1. Introduction
The Kumaraswamy distribution is a well-known distribution, especially to those familiar with the hydrological literature [
1]. Kumaraswamy’s densities are unimodal and uniantimodal and, depending on the parameter values chosen, are either increasing or decreasing or constant functions. Note that most if not all of the above characteristics are shared by both Kumarasawmy and Beta distributions (see [
2,
3,
4]). In fact, Kumarasawmy and Beta distributions share numerous characteristics, although some of them are much more readily available, from the mathematical point of view, for the Kumaraswamy distribution. Kumaraswamy distribution is appropriate for the modeling of bounded natural and physical phenomena, such as atmospheric temperatures or hydrological measurements [
5,
6], record data, such as tests, games or sports [
7], economic observations [
8], or for empirical data with failure rate with an increasing prior [
9]. It is also appropriate in situations where one considers a distribution with infinite lower and/or upper bounds to fit data, when, in fact, the bounds are finite, which makes Kumaraswamy useful in preventive maintenance. Some specific examples discussed in the literature include failure and running times of devices [
10] and deterioration or fatigue failure [
11]. Furthermore, due to the closed form of both its distribution as well as its quantile function (inverse cumulative distribution), Kumaraswamy appears advantageous when it comes to the quantile modeling perspective [
12,
13]. These characteristics make Kumaraswamy useful and easily applicable in reliability theory.
A general class of distributions with Kumaraswamy as a baseline distribution is considered in this work by using a parent continuous distribution function:
. The Kumaraswamy distribution is viewed as the baseline distribution of the proposed G-class because it arises in the trivial case associated with
being the identity function, which corresponds to the
parent distribution. For an arbitrary continuous parent distribution, one can generate a general subclass of distributions with the support that is different from the support of the baseline distribution (i.e., the Kumaraswamy distribution), distribution that is defined like the Beta distribution, in
. The general form of the G-class of distributions based on an arbitrary parent cdf
with Kumaraswamy as the baseline distribution, is defined by the following (see [
2,
14,
15,
16]):
where both parameters
c and
a are considered shape parameters associated with the skewness and a tail weight of
. Note that additional structural parameters associated with
(such as the shape parameter
c) and/or distributional parameters associated with the parent distribution
may also be involved in (
1). Due to the fact that the distribution function in (
1) is written in a closed form, it can be effectively used for both uncensored and censored data in reliability theory as well as in survival analysis.
The statistical inference, including parameter estimation in the context of reliability modeling, is of vital importance. In addition to the use of a proper distribution, such as (
1), for modeling purposes, one may also be interested in evaluating the performance of the reliability system involved. Indeed, for instance, the problem of performance of a system is of great importance in mechanical engineering and refers to a component of strength
X, which is subject to stress
Y. The system stays in operation as long as the stress is less than the strength, so the system performance is associated with the probability of exceedance, usually denoted by
R. The quantity of interest in such cases is the
stress–strength reliability or reliability parameter which is a measure of reliability defined by the following:
The concept of
stress–strength reliability has been investigated extensively in the literature for various lifetime distributions. The reliability parameter has been obtained for several distributions that typically appear in reliability analyses, such as Exponential, Gamma, Weibull, Burr, Marshall–Olkin extended Lomax distribution and inverse Rayleigh distribution. Such distributions were considered for at least one of the two variables of interest, namely
X and
Y (see [
17,
18,
19,
20,
21]).
In this work, we focus on the general class of distributions of the form (
1), using a parent continuous distribution function, and discuss some of its properties, including the stress–strength reliability. In addition, and for a multi-state system, we provide parameter estimates for the class given in (
1), which are assumed to vary over the states of the system. The theoretical part of the work also includes the asymptotics for the proposed estimators. The performance of the proposed methodology is investigated with simulated results.
The paper is organized as follows: In
Section 2, we propose and discuss the G-class of distributions (
1). In
Section 3 and
Section 4, the semi-Markov setting and the parameter estimation are provided. Reliability characteristics are discussed in
Section 5, while applications are analyzed in the final section.
