1. Introduction
Principal component analysis (PCA) is a standard method for dimensionality reduction that analyzes a set of high dimensional data. The goal of PCA is to extract the important information from the data by computing a set of orthogonal vectors which span lower dimensional subspaces called principal components [
1]. The study of PCA can be traced back to Pearson [
2], and its modern instantiation was formalized by Hotelling [
3]. Nowadays, PCA has been widely applied on, for instance, computer vision [
4,
5], data visualization [
6], and data compression [
7].
Recently, R. Yoshida, L. Zhang and X. Zhang proposed the tropical principal component analysis (tropical PCA) [
8], which is of great use in the analysis of phylogenetic trees in Phylogenetics (also see [
9]). Phylogenetics is a subject that is very powerful for explaining genome evolution, processes of speciation and relationships among species. It offers a great challenge of analysing data sets that consist of phylogenetic trees.
Analysing data sets of phylogenetic trees with a fixed number of leaves is difficult because the space of phylogenetic trees is high dimensional and not Euclidean; it is a union of lower dimensional polyhedra cones in
, where
n is the number of leaves [
9]. Many multivariate statistical procedures have been applied to such data sets [
10,
11,
12,
13,
14,
15]. Researchers have also undertaken a lot of work to apply PCA on data sets that consist of phylogenetic trees. For instance, Nye showed an algorithm [
16] to compute the first order principal component over the space of phylogenetic trees. Nye [
16] used a two-point convex hull under the CAT(0)-metric as the first order principal component over the Billera-Holmes-Vogtman (BHV) tree space introduced in [
17]. However, Lin et al. [
18] showed that the three-point convex hull in the BHV tree space can have arbitrarily high dimension, which means that the idea in [
16] cannot be generalized to higher order principal components (e.g., see [
9]). In addition, Nye et al. [
19] used the locus of the weighted Fréchet mean when the weights vary over the
k-simplex as the
k-th principal component in the BHV tree space, and this approach performed well in simulation studies.
On the other hand, the tropical metric in tree spaces is well-studied [
20] (Chapter 5) and well-behaved [
18]. In 2019, Yoshida et al. [
8] defined the tropical PCA under the tropical metric in two ways: the Stiefel tropical linear space of fixed dimension, and the tropical polytope with a fixed number of vertices. Page et al. [
9] used tropical polytopes for tropical PCA to visualize data sets of phylogenetic trees, and used Markov Chain Monte Carlo (MCMC) approach to optimally estimate the tropical PCA. Their experimental results [
9] showed that the MCMC method of computing tropical PCA performed well on both simulated data sets and empirical data sets.
This paper is motivated by the difference between the classical PCA (in Euclidean spaces) and the tropical PCA as follows. In the classical PCA, by the definition of Euclidean metric, the projection of the mean point of a data set
X on the principle component is the mean point of the projection of
X. Based on this fact and the definition of Euclidean metric, the mean squared error (MSE) between
X and the projection of
X reaches the minimum, and the projected variance reaches the maximum simultaneously (e.g., see [
21] (Page 188 to 189)). In fact, the PCA in the BHV tree space proposed by Nye [
16] also makes the MSE between a data set
X and the projection of
X reaches the minimum, and the projected variance reaches the maximum simultaneously. However, in tropical PCA [
8,
9], it is not guaranteed that the variance of the projection of
X reaches the maximum, while the MSE between
X and the projection of
X reaches the minimum. The fundamental reason for this is that the tropical metric is different from Euclidean metric. Also, in the tropical PCA defined by tropical polytopes, the projection of a tropical mean point (in this paper we call it a Fermat-Weber point) of a data set
X is not necessarily a Fermat-Weber point of the projection of
X (see Example 4). More specifically, it is known that, for a data set
X in the Euclidean space, the mean point of
X is unique. However, for a data set
X in the tropical projective torus (denoted by
), the Fermat-Weber point of
X is not necessarily unique [
22] (Proposition 20). For a data set
and a tropical convex hull
, the tropical projection [
23] (Formula 3.3) of the set of Fermat-Weber points of
X on
are not exactly equal to the set of Fermat-Weber points of the projection of
X on
. In addition, it is also known that, in
, if a set is the union of
X and a Fermat-Weber point of
X, then the union has exactly one Fermat-Weber point [
24] (Lemma 8). So, if a set is the union of
X and a Fermat-Weber point of
X, can the projection of the Fermat-Weber point of the union be a Fermat-Weber point of the projection of the union? By experiments we know that this is still not guaranteed, and it depends on the choice of the tropical convex hull
(see Example 5). Therefore, it is natural to ask the following question.
Main Question. For a given data set X in the tropical projective torus, how to find a tropical polytope , such that the projection of a Fermat-Weber point of X on is a Fermat-Weber point of the projection of X on ?
In this paper, we study the main question by focusing on tropical triangles (three-point tropical polytopes). Our goal is to develop an algorithm that can answer the main question with a high success rate. We develop one algorithm (Algorithm 1) and its improved version (Algorithm 2), such that for a given data set
, these algorithms output a tropical triangle
, on which the projection of a Fermat-Weber point of
X is a Fermat-Weber point of the projection of
X. By sufficient experiments with random data sets, we show that Algorithms 1 and 2 can both succeed with a much higher probability than choosing a tropical triangle
randomly. We also show that the success rate of these two algorithms is stable while data sets are changing randomly. Algorithm 2 can output the result much faster than Algorithm 1 does averagely, because in most cases, Algorithm 2 correctly terminates with less steps than Algorithm 1 does (See
Section 5). Our work can be viewed as a first step to an ambitious goal. We remark that, once the main question is completely solved, we can then ask how to characterize all nice tropical polytopes. Here, by a “nice tropical polytope”, we mean a tropical polytope, on which the projection of a Fermat-Weber point of a given data set
X is a Fermat-Weber point of the projection of
X. Then, we can use the nice tropical polytopes as principal components in the tropical PCA and possibly in other data analysis such as linear discriminant analysis.
