Applying Visual Cryptography to Enhance Text Captchas


Abstract
:1. Introduction
2. Preliminaries
2.1. One Typical Text Captcha Generation Method
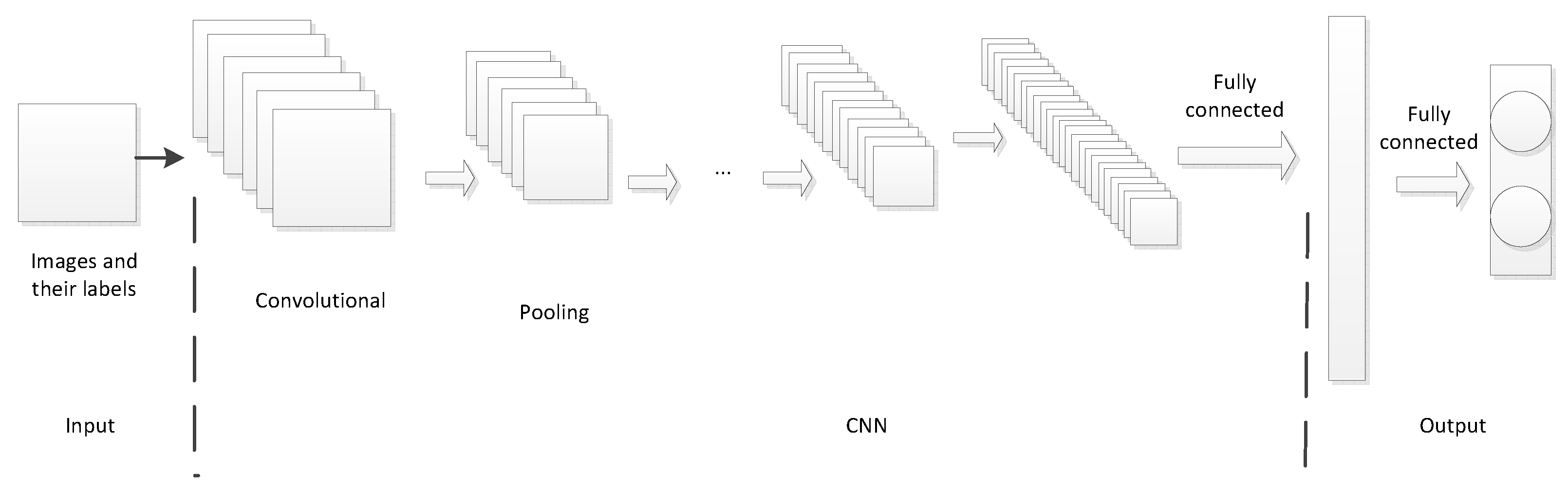
2.2. One Typical Deep Learning Breaking Method
2.3. Another Typical Deep Learning Breaking Method
2.4. VC for -threshold
| Algorithm 1: One typical RG-based VC |
| Input: A binary secret image S with size of H × W Output: 2 shadow images and Step 1: For each secret position , repeat Steps 2-5 Step 2: Generate randomly. Step 3: If , go to Step 5; else go to Step 4. Step 4: Randomly select , and calculate . Step 5: Randomly rearrange to Step 6: Output the 2 shadow images and |
| Algorithm 2: One typical RG-based VC for -threshold |
| Input: Any binary image S with size of H × W; threshold parameters Output: n binary shadow images Step 1: For each position , repeat Steps 2-4 Step 2: Set randomly.If , randomly select , and compute . Step 3: Compute , set and . Step 4: Randomly rearrange to Step 5: Output n shadow images |
3. The Designed Method
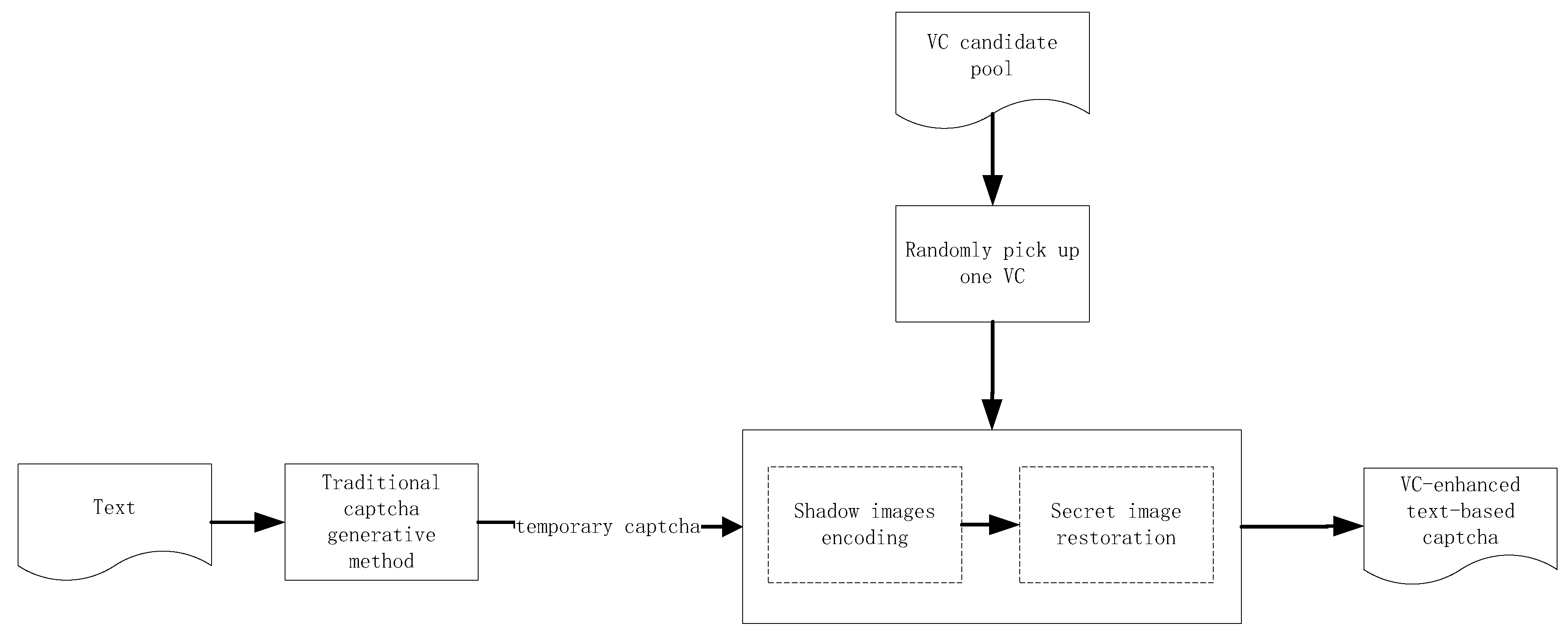
| Algorithm 3: The designed VCETC |
| Input: Text content appeared in the captcha; pre-existed traditional captcha generation method; VC candidate pool, that is, , for Output: Output VC-enhanced text-based captcha Step 1: Utilize pre-existed traditional captcha generation method to generate temporary captcha, denoted by , according to the text content. Step 2: Convert into binary image with automatic threshold to obtain . Step 3: Randomly pick up one VC method from VC candidate pool.Use the VC method to encode to obtain n shadow images . Step 4: Randomly choose t shadow images, denoted by , from all the n shadow images, to restore based on superposing operation, where . Step 5: Output VC-enhanced text-based captcha |
- In the input, pre-existed traditional captcha generation method is input and based on which we can further improve the performance. Thus, other pre-existed traditional text-based captcha generation method can also be input in our method and our method is only one enhanced method based on pre-existed traditional captcha generation method rather than a redesign.
- In Step 3, the randomness of the selected VC method is applied to the captcha . In addition, the random selection of VC method and t further increases the randomness in the captcha .