2. The G-Class of Distributions
Consider the family of distributions with shape parameter
a and distribution function, given by the following:
which is absolutely continuous w.r.t. the Lebesgue measure, with density function
and with
being the standard family member when
. Classical reliability distributions, such as Exponential, Rayleigh and Weibull distributions are members of (
3). One of the special features of (
3) is that the distribution of the minimum, i.e., of the ordered statistic
of a random sample
from (
3), falls within this class (see [
22,
23]).
Notice that the
general G-class of distributions in (
1) with a parent continuous distribution
builds a new general class of distributions with each member lying within the class given in (
3), with
and Kumaraswamy as the baseline distribution of the entire class. It should be noted that the baseline (Kumaraswamy) distribution is obtained for the Uniform distribution in
, i.e., for the identity function
, with cdf provided by the following expression:
Note that the Kumaraswamy distribution is a member of the
G-class (
1) with
. Kumaraswamy distribution, which, due to the form of the function
G, can be viewed as a Generalized Uniform distribution, is an easy to handle distribution in the sense that it has simple explicit expressions for the distribution and quantile functions as well as the L-moments and the moments of order statistics [
2]. Furthermore, it has a simple formula for the generation of random samples. The proposed general G-class though, goes beyond the Kumaraswamy since for each (any) continuous distribution chosen as the parent distribution G (i.e., Exponential, Gamma, Weibull, Gumbel, Rayleigh, and Inverse Gaussian), a new special/specific general (sub)class of densities arises (Generalized Exponential, Gamma, Weibull, Gumbel, Rayleigh or Inverse Gaussian, etc.). Observe that each of these general specific subclasses offers additional flexibility to the researcher for accommodating complex reliability phenomena. Observe further that the G-class in (
1) generates a family of distributions with support that goes beyond the restrictive support
of the baseline distribution in (
4) and, in fact, it coincides with the support of the parent distribution
. This characteristic extends even further the applicability of the G-class of distributions, covering, among others, classical reliability and survival analysis problems, where the time-to-event is the main feature to be investigated (see, for example, [
24]).
2.1. Basic Characteristics of the G-Class of Distributions
The basic functions, including the pdf of the G-class of distributions (
1), are given in the lemma below.
Lemma 1. Let X be a random variable from the G-class of distributions (1) with being absolutely continuous with respect to the Lebesgue measure. Then, the density function, the hazard (failure) rate function, the reversed hazard rate function, and the cumulative hazard rate function, are the following:where the pdf associated with . Proof. The results follow immediately using the following standard definitions:
where
F is the cdf of the random variable involved, given in the case at hand, by (
1). □
Having as the baseline distribution of (
1) the Kumaraswamy distribution given in (
4), it is easily seen that the associated pdf is given by the following:
Taking as a parent distribution the Exponential distribution with
, we have the following:
and
while for the Weibull distribution with
as a parent distribution, we have the following:
and
For the baseline Kumaraswamy distribution
, observe that if the random variable
then
and
. However, if
then
and
. In addition, if
then
. In general, the parameters
c and
a control the skewness and the tail of the distribution so that the
G-class becomes ideal for fitting skew data, which cannot be otherwise described.
As expected, irrespective of the parent distribution, the resulting distribution is a member of (
1) as summarized below.
Lemma 2. Let G be a specific distribution function with dimensional distribution parameter . Then, for the specific parent continuous distribution , the resulting is a member of the G-class of distributions (1). Proof. Consider a cdf
and define
such that
. Then, the resulted
F satisfies expression (
1) and the result is immediate. □
Reliability Characteristics
In this section, we provide some basic reliability characteristics, including the expression for the reliability parameter in the case of two random variables with distributions in the G-class of distributions, with different shape parameters.
