
Prognostic and Classification of Dynamic Degradation in a Mechanical System Using Variance Gamma Process




Abstract
:1. Introduction
2. Variance Gamma Process
3. Environmental Conditions and Failure Time
3.1. Environmental Conditions: Covariates
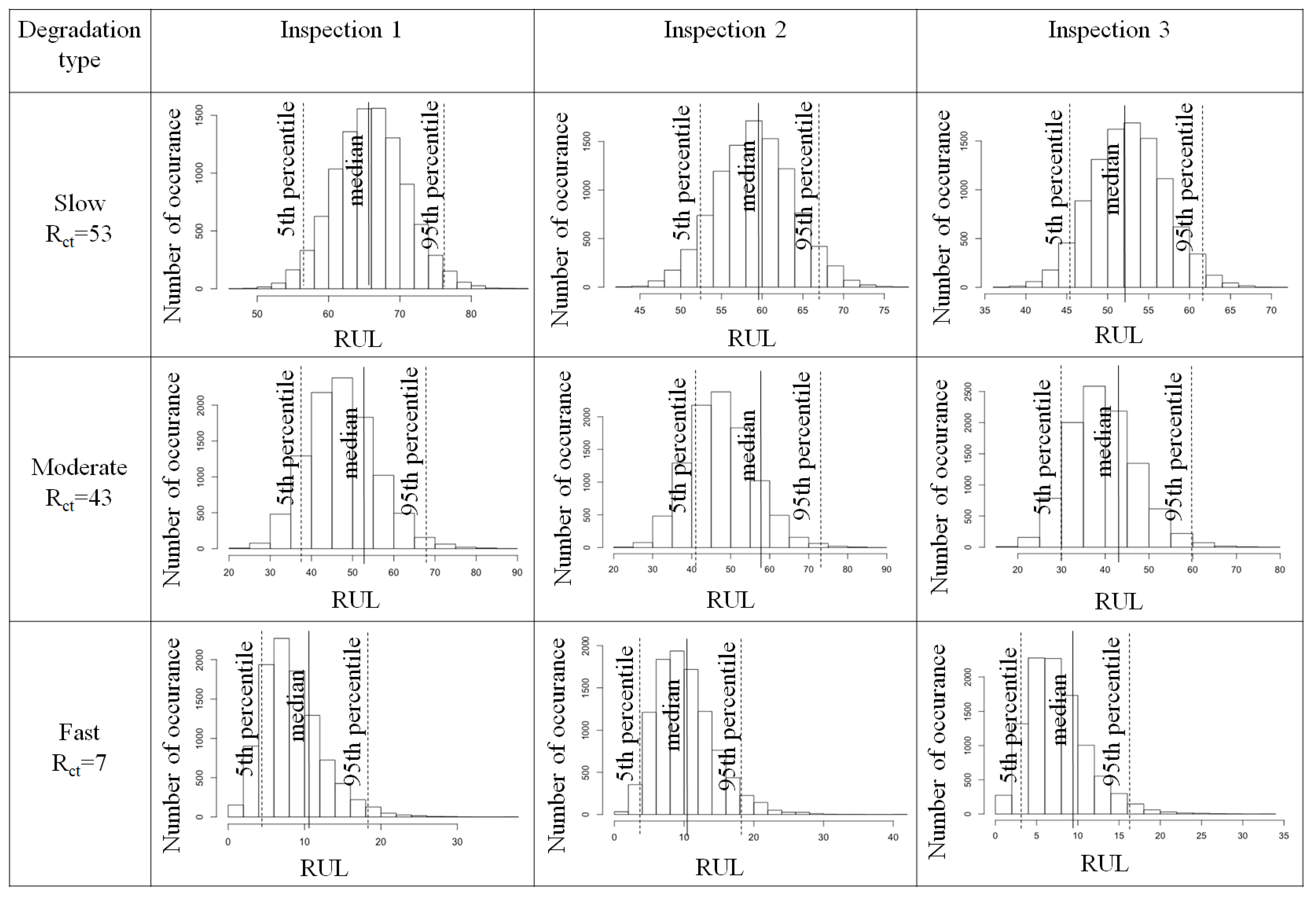
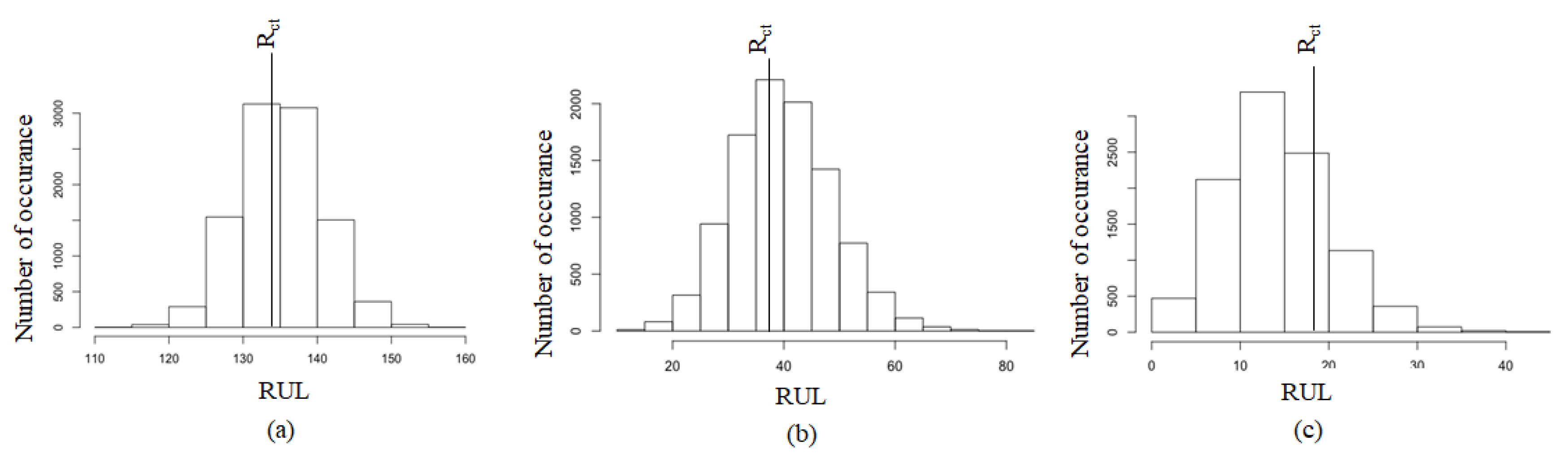
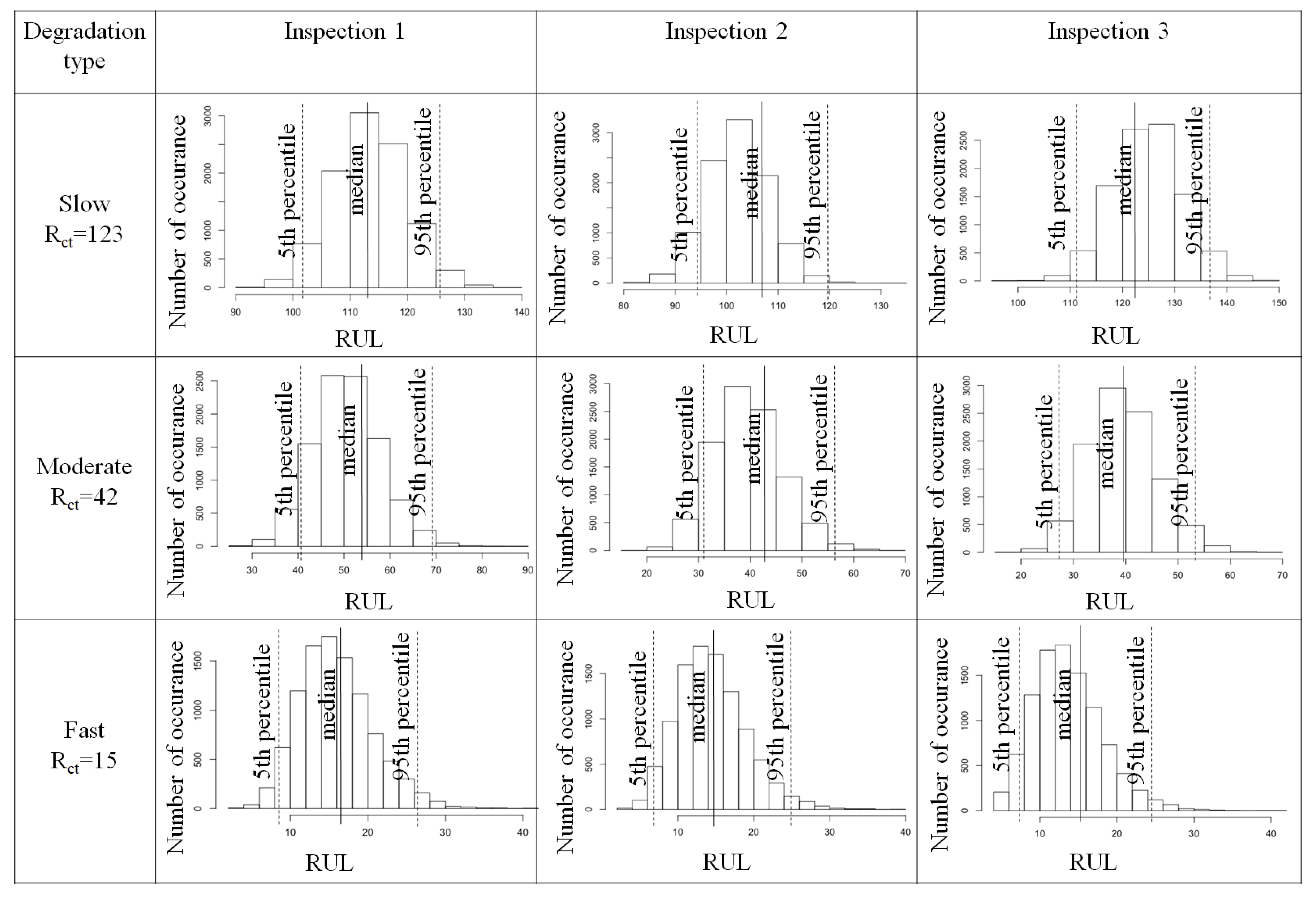
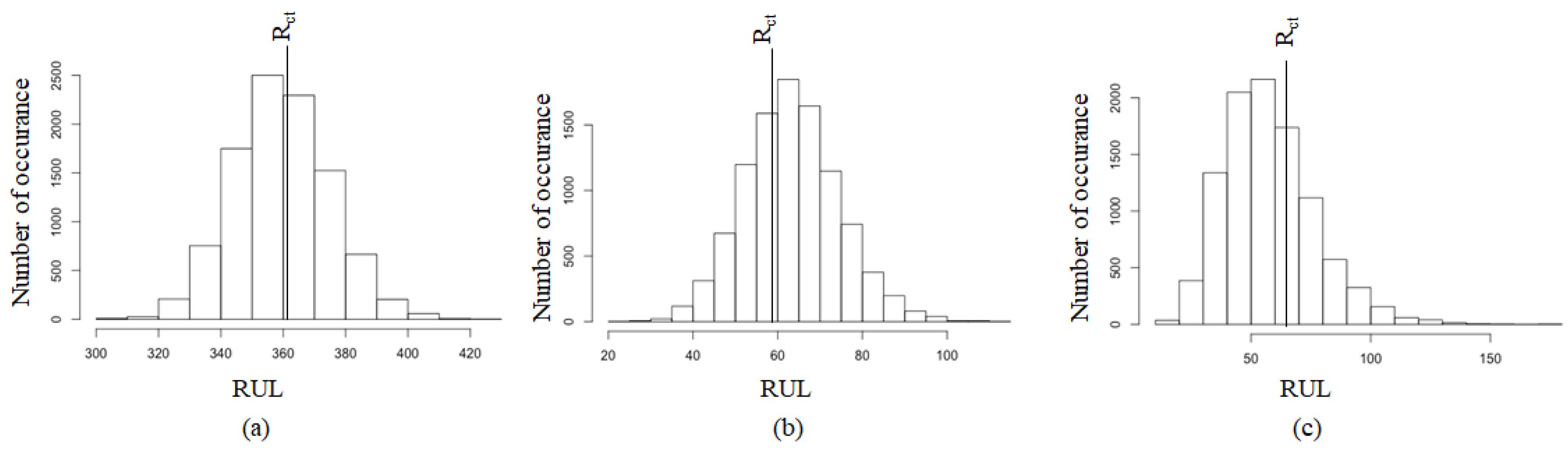
3.2. Failure Time
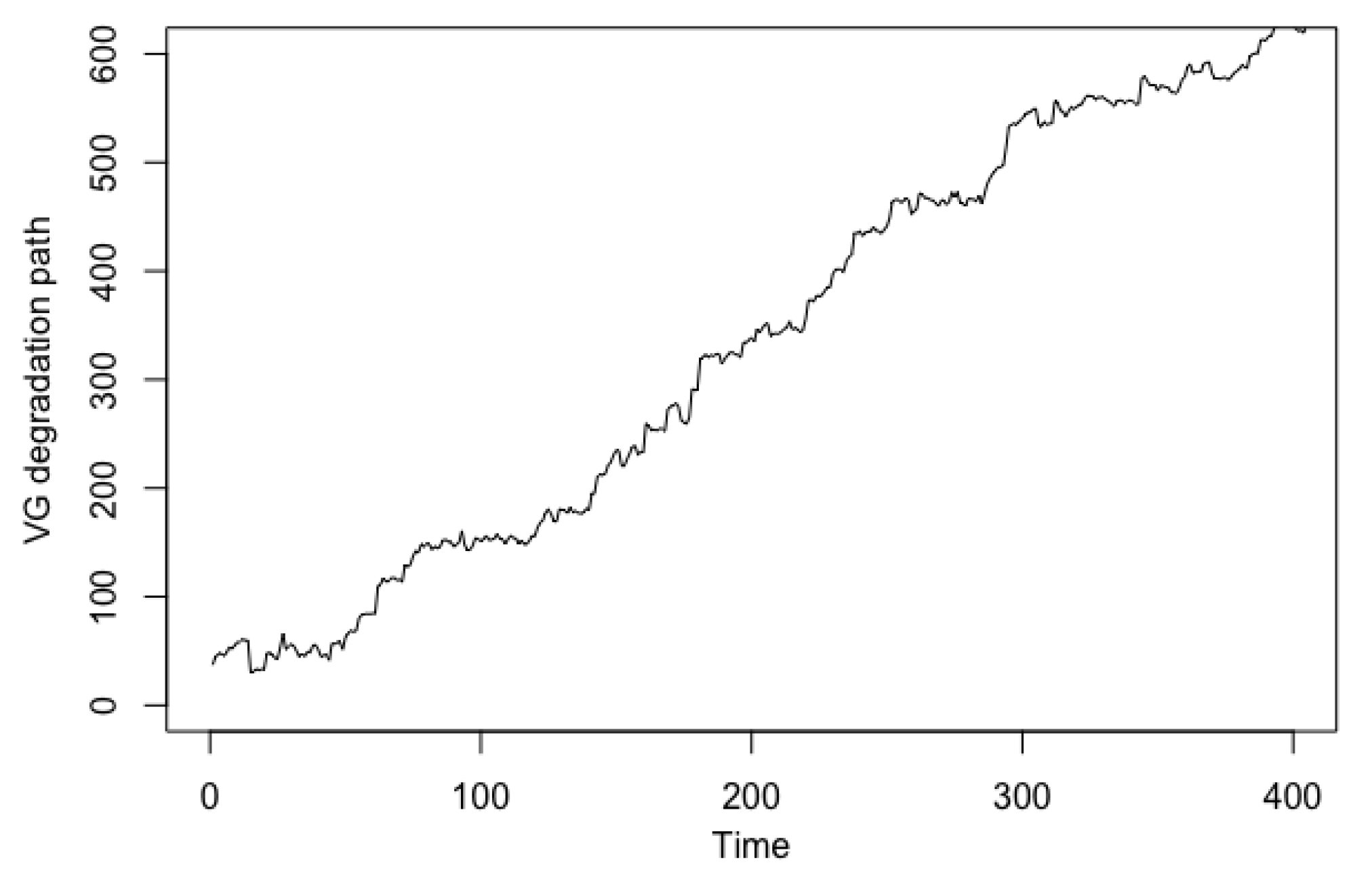
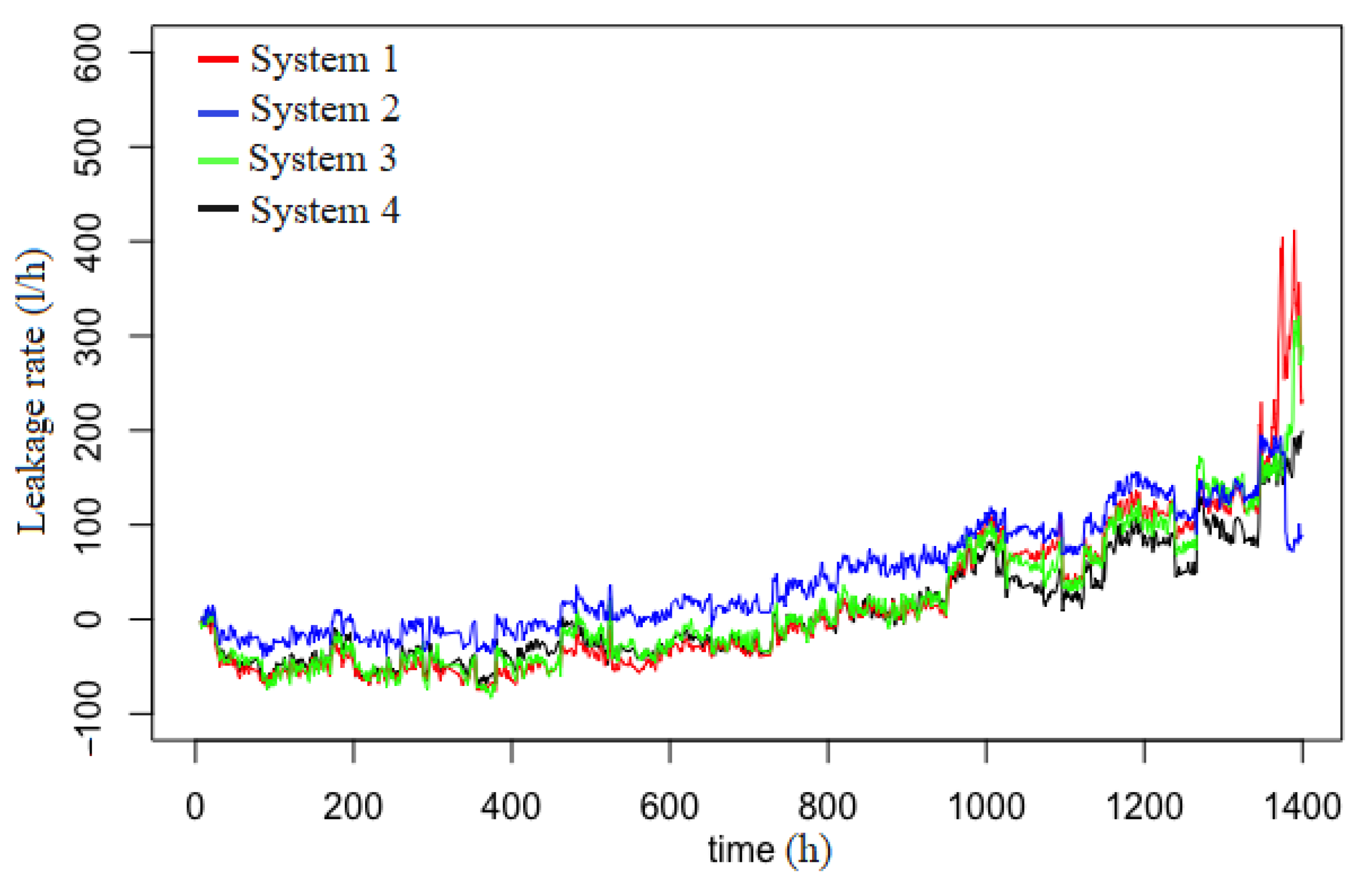
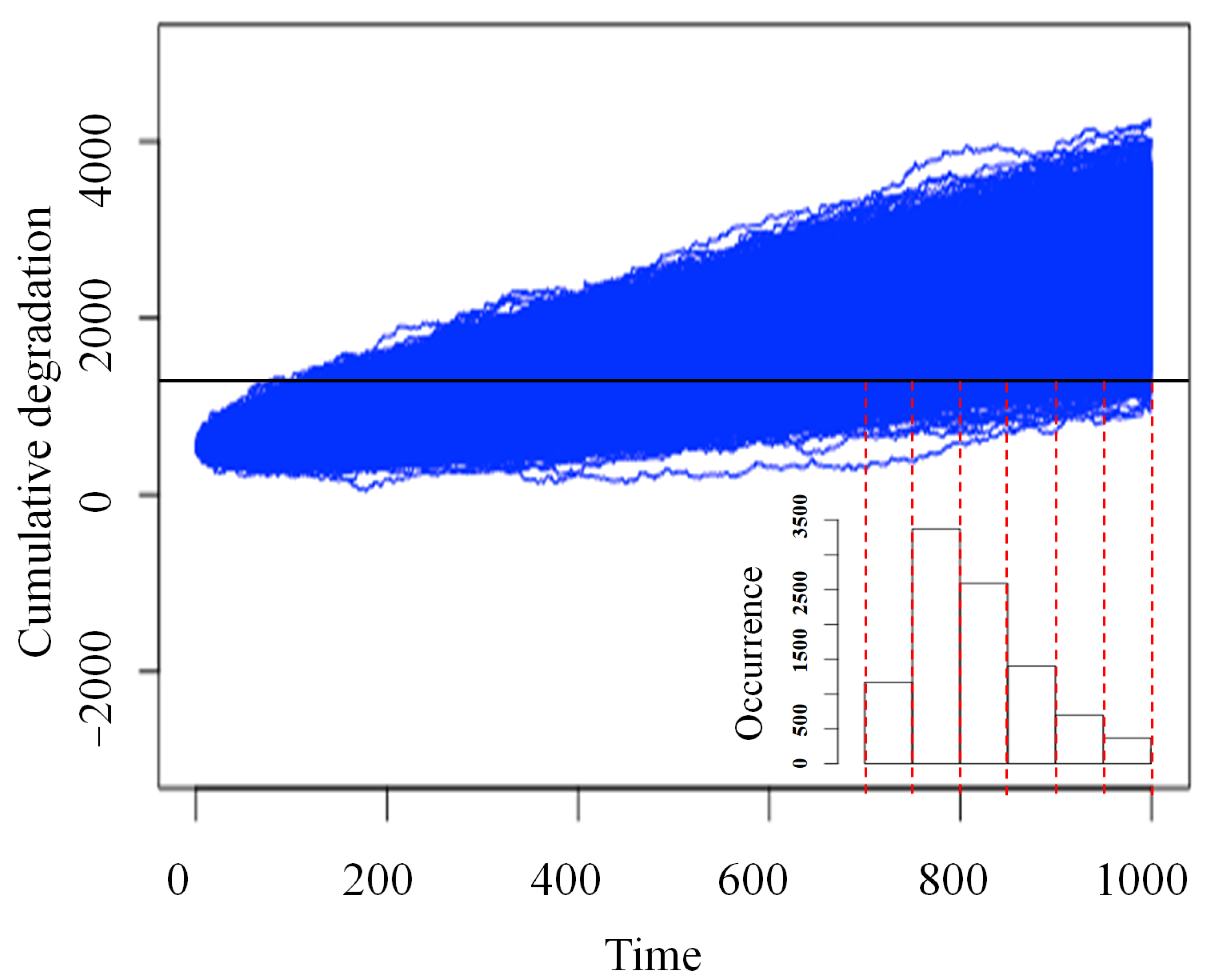
4. Centrifugal Pump System and Degradation Data
