1. Introduction
Parametric probability distributions are used in several specific fields such as reliability of complex systems and different industrial applications, among them, electronics. The study of reliability is an essential tool at the industry, mostly when products are made of a high number of different components. These probability distributions are assumed to be fully known, and the corresponding properties are analysed in depth. A specific statistical inference is carried out to estimate the parameters of the distribution from a process data. In this context, maximum likelihood is one of the most considered methodologies used thanks to the good asymptotic properties of the estimators. Care must be taken to diagnose the underlying assumptions associated with the assumed specific parametric distribution to ensure a reasonable fit with the empirical data.
A detailed review of the most used basic parametric probability distributions in reliability can be seen in [
1,
2,
3]. Key text books in reliability and related topics tend to present parametric probability distributions in detail, see, e.g., [
4,
5]. Some of the most commonly used parametric probability distributions are the exponential, Weibull and log-normal distribution. Ref. [
6] proposed a new approach based on different Weibull distributions for modelling the lifetime data in systems whose components randomly fail. Recently, in [
7] is introduced a new lifetime distribution by considering a series system such that the components are log-normal and Weibull distributed. This lifetime model proposes a new flexible lifetime distribution that can be used to model lifetime data in a wider class of reliability problems. The parameters are estimated by considering maximum likelihood.
One of the most interesting distribution class, used to model multi-state reliability systems, is the phase-type distribution (PH). This class of distributions were introduced and described in detail by [
8]. The good properties of these distributions enable us to model complex systems in an algorithmic and computational form. Besides, this class of distributions is dense in the set of non-negative probability distributions [
9]. Thus, any non-negative distribution can be approximated as much as desired through a PH. In relation to the parameter estimation of PH probability distributions by maximum likelihood, a recurring method called EM algorithm is often employed [
10]. Recently, [
11,
12] showed that PH distributions explain the behaviour of Resistive Random Access Memories (RRAM) better than Weibull distributions, as had been considered up to now.
One of the main problems when PH distributions are considered to be fitted to a data set is the number of parameters. The number of phases of the PH distribution increases as the data set variability rises, and then, the number of parameters to be estimated could be very high [
13]. Another consideration is when the empirical distribution has multiple modes or the tail is heavy. Again, the number of phases is high in these situations. As models for heavy tailed distributions, a new class of infinite-dimensional PH distributions with finitely many parameters was proposed in [
14], meanwhile [
15] provided a new solution by introducing time-inhomogeneity in the Markov jump process underlying the construction of the PH distribution. The authors transform PH distributions into heavy-tailed ones, but rather than transforming the PH distribution directly, they transform the time scales of each state of the underlying Markov process. They introduce the matrix-Pareto distribution and they fit this one to a real dataset by considering an Erlang PH structure. A different option is to consider simpler structures that are more attractive both for fitting and simulation. In this line, multiple analyses have being developed by using specific structures for the PH distribution such as Coxian or Erlang distributions [
16,
17], whose number of parameters to be estimated is lower [
18,
19]. However, even using these specific structures, in which the dimension of estimation is smaller, there are situations where the adjustment is not all suitable.
Regarding these problems, as a kind of example/motivation, in [
13], forming voltage distributions for different RRAMs were fitted by using PH distributions. Several cases did not provide optimal results when a PH distribution was fitted. In particular, for the dataset related to the devices with dielectric HfAlO and subjected to a temperature of 80 °C (see Table 1 and Table 2 therein), the best PH-distribution was achieved with 128 phases. Even though the number of phases was really high, the fitting is not as satisfactory as one could expect. Another example can be seen in [