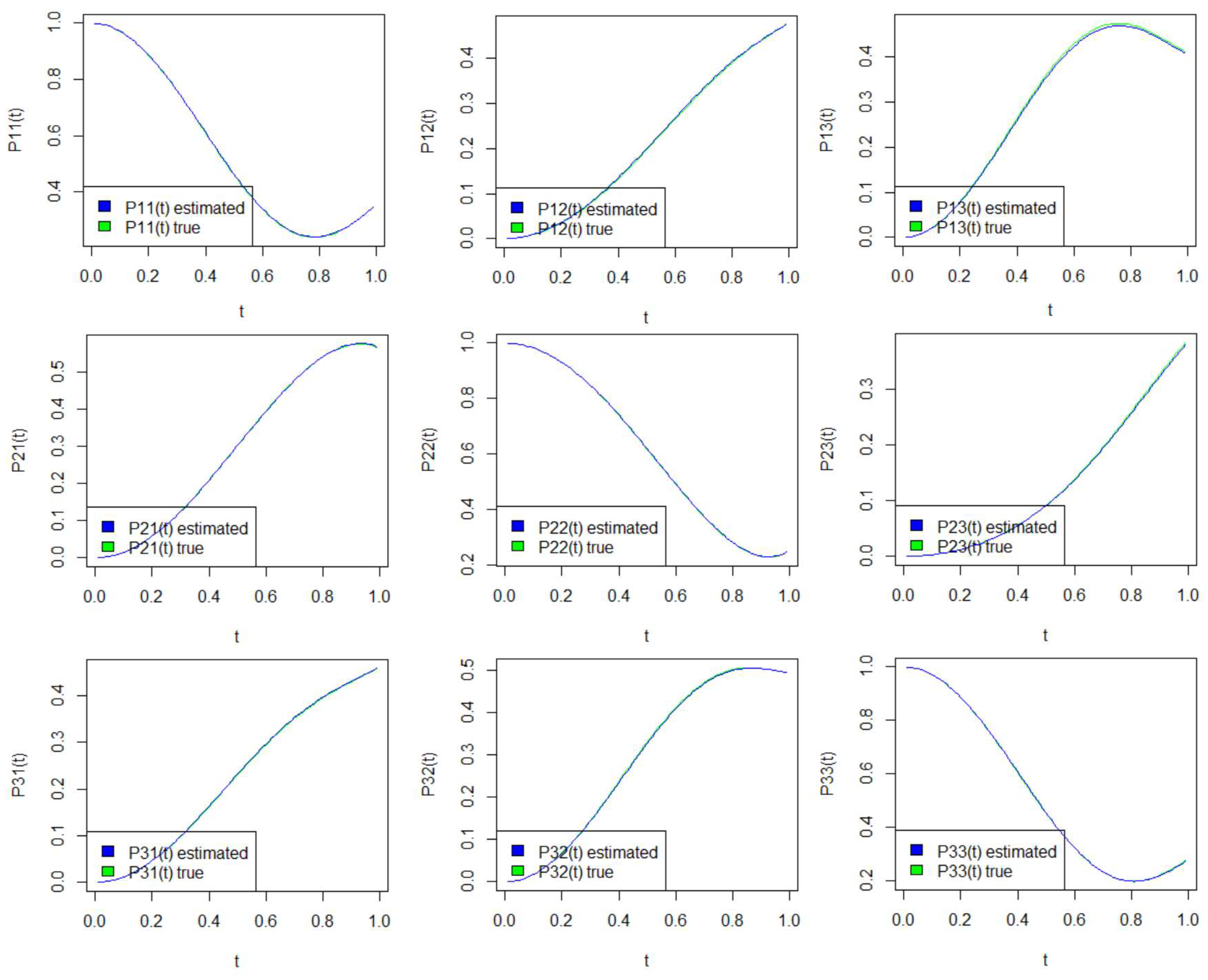
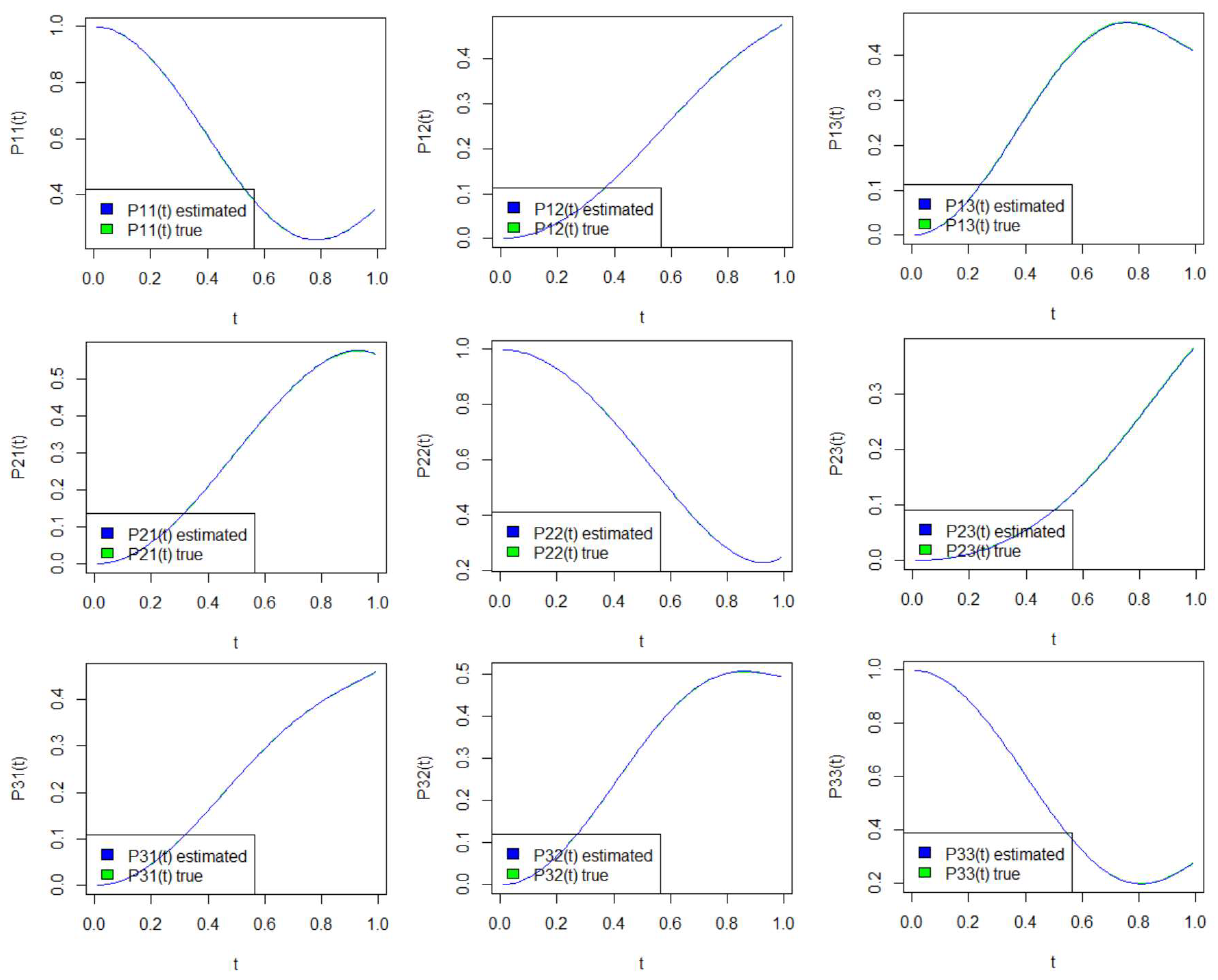
Theorem 1. Let T be a random variable with cdf belonging to the G-class. Then, the reliability and hazard functions of the random variable T are given, respectively, by the following:and Proof. The result is immediate from the definitions of the reliability and hazard functions and the expressions (
1) and (
5). □
Theorem 2. Let be independent random variables from the G-class with shape parameters and , respectively, and common shape parameter c. Then, the reliability parameter R given in (2) is a constant that depends only on the shape parameters and . Proof. Let
and
with
, the common parent distribution that may or may not depend on distributional parameters.
