
NICE: Noise Injection and Clamping Estimation for Neural Network Quantization

 ,
,
Abstract
:1. Introduction
2. Related Work
3. Method
| Algorithm 1 Training a neural network with NICE. N denotes the number of layers; S is the number of epochs in which each layer’s weights are noised; T is the total number of training epochs; c is the current noised layer; i denotes the ith layer; W is the weights of the layer; f denotes the layer’s function, i.e, convolution or fully connected; and and are hyper-parameters. | ||
| 1: | procedureNICE(Network) | ▹ Training using NICE method |
| 2: | for to N do | |
| 3: | ← | ▹ Weights of each layer |
| 4: | ← | ▹ Weights of each layer |
| 5: | ← | ▹ Activations of each layer on training set |
| 6: | ← | ▹ Activations of each layer on training set |
| 7: | ←+× | ▹ Weight clamp |
| 8: | ←+× | ▹ Activations clamp |
| 9: | end for | |
| 10: | e←0 | |
| 11: | c←0 | |
| 12: | while do | |
| 13: | for to N do | |
| 14: | for to S do | |
| 15: | ← | ▹ Adding uniform noise to weights |
| 16: | ← | |
| 17: | ← | |
| 18: | ←f | |
| 19: | ← | |
| 20: | ← | |
| 21: | ▹ Backpropagation | |
| 22: | end for | |
| 23: | c← | |
| 24: | end for | |
| 25: | e← | |
| 26: | end while | |
| 27: | end procedure | |
3.1. Uniform Noise Injection
3.2. Gradual Quantization
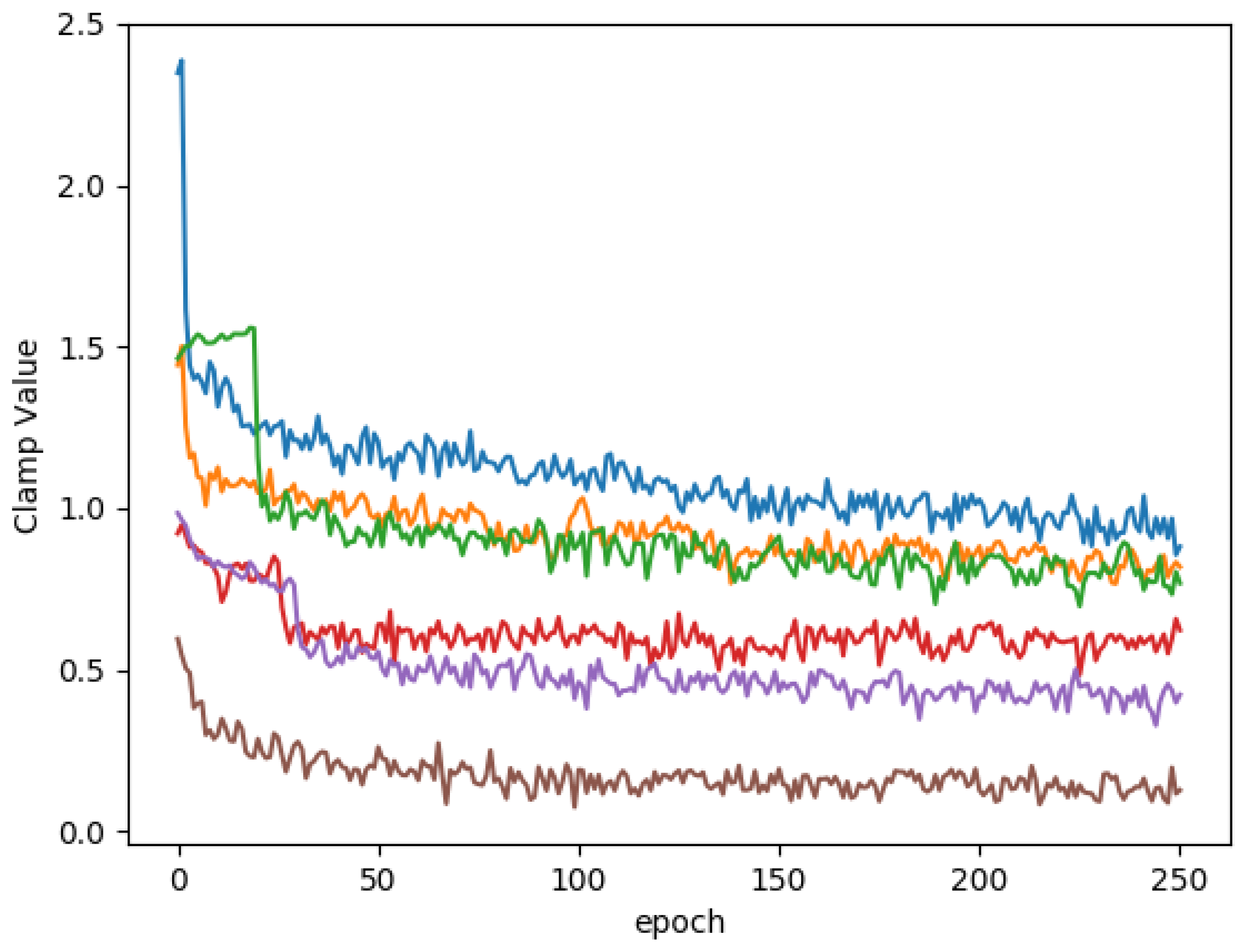
3.3. Clamping and Quantization
4. Results
4.1. CIFAR-10
4.2. ImageNet
4.3. Regression—Joint Denoising and Demosaicing
4.4. Ablation Study
5. Hardware Implementation
5.1. Optimizing Quantization Flow for Hardware Inference
5.2. Hardware Flow
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Molchanov, D.; Ashukha, A.; Vetrov, D. Variational Dropout Sparsifies Deep Neural Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Yu, X.; Liu, T.; Wang, X.; Tao, D. On Compressing Deep Models by Low Rank and Sparse Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Denton, E.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation. arXiv 2014, arXiv:1404.0736. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Jin, P.H.; Zhao, S.; Golmant, N.; Gholaminejad, A.; Gonzalez, J.; Keutzer, K. Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions. arXiv 2017, arXiv:1711.08141. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep learning with limited numerical precision. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15), Lille, France, 6–11 July 2015; pp. 1737–1746. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Schwartz, E.; Giryes, R.; Bronstein, A.M. DeepISP: Learning End-to-End Image Processing Pipeline. arXiv 2018, arXiv:1801.06724. [Google Scholar] [CrossRef] [Green Version]