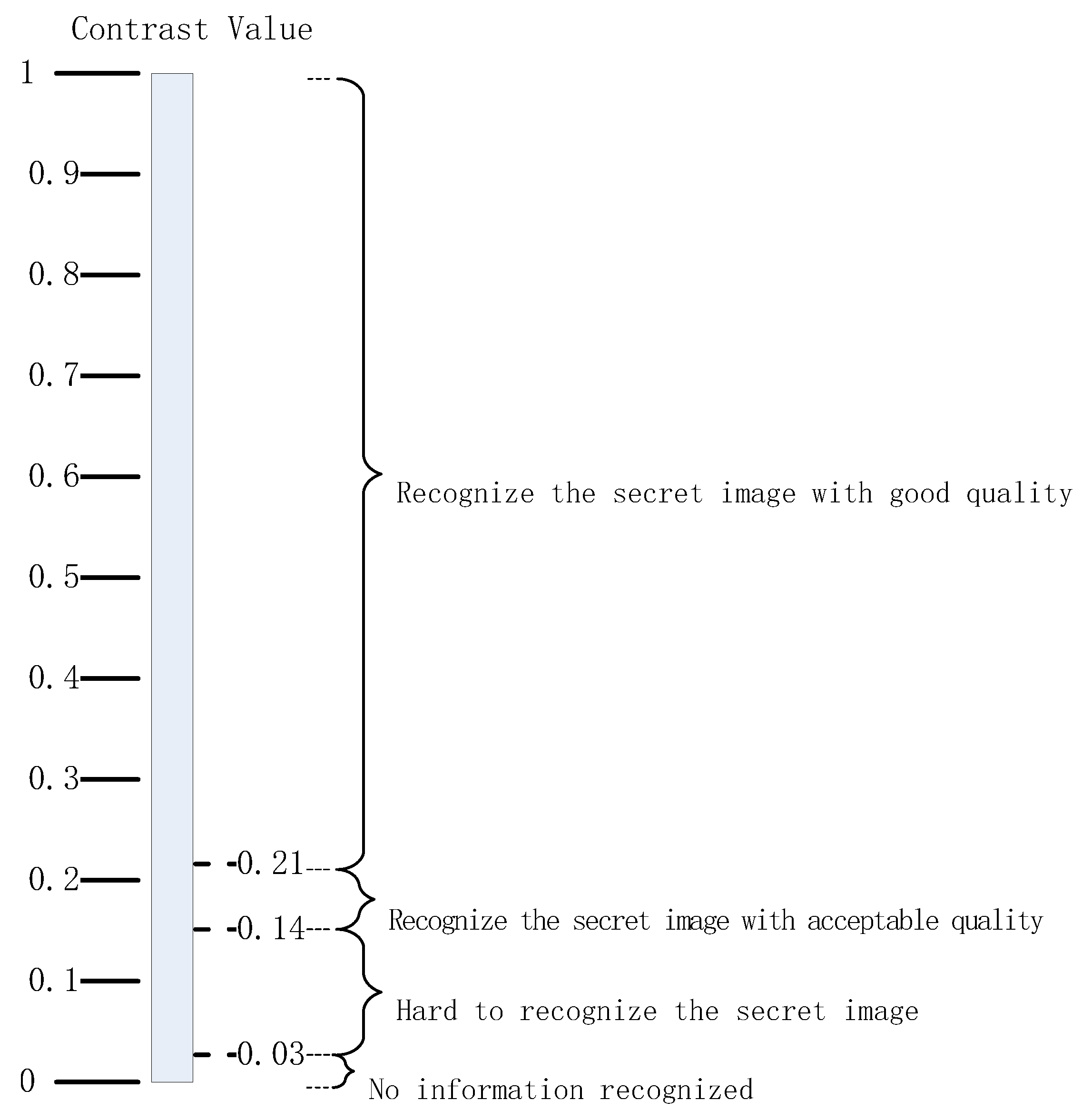
- VC candidate pool, that is, , for , can be set up through screening possible VC schemes and their parameters whose contrast value is in , where 0.14 is derived from clarity as Figure 3 for human recognition and 0.36 is given by our experiments.
- We can use the VC method to encode the text captcha first and then use pre-existed traditional captcha generation method to proceed the temporary captcha as well.
- In Step 4, we directly stack the selected t shadow images. We can further improve the randomness by performing dynamic stacking from random angles with random velocities like the gif in Reference [34].
- Some other text-based applications can apply our method as well.
