washington, DC, USA, 2019. Available online: http://www.epa.ie/pubs/reports/air/quality/Air%20Quality%20In%20Ireland%202018.pdf (accessed on 7 February 2020).
- EPA. Air Quality in Ireland 2013: Key Indicators of Ambient Air Quality; Environmental Protection Agency: Washington, DC, USA, 2014. Available online: https://www.epa.ie/pubs/reports/air/quality/Air%20Quality%20Report%202013.pdf (accessed on 7 February 2020).
- Romer, U. Weather Online(Ireland). 2013. Available online: https://www.weatheronline.co.uk/weather/maps/current?TYP=tmin&KEY=IE&LANG=en&ART=tabelle&JJ=xxxx&SORT=2&INT=24 (accessed on 19 December 2019).
- Carslaw, D.; Ropkins, K. Openair—An R package for air quality data analysis. Environ. Model. Softw. 2012, 27–28, 52–61. [Google Scholar]
- Piatesky-Shapiro, G.; Frawley, W. Knowledge Discovery in Databases; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Takeuchi, J.; Yamanishi, K. A unifying framework for detecting outliers and change points from time series. IEEE Trans. Knowl. Data Eng. 2006, 18, 482–492. [Google Scholar] [CrossRef]
- Sim, C.; Gan, F.; Chang, T. Outlier Labeling With Boxplot Procedures. J. Am. Stat. Assoc. 2005, 100, 642–652. [Google Scholar] [CrossRef]
- Montgomery, D. Design and Analysis of Experiments; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013; Chapter 1–2; pp. 1–65. [Google Scholar]
- Shewhart, W. Economic Control of Quality of Manufactured Product; Van Nostrand Company: New York, NY, USA, 1931. [Google Scholar]
- Chen, Y.K. An evolutionary economic-statistical design for VSIXcontrol charts under non-normality. J. Adv. Manuf. Technol. 2003, 22, 602–610. [Google Scholar]
- Freeman, J.; Modarres, R. Inverse Box-Cox: the power-normal distribution. Stat. Probab. Lett. 2006, 76, 764–772. [Google Scholar]
- Box, G.; Cox, D. An analysis of transformations. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1964, 26, 211–252. [Google Scholar]
- Grant, E.; Leavenworth, R. Statistical Quality Control; McGraw-Hill: New York, NY, USA, 1998. [Google Scholar]
- Champ, C.; Woodall, W. Exact results for Shewhart control charts with supplementary runs rules. Technometrics 1987, 29, 393–399. [Google Scholar]
- Zhang, M.; Lin, W.; Klein, S.; Bacmeister, J.; Bony, S.; Cederwall, R.; Del Genio, A.; Hack, J.; Loeb, N.; Lohmann, U.; et al. Comparing clouds and their seasonal variations in 10 atmospheric general circulation models with satellite measurements. J. Geophys. Res. 2005, 110. [Google Scholar] [CrossRef] [Green Version]
- Electric, W. Statistical Quality Control Handbook; AT&T Technologics: Indianapolis, Indiana, 1956. [Google Scholar]
- Ramsay, J.; Silverman, B. Functional Data Analysis; Springer: New York, NY, USA, 2005. [Google Scholar]
- Sánchez-Lasheras, F.; Ordóñez, C.; Garcia Nieto, P.J.; García-Gonzalo, E. Detection of outliers in pollutant emissions from the Soto de Ribera coal-fired plant using Functional Data Analysis: A case study in northern Spain. Proceedings 2018, 2, 1473. [Google Scholar] [CrossRef] [Green Version]
- Muñiz, C.D.; García Nieto, P.J.; Alonso Fernández, J.R.; Torres, J.V.; Taboada, J. Detection of outliers in water quality monitoring samples using functional data analysis in San Esteban estuary (Northern Spain). Sci. Total. Environ. 2012, 439, 54–61. [Google Scholar]
- Kamada, M.; Toraich, K.; Mori, R. Periodic spline orthonormal bases. J. Approx. Theory 1988, 55, 27–34. [Google Scholar]
- Febrero, M.; Galeano, P.; González-Manteiga, W. Outlier detection in functional data by depth measures, with application to identify abnormal NOx levels. Environmetrics 2008, 19, 331–345. [Google Scholar]
