
Multi-Transformer: A New Neural Network-Based Architecture for Forecasting S&P Volatility


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data and Model Inputs
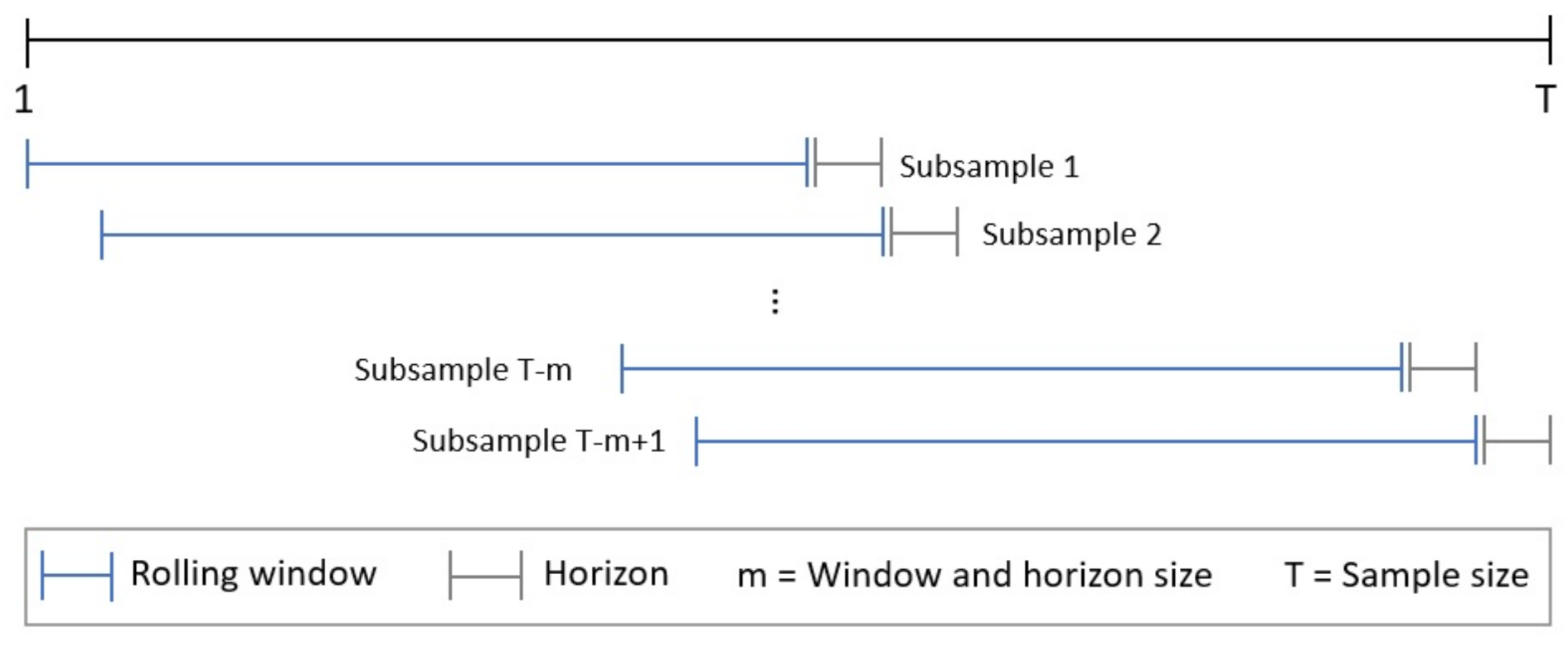
2.2. Models Validation
2.3. Benchmark Models
- The last daily logarithmic return, , for the ANN-GARCH and the last ten in the case of the LSTM-GARCH (as explained in Section 2.1).
- The standard deviation of the last five daily logarithmic returns:where and . As with the previous input variable, the last standard deviation is considered in the ANN-GARCH, whereas the last ten are taken into consideration by the LSTM-GARCH architecture.