4. Experiments and Comparisons
4.1. Breaking Traditional Captcha Generative Captchas by Deep Learning Way
4.1.1. The First Deep Learning Way
4.1.2. The Second Deep Learning Way
4.2. Our Designed Captcha Test by Deep Learning Way
4.2.1. The First Deep Learning Way
4.2.2. The Second Deep Learning Way
4.2.3. The Subjective Recognized Rates with Human Naked Eyes
4.2.4. Brief Summary of the Experiments
- Due to the features of the randomness for each encoding process in VC and its visual recognizability with naked human eyes, our designed VCETC can in some degree enhance traditional captchas to resist some deep learning-based ways even our designed VCETC are used as the training set.
- Due to the feature of visual recognizability with naked human eyes, VCETCs are suitable for human eyes.
- According to subjective test, our designed VCETC slightly affects user experience with lower storage space, that is, the binary captcha needs a lower storage space and transmission bandwidth than color ones.
4.3. Use-Case Scenario
5. Conclusions
- There are many practically oriented programs for solving the captchas problem to circumvention the need of human participation expected by website, which are not based on CNN, such as “Universal Share Downloader” (USD) based on plugins and direct optical character recognition (OCR) to recognize some typical captchas. Due to the features of the randomness for each encoding process in VC, our method may enhance such text captchas.
- VCETCs are applied to image-based captchas [35] to enhance them.
- We will provide additional information and discussion to elaborate more on the use case scenario, and how we envision to include the recommender systems.
- Our method can add many dynamic mechanisms to further improve the performance.
- Other recent attempts to improve text-based captchas have been proposed in the scientific literature as well. We will compare our method to the more state of the art enhanced methods.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ahn, L.V. Telling humans and computers apart automatically. Commun. ACM 2004, 47, 56–60. [Google Scholar] [CrossRef] [Green Version]
- Chow, Y.W.; Susilo, W.; Thorncharoensri, P. CAPTCHA Design and Security Issues. In Advances in Cyber Security: Principles, Techniques, and Applications; Li, K.C., Chen, X., Susilo, W., Eds.; Springer: Singapore, 2019; pp. 69–92. [Google Scholar] [CrossRef]
- Bursztein, E.; Aigrain, J.; Moscicki, A.; Mitchell, J.C. The End is Nigh: Generic Solving of Text-based CAPTCHAs. In Proceedings of the Usenix Conference on Offensive Technologies, San Diego, CA, USA, 19 August 2014. [Google Scholar]
- George, D.; Lehrach, W.; Kansky, K.; Lázaro-Gredilla, M.; Laan, C.; Marthi, B.; Lou, X.; Meng, Z.; Liu, Y.; Wang, H. A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs. Science 2017, 358, eaag2612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ye, G.; Tang, Z.; Fang, D.; Zhu, Z.; Feng, Y.; Xu, P.; Chen, X.; Wang, Z. Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; ACM: New York, NY, USA, 2018; pp. 332–348. [Google Scholar] [CrossRef] [Green Version]
- Tengxing Breaking Captchas. 2017. Available online: https://github.com/tengxing/tensorflow-learn/tree/master/captcha (accessed on 15 November 2017).
