Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms



Abstract
:1. Introduction
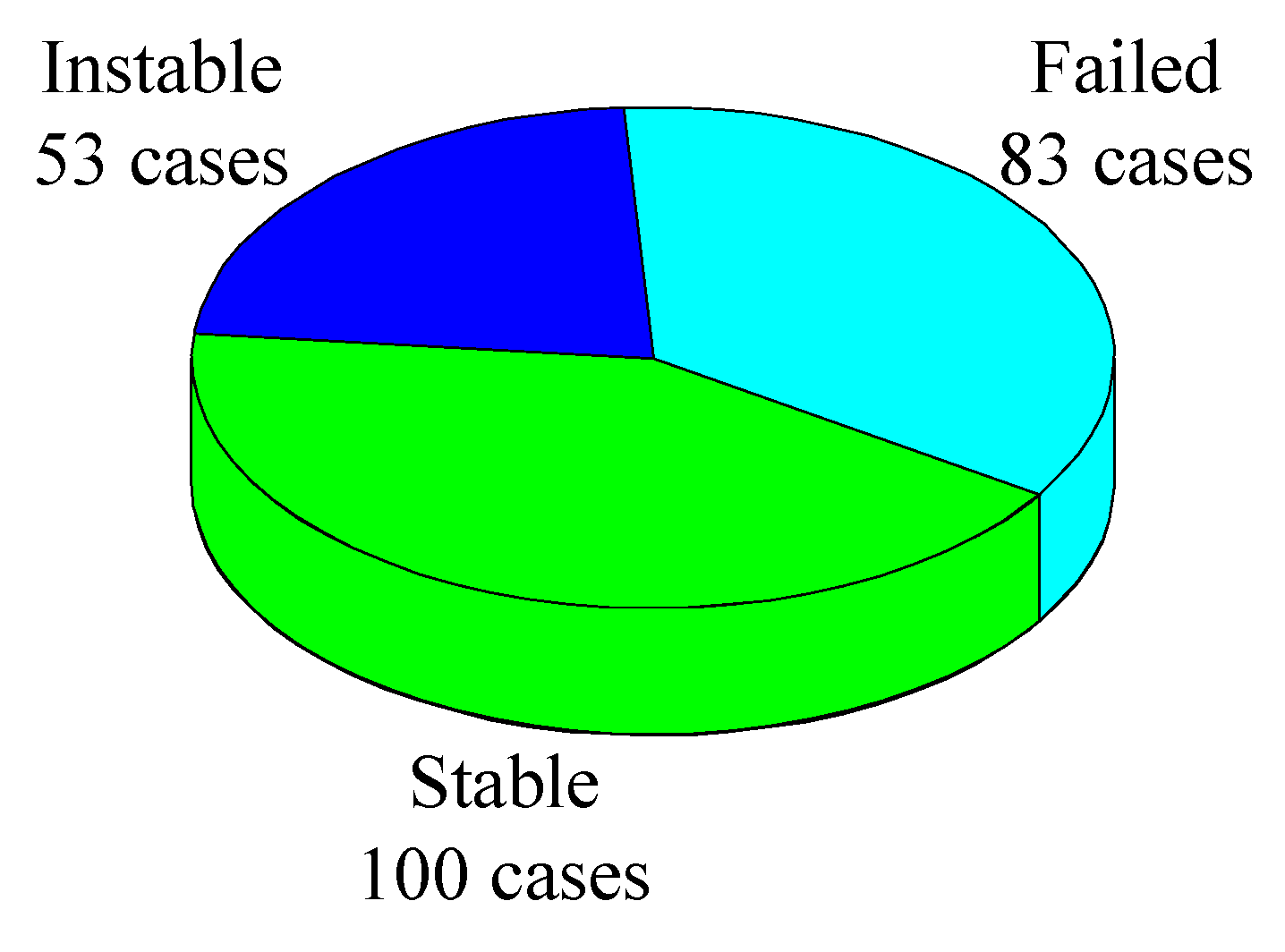
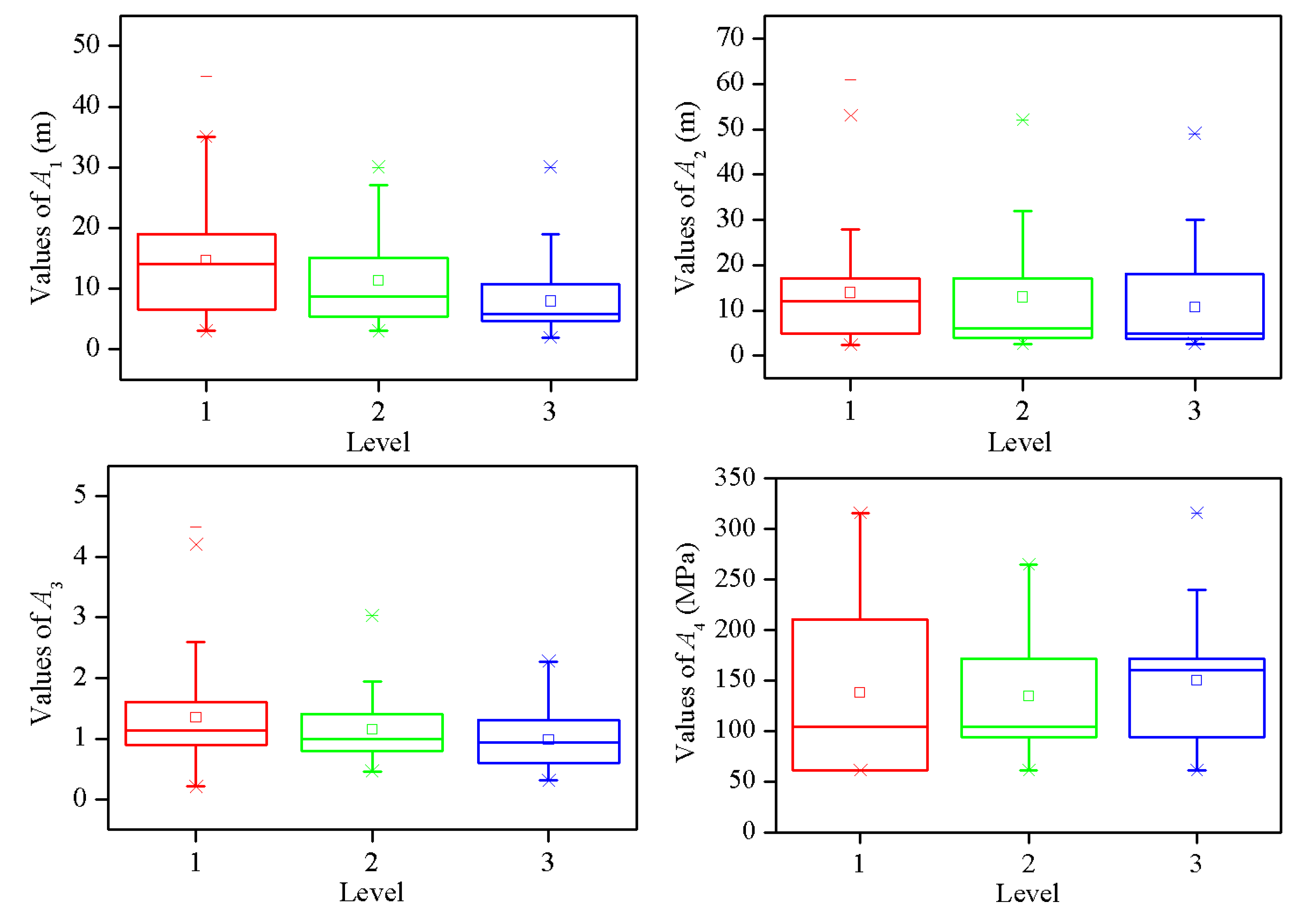
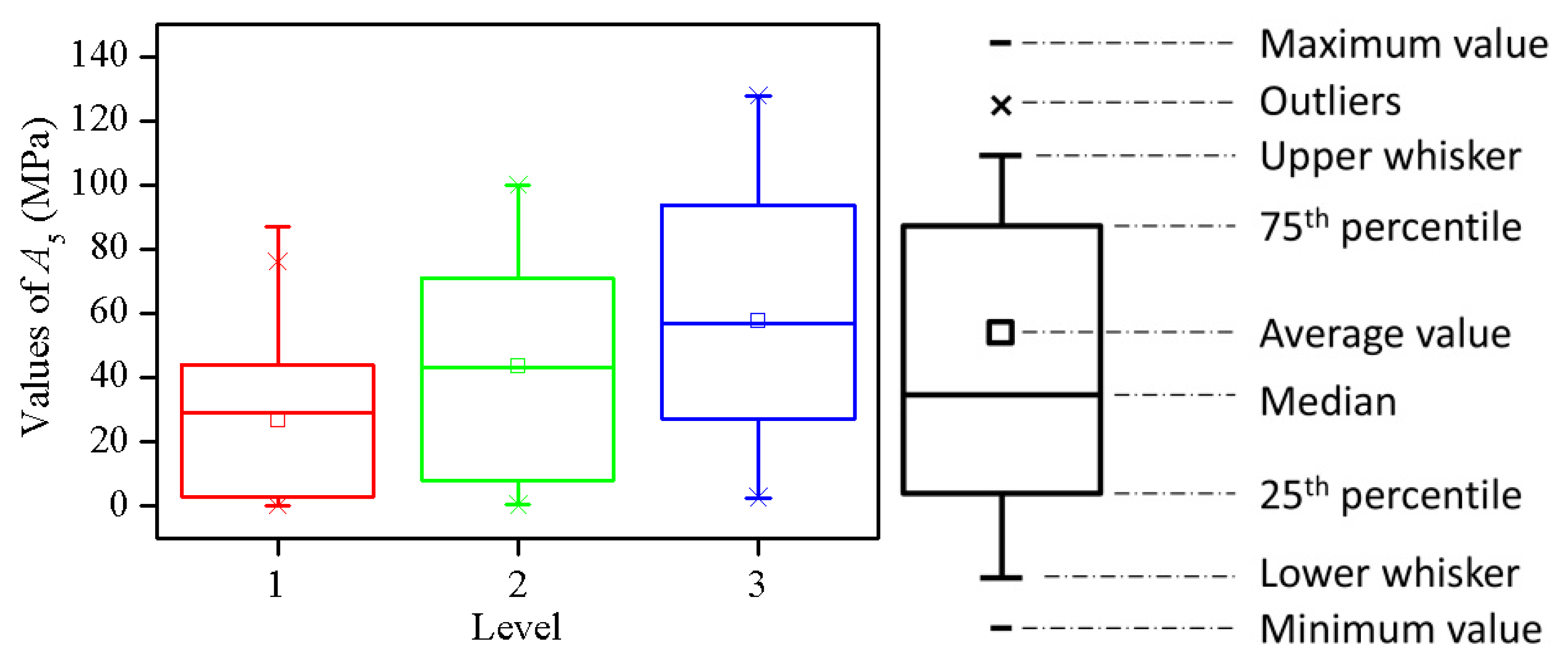
2. Data Acquisition
3. Methodology
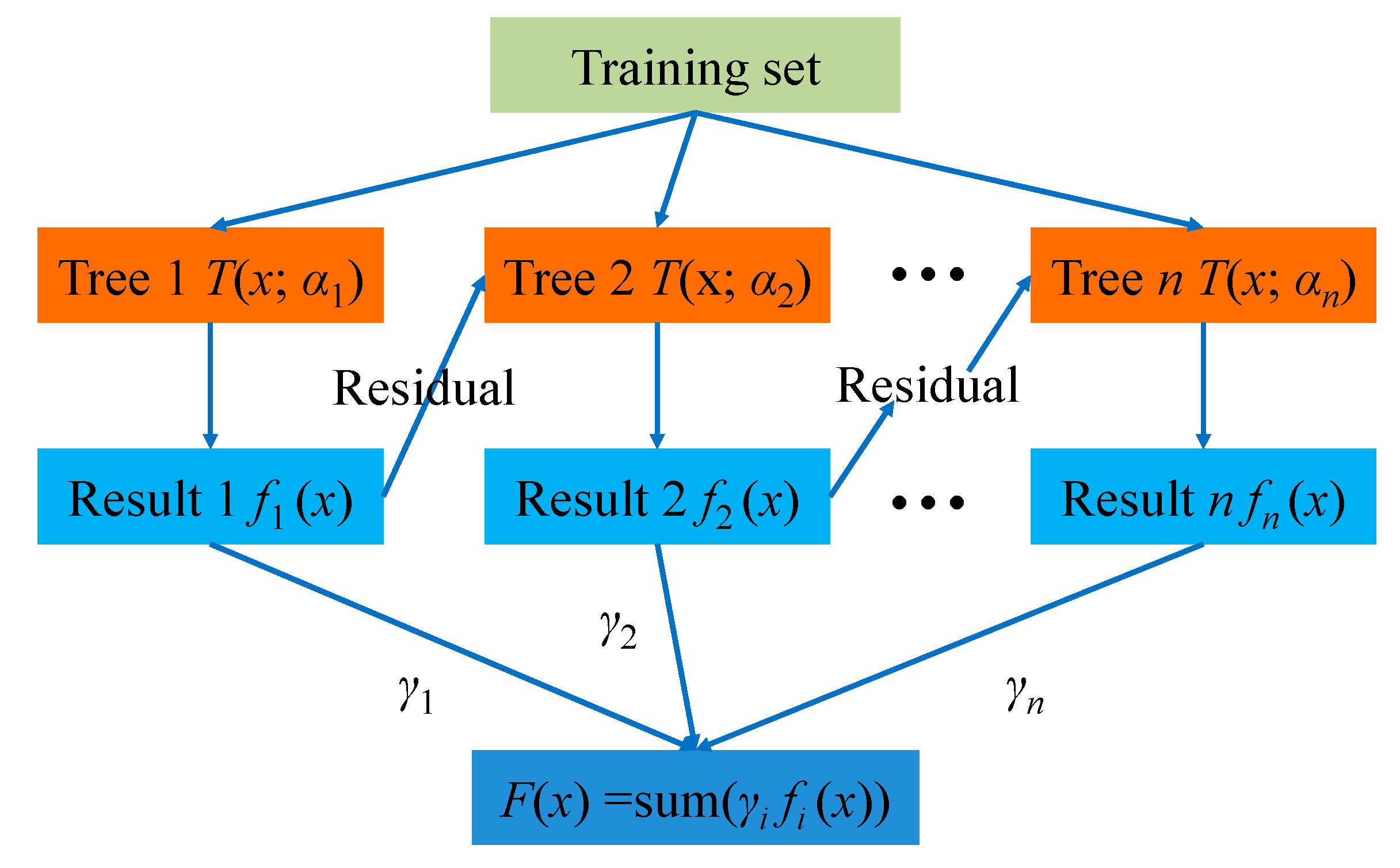
3.1. GBDT Algorithm
3.2. XGBoost Algorithm
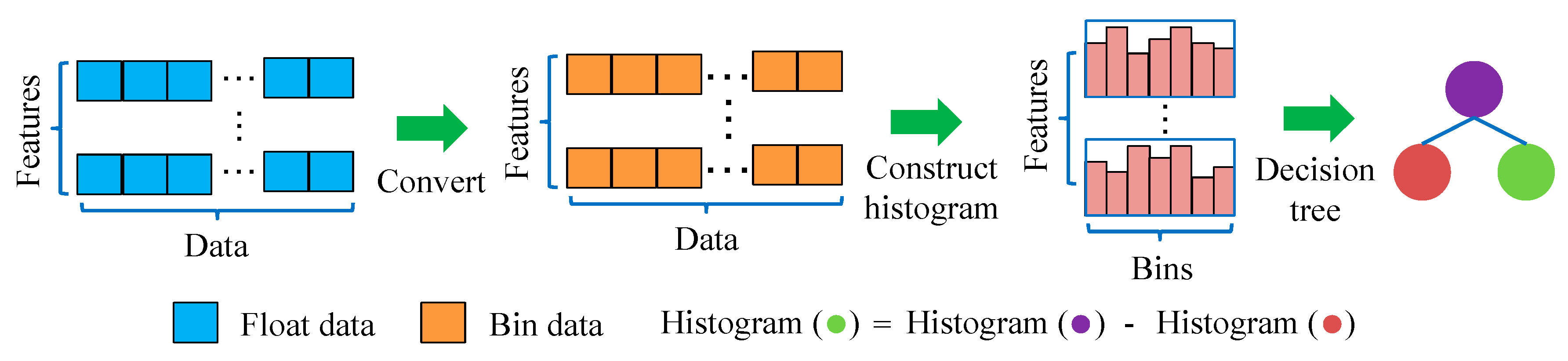
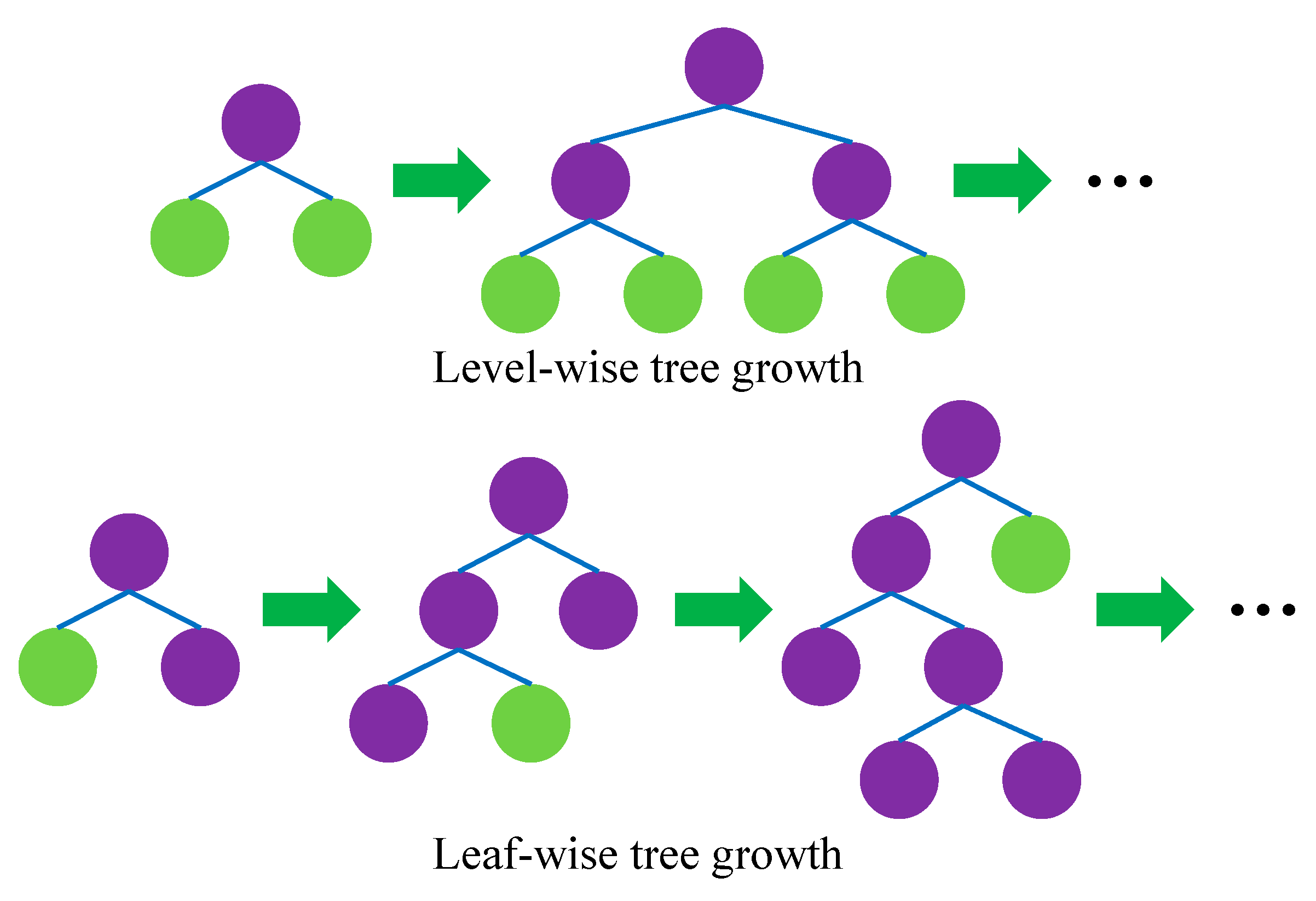
