Consider a multidimensional smoothing problem of a response variable
with two covariates,
and
.
where
is a Gaussian i.i.d error term with zero mean and variance covariance matrix
, where
is a diagonal matrix when data are not correlated. The function
is a
multidimensional smooth function that depends on the two explanatory variables
and
, and each of them have lengths
and
, respectively. Although, here, we assume i.i.d. for simplicity, the results can be easily extended to a more general variance–covariance matrix
. The model in (1), can be represented in terms of basis functions with
with
, a
B-spline regression basis, and
, the vector of coefficients. If we consider data in a regular array structure, a smooth multidimensional surface is constructed via the Kronecker product of the marginal
B-spline basis of each covariate, the basis in model (2) is,
where ⊗ is the Kronecker product of two matrices, and
and
, of dimensions
and
, are the marginal
B-spline bases for
and
, respectively. Then, the dimension of (3) is
. On the other hand, if we consider scattered data, the basis is constructed by the tensor product of the marginal B-spline basis defined in [
7] as the so-called box-product, denoted by symbol □:
where the operator ⊙ is the element-wise matrix product and
and
are column vectors of ones of lengths
and
.
In the two-dimensional case, a matrix
penalizes the difference between adjacent coefficients of the rows and columns of the coefficient matrix
(4). Therefore, the penalty matrix
has the following expression:
where
and
are the difference matrices acting on the rows and columns of
, respectively.
and
are the smoothing parameters for each dimension of the model. Since
and
are not necessary equal, penalty (6) allows for anisotropic smoothing. To estimate the regression coefficients, we minimize the following function for the penalized sum of squares:
Once we have given this brief introduction to multidimensional P-splines, we generalize the approach given in [
10] to obtain out-of-sample predictions not only in one,
, but in both independent variables,
(the subscript ‘
’ denotes the dimension for which we are interested in for out-of-sample prediction). For the particular case in which a single covariate is extended, we will state several properties of the prediction method. Since the natural extension of the penalty matrix provides a change in the fit, in order to overcome this problem, we will suggest using constraints on the model coefficients.
2.1. Out-of-Sample Prediction of a Single Covariate
For the multidimensional P-spline model (1), we will consider first the case where the interest is on predicting outside the range of one of the covariates. This was already discussed in [
10] for mortality life tables, where death counts were collected at different ages and years, and the aim was to forecast future mortality across ages.
Given a vector of
observations
of the response variable, suppose we want to predict
new values
at
and
, where subscript
p denotes the ‘predicted‘ range of the
covariate and the response vector is
, where
is the vector of observed values and
is the new unknown observations to be predicted that can take arbitrary values—if we arrange the vector of observations into a matrix
of dimension
, such that
of length
the new matrix of observations can be written as:
where
is a matrix of dimensions
. Hence, matrix
is, in this case, of dimensions
. In order to fit and predict
we consider the extended model:
where
is the extended error covariance-matrix defined as
, with
, and
is a diagonal matrix with 1’s for the first
entries (when the data are observed) and infinite values for the last
(when the data are missing). For the
covariate, as we are not predicting new observation,
of a diagonal matrix of one’s of dimension
.
Following [
10], the extended basis is defined as:
where
and
are the regression bases with
and
, the two regressors. The new extended marginal B-spline basis for the
-covariate,
, is constructed from a new set of knots that consists of the original knots covering
,
, and extended to the new range of the
values of
,
. In other words,
is a direct extension of
. To estimate the new regression coefficients
, we minimize the extended penalized sum of squares:
where the extended penalty matrix is given by:
since only the covariate
is extended,
and
are:
and
where
and
are the difference matrices acting on the columns and rows of the matrix formed by the extended vector of coefficients:
The minimizer of (12) is given by:
The fact that we extend just one of the two covariates, and the particular form of the penalties based on differences between adjacent coefficients, yields certain important properties satisfied by the model. These properties are the direct result of the following theorem:
Theorem 1. The coefficients obtained from minimization of (12) with the extended basis (11), extended error covariance matrix (10) and extended penalty matrix (13) meet the following properties:
- I.