- Lin, G.; Shen, W. Research on convolutional neural network based on improved Relu piecewise activation function. Procedia Comput. Sci. 2018, 131, 977–984. [Google Scholar] [CrossRef]
- Iliev, A.; Kyurkchiev, N.; Markov, S. On the approximation of the step function by some sigmoid functions. Math. Comput. Simul. 2017, 133, 223–234. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Von Ahn, L.; Maurer, B.; McMillen, C.; Abraham, D.; Blum, M. reCAPTCHA: Human-Based Character Recognition via Web Security Measures. Science 2008, 321, 1465–1468. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saadat Beheshti, S.M.R.; Liatsis, P.; Rajarajan, M. A CAPTCHA model based on visual psychophysics: Using the brain to distinguish between human users and automated computer bots. Comput. Secur. 2017, 70, 596–617. [Google Scholar] [CrossRef]
- Kim, S.; Choi, S. DotCHA: A 3D Text-Based Scatter-Type CAPTCHA; Web Engineering; Bakaev, M., Frasincar, F., Ko, I.Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 238–252. [Google Scholar]
- Naor, M.; Shamir, A. Visual cryptography. In Advances in Cryptology-EUROCRYPT’94 Lecture Notes in Computer Science, Workshop on the Theory and Application of Cryptographic Techniques, Perugia, Italy, 9–12 May 1994; Springer: Berlin/Heidelberg, Germany, 1995; pp. 1–12. [Google Scholar]
- Weir, J.; Yan, W. A comprehensive study of visual cryptography. In Transactions on DHMS V, LNCS 6010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 70–105. [Google Scholar]
- Wang, Z.; Arce, G.R.; Di Crescenzo, G. Halftone visual cryptography via error diffusion. IEEE Trans. Inf. Forensci. Secur. 2009, 4, 383–396. [Google Scholar] [CrossRef]
- Li, P.; Liu, Z.; Yang, C.N. A construction method of (t,k,n)-essential secret image sharing scheme. Signal Process. Image Commun. 2018, 65, 210–220. [Google Scholar] [CrossRef]
- Kafri, O.; Keren, E. Encryption of pictures and shapes by random grids. Opt. Lett. 1987, 12, 377–379. [Google Scholar] [CrossRef]
- Yang, C.N.; Wu, C.C.; Wang, D.S. A discussion on the relationship between probabilistic visual cryptography and random grid. Inf. Sci. 2014, 278, 141–173. [Google Scholar] [CrossRef]
- Yan, X.; Liu, X.; Yang, C.N. An enhanced threshold visual secret sharing based on random grids. J. Real-Time Image Process. 2018, 14, 61–73. [Google Scholar] [CrossRef]
- Wang, W.; Liu, F.; Guo, T.; Ren, Y. Temporal Integration Based Visual Cryptography Scheme and Its Application. In Proceedings of the Digital Forensics and Watermarking: 16th International Workshop, IWDW 2017, Magdeburg, Germany, 23–25 August 2017; pp. 406–419. [Google Scholar]
- Li, Y.; Guo, L. Robust Image Fingerprinting via Distortion-Resistant Sparse Coding. IEEE Signal Process. Lett. 2018, 25, 140–144. [Google Scholar] [CrossRef]
- Chavan, P.V.; Atique, M.; Malik, L. Signature based authentication using contrast enhanced hierarchical visual cryptography. In Proceedings of the Electrical, Electronics and Computer Science, Bhopal, India, 1–2 March 2014; pp. 1–5. [Google Scholar]
- Luo, H.; Lu, Z.M.; Pan, J.S. Multiple Watermarking in Visual Cryptography. In Proceedings of the International Workshop on Digital Watermarking; Springer: Berlin/Heidelberg, Germany, 2007; pp. 60–70. [Google Scholar]
- El-Latif, A.A.A.; Abd-El-Atty, B.; Hossain, M.S.; Rahman, M.A.; Alamri, A.; Gupta, B.B. Efficient quantum information hiding for remote medical image sharing. IEEE Access 2018. [Google Scholar] [CrossRef]
- Wang, G.; Liu, F.; Yan, W.Q. Basic Visual Cryptography Using Braille. Int. J. Digit. Crime Forensics 2016, 8, 85–93. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Y.; Fu, Z.; Yu, B.; Shen, G. A new two-level QR code with visual cryptography scheme. Multimedia Tools Appl. 2017. [Google Scholar] [CrossRef]
- Komargodski, I.; Naor, M.; Yogev, E. Secret-Sharing for NP. J. Cryptol. 2017, 30, 444–469. [Google Scholar] [CrossRef]
- Belazi, A.; El-Latif, A.A.A. A simple yet efficient S-box method based on chaotic sine map. Opt. Int. J. Light Electron Opt. 2017, 130, 1438–1444. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Wang, Y.; Zhu, L.; Ji, W. Cheating identifiable secret sharing scheme using symmetric bivariate polynomial. Inf. Sci. 2018, 453, 21–29. [Google Scholar] [CrossRef]
- Liu, F.; Wu, C.; Qian, L. Improving the visual quality of size invariant visual cryptography scheme. J. Vis. Commun. Image Represent. 2012, 23, 331–342. [Google Scholar] [CrossRef]
- Yan, X.; Lu, Y.; Huang, H.; Liu, L.; Wan, S. Clarity Corresponding to Contrast in Visual Cryptography. In Proceedings of the Social Computing: Second International Conference of Young Computer Scientists, Engineers and Educators, ICYCSEE 2016, Harbin, China, 20–22 August 2016; pp. 249–257. [Google Scholar] [CrossRef]
- Yan, X.; Wang, S.; Niu, X. Threshold construction from specific cases in visual cryptography without the pixel expansion. Signal Process. 2014, 105, 389–398. [Google Scholar] [CrossRef]
- Yan, X.; Lu, Y.; Liu, L.; Wan, S. Random Grids-Based Threshold Visual Secret Sharing with Improved Visual Quality. In Proceedings of the Digital Forensics and Watermarking: 15th International Workshop, IWDW 2016, Beijing, China, 17–19 September 2016; pp. 209–222. [Google Scholar] [CrossRef]
- Visual cryptography in Wikipedia. 2019. Available online: https://en.wikipedia.org/wiki/Visual_cryptography (accessed on 15 November 2017).