- Polino, A.; Pascanu, R.; Alistarh, D. Model compression via distillation and quantization. arXiv 2018, arXiv:1802.05668. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 525–542. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations. J. Mach. Learn. Res. 2018, 18, 1–30. [Google Scholar]
- Mishra, A.; Nurvitadhi, E.; Cook, J.J.; Marr, D. WRPN: Wide Reduced-Precision Networks. arXiv 2017, arXiv:1709.01134. [Google Scholar]
- Zhang, D.; Yang, J.; Ye, D.; Hua, G. LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhu, C.; Han, S.; Mao, H.; Dally, W.J. Trained ternary quantization. arXiv 2016, arXiv:1612.01064. [Google Scholar]
- Banner, R.; Hubara, I.; Hoffer, E.; Soudry, D. Scalable Methods for 8-bit Training of Neural Networks. arXiv 2018, arXiv:1805.11046. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. In Proceedings of the International Conference on Learning Representations, ICLR2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. DoReFa-Net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Cai, Z.; He, X.; Sun, J.; Vasconcelos, N. Deep Learning with Low Precision by Half-wave Gaussian Quantization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bengio, Y.; Léonard, N.; Courville, A.C. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Mishra, A.; Marr, D. Apprentice: Using Knowledge Distillation Techniques To Improve Low-Precision Network Accuracy. arXiv 2017, arXiv:1711.05852. [Google Scholar]
- Jung, S.; Son, C.; Lee, S.; Son, J.; Kwak, Y.; Han, J.J.; Choi, C. Joint Training of Low-Precision Neural Network with Quantization Interval Parameters. arXiv 2018, arXiv:1808.05779. [Google Scholar]
- Choi, J.; Wang, Z.; Venkataramani, S.; Chuang, P.I.; Srinivasan, V.; Gopalakrishnan, K. PACT: Parameterized Clipping Activation for Quantized Neural Networks. arXiv 2018, arXiv:1805.06085. [Google Scholar]
- Dong, Y.; Ni, R.; Li, J.; Chen, Y.; Zhu, J.; Su, H. Learning Accurate Low-Bit Deep Neural Networks with Stochastic Quantization. In Proceedings of the British Machine Vision Conference (BMVC’17), London, UK, 4–7 September 2017. [Google Scholar]
- McKinstry, J.L.; Esser, S.K.; Appuswamy, R.; Bablani, D.; Arthur, J.V.; Yildiz, I.B.; Modha, D.S. Discovering Low-Precision Networks Close to Full-Precision Networks for Efficient Embedded Inference. arXiv 2018, arXiv:1809.04191. [Google Scholar]
