Community Detection of Multi-Layer Attributed Networks via Penalized Alternating Factorization


Abstract
:1. Introduction
2. Problem Formulation
2.1. Single Network
2.2. Multi-Layer Attributed Network
3. Learning Algorithm
| Algorithm 1 Penalized Alternating Factorization (PAF) Algorithm. |
|
4. Theoretical Analysis
5. Numerical Study
- I
- The adjacency matrix A is generated from the undirected SBM with the parametersEach row of the attribution matrix is independently generated from the multivariate normal distribution , where the kth element of is 1 and the remaining element is 0, and .
- II
- The same as Setting I, except that the undirected SBM is replaced by directed SBM.
- III
- The adjacent matrices are generated independently from the undirected multi-layer SBM with common community labels, where the parameters are set as follows,Each row of the attribution matrix is independently generated from the multivariate normal distribution , where the kth element of is 1 and the remaining elements are 0, and .
- IV
- The same as Setting III, except that the undirected multi-layer SBM model is replaced by directed multi-layer SBM.
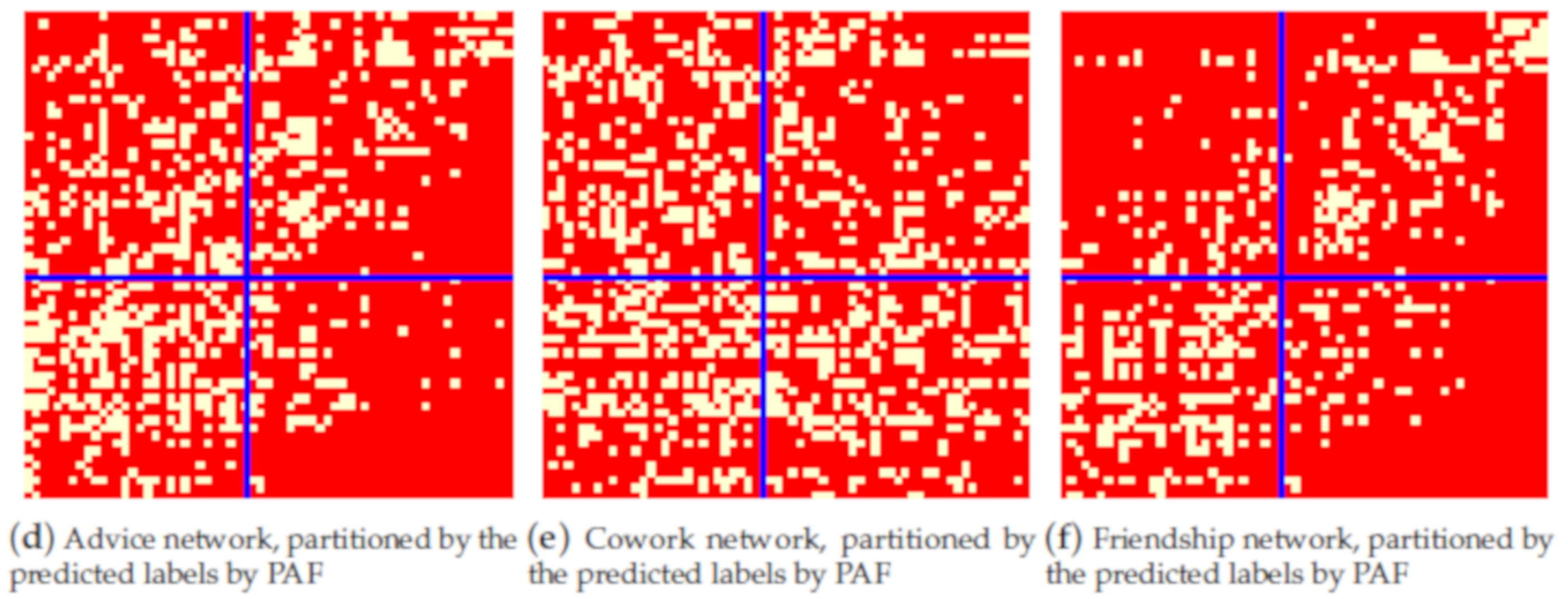
6. Empirical Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ANMF | asymmetric non-negative matrix factorization |
| KL | Kurdyka-Łojasiewicz |
| NMF | non-negative matrix factorization |
| NMI | normalized mutual information |
| PAF | penalized alternative factorization |
| SBM | stochastic block model |
| SCP | spectral clustering with perturbations |
Appendix A. Proof of Some Theoretical Results
Appendix A.1. Proof of Proposition 1
Appendix A.2. Proof of Proposition 2
Appendix A.3. Proof of Proposition 3
Appendix A.4. Proof of Theorem 1
- Sufficient decrease property:
- A subgradient lower bound for the iteration gap:where is the subderivative of the function and
Appendix B. Some Additional Numerical Results
- V
- The adjacent matrices are generated independently from the undirected and directed multi-layer SBMs, respectively, with common community labels, where the parameters are set as follows,Each row of the attribution matrix is independently generated from the multivariate normal distribution , where the kth element of is 1 and the remaining elements are 0, and .