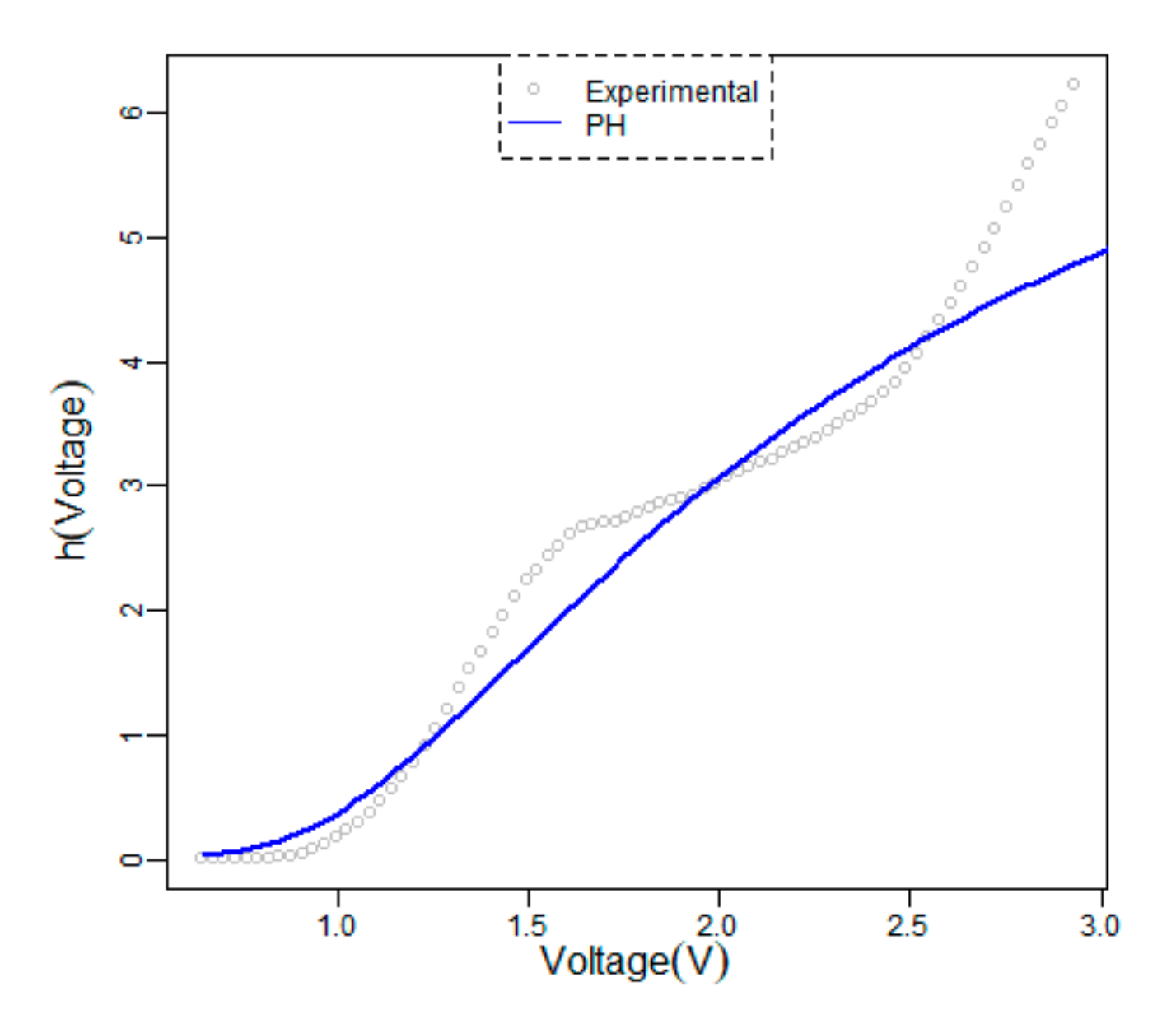
11] with the modelling of reset voltages (voltage in which the RRAMs’ conductive filament is broken). Here, the optimum number of states is only 15, but as it is displayed in
Figure 1, the empirical and theoretical hazard rates show a non-accurate fitting. Note that the empirical hazard rate has been obtained by means of a “
muhaz” package available in R-cran. By default, this function estimates the hazard function using the Epanechnikov kernel and the local method for bandwidth functions, in which the optimal one is worked out at a grid point by minimizing the local mean squared error [
20].
The motivation of this paper is to provide a new tool that improves the quality of the fitting for similar scenarios. For that purpose, a new distribution called one cut-point PH distribution is introduced. This distribution is a first approach to non-homogeneous PH distributions. The main measures associated to this class can be expressed in an algorithmic and computational form, as the original PH distributions. Additionally, this class will enable us to get adjustments with a lower number of parameters when the embedded distribution presents some of the aforementioned features. This new distribution is defined, and the main measures are worked out. In addition, the likelihood distribution is built to estimate the model parameters. The one cut-point PH distribution is applied to analyse the behaviour of a conductive filament (CF) in RRAMs with filamentary charge transport, according to several characteristics [
13,
21].
Resistive Random Access Memories are under scrutiny both at the academia and the industry [
21] due to their potential in applications related to non-volatile memories, neuromorphic computing and hardware cryptography [
21,
22]; they are used in entropy sources for the implementation of physical unclonable functions and random number generators [
22]. The operation of most of these devices is filamentary, as it consists of the formation and destruction of a conductive filament that changes the device resistance. The filament can be modified many times in a process known as resistive switching, which is characterized by the constant random creation (set process) and rupture (reset process) of the conductive filament. The CF, controlled by means of electric signals, allows both digital and analog operation in different applications with very good perspectives since these devices can be easily scaled to keep up with the continuous miniaturization race that it is taking place in the industry [
21].
The paper is organized as follows.
Section 2 motivates the new distribution from a real problem and the PH distributions class is remembered. The new distribution and features are given in
Section 3. Several real applications show the versatility of this new distribution in
Section 4. Conclusions are given in
Section 5.
2. Introducing the One Cut-Point PH Distribution
We assume a device with several internal transient unobservable states,
S = {1, 2, ...,
n}. The performance of the device goes through these stages up to reach an event, state
n + 1. If the internal behaviour of the device is Markovian, then the time up to this event is phase-type distributed [
8].
The generator of the Markov process that governs the internal behaviour is a
Q-matrix with order
n + 1 where the last state is an absorbing state. This generator, with order
n + 1 ×
n + 1, can be expressed by blocks as follows:
where the matrix
T, order
n ×
n, contains the transition intensities between transient states and the column vector
T0, order
n × 1, the transition intensities from a transient state up to the absorbing event. Matrix
T is a non-singular matrix given by the embedded Markov structure. Throughout the paper, given a matrix
A, the column vector
A0 is given by
A0 = −
Ae, being
e a column vector of ones with appropriate order. If
A is a non-singular matrix then
and
.
Then, it is well-known that the time up to the absorption, X, when the initial distribution for the transient states is the row vector α, is PH distributed with representation . The reliability function of a PH distribution with representation is given by . It can be interpreted as follows. The element (i, j) of the matrix is the probability of being in state j at time x given that initially it is in state i. Therefore, is the probability of being in a transient state at time x.