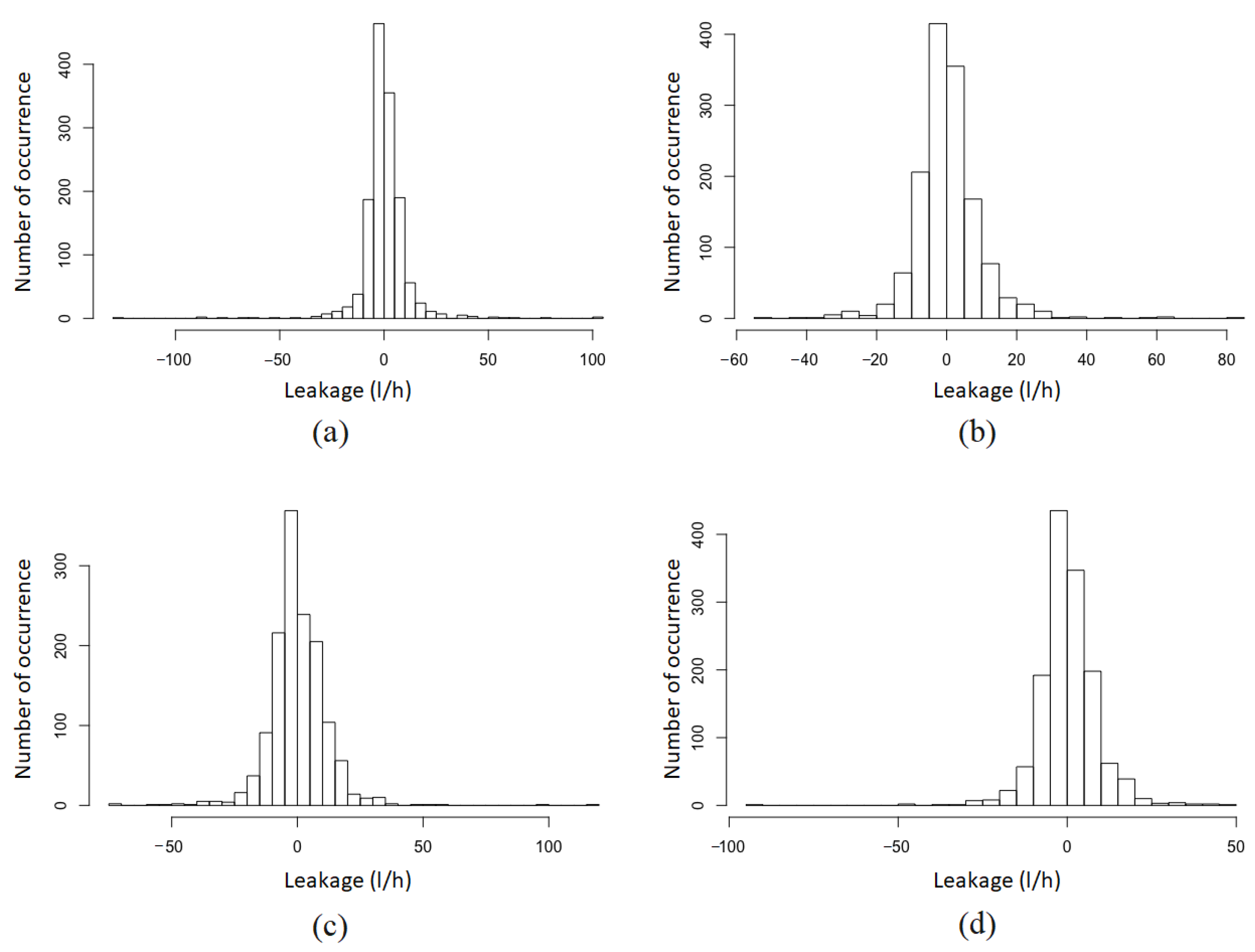
4.1. Presentation of Degradation Data
4.2. Degradation Model with Covariates
5. Classification Methods
5.1. Classification Methods for Simulated Data
5.1.1. K-Nearest-Neighbour Algorithms
5.1.2. Neural Network Algorithms
5.2. Classification Methods for Real Data
5.2.1. K-Nearest-Neighbour Algorithms
5.2.2. Neural Network Algorithms
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bogdanoff, J.L.; Kozin, F. Probabilistic Models of Cumulative Damage; Wiley-Interscience: New York, NY, USA, 1985; 350p. [Google Scholar]