| Algorithm 1: First Version |
![Mathematics 09 03102 i001]() |
| Algorithm 2: Improved Version |
![Mathematics 09 03102 i002]() |
This paper is organized as follows. In
Section 2, we remind readers of the basic definitions in tropical geometry. In
Section 3, we prove Theorem 1 and Theorem 2 for the correctness of the algorithms developed in this paper. In
Section 4, we present Algorithms 1 and 2. We also explain how the algorithms work by two examples. In
Section 5, we apply the algorithms developed in
Section 4 on random data sets, and illustrate the experimental results.
2. Tropical Basics
In this section, we set up the notation throughout this paper, and prepare some basic tropical arithmetic and geometry (see more details in [
20]). We will redefine our motivation in a precise way after Definition 6.
Definition 1 (Tropical Arithmetic Operations). We denote by the max-plus tropical semi-ring
. We define the tropical addition
and thetropical multiplication
as Definition 2 (Tropical Vector Addition).
For any scalars , and for any vectorswe define the tropical vector addition
as: Example 1. Also we let . Then we have For any point
, we define
the equivalence class For instance, the vector
is equivalent to (0,0,0). In the rest of this paper, we consider the
tropical projective torusFor convenience, we simply denote by
its equivalence class instead of
, and we assume the first coordinate of every point in
is 0. Because for any
, it is equivalent to
Definition 3 (Tropical Distance). For any two pointswe define the tropical distance
as: Note that the tropical distance is a metric in
[
18] (Page 2030).
Example 2. Let . The tropical distance between , is Definition 4 (Tropical Convex Hull).
Given a finite subsetwe define the tropical convex hull
as the set of all tropical linear combinations of X: If then the tropical convex hull of X is called a tropical triangle.
Example 3. Consider a set , where The tropical convex hull is shown in Figure 1. Definition 5 (Tropical Fermat-Weber Points). We define the set of tropical Fermat-Weber points
of X as The Fermat-Weber point of X is denoted by .
Proposition 1 ([
18], Proposition 25).
Given , the set of tropical Fermat-Weber points of X in is a convex polytope in . It consists of all optimal solutions to the linear programming problem: Definition 6 (Tropical Projection). Also let . For any point , we define the projection of
on as:where for all [23] (Formula 3.3). Now we are prepared to repeat the main question in a precise way: for a given data set
X, how to find a tropical triangle