As it has been mentioned in the introduction, one of the main problems when PH distributions are considered is the order and the internal structure of the matrix
T and therefore, the number of parameters to estimate. The problem described in the introduction from [
11,
13] can be provoked because the internal behaviour of the states is not the same over time, that is, the internal behaviour is non-homogeneous. From
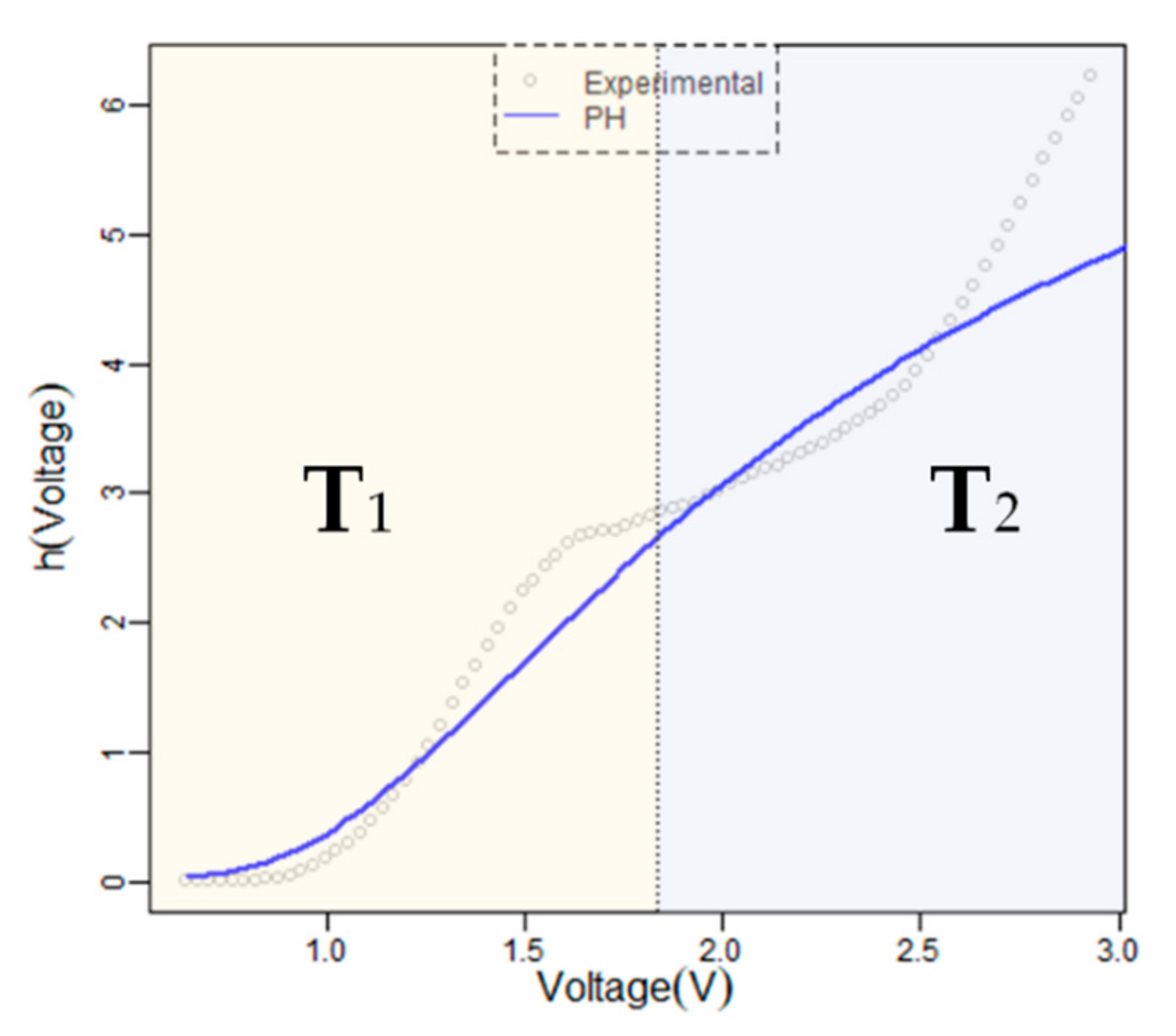
Figure 1, it can be observed that the data set has different performances. A first approach is to consider one cut-point by partitioning the real line in two semi-lines. We can consider that the internal behaviour of the device passes across
n states, but the intensities are not the same in each interval. If the cut-point is denoted by
a, which can be estimated, the transition intensities are given, for period one and two, from matrices
T1 and
T2, respectively.
Figure 2 shows the situation for the motivation example from the hazard rate function.
The probability distribution for this new approach can be built as follows. The reliability function will depend on whether the survival time occurs earlier or later than a.
The variables X1 and X2 are defined as the event time when occurs before than a and the remaining time up to the event from a when it occurs after a, respectively. Therefore, X = X1 for 0 ≤ x ≤ a and X = a + X2 for x > a.
If x ≤ a, the reliability function for X is the same than the reliability function for X1, and it follows a phase type distribution with representation in this period of time. Then,
The variable X2, remaining time up to the event from a, follows a phase type distribution with representation . Then, if the event occurs after a, that is, x > a,
This last scenario can be interpreted as follows: at time a the event does not occur and the initial distribution for this second period of time is , then the probability of failure at a certain time after a is governed by matrix T2.
3. The One Cut-Point PH Distribution. Definition and Estimation
3.1. Definition
The one cut-point distribution is defined as follows.