- Van Noortwijk, J.M. A survey of the application of gamma processes in maintenance. Reliab. Eng. Syst. Saf. 2009, 94, 2–21. [Google Scholar] [CrossRef]
- Frangopol, D.M.; Kallen, M.J.; Noortwijk, J.M.V. Probabilistic models for life-cycle performance of deteriorating structures: Review and future directions. Prog. Struct. Eng. Mater. 2004, 6, 197–212. [Google Scholar] [CrossRef]
- Abdel-Hameed, M. Degradation processes: An overview. In Advances in Degradation Modeling; Springer: Berlin/Heidelberg, Germany, 2010; pp. 17–25. [Google Scholar]
- Madan, D.B.; Seneta, E. The variance gamma (VG) model for share market returns. J. Bus. 1990, 63, 511–524. [Google Scholar] [CrossRef]
- Madan, D.B.; Milne, F. Option pricing with vg martingale components 1. Math. Financ. 1991, 1, 39–55. [Google Scholar] [CrossRef] [Green Version]
- Madan, D.B.; Carr, P.P.; Chang, E.C. The variance gamma process and option pricing. Rev. Financ. 1998, 2, 79–105. [Google Scholar] [CrossRef] [Green Version]
- Fiorani, F. The Variance-Gamma process for option pricing. J. Comput. Financ. 1999, 2, 61–73. [Google Scholar] [CrossRef] [Green Version]
- Fiorani, F. Option Pricing Under the Variance Gamma Process. 2004. Available online: https://ssrn.com/abstract=1411741 (accessed on 23 November 2020).
