
Spherical Distributions Used in Evolutionary Algorithms

{kind=link}
Abstract
:1. Introduction
| Algorithm 1 An elitist, one-individual, mutation+selection EA. |
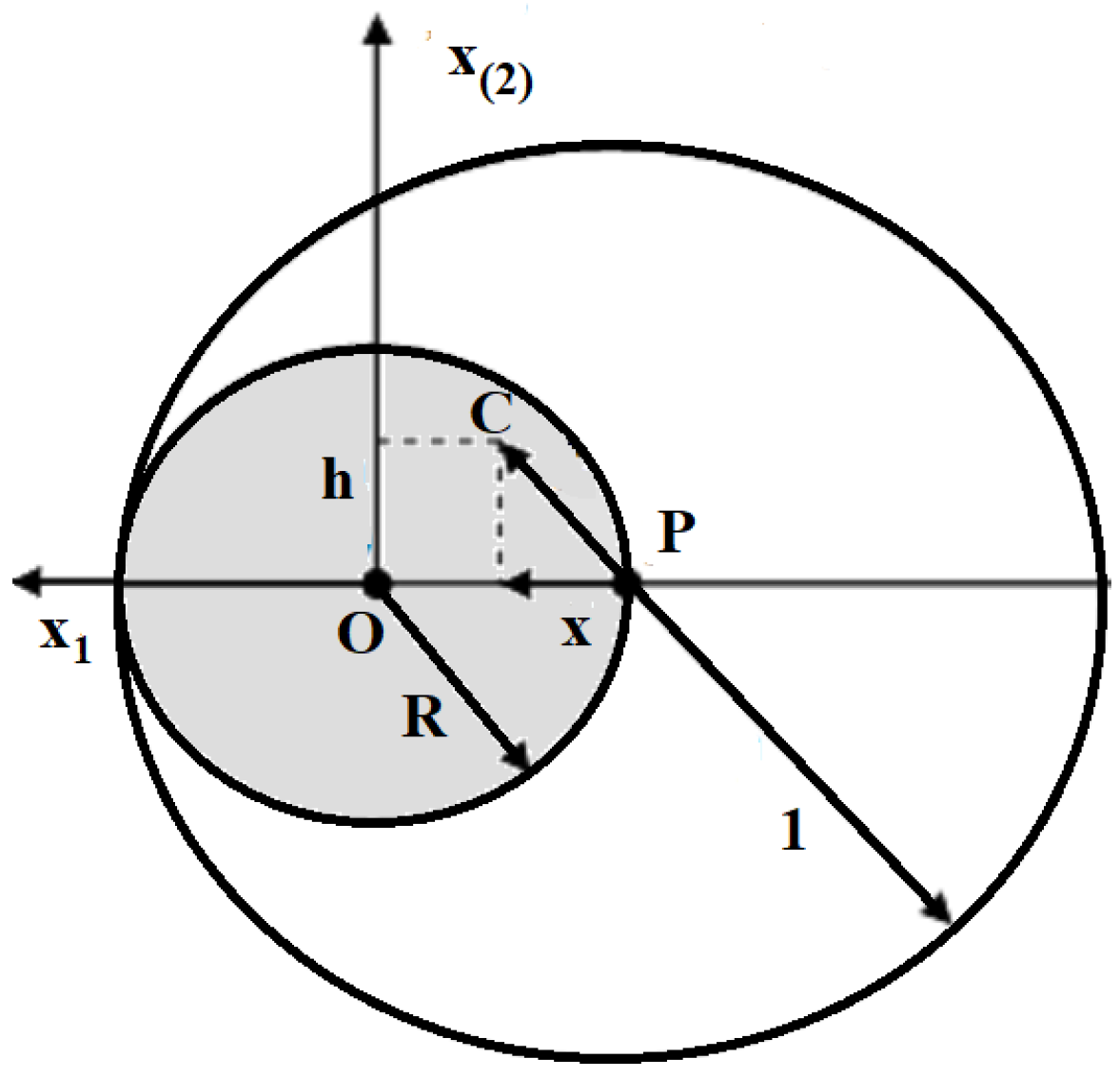
Set and the initial point of the algorithm, Repeat Mutation: generate a new point according to a multi-variate distribution Selection:if then else Until , for some fixed |
- An n-dimensional random variable is said to have spherically symmetric distribution(or simply spherical distribution) iffor some one-dimensional random variable (radius) , and the uniform distribution on the unit sphere . Moreover, and are independent, and also
- If the spherical distribution has pdf g, then g satisfies , and there is a special connection between g and f, the pdf of , namely,
- the uniform distribution on the unit sphere, with support , denoted ;
- the uniform distribution in (inside) the unit sphere, with support , denoted simply UNIFORM in this paper; and
- the standard normal distribution, denoted or simply NORMAL.