- Arora, S.; Ge, R.; Neyshabur, B.; Zhang, Y. Stronger generalization bounds for deep nets via a compression approach. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Karbachevsky, A.; Baskin, C.; Zheltonozhskii, E.; Yermolin, Y.; Gabbay, F.; Bronstein, A.M.; Mendelson, A. Early-Stage Neural Network Hardware Performance Analysis. Sustainability 2021, 13, 717. [Google Scholar] [CrossRef]
- Baskin, C.; Schwartz, E.; Zheltonozhskii, E.; Liss, N.; Giryes, R.; Bronstein, A.M.; Mendelson, A. UNIQ: Uniform Noise Injection for the Quantization of Neural Networks. arXiv 2018, arXiv:1804.10969. [Google Scholar]
- Sripad, A.; Snyder, D. A necessary and sufficient condition for quantization errors to be uniform and white. IEEE Trans. Acoust. Speech, Signal Process. 1977, 25, 442–448. [Google Scholar] [CrossRef]
- Gray, R.M. Quantization noise spectra. IEEE Trans. Inf. Theory 1990, 36, 1220–1244. [Google Scholar] [CrossRef]
- Xu, C.; Yao, J.; Lin, Z.; Ou, W.; Cao, Y.; Wang, Z.; Zha, H. Alternating Multi-bit Quantization for Recurrent Neural Networks. arXiv 2018, arXiv:1802.00150. [Google Scholar]
- Khashabi, D.; Nowozin, S.; Jancsary, J.; Fitzgibbon, A.W. Joint Demosaicing and Denoising via Learned Nonparametric Random Fields. IEEE Trans. Image Process. 2014, 23, 4968–4981. [Google Scholar] [CrossRef]
- Wang, D.; An, J.; Xu, K. PipeCNN: An OpenCL-Based FPGA Accelerator for Large-Scale Convolution Neuron Networks. arXiv 2016, arXiv:1611.02450. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activation Bits | |||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 32 | ||
| Weight bits | 2 | 89.5 | 92.53 | 92.69 | 92.71 |
| 3 | 91.32 | 92.74 | 93.01 | 93.26 | |
| 32 | 91.87 | 93.04 | 93.15 | 93.02 | |
| Network | Method | Precision (w,a) | Accuracy (% Top-1) | Accuracy (% Top-5) |
|---|---|---|---|---|
| ResNet-18 | baseline | 32,32 | 69.76 | 89.08 |
| ResNet-18 | FAQ | 8,8 | 70.02 | 89.32 |
| ResNet-18 | NICE (Ours) | 5,5 | 70.35 | 89.8 |
| ResNet-18 | PACT | 5,5 | 69.8 | 89.3 |
| ResNet-18 | NICE (Ours) | 4,4 | 69.79 | 89.21 |
| ResNet-18 | JOINT | 4,4 | 69.3 | - |
| ResNet-18 | PACT | 4,4 | 69.2 | 89.0 |
| ResNet-18 | FAQ | 4,4 | 69.81 | 89.10 |
| ResNet-18 | LQ-Nets | 4,4 | 69.3 | 88.8 |
| ResNet-18 | JOINT | 3,3 | 68.2 | - |
| ResNet-18 | NICE (Ours) | 3,3 | 67.68 | 88.2 |
| ResNet-18 | LQ-Nets | 3,3 | 68.2 | 87.9 |
| ResNet-18 | PACT | 3,3 | 68.1 | 88.2 |