The reliability parameter can be written as the following:
Setting
and
the above integration becomes:
□
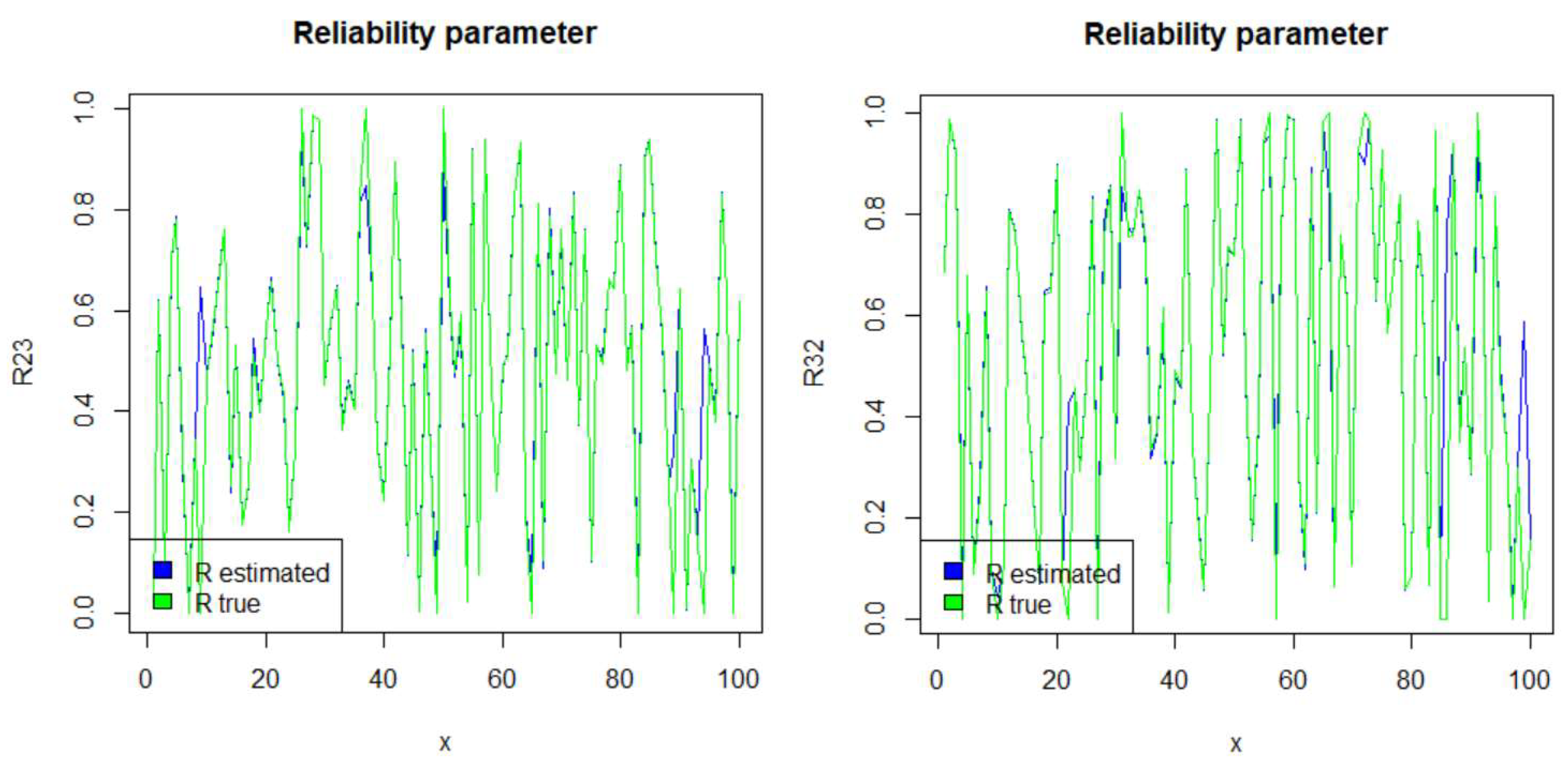
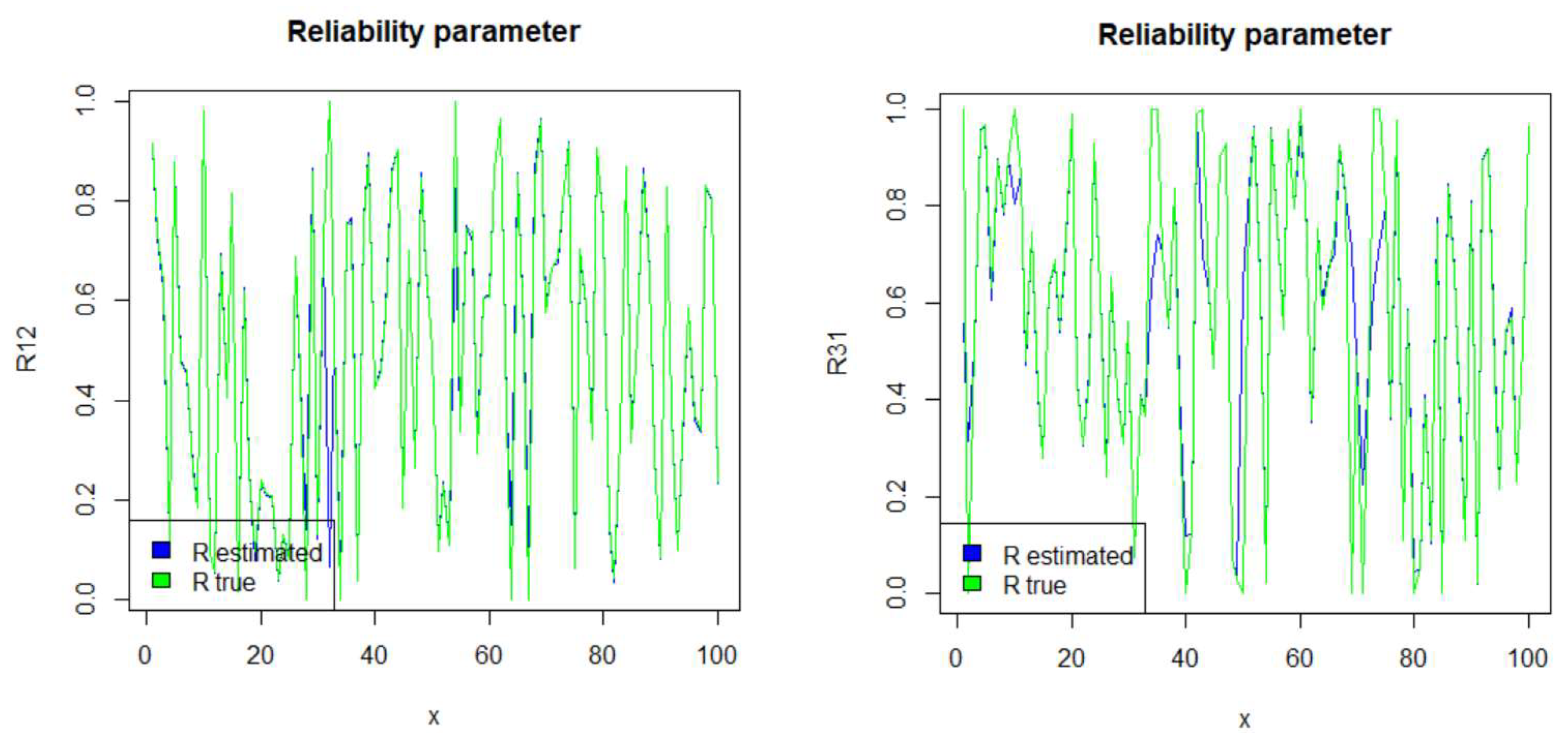
Remark 1. Consider X and Y, two random variables having the baseline Kumaraswamy distribution of the G-class. In this case and under the setting of Theorem 2, the reliability parameter between X and Y is the following: Setting and , we have the following: Remark 2. If we consider as the parent distribution the Exponential distribution , and under the setting of Theorem 2, the reliability parameter associated with X and Y is the following:which, for and takes the following form: Remark 3. If , then the two distributions of the G-class (for any continuous ) share a common shape parameter, i.e., . In general, for thenso that if while if . Thus, R increases if increases as compared to ; otherwise R decreases. 2.2. Ordered Statistics and Distribution of the Minimum
In this section, we establish that the G-class is closed under minima which is a significant property with a pivotal role in inferential statistics under the multi-state setting of the following section.