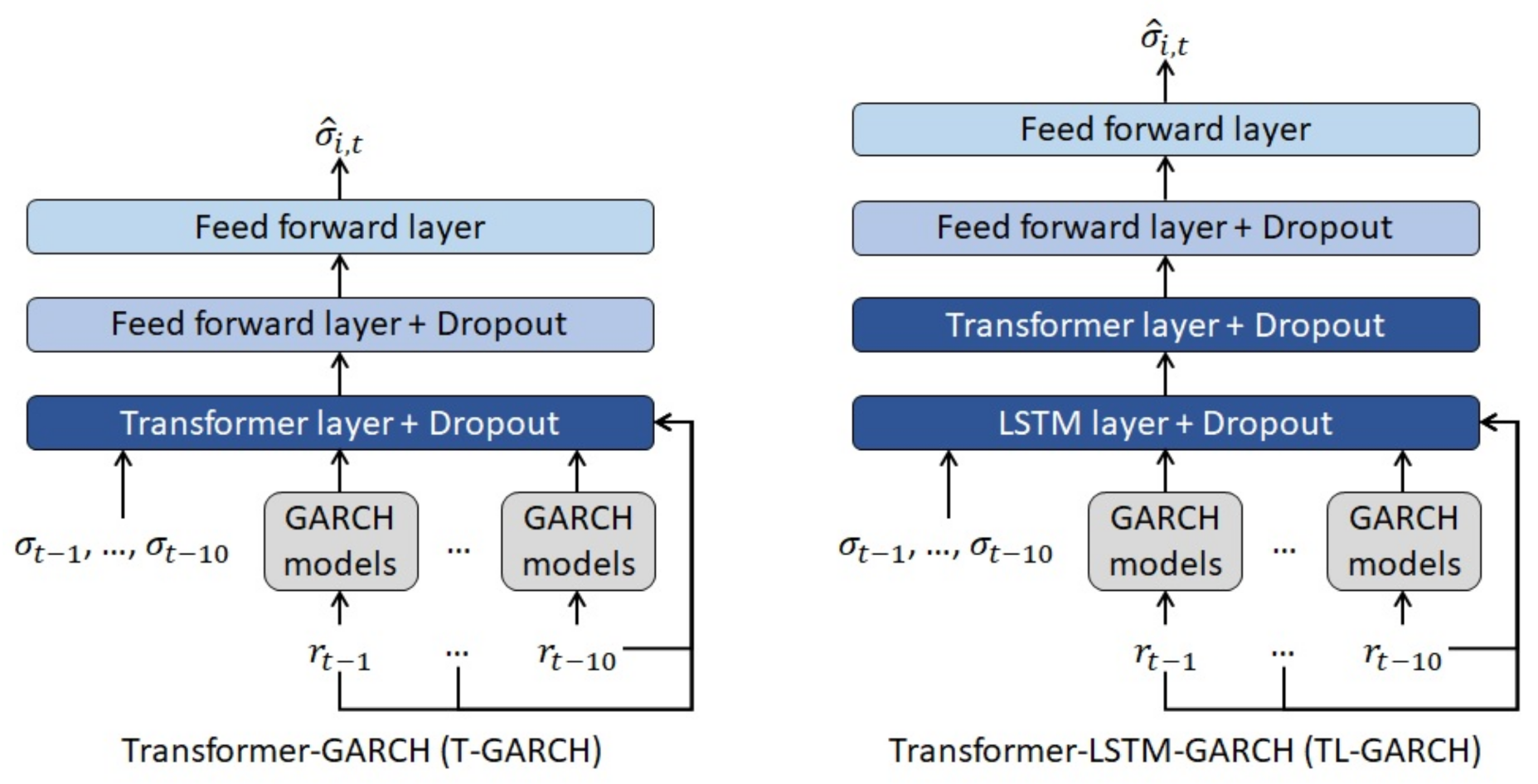
2.4. Transformer-Based Models
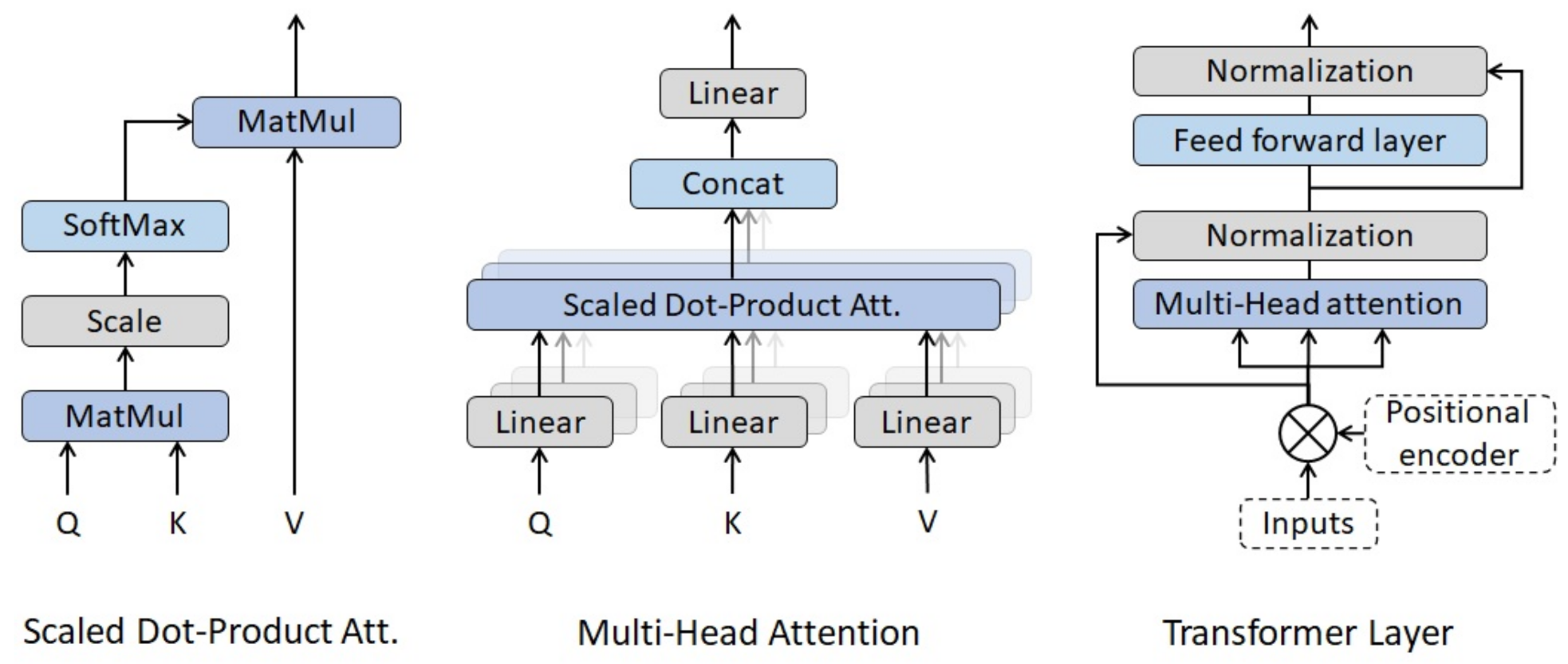
- Positional encoder. As previously stated, Transformer layers have no recurrence structure. Thus, the information about the relative position of the observations within the time series needs to be included in the model. To do so, a positional encoding is added to the input data. In the context of NLP, Vaswani et al. [54] suggested the following wave functions as positional encoders:where is the total number of explanatory variables (or word embedding dimension in NLP) used as input in the model, is the position of the observation within the time series and . This positional encoder modifies the input data depending on the lag of the time series and the embedding dimension used for the words.As volatility models do not use words as inputs, the positional encoder is modified in order to avoid any variation of the inputs depending on the number of time series used as input. Thus, the positional encoder suggested in this paper changes depending on the lag, but it remains the same across the different explanatory variables introduced in the model. As in the previous case, a wave function plays the role of positional encoder:where is the position of the observation within the time series and maximum lag.
