1. Introduction
Combinatorial optimization is an important branch of operations research. It refers to solving problems of variable combinations by minimizing (or maximizing) an objective function under given constraints, and is based on the research of mathematical methods to find optimal arrangements, groupings, orderings, or screenings of discrete events. As a research hot-spot in combinatorial optimization, the Max-cut problem is one of the 21 typical non-deterministic polynomial (NP)-complete problems proposed by Richard M. Karp [
1]. It refers to obtaining a maximum segmentation for a given directed graph, such that the sum of the weights across all edges of two cutsets is maximized [
2]. The Max-cut problem has a wide range of applications in engineering problems, such as Very Large Scale Integration (VLSI) circuit design, statistical physics, image processing, and communications network design [
3]. As a solution of the Max-cut problem can be used to measure the robustness of a network [
4] and as a standard for network classification [
5], it can also be applied to social networks.
It has been discovered that many classic combinatorial optimization problems derived from engineering, economics, and other fields are NP-hard. The Max-cut problem concerned in this paper is among these problems. For combinatorial optimization problems, algorithms can be roughly divided into two categories: one is represented by exact solution approaches, including enumeration methods [
6] and branch and bound methods [
7], etc. The other category is represented by heuristic algorithms including genetic algorithms, ant colony algorithms, simulated annealing algorithms, neural networks, Lin–Kernighan Heuristic (LKH) algorithms, and so on [
8]. However, there is no polynomial time solvable algorithm to find a global optimal solution for NP-hard problems. Compared with the exact approach, heuristic algorithms are able to deal with large-scale problems efficiently. They have certain advantages in computing efficiency and can be applied to solving large-scale problems with huge amount of variables. In order to solve the Max-cut problem, a large number of heuristic algorithms have been proposed, such as evolutionary algorithms and ant colony algorithms. However, for these algorithms, the most obvious disadvantage of them is that they are easy to fall into local optima. For this reason, more and more experts have begun working on the research and innovation of some novel and effective algorithms for large-scale Max-cut problems.
Deep learning is a research field which has developed very rapidly in recent years, achieving great success in many sub-fields of artificial intelligence. From its root, deep learning is a sub-problem of machine learning. Its main purpose is to automatically learn effective feature representations from a large amount of data, such that it can better solve the credit assignment problem (CAP) [
9]; that is, the contribution or influence of different components in a system or their parameters to the output of the final system. The emergence of deep neural networks has provided the possibility for solving large-scale combinatorial optimization problems. In recent years, with the development of the combination of deep neural networks and operations research for large-scale combinatorial optimization problems, scholars have explored how to apply deep neural networks in these fields, and have achieved certain results. The related research has mainly focused on the algorithm design for combinatorial optimization problems based on pointer networks. Vinyals used the attention mechanism [
10] to integrate a pointer structure into the sequence-to-sequence model, thus creating the pointer network. Bello improved the pointer network structure and used a strategy gradient algorithm combined with time-series difference learning to train the pointer network in reinforcement learning to solve the combinatorial optimization problem [
11]. Mirhoseini removed the coding part of a recurrent neural network (RNN) and used the embedded input to replace the hidden state of the RNN. With this modification, the computational complexity was greatly reduced and the efficiency of the model was improved [
12]. In Reference [
13], a purely data-driven method to obtain approximate solutions of NP-hard problems was proposed. In Reference [
14], a pointer network was used to establish a flight decision prediction model. Khalil solved classical combinatorial optimization problems by Q-learning [
15]. The pointer network model has also been used, in Reference [
16], to solve the weightless Max-cut problem. Similarly, solved the unconstrained boolean quadratic programming problem (UBQP) through the pointer network [
17].
The section arrangement of this paper is as follows.
Section 2 mainly introduces the Max-cut problem and the method for generating its benchmark.
Section 3 demonstrates the pointer network model, including the Long Short-Term Memory network and Encoder–Decoder.
Section 4 introduces two ways to train the pointer network model to solve the Max-cut problem, namely supervised learning and reinforcement learning.
Section 5 illustrates the details of the experimental procedure and the results.
Section 6 provides the conclusions.
2. Motivation and Data Set Structure
2.1. Unified Model of the Max-Cut Problem
The definition of the Max-cut problem is given as follows.
An undirected graph
consists of a set of vertices
V and a set of edges
E, where
is its set of vertices, and
is its set of edges, and
is the weight on the edge connecting vertex
i and vertex
j. For any proper subset
S of the vertex set
V, let:
where
is a set of edges, one end of which belongs to
S and the other end belongs to
. Then, the cut
determined by
S is:
In simple terms, the Max-cut problem is to find a segmentation of a vertex set V, where the maximum weight of the edges is segmented.
2.2. Benchmark Generator of the Max-Cut Problem
When applying deep learning to train and solve the Max-cut problem, whether supervised learning or reinforcement learning, a large number of training samples are necessary. The method of data set generation introduced here is to transform the {−1,1} quadratic programming problem into the Max-cut problem.