The first c, , coefficients of , are:where and are defined in (14) and , , and defined in (15). - II.
The coefficients for the predicted values arewhere is defined in (14) and , is defined in (15).
Therefore, according to the previous theorem, when we predict in two dimensions extending one covariate, the predicted values,
, obtained by using the new coefficients,
; depend on the ratio
, unless
(i.e., an isotropic smoothing). Therefore, while in the case of one-dimensional smooth models, the smoothing parameter does not play any role in the prediction (see [
13] for details), we have found that in two dimensions the smoothing parameters in both directions,
and
, determine the prediction.
Notice that we have proved that the coefficients that give the fit when the fit and the prediction are obtained at the same time (18) are different from the solution we obtain only fitting the data (8) (this property is verified in the case of one-dimensional smooth models [
13]). Although, in the one-dimensional case, the extended penalty is not a direct extension of the penalty used to fit the data, the blocks of the extended penalty are simplified and the fit remains the same. This does not happen in the case of two dimensions, unless the block
in (14) is equal to zero, as shown by the following corollary.
Corollary 1 (Theorem 1). If (or equivalently, if ) in (14), the solution of (12) verifies the following properties:
- 1.
When performing out-of-sample predictions, the fit remains invariant.
- 2.
Consider the coefficient matrix obtained from the model fit, , and the c matrix of predicted coefficients, , each row , of the additional matrix of coefficients is a linear combination of the last old coefficients of that row ( is the order of the penalty acting on rows and is the number of rows of ).
For the particular case of second and third order penalties, i.e.,
and
, the proof is given in the
Supplementary Materials.
As we have showed in the previous corollary, setting
to zero, the fit is preserved and everything is analogous to the one-dimensional case. In the literature, there are some works in which
is considered equal to zero, e.g., [
12]. However, in practice, we do not set
to zero since we would not be imposing the penalty correctly. In addition, we cannot extend it to situations where we want to make out-of-sample predictions in two dimensions. We cannot set
and
to zero in (14) and (15), since the matrix
would be singular.
It is important to note that, regardless of the value of , by (19) the new coefficients are determined by the last columns of the coefficients that give the fit. Therefore, we do not need to set equal to zero to know which coefficients determine the prediction.
2.2. Out-of-Sample Prediction in Two Dimensions
In this section, we address the case in which we are interested in making predictions outside the range of the observed values of both covariates and .
Given a vector of
observations
of the response variable, now we want to predict
new values at
,
and
, i.e., if we arrange the observation vector into a matrix
of dimension
, the observed and predicted values can be arranged into a matrix of dimension
(
,
), as:
Note that the dimensions of , and are , and , respectively.
We again use the model in (10), but now the full extended basis is the Kronecker product of the two extended marginal B-spline basis,
and
, of dimensions
and
, respectively:
where the extended bases
and
are constructed from a new set of knots that consists of the original knots and extended to cover the full range of
and
, respectively. The extended covariance matrix
with
, where
and
are diagonal matrices of dimensions
(
) and
(
), respectively, with infinity entry if the data are missing and 1 if the data are observed. The infinity quantities express the uncertainty since we do not have any information about the data
. To estimate the extended coefficients, we minimize the penalized sum of squares in (12) with an extended penalty matrix
with
and
as in (15). Note that
and
are direct extensions of
and
but
and
are not direct extensions of
and
. Moreover, if
is given in (8) and we are extending the two covariates,
, in matrix form
is:
Note that in the case of fitting, the extension of the predicted new values depends on the data structure. If we consider scattered data, we set out-of-sample points at which we want to predict new values for and is a diagonal matrix with the first n values equal to 1 and the last values equal to infinity. Everything else is independent of the data structure.