2. Materials and Methods. Spherical Distributions
- - is obviously the Dirac distribution in 1:
- UNIFORM- is distributed , with pdf ([15], p. 75):
2.1. Uniform in the Sphere
- Let be UNIFORM, where is m-dimensional, . The conditional distribution of given is UNIFORM in the m dimensional sphere with radius .
- If and is a point in with , the conditional distribution of given is
2.2. Normal
- The pdf of the first component, , is
- The joint pdf of the last components, , is
3. Results
3.1. Uniform Mutation
3.2. Normal Mutation
- The success probability is
- The expected progress is
3.3. Comparison
- For any real set of parameters and any real number x, definewhere is the Pochhammer symbol, with
- If and , we write , if
- If , the following inequality holds:
4. Discussion
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Pearson, K. The problem of the random walk. Nature 1905, 72, 294. [Google Scholar] [CrossRef]
- Kluyver, J.C. A local probability problem. Nederl. Acad. Wetensch. Proc. 1905, 8, 341–350. [Google Scholar]
- Watson, G.N. A Treatise on the Theory of Bessel Functions; University Press: Cambridge, UK, 1995. [Google Scholar]
- Zhou, Y. On Borwein’s conjectures for planar uniform random walks. J. Aust. Math. Soc. 2019, 107, 392–411. [Google Scholar] [CrossRef] [Green Version]
- Dunson, D.B.; Johndrow, J.E. The Hastings algorithm at fifty. Biometrika 2020, 107, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Beyer, H.-G. The Theory of Evolution Strategies; Springer: Heidelberg, Germany, 2001. [Google Scholar]
- Rudolph, G. Convergence Properties of Evolutionary Algorithms; Kovać: Hamburg, Germany, 1997. [Google Scholar]
- Agapie, A.; Wright, A.H. Theoretical analysis of steady state genetic algorithms. Appl. Math. 2014, 59, 509–525. [Google Scholar] [CrossRef] [Green Version]
- Agapie, A.; Agapie, M.; Rudolph, G.; Zbaganu, G. Convergence of evolutionary algorithms on the n-dimensional continuous space. IEEE Trans. Cybern. 2013, 43, 1462–1472. [Google Scholar] [CrossRef] [PubMed]
- Agapie, A.; Agapie, M.; Zbaganu, G. Evolutionary Algorithms for Continuous Space Optimization. Int. J. Syst. Sci. 2013, 44, 502–512. [Google Scholar] [CrossRef]
- Agapie, A. Estimation of Distribution Algorithms on Non-Separable Problems. Int. J. Comp. Math. 2010, 87, 491–508. [Google Scholar] [CrossRef]
- Agapie, A. Theoretical analysis of mutation-adaptive evolutionary algorithms. Evol. Comp. 2001, 9, 127–146. [Google Scholar] [CrossRef]
- Auger, A. Convergence results for the (1,λ)-SA-ES using the theory of ϕ-irreducible Markov chains. Theor. Comput. Sci. 2005, 334, 35–69. [Google Scholar] [CrossRef] [Green Version]
- Li, S. Concise Formulas for the Area and Volume of a Hyperspherical Cap. Asian J. Math. Stat. 2011, 4, 66–70. [Google Scholar] [CrossRef] [Green Version]
- Fang, K.-T.; Kotz, S.; Ng, K.-W. Symmetric Multivariate and Related Distributions; Chapman and Hall: London, UK, 1990. [Google Scholar]
- Mardia, K.V.; Jupp, P.E. Directional Statistics; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Watson, G.S. Statistics on Spheres; University of Arkansas Lecture Notes in the Mathematical Sciences; Wiley: New York, NY, USA, 1983. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Fang, K.-T.; Yang, Z.; Kotz, S.; Ng, K.-W. Generation of multivariate distributions by vertical density representation. Statistics 2001, 35, 281–293. [Google Scholar] [CrossRef]
- Harman, R.; Lacko, V. On decompositional algorithms for uniform sampling from n-spheres and n-balls. J. Multivar. Anal. 2010, 101, 2297–2304. [Google Scholar] [CrossRef] [Green Version]
- Rechenberg, I. Evolutionsstrategie: Optimierung Technischer Systeme Nach Prinzipiender Biologischen Evolution; Frommann-Holzboog Verlag: Stuttgart, Germany, 1973. [Google Scholar]