- Zuo, Y.; Serfling, R. General notions of statistical depth function. Ann. Stat. 2000, 28, 461–482. [Google Scholar]
- Cuevas, A.; Febrero, M.; Fraiman, R. On the use of the bootstrap for estimating functions with functional data. Comput. Stat. Data Anal. 2006, 51, 1063–1074. [Google Scholar]
- Cuevas, A. A partial overview of the theory of statistics with functional data. J. Stat. Plan. Inference 2014, 147, 1–23. [Google Scholar]
- Jäntschi, L.; Bolboacă, S.D. Computation of Probability Associated with Anderson-Darling Statistic. Mathematics 2018, 6, 88. [Google Scholar] [CrossRef] [Green Version]
- Jäntschi, L.; Bolboacă, S.D. Rarefaction on natural compound extracts diversity among genus. J. Comput. Sci. 2014, 5, 363–367. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- Van Rossum, G.; Drake, F.L., Jr. Python Reference Manual; Centrum voor Wiskunde en Informatica: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Cosma, C.; Suciu, I.; Jäntschi, L.; Bolboaca, S. Ion-Molecule Reactions and Chemical Composition of Emanated from Herculane Spa Geothermal Sources. Int. J. Mol. Sci. 2008, 9, 1024–1033. [Google Scholar] [CrossRef]
- Yu, G.; Zou, C.; Wang, Z. Outlier Detection in Functional Observations With Applications to Profile Monitoring. Technometrics 2012, 54, 308–318. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| max | 153.48 g/m | Q1 | 9.56 g/m |
| min | 0 g/m | Q2 | 20.61 g/m |
| mean | 28.47 g/m | Q3 | 42.33 g/m |
| mode | 42.33 g/m | IQR | 32.77 g/m |
| std | 23.91 g/m | var | 571.79g/m |
| n | 8760 |
| Nº | Date | Day | Lowest Tª | Average Lowest Tª | Sunshine Hours | Average Sunshine Hours | Precipitations |
|---|---|---|---|---|---|---|---|
| 10 | 10/01 | Thursday | −2.5 C | 2.6 C | 0 h | 1.2 h | 2 mm |
| 11 | 11/01 | Friday | −0.5 C | 2.6 C | 1 h | 1.2 h | 0.5 mm |
| 59 | 28/02 | Thursday | 1 C | 2 C | 0 h | 2.6 h | 0 mm |
| 60 | 01/03 | Friday | −3.1 C | 1.2 C | 3 h | 2.1 h | 0 mm |
| 64 | 5/03 | Tuesday | −3,8 C | 1.2 C | 5 h | 2.1 h | 0 mm |
| 78 | 19/03 | Tuesday | 0 C | 1.2 C | 0 h | 2.1 h | 5.6 mm |
| 122 | 02/05 | Thursday | −0.4 C | 6.3 C | 5 h | 6.3 h | 0 mm |
| 193 | 12/07 | Friday | 8.7 C | 11.9 C | 14 h | 7.7 h | 0 mm |
| 305 | 01/11 | Friday | 2 C | 4.2 C | 4.20 h | 2.7 h | 0 mm |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez Torres, J.; Pastor Pérez, J.; Sancho Val, J.; McNabola, A.; Martínez Comesaña, M.; Gallagher, J. A Functional Data Analysis Approach for the Detection of Air Pollution Episodes and Outliers: A Case Study in Dublin, Ireland. Mathematics 2020, 8, 225. https://doi.org/10.3390/math8020225
Martínez Torres J, Pastor Pérez J, Sancho Val J, McNabola A, Martínez Comesaña M, Gallagher J. A Functional Data Analysis Approach for the Detection of Air Pollution Episodes and Outliers: A Case Study in Dublin, Ireland. Mathematics. 2020; 8(2):225. https://doi.org/10.3390/math8020225
Chicago/Turabian StyleMartínez Torres, Javier, Jorge Pastor Pérez, Joaquín Sancho Val, Aonghus McNabola, Miguel Martínez Comesaña, and John Gallagher. 2020. "A Functional Data Analysis Approach for the Detection of Air Pollution Episodes and Outliers: A Case Study in Dublin, Ireland" Mathematics 8, no. 2: 225. https://doi.org/10.3390/math8020225
APA StyleMartínez Torres, J., Pastor Pérez, J., Sancho Val, J., McNabola, A., Martínez Comesaña, M., & Gallagher, J. (2020). A Functional Data Analysis Approach for the Detection of Air Pollution Episodes and Outliers: A Case Study in Dublin, Ireland. Mathematics, 8(2), 225. https://doi.org/10.3390/math8020225