such that the following equality holds
The above question is motivated by the fact that the equality (
19) does not hold for any tropical triangle
(see Example 4). It is remarkable that the Fermat-Weber point might not be unique. The following Proposition 2 indicates that for some special data sets, the Fermat-Weber point is unique. But even for these special sets, the equality (
19) still does not hold for any tropical triangle (see Example 5). In the rest of this paper, we will develop algorithms for automatically searching tropical triangles such that the equality (
19) holds.
Proposition 2 ([
24], Lemma 8).
Let . Suppose is a Fermat-Weber point of X. Then has exactly one Fermat-Weber point, which is . Examples
Example 4. This example shows that, for a given data set and a given two-point tropical polytope , the projection of a Fermat-Weber point of X on is not necessarily a Fermat-Weber point of the projection of X on .
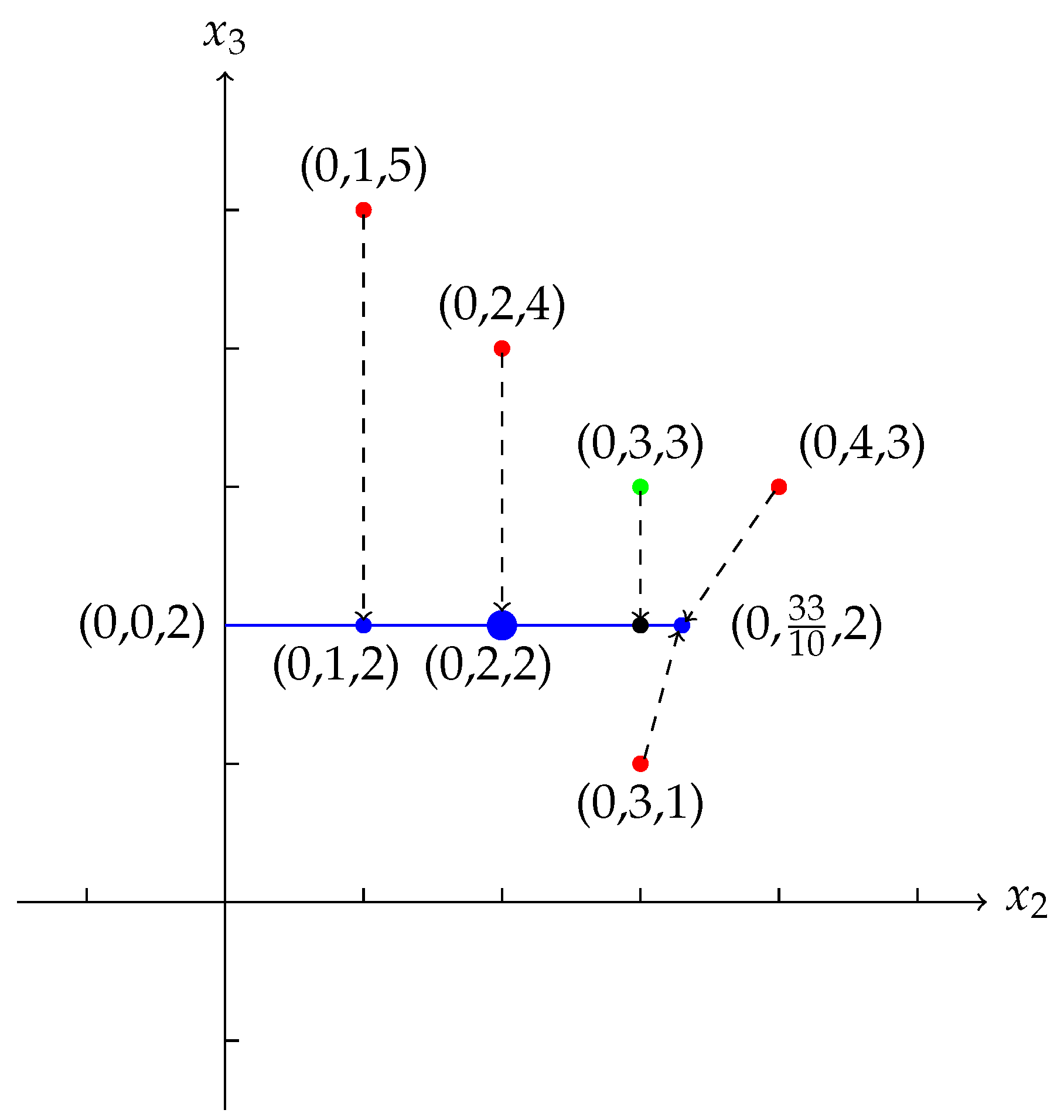
Suppose we have By solving the linear programming (16) in Proposition 1 (e.g., usinglpSolveinR), we obtain that, is a Fermat-Weber point of X. Let Then the projection of X on is We remark that, in P, is the projection of , is the projection of , and is the projection of both and on .
Note that is the unique Fermat-Weber point of P, while the projection of a Fermat-Weber point of X is . So we can see that the projection of a Fermat-Weber point of X on is not a Fermat-Weber point of the projection. In Figure 2, the red points are the points in X. The green point is a Fermat-Weber point of X. The blue line segment is the tropical convex hull generated by and . The blue points are the projection P of X. And the biggest blue one is the Fermat-Weber point of P. The black point is the projection of the green point. Example 5. This example shows that, in , if a set is the union of X and a Fermat-Weber point of X, then it is not guaranteed that the projection of the Fermat-Weber point of is a Fermat-Weber point of the projection of . Besides, whether the projection of the Fermat-Weber point of is a Fermat-Weber point of the projection of depends on the choice of the tropical convex hull .
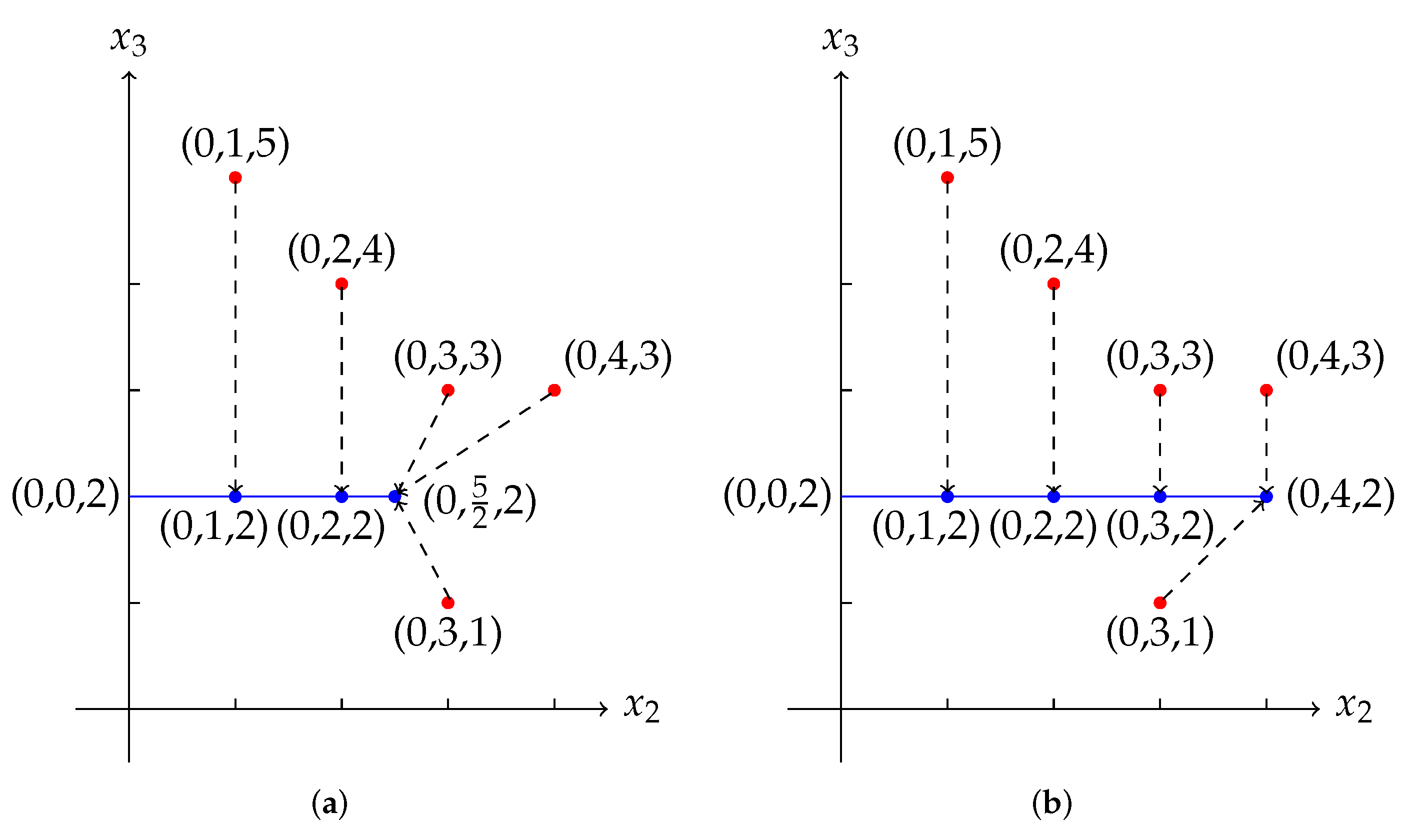
By solving the linear programming (16) in Proposition 1, we obtain that, is a Fermat-Weber point of X. Then Let and are the projection of on and respectively, where We remark that, in , is the projection of , is the projection of , and is the projection of , and on . And in , is the projection of , is the projection of , is the projection of , and is the projection of and on .
