When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria


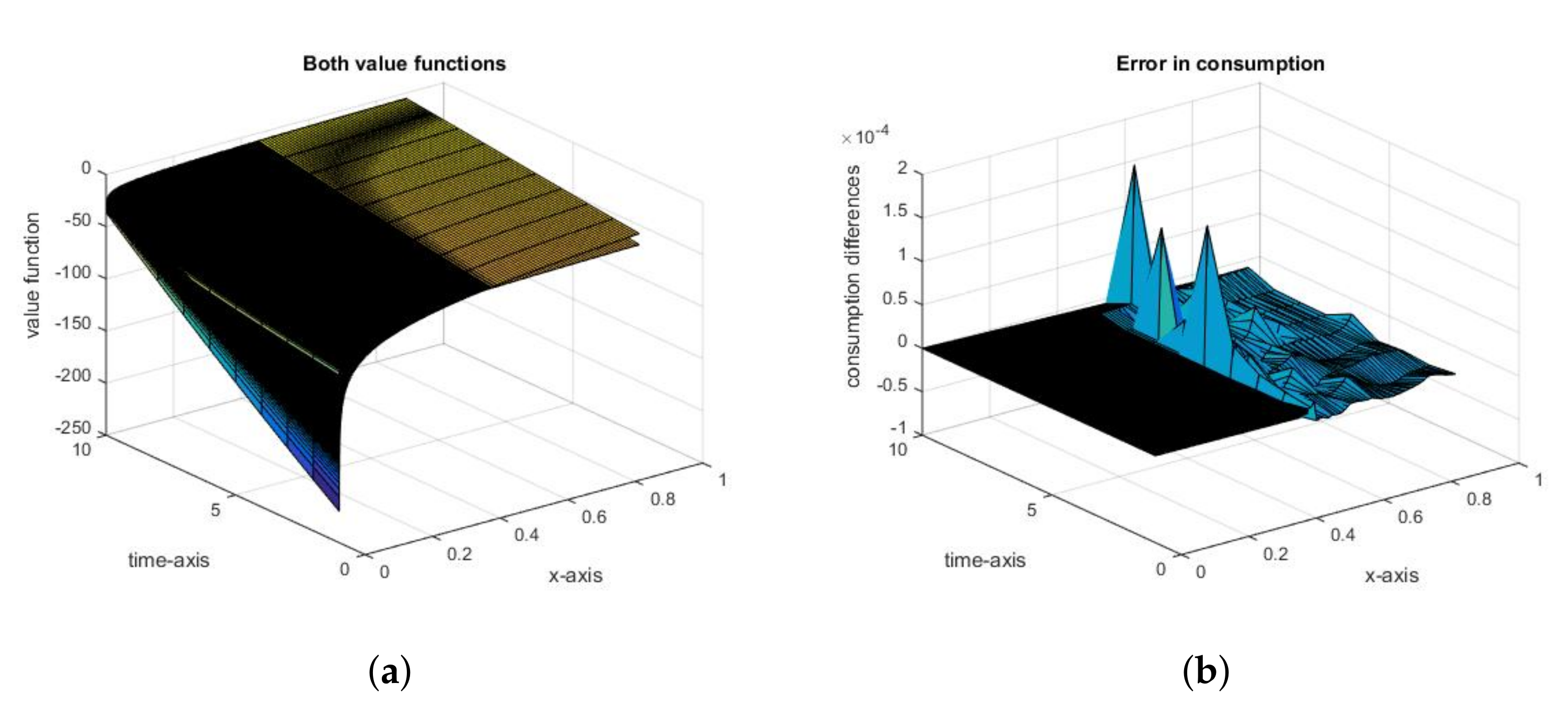{kind=link}
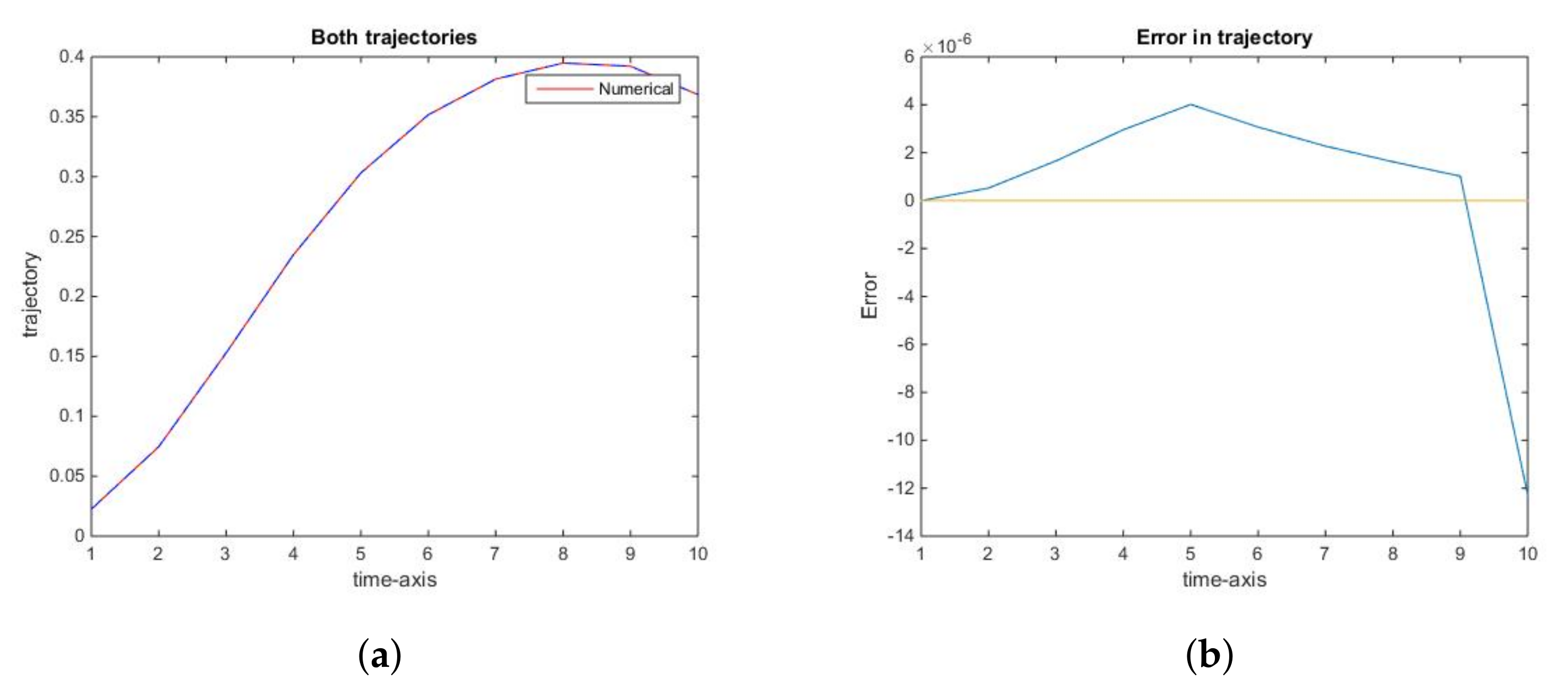{kind=link}
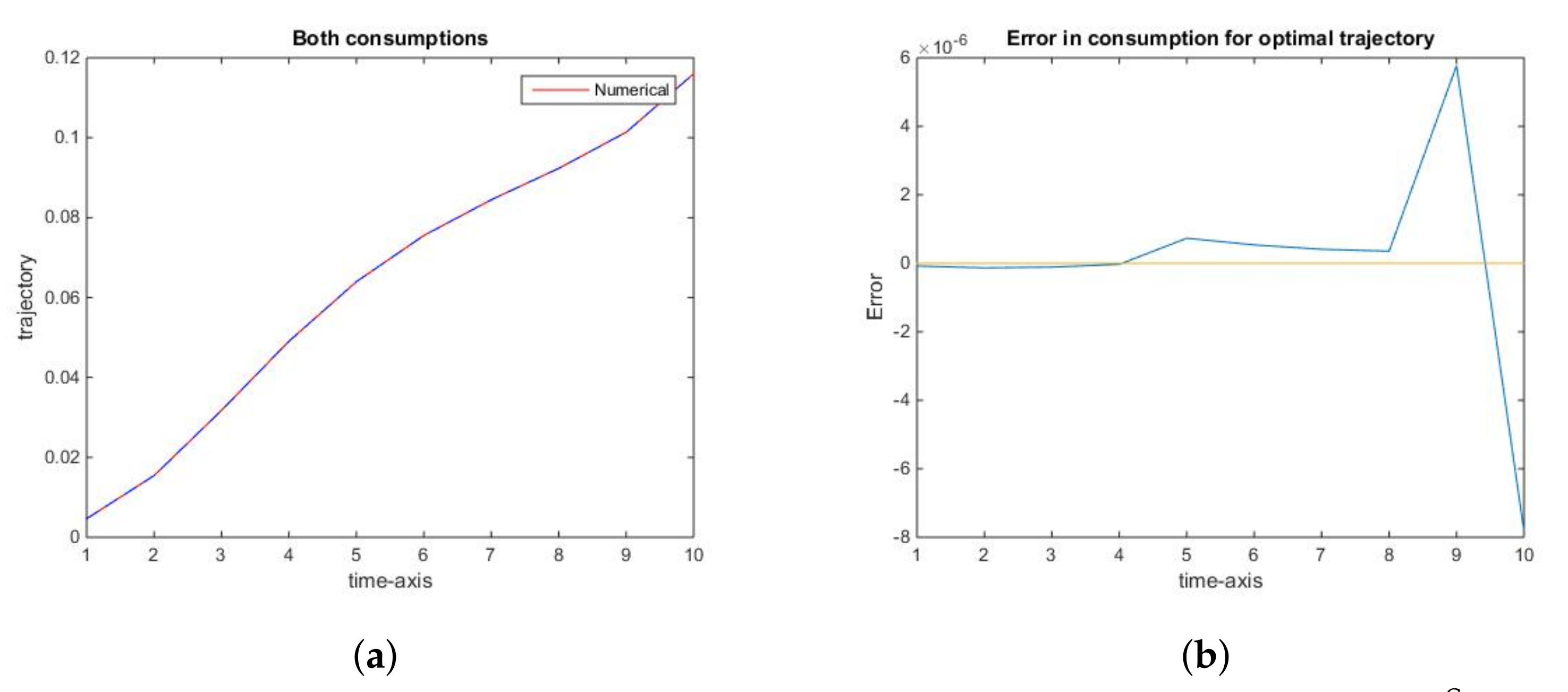{kind=link}
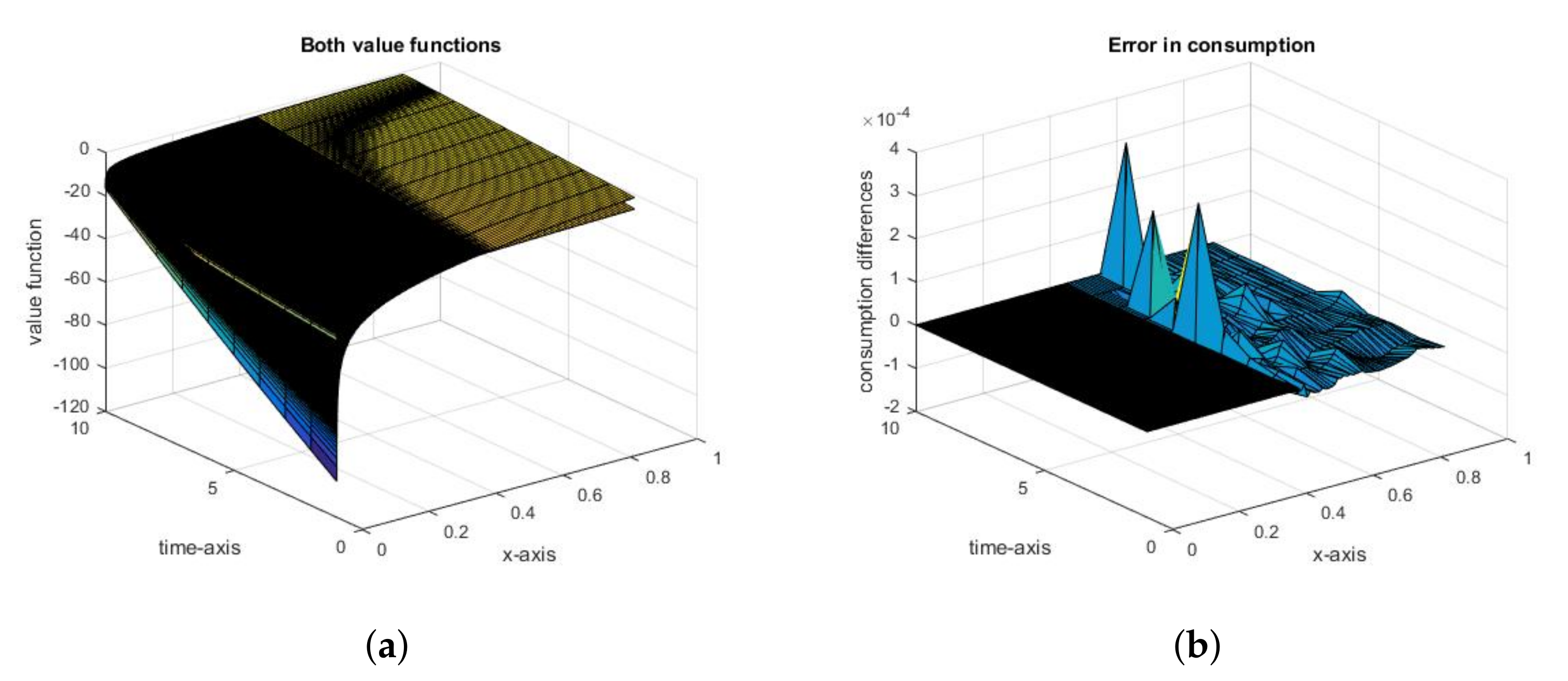{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Motivating Example—Fish Wars—The Optima and Equilibria