- Yoo, E. Variance Gamma Pricing of American Futures Options; Florida State University: Tallahassee, FL, USA, 2008. [Google Scholar]
- Marfè, R. A generalized variance gamma process for financial applications. Quant. Financ. 2012, 12, 75–87. [Google Scholar] [CrossRef]
- Rathgeber, A.W.; Stadler, J.; Stöckl, S. Modeling share returns-an empirical study on the Variance Gamma model. J. Econ. Financ. 2016, 40, 653–682. [Google Scholar] [CrossRef]
- Nitithumbundit, T.; Chan, J.S. ECM Algorithm for Auto-Regressive Multivariate Skewed Variance Gamma Model with Unbounded Density. Methodol. Comput. Appl. Probab. 2019, 22, 1169–1191. [Google Scholar] [CrossRef]
- Whitley, A. Pricing of European, Bermudan and American Options under the Exponential Variance Gamma Process. 2009. Available online: https://ora.ox.ac.uk/objects/uuid:7e32bbe5-eb07-442b-bbc4-e1d496ac8aab (accessed on 23 November 2020).
- Bollin, B.; Ślepaczuk, R. Variance Gamma Model in Hedging Vanilla and Exotic Options; Technical Report; 2020; Available online: https://www.wne.uw.edu.pl/files/8416/0034/9047/WNE_WP337.pdf (accessed on 23 November 2020).