- Schwefel, H.-P. Evolution and Optimum Seeking; Wiley: New York, NY, USA, 1995. [Google Scholar]
- Schumer, M.A.; Steiglitz, K. Adaptive Step Size Random Search. IEEE Trans. Aut. Control 1968, 13, 270–276. [Google Scholar] [CrossRef] [Green Version]
- Rudolph, G. Local convergence rates of simple evolutionary algorithms with Cauchy mutations. IEEE Trans. Evol. Comp. 1997, 1, 249–258. [Google Scholar] [CrossRef]
- Jägersküpper, J. Analysis of a simple evolutionary algorithm for minimisation in Euclidean spaces. In International Colloquium on Automata, Languages, and Programming; Lecture Notes in Computer Science; Springer: New York, NY, USA, 2003; Volume 2719, pp. 1068–1079. [Google Scholar]
- Jägersküpper, J.; Witt, C. Rigorous runtime analysis of a (μ+1) ES for the sphere function. In Proceedings of the 7th Annual Conference on Genetic and Evolutionary Computation, Washington, DC, USA, 25–29 June 2005; pp. 849–856. [Google Scholar]
- Agapie, A.; Solomon, O.; Giuclea, M. Theory of (1+1) ES on the RIDGE. IEEE Trans. Evol. Comp. 2021, 2021. [Google Scholar] [CrossRef]
- Agapie, A.; Solomon, O.; Bădin, L. Theory of (1+1) ES on SPHERE revisited. 2021. under review. [Google Scholar]
- Beyer, H.-G. On the performance of (1, λ)-evolution strategies for the ridge function class. IEEE Trans. Evol. Comput. 2001, 5, 218–235. [Google Scholar] [CrossRef]
- Cambanis, S.; Huang, S.; Simons, G. On the Theory of Elliptically Contoured Distributions. J. Mult. Anal. 1981, 11, 368–385. [Google Scholar] [CrossRef] [Green Version]
- Huntington, E.V. Frequency Distribution of Product and Quotient. Ann. Math. Statist. 1939, 10, 195–198. [Google Scholar] [CrossRef]
- Huang, H.; Su, J.; Zhang, Y.; Hao, Z. An Experimental Method to Estimate Running Time of Evolutionary Algorithms for Continuous Optimization. IEEE Trans. Evol. Comput. 2020, 24, 275–289. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. (Eds.) Handbook of Mathematical Functions, 9th ed.; Dover: New York, NY, USA, 1972. [Google Scholar]
- Neuman, E. Inequalities and Bounds for the Incomplete Gamma Function. Results Math. 2013, 63, 1209–1214. [Google Scholar] [CrossRef]
- Volkmer, H.; Wood, J.J. A note on the asymptotic expansion of generalized hypergeometric functions. Anal. Appl. 2014, 12, 107–115. [Google Scholar] [CrossRef]
- Slater, L.J. Generalized Hypergeometric Functions; University Press: Cambridge, UK, 1966. [Google Scholar]
- Karp, D.B. Representations and Inequalities for Generalized Hypergeometric Functions. J. Math. Sci. 2015, 207, 885–897. [Google Scholar] [CrossRef] [Green Version]
- Luke, Y.L. Inequalities for generalized hypergeometric functions. J. Approx. Theory 1972, 5, 41–65. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comp. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Kadirkamanathan, V.; Selvarajah, K.; Fleming, P.J. Stability analysis of the particle dynamics in particle swarm optimizer. IEEE Trans. Evol. Comp. 2006, 10, 245–255. [Google Scholar] [CrossRef]
- Dasgupta, S.; Das, S.; Biswas, A.; Abraham, A. On stability and convergence of the population-dynamics in differential evolution. AI Commun. 2009, 22, 1–20. [Google Scholar] [CrossRef] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agapie, A. Spherical Distributions Used in Evolutionary Algorithms. Mathematics 2021, 9, 3098. https://doi.org/10.3390/math9233098
Agapie A. Spherical Distributions Used in Evolutionary Algorithms. Mathematics. 2021; 9(23):3098. https://doi.org/10.3390/math9233098
Chicago/Turabian StyleAgapie, Alexandru. 2021. "Spherical Distributions Used in Evolutionary Algorithms" Mathematics 9, no. 23: 3098. https://doi.org/10.3390/math9233098
APA StyleAgapie, A. (2021). Spherical Distributions Used in Evolutionary Algorithms. Mathematics, 9(23), 3098. https://doi.org/10.3390/math9233098