- Multi-Head attention. It can be considered the key component of the Transformer layers proposed by [54]. As shown in Figure 3, Multi-Head attention is composed of several scaled dot-product attention units running in parallel. Scaled dot-product attention is computed as follows:where Q, K and V are input matrices and the number of input variables taken into consideration within the dot-product attention mechanism. Multi-Head attention splits the explicative variables in different groups or `heads’ in order to run the different scaled dot-product attention units in parallel. Once the different heads are calculated, the outputs are concatenated (Concat operator) and connected to a feed forward layer with linear activation. Thus, the Multi-Head attention mechanism has the following expression:where h is the number of heads. It is also worth mentioning that all the matrices of parameters (, , and ) are trained using feed forward layers with linear activations.
- Adaptative Moment Estimator (ADAM) is the algorithm used for updating the weights of the feed forward, LSTM and Transformer layers. This algorithm takes into consideration current and previous gradients in order to implement a progressive adaptation of the initial learning rate. The values suggested by [67] for the ADAM parameters are used in this paper and the initial learning rate is set to .
- The feed forward layers with dropout present in both models have 8 neurons, while the output layer has just one.
- The level of dropout regularization [68] is optimized with the training set mentioned in Section 2.1.
- The loss function used for weights optimization and back propagation purposes is the mean squared error.
- Batch size is equal to 64 and the models are trained during 5000 epochs in order to obtain the final weights.
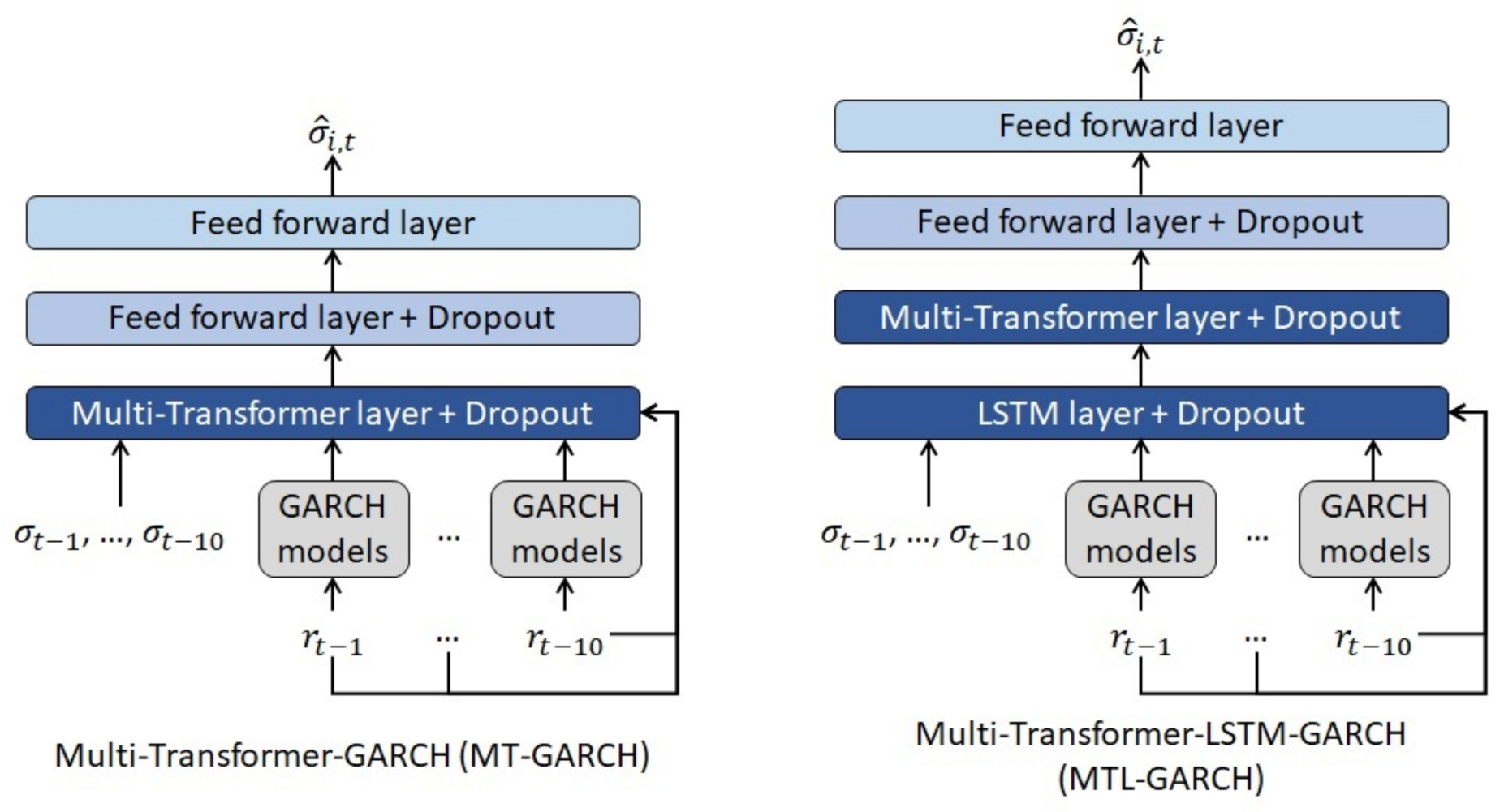
2.5. Multi-Transformer-Based Models
- As shown in Figure 5, Multi-Transformer layers generate T different random samples of the input data. In the volatility models proposed in this paper, of the observations of the database are randomly selected in order to compute the different samples.