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. B 1972, 34, 187–202. [Google Scholar] [CrossRef]
- Deloux, E.; Castanier, B.; Bérenguer, C. Predictive maintenance policy for a gradually deteriorating system subject to stress. Reliab. Eng. Syst. Saf. 2009, 94, 418–431. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Gaudoin, O.; Doyen, L.; Xie, M. Optimal inspection and replacement policy based on experimental degradation data with covariates. IISE Trans. 2019, 51, 322–336. [Google Scholar] [CrossRef]
- Barabadi, A.; Barabady, J.; Markeset, T. Application of reliability models with covariates in spare part prediction and optimization—A case study. Reliab. Eng. Syst. Saf. 2014, 123, 1–7. [Google Scholar] [CrossRef]
- Okaro, I.A.; Tao, L. Reliability analysis and optimisation of subsea compression system facing operational covariate stresses. Reliab. Eng. Syst. Saf. 2016, 156, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Moniri-Morad, A.; Pourgol-Mohammad, M.; Aghababaei, H.; Sattarvand, J. Reliability-based covariate analysis for complex systems in heterogeneous environment: Case study of mining equipment. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2019, 233, 593–604. [Google Scholar] [CrossRef]
- Slimacek, V.; Lindqvist, B. Reliability of wind turbines modeled by a Poisson process with covariates, unobserved heterogeneity and seasonality. Wind Energy 2016, 19, 1991–2002. [Google Scholar] [CrossRef]
- Duan, F.; Wang, G. Exponential-dispersion degradation process models with random effects and covariates. IEEE Trans. Reliab. 2018, 67, 1128–1142. [Google Scholar] [CrossRef]
- Barabadi, A.; Barabady, J.; Markeset, T. Maintainability analysis considering time-dependent and time-independent covariates. Reliab. Eng. Syst. Saf. 2011, 96, 210–217. [Google Scholar] [CrossRef]
- Guo, R.; Love, E. Reliability modelling with fuzzy covariates. Int. J. Reliab. Qual. Saf. Eng. 2003, 10, 131–157. [Google Scholar] [CrossRef] [Green Version]
- Zhu, W.; Fouladirad, M.; Bérenguer, C. Condition-based maintenance policies for a combined wear and shock deterioration model with covariates. Comput. Ind. Eng. 2015, 85, 268–283. [Google Scholar] [CrossRef]
- Zhang, N.; Fouladirad, M.; Barros, A. Reliability-based measures and prognostic analysis of a K-out-of-N system in a random environment. Eur. J. Oper. Res. 2019, 272, 1120–1131. [Google Scholar] [CrossRef]
- Lawless, J.; Crowder, M. Covariates and random effects in a gamma process model with application to degradation and failure. Lifetime Data Anal. 2004, 10, 213–227. [Google Scholar] [CrossRef] [PubMed]
- Laucelli, D.; Rajani, B.; Kleiner, Y.; Giustolisi, O. Study on relationships between climate-related covariates and pipe bursts using evolutionary-based modelling. J. Hydroinform. 2014, 16, 743–757. [Google Scholar] [CrossRef]
- Park, S.; Jun, H.; Agbenowosi, N.; Kim, B.J.; Lim, K. The proportional hazards modeling of water main failure data incorporating the time-dependent effects of covariates. Water Resour. Manag. 2011, 25, 1–19. [Google Scholar] [CrossRef]
- Balekelayi, N.; Tesfamariam, S. Statistical inference of sewer pipe deterioration using Bayesian geoadditive regression model. J. Infrastruct. Syst. 2019, 25, 04019021. [Google Scholar] [CrossRef]
- Gorjian, N.; Rameezdeen, R.; Gorjian Jolfaei, N.; Chow, C.; Jin, B. Ref: EATJ-D-19-00148-prediction of remaining useful life of naval structures using a covariate-base hazard model. Aust. J. Struct. Eng. 2020, 1–10. [Google Scholar] [CrossRef]
- Xu, Z.; Hong, Y.; Jin, R. Nonlinear general path models for degradation data with dynamic covariates. Appl. Stoch. Model. Bus. Ind. 2016, 32, 153–167. [Google Scholar] [CrossRef]
- Zhou, B.; Qi, F.; Tao, H. Condition-based maintenance modeling for a two-stage deteriorating system with random changes based on stochastic process. J. Qual. Maint. Eng. 2017, 23. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, X.; Liu, G.; Liu, Y. Life cycle cost analysis considering multiple dependent degradation processes and environmental influence. Reliab. Eng. Syst. Saf. 2020, 197, 106784. [Google Scholar] [CrossRef]
- Giorgio, M.; Guida, M.; Pulcini, G. A new class of Markovian processes for deteriorating units with state dependent increments and covariates. IEEE Trans. Reliab. 2015, 64, 562–578. [Google Scholar] [CrossRef]
- Arabani, M.; Manavizadeh, N.; Balali, S. A Stochastic Model for Indirect Condition Monitoring Using Proportional Covariate Model. Int. J. Eng. Trans. A Basics 2007, 21, 45–56. [Google Scholar]
- Mahmoodi, S.; Hamed Ranjkesh, S.; Zhao, Y.Q. Condition-based maintenance policies for a multi-unit deteriorating system subject to shocks in a semi-Markov operating environment. Qual. Eng. 2020, 1–12. [Google Scholar] [CrossRef]
- Ahmadzadeh, F.; Ghodrati, B.; Kumar, U. Mean residual life estimation considering operating environment. In Proceedings of the International Conference on Quality, Reliability, Infocom Technology and Industrial Technology Management, Newdelhi, India, 26–28 November 2012. [Google Scholar]
- Shahraki, A.F.; Yadav, O.P. Selective maintenance optimization for multi-state systems operating in dynamic environments. In Proceedings of the 2018 Annual Reliability and Maintainability Symposium (RAMS), IEEE, Reno, NV, USA, 22–25 January 2018; pp. 1–6. [Google Scholar]