First of all, the benchmark generator method for the boolean quadratic programming (BQP) problem, proposed by Michael X. Zhou [
18], is used to generate random {−1,1} quadratic programming problems, which can be solved in polynomial time. Next, inspired by [
19], we transform the results of the previous step into solutions of the Max-cut problem. The specific implementation is described below.
Michael X. Zhou transformed the quadratic programming problem shown by Equation (
3) into the dual problem shown by Equation (
4) through the Lagrangian dual method.
where
is a given indefinite matrix, and
is a given non-zero vector.
The dual problem is described as follows:
Then, according to the paper [
19], the solution of the {−1,1} quadratic programming problem can be transformed into the solution of the Max-cut problem.
The integer programming for the Max-cut problem is given by:
where
i in
represents the vertex
i, and
and 1 represent the values of the two sets. If
is equal to 1 and the vertices of edge
are in the same set, then
is not a cut edge; if
is equal to
and the vertices of the edge
are not in the same set, then
is the cut edge. If
is a cut edge,
is equal to 1; if
is not a cut edge,
is equal to 0. Thus, the objective function represents the sum of the weights of the cut edges of the Max-cut. Define
, and the weight of the cut is
.
The pseudocode for generating the benchmark of the Max-cut problem is shown in Algorithm 1, where the parameter
is used to control the value range of the elements in matrix
Q.
| Algorithm 1 A benchmark generator for the Max-cut problem |
| Input: Dimension: n; ; |
| Output: Matrix: Q; Vector: x |
- 1:
Randomly generate an n-dimensional matrix that conforms to the standard normal distribution to obtain Q; - 2:
; - 3:
Convert Q to a symmetric matrix with ; - 4:
Generate random numbers in the range (0,1) of n rows and 1 column as a vector x; - 5:
; - 6:
Take the absolute value of Q and sum it over the rows, assigning the result to ; - 7:
Place the value of the vector on the main diagonal of the square matrix in order, and let the values of (except the main diagonal) be zero. - 8:
; - 9:
Set an additional variable , , and ; - 10:
Update Q: ; - 11:
Set an additional variable , and let ; - 12:
Update x: .
|
This method for obtaining Max-cut benchmark data sets effectively solves the difficulty in training the network to solve the Max-cut problem model when lacking a large number of training samples. However, there is a common defect in this method: in the training set obtained using the dual problem to deduce the solution of the original problem, its data samples obey certain rules. This may lead to difficulty in learning the general rule of the Max-cut problem when training with the method by deep learning.
Therefore, in addition to the above method, we consider using the benchmark generator in the Biq Mac Library to solve the Max-cut problem. The Biq Mac Library offers a collection of Max-cut instances. Biq Mac is a branch and bound code based on semi-definite programming (SDP). The dimension of the problems (i.e., number of variables or number of vertices in the graph) ranges from 60–100. These instances are mainly used to test the pointer network model for the Max-cut problem.
3. Models
3.1. Long Short-Term Memory
It is difficult for traditional neural networks to classify subsequent events by using previous event information. However, an RNN can continuously operate information in a cyclic manner to ensure that the information persists, thereby effectively processing time-series data of any length. Given an input sequence
, the RNN updates the activity value
of the hidden layer with feedback and calculates the output sequence
using the following equations:
As long as the alignment between input and output is known in advance, an RNN can easily map sequences to sequences. However, the RNN cannot solve the problem when the input and output sequences have different lengths or have complex and non-monotonic relationships [
20]. In addition, when the input sequence is long, the problem of gradient explosion and disappearance will occur [
21]; which is also known as the long-range dependence problem. In order to solve these problems, many improvements have been made to RNNs; the most effective way, thus far, is to use a gating mechanism.
A long short-term memory (LSTM) network [
22] is a variant of RNN, which is an outstanding embodiment of RNN based on the gating mechanism.