As in the case of only one-dimensional out-of-sample prediction, when using model (1) or model (10), the fit to the observed data is not the same, as one might expect. In the next section, we recommend using constraints to maintain the fit when fitting and prediction are obtained at the same time.
2.3. Out-of-Sample Prediction with Constraints
As we showed in the previous section, the natural expansion of the penalty matrix provides a change in fit. To overcome this problem, and as a possible way to incorporate known information about the prediction, we recommend the use of constrained P-splines. This method will allow us to impose constant and fixed constraints, as well as constraints that depend on observed data.
Our proposal is to derive the solution of the extended model (10) subject to a set of
l linear constraints given by
, where
is a known matrix of dimension
acting on all coefficients, and
is the restrictions vector of dimension
. Therefore, we have the following extended regression model with constraints:
subject to
Depending on whether we are predicting out-of-sample in one or two dimensions, we define
,
and
as shown in
Section 2.1 and
Section 2.2. The superscript
refers to the use of constraints.
We extend the results of [
14] to the case of penalized least squares and obtain the Lagrange formulation of the penalized least squares minimization problem:
where
is defined depending on whether we extend one or two covariates,
is the extended penalty matrix (13) or (22),
denotes the restricted penalized least squares (RPLS) estimator and
is a
vector of Lagrange multipliers.
Differentiating the expression in (26), we obtain:
The system of equations can be written as:
yielding the following solutions:
where
is the unconstrained penalized least squares estimator as in (17).
Therefore, the constrained vector of coefficients , are obtained by computing the vector of Lagrange multipliers (30) and substituting in (29), i.e., is the unconstrained solution, , plus a multiple of the discrepancy vector.
Using these results, we can obtain the constrained fitted and predicted values as
defining the matrices
the response vector of new values
can be written as:
The variance of depends on the following conditions:
- (a)
If the constraint
is a constant, i.e., it does not depend on the data, the variance is:
with
.
- (b)
If the constraint depends on the data, we must consider the variability of
. For instance, if the constraint implies that the fit has to be maintained, i.e.,
, the variance is:
with
where
is a null matrix of dimension,
,
is the number of new coefficients, and
is the number of new observations.
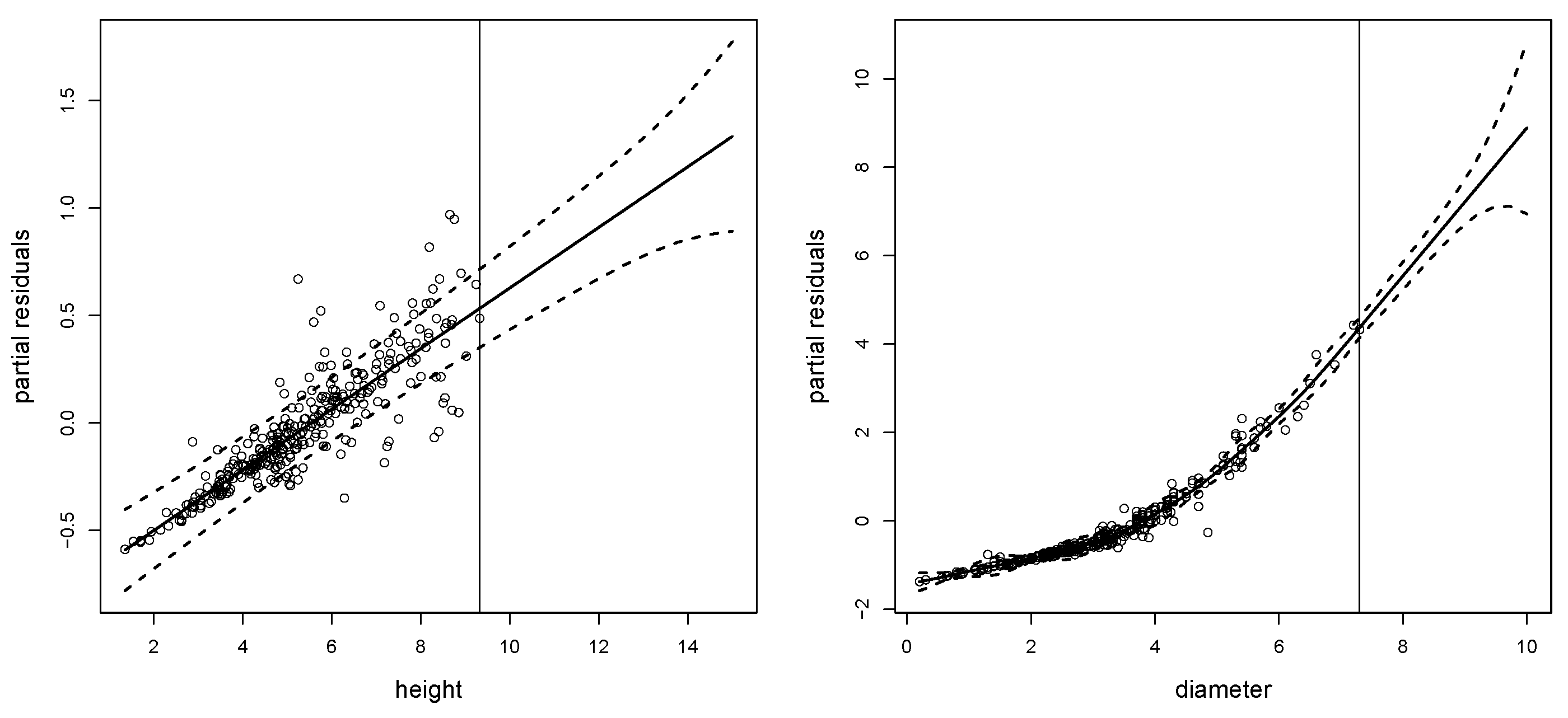
To help readers understand the process, we now explain how to impose constraints on the fit in practice. Suppose we just make out-of-sample predictions in one of the two covariates and, for example, the estimated coefficients matrix obtained when only fitting the observed data has dimensions of
, and the one obtained when fitting and forecasting simultaneously has dimension
, then
where in
the coefficients that determine the fit have superscript
and the coefficients that determine the forecast have superscript symbol
. If we impose the constraint that the fit has to be maintained, we use the constraint equation in (25) with
,
(
is an identity matrix of dimension 12 and
a zero matrix of dimension
) and
.
On the other hand, if we extend the two covariates, the coefficient matrices obtained when only fitting and when fit and prediction is carried out simultaneously are:
i.e.,
,
,
and
. To impose the restriction the fit has to be maintained, we set
,
(
is an identity matrix of dimension 4 and
is a zero matrix of dimension 2) and
in Equation (25).
In general, if the constraint implies that the fit has to be maintained and
,
is a block diagonal matrix with the first block an identity matrix of dimensions
and
blocks equal to
, i.e.,
and
.
2.4. Example 1: Prediction of Mortality Data
We illustrate our constrained out-of-sample prediction method with the analysis of male mortality data in the US. Although mortality data are usually analyzed by Poisson distribution, for the simple purpose of illustrating the proposed method, we will assume that the logarithm of the mortality rates are normally distributed. The data come from the Human Mortality Database (Link:
https://www.mortality.org/ (last accessed date: 1 July 2021). We observed the log of mortality rates from ages 0 to
over the period 1960–2014, and forecasted up to 2050, i.e., we obtained out-of-sample predictions in one of the two covariates, in this case, year.