| ResNet-34 | baseline | 32,32 | 73.30 | 91.42 |
| ResNet-34 | FAQ | 8,8 | 73.71 | 91.63 |
| ResNet-34 | NICE (Ours) | 5,5 | 73.72 | 91.60 |
| ResNet-34 | NICE (Ours) | 4,4 | 73.45 | 91.41 |
| ResNet-34 | FAQ | 4,4 | 73.31 | 91.32 |
| ResNet-34 | LQ-Nets | 3,3 | 71.9 | 88.15 |
| ResNet-34 | NICE (Ours) | 3,3 | 71.74 | 90.8 |
| ResNet-50 | baseline | 32,32 | 76.15 | 92.87 |
| ResNet-50 | FAQ | 8,8 | 76.52 | 93.09 |
| ResNet-50 | PACT | 5,5 | 76.7 | 93.3 |
| ResNet-50 | NICE (Ours) | 5,5 | 76.73 | 93.31 |
| ResNet-50 | NICE (Ours) | 4,4 | 76.5 | 93.3 |
| ResNet-50 | LQ-Nets | 4,4 | 75.1 | 92.4 |
| ResNet-50 | PACT | 4,4 | 76.5 | 93.2 |
| ResNet-50 | FAQ | 4,4 | 76.27 | 92.89 |
| ResNet-50 | NICE (Ours) | 3,3 | 75.08 | 92.35 |
| ResNet-50 | PACT | 3,3 | 75.3 | 92.6 |
| ResNet-50 | LQ-Nets | 3,3 | 74.2 | 91.6 |
| Method | Bits | Bits | Bits | Bits | Bits |
|---|---|---|---|---|---|
| (w = 32, a = 32) | (w = 4, a = 8) | (w = 4, a = 6) | (w = 4, a = 5) | (w = 3, a = 6) | |
| NICE (Ours) | 39.696 | 39.456 | 39.332 | 39.167 | 38.973 |
| WRPN (our experiments) | 39.696 | 38.086 | 37.496 | 36.258 | 36.002 |
| Noise with Gradual Training | Activation Clamping Learning | Accuracy on 5,5 [w,a] | Accuracy on 3,3 [w,a] |
|---|---|---|---|
| - | - | 69.72 | 66.51 |
| - | ✓ | 69.9 | 67.2 |
| ✓ | - | 70.25 | 66.7 |
| ✓ | ✓ | 70.3 | 67.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baskin, C.; Zheltonozhkii, E.; Rozen, T.; Liss, N.; Chai, Y.; Schwartz, E.; Giryes, R.; Bronstein, A.M.; Mendelson, A. NICE: Noise Injection and Clamping Estimation for Neural Network Quantization. Mathematics 2021, 9, 2144. https://doi.org/10.3390/math9172144
Baskin C, Zheltonozhkii E, Rozen T, Liss N, Chai Y, Schwartz E, Giryes R, Bronstein AM, Mendelson A. NICE: Noise Injection and Clamping Estimation for Neural Network Quantization. Mathematics. 2021; 9(17):2144. https://doi.org/10.3390/math9172144
Chicago/Turabian StyleBaskin, Chaim, Evgenii Zheltonozhkii, Tal Rozen, Natan Liss, Yoav Chai, Eli Schwartz, Raja Giryes, Alexander M. Bronstein, and Avi Mendelson. 2021. "NICE: Noise Injection and Clamping Estimation for Neural Network Quantization" Mathematics 9, no. 17: 2144. https://doi.org/10.3390/math9172144
APA StyleBaskin, C., Zheltonozhkii, E., Rozen, T., Liss, N., Chai, Y., Schwartz, E., Giryes, R., Bronstein, A. M., & Mendelson, A. (2021). NICE: Noise Injection and Clamping Estimation for Neural Network Quantization. Mathematics, 9(17), 2144. https://doi.org/10.3390/math9172144