- Alqahtani, F.H.; Alsulaiman, F.A. Is image-based CAPTCHA secure against attacks based on machine learning? An experimental study. Comput. Secur. 2020, 88, 101635. [Google Scholar] [CrossRef]
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.E.; Dimitriou, A.; Papavassiliou, S. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 2015 13th International Conference on Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Belk, M.; Germanakos, P.; Fidas, C.; Holzinger, A.; Samaras, G. Towards the Personalization of CAPTCHA Mechanisms Based on Individual Differences in Cognitive Processing. In Human Factors in Computing and Informatics; Holzinger, A., Ziefle, M., Hitz, M., Debevc, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 409–426. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| Threshold | |
| 0(resp.1) | A white(resp. black) pixel |
| S | The secret binary image |
| The restored binary secret image | |
| ( resp. ) | The area of all the white (resp. black) pixels in S |
| A bit-wise complementary operation on a binary pixel b | |
| ⊗ | Stacking (OR) operation |
| ⊕ | Boolean XOR operation |
| Shadow images generated by VSS schemes | |
| t | Number of collecting shadow images in the recovery phase |
| Contrast of the restored secret image by stacking recovery | |
| The probability when any event x occurs | |
| A model trained with traditional captchas by the first (second) deep learning-based breaking method | |
| A model trained with captchas generated by our method by the first (second) deep learning-based breaking method |
| Type | Success Rate | Type | Success Rate | Decreased Value |
|---|---|---|---|---|
| Traditional captchas | 86.75% | Our designed captchas | 70.50% | 16.25%↓ |
| Traditional captchas within 2 s | 83.25% | Our designed captchas within 2 s | 63% | 20.25%↓ |
| Item | The First Deep Learning Way | The Second Deep Learning Way |
|---|---|---|
| Training set | 100,000 captchas | 500 captchas |
| Testing set | 10,000 captchas | 4540 captchas |
| Success rate of traditional captchas | 95% | 71.52% |
| Success rate of our designed captchas | 8.7% (the loss function is not decreased all the time with additional 8000 captchas generated by our method) | 53.83% |
| Method | Number of Generated Captchas | Total Generating and Storage Time | Average Generating and Storage Time |
|---|---|---|---|
| Traditional captcha generation method | 2500 | 165 | 0.0661 |
| The proposed method | 2500 | 295 | 0.1182 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Liu, F.; Yan, W.Q.; Lu, Y. Applying Visual Cryptography to Enhance Text Captchas. Mathematics 2020, 8, 332. https://doi.org/10.3390/math8030332
Yan X, Liu F, Yan WQ, Lu Y. Applying Visual Cryptography to Enhance Text Captchas. Mathematics. 2020; 8(3):332. https://doi.org/10.3390/math8030332
Chicago/Turabian StyleYan, Xuehu, Feng Liu, Wei Qi Yan, and Yuliang Lu. 2020. "Applying Visual Cryptography to Enhance Text Captchas" Mathematics 8, no. 3: 332. https://doi.org/10.3390/math8030332
APA StyleYan, X., Liu, F., Yan, W. Q., & Lu, Y. (2020). Applying Visual Cryptography to Enhance Text Captchas. Mathematics, 8(3), 332. https://doi.org/10.3390/math8030332