References
- Newman, M.E.J. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Wasserman, S. Advances in Social Network Analysis: Research in the Social and Behavioral Sciences; Sage: Thousand Oaks, CA, USA, 1994. [Google Scholar]
- Bader, G.D.; Hogue, C.W.V. An automated method for finding molecular complexes in large protein interaction networks. BMC Bioinform. 2003, 4, 2. [Google Scholar] [CrossRef] [Green Version]
- Sporns, O. Networks of the Brain; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Rogers, E.M.; Kincaid, D.L. Communication Networks: Toward a New Paradigm for Research; Free Press: New York, NY, USA, 1981; Volume 11, p. 2. [Google Scholar]
- Schlitt, T.; Brazma, A. Current approaches to gene regulatory network modelling. BMC Bioinform. 2007, 8, S9. [Google Scholar] [CrossRef] [Green Version]
- Mcpherson, M.; Smithlovin, L.; Cook, J.M. Birds of a feather: Homophily in social networks. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef] [Green Version]
- Moody, J.; White, D.R. Structural cohesion and embeddedness: A hierarchical concept of social groups. Am. Sociol. Rev. 2003, 103–127. [Google Scholar] [CrossRef] [Green Version]
- Flake, G.W.; Lawrence, S.; Giles, C.L. Efficient identification of web communities. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 150–160. [Google Scholar]
- Sporns, O.; Betzel, R.F. Modular brain networks. Annu. Rev. Psychol. 2016, 67, 613–640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spirin, V.; Mirny, L.A. Protein complexes and functional modules in molecular networks. Proc. Natil. Acad. Sci. USA 2003, 100, 12123–12128. [Google Scholar] [CrossRef] [Green Version]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 10, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef] [Green Version]
- Khan, B.S.; Niazi, M.A. Network community detection: A review and visual survey. arXiv 2017, arXiv:1708.00977. [Google Scholar]
- Porter, M.A.; Onnela, J.-P.; Mucha, P.J. Communities in networks. Not. AMS 2009, 56, 1082–1097. [Google Scholar]
- Schaub, M.T.; Delvenne, J.-C.; Rosvall, M.; Lambiotte, R. The many facets of community detection in complex networks. Appl. Netw. Sci. 2017, 2, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M.E.J. Detecting community structure in networks. Eur. Phys. J. B 2004, 38, 321–330. [Google Scholar] [CrossRef]
- Hespanha, J.P. An Efficient Matlab Algorithm for Graph Partitioning; University of California: Santa Barbara, CA, USA, 2004. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, J. Fast community detection by score. Ann. Stat. 2015, 43, 57–89. [Google Scholar] [CrossRef]
- Lei, J.; Rinaldo, A. Consistency of spectral clustering in stochastic block models. Ann. Stat. 2015, 43, 215–237. [Google Scholar] [CrossRef]
- McSherry, F. Spectral partitioning of random graphs. In Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science, Newport Beach, CA, USA, 8–11 October 2001; pp. 529–537. [Google Scholar]
- Rohe, K.; Chatterjee, S.; Yu, B. Spectral clustering and the high-dimensional stochastic blockmodel. Ann. Stat. 2011, 39, 1878–1915. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.T.; Li, X. Robust and computationally feasible community detection in the presence of arbitrary outlier nodes. Ann. Stat. 2015, 43, 1027–1059. [Google Scholar] [CrossRef] [Green Version]
- Hajek, B.; Wu, Y.; Xu, J. Achieving exact cluster recovery threshold via semidefinite programming: Extensions. IEEE Trans. Inf. Theory 2016, 62, 5918–5937. [Google Scholar] [CrossRef] [Green Version]