Definition. A variable X, defined in the non-negative real semi line, is a one cut-point phase type distribution with representationif its probability density function is given by From the definition, the cumulative distribution function is worked out,
and therefore the reliability function is
as it was shown in previous section.
Two well-known interesting measures in the reliability field are the hazard rate and the cumulative hazard rate functions whose expressions are given, respectively, as
and
It is interesting to highlight that the probability density function and the hazard rate function are not continuous at point a; however, the reliability function and the cumulative hazard rate function do verify this property.
The characteristic function provides an alternative way for describing a random variable. It is defined as
. From the one cut-point density function, the characteristic function has the following matrix-algorithmic expression for
t in a neighbourhood of zero,
Following a similar reasoning, the moment-generating function is worked out
Since
, the first two moments have been worked out. Thus, for the mean we have
Given that
and therefore
and
, then
The matrix expressions for the moments are
3.2. Parameter Estimation
Parameter estimation of one cut-point PH distributions refers to finding a representation of order n from a sample size equal to m, {x1, x2, ..., xm}. The sample points is a realization of {X1, X2, ..., Xm}, independent and identically distributed random variables. We will estimate the parameters by considering the well-known maximum likelihood method.
Each observation of the sample, xi, contributes to the likelihood function with the probability density function, that is,
Then, the likelihood function is given by
where
I{} is the indicator function.
Therefore, the log-likelihood function is given by
The likelihood function and the results shown in this section have been computationally implemented in R-cran.
4. Application
The conductive filament creation and rupture (i.e., the resistive switching process) in Resistive Random Access Memories according to several characteristics is analysed by applying one cut-point PH distributions. The CF creation is an inherent stochastic process since different ions in the dielectric are moved by the electric field and influenced by temperature in a random manner [
23]. The ions form clusters that finally configure a percolation path that constitutes the CF. Since the generation of the ions and their movement is random, the whole CF evolution is therefore inherently random. This leads to the known cycle-to-cycle (C2C) variability [
12], i.e., a variability that reflects that the device resistance changes each time the CF is formed, in each cycle. In addition to the C2C variability, RRAM device-to-device variability due to differences between devices in the fabrication process of a chip can also be seen [
12]. The former, the C2C variability, is the subject of our study here.
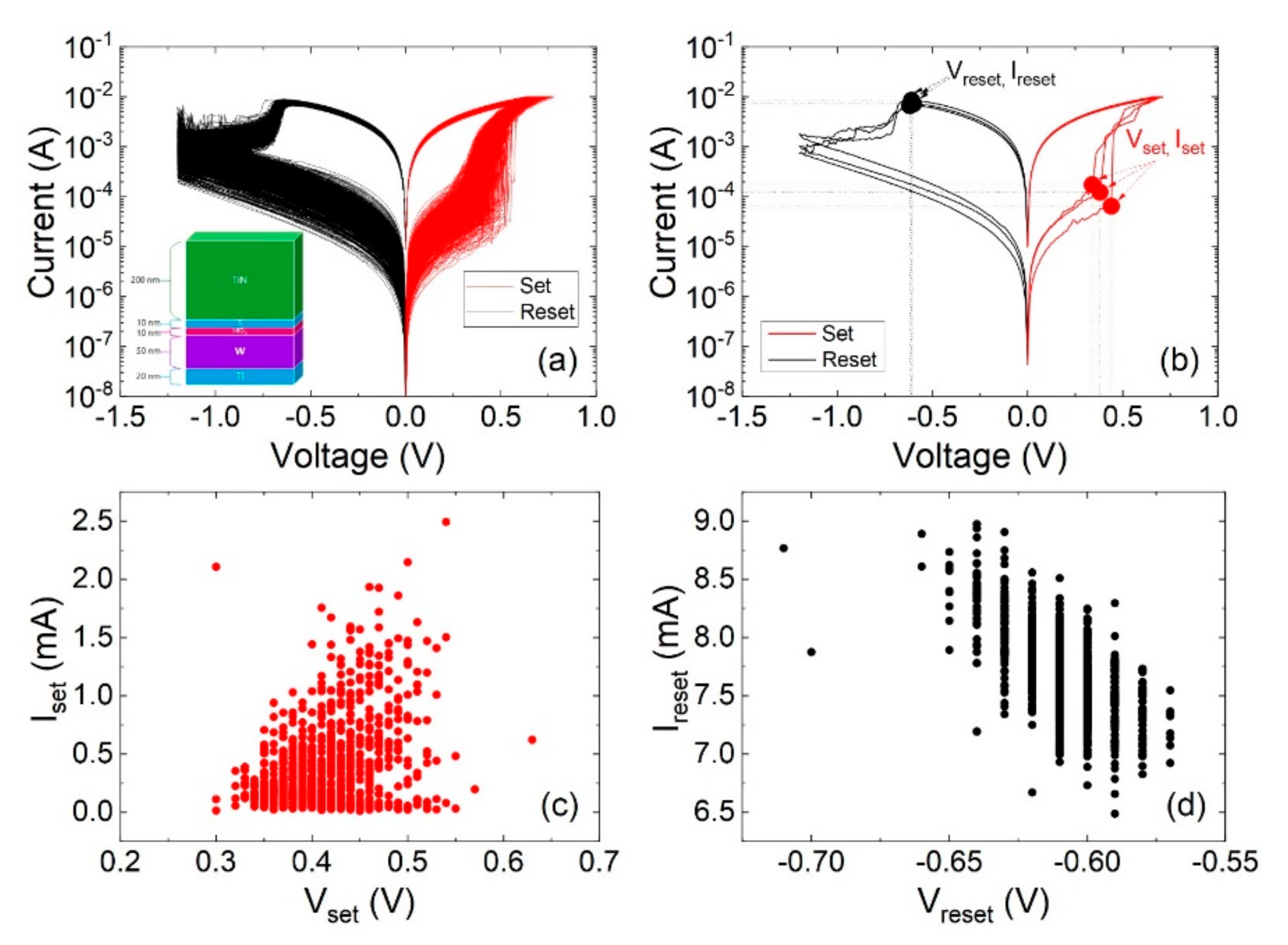
We consider devices of a 10nm thick HfO
2 dielectric in between a Ti and W electrodes [
24], see the inset in
Figure 3a. The different current–voltage curves (
Figure 3a) have been measured using low slope voltages ramps with time. The set and reset voltages and currents (
Figure 3b) have been determined for a long series of 1000 resistive switching cycles.