- Multi-Transformer architecture is composed of T Multi-Head attention units (in this paper ), one per each random sample of the input data. Then, the average of the different units is computed in order to obtain the final attention matrix. Thus, the Average Multi-Head (AMH) mechanism present in Multi-Transformer can be defined as follows:
3. Results
3.1. Fitting of Models Based on Neural Networks
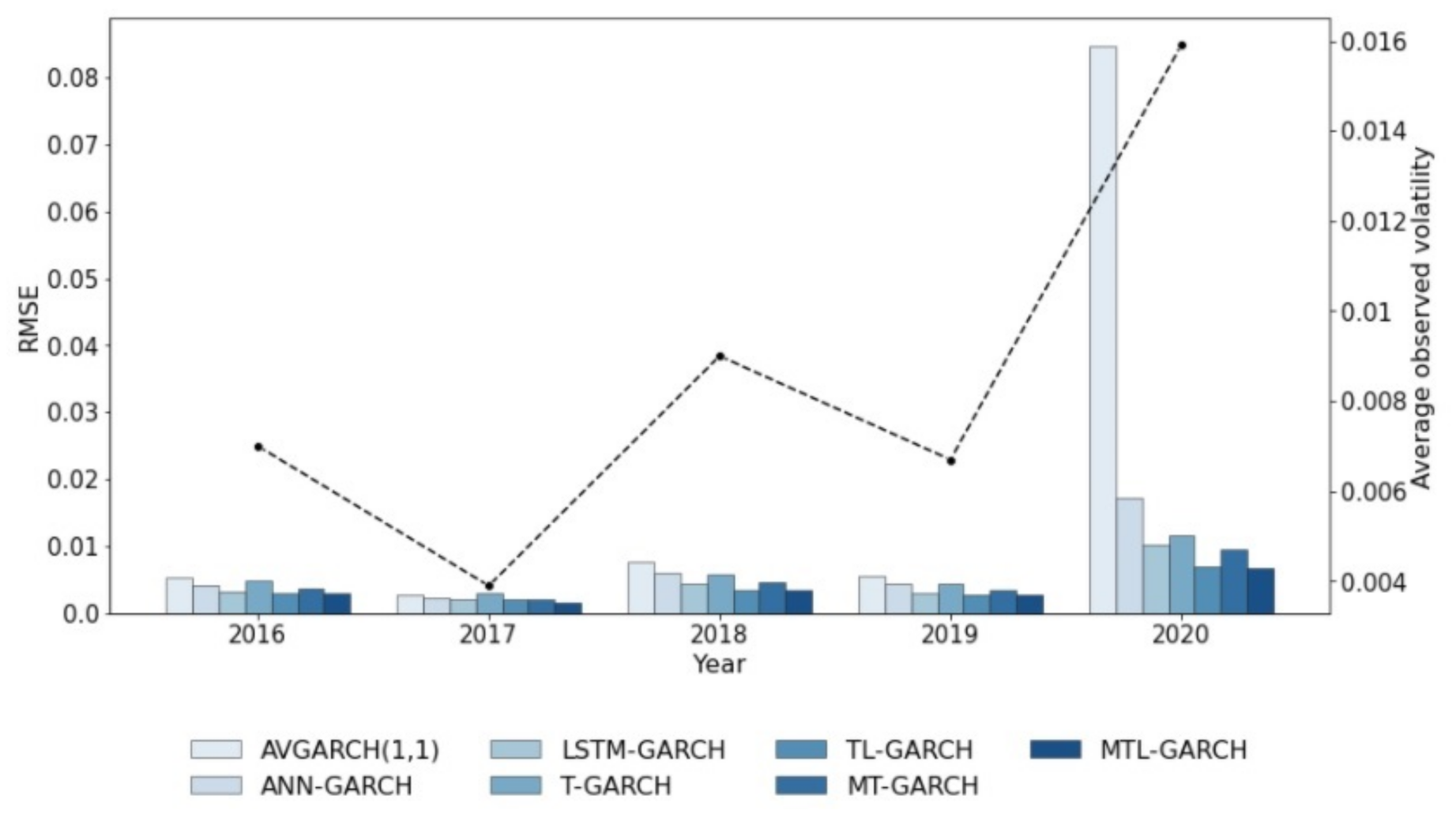
3.2. Comparison against Benchmark Models
- Traditional GARCH processes are outperformed by models based on merging artificial neural network architectures such as feed forward, LSTM or Transformer layers with the outcomes of autoregressive algorithms (also named hybrid models).