- Le, C.M.; Levina, E.; Vershynin, R. Optimization via low-rank approximation for community detection in networks. Ann. Stat. 2016, 44, 373–400. [Google Scholar] [CrossRef]
- Wang, F.; Li, T.; Wang, X.; Zhu, S.; Ding, C. Community discovery using non-negative matrix factorization. Data Min. Knowl. Discov. 2011, 22, 493–521. [Google Scholar] [CrossRef]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic block models: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Karrer, B.; Newman, M.E.J. Stochastic blockmodels and community structure in networks. Phys. Rev. E 2011, 83, 016107. [Google Scholar] [CrossRef] [Green Version]
- Hoff, P.D. Modeling homophily and stochastic equivalence in symmetric relational data. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2008; pp. 657–664. [Google Scholar]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amini, A.A.; Chen, A.; Bickel, P.J.; Levina, E. Pseudo-likelihood methods for community detection in large sparse networks. Ann. Stat. 2013, 41, 2097–2122. [Google Scholar] [CrossRef]
- Qin, T.; Rohe, K. Regularized spectral clustering under the degree-corrected stochastic blockmodel. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2013; pp. 3120–3128. [Google Scholar]
- Hoff, P.D. Random effects models for network data. In Dynamic Social Network Modeling and Analysis Workshop Summary and Papers; National Academies Press: Washington, DC, USA, 2003. [Google Scholar]
- Zanghi, H.; Volant, S.; Ambroise, C. Clustering based on random graph model embedding vertex features. Pattern Recogn. Lett. 2010, 31, 830–836. [Google Scholar] [CrossRef] [Green Version]
- Handcock, M.S.; Raftery, A.E.; Tantrum, J.M. Model-based clustering for social networks. J. R. Stat. Soc. Ser. A (Stat. Soc.) 2007, 170, 301–354. [Google Scholar] [CrossRef] [Green Version]
- Yang, T.; Jin, R.; Chi, Y.; Zhu, S. Combining link and content for community detection: A discriminative approach. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 927–936. [Google Scholar]
- Kim, M.; Leskovec, L.J. Latent multi-group membership graph model. arXiv 2012, arXiv:1205.4546. [Google Scholar]
- Leskovec, J.; Mcauley, J.J. Learning to discover social circles in ego networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2012; pp. 539–547. [Google Scholar]
- Yang, J.; McAuley, J.; Leskovec, J. Community detection in networks with node attributes. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1151–1156. [Google Scholar]
- Xu, Z.; Ke, Y.; Wang, Y.; Cheng, H.; Cheng, J. A model-based approach to attributed graph clustering. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 505–516. [Google Scholar]
- Hoang, T.-A.; Lim, E.-P. On joint modeling of topical communities and personal interest in microblogs. In International Conference on Social Informatics; Springer: Cham, Switzerland, 2014; pp. 1–16. [Google Scholar]
- Newman, M.E.J.; Clauset, A. Structure and inference in annotated networks. Nat. Commun. 2016, 7, 11863. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Levina, E.; Zhu, J. Community detection in networks with node features. Electron. J. Stat. 2016, 10, 3153–3178. [Google Scholar] [CrossRef]
- Boorman, S.A.; White, H.C. Social structure from multiple networks. ii. role structures. Am. J. Sociol. 1976, 81, 1384–1446. [Google Scholar] [CrossRef]