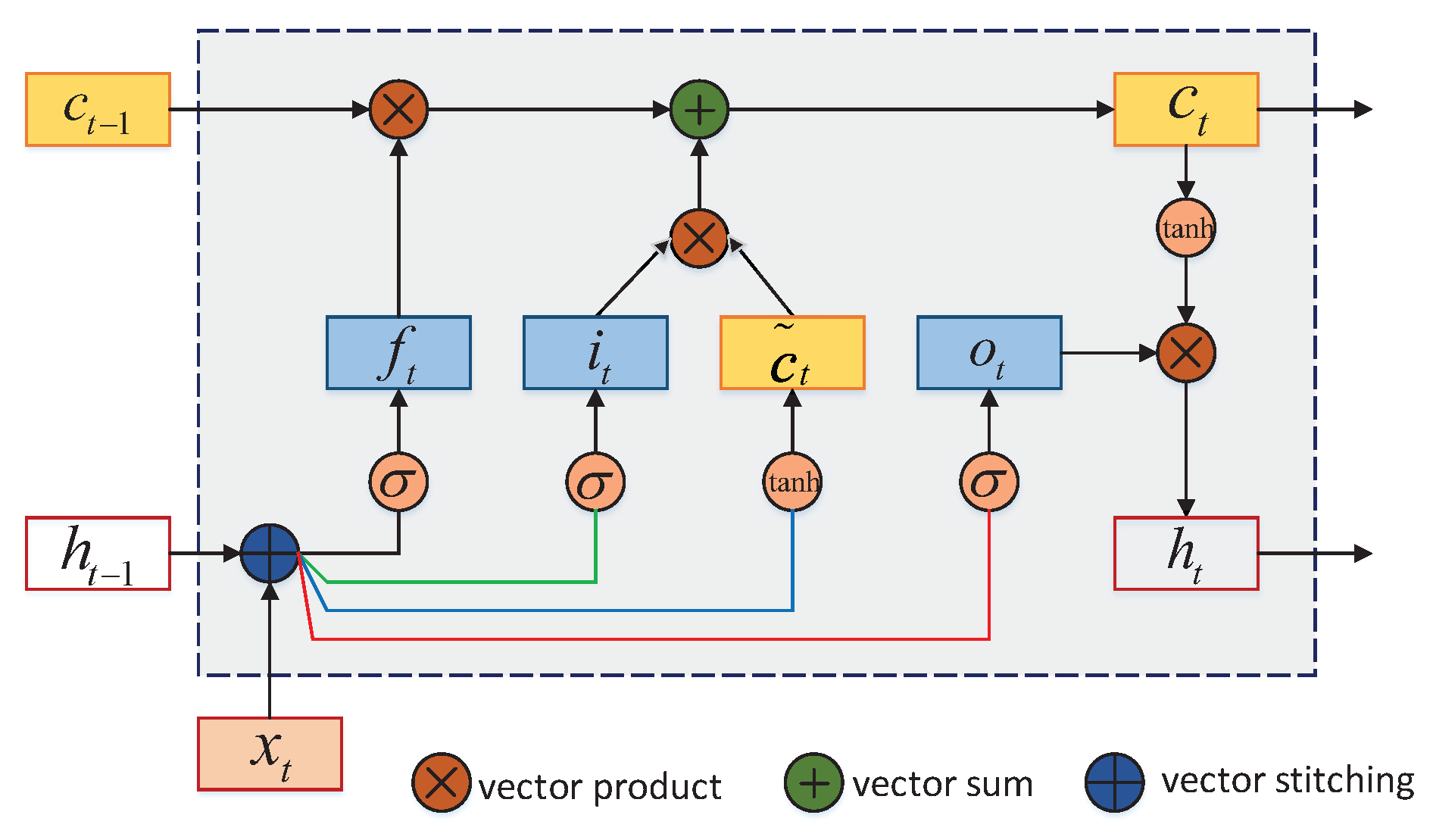
Figure 1 shows the structure of the loop unit of a LSTM. By applying the LSTM loop unit of the gating mechanism, the entire network can establish long-term timing dependencies to better control the path of information transmission. The equations of the LSTM model can be briefly described as:
where
is the input at the current time;
and
are the network parameters;
is the Logistic function, with output interval
;
is the external state at the previous time; ⊙ is the product of vector elements;
is the memory unit at the previous moment; and
is the candidate state obtained by the non-linear function. At each time
t, the internal state
of the LSTM records historical information up to the current time. The three gates used to control the path of information transmission are
,
, and
. The functions of three gates are:
The forget gate controls how much information the previous state needs to forget;
The input gate controls how much information the candidate state needs to be saved at the current moment; and
The output gate controls how much information the internal state of the current moment needs to be output to the external state .
In our algorithm, the purpose of the LSTM is to estimate the conditional probability
, where
is the input sequence,
is the corresponding output sequence, and the length
may be different from
T. The LSTM first obtains a fixed dimension representation
X of the input sequence
(given by the last hidden state of the LSTM), then calculates
, whose initial hidden state is set to
:
where each
distribution is represented by the softmax of all variables in the input Max-cut problem matrix.