Note that is the unique Fermat-Weber point of , while the projection of the Fermat-Weber point of on is . So we can see that the projection of the Fermat-Weber point of on is not a Fermat-Weber point of the projection. On the other hand, the projection of the Fermat-Weber point on is , which is exactly a Fermat-Weber point of the projection. In the panel (a) of Figure 3, the points in are red. The projection points of are blue. The blue line segment is the tropical convex hull generated by and . The blue points are the projection of . Note that is the projection of the Fermat-Weber point of , and is the unique Fermat-Weber point of . In the panel (b) of Figure 3, the points in are red. The projection points of are blue. The blue line segment is the tropical convex hull generated by and . The blue points are the projection of . Note that is the projection of the Fermat-Weber point of , which is a Fermat-Weber point of . 3. Theorems
In this section, we introduce Theorems 1 and 2 for proving the correctness of the algorithms developed in the next section.
Lemma 1. Suppose we have a data set Let t be a number which is no more than For any two fixed integers , we define three points as follows. Let . Then, the projection of X on iswhere and are respectively located at the -th and -th coordinates of . Proof. Recall that we assume the first coordinate of every point in
is 0. For any
by Definition 6, we have that
in (
18) should be:
Then the conclusion follows from (
18). □
Suppose
X is the data set stated in Lemma 1. For
,
and
in Lemma 1, let
, we have the following remarks: the equalities (26)–(28) make sure that the tropical triangle
is big enough; the equalities (
25) and (29) make sure that
parallels with a coordinate plane; the equality (29) makes sure that
is located under all points in
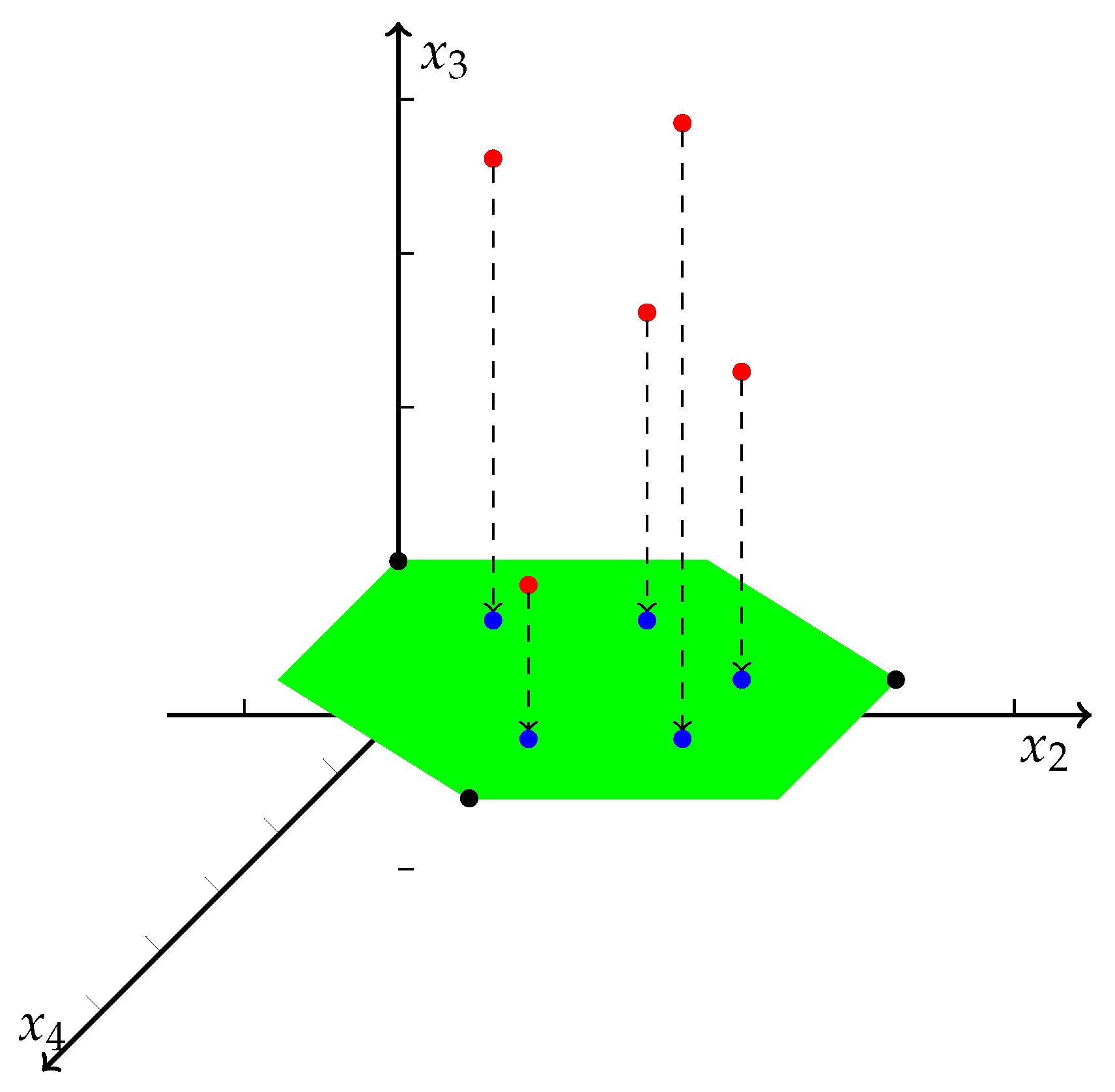
X. Lemma 1 shows that we can project
X vertically onto
(see Example 6 and
Figure 4).
