
A Modified Recursive Regularization Factor Calculation for Sparse RLS Algorithm with l1-Norm


Abstract
:1. Introduction
2. Problem Formulation
| Algorithm 1 conventional RLS algorithm |
|
| Algorithm 2-norm sparse RLS algorithm |
|
3. Proposed Recursive Regularization Factor for Sparse RLS Algorithm
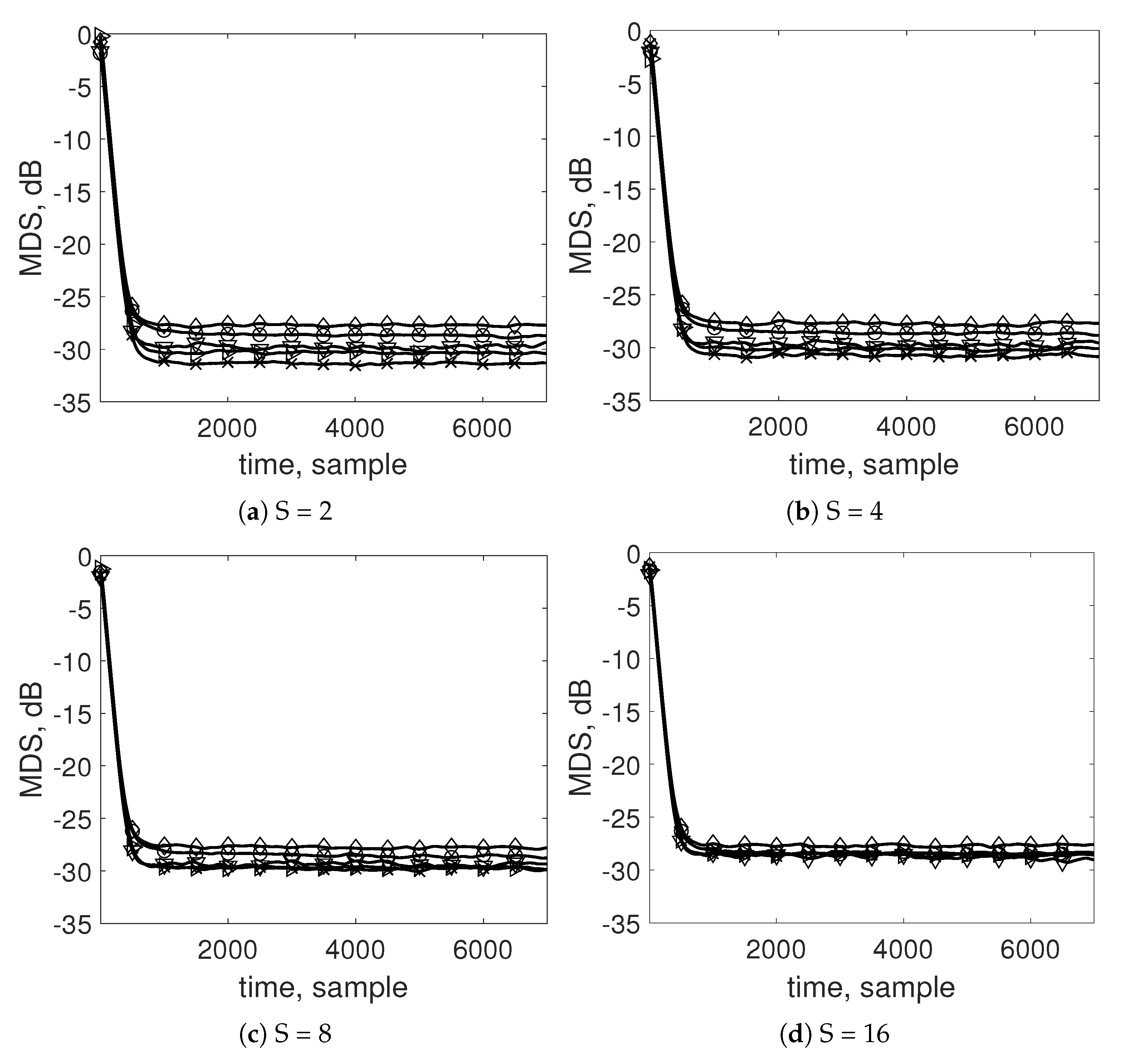
4. Simulation Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schreiber, W.F. Advanced television systems for terrestrial broadcasting: Some problems and some proposed solutions. IEEE Proc. 1995, 83, 958–981. [Google Scholar] [CrossRef]
- Ariyavisitakul, S.; Sollenberger, N.R.; Greenstein, L.J. Tap selectable decision-feedback equalization. IEEE Trans. Commun. 1997, 45, 1497–1500. [Google Scholar] [CrossRef]
- Li, W.; Preisig, J.C. Estimation of rapidly time-varying sparse channels. IEEE J. Ocean. Eng. 2007, 32, 927–939. [Google Scholar] [CrossRef]
- Bruckstein, A.M.; Donoho, D.L.; Elad, M. From sparse solutions of systems of equations to sparse modeling of signals and images. SIAM Rev. 2009, 51, 34–81. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Gu, Y.; Hero, A. Sparse LMS for system identification. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2009), Taipei, Taiwan, 19–24 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 3125–3128. [Google Scholar]
- Taheri, O.; Vorobyov, S. Sparse channel estimation with lp-norm and reweighted l1-norm penalized least mean squares. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2011), Prague, Czech Republic, 22–27 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2864–2867. [Google Scholar]
- Gui, G.; Xu, L.; Adachi, F. RZA-NLMF algorithm-based adaptive sparse sensing for realizing compressive sensing. EURASIP J. Adv. Signal Process. 2014, 2014, 125–134. [Google Scholar] [CrossRef] [Green Version]
- Amresh, K.; Ikhlaq, H.; Bhim, S. Double-stage three-phase grid-integrated solar PV system with fast zero attracting normalized least mean fourth based adaptive control. IEEE Trans. Ind. Electron. 2018, 65, 3921–3931. [Google Scholar]
- Gui, G.; Abolfazl, M.; Adachi, F. Sparse LMS/F algorithms with application to adaptive system identification. Wirel. Commun. Mob. Comput. 2015, 15, 1649–1658. [Google Scholar] [CrossRef]
- Gui, G.; Xu, L.; Adachi, F. Extra gain: Improved sparse channel estimation using reweighted l1-norm penalized LMS/F algorithm. In Proceedings of the 2014 IEEE/CIC International Conference on Communications in China (ICCC 2014), Shanghai, China, 13–15 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 13–15. [Google Scholar]