Theorem 3. If are random variables from the G-class, then the distribution function of the minimum ordered statistic is given by the following:and belongs to the G-class. Proof. It is straightforward that
which belongs to the G-class with shape parameters
c and
. □
Lemma 3. Let be random variables from the G-class of distributions (1), where G is the Exponential distribution. The distribution function of the first ordered statistic falls into the G-class. Proof. The result arises naturally from the previous theorem. In fact, by substituting
the distribution of the minimum becomes the following:
□
Remark 4. The results of this section can be generalized by dropping the assumption of identically distributed random variables. Indeed, if one considers the case of independent but not necessarily identically distributed (inid) r.v’s and assumes a random sample with the cdf of , being given bythen Theorem 3 still holds true with belonging to the G-class (1) with parameters c and , namely the following: The next subsection concentrates on inid r.v’s under the multi-state setting with the sojourn times
(the time spend on state
i before moving to state
j) having a distribution
, belonging to (
1) with shape parameter
, and a common parameter
c for any
with
N representing the finite number of system states. From a practical point of view, such a setting is quite meaningful since the transition from one state to another in multi-state systems is not necessarily described by the iid framework. Thus, for instance, the waiting time in a state
i (before the system moves to state
j) could be properly described by, for example, the Exponential distribution, but the distribution of the waiting time in state
i or even in state
j (before moving to state
k) may have a heavier or lighter tail than the Exponential distribution. Such situations are tractable within our
inid framework by allowing the parameter controlling the tail part of the distribution, i.e., the parameter
a, to vary according to the specific current and next visited states. The case of varying both
a and
c parameters is a complex mathematical problem that will be left for future work.
3. The Semi-Markov Model and Multi-State Systems
A multi-state model is a continuous time stochastic process with values in a discrete set. Diverting from the standard class of Markov processes to the semi-Markov processes, we abandon the restriction of memoryless state sojourn times but, at the same time, we retain the treatment of the data as jump processes in continuous time. In fact, for semi-Markov processes, the Markov property is assumed only for the embedded chain of distinct visited states and we also have a Markov property that acts on random time instants, i.e., on the jump time instants. Such characteristics allow for a great applicability of semi-Markov processes in fields such as economics, finance, survival analysis, reliability, health care systems, etc. [
25,
26,
27,
28,
29,
30,
31].
Consider a stochastic jump process with state space We denote by the jump times, by the visited states at these times and by the sojourn times,
We assume that
is a
semi-Markov process (SMP) and that
is a
Markov renewal process (MRP) associated to the SMP (cf. [
29]). It immediately follows that
is a Markov chain, called the
embedded Markov chain. Let us also denote by
the counting process of the number of jumps in the time interval
.
We assume that the SMP is regular, that is for all and state
A SMP is defined by the
initial law:
and the
semi-Markov kernel:
We can also define the
transition probabilities of
as follows:
and the
conditional sojourn time distribution functions as the following:
So, we have the following:
The time spent in state i before moving directly to state j is denoted by let be the corresponding cumulative distribution function and the density function with respect to the Lebesgue measure.
The model we consider assumes that the next state to be visited after
i is the one for which
is the minimum. Under this condition, we have the following:
where
and
We denote by
the density of
w.r.t. the Lebesgue measure. Note that
The following proposition holds under the G-class.