The Lee–Carter method [
16] is one of the most commonly used methods for estimating and forecasting mortality data; however, this method may produce an unwanted cross-over of forecasted mortality (higher mortality rates for younger ages than for older ages). The Lee-Carter model is defined as:
where
is the central rate of mortality at age
x and year
y,
,
and
are parameters to be estimated, and
is the error term with mean zero and variance
. This model is fitted to historical data and the resulting estimated
s are then modelled and projected as a stochastic time series using standard Box–Jenkins methods. Ref. [
17] proposed a modification to the Lee–Carter model based on the estimation of smooth versions of
to avoid the cross-over of projected mortality rates. In order to compare our method with the solution given by [
17], we obtained fits and predictions through four different models:
- (a)
Model 1: an unconstrained model:
where
is the log mortality rate and
is defined as in (10).
- (b)
Model 2: The model defined in (a) subject to the constraint that the fit is maintained when fitting and forecasting at the same time.
- (c)
Model 3: The model defined in (a) is subject to two constraints:
- -
The fit is maintained;
- -
The inter-age structure is preserved. We impose this constraint to avoid age crossing, that is, to prevent the death rate of younger ages from being higher than that of older ages. To achieve this, we use the pattern of the estimated coefficients in the past few years and forecast it. In particular, we ensure that the difference between the coefficients of every two consecutive projections is constant and equal to the difference between the corresponding last coefficient in the fitting.
Let us use an example to explain how to impose these two constraints at the same time. Suppose that the dimension of the coefficient matrix from the fitting is
, and the dimensions of the coefficient matrix given the fitting and prediction is
, that is,
in
, the coefficients that determine the fit have the superscript • and the coefficients that determine the forecast have the superscript ∘. Now, in the restriction Equation (25),
, and
with
and
,
i.e., we are imposing that the coefficients that determine the fit (when fitting and forecasting simultaneously) have to be the ones we obtain when only fitting the data, and that the difference between the coefficients that determine the forecast of two consecutive rows has to be equal to the difference between the last coefficients from the fit of those rows.