3.3. LightGBM Algorithm
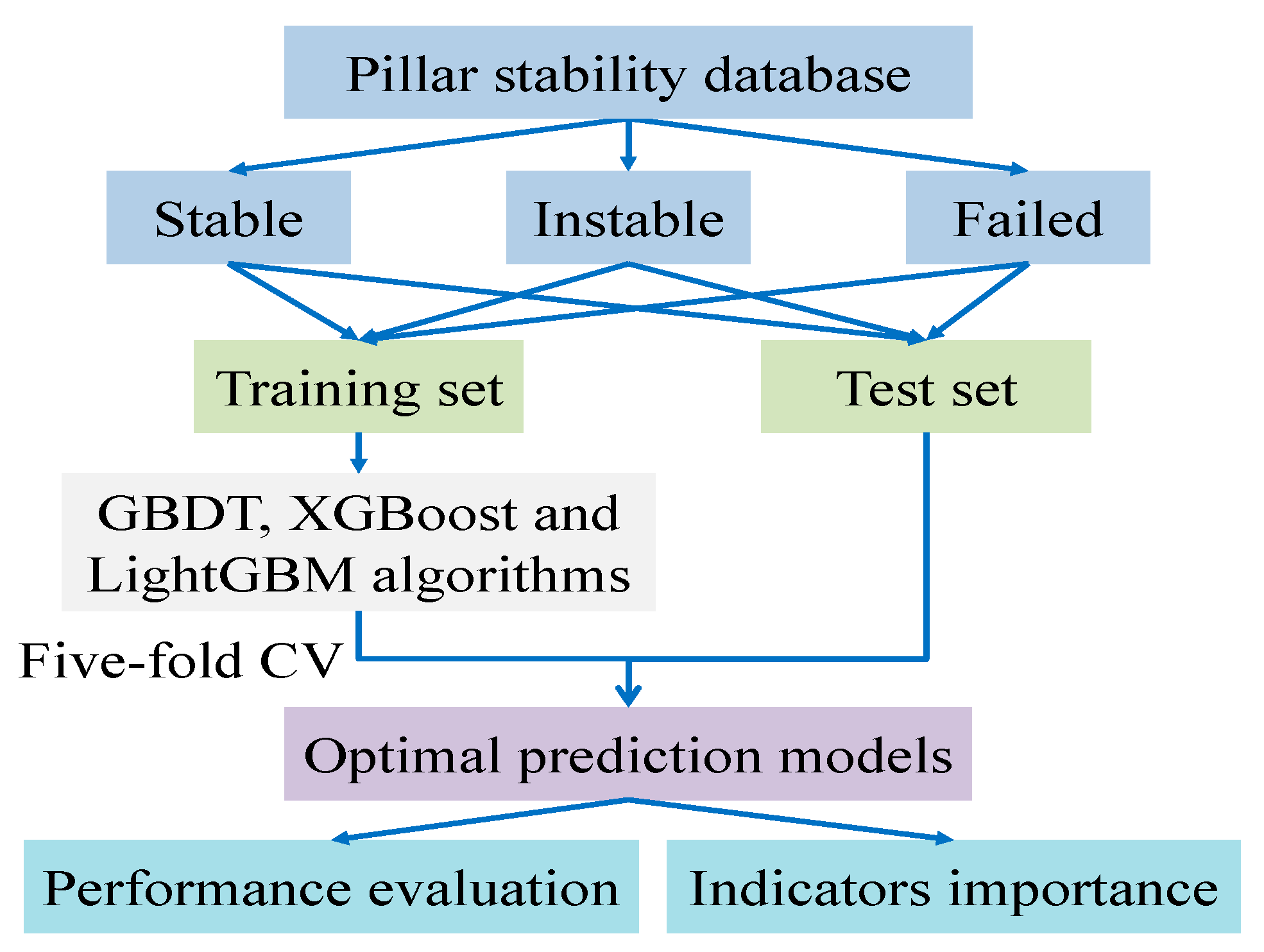
4. Construction of Prediction Model
4.1. Hyperparameter Optimization
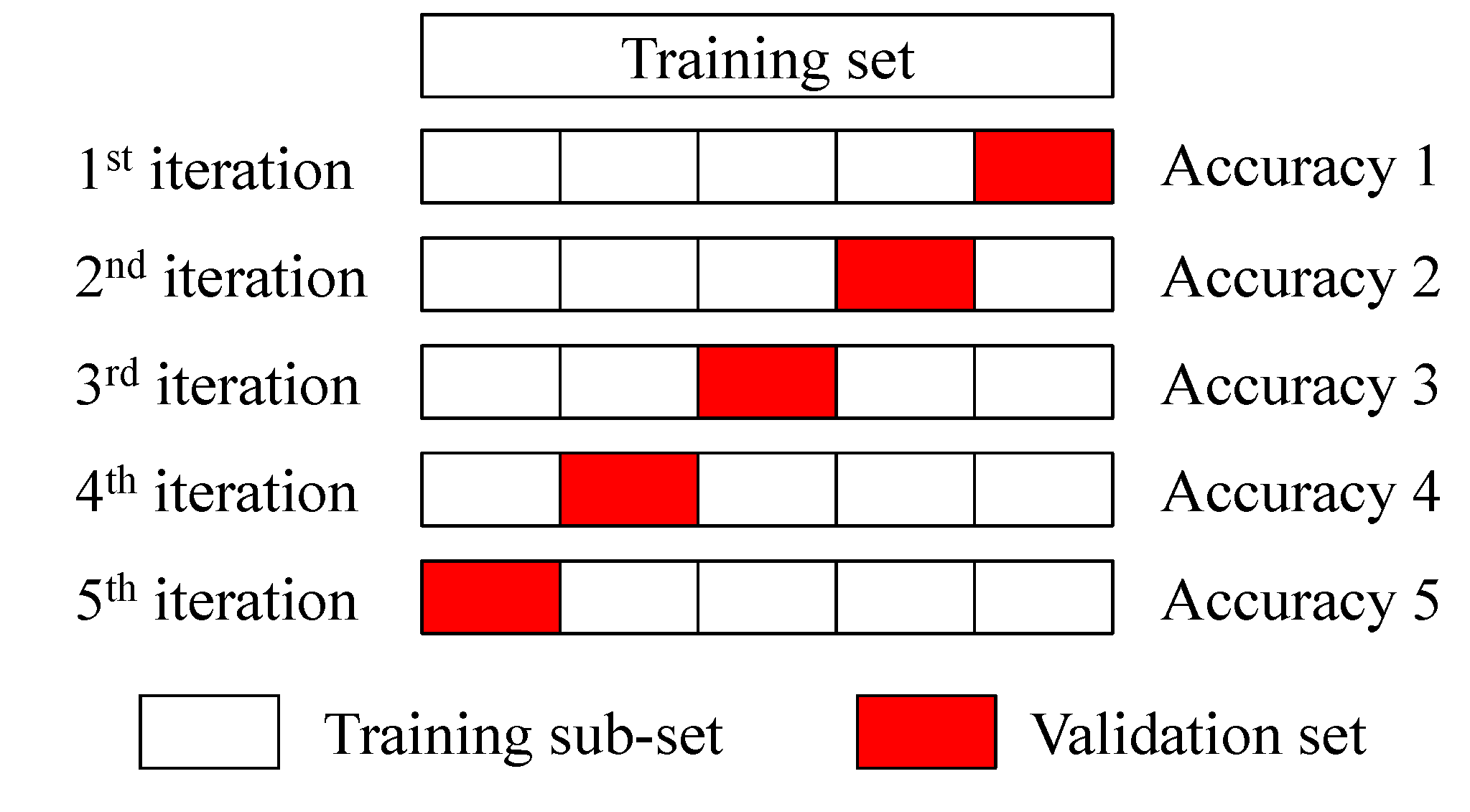
4.2. Model Evaluation Indexes
5. Results and Analysis
5.1. Overall Prediction Results
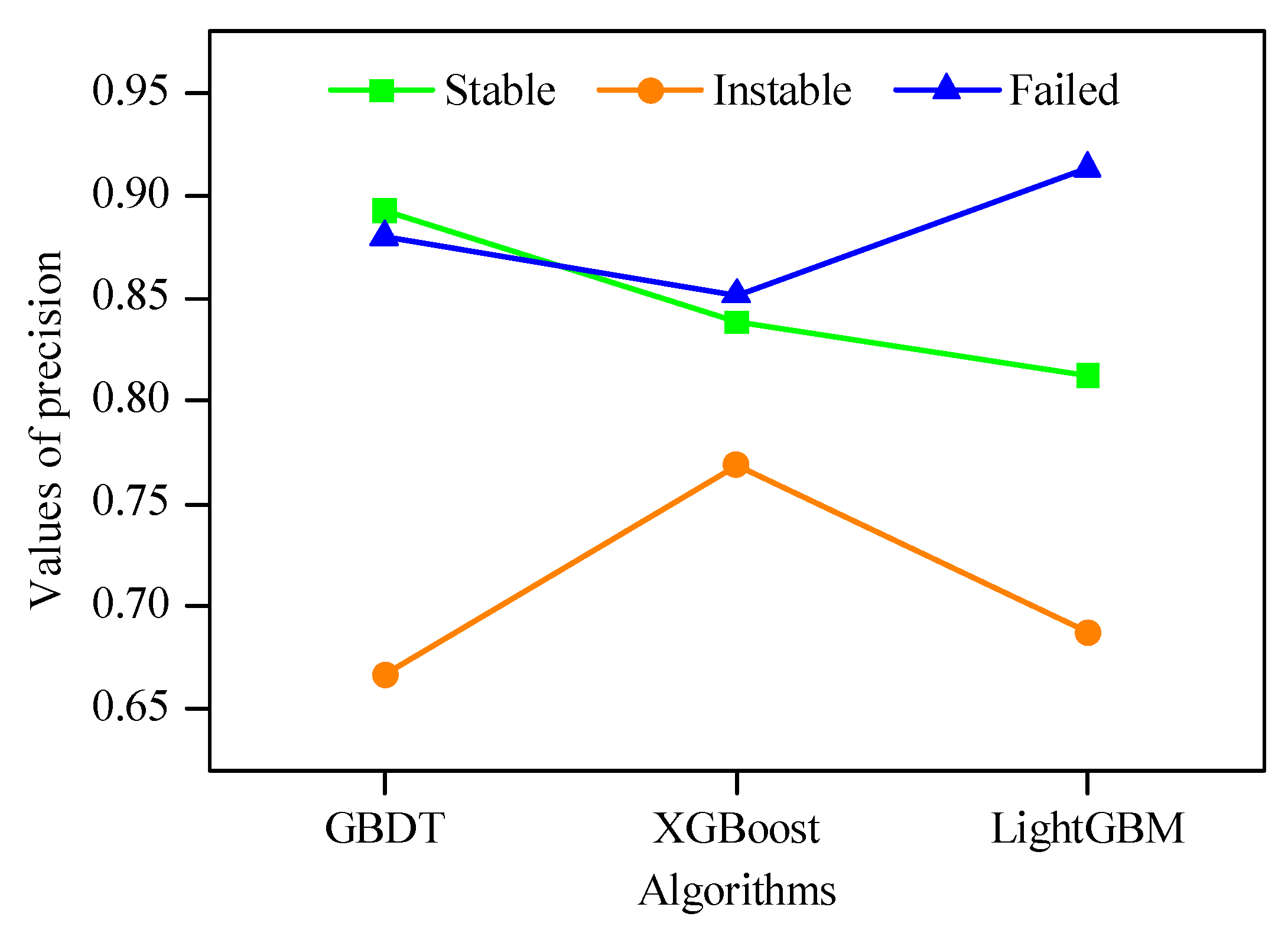
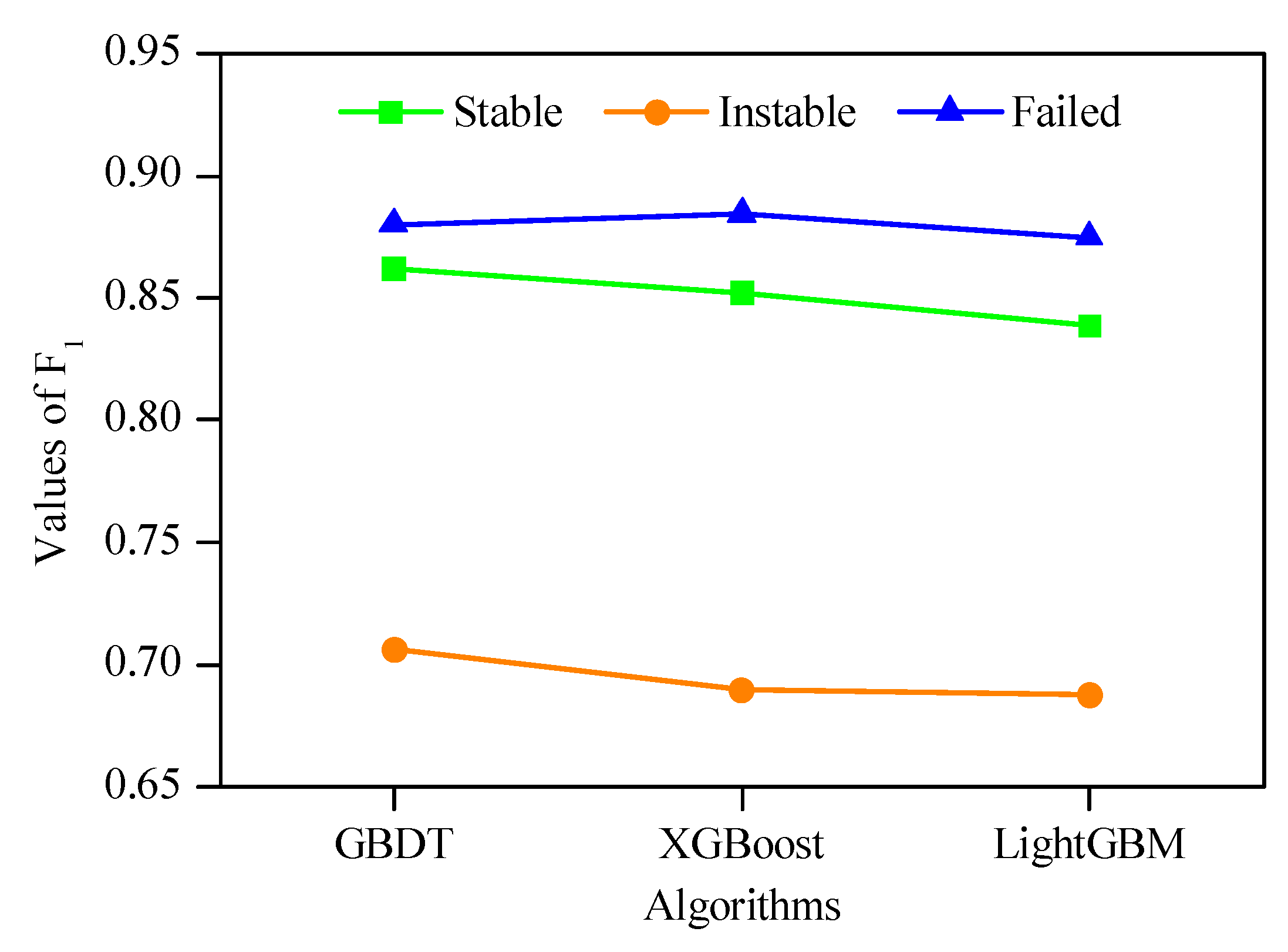
5.2. Prediction Results of Each Stability