- The comparison between ANN-GARCH and the rest of the volatility forecasting models based on artificial neural networks (LSTM-GARCH, T-GARCH, TL-GARCH, MT-GARCH and MTL-GARCH) reveals that feed forward layers lead to less accurate forecasts than other architectures. Multi-Transformer, Transformer and LSTM were specially created to forecast time series and, thus, the volatility models based on these layers are more accurate than ANN-GARCH.
- Merging Multi-Transformer and Transformer layers with LSTMs leads to more accurate predictions than traditional LSTM-based architectures. Indeed, TL-GARCH achieves better results than LSTM-GARCH, even though the number of weights of TL-GARCH is significantly lower. Thus, the novel Transformer and Multi-Transformer layers introduced for NLPs purposes can be adapted as described in Section 2.4 and Section 2.5 in order to generate more accurate volatility forecasting models. It is also worth mentioning that Multi-Transformer layers, which were also introduced in this paper, lead to more accurate forecasts thanks to their ability to average several attention mechanisms. In fact, the model that achieves the lower MAE and RMSE is a mixture of Multi-Transformer and LSTM layers (MTL-GARCH).
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hull, J. Risk Management and Financial Institutions, 4th ed.; Wiley and Sons: London, UK, 2015. [Google Scholar]
- Rajashree, P.; Ranjeeeta, B. A differential harmony search based hybrid internal type2 fuzzy EGARCH model for stock market volatility prediction. Int. J. Approx. Reason. 2015, 59, 81–104. [Google Scholar]
- Engle, R. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Mandelbrot, B. The variation of certain speculative prices. J. Bus. 1963, 36, 394–419. [Google Scholar] [CrossRef]
- Engle, R.; Lee, G. A permanent and transitory component model of stock return volatility. In Cointegration, Causality, and Forecasting: A Festschrift in Honor of Clive W. J. Granger; Engle, R., White, H., Eds.; Oxford University Press: Oxford, UK, 1999; pp. 475–497. [Google Scholar]
- Haas, M.; Mittnik, S.; Paolella, M. Mixed normal conditional heteroskedasticity. J. Financ. Econom. 2004, 2, 211–250. [Google Scholar] [CrossRef]
- Haas, M.; Mittnik, S.; Paolella, M. A new approach to Markov-switching GARCH models. J. Financ. Econom. 2004, 2, 493–530. [Google Scholar] [CrossRef]
- Haas, M.; Paolella, M. Mixture and regime-switching GARCH models. In Handbook of Volatility Models and Their Applications; Bauwens, L., Hafner, C., Laurent, S., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2012; pp. 71–102. [Google Scholar]
- Nelson, D.B. Conditional Heteroskedasticity in Asset Returns: A New Approach. Econometrica 1991, 59, 347–370. [Google Scholar] [CrossRef]
- Glosten, L.; Jagannathan, R.; Runkle, D. On the Relation between the Expected Value and the Volatility of the Nominal Excess Return on Stocks. J. Financ. 1993, 48, 1779–1801. [Google Scholar] [CrossRef]
- Kraft, D.; Engle, R. Autoregressive Conditional Heteroskedasticity in Multiple Time Series; Department of Economics, UCSD: San Diego, CA, USA, 1982. [Google Scholar]
- Engle, R.; Granger, C.; Kraft, D. Combining competing forecasts of inflation with a bivariate ARCH model. J. Econ. Dyn. Control. 1984, 8, 151–165. [Google Scholar] [CrossRef]
- Bollerslev, T.; Engle, R.; Wooldridge, J. A Capital Asset Pricing Model with time-varying covariances. J. Political Econ. 1988, 96, 116–131. [Google Scholar] [CrossRef]
- Tse, Y.; Tsui, K. A multivariate GARCH model with time-varying correlations. J. Bus. Econ. Stat. 2002, 20, 351–362. [Google Scholar] [CrossRef]
- Engle, R. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. J. Bus. Econ. Stat. 2002, 20, 339–350. [Google Scholar] [CrossRef]
- Engle, R.; Kroner, F. Multivariate simultaneous generalized ARCH. Econom. Theory 1995, 11, 122–150. [Google Scholar] [CrossRef]
- Engle, R.; Ng, V.; Rotschild, M. Asset pricing with a factor-ARCH covariance structure: Empirical estimates for Treasury Bills. J. Econom. 1990, 45, 213–238. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhu, K.; Ling, S. The ZD-GARCH model: A new way to study heteroscedasticity. J. Econom. 2018, 202, 1–17. [Google Scholar] [CrossRef]