Figure 3c,d are typical plots that show C2C variability.
Some of the resistive switching parameters (RSP) that can be employed to characterize a RRAM technology are the set and reset voltages and currents, see
Figure 3b. These RSP identify the voltage and current levels that should be used in circuits, in which RRAMs are employed as components. In this respect, the correct modelling of the behaviour would allow circuit designers to determine the operation limits of their circuits, that is why this issue is essential. In addition to the direct analysis of the values obtained, as it is presented by most of the experimental works, the advanced statistical modelling of the RSP data permits a better variability study from the circuit simulation viewpoint. Different complex approaches have been introduced to model these data using a unimodal statistical distribution [
11,
25]. While it is true that these complex models get better results than the classical methodologies applied in the electronics industry until now, they might not be accurate enough in certain occasions. On account of this weakness, we apply the new methodology to describe the experimental data. In this respect, as it will be shown below, a better representation of the distribution tails is achieved and the number of parameters to be estimated is reduced as well. This analysis has been carried out with R-cran by using the implementation developed for this objective. Regarding the process of parameters optimization, the “
optim” function available in R-cran has been used through L-BFGS-B method [
26]. This method uses a limited-memory modification of the quasi-Newton method and enables us to establish a lower and/or upper bound for the parameters.
4.1. The Reset Voltage
The reset voltage describes the voltage level at which the conductive filament is broken and the resistance of the devices increases greatly. To analyse the reset voltage, a data set with 1000 experimental observations has been considered. The empirical voltage mean and the standard deviation are 0.6091 and 0.0158, respectively. Firstly, a PHD has been fitted to the data set by considering a general internal structure. After the analysis, fixing the number of phases, all the results converge to the same internal structure, which corresponds to an Erlang distribution with representation PH. This structure can be expressed as follows:
For this dataset, even if the number of states is too high, the goodness of fit was analysed from the Anderson–Darling (A-D) test, obtaining a p-value less than 0.0001 and rejecting the goodness of the fit. Hereinafter, and for computational reasons, a PH with the structure described above with 200 phases is considered.
A one cut-point defined in
Section 3 has been considered to estimate the reset voltages. To simplify the model, a one cut-point PH distribution with representation
, where
T1 and
T2 have Erlang internal structure, has been assumed. In total, four parameters were estimated, the cut-point is
a = 0.595 (confidence interval [0.571; 0.619] at 95%), the number of phases is reduced considerably (only 14 phases are needed), and the parameters of
T1 and
T2 are,
with
. Vector
α continues being
.
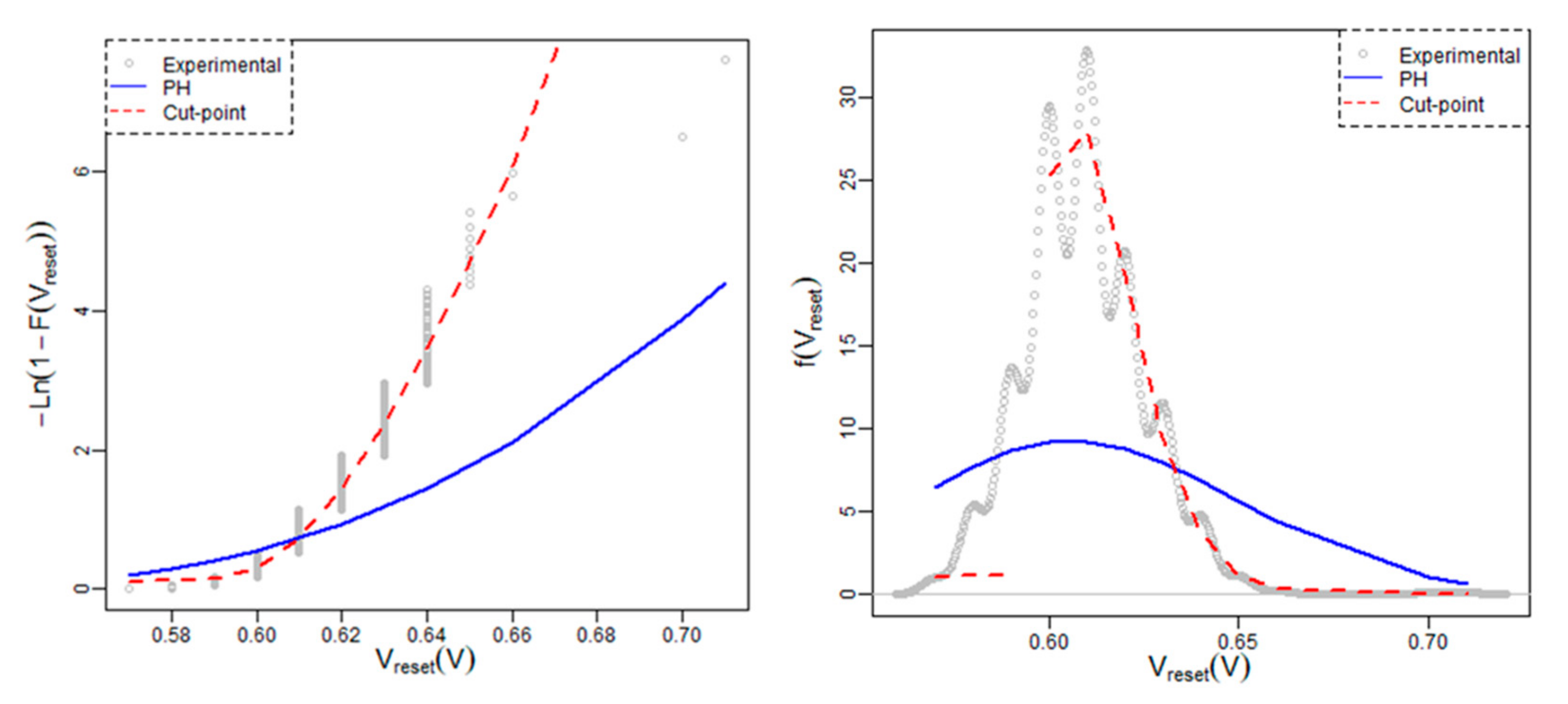
Figure 4 shows the cumulative hazard rate and the probability density function for the empirical, PH and cut-point PH cases. Note that the empirical density has been worked out by means of “
density” function available in R-cran. By default, this function disperses the mass of the empirical distribution over a regular grid of points and makes use of the Fourier transform in order to combine this approximation with a discretized version of the kernel, so that to use linear approximation to evaluate the density at the specified points [
27,
28]. The cut-point approach not only reduces the parameters to be estimated, but also improves the quality of the fitting.
Table 1 shows the main empirical characteristics and a comparison between models.
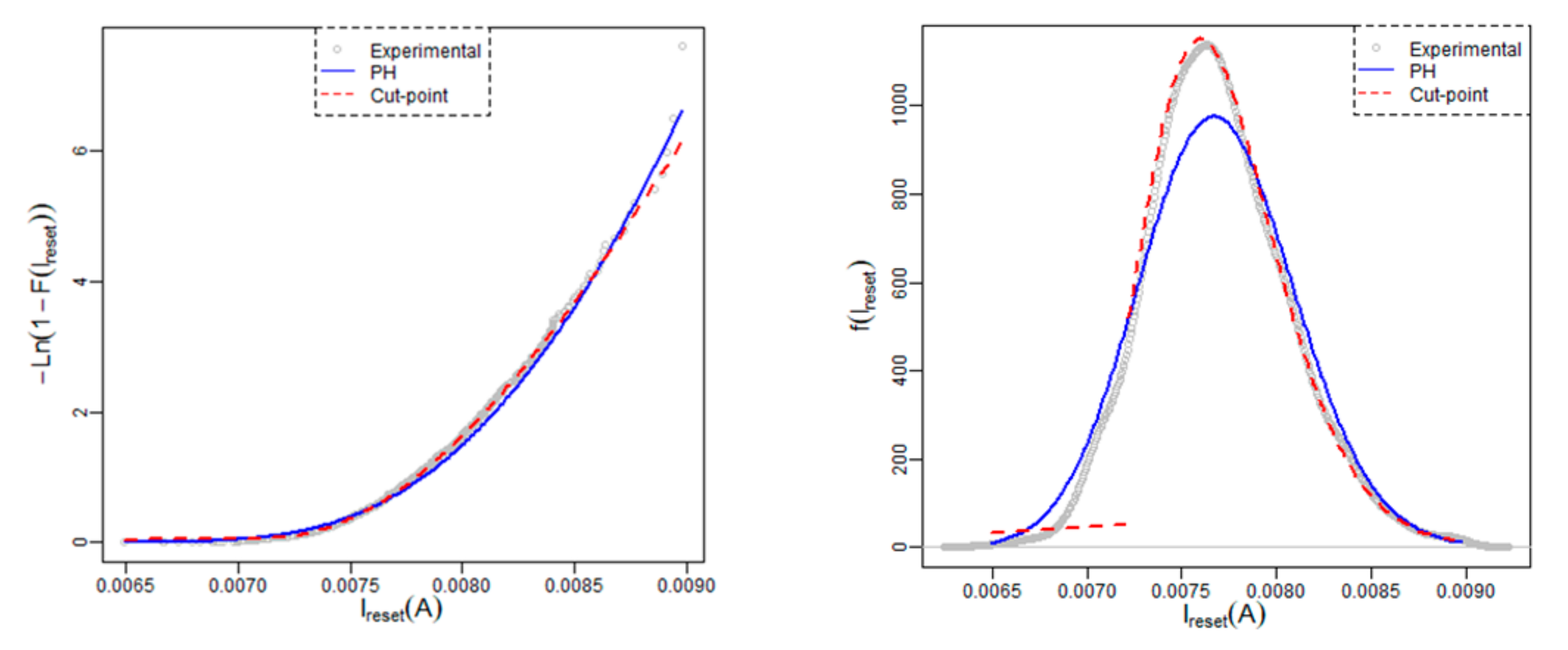
4.2. Reset Current
The reset current represents the current at the reset point and it is statistically linked to the CF size at the point where it is ruptured. There is a connection between this parameter and the reset voltage; however, different factors can statistically decouple them, as can be clearly seen in
Figure 3d. For this parameter, a multimodal distribution analysis is expected to work also better.