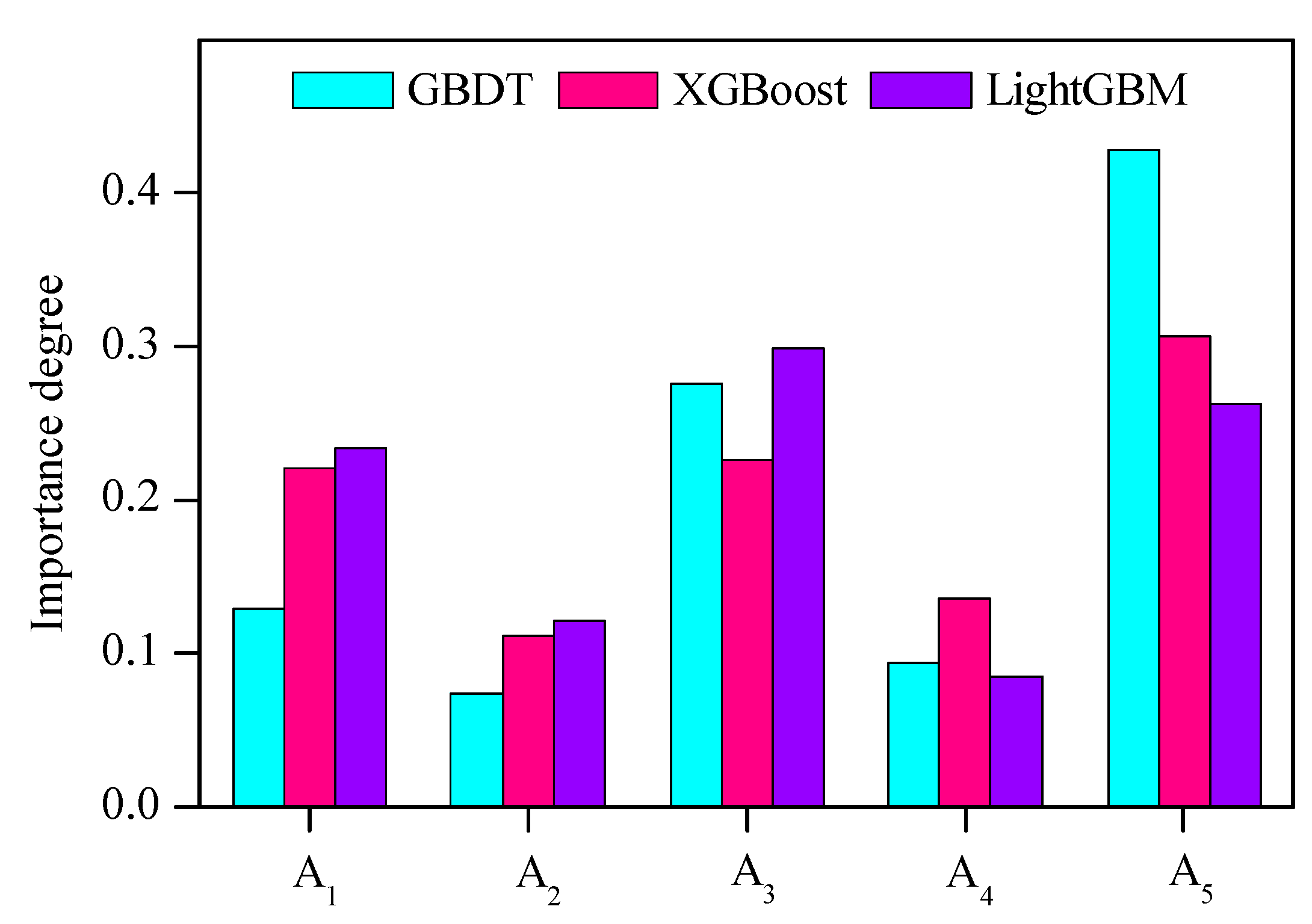
5.3. Relative Importance of Indicators
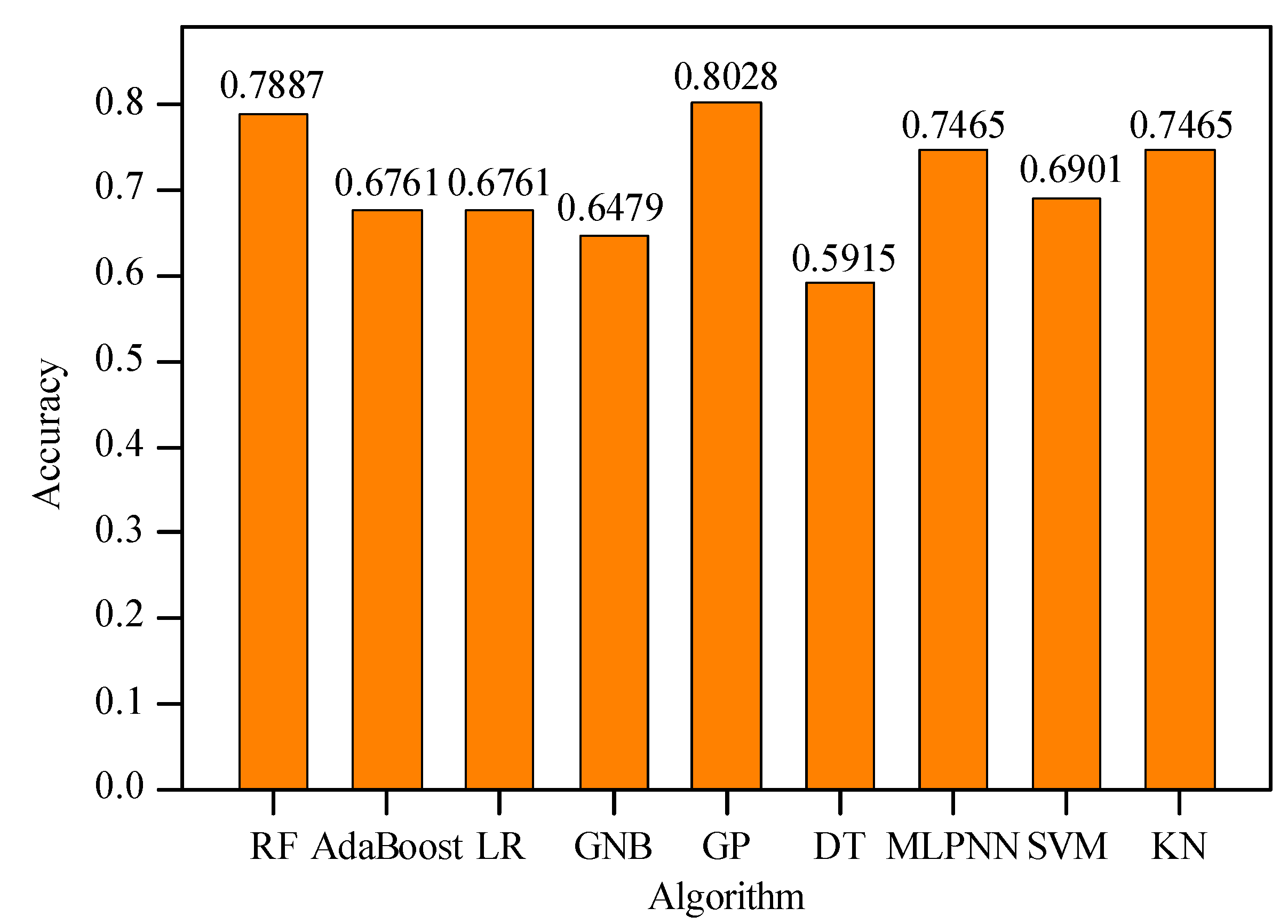
6. Discussions
- (1)
- The dataset is relatively small and unbalanced. The prediction performance of ML algorithms is heavily affected by the number and quality of dataset. Generally, if the dataset is small, the generalization and reliability of model would be influenced. Although GBDT, XGBoost, and LightGBM algorithms work well with small datasets, the prediction performances could be better on a larger dataset. In addition, the dataset is unbalanced, particularly for samples with instable level. Compared with other levels, the prediction performance for the instable level is not good. This illustrates the adverse effects of imbalanced data on results. Therefore, it is meaningful to establish a larger and more balanced pillar stability database.
- (2)
- Other indicators may also have influences on the prediction results. Pillar stability is affected by numerous factors, including the inherent characteristics and external environments. Although the five indictors adopted in this study can describe the necessary conditions of pillar stability to some extent, some other indicators may also have effects on pillar stability, such as joints, underground water, and blasting disturbance. Theoretically, the joints and underground water can affect the pillar strength, and blasting disturbance can be deemed as a dynamic stress on the pillar. Accordingly, it is significant to analyze the influences of these indicators on the prediction results.