- Heston, S.L. A closed-form solution for options with stochastic volatility with applications to bond and currency options. Rev. Financ. Stud. 1993, 6, 327–343. [Google Scholar] [CrossRef] [Green Version]
- Cox, J.; Ingersoll, J.; Ross, S. A Theory of the Term Structure of Interest Rates. Econometrica 1985, 53, 385–407. [Google Scholar] [CrossRef]
- Melino, A.; Turnbull, S. Pricing foreign currency options with stochastic volatility. J. Econom. 1990, 45, 239–265. [Google Scholar] [CrossRef]
- Andersen, T.; Sorensen, B. GMM estimation of a stochastic volatility model: A Monte Carlo study. J. Bus. Econ. Stat. 1999, 14, 329–352. [Google Scholar]
- Durbin, J.; Koopman, S. Monte Carlo maximum likelihood estimation for non-Gaussian state space models. Biometrika 1997, 84, 669–684. [Google Scholar] [CrossRef] [Green Version]
- Broto, C.; Ruiz, E. Estimation methods for stochastic volatility models: A survey. J. Econ. Surv. 2004, 18, 613–649. [Google Scholar] [CrossRef] [Green Version]
- Danielsson, J. Stochastic volatility in asset prices: Estimation by simulated maximum likelihood. J. Econom. 2004, 64, 375–400. [Google Scholar] [CrossRef]
- Andersen, T. Encyclopedia of Complexity and System Sciences; Chapter Stochastic Volatility; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hull, J.C.; White, A. The Pricing of Options on Assets with Stochastic Volatilities. J. Financ. 1987, 42, 281–300. [Google Scholar] [CrossRef]
- Hagan, P.; Kumar, D.; Lesniewski, A.; Woodward, D. Managing Smile Risk. Wilmott Mag. 2002, 1, 84–108. [Google Scholar]
- Mcculloch, W.; Pitts, W. A Logical Calculus of Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 127–147. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2000, 29, 1189–1232. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Gestel, T.; Suykens, J.; Baestens, D.; Lambrechts, A.; Laneknet, G. Financial time series prediction using least squares Support Vector Machines within the evidence framework. IEEE Trans. Neural Netw. 2001, 12, 809–821. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, A.; Dhinga, B. Stock markets prediction using hidden Markov models. In Proceedings of the 2012 Students Conference on Engineering and Systems, Allahabad, India, 16–18 March 2012; pp. 1–4. [Google Scholar]
- Dias, F.; Nogueira, R.; Peixoto, G.; Moreira, W. Decision-making for financial trading: A fusion approach of Machine Learning and Portfolio Selection. Expert Syst. Appl. 2019, 115, 635–655. [Google Scholar]
- Hamid, S.; Iqbid, Z. Using neural networks for forecasting volatility of S&P 500 Index futures prices. J. Bus. Res. 2002, 57, 1116–1125. [Google Scholar]
- Roh, T. Forecasting the Volatility of Stock Price Index. Expert Syst. Appl. 2006, 33, 916–922. [Google Scholar]
- Hajizadeh, E.; Seifi, A.; Zarandi, F.; Turksen, I. A hybrid modeling approach for forecasting the volatility of S&P 500 Index return. Expert Syst. Appl. 2012, 39, 531–536. [Google Scholar]
- Kristjanpoller, W.; Fadic, A.; Minutolo, M. Volatility forecast using hybrid neural network models. Expert Syst. Appl. 2014, 41, 2437–2442. [Google Scholar] [CrossRef]
- Monfared, S.A.; Enke, D. Volatility Forecasting Using a Hybrid GJR-GARCH Neural Network Model. Procedia Comput. Sci. 2014, 36, 246–253. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Que, D.; Cao, G. Volatility Forecast Based on the Hybrid Artificial Neural Network and GARCH-type Models. Procedia Comput. Sci. 2016, 91, 1044–1049. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Won, C. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Back, Y.; Kim, H. ModAugNet: A new forecasting framework for stock market index value with an overfitting prevention LSTM module and a prediction LSTM module. Expert Syst. Appl. 2018, 113, 457–480. [Google Scholar] [CrossRef]
- Bildirici, M.; Ersin, O. Improving forecasts of GARCH family models with the artificial neural networks: An applicaiton to the daily returns in Istanbul Stock Exchange. Expert Syst. Appl. 2009, 36, 7355–7362. [Google Scholar] [CrossRef]
