
Cancer Cell Profiling Using Image Moments and Neural Networks with Model Agnostic Explainability: A Case Study of Breast Cancer Histopathological (BreakHis) Database

 ,
, 
Abstract
:1. Introduction
- Breast cancer histopathology (BreakHis) images for automatic cancer prediction are studied, which is a challenging task even for trained pathologists and trainees. The proposed system will assist in reducing manual repetitive tasks and increase accuracy using the power of machine learning.
- Zernike moments are used for feature extraction and vectorization, which are rotation invariant and can be made scale and translation invariant. It is an ideal choice for shape detectors where color does not matter and can be ignored for H&E (hematoxylin and eosin) staining.
- Artificial Neural Networks (ANN) are used for binary classification, and Explainable Artificial Intelligence (XAI) Local Interpretable Model-Agnostic Explanations (LIME) is used to justify test results visually.
2. Literature Review
3. Background
3.1. Feature Extraction Techniques
3.2. Classification Techniques
3.3. Explainable Artificial Intelligence (XAI) LIME Model
| Algorithm 1 Algorithm of XAI LIME is summarized as below [23] |
| Input: data feature vector x, classifier f, number of features m and super-pixels n for granularity to highlight Output: coefficients of the explainable linear model STEP 1: y: = f(x) i.e., prediction by f(.) on x STEP 2: if i > n goto Step 6 STEP 3: p: = randomPickSuperpixel(x) %permute function STEP 4: observation: = f(p) i.e., predict p on f STEP 5: distance: = abs(y-observation) STEP 6: SimilarityScore: = ComputeSimScore(distance) STEP 7: x: = xPick(SimilarityScore,m,p) STEP 8: L: = LinearModelFitting (SimilarityScore,m,p) STEP 9: Return weights obtained by L |
4. Methodology
5. Results and Discussion
5.1. Dataset
5.2. Feature Extraction Using Zernike Moments
5.3. Data Visualization Using PCA
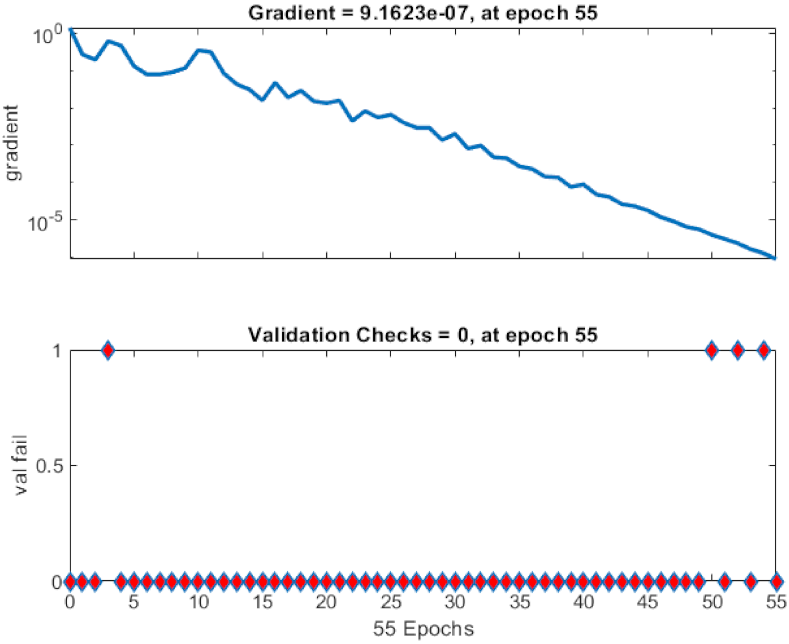
5.4. Classification
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Neural Network Weights and Bias Values
- weight and bias values:
- IW: {2x1 cell} containing 1 input weight matrix
- LW: {2x2 cell} containing 1 layer weight matrix
- b: {2x1 cell} containing 2 bias vectors

- MATLAB code:
- % Solve a Pattern Recognition Problem with a Neural Network
- % Script generated by Neural Pattern Recognition app
- % Created 20 September 2021 15:40:17
- %
- % This script assumes these variables are defined:
- %
- % ZMs-input data. (Zernike moments 625x12 sick and 1370x12 healthy vectors)
- % Y-target data. (625x1 zeros, 1370x1 ones)
- x = ZMs’;
- t = Y’;
- % Choose a Training Function
- % For a list of all training functions type: help nntrain
- % ‘trainlm’ is usually fastest.