- Babadi, B.; Kalouptsidis, N.; Tarokh, V. SPARLS: The sparse RLS algorithm. IEEE Trans. Signal Process. 2010, 58, 4013–4025. [Google Scholar] [CrossRef] [Green Version]
- Angelosante, D.; Bazerque, J.; Giannakis, G. Online adaptive estimation of sparse signals: Where RLS meets the l1-norm. IEEE Trans. Signal Process. 2010, 58, 3436–3477. [Google Scholar] [CrossRef]
- Eksioglu, E. RLS algorithm with convex regularization. IEEE Signal Process. Lett. 2011, 18, 470–473. [Google Scholar] [CrossRef]
- Zakharov, Y.; Nascimento, V. DCD-RLS adaptive filters with penalties for sparse identification. IEEE Trans. Signal Process. 2013, 61, 3198–3213. [Google Scholar] [CrossRef]
- Lim, J.; Pang, H. Mixed norm regularized recursive total least squares for group sparse system identification. Int. J. Adapt. Control Signal Process. 2016, 30, 664–673. [Google Scholar] [CrossRef]
- Lim, J.; Pang, H. l1 regularized recursive total least squares based sparse system identification for the error-in-variables. SpringerPlus 2016, 5, 1460. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Gui, G. Recursive least square-based fast sparse multipath channel estimation. Int. J. Commun. Syst. 2017, 30, e3278. [Google Scholar] [CrossRef]
- Yang, J.; Xu, Y.; Rong, H.; Du, S.; Chen, B. Sparse recursive least mean p-power extreme learning machine for regression. IEEE Access 2018, 6, 16022–16034. [Google Scholar] [CrossRef]
- Yang, C.; Qiao, J.; Ahmad, Z.; Nie, K.; Wang, L. Online sequential echo state network with sparse RLS algorithm for time series prediction. Neural Netw. 2019, 118, 32–42. [Google Scholar] [CrossRef] [PubMed]
- Lim, J.; Lee, S. Regularization factor selection method for l1-Regularized RLS and its modification against uncertainty in the regularization factor. Appl. Sci. 2019, 9, 202. [Google Scholar] [CrossRef] [Green Version]
- Lim, J. l1-norm iterative Wiener filter for sparse channel estimation. Circuits Syst. Signal Process. CSSP 2020, 39, 6386–6393. [Google Scholar] [CrossRef]
- Stankovic, L. Digital Signal Processing with Selected Topics Adaptive Systems, Time-Frequency Analysis, Sparse Signal Processing; CreateSpace Independent Publishing Platform: Charleston, SC, USA, 2015; p. 766. [Google Scholar]
- Khalid, S.; Abrar, S. Blind adaptive algorithm for sparse channel equalization using projections onto lp-ball. Electron. Lett. 2015, 51, 1422–1424. [Google Scholar] [CrossRef]