- Kristjanpoller, W.; Minutolo, M. Gold price volatility: A Forecasting approach using the Artificial Neural Network-GARCH model. Expert Syst. Appl. 2015, 42, 7245–7251. [Google Scholar] [CrossRef]
- Kristjanpoller, W.; Hernández, E. Volatility of main metals forecasted by a hybrid ANN-GARCH model with regressors. Expert Syst. Appl. 2017, 84, 290–300. [Google Scholar] [CrossRef]
- Kristjanpoller, W.; Minutolo, M. Forecasting volatility of oil price using an Artificial Neural Network-GARCH model. Expert Syst. Appl. 2016, 65, 233–241. [Google Scholar] [CrossRef]
- Verma, S. Forecasting volatility of crude oil futures using a GARCH–RNN hybrid approach. Intell. Syst. Accounting, Financ. Manag. 2021. [Google Scholar] [CrossRef]
- Ramos-Pérez, E.; Alonso-González, P.; Núñez-Velázquez, J. Forecasting volatility with a stacked model based on a hybridized Artificial Neural Network. Expert Syst. Appl. 2019, 129, 1–9. [Google Scholar] [CrossRef]
- Vidal, A.; Kristjanpoller, W. Gold volatility prediction using a CNN-LSTM approach. Expert Syst. Appl. 2020, 157. [Google Scholar] [CrossRef]
- Jung, G.; Choi, S.Y. Forecasting Foreign Exchange Volatility Using Deep Learning Autoencoder-LSTM Techniques. Complexity 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Peng, Y.; Melo, P.; Camboim de Sá, J.; Akaishi, A.; Montenegro, M. The best of two worlds: Forecasting high frequency volatility for cryptocurrencies and traditional currencies with Support Vector Regression. Expert Syst. Appl. 2018, 97, 177–192. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 2017, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Swanson, N.R. Money and output viewed through a rolling window. J. Monet. Econ. 1998, 41, 455–474. [Google Scholar] [CrossRef]
- Goyal, A.; Welch, I. Predicting the Equity Premium With Dividend Ratios; NBER Working Papers 8788; National Bureau of Economic Research, Inc.: Cambridge, MA, USA, 2002. [Google Scholar]
- Zivot, E.; Wang, J. Modeling Financial Time Series with S-PLUS®; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Molodtsova, T.; Papell, D. Taylor Rule Exchange Rate Forecasting during the Financial Crisis. NBER Int. Semin. Macroecon. 2012, 9, 55–97. [Google Scholar] [CrossRef] [Green Version]
- Kupiec, P.H. Techniques for Verifying the Accuracy of Risk Measurement Models. J. Deriv. 1995, 3, 73–84. [Google Scholar] [CrossRef]
- Christoffersen, P.F.; Bera, A.; Berkowitz, J.; Bollerslev, T.; Diebold, F.; Giorgianni, L.; Hahn, J.; Lopez, J.; Mariano, R. Evaluating Interval Forecasts. Int. Econ. Rev. 1997, 39, 841–862. [Google Scholar] [CrossRef]
- Bauwens, L.; Hafner, C.; Laurent, S. Handbook of Volatility Models and Their Applications; Wiley Handbooks in Financial E; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Taylor, S.J. Modelling Financial Time Series; Wiley: Hoboken, NJ, USA, 1986. [Google Scholar]
- Baillie, R.T.; Bollerslev, T.; Mikkelsen, H.O. Fractionally integrated generalized autoregressive conditional heteroskedasticity. J. Econom. 1996, 74, 3–30. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Jeremic, Z.; Terzić, I. Empirical estimation and comparison of Normal and Student T linear VaR on the Belgrade Stock Exchange. In Proceedings of the Sinteza 2014—Impact of the Internet on Business Activities in Serbia and Worldwide, Belgrade, Serbia, 25–26 April 2014; pp. 298–302. [Google Scholar] [CrossRef] [Green Version]
- McNeil, A.J.; Frey, R.; Embrechts, P. Quantitative Risk Management: Concepts, Techniques and Tools; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ||||
|---|---|---|---|---|
| ANN-GARCH | 0.0351 | 0.0092 | 0.0085 | 0.0082 |
| LSTM-GARCH | 0.0065 | 0.0057 | 0.0056 | 0.0054 |
| T-GARCH | 0.0089 | 0.0076 | 0.0072 | 0.0074 |
| TL-GARCH | 0.0050 | 0.0045 | 0.0044 | 0.0045 |
| MT-GARCH | 0.0068 | 0.0062 | 0.0064 | 0.0064 |
| MTL-GARCH | 0.0047 | 0.0045 | 0.0042 | 0.0044 |
| Model | 2016 | 2017 | 2018 | 2019 | 2020 | Total |
|---|---|---|---|---|---|---|
| GARCH(1,1) | 0.0058 | 0.0026 | 0.0095 | 0.0073 | 0.1026 | 0.0464 |
| AVGARCH(1,1) | 0.0053 | 0.0027 | 0.0076 | 0.0056 | 0.0847 | 0.0383 |
| EGARCH(1,1) | 0.0056 | 0.0028 | 0.0093 | 0.0078 | 0.0880 | 0.0399 |
| GJR-GARCH(1,1,1) | 0.0090 | 0.0028 | 0.0126 | 0.0068 | 0.1248 | 0.0565 |