- (d)
Model 4: is the Lee–Carter model proposed in [
16], but modified to get regular projected life tables [
17].
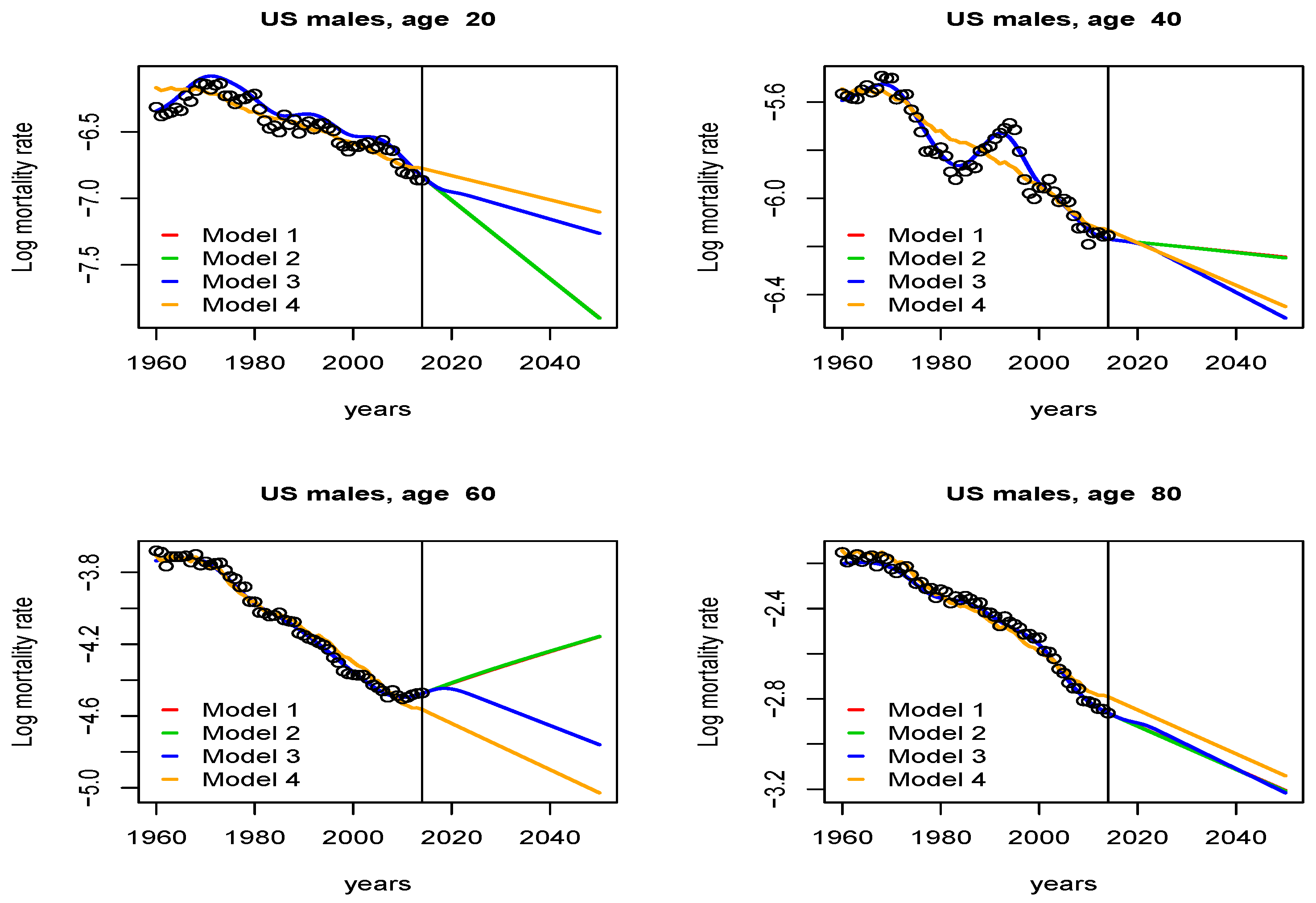
Figure 1 shows the fit and the forecast obtained with all four models. In order to highlight the difference between the results, we have selected four ages: 20, 40, 60, and 80.
Figure 2 shows the fit and forecast for these ages obtained by model 1 (red line), model 2 (green line), model 3 (blue line) and model 4 (orange line). The first three models (models 1, 2 and 3) provide almost the same fit. However, the fit given by model 4 is quite different and worse than the fits of other models, at 20 and 40 years. This is to be expected because the Lee–Carter model is not flexible enough to capture the increase in mortality in the early 1980s.
The predictions with models 1 and 2 are almost identical. Although it gave very similar results in the fitting, model 3 provided completely different results in the predictions, as expected. For 60 years of age, model 1 and model 2 predict that the logarithmic death rate will increase during 2020–2050, because they predict an upward trend in death rates from 2010 to 2014. This is inconsistent with the expected result. In the case of model 4, forecasts are close to model 3 for ages 40 and 80, but in the case of age 20 it seems to clearly overestimate the mortality. In model 3, the increasing trend is corrected after the initial years to maintain the structure of the adjacent ages, thus avoiding irregular predictions (as happens at age 60).
As we have seen, when we impose the two constraints, we obtain the most realistic results: maintain the fit and the cross-age structure, that is, those given by model 3. If we do not maintain the coefficient pattern, age crossover may occur. We further illustrate this fact in
Figure 3, we plot the projections obtained with model 2 (green line) and model 3 (blue line) for ages 66 and 67. We can see that the fit of the two models is the same, and within the known data range, the log mortality of age 66 is lower than that of age 67. However, in the forecast, model 2 does not avoid the cross-over for ages 66 and 67 and so, in 2050, the log mortality rate is larger for age 66 than for age 47, this cross-over is not biologically acceptable since it is expected that mortality rates of older people are higher. This does not occur with model 3 where the restrictions imposed preserve the cross-age structure among ages.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