2.1. Analytic Solutions
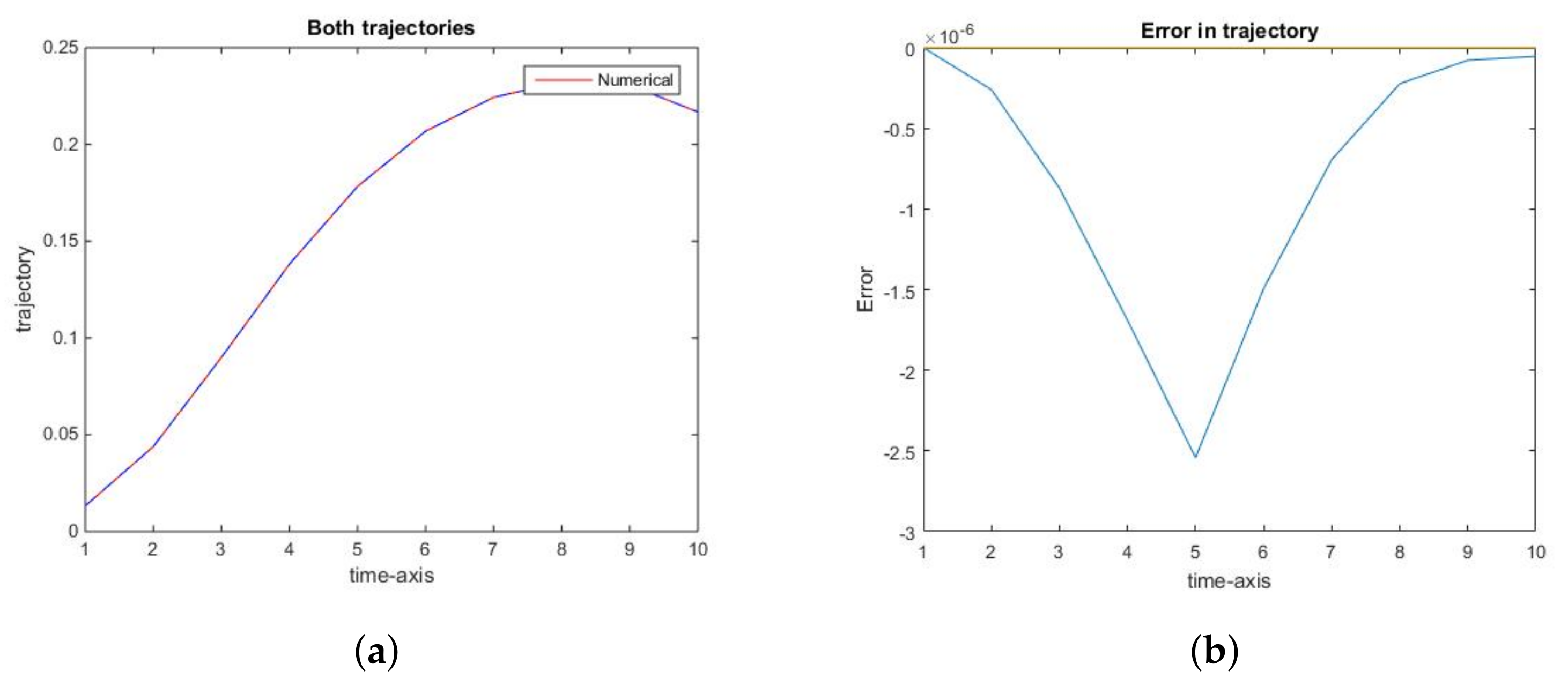
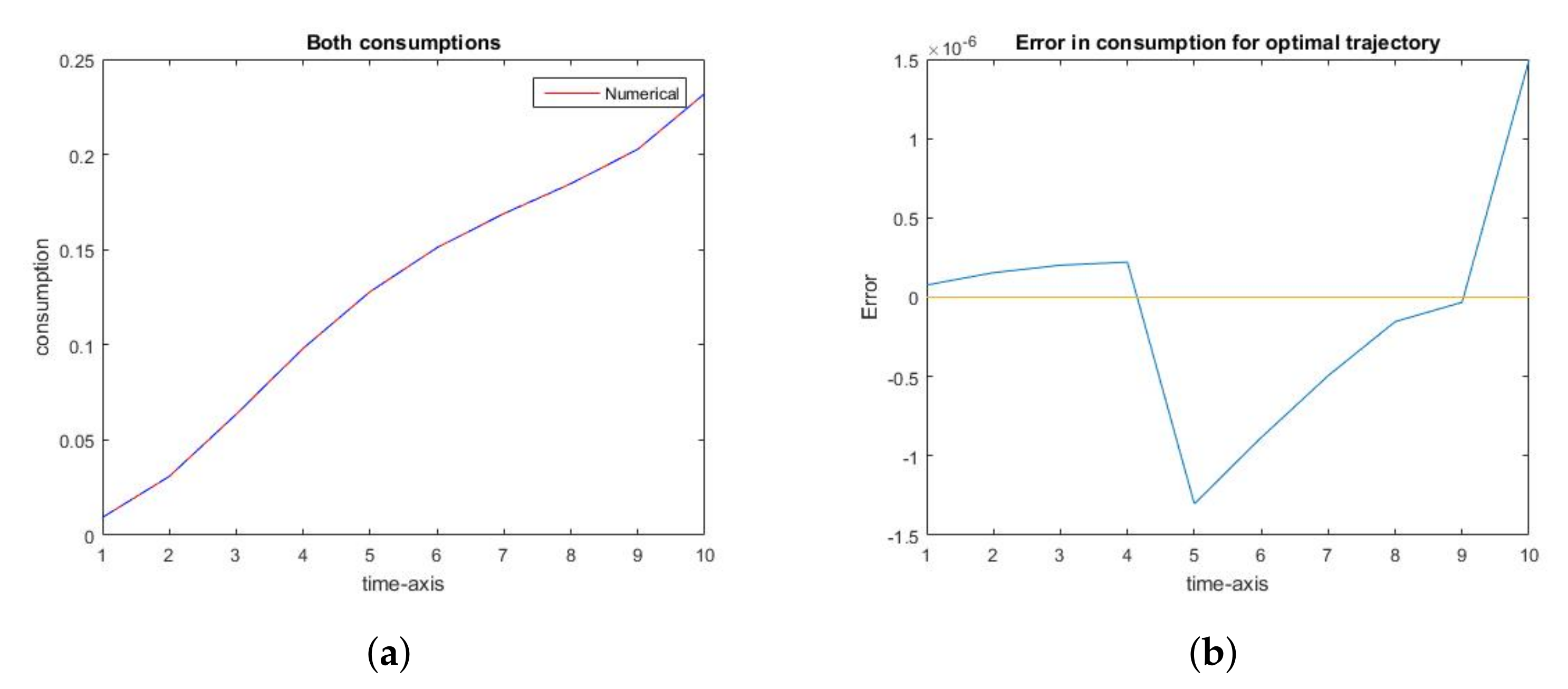
2.2. Comparison of Analytic and Numerical Results
2.2.1. The Social Optimum
2.2.2. Nash Equilibrium
2.3. General Conclusions from the Analysis of the Fish Wars Example
3. When and What Kind of Inaccuracies in Computation or Calculation of the Value Function Do Not Propagate on the Optimal Path in Dynamic Optimization Problems
- with the time set or , denoted by ; the finite or infinite horizon is denoted by T;
- with discount factor ;
- the set of states ;
- the set of control parameters ;
- the current payoff function ;
- where we consider the feedback controls (which, if independent of time, are denoted as )
- with admissibility constraint for all and for ; the set of admissible controls is denoted by , and
- the transformation of the state variable is given by a function or, more generallywith for all with . In the latter case, there is no need to specify , as it does not influence the results.