| TrGARCH(1,1,1) | 0.0074 | 0.0027 | 0.0115 | 0.0058 | 0.1153 | 0.0521 |
| FIGARCH(1,1) | 0.0062 | 0.0029 | 0.0095 | 0.0066 | 0.1011 | 0.0457 |
| ANN-GARCH | 0.0042 | 0.0023 | 0.0060 | 0.0044 | 0.0171 | 0.0086 |
| LSTM-GARCH | 0.0032 | 0.0021 | 0.0043 | 0.0030 | 0.0101 | 0.0054 |
| T-GARCH | 0.0048 | 0.0029 | 0.0058 | 0.0044 | 0.0117 | 0.0067 |
| TL-GARCH | 0.0030 | 0.0019 | 0.0033 | 0.0026 | 0.0070 | 0.0040 |
| MT-GARCH | 0.0036 | 0.0021 | 0.0046 | 0.0033 | 0.0096 | 0.0054 |
| MTL-GARCH | 0.0030 | 0.0016 | 0.0033 | 0.0026 | 0.0066 | 0.0038 |
| Model | 2016 | 2017 | 2018 | 2019 | 2020 | Total |
|---|---|---|---|---|---|---|
| GARCH(1,1) | 0.0037 | 0.0019 | 0.0058 | 0.0044 | 0.0363 | 0.0105 |
| AVGARCH(1,1) | 0.0034 | 0.0019 | 0.0049 | 0.0037 | 0.0296 | 0.0087 |
| EGARCH(1,1) | 0.0035 | 0.0020 | 0.0060 | 0.0048 | 0.0333 | 0.0100 |
| GJR-GARCH(1,1,1) | 0.0048 | 0.0020 | 0.0074 | 0.0042 | 0.0404 | 0.0118 |
| TrGARCH(1,1,1) | 0.0042 | 0.0020 | 0.0069 | 0.0038 | 0.0365 | 0.0107 |
| FIGARCH(1,1) | 0.0038 | 0.0021 | 0.0055 | 0.0041 | 0.0361 | 0.0104 |
| ANN-GARCH | 0.0029 | 0.0019 | 0.0038 | 0.0029 | 0.0095 | 0.0042 |
| LSTM-GARCH | 0.0022 | 0.0015 | 0.0027 | 0.0021 | 0.0060 | 0.0029 |
| T-GARCH | 0.0035 | 0.0021 | 0.0041 | 0.0031 | 0.0070 | 0.0040 |
| TL-GARCH | 0.0020 | 0.0014 | 0.0021 | 0.0018 | 0.0044 | 0.0023 |
| MT-GARCH | 0.0024 | 0.0016 | 0.0031 | 0.0023 | 0.0057 | 0.0030 |
| MTL-GARCH | 0.0019 | 0.0012 | 0.0021 | 0.0018 | 0.0041 | 0.0022 |
| Model | 2016 | 2017 | 2018 | 2019 | 2020 | Total |
|---|---|---|---|---|---|---|
| GARCH(1,1) | 0.543 | 0.540 | 0.051 | 0.543 | 0.052 | 0.008 |
| AVGARCH(1,1) | 0.543 | 0.540 | 0.051 | 0.543 | 0.052 | 0.008 |
| EGARCH(1,1) | 0.543 | 0.540 | 0.051 | 0.543 | 0.052 | 0.008 |
| GJR-GARCH(1,1,1) | 0.543 | 0.540 | 0.011 | 0.543 | 0.190 | 0.008 |
| TrGARCH(1,1,1) | 0.543 | 0.540 | 0.051 | 0.810 | 0.190 | 0.042 |
| FIGARCH(1,1) | 0.543 | 0.540 | 0.051 | 0.543 | 0.052 | 0.008 |
| ANN-GARCH | 0.543 | 0.540 | 0.001 | 0.002 | 0.012 | 0.001 |
| LSTM-GARCH | 0.810 | 0.186 | 0.540 | 0.188 | 0.190 | 0.042 |
| T-GARCH | 0.188 | 0.540 | 0.002 | 0.543 | 0.052 | 0.001 |
| TL-GARCH | 0.543 | 0.540 | 0.813 | 0.810 | 0.810 | 0.782 |
| MT-GARCH | 0.112 | 0.540 | 0.540 | 0.188 | 0.052 | 0.089 |
| MTL-GARCH | 0.543 | 0.113 | 0.113 | 0.810 | 0.190 | 0.910 |
| Model | 2016 | 2017 | 2018 | 2019 | 2020 | Total |
|---|---|---|---|---|---|---|
| GARCH(1,1) | 0.522 | 0.520 | 0.004 | 0.523 | 0.048 | 0.002 |
| AVGARCH(1,1) | 0.522 | 0.520 | 0.004 | 0.523 | 0.048 | 0.002 |
| EGARCH(1,1) | 0.522 | 0.520 | 0.004 | 0.523 | 0.048 | 0.002 |
| GJR-GARCH(1,1,1) | 0.522 | 0.520 | 0.002 | 0.523 | 0.179 | 0.002 |
| TrGARCH(1,1,1) | 0.522 | 0.520 | 0.004 | 0.800 | 0.179 | 0.009 |
| FIGARCH(1,1) | 0.522 | 0.520 | 0.004 | 0.523 | 0.048 | 0.002 |
| ANN-GARCH | 0.522 | 0.520 | 0.001 | 0.002 | 0.002 | 0.001 |
| LSTM-GARCH | 0.800 | 0.180 | 0.520 | 0.177 | 0.179 | 0.037 |
| T-GARCH | 0.176 | 0.520 | 0.001 | 0.523 | 0.048 | 0.001 |
| TL-GARCH | 0.522 | 0.520 | 0.803 | 0.800 | 0.797 | 0.693 |
| MT-GARCH | 0.113 | 0.520 | 0.520 | 0.177 | 0.048 | 0.079 |
| MTL-GARCH | 0.522 | 0.113 | 0.113 | 0.800 | 0.179 | 0.790 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos-Pérez, E.; Alonso-González, P.J.; Núñez-Velázquez, J.J. Multi-Transformer: A New Neural Network-Based Architecture for Forecasting S&P Volatility. Mathematics 2021, 9, 1794. https://doi.org/10.3390/math9151794
Ramos-Pérez E, Alonso-González PJ, Núñez-Velázquez JJ. Multi-Transformer: A New Neural Network-Based Architecture for Forecasting S&P Volatility. Mathematics. 2021; 9(15):1794. https://doi.org/10.3390/math9151794
Chicago/Turabian StyleRamos-Pérez, Eduardo, Pablo J. Alonso-González, and José Javier Núñez-Velázquez. 2021. "Multi-Transformer: A New Neural Network-Based Architecture for Forecasting S&P Volatility" Mathematics 9, no. 15: 1794. https://doi.org/10.3390/math9151794
APA StyleRamos-Pérez, E., Alonso-González, P. J., & Núñez-Velázquez, J. J. (2021). Multi-Transformer: A New Neural Network-Based Architecture for Forecasting S&P Volatility. Mathematics, 9(15), 1794. https://doi.org/10.3390/math9151794