- % ‘trainbr’ takes longer but may be better for challenging problems.
- % ‘trainscg’ uses less memory. Suitable in low memory situations.
- trainFcn = ‘trainscg’; % Scaled conjugate gradient backpropagation.
- % Create a Pattern Recognition Network
- hiddenLayerSize = 10;
- net = patternnet(hiddenLayerSize, trainFcn);
- % Choose Input and Output Pre/Post-Processing Functions
- % For a list of all processing functions type: help nnprocess
- net.input.processFcns = {‘removeconstantrows’,’mapminmax’};
- % Setup Division of Data for Training, Validation, Testing
- % For a list of all data division functions type: help nndivision
- net.divideFcn = ‘dividerand’; % Divide data randomly
- net.divideMode = ‘sample’; % Divide up every sample
- net.divideParam.trainRatio = 70/100;
- net.divideParam.valRatio = 15/100;
- net.divideParam.testRatio = 15/100;
- % Choose a Performance Function
- % For a list of all performance functions type: help nnperformance
- net.performFcn = ‘crossentropy’; % Cross-Entropy
- % Choose Plot Functions
- % For a list of all plot functions type: help nnplot
- net.plotFcns = {‘plotperform’,’plottrainstate’,’ploterrhist’, ...
- ‘plotconfusion’, ‘plotroc’};
- % Train the Network
- [net,tr] = train(net,x,t);
- % Test the Network
- y = net(x);
- e = gsubtract(t,y);
- performance = perform(net,t,y)
- tind = vec2ind(t);
- yind = vec2ind(y);
- percentErrors = sum(tind ~= yind)/numel(tind);
- % Recalculate Training, Validation and Test Performance
- trainTargets = t .* tr.trainMask{1};
- valTargets = t .* tr.valMask{1};
- testTargets = t .* tr.testMask{1};
- trainPerformance = perform(net,trainTargets,y)
- valPerformance = perform(net,valTargets,y)
- testPerformance = perform(net,testTargets,y)
- % View the Network
- view(net)
- % Plots
- % Uncomment these lines to enable various plots.
- %figure, plotperform(tr)
- %figure, plottrainstate(tr)
- %figure, ploterrhist(e)
- %figure, plotconfusion(t,y)
- %figure, plotroc(t,y)
- % Deployment
- % Change the (false) values to (true) to enable the following code blocks.
- % See the help for each generation function for more information.
- if (false)
- % Generate MATLAB function for neural network for application
- % deployment in MATLAB scripts or with MATLAB Compiler and Builder
- % tools, or simply to examine the calculations your trained neural
- % network performs.
- genFunction(net,’myNeuralNetworkFunction’);
- y = myNeuralNetworkFunction(x);
- end
- if (false)
- % Generate a matrix-only MATLAB function for neural network code
- % generation with MATLAB Coder tools.
- genFunction(net,’myNeuralNetworkFunction’,’MatrixOnly’,’yes’);
- y = myNeuralNetworkFunction(x);
- end
- if (false)
- % Generate a Simulink diagram for simulation or deployment with.
- % Simulink Coder tools.
- gensim(net);
- end
References
- Cancer, WHO. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 7 May 2021).
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- GLOBOCAN 2020: New Global Cancer Data. Available online: https://www.uicc.org/news/globocan 2020 new global cancer data (accessed on 7 May 2021).