3.2. Encoder–Decoder Model
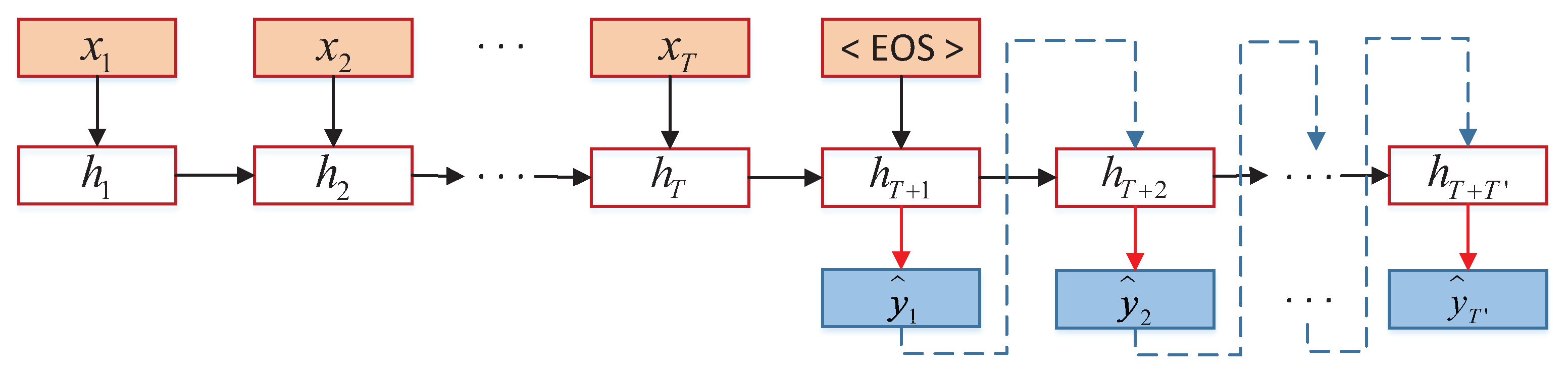
The encoder–decoder model is also called the asynchronous sequence-to-sequence model; that is, the input sequence and the output sequence neither need to have a strict correspondence relationship, nor do they need to maintain the same length. Compared with traditional structures, it greatly expands the application scope of the model. It can directly model sequence problems in a pure data-driven manner and can train the model using an end-to-end method. It can be seen that it is very suitable for solving combinatorial optimization problems.
In the encoder–decoder model (shown in
Figure 2), the input is a sequence
of length
T, and the output is a sequence
of length
. The implementation process is realized by first encoding and then decoding. Firstly, a sample
x is input into an RNN (encoder) at different times to obtain its encoding
. Secondly, another RNN (decoder) is used to obtain the output sequence
. In order to establish the dependence between the output sequences, a non-linear autoregressive model is usually used in the decoder:
where
and
are RNNs used as encoder and decoder, respectively;
is a classifier; and
are vector representations used to predict the output.
3.3. Pointer Network
The amount of information that can be stored in a neural network is called the network capacity. Generally speaking, if more information needs to be stored, then more neurons are needed or the network must be more complicated, which will cause the number of necessary parameters of the neural network to increase exponentially. Although general RNNs have strong capabilities, when dealing with complex tasks, such as processing large amounts of input information or complex computing processes, the computing power of computers is still a bottleneck that limits the development of neural networks.
In order to reduce the computational complexity, we use the mechanisms of the human brain to solve the information overload problem. In such a way, we add an attention mechanism to the RNN. When the computing power is limited, it is used as a resource allocation scheme to allocate computing resources to more important tasks.
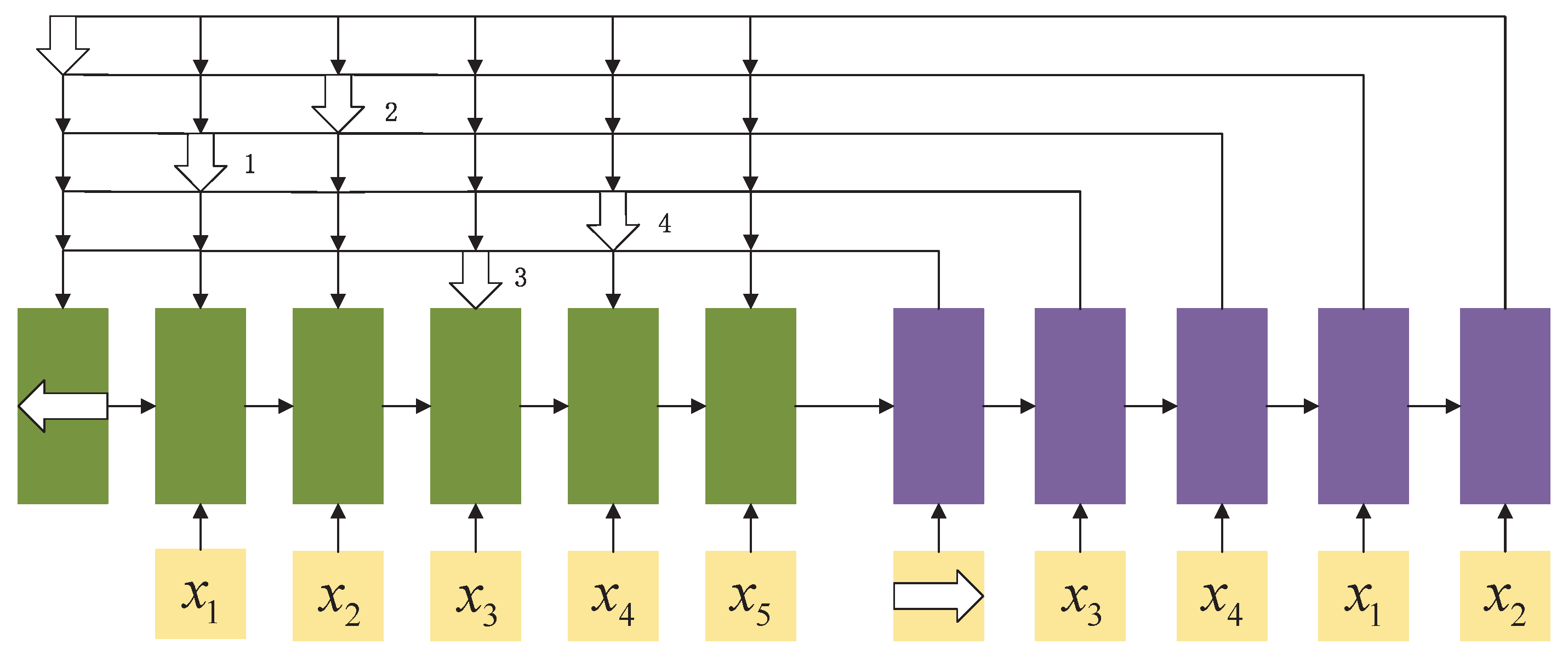
A pointer network is a typical application for combining an attention mechanism and a neural network. We use the attention distribution as a soft pointer to indicate the location of relevant information. In order to save computing resources, it is not necessary to input all the information into the neural network, only the information related to the task needs to be selected from the input sequence
X. A pointer network [
9] is also an asynchronous sequence-to-sequence model. The input is a sequence
of length
T, and the output is a sequence
. Unlike general sequence-to-sequence tasks, the output sequence here is the index of the input sequence. For example, when the input is a group of out-of-order numbers, the output is the index of the input number sequence sorted by size (e.g., if the input is 20, 5, 10, then the output is 1, 3, 2).
The conditional probability
can be written as:
where the conditional probability
can be calculated using the attention distribution. Suppose that an RNN is used to encode
to obtain the vector
, then
where
is the unnormalized attention distribution of each input vector at the
ith step of the encoding process,
where
v,
, and
are learnable parameters.
Figure 3 shows an example of a pointer network.
4. Learning Mechanism
Machine learning methods can be classified according to different criteria. Generally speaking, according to the information provided by the training samples and different feedback mechanisms, we classify machine learning algorithms into three categories: supervised learning, unsupervised learning, and reinforcement learning. Our algorithm uses supervised learning (SL) and reinforcement learning (RL) to train the pointer network model to obtain the solution of the Max-cut problem, which will be described in detail below.