- Oppenheim, A.; Schafer, R. Digital Signal Processing; Pretice-Hall: Hoboken, NJ, USA, 1975; p. 204. [Google Scholar]
- Farhang-Boroujeny, B. Adaptive Filter Theory and Applicaions; John Wiley & Sons: Hoboken, NY, USA, 1999; pp. 419–427. [Google Scholar]
- Diniz, P. Adaptive Filtering Algorithms and Practical Implementation, 3rd ed.; Springer: New York, NY, USA, 2008; p. 208. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Channel Length | No. of Non-Zero Coefficients | SNR | 20 dB | 10 dB | 0 dB |
|---|---|---|---|---|---|
| L = 64 | S = 4 | proposed method | −30.0 | −20.2 | −10.2 |
| -RLS with true impulse response | −30.8 | −20.6 | −11.0 | ||
| -RLS from [19] | −28.7 | −18.7 | −8.7 | ||
| -IWF from [21] | −29.5 | −19.7 | −9.0 | ||
| conventional RLS | −27.7 | −17.5 | −7.8 | ||
| S = 16 | proposed method | −28.4 | −18.6 | −9.1 | |
| -RLS with true impulse response | −28.5 | −18.5 | −9.3 | ||
| -RLS from [19] | −28.5 | −18.4 | −8.6 | ||
| -IWF from [21] | −29.0 | −18.8 | −9.2 | ||
| conventional RLS | −27.6 | −17.7 | −7.8 | ||
| L = 256 | S = 4 | proposed method | −24.4 | −14.3 | −4.2 |
| -RLS with true impulse response | −25.3 | −15.5 | −5.5 | ||
| -RLS from [19] | −22.7 | −12.7 | −2.6 | ||
| -IWF from [21] | −25.2 | −15.2 | −3.6 | ||
| conventional RLS | −21.2 | −11.2 | −1.4 | ||
| S = 16 | proposed method | −24.2 | −14.3 | −4.4 | |
| -RLS with true impulse response | −24.6 | −14.6 | −5.0 | ||
| -RLS from [19] | −22.7 | −12.5 | −2.6 | ||
| -IWF from [21] | −24.8 | −14.8 | −3.4 | ||
| conventional RLS | −21.1 | −11.1 | −1.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, J.; Lee, K.; Lee, S. A Modified Recursive Regularization Factor Calculation for Sparse RLS Algorithm with l1-Norm. Mathematics 2021, 9, 1580. https://doi.org/10.3390/math9131580
Lim J, Lee K, Lee S. A Modified Recursive Regularization Factor Calculation for Sparse RLS Algorithm with l1-Norm. Mathematics. 2021; 9(13):1580. https://doi.org/10.3390/math9131580
Chicago/Turabian StyleLim, Junseok, Keunhwa Lee, and Seokjin Lee. 2021. "A Modified Recursive Regularization Factor Calculation for Sparse RLS Algorithm with l1-Norm" Mathematics 9, no. 13: 1580. https://doi.org/10.3390/math9131580
APA StyleLim, J., Lee, K., & Lee, S. (2021). A Modified Recursive Regularization Factor Calculation for Sparse RLS Algorithm with l1-Norm. Mathematics, 9(13), 1580. https://doi.org/10.3390/math9131580