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Ghasemi, E.; Ataei, M.; Shahriar, K. Prediction of global stability in room and pillar coal mines. Nat. Hazards 2014, 72, 405–422. [Google Scholar] [CrossRef]
- Liang, W.Z.; Dai, B.; Zhao, G.Y.; Wu, H. Assessing the Performance of Green Mines via a Hesitant Fuzzy ORESTE–QUALIFLEX Method. Mathematics 2019, 7, 788. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.A.; Shang, X.C.; Ma, H.T. Investigation of catastrophic ground collapse in Xingtai gypsum mines in China. Int. J. Rock Mech. Min. 2008, 45, 1480–1499. [Google Scholar] [CrossRef]
- Zhou, Y.J.; Li, M.; Xu, X.D.; Li, X.T.; Ma, Y.D.; Ma, Z. Research on catastrophic pillar instability in room and pillar gypsum mining. Sustainability 2018, 10, 3773. [Google Scholar] [CrossRef] [Green Version]
- Liang, W.Z.; Zhao, G.Y.; Wu, H.; Chen, Y. Assessing the risk degree of goafs by employing hybrid TODIM method under uncertainty. B. Eng. Geol. Environ. 2019, 78, 3767–3782. [Google Scholar] [CrossRef]
- Peng, K.; Liu,, Z.P.; Zou, Q.L.; Zhang, Z.Y.; Zhou, J.Q. Static and dynamic mechanical properties of granite from various burial depths. Rock Mech. Rock Eng. 2019, 52, 3545–3566. [Google Scholar]
- Luo, S.Z.; Liang, W.Z.; Xing, L.N. Selection of mine development scheme based on similarity measure under fuzzy environment. Neural Comput. Appl. 2019, 32, 5255–5266. [Google Scholar] [CrossRef]
- González-Nicieza, C.; Álvarez-Fernández, M.I.; Menéndez-Díaz, A.; Alvarez-Vigil, A.E. A comparative analysis of pillar design methods and its application to marble mines. Rock Mech. Rock Eng. 2006, 39, 421–444. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Comparative performance of six supervised learning methods for the development of models of hard rock pillar stability prediction. Nat. Hazards 2015, 79, 291–316. [Google Scholar] [CrossRef]
- Lunder, P.J. Hard Rock Pillar Strength Estimation: An Applied Empirical Approach. Master’s Thesis, University of British Columbia, Vancouver, BC, Canada, 1994. [Google Scholar]
- Cauvin, M.; Verdel, T.; Salmon, R. Modeling uncertainties in mining pillar stability analysis. Risk Anal. 2009, 29, 1371–1380. [Google Scholar] [CrossRef]
- Mortazavi, A.; Hassani, F.P.; Shabani, M. A numerical investigation of rock pillar failure mechanism in underground openings. Comput. Geotech. 2009, 36, 691–697. [Google Scholar] [CrossRef]
- Shnorhokian, S.; Mitri, H.S.; Moreau-Verlaan, L. Stability assessment of stope sequence scenarios in a diminishing ore pillar. Int. J. Rock Mech. Min. 2015, 74, 103–118. [Google Scholar] [CrossRef]
- Elmo, D.; Stead, D. An integrated numerical modelling–discrete fracture network approach applied to the characterisation of rock mass strength of naturally fractured pillars. Rock Mech. Rock Eng. 2010, 43, 3–19. [Google Scholar] [CrossRef]
- Li, L.C.; Tang, C.A.; Wang, S.Y.; Yu, J. A coupled thermo-hydrologic-mechanical damage model and associated application in a stability analysis on a rock pillar. Tunn. Undergr. Space Technol. 2013, 34, 38–53. [Google Scholar] [CrossRef]
- Jaiswal, A.; Sharma, S.K.; Shrivastva, B.K. Numerical modeling study of asymmetry in the induced stresses over coal mine pillars with advancement of the goaf line. Int. J. Rock Mech. Min. 2004, 41, 859–864. [Google Scholar] [CrossRef]
- Li, X.Y.; Kim, E.; Walton, G. A study of rock pillar behaviors in laboratory and in-situ scales using combined finite-discrete element method models. Int. J. Rock Mech. Min. 2019, 118, 21–32. [Google Scholar] [CrossRef]
- Liang, W.Z.; Zhao, G.Y.; Wang, X.; Zhao, J.; Ma, C.D. Assessing the rockburst risk for deep shafts via distance-based multi-criteria decision making approaches with hesitant fuzzy information. Eng. Geol. 2019, 260, 105211. [Google Scholar] [CrossRef]
- Deng, J.; Yue, Z.Q.; Tham, L.G.; Zhu, H.H. Pillar design by combining finite element methods, neural networks and reliability: A case study of the Feng Huangshan copper mine, China. Int. J. Rock Mech. Min. 2003, 40, 585–599. [Google Scholar] [CrossRef]
- Griffiths, D.V.; Fenton, G.A.; Lemons, C.B. Probabilistic analysis of underground pillar stability. Int. J. Numer. Anal. Met. 2002, 26, 775–791. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, V.; Picariello, A.; Sperli’ì, G. Extreme events management using multimedia social networks. Future Gener. Comput. Syst. 2019, 94, 444–452. [Google Scholar] [CrossRef]
- Tawadrous, A.S.; Katsabanis, P.D. Prediction of surface crown pillar stability using artificial neural networks. Int. J. Numer. Anal. Met. 2007, 31, 917–931. [Google Scholar] [CrossRef]
- Wattimena, R.K. Predicting the stability of hard rock pillars using multinomial logistic regression. Int. J. Rock Mech. Min. 2014, 71, 33–40. [Google Scholar] [CrossRef]
- Ding, H.X.; Li, G.H.; Dong, X.; Lin, Y. Prediction of pillar stability for underground mines using the stochastic gradient boosting technique. IEEE Access 2018, 6, 69253–69264. [Google Scholar]
- Ghasemi, E.; Kalhori, H.; Bagherpour, R. Stability assessment of hard rock pillars using two intelligent classification techniques: A comparative study. Tunn. Undergr. Space Technol 2017, 68, 32–37. [Google Scholar] [CrossRef]
- Sun, R.; Wang, G.Y.; Zhang, W.Y.; Hsu, L.T.; Ochieng, W.Y. A gradient boosting decision tree based GPS signal reception classification algorithm. Appl. Soft Comput. 2020, 86, 105942. [Google Scholar] [CrossRef]
- Lombardo, L.; Cama, M.; Conoscenti, C.; Märker, M.; Rotigliano, E.J.N.H. Binary logistic regression versus stochastic gradient boosted decision trees in assessing landslide susceptibility for multiple-occurring landslide events: Application to the 2009 storm event in Messina (Sicily, southern Italy). Nat. Hazards 2015, 79, 1621–1648. [Google Scholar] [CrossRef]
- Tama, B.A.; Rhee, K.H. An in-depth experimental study of anomaly detection using gradient boosted machine. Neural Comput. Appl. 2019, 31, 955–965. [Google Scholar] [CrossRef]
- Sachdeva, S.; Bhatia, T.; Verma, A.K. GIS-based evolutionary optimized gradient boosted decision trees for forest fire susceptibility mapping. Nat. Hazards 2018, 92, 1399–1418. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.L.; Meng, Q.; Finley, T.; Wang, T.F.; Chen, W.; Ma, W.D.; Ye, Q.W.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Esterhuizen, G.S.; Dolinar, D.R.; Ellenberger, J.L. Pillar strength in underground stone mines in the United States. Int. J. Rock Mech. Min. 2011, 48, 42–50. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Rao, H.D.; Shi, X.Z.; Rodrigue, A.K.; Feng, J.J.; Xia, Y.C.; Elhoseny, M.; Yuan, X.H.; Gu, L.C. Feature selection based on artificial bee colony and gradient boosting decision tree. Appl. Soft Comput. 2019, 74, 634–642. [Google Scholar] [CrossRef]
- Website of the Kaggle. Available online: https://www.kaggle.com/ (accessed on 3 May 2020).