4.1. Supervised Learning
4.1.1. Input and Output Design
The feature of the Max-cut problem is that its variable is either 0 or 1, such the problem is equivalent to selecting a set of variables from all variables with a value of 1 to maximize the objective function. This is a typical choice problem in combinatorial optimization problems. The goal of supervised learning is to learn the relationship between the input x and the output y by modeling or . For the Max-cut problem, the pointer network uses an symmetric matrix Q to represent the input sequence of the n nodes, where is an element in the symmetric matrix, which represents the weight of the connection between vertex i vertex and vertex j (, means there is no connection between vertex i and vertex j). The output sequence of the pointer network is represented by , which contains two variables; that is 0 and 1. Vertices with 0 and vertices with 1 are divided into two different sets. The result of summing weights with all edges across the two cut sets is the solution to the Max-cut problem.
The following example is used to explain the input and output design of the pointer network to solve the Max-cut problem.
The symmetric matrix
Q of the above problem can be expressed as:
and the characteristics of the variables
,
,
, and
are represented by the vectors
,
,
, and
, respectively.
For the Max-cut problem, the optimal solution of the above example is x. The sequence is the input of the pointer network, and the known optimal solution is used to train the network model and guide the model to select and . The input vector selected by the decoder represents the corresponding variable value of 1, while the corresponding variable value of the unselected vector is 0.
For the output part of the pointer network model, for the
matrix, we design a matrix of dimension
to represent the network output. Exactly as in Example 1, the output result is a label that be described by the matrix
:
The relationship between
and the variable
x is:
We use
to indicate the end of the pointer network solution process. After the model training is completed, the probability distribution of the softmax of the output matrix is obtained. The corresponding result may be as described by the matrix
. In the solution phase, we select the one with the highest probability in the output probability distribution and set it to 1, and the rest of the positions to 0. According to the result of
, the pointer network selects the variables
and
with a value of 1, and the remaining variables have a value of 0—which is consistent with the result selected by
:
4.1.2. Algorithm Design
When training deep neural networks, for
N given training samples
, the softmax regression in supervised learning uses cross entropy as a loss function and uses gradient descent to optimize the parameter matrix
W. The goal of neural network training is to learn the parameters which minimize the value of the cross-entropy loss function. In practical applications, the mini-batch stochastic gradient descent (SGD) method has the advantages of fast convergence and small computational overhead, so, it has gradually become the main optimization algorithm used in large-scale machine learning [
23]. Therefore, during the training process, we use mini-batch SGD. At each iteration, we randomly select a small number of training samples to calculate the gradient and update the parameters. Assuming that the number of samples per mini-batch is
K, the training process of softmax regression is: initialize
, and then iteratively update by the following equation
where
is the learning rate and
is the output of the softmax regression model when the parameter is
.