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A Dataset for Breast Cancer Histopathological Image Classification. IEEE Trans. Biomed. Eng. 2016, 63, 1455–1462. [Google Scholar] [CrossRef] [PubMed]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. Breast cancer histopathological image classification using Convolutional Neural Networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2560–2567. [Google Scholar] [CrossRef]
- Spanhol, F.A.; Oliveira, L.S.; Cavalin, P.R.; Petitjean, C.; Heutte, L. Deep features for breast cancer histopathological image classification. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 1868–1873. [Google Scholar] [CrossRef]
- Zhu, C.; Song, F.; Wang, Y.; Dong, H.; Guo, Y.; Liu, J. Breast cancer histopathology image classification through assembling multiple compact CNNs. BMC Med. Inf. Decis. Mak. 2019, 19, 198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Komura, D.; Ishikawa, S. Machine learning methods for histopathological image analysis. Comput. Struct. Biotechnol. J. 2018, 16, 34–42. [Google Scholar] [CrossRef] [PubMed]
- Koelzer, V.H.; Sirinukunwattana, K.; Rittscher, J.; Mertz, K.D. Precision immunoprofiling by image analysis and artificial intelligence. Virchows Arch. 2019, 474, 511–522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Robertson, S.; Azizpour, H.; Smith, K.; Hartman, J. Digital image analysis in breast pathology—From image processing techniques to artificial intelligence. Transl. Res. 2018, 194, 19–35. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.; Chen, H.; Li, X.; Xu, N.; Sun, H. A review for cervical histopathology image analysis using machine vision approaches. Artif. Intell. Rev. 2020, 53, 4821–4862. [Google Scholar]
- Linder, N.; Turkki, R.; Nordling, S.; Kovanen, P.E.; Verrill, C.; Walliander, M.; Lundin, M.; Haglund, C.; Lundin, J. Deep learning based tissue analysis predicts outcome in colorectal cancer. Sci. Rep. 2018, 8, 1–11. [Google Scholar]
- Couture, H.D.; Williams, L.A.; Geradts, J.; Nyante, S.J.; Butler, E.N.; Marron, J.S.; Perou, C.M.; Troester, M.A.; Niethammer, M. Image analysis with deep learning to predict breast cancer grade, ER status, histologic subtype, and intrinsic subtype. NPJ Breast Cancer 2018, 4, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Klein, O.; Kanter, F.; Kulbe, H.; Jank, P.; Denkert, C.; Nebrich, G.; Schmitt, W.D.; Wu, Z.; Kunze, C.A.; Sehouli, J.; et al. MALDI-imaging for classification of epithelial ovarian cancer histotypes from a tissue microarray using machine learning methods. PROTEOMICS–Clin. Appl. 2019, 13, 1700181. [Google Scholar] [CrossRef] [Green Version]
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm intelligence algorithms for feature selection: A review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef] [Green Version]
- Khotanzad, A.; Hong, Y.H. Invariant image recognition by Zernike moments. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 489–497. [Google Scholar] [CrossRef] [Green Version]
- Teague, M.R. Image analysis via the general theory of moments. JOSA 1980, 70, 920–930. [Google Scholar] [CrossRef]
- Singh, C.; Upneja, R. Error analysis in the computation of orthogonal rotation invariant moments. J. Math. Imag. Vis. 2014, 49, 251–271. [Google Scholar] [CrossRef]
- Du, K.L.; Swamy, M.N.S. Neural Networks and Statistical Learning; Springer: London, UK, 2019; p. 988. ISBN 978-1-4471-7452-3. [Google Scholar]
- Malik, H.; Singh, M. Comparative study of different neural networks for 1-year ahead load forecasting. In Applications of Artificial Intelligence Techniques in Engineering; Springer: Singapore, 2019; pp. 31–42. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016. [Google Scholar]
- Siddharth, S.; Omare, N.; Shukla, K.K. An Approach to identify Captioning Keywords in an Image using LIME. In Proceedings of the 2021 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 19–20 February 2021. [Google Scholar]
- Arun, D.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. Arxiv Prepr. Arxiv. 2020, 2006, 11371. [Google Scholar]
- Markus, R. What is principal component analysis? Nat. Biotechnol. 2008, 26, 303–304. [Google Scholar]
- Svante, W.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar]