A cut-point PH distribution has been fitted for the reset current and it has been compared with a PH adjustment. This analysis has been carried out from the sample we are employing, whose size is equal to 1000. Analogously to the reset voltage, the internal structure for the PH and one cut-point PH distribution is Erlang. In this case, the estimated cut-point is equal to
a = 0.0072 with confidence interval [0.0068; 0.0076] at 95%.
Table 2 shows a summary of the models, adjustment and estimates.
As it can be seen in
Table 2, the number of phases decreases considerably and the Anderson–Darling test rejects the PH model but not the one cut-point model.
Figure 5 shows the fitting graphically.
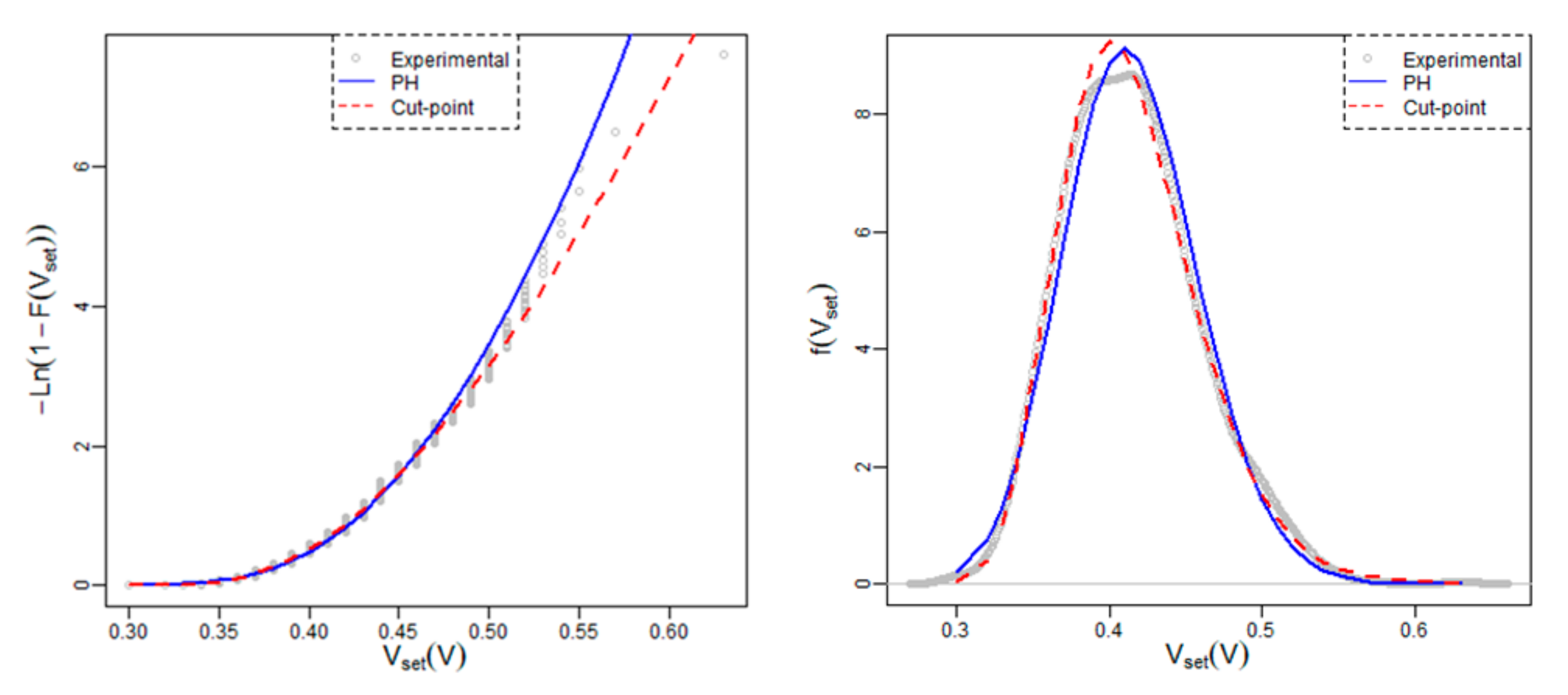
4.3. The Set Voltages
The set voltage marks the conduction point in which the percolation path that constitutes the conductive filament is fully formed. The randomness connected to the physical mechanisms involved in the CF formation is reflected in the experimental data variability. We also present here a multimodal approach to tackle the set voltage analysis.
A similar study has been performed for the voltage up to the set voltage. A sample with 1000 elements is taken into account corresponding to the same resistive switching series. The estimated cut-point is
a = 0.315 with confidence interval [0.296; 0.334] at 95%. The empirical results and the data for the PH and the one cut-point PH fit is shown in
Table 3.