Example 6. Let . Fix . By (25)–(29), we can define three points as: Let (see the green region in Figure 4). Then, by Lemma 1, the projection points of X on are shown in Figure 4 (see the blue points). Definition 7 (Data Matrix). We define any matrix X with n columns as adata matrix, where each row of X is regarded as a point in .
Below we denote by the data matrix X with size .
Definition 8 (Fermat-Weber Points of a Data Matrix). For a given data matrix , suppose the i-th row of X is (). We define theFermat-Weber point ofX as the Fermat-Weber point of . We still denote by the Fermat-Weber point of X.
Definition 9 (Projection Matrix). For a given data matrix , and for any two fixed integers , we define the projection matrix
of X (denoted by ) as a matrix with size , such that for all , the row of iswhere and are respectively the -entry and the -entry of X, and are respectively located at the -entry and the -entry of of .
t is a fixed number, such that .
Note that the projection matrix is still a data matrix.
Recall the Proposition 2 tells that, if is a Fermat-Weber point of , then is the unique Fermat-Weber point of .
Theorem 1. Suppose we have a data matrix , where the last row of X is a Fermat-Weber point of the matrix made by the first m rows of X. We fix two integers and . Let be the last row of .
If is a Fermat-Weber point of , and , and are defined by (25)–(29), then the projection of the Fermat-Weber point of X on is a Fermat-Weber point of the projection of X on . Proof. By Lemma 1 and Definition 9 we know that, the projection of
X on
is
. Note that the last row of
X is the unique Fermat-Weber point of
X. Also note that
is the projection of the last row of
X. Then by the assumption that
is a Fermat-Weber point of
we know that, the projection of the Fermat-Weber point of
X on
is a Fermat-Weber point of the projection of
X on
. □
Theorem 2. Suppose we have a data matrix . We fix two integers and . Let be a pointwhere and are undetermined numbers, and t is the smallest entry of X. Let be a Fermat-Weber point of . If and then is a Fermat-Weber point of . Proof. By Definition 9, the
i-th row of
has the form
Assume that
is a Fermat-Weber point of
. Suppose there exists
such that
For any
, let
It is easy to see that So, by Definition 5, is a Fermat-Weber point of □
4. Algorithms
In this section, we develop Algorithms 1 and 2, such that for a given data set , these two algorithms output a tropical triangle , on which the projection of a Fermat-Weber point of X is a Fermat-Weber point of the projection of X.
The input of Algorithms 1 and 2 is a data set
Algorithms 1 and 2 output three points
such that the projection of a Fermat-Weber point of
on
is a Fermat-Weber point of the projection of
on
.
There are two main steps in each algorithm as follows.
Step 1. We define a data matrix
X, such that for all
the
i-th row of
X is
We obtain a Fermat-Weber point
by solving the linear programming (
16). We define a matrix
with size
, such that the last row of
is
, and the first
m rows of
come from
X.
Step 2. We traverse all pairs
such that
, and we calculate the projection matrix
by Definition 9. Check if the last row of
is a Fermat-Weber point of
. If so, we calculate the three points
by (
25)–(29) in Lemma 1, return the output, and terminate. By Theorem 1 we know that, the projection of a Fermat-Weber point of
X on
is a Fermat-Weber point of the projection of
X on
If for all
, the last row of
is not a Fermat-Weber point of
, then return FAIL.
Remark 1. It is not guaranteed that Algorithms 1 and 2 will always succeed (return the tropical triangle). If the algorithms succeed, then by Theorem 1, Algorithm 1 is correct, and by Theorems 1 and 2, Algorithm 2 is correct.
Algorithms 1 and 2 always succeed or fail simultaneously. But our experimental results in the next section show that, Algorithm 1 or Algorithm 2 succeeds with a much higher probability than choosing tropical triangles randomly. Our experimental results also show that, if Algorithms 1 and 2 succeed, then with the probability more than , Algorithm 2 would terminate in less traversal steps than Algorithm 1 does (see Section 5). Remark that, the difference between Algorithms 1 and 2 is the traversal strategy, i.e., the Step 2. is different. Below we give more details about Step 2.
- 1.
In Algorithm 1: Step 2.,we traverse all pairs () in L one by one, i.e., we traverse the pairs in the lexicographical order.
- 2.
In Algorithm 2: Step 2., we consider the same
L defined in (
45). Note that
. Let
W and
S be two empty sets. In the future, we will record in
W some indices that will be traversed in priority, and record in
S the pairs that have been traversed. Let
,
and
be null vectors.