Remark 5. The model considered in this work assumes that the next state to be visited after state i is the one for which is the minimum. In many cases, especially in reliability applications, the optimal choice for the next state to be visited is the one with the “lowest cost” or the “minimum distance”. This can be achieved by setting a system such that j is chosen so that the potential time spent in state i before moving directly to state j is minimal over all states in the state-space. The definition for can be adjusted accordingly if one focuses on the cost instead of the time, in which case is the potential cost for the route from state i to state j.
4. Inference with and without Censoring
We proceed now to the statistical inference with and without censoring. More specifically, for the latter case, the sojourn times are fully observed, while, for the former, right censoring is observed at the last visited state.
Let
M be the total observation time. Then, the likelihood function for the case without censoring and for the sample paths
is given by the following:
where
,
: the number of visits to state i up to time M of the lth trajectory, ,
: the number of transitions from state i to state j up to time M during the lth trajectory, ,
,
: the sojourn time in state i during the kth visit, of the lth trajectory, .
Using the relevant expressions associated with the G-class, Equation (
22) becomes the following:
Maximizing accordingly the above function, the maximum likelihood estimators of the parameters
and of the initial distribution law
are obtained:
and
where
Observe that the results above hold for any number of trajectories. For the special case of a single sample path the estimator
could be simplified as follows:
Turning now to the case with censoring at time
M, we consider
L censored sample paths denoted by
. Then, the associated likelihood function is equal to the following:
where
is the observed censored time of the lth trajectory;
is the number of visits of state i, as last visited state, over the L trajectories; note that
is the observed censored sojourn time in state i during the kth visit, .
It should be pointed out that, if M happens to be a jump time, then, for the associated path(s), we have and thus the corresponding likelihood term equals 1. If this happens to occur for all values of , then the censoring case described above collapses to the uncensored case discussed earlier.
For the G-class, the likelihood with censoring for the case of
L trajectories given in (
26) takes the following form:
The resulting estimators
and of the initial distribution law
are provided by the following expressions:
and
Note that, the above results hold for any number of trajectories. For the special case of
the parameter estimates take the following simplified form:
where
represents the last sojourn censored time.
Choosing the appropriate estimator from those obtained in this section, we can now proceed to introduce the estimators of the main components
,
and
of the semi-Markov model:
and
Parameter Estimation for Kumaraswamy Distribution
The estimator of the parameter
for the Kumaraswamy distribution with
in (
1) and without censoring takes the following form:
Note that the maximum likelihood estimator
of the shape parameter
c is obtained by solving the equation given by the following:
Finally note that, in the censored case, the estimator of
becomes:
5. Transition Matrix and Reliability Approach of Semi-Markov Processes
For the purpose of this section, the Markov renewal function,
,
,
is defined as the following [
29]:
where
is the
nth convolution of
Q by itself.
For
, the semi-Markov transition matrix is defined as follows [
29]:
The main idea for a reliability analysis is that the space
E is divided into two subsets—
U, which contains the functioning states, and
D, which contains the failure states—such that
and
, i.e.,
and
. We also consider the corresponding restrictions of any matrix or matrix valued-function, for example,
denoted by
respectively. We denote by
the semi-Markov transition matrix, by
and
the restrictions of
induced by the corresponding restrictions of the semi-Markov kernel to the set
U and
D, respectively (attention:
and
are not the restrictions of
to the sets
U and
D) and by
and
the restrictions of the initial law
to the sets
U and
D, respectively. Finally, let
be the restriction of the embedded Markov chain transition matrix to the set
U. Having this in mind, one can furnish several reliability indices as those derived below. Indeed, for instance, the reliability function and the failure rate are given respectively by the following:
and
Furthermore, the availability
and maintainability
at time
t for a semi-Markov system are defined respectively by the following (for details see [
29,
32]):
where
and
.
Finally, MTTF (the mean time to failure) is given by the following:
where
is the restriction to set
U of the mean sojourn time in state
i,
, which can be estimated by the following:
or










{kind=link}
{kind=link}
{kind=link}
{kind=link}