The fitting is shown in
Figure 6. Here, we can see how the cut-point fit rectifies the lack of precision in distribution tail.
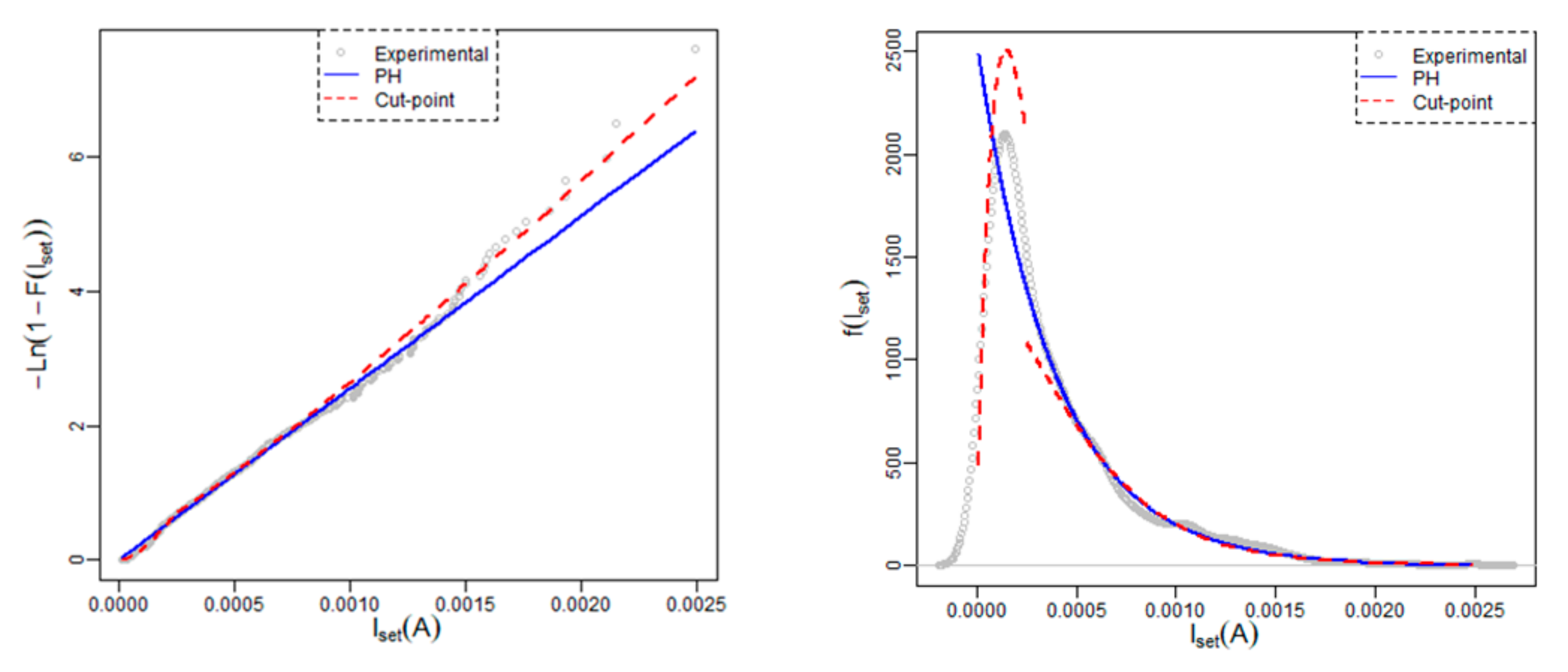
4.4. The Set Current
The set current is the current level at the set voltage in the current-voltage curve. The current level is much lower than the reset current since the device starts the set process in a High Resistance State, so, the first point with the percolation path formed represents, in general a low current state. Again, the resistive switching characteristic randomness can be observed. As highlighted in the reset current case, there are factors that affect the correlation between of the set voltage and current data, as can be seen in
Figure 3c.
Table 4 shows the obtained results after performing an exhaustive analysis on the behaviour of the set current by means of the new methodology presented in the current manuscript. The estimated cut point is
a = 0.00025 with confidence interval [0.00019; 0.00031] at 95%.
The new model of one cut-point improves the fit to the data set, without rejecting the case of the new model. A graphical analysis is shown in
Figure 7.
5. Conclusions
The good properties of phase-type distributions make this class of distributions a suitable candidate to model experimental data in the field of reliability. Among other features, PH enables the interpretation of the results in a simple way thanks to its matrix-algebraic form and moreover, they generalize a large number of known distributions such as Exponential, Erlang or Coxian distribution. In addition, a reason why this class is usually considered in many applications is due to the fact that it is dense in the set of probability distributions defined on any half-line of real number. This assertion implies that any non-negative probability distributions can be approximated as much as desired by a PH. The PH inherent problem is that their fittings show certain weaknesses in several aspects.
Sometimes the adjustment is improvable in the tails of the distribution (especially in heavy distributions) and in other occasions, even for an appropriate fitting, the number of parameters to estimate is really high. In this respect, a new class of distributions, called one cut-point PH distributions, is introduced in the current work in order to solve the problems aforementioned. This distribution, which is a first approach to non-homogeneous PH distributions, inherits the most important characteristics of the original PH.
The motivation of this paper is to provide a new tool to model experimental data measured on Resistive Random Access Memories, one of the most promising devices in the current semiconductor industry landscape. The results presented show that the fitting considering a cut-point PH distribution significantly improves the obtained results in comparison to the classic PH.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}