- In the case when the time horizon is finite, we also consider a terminal payoff given by a function , paid after the termination of the game.
- for the infinite time horizon, while
- for a finite time horizon T,
- where the trajectory X corresponding to c is given bywith the initial condition .
- Whenever we want to emphasize the dependence of X on a control c, we write , if we want to emphasize the dependence of X on the initial condition, we write , while if we want to emphasize both.
- We assume that the problem is such that J is always well defined although it may be .
- We restrict the set of initial conditions to .
- V—the actual value function of the dynamic optimization problem;
- —another function regarded as an approximation of V; it may be either a solution of a numerical procedure or the actual V with values on certain subsets replaced by another value, e.g., some constraint known a priori.
- —the maximized function on the right-hand side of the Bellman Equation bellman-general (as a function of c).
- —the maximized function on the right-hand side of the Bellman Equation (3) with V replaced by (as a function of c).
- —the set of optimal controls; we assume that it is non-empty.
- —the set of controls such that ; we assume that it is non-empty.
- .
- For , }.
- .
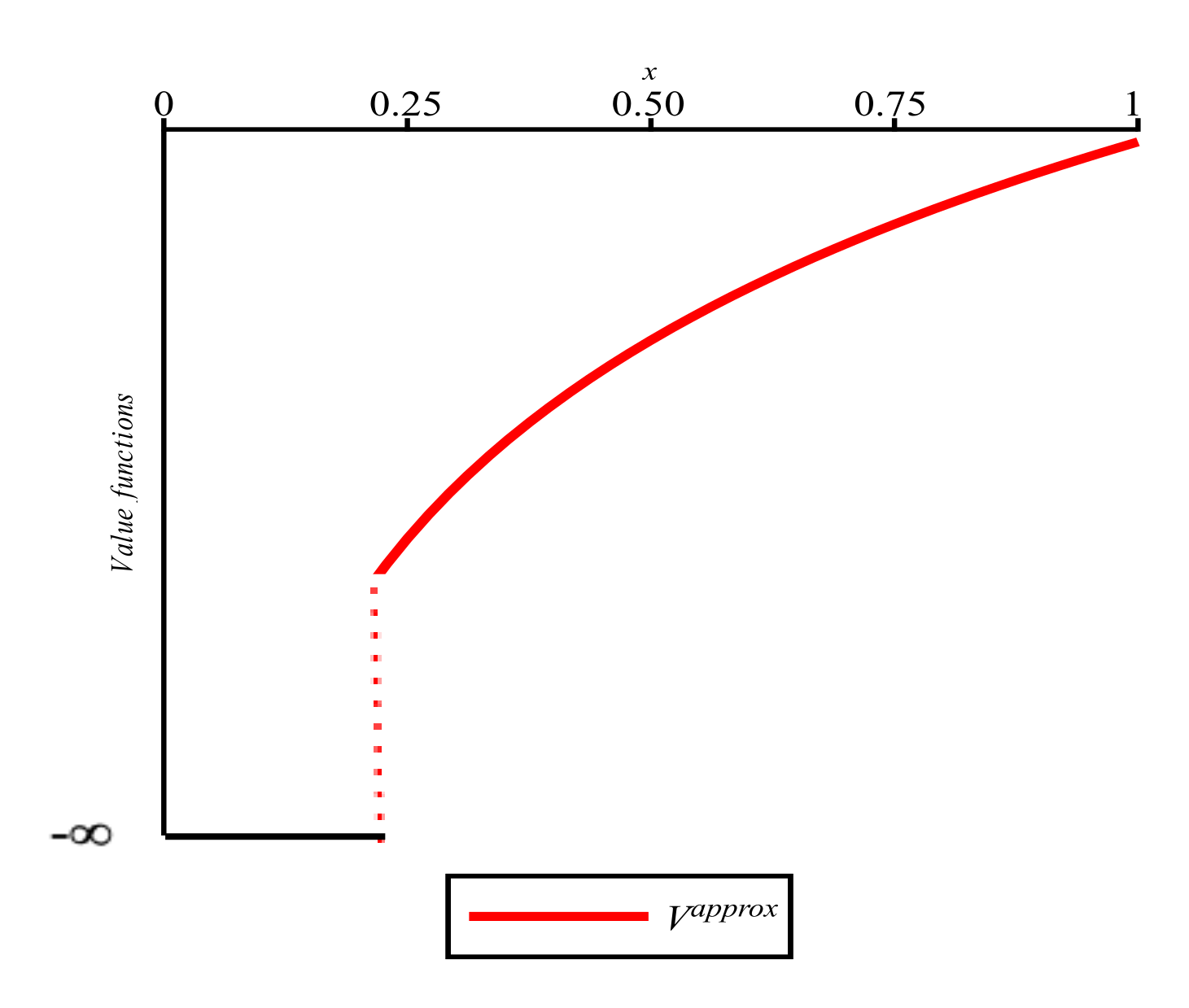
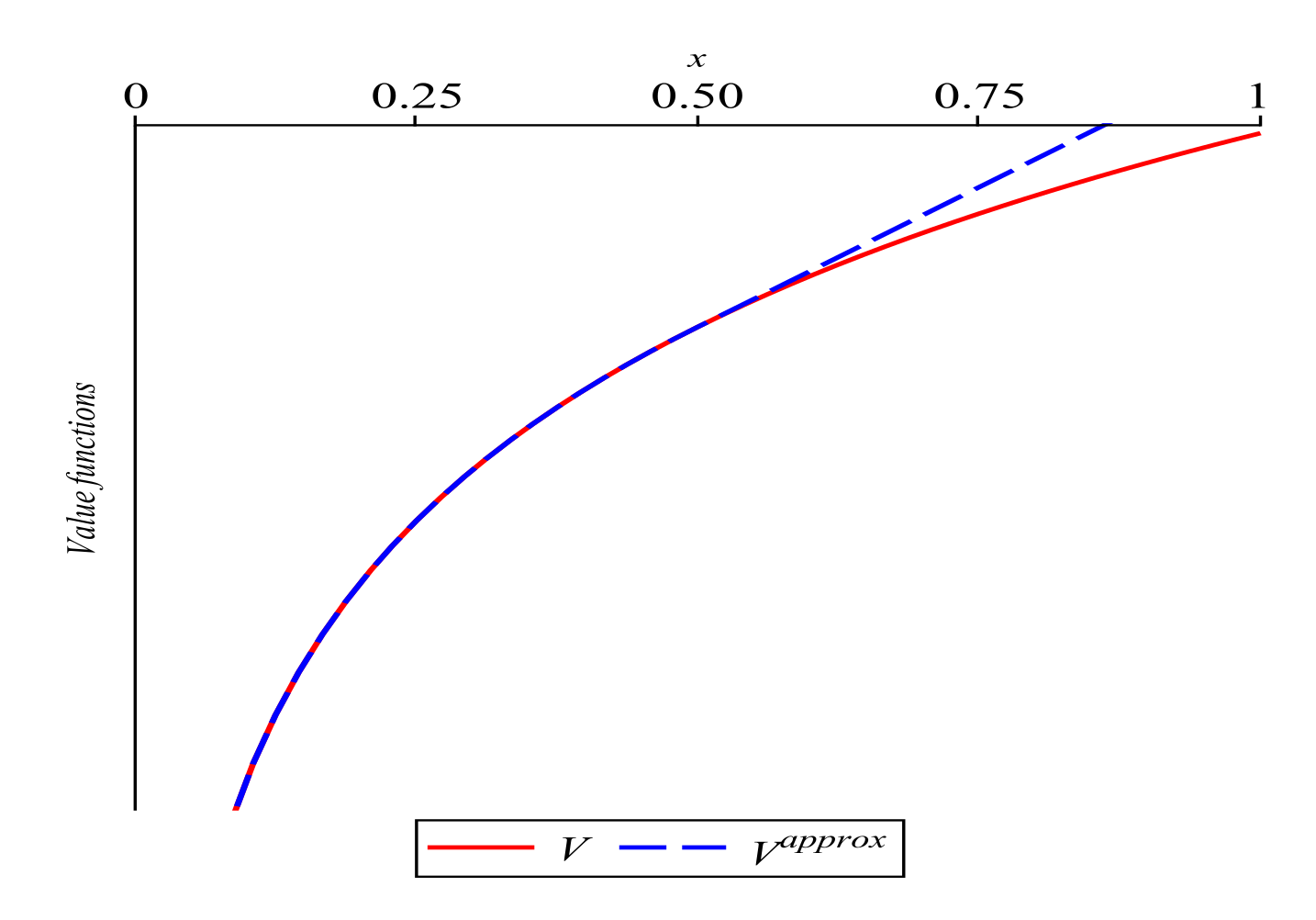
Illustration of Usefulness of Theorems 1 and 2 by Examples
4. When and What Kind of Inaccuracies in Computation or Calculation of the Value Functions Do Not Propagate on the Nash Equilibrium Path in Dynamic Games
- with n players;
- with finite or infinite horizon T;
- the time set or is denoted by ;
- with discount factor ;
- the set of states ;
- players’ sets of decisions
- with notation and ;
- players’ current payoff functions ;
- where we consider feedback strategies (if independent of time, they are written as )
- which fulfill the admissibility constraint for all and for .
- We denote the set of admissible strategies of player i by , while the set of strategies of the remaining players by and the set of strategy profiles by ;
- For simplicity, we introduce the symbol to denote the profile at which player i chooses while the remaining players choose their strategies , which are their strategies resulting from ;
- the transformation of the state variable is determined by or, more generally,with for all with . Specifying is unnecessary since it does not influence the results.
- In the case when the time horizon is finite, we also consider terminal payoffs given by functions , paid after termination of the game.
- The payoff is in the case of the infinite time horizon
- and for finite time horizon T,
- where the trajectory X corresponding to a strategy profile c is given bywith the initial condition .
- Whenever we want to emphasize the dependence of X on a strategy of player i, we write , if we want to emphasize the dependence of X on the initial condition, we write , while if we want to emphasize both. If we also want to emphasize the strategies of the remaining players, we write , or whenever c denotes the whole profile.
- We assume that the problem is such that is always well defined although it may be .
- We restrict the initial condition to .
- —the actual value function of the dynamic optimization problem of player i given , i.e., .