The training process of mini-batch SGD is shown in Algorithm 2.
| Algorithm 2 Mini-batch SGD of pointer network |
| Input: training set: ; mini-batch size: K; number of training steps: L; learning rate: ; |
| Output: optimal: W |
- 1:
random initial W; - 2:
repeat - 3:
randomly reorder the samples in training set D; - 4:
fordo - 5:
select samples from the training set D; - 6:
update parameters: ; - 7:
end for - 8:
until the error rate of model no longer decreases.
|
4.2. Reinforcement Learning
Reinforcement learning is a very attractive method in machine learning. It can be described as an agent continuously learning from interaction with the environment to achieve a specific goal (such as obtaining the maximum reward value). The difference between reinforcement learning and supervised learning is that reinforcement learning does not need to give the “correct” strategy as supervised information, it only needs to give the return of the strategy and then adjust the strategy to achieve the maximum expected return. Reinforcement learning is closer to the nature of biological learning and can cope with a variety of complex scenarios, thus coming closer to the goal of general artificial intelligence systems.
The basic elements in reinforcement learning include:
The can sense the state of the external environment and the reward of feedback, then make decisions;
The is everything outside the , which is affected by the actions of the by changing its state and feeding the corresponding reward back to the ;
s is a description of the , which can be discrete or continuous, and its state space is S;
a is a description of the behavior of the , which can be discrete or continuous, and its action space is A;
The reward is a scalar function—that is, after the agent makes an action a based on the current state s, the environment will give a reward to the agent. This reward is related to the state at the next moment.
For simplicity, we consider the interactions between
and
as a discrete time-series in this paper.
Figure 4 shows the interaction between an
and an
.
4.2.1. Input and Output Design
The pointer network input under reinforcement learning is similar to that under supervised learning. The only difference is that, when applying reinforcement learning, a special symbol
needs to be added, as reinforcement learning only focuses on those variables selected before the variable
.
is a separator that divides a variable into two types. We use the following rules: when inputting into the pointer network, all variables before
are set to 1, and all variables after
are set to 0. We use the zero vector to represent the
. Therefore, in order to change the
n-dimensional matrix
Q into
dimensions, we add a row and a column of 0 to the last row and the last column of matrix
Q. Under this rule, taking Example 1 as an example, to convert the matrix
Q into the matrix
P, the input sequence of the pointer network is
:
Similar to supervised learning, at the output of the pointer network, a symbol is added to divide the set of output vertices. As in Example 1, the output of the pointer network is , which means that the four vertices are divided into two sets, which are and . The numbers in front of indicate that the value at these vertex positions is 1, and the numbers after indicate that the value at these positions is 0. Thus, the max-cut value can be calculated according to the divided sets, and it is this value that is used as the reward in reinforcement learning.
4.2.2. Actor–Critic Algorithm
The actor–critic algorithm is a reinforcement learning method which combines a policy gradient and temporal difference learning. We combine the input–output structure characteristics of the Max-cut problem with the actor–critic algorithm in reinforcement learning to train the pointer network model. The actor–critic algorithm used for solving such combinatorial optimization problems uses the same pointer network encoder for both the actor network and the critic network. First, the actor network encodes the input sequence. Next, the decoder part selects the variable with value 1, according to the probability. The critic network encodes the input sequence, then predicts the optimal value of the Max-cut problem using a value function.
In the actor–critic algorithm, is the input to the actor network, which corresponds to the given symmetric matrix Q in the Max-cut problem; that is, Q is used as the input sequence of the actor network. The actor refers to the policy function , which can learn a strategy to obtain the highest possible reward. For the Max-cut problem, represents the strategy scheme in which variables are selected as 1. The critic refers to the value function , which estimates the value function of the current strategy. With the help of the value function, the actor–critic algorithm can update the parameters in a single step, without having to wait until the end of the round to update. In the actor–critic algorithm, the policy function and the value function are both functions that need to be learned simultaneously during the training process.
Assuming the return
from time
t, we use Equation (
21) to approximate it:
where
is the state at
and
is the instant reward.