- Breiger, R.L. Social structure from multiple networks. Am. J. Sociol. 1976, 81, 730–780. [Google Scholar]
- Cheng, W.; Zhang, X.; Guo, Z.; Wu, Y.; Sullivan, P.F.; Wang, W. Flexible and robust co-regularized multi-domain graph clustering. Knowl. Discov. Data Min. 2013, 320–328. [Google Scholar]
- Boccaletti, S.; Bianconi, G.; Criado, R.; DelGenio, C.I.; Gómez-Gardenes, J.; Romance, M.; Sendina-Nadal, I.; Wang, Z.; Zanin, M. The structure and dynamics of multilayer networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef] [Green Version]
- Kivelä, M.; Arenas, A.; Barthelemy, M.; Gleeson, J.P.; Moreno, Y.; Porter, M.A. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar]
- Matias, C.; Miele, V. Statistical clustering of temporal networks through a dynamic stochastic block model. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2017, 79, 1119–1141. [Google Scholar] [CrossRef]
- Cardillo, A.; Gómez-Gardenes, J.; Zanin, M.; Romance, M.; Papo, D.; DelPozo, F.; Boccaletti, S. Emergence of network features from multiplexity. Sci. Rep. 2013, 3, 1344. [Google Scholar] [CrossRef] [Green Version]
- Fienberg, S.E.; Meyer, M.M.; Wasserman, S.S. Analyzing Data from Multivariate Directed Graphs: An Application to Social Networks; Technical Report; Department of Statistics, Carnegie Mellon University: Pittsburgh, PA, USA, 1980. [Google Scholar]
- Fienberg, S.E.; Meyer, M.M.; Wasserman, S.S. Statistical analysis of multiple sociometric relations. J. Am. Stat. Assoc. 1985, 80, 51–67. [Google Scholar] [CrossRef]
- Ferriani, S.; Fonti, F.; Corrado, R. The social and economic bases of network multiplexity: Exploring the emergence of multiplex ties. Strateg. Organ. 2013, 11, 7–34. [Google Scholar] [CrossRef]
- Yan, T.; Jiang, B.; Fienberg, E.S.; Leng, C. Statistical inference in a directed network model with covariates. J. Am. Stat. Assoc. 2019, 114, 857–868. [Google Scholar] [CrossRef] [Green Version]
- Lazega, E. The Collegial Phenomenon: The Social Mechanisms of Cooperation among Peers in a Corporate Law Partnership; Oxford University Press on Demand: Oxfor, UK, 2001. [Google Scholar]
- Attouch, H.; Bolte, J.; Svaiter, B.F. Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized gauss-seidel methods. Math. Programm. 2013, 137, 91–129. [Google Scholar] [CrossRef]
- Bolte, J.; Sabach, S.; Teboulle, M. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Programm. 2014, 146, 459–494. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NMI |
|---|---|
| JCDC, | 0.54 |
| JCDC, | 0.50 |
| SCP | 0.44 |
| k-means | 0.44 |
| CASC | 0.49 |
| CESNA | 0.07 |
| BAGC | 0.20 |
| PAF | 0.58 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, J.; Liu, B. Community Detection of Multi-Layer Attributed Networks via Penalized Alternating Factorization. Mathematics 2020, 8, 239. https://doi.org/10.3390/math8020239
Liu J, Wang J, Liu B. Community Detection of Multi-Layer Attributed Networks via Penalized Alternating Factorization. Mathematics. 2020; 8(2):239. https://doi.org/10.3390/math8020239
Chicago/Turabian StyleLiu, Jun, Jiangzhou Wang, and Binghui Liu. 2020. "Community Detection of Multi-Layer Attributed Networks via Penalized Alternating Factorization" Mathematics 8, no. 2: 239. https://doi.org/10.3390/math8020239
APA StyleLiu, J., Wang, J., & Liu, B. (2020). Community Detection of Multi-Layer Attributed Networks via Penalized Alternating Factorization. Mathematics, 8(2), 239. https://doi.org/10.3390/math8020239