- —another function regarded as approximation of ; it may be either a solution of a numerical procedure or the actual with values on certain subsets replaced by another values, e.g., some constraints; we assume a priori that, in the finite time horizon T, .
- —the maximized function on the right-hand side of the Bellman Equation (3) rewritten to maximization of player i given ;
- —the maximized function on the right-hand side of the Bellman Equation (3) rewritten to maximization of player i given with replaced by .
- —the set of strategies of player i which are best responses to ; we assume that it is non-empty;
- —the set of strategies such that; we assume that it is non-empty;
- For : ;
- For : ;
- ;
- .
- —a one stage game with strategies , and payoffs .
- —a one stage game with strategies , and payoffs .
- is the set of profiles from for which a Nash equilibrium in exists for each .We assume that , which is equivalent to the existence of a Nash equilibrium.
- is the set of profiles from for which a Nash equilibrium in exists for each .We assume that .
- by:
- –
- ,
- –
- being the set of profiles from for which a Nash equilibrium in exists for each .
- by
- –
- ,
- –
- being the set of profiles from for which a Nash equilibrium in exists for each .
- being the set of feedback Nash equilibria.
- being the set of profiles that fulfill, starting from T backwards, that is a Nash equilibrium of the static game .
5. Conclusions and Further Research
Author Contributions
Funding
Conflicts of Interest
Appendix A. Numerical Solutions for the Motivating Example
Appendix A.1. Computation of Social Optimum
| Algorithm A1. Computation of the social optimum. |
|
Appendix A.2. Computation of Nash Equilibria
| Algorithm A2. Computation of the Nash Equilibrium. |
|
References
- Stokey, N.L. Recursive Methods in Economic Dynamics; Harvard University Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Kamihigashi, T. On the principle of optimality for nonstationary deterministic dynamic programming. Int. J. Econ. Theory 2008, 4, 519–525. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A.; Singh, R. Infinite horizon dynamic optimization with unbounded returns—Necessity, sufficiency, existence, uniqueness, convergence and a sequence of counterexamples. SSRN Electron. J. 2018. [Google Scholar] [CrossRef]
- Martins-da Rocha, V.F.; Vailakis, Y. Existence and uniqueness of a fixed point for local contractions. Econometrica 2010, 78, 1127–1141. [Google Scholar] [CrossRef] [Green Version]
- Le Van, C.; Morhaim, L. Optimal growth models with bounded or unbounded returns: A unifying approach. J. Econ. Theory 2002, 105, 158–187. [Google Scholar] [CrossRef] [Green Version]
- Rincón-Zapatero, J.P.; Rodríguez-Palmero, C. Existence and uniqueness of solutions to the Bellman equation in the unbounded case. Econometrica 2003, 71, 1519–1555. [Google Scholar] [CrossRef] [Green Version]
- Matkowski, J.; Nowak, A. On discounted dynamic programming with unbounded returns. Econ. Theory 2011, 46, 455–474. [Google Scholar] [CrossRef] [Green Version]
- Kamihigashi, T. Elementary results on solutions to the Bellman equation of dynamic programming: Existence, uniqueness, and convergence. Econ. Theory 2014, 56, 251–273. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Wiszniewska-Matyszkiel, A. A class of linear quadratic dynamic optimization problems with state dependent constraints. Math. Methods Oper. Res. 2020, 91, 325–355. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Wiszniewska-Matyszkiel, A. Linear quadratic game of exploitation of common renewable resources with inherent constraints. Topol. Methods Nonl. Anal. 2018, 51, 23–54. [Google Scholar] [CrossRef]
- Bock, H.G. Nonlinear mixed-integer optimal control–from the Maximum Principle Approach to online computation of closed loop controls in real time. In Proceedings of the 14th Viennese Conference on Optimal Control and Dynamic Games, Vienna, Austria, 3–6 July 2018. [Google Scholar]
- Horwood, J.; Whittle, P. Optimal control in the neighbourhood of an optimal equilibrium with examples from fisheries models. Math. Med. Biol. A J. IMA 1986, 3, 129–142. [Google Scholar] [CrossRef]
- Horwood, J.; Whittle, P. The optimal harvest from a multicohort stock. Math. Med. Biol. A J. IMA 1986, 3, 143–155. [Google Scholar] [CrossRef]
- Krawczyk, J.B.; Tolwinski, B. A cooperative solution for the three-nation problem of exploitation of the southern bluefin tuna. Math. Med. Biol. A J. IMA 1993, 10, 135–147. [Google Scholar] [CrossRef]
- Levhari, D.; Mirman, L.J. The great fish war: An example using a dynamic Cournot-Nash solution. Bell J. Econ. 1980, 11, 322–334. [Google Scholar] [CrossRef]
- Okuguchi, K. A dynamic Cournot-Nash equilibrium in fishery: The effects of entry. Decis. Econ. Financ. 1981, 4, 59–64. [Google Scholar] [CrossRef]
- Mazalov, V.V.; Rettieva, A.N. Fish wars with many players. Int. Game Theory Rev. 2010, 12, 385–405. [Google Scholar] [CrossRef]
- Mazalov, V.V.; Rettieva, A.N. The compleat fish wars with changing area for fishery. IFAC Proc. Vol. 2009, 42, 168–172. [Google Scholar] [CrossRef]