- Baptista, F.; Darío, S.R.; Fernando, M.-D. Performance comparison of ANN training algorithms for classification. In Proceedings of the 2013 IEEE 8th International Symposium on Intelligent Signal Processing, Funchal, Portugal, 16–18 September 2013. [Google Scholar]
- Dudzik, M. Towards characterization of indoor environment in smart buildings: Modelling PMV index using neural network with one hidden layer. Sustainability 2020, 12, 6749. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Dataset/Type of Images | Contribution | Pros/Cons |
|---|---|---|---|---|
| [4] | 2016 | Breast cancer histopathological images BreaKHis dataset | BreaKHis dataset collection from 7909 breast cancer histopathology images acquired on 82 patients | Max accuracy is 85% using basic image features and traditional machine learning methods. |
| [5] | 2016 | BreaKHis dataset | Applied CNN on the collected BreaKHis dataset | Accuracy improved slightly than [4] but still room for enhancement |
| [6] | 2017 | BreaKHis dataset | In between solution of [4,5] i.e., using deep features to input for the classifiers | Better accuracy than [4] and in some cases of [5] |
| [7] | 2019 | BreaKHis dataset | Assembling multiple CNNs and embedding Squeeze Excitation Pruning (SEP) block to remove redundant channels and reduce overfitting | Time consuming as compared to traditional supervised ML models |
| [8] | 2018 | Histopathological images | Review article about digital pathology with machine learning | Limitations are color variation, artefacts, intensity variations, multiple magnification levels to select from |
| [9] | 2019 | Colorectal cancer | Precision immunoprofiling by image analysis and artificial intelligence | Advanced image analysis and AI techniques should be explored |
| [10] | 2018 | Breast cancer | AI and deep learning techniques have been used for diagnostic breast pathology | Contribution is to identify patterns not visible for the eye of a pathologist or so called ‘imaging biomarkers’ using deep learning |
| [11] | 2020 | Colorectal adenocarcinoma tissue | A review of 1988–2020 for cervical histopathology image analysis using machine vision | New AI and image processing algorithms should be explored. Model performance is based upon underlying data distribution. |
| [12] | 2018 | Colorectal cancer | Tissue analysis in colorectal cancer using deep learning | Directly predict patient outcome with AUC = 0.69, without any intermediate tissue classification; samples from 420 patients |
| [13] | 2018 | Breast cancer | Breast cancer grade prediction using image analysis and deep learning | Ductal vs. Lobular (94% accuracy), limitation is that dataset size was small |
| [14] | 2019 | Ovarian cancer from MALDI images | Tissue microarray (TMA) for ovarian cancer histotypes using ML | CNN and NN are suitable for epithelial ovarian cancer (EOC), sensitivity (69–100%) and specificity (90–99%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaplun, D.; Krasichkov, A.; Chetyrbok, P.; Oleinikov, N.; Garg, A.; Pannu, H.S. Cancer Cell Profiling Using Image Moments and Neural Networks with Model Agnostic Explainability: A Case Study of Breast Cancer Histopathological (BreakHis) Database. Mathematics 2021, 9, 2616. https://doi.org/10.3390/math9202616
Kaplun D, Krasichkov A, Chetyrbok P, Oleinikov N, Garg A, Pannu HS. Cancer Cell Profiling Using Image Moments and Neural Networks with Model Agnostic Explainability: A Case Study of Breast Cancer Histopathological (BreakHis) Database. Mathematics. 2021; 9(20):2616. https://doi.org/10.3390/math9202616
Chicago/Turabian StyleKaplun, Dmitry, Alexander Krasichkov, Petr Chetyrbok, Nikolay Oleinikov, Anupam Garg, and Husanbir Singh Pannu. 2021. "Cancer Cell Profiling Using Image Moments and Neural Networks with Model Agnostic Explainability: A Case Study of Breast Cancer Histopathological (BreakHis) Database" Mathematics 9, no. 20: 2616. https://doi.org/10.3390/math9202616
APA StyleKaplun, D., Krasichkov, A., Chetyrbok, P., Oleinikov, N., Garg, A., & Pannu, H. S. (2021). Cancer Cell Profiling Using Image Moments and Neural Networks with Model Agnostic Explainability: A Case Study of Breast Cancer Histopathological (BreakHis) Database. Mathematics, 9(20), 2616. https://doi.org/10.3390/math9202616