In each step of the update, the strategy function
and the value function
are learned. On one hand, the parameter
is updated, such that the value function
is close to the estimated real return
:
On the other hand, the value function
is used as a basis function to update the parameter, in order to reduce the variance of the policy gradient:
In each update step, the actor performs an action a, according to the current environment state s and the strategy ; the environment state becomes and the actor obtains an instant reward r. The critic (value function ) adjusts its own scoring standard, according to the real reward given by the environment and the previous score , such that its own score is closer to the real return of the environment. The actor adjusts its strategy according to the critic’s score, and strives to do better next time. At the beginning of the training, actors performs randomly and critic gives random marks. Through continuous learning, the critic’s ratings become more and more accurate, and the actor’s movements become better and better.
Algorithm 3 shows the training process of the actor–critic algorithm.
| Algorithm 3 Actor–critic algorithm |
| Input: state space: S; action space: A; differentiable strategy function: ; differentiable state value function: ; discount rate: ; learning rate: ; |
| Output: strategy: |
- 1:
random initial , ; - 2:
repeat - 3:
initial starting state s; - 4:
; - 5:
repeat - 6:
In state s, select an action ; - 7:
perform the action a to get an instant reward r and a new state ; - 8:
; - 9:
; - 10:
; - 11:
; - 12:
; - 13:
until s is the termination state; - 14:
untilθ converges.
|
5. Experimental Results and Analysis
Based on the TensorFlow framework, this paper uses two learning strategies (supervised learning and reinforcement learning) to train and predict the Max-cut problem with a pointer network. The model is trained on a deep learning server platform consisting of two NVIDIA TITAN Xp GPUs and an Intel Core i9-7960X CPU.
The initial parameters in the pointer network are randomly generated by a uniform distribution in [−0.08, 0.08], and the initial learning rate is 0.001. During the training process, when supervised learning is applied to train the pointer network, the model uses a single-layer LSTM with 256 hidden units and is trained with mini-batch SGD. When applying reinforcement learning to train the pointer network, the model uses three layers of LSTMs, with each layer consisting of 128 hidden units, and is trained with the actor–critic algorithm. In the prediction stage, the heat parameter in the pointer network is set to 3, and the initial reward baseline is set to 100. The model tested during the prediction phase is the last iteration of the training phase. For the Max-cut problem of different dimensions, except for increasing the sequence length, the other hyperparameter settings are the same. In the implementation, we use the Adam algorithm to adjust the learning rate. Adam algorithm can make effective dynamic adjustments to the model to make the changes in hyperparameters relatively stable [
24].
We constructed a data set based on the method mentioned in
Section 2.2 (using the {−1,1} quadratic programming problem transformed into the Max-cut problem), which we refer to as the Zhou data set. In order not to lose generality, we also used the Binary quadratic and Max cut Libraries (Biq Mac Library), which are the most commonly used benchmark generators for the Max-cut problem. We performed experiments on the Zhou data set and the Biq Mac Library data set, respectively.
5.1. Experiments on Zhou Data Set
According to the method for randomly generating Max-cut problems in
Section 2.2, a large number of Max-cut problems with known exact solutions were obtained, which we formed into data sets with specified input and output formats. The training set and the test set are both data generated from the same probability distribution, and the density of the input matrix
Q in the data sample is 94.6%. Each sample in the training and test sets is unique. Then, we divided the data sets randomly into training and test sets according to the ratio of 10:1. For different dimensions, the training set contained 1000 samples and the test set contained 100 samples. The maximum number of training iterations was set to 100,000. The accuracy of the solution trained by the model is defined as:
where
is the solution of trained pointer network model, and
is the optimal value of the Max-cut problem.
We first used supervised learning to train the pointer network on the 10-, 30-, 50-, 60-, 70-, 80-, 90-, 100-, 150-, and 200-dimensional Max-cut problems, respectively.
Table 1 shows average accuracy of the Max-cut problem of the above dimensions. And the detailed experimental results are listed in
Table 2.
Then the pointer network based on reinforcement learning was also trained with the Zhou data set, on 10-, 50-, 150-, 200-, 250-, and 300-dimensional Max-cut problems.
Table 3 shows the average accuracy of the Max-cut problem for the above dimensions. And the detailed experimental results are listed in
Table 4.