- Rettieva, A. A discrete-time bioresource management problem with asymmetric players. Autom. Remote Control 2014, 75, 1665–1676. [Google Scholar] [CrossRef]
- Nowak, A.S. Equilibrium in a dynamic game of capital accumulation with the overtaking criterion. Econ. Lett. 2008, 99, 233–237. [Google Scholar] [CrossRef]
- Nowak, A.S. A note on an equilibrium in the great fish war game. Econ. Bull. 2006, 17, 1–10. [Google Scholar]
- Fischer, R.D.; Mirman, L.J. Strategic dynamic interaction: Fish wars. J. Econ. Dyn. Control 1992, 16, 267–287. [Google Scholar] [CrossRef]
- Fischer, R.D.; Mirman, L.J. The compleat fish wars: Biological and dynamic interactions. J. Environ. Econ. Manag. 1996, 30, 34–42. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A. A Dynamic Game with Continuum of Players and Its Counterpart with Finitely Many Players. In Advances in Dynamic Games; Springer: Berlin, Germany, 2005; pp. 455–469. [Google Scholar]
- Wiszniewska-Matyszkiel, A. Open and closed loop Nash equilibria in games with a continuum of players. J. Optim. Theory Appl. 2014, 160, 280–301. [Google Scholar] [CrossRef] [Green Version]
- Kwon, O.S. Partial international coordination in the great fish war. Environ. Resour. Econ. 2006, 33, 463–483. [Google Scholar] [CrossRef]
- Breton, M.; Keoula, M.Y. Farsightedness in a coalitional great fish war. Environ. Resour. Econ. 2012, 51, 297–315. [Google Scholar] [CrossRef]
- Breton, M.; Keoula, M.Y. A great fish war model with asymmetric players. Ecol. Econ. 2014, 97, 209–223. [Google Scholar] [CrossRef]
- Koulovatianos, C. Strategic exploitation of a common-property resource under rational learning about its reproduction. Dyn. Games Appl. 2015, 5, 94–119. [Google Scholar] [CrossRef]
- Dutta, P.K.; Sundaram, R.K. The tragedy of the commons? Econ. Theory 1993, 3, 413–426. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A. When beliefs about future create future—Exploitation of a common ecosystem from a new perspective. Strat. Behav. Environ. 2014, 4, 237–261. [Google Scholar] [CrossRef]
- Wiszniewska-Matyszkiel, A. Belief distorted Nash equilibria: Introduction of a new kind of equilibrium in dynamic games with distorted information. Ann. Oper. Res. 2016, 243, 147–177. [Google Scholar] [CrossRef] [Green Version]
- Wiszniewska-Matyszkiel, A. Common resources, optimality and taxes in dynamic games with increasing number of players. J. Math. Anal. Appl. 2008, 337, 840–861. [Google Scholar] [CrossRef] [Green Version]
- Hannesson, R. Fishing as a Supergame. J. Environ. Econ. Manag. 1997, 32, 309–322. [Google Scholar] [CrossRef]
- Górniewicz, O.; Wiszniewska-Matyszkiel, A. Verification and refinement of a two species Fish Wars model. Fisheries Res. 2018, 203, 22–34. [Google Scholar] [CrossRef]
- Breton, M.; Dahmouni, I.; Zaccour, G. Equilibria in a two-species fishery. Math. Biosci. 2019, 309, 78–91. [Google Scholar] [CrossRef] [PubMed]
- Carraro, C.; Filar, J. Control and Game-Theoretic Models of the Environment; Springer Science & Business Media: Berlin, Germany, 2012; Volume 2. [Google Scholar]
- Van Long, N. Dynamic games in the economics of natural resources: A survey. Dyn. Games Appl. 2011, 1, 115–148. [Google Scholar] [CrossRef]
- Van Long, N. Applications of dynamic games to global and transboundary environmental issues: A review of the literature. Strat. Behav. Environ. 2012, 2, 1–59. [Google Scholar] [CrossRef]
- Haurie, A.; Krawczyk, J.B.; Zaccour, G. Games and Dynamic Games; World Scientific Publishing Company: Singapore, 2012; Volume 1. [Google Scholar]
- Singh, R. Calculation of Optima and Equilibria in Dynamic Resource Extraction Problems. Available online: https://depotuw.ceon.pl/handle/item/3317 (accessed on 16 May 2020).
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Blackwell, D. Discounted dynamic programming. Ann. Math. Stat. 1965, 36, 226–235. [Google Scholar] [CrossRef]
- Başar, T.; Olsder, G.J. Dynamic Noncooperative Game Theory; SIAM: Bangkok, Thailand, 1998. [Google Scholar]
- Wiszniewska-Matyszkiel, A. On the terminal condition for the Bellman equation for dynamic optimization with an infinite horizon. Appl. Math. Lett. 2011, 24, 943–949. [Google Scholar] [CrossRef] [Green Version]








© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wiszniewska-Matyszkiel, A.; Singh, R. When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria. Mathematics 2020, 8, 1109. https://doi.org/10.3390/math8071109
Wiszniewska-Matyszkiel A, Singh R. When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria. Mathematics. 2020; 8(7):1109. https://doi.org/10.3390/math8071109
Chicago/Turabian StyleWiszniewska-Matyszkiel, Agnieszka, and Rajani Singh. 2020. "When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria" Mathematics 8, no. 7: 1109. https://doi.org/10.3390/math8071109
APA StyleWiszniewska-Matyszkiel, A., & Singh, R. (2020). When Inaccuracies in Value Functions Do Not Propagate on Optima and Equilibria. Mathematics, 8(7), 1109. https://doi.org/10.3390/math8071109