- Zeng, H.; Yang, C.; Zhang, H.; Wu, Z.H.; Zhang, J.M.; Dai, G.J.; Babiloni, F.; Kong, W.Z. A lightGBM-based EEG analysis method for driver mental states classification. Comput. Intel. Neurosc. 2019, 2019, 3761203. [Google Scholar] [CrossRef] [PubMed]
- Kodaz, H.; Özşen, S.; Arslan, A.; Güneş, S. Medical application of information gain based artificial immune recognition system (AIRS): Diagnosis of thyroid disease. Expert Syst. Appl. 2009, 36, 3086–3092. [Google Scholar] [CrossRef]
- Weng, T.Y.; Liu, W.Y.; Xiao, J. Supply chain sales forecasting based on lightGBM and LSTM combination model. Ind. Manage. Data Syst. 2019, 120, 265–279. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Website of the XGBoost Library. Available online: https://xgboost.readthedocs.io/en/latest/ (accessed on 3 May 2020).
- Website of the LightGBM Library. Available online: https://lightgbm.readthedocs.io/en/latest/ (accessed on 3 May 2020).
- Kumar, P. Machine Learning Quick Reference; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Jung, Y. Multiple predicting K-fold cross-validation for model selection. J. Nonparametr. Stat. 2018, 30, 197–215. [Google Scholar] [CrossRef]
- Lunder, P.J.; Pakalnis, R.C. Determination of the strength of hard-rock mine pillars. CIM Bull. 1997, 90, 51–55. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Samples | A1 (m) | A2 (m) | A3 | A4 (MPa) | A5 (MPa) | Level |
|---|---|---|---|---|---|---|
| 1 | 5.9 | 4 | 1.48 | 172 | 49.6 | Stable |
| 2 | 7.2 | 4 | 1.8 | 172 | 56.7 | Stable |
| 3 | 7.8 | 4 | 1.95 | 172 | 99.9 | Unstable |
| … | … | … | … | … | … | … |
| 234 | 14.25 | 18 | 0.79 | 104 | 5.33 | Unstable |
| 235 | 13 | 17 | 0.76 | 104 | 16.67 | Stable |
| 236 | 7.75 | 11 | 0.70 | 104 | 4.57 | Unstable |
| Samples | A1 (m) | A2 (m) | A3 | A4 (MPa) | A5 (MPa) |
|---|---|---|---|---|---|
| Minimum | 1.90 | 2.4 | 0.21 | 61 | 0.14 |
| Maximum | 45 | 61 | 4.50 | 316 | 127.60 |
| Mean | 11.51 | 12.58 | 1.17 | 141.06 | 41.50 |
| Standard deviation | 7.75 | 11.34 | 0.61 | 64.62 | 31.42 |
| Algorithm | Hyperparameters | Meanings | Search Ranges | Optimal Values |
|---|---|---|---|---|
| GBDC | n_estimators | Number of trees | (1000, 2000) | 1200 |
| learning_rate | Shrinkage coefficient of each tree | (0.01, 0.2) | 0.17 | |
| max_depth | Maximum depth of a tree | (10, 100) | 20 | |
| min_samples_leaf | Minimum number of samples for leaf nodes | (2, 11) | 7 | |
| min_samples_split | Minimum number of samples for nodes split | (2, 11) | 7 | |
| XGBoost | n_estimators | Number of trees | (1000, 2000) | 1000 |
| learning_rate | Shrinkage coefficient of each tree | (0.01, 0.2) | 0.2 | |
| max_depth | Maximum depth of a tree | (10, 100) | 50 | |
| colsample_bytree | Subsample ratio of columns for tree construction | (0.1, 1) | 1 | |
| subsample | Subsample ratio of training samples | (0.1, 1) | 0.3 | |
| LightGBM | n_estimators | Number of trees | (1000, 2000) | 1900 |
| learning_rate | Shrinkage coefficient of each tree | (0.01, 0.2) | 0.2 | |
| max_depth | Maximum depth of a tree | (10, 100) | 80 | |
| num_leaves | Number of leaves for each tree | (2, 100) | 11 |
| Predicted | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GBDT | XGBoost | LightGBM | ||||||||
| 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | ||
| True | 1 | 25 | 4 | 1 | 26 | 2 | 2 | 26 | 3 | 1 |
| 2 | 2 | 12 | 2 | 4 | 10 | 2 | 4 | 11 | 1 | |
| 3 | 1 | 2 | 22 | 1 | 1 | 23 | 2 | 2 | 21 | |
| Accuracy | ||||
|---|---|---|---|---|
| GBDT | 0.8310 | 0.8132 | 0.8211 | 0.8160 |
| XGBoost | 0.8310 | 0.8199 | 0.8039 | 0.8089 |
| LightGBM | 0.8169 | 0.8043 | 0.7981 | 0.8004 |
| Algorithm | Hyperparameters | Meanings | Search Range | Optimal Values |
|---|---|---|---|---|
| RF | n_estimators | Number of trees | (1000, 2000) | 1100 |
| min_samples_split | Minimum number of samples for nodes split | (2, 11) | 4 | |
| max_depth | Maximum depth of a tree | (10, 100) | 20 | |
| min_samples_leaf | Minimum number of samples for leaf nodes | (2, 11) | 2 | |
| AdaBoost | n_estimators | Number of trees | (1000, 2000) | 1200 |
| learning_rate | Shrinkage coefficient of each tree | (0.01, 0.2) | 0.01 | |
| LR | penalty | Norm used in the penalization | {l1, l2} | l2 |
| Inverse of regularization strength | (0.1, 10) | 1.0 | ||
| GNB | ||||
| GP | Parameter of radial basis function () | (0.1, 2.0) | 0.9 | |
| Parameter of radial basis function () | (0.1, 2.0) | 0.3 | ||
| DT | min_samples_split | Minimum number of samples for nodes split | (2, 11) | 4 |
| max_depth | Maximum depth of a tree | (10, 100) | 80 | |
| min_samples_leaf | Minimum number of samples for leaf nodes | (2, 11) | 4 | |
| MLPNN | hidden_layer_sizes | Number of neurons in the hidden layer | (10, 100) | 87 |
| learning_rate_init | Initial learning rate for weight updates | (0.0001,0.002) | 0.0019 | |
| SVM | Regularization parameter | (0.1, 10) | 1.2 | |
| KNN | n_neighbors | Number of neighbors | (1, 20) | 3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, W.; Luo, S.; Zhao, G.; Wu, H. Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics 2020, 8, 765. https://doi.org/10.3390/math8050765
Liang W, Luo S, Zhao G, Wu H. Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics. 2020; 8(5):765. https://doi.org/10.3390/math8050765
Chicago/Turabian StyleLiang, Weizhang, Suizhi Luo, Guoyan Zhao, and Hao Wu. 2020. "Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms" Mathematics 8, no. 5: 765. https://doi.org/10.3390/math8050765
APA StyleLiang, W., Luo, S., Zhao, G., & Wu, H. (2020). Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics, 8(5), 765. https://doi.org/10.3390/math8050765