Now we start a loop (see lines 2–2 in Algorithm 2). In this loop, we traverse all pairs in
L while
, and
,
and
are null. For each pair
, if
, then we skip the pair. If
, then we add the pair into
S, and calculate the projection matrix
by Definition 9. Let
be the last row of
. If
is a Fermat-Weber point of
, then we calculate
,
and
by formulas (
25)–(29) in Lemma 1, return the output and terminate. By Theorem 1 we know that, the projection of a Fermat-Weber point of
X on
is a Fermat-Weber point of the projection of
X on
If
is not a Fermat-Weber point of
, then by Theorem 2, at most one of the following two equalities holds:
where
is a Fermat-Weber point of
So we have 3 cases.
Now we explain what we do if
(Case 1) happens (
(Case 2) is similar). Note that
W is nonempty at this time, and
,
and
are null. For each element
, we define
We start traversing all pairs in
. For each pair
, if
, then we skip the pair. If
, then we add the pair into
S, and calculate the projection matrix
by Definition 9. Let
be the last row of
. If
is a Fermat-Weber point of
, then calculate
,
and
by formulas (
25)–(29) in Lemma 1, output
,
and
, and terminate. If
is not a Fermat-Weber point of
, then by Theorem 2, at most one of the following two equalities holds:
where
is a Fermat-Weber point of
So we have 2 cases.
We move on to the next pair in . If for any pair , we have , and the last row of is not a Fermat-Weber point of , then we remove this from W. If W becomes empty again, then we continue the traversal of L we paused in (Case 1). If W is still nonempty after one element in W has been removed, then for the next we traverse .
Now we give two examples to better explain how Algorithms 1 and 2 work.
Example 7. This example explains how Algorithm 1 works. Suppose we have a data matrix By running the packagelpSolve [26] inRto solve the linear programming (16), we obtain a Fermat-Weber point of X, which is Define a matrix with size , such that the last row of is , and the first m rows of come from X. We have Now we start traversing all pairs in L, where - 1.
The first pair is . Note that by Definition 9 we have
We can compute a Fermat-Weber point of : The last row of is . By Definition 5 we can check that, is not a Fermat-Weber point of . We move on to the next pair.
- 2.
Similarly, we pass , and . For the pair , note that
We can compute a Fermat-Weber point of : , which is exactly the last row of . By (25)–(29) in Lemma 1, we make three points: Then, output , and terminate.
Example 8. This example explains how Algorithm 2 works. Suppose we have a data matrix By solving the linear programming (16), we obtain a Fermat-Weber point of X, which is Define a matrix with size , such that the last row of is , and the first m rows of come from X. We have Let L be a list that contains all pairs in the lexicographical order, that is Also let W and S be two empty sets. We will record in W some indices that will be traversed in priority, and record in S the pairs that have been traversed. Now we start the traversal.
- 1.
We first start traversing pairs in L. The first pair in L is . Add into S. Note that
We can compute a Fermat-Weber point of : The last row of is . By Definition 5 we can check that, is not a Fermat-Weber point of . We have and Now(Case 3)happens, so we move on to the next pair in L.
- 2.
The next pair in L is . Add into S. Note that
We can compute a Fermat-Weber point of : . The last row of is . By Definition 5 we can check that, is not a Fermat-Weber point of . We have and Now(Case 1)happens, so we add 2 into W, and pause the traversal in L. Note that, now is nonempty, and the first element in W is 2. By (48), we have We start traversing pairs in - 3.
Note that now The first pair in is , which is in S already, so we skip it. Similarly we skip . The third pair in is , which is not in S, so we do the following steps. Add into S. Note that
We can compute a Fermat-Weber point of : . The last row of is . By Definition 5 we can check that, is not a Fermat-Weber point of . We have and Now(Case 1.2)happens, so we add 5 into W, and now . Note that . Since for every pair , is in S, and the last row of is not a Fermat-Weber point of , we remove 2 from W.
- 4.
Note that, now is nonempty. By (48), we have The first pair in is , which is in S already, so we skip it. The second pair in is , which is not in S, so we do the following steps. Add into S. Note that
We can compute a Fermat-Weber point of : , which is the last row of . By (25)–(29) in Lemma 1, we make three points: and Then, output , and terminate. Below we give the pseudo code of Algorithms 1 and 2. Note that, Algorithms 3 and 4 are sub-algorithms of Algorithms 1 and 2. For a given data matrix
X, Algorithm 3 calculates the summation of tropical distance between the last row of
X and each row of
X, and also calculates the summation of tropical distance between a Fermat-Weber point of
X and each row of
X. We will use Algorithm 3 to check if the last row of
X is a Fermat-Weber point of
X. Algorithm 4 calculates three points
,
and
by (
25)–(29).
| Algorithm 3: Verify-FW-Point |
Input: Data matrix Output: TRUE, if the last row of X is a Fermat-Weber point of X; FALSE, if the last row of X is not a Fermat-Weber point of X - 1
the last row of X - 2
a Fermat-Weber point of X - 3
, , where is the i-th row of X - 4
ifthen return TRUE, otherwise, return FALSE
|
| Algorithm 4: Compute-Triangle |
Input: Output: , where , and are defined by ( 25)–(29) - 1
-dimensional null vectors - 2
the smallest entry of X - 3
the smallest coordinates in the -th and -th columns of X respectively - 4
the largest coordinates in the -th and -th columns of X respectively - 5
for - 6
, - 7
, - 8
, - 9
- 10
return
|
5. Implementation and Experiment
We implement Algorithms 1 and 2 in
language, and test how Algorithms 1 and 2 perform. We also use
language for numerical computation. Data matrices,
R code and computational results in this paper are available in
Supplementary Materials.