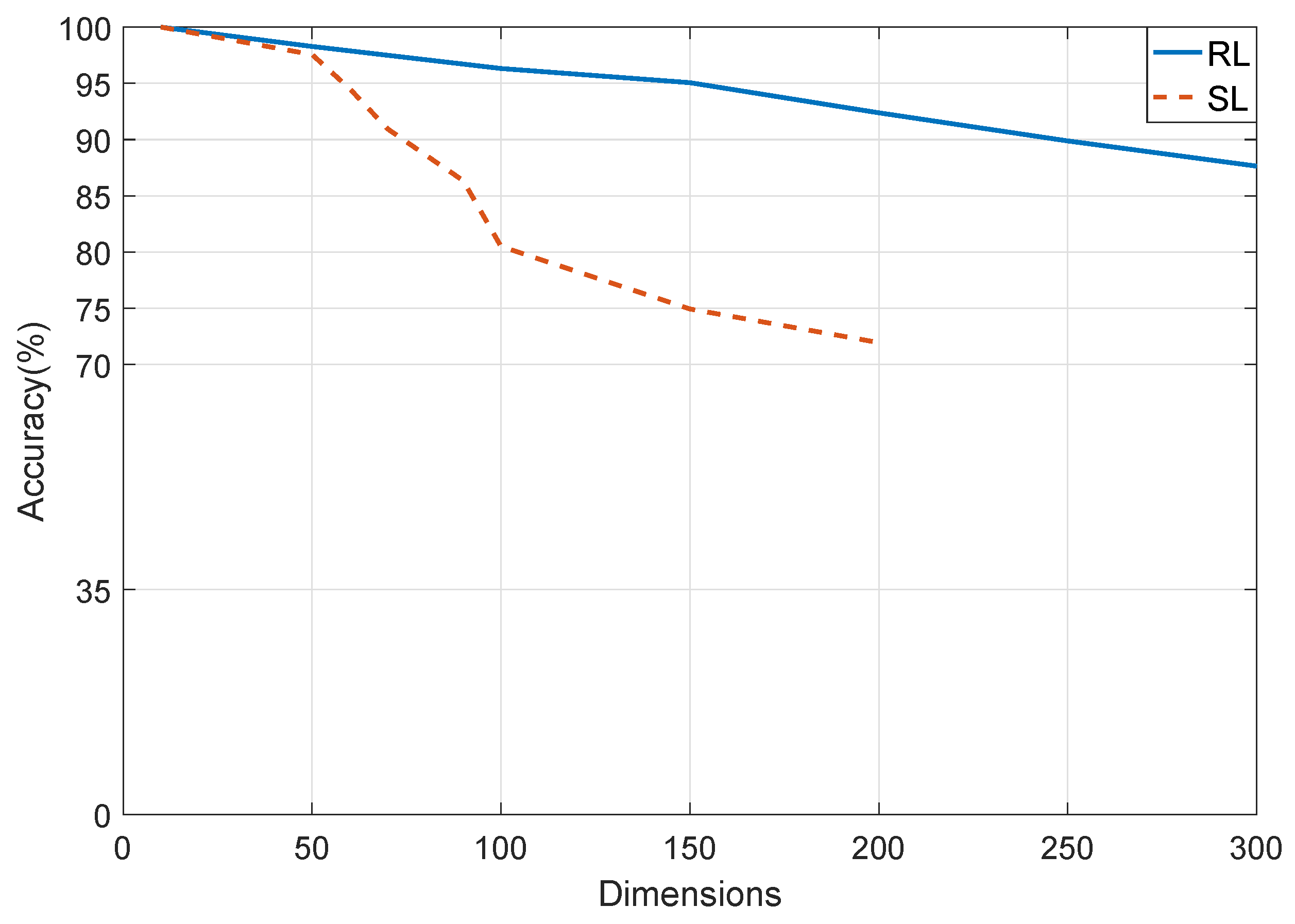
It can be seen, from
Table 1 and
Table 3 that, regardless of whether supervised learning or reinforcement learning was used, the average accuracy of the pointer network solution decreased as the number of dimensions increased. However, the average accuracy of reinforcement learning decreased very slightly. Secondly, by comparing the two tables, we find that the pointer network model obtained through reinforcement learning was more accurate than that obtained by supervised learning. Finally, it can be seen that the time taken to train the model with reinforcement learning was faster than that for supervised learning.
Figure 5 shows the accuracy of the solution for the Max-cut problem samples trained with supervised learning and reinforcement learning.
5.2. Experiments on Biq Mac Library
In order to further verify the generalization ability of the pointer network model, ten groups of 60-, 80-, and 100-dimensional Max-cut samples were selected from the Biq Mac Library (
http://biqmac.uni-klu.ac.at/biqmaclib.html). As the Max-cut problem data set of each dimension in the Biq Mac Library only has ten groups of data, the amount of data was not enough to train the pointer network (training the pointer network model requires at least 100 groups of data), so we only used the Biq Mac Library as the test set; the Zhou data set was still used as the training set.
Table 5 shows the detailed experimental results of the Max-cut problem with 60, 80, and 100 dimensions using the Biq Mac Library by reinforcement learning.
The average prediction results are shown in
Table 6.
It can be seen, from
Table 3 and
Table 6, that the average accuracies when predicting the Biq Mac Library using reinforcement learning were lower than the accuracies on Zhou dataset. This is because the Biq Mac Library is composed of data samples with different distributions, which can better characterize the essential characteristics of the Max-cut problem. We believe that, in future research, if the model can be trained on a larger training set with the distribution of the Biq Mac Library, its performance can be definitely improved.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}