Now we present four tables and one figure to illustrate how Algorithms 1 and 2 perform. For each table or figure, we provide one paragraph for explaining presented information.
For a fixed data matrix
,
Table 1 shows the proportion of random tropical triangles, on which the projection of a Fermat-Weber point of
X is a Fermat-Weber point of the projection of
X. First, we explain what we mean by “success rate” in
Table 1. In fact, we mean the proportion of random tropical triangles, on which the projection of a Fermat-Weber point of
X is a Fermat-Weber point of the projection of
X. For example, we explain how we calculate the success rate for
and
. We generated a data matrix
X with size
, and randomly chose 100 tropical triangles. There were only 16 triangles such that the projection of a Fermat-Weber point of
X is a Fermat-Weber point of the projections. So, the success rate is
. From
Table 1 we can see that, for a given data matrix
X, when randomly choosing tropical triangles, the “success rate” is low. For instance, the highest success rate is
, and the lowest success rate is even only
. Besides, the success rate is extremely low when
m and
n are both big.
Table 2 shows the success rate of Algorithm 1 or Algorithm 2 (recall Remark 1 tells that, Algorithms 1 and 2 always succeed or fail simultaneously). From
Table 1 and
Table 2 we can see that, the success rates recorded in
Table 2 are much higher than those in
Table 1. For instance, the lowest rate in
Table 2 is
, which is still higher than the highest rate in
Table 1, and the highest rate in
Table 2 is
, which is close to
.
We fix
, and we fix
.
Table 3 shows how high the success rate of Algorithm 1 or Algorithm 2 would be when we change the data matrix
. In order to change
X, we change
v, such that
. We can see from
Table 3 that, when
v is changing from 1 to 800, the success rate of Algorithm 1 or Algorithm 2 is still around
. Note that
v is the variance of each coordinate of data points, which means that, when the coordinate of data points fluctuates violently, the success rate of Algorithm 1 or Algorithm 2 is still stable.
By “time” we mean the total computational time that Algorithm 1 or Algorithm 2 takes divided by the number of input data matrices. From
Table 4 we can see that, Algorithms 1 and 2 are both efficient. For instance, when there are 120 data points, and the dimension of each point is 20, the computational timings of Algorithms 1 and 2 are still no more than 7 min (373.5734 s and 291.9031 s). In addition, in most cases, Algorithm 2 takes less time than Algorithm 1 does. For instance, when
m is 120, and
n is 20, Algorithm 2 takes around one and a half minutes less than Algorithm 1 does.
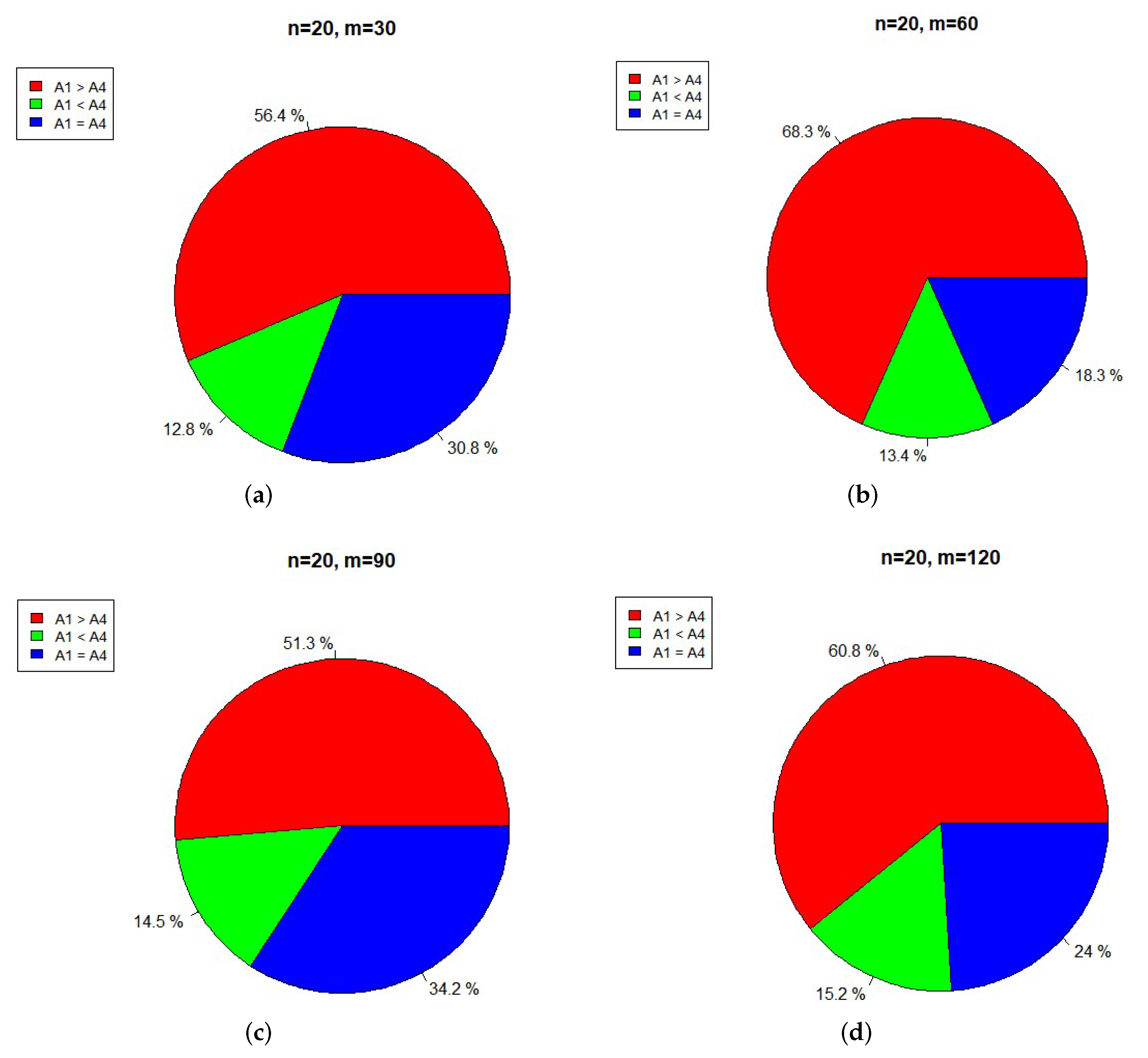
Figure 5 compares the numbers of traversal steps of Algorithms 1 and 2. From
Figure 5 we can see that, with the proportion more than
, Algorithm 1 takes more traversal steps than Algorithm 2 does. In
Figure 5,
m represents the number of data points in data matrix
X;
n represents the dimension of data points in data matrix
X. “
” means Algorithm 1 takes more steps than Algorithm 2 does. “
” means Algorithm 1 takes less steps than Algorithm 2 does. “
” means Algorithm 1 takes equal steps to Algorithm 2. For each pair
, we run Algorithms 1 and 2 with 100 random data matrices
. If Algorithms 1 and 2 correctly terminate, then record the number of traversal steps that Algorithms 1 and 2 respectively take.











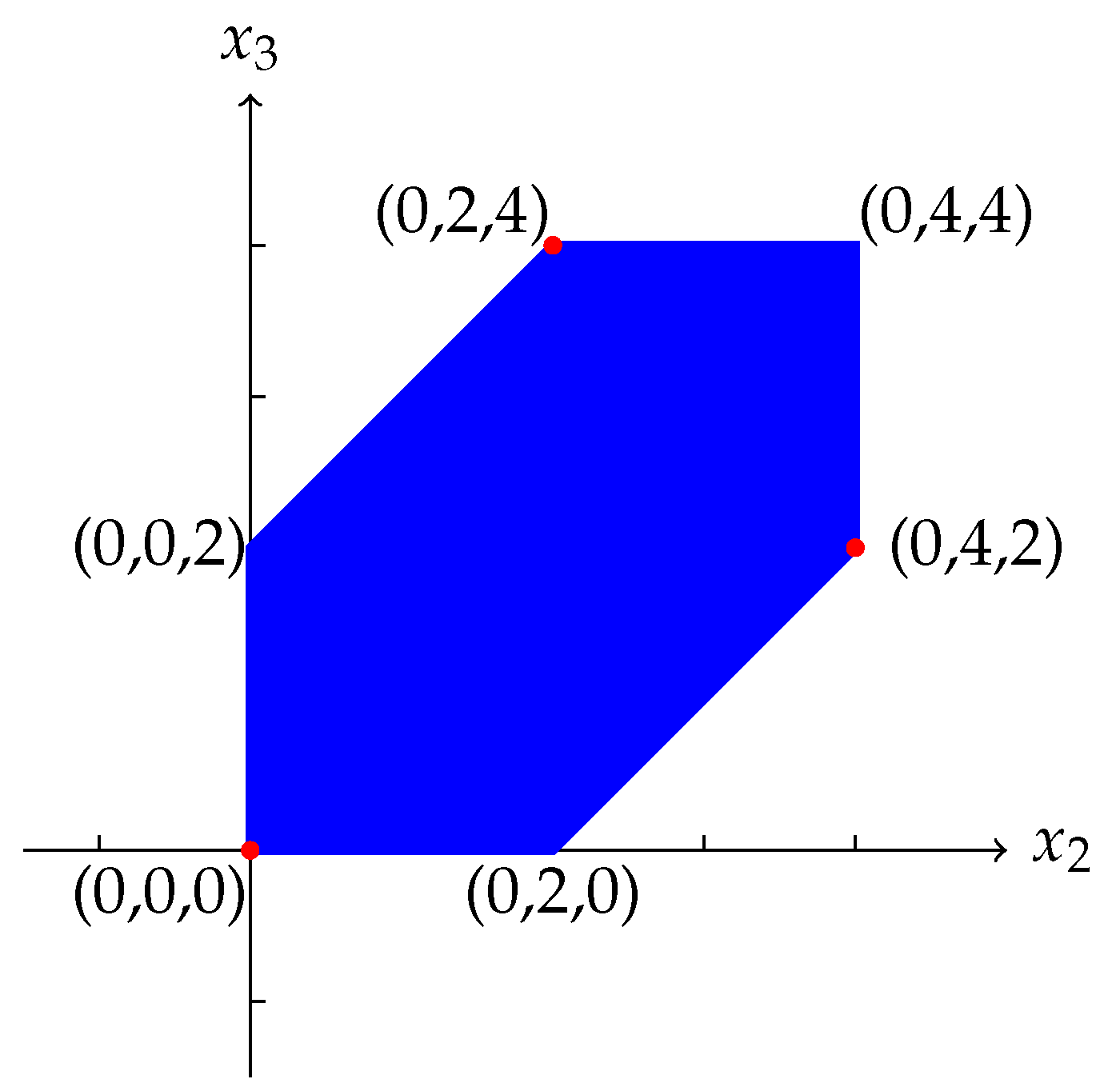{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}