- Si, W.; Love, E.; Yang, Q. Two-state optimal maintenance planning of repairable systems with covariate effects. Comput. Oper. Res. 2018, 92, 17–25. [Google Scholar] [CrossRef]
- Tang, D.; Makis, V.; Jafari, L.; Yu, J. Optimal maintenance policy and residual life estimation for a slowly degrading system subject to condition monitoring. Reliab. Eng. Syst. Saf. 2015, 134, 198–207. [Google Scholar] [CrossRef]
- Huynh, K.T.; Barros, A.; Bérenguer, C. Adaptive condition-based maintenance decision framework for deteriorating systems operating under variable environment and uncertain condition monitoring. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2012, 226, 602–623. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Scarf, P. Decline and repair, and covariate effects. Eur. J. Oper. Res. 2015, 244, 219–226. [Google Scholar] [CrossRef] [Green Version]
- Hong, Y.; Duan, Y.; Meeker, W.Q.; Stanley, D.L.; Gu, X. Statistical methods for degradation data with dynamic covariates information and an application to outdoor weathering data. Technometrics 2015, 57, 180–193. [Google Scholar] [CrossRef] [Green Version]
- Si, W.; Shao, Y.; Wei, W. Accelerated Degradation Testing With Long-Term Memory Effects. IEEE Trans. Reliab. 2020, 69, 1254–1266. [Google Scholar] [CrossRef]
- Aalen, O.O.; Borgan, Ø.; Fekjær, H. Covariate adjustment of event histories estimated from Markov chains: The additive approach. Biometrics 2001, 57, 993–1001. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.A.; Chowdhury, R.I. A higher order Markov model for analyzing covariate dependence. Appl. Math. Model. 2006, 30, 477–488. [Google Scholar] [CrossRef]
- Sirima, P.; Pokorny, P. Hidden Markov models with covariates for analysis of defective industrial machine parts. J. Math. Stat. 2014, 10, 322–330. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Fouladirad, M.; Bérenguer, C.; Bordes, L. Condition-based inspection/replacement policies for non-monotone deteriorating systems with environmental covariates. Reliab. Eng. Syst. Saf. 2010, 95, 921–934. [Google Scholar] [CrossRef]
- Deloux, E.; Fouladirad, M.; Bérenguer, C. Health-and-usage-based maintenance policies for a partially observable deteriorating system. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2016, 230, 120–129. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Di Lucca, G.A.; Di Penta, M.; Gradara, S. An approach to classify software maintenance requests. In Proceedings of the International Conference on Software Maintenance, Montreal, QC, Canada, 3–6 October 2002; IEEE: New York, NY, USA, 2002; pp. 93–102. [Google Scholar]
- Yao, Y.; Tang, X.; Lim, E.P. Localized monitoring of kNN queries in wireless sensor networks. VLDB J. 2009, 18, 99–117. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Z.; Guo, L. Real-time Online Fault Diagnosis of Rolling Bearings Based on KNN Algorithm. J. Phys. Conf. Ser. 2020, 1486, 032019. [Google Scholar] [CrossRef]
- Lee, J. Measurement of machine performance degradation using a neural network model. Int. J. Model. Simul. 1996, 16, 192–199. [Google Scholar] [CrossRef]
- Huang, Y.H. Artificial neural network model of bridge deterioration. J. Perform. Constr. Facil. 2010, 24, 597–602. [Google Scholar] [CrossRef]
- Quah, T.S.; Thwin, M.M.T. Application of neural networks for software quality prediction using object-oriented metrics. In Proceedings of the International Conference on Software Maintenance, ICSM 2003, Amsterdam, The Netherlands, 22–26 September 2003; IEEE: New York, NY, USA, 2003; pp. 116–125. [Google Scholar]
- Hurd, T.R. Credit risk modeling using time-changed Brownian motion. Int. J. Theor. Appl. Financ. 2009, 12, 1213–1230. [Google Scholar] [CrossRef]
- Hurd, T.; Kuznetsov, A. On the first passage time for Brownian motion subordinated by a Lévy process. J. Appl. Probab. 2009, 46, 181–198. [Google Scholar] [CrossRef] [Green Version]
- Li, H. First-Passage Time Models with a Stochastic Time Change in Credit Risk. In Theses and Dissertations (Comprehensive); Wilfrid Laurier University: Waterloo, ON, Canada, 2009. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| K | 1 | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|---|
| Accuracy | 0.6833 | 0.7945 | 0.8256 | 0.9013 | 0.8513 | 0.8386 |
| Classification rate | 68.33% | 79.45% | 82.56% | 90.13% | 85.13 % | 83.86% |
| VG Parameters | Deg. | VG | VG | VG | VG | VG | VG | VG | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Type | Min | Max | Mod | Mean | Skew | Kurt | Var | ||||
| 0.45 | 0.30 | 0.25 | 0.25 | S | −0.853 | 2.618 | 0.442 | 0.569 | 0.458 | 3.892 | 0.225 |
| 3.5 | 2.5 | 1 | 0.75 | M | −5.249 | 37.592 | 1.75 | 4.250 | 2.507 | 13.530 | 24.75 |
| 0.35 | 0.5 | 0.40 | 0.40 | S | −0.514 | 2.867 | 0.512 | 0.629 | 0.737 | 4.572 | 0.147 |
| 0.25 | 0.75 | 0.25 | 0.15 | S | −0.282 | 1.510 | 0.246 | 0.301 | 0.505 | 3.923 | 0.045 |
| 10 | 9 | 1 | 2 | F | −25.036 | 125.741 | 10 | 13.853 | 3.809 | 28.370 | 180 |
| 1 | 1.5 | 0.75 | 1.5 | S | 0.263 | 10.997 | 1.727 | 2.967 | 1.627 | 7.188 | 2.687 |
| 3 | 2 | 2 | 1.5 | M | −7.425 | 25.538 | 1.5 | 3.246 | 2.453 | 13.318 | 17 |
| 10 | 8 | 1 | 2 | F | −14.722 | 151.918 | 8 | 14.993 | 4.314 | 31.739 | 315 |
| 5 | 1.5 | 0.5 | 1 | M | −6.583 | 32.533 | 2 | 3.484 | 2.915 | 18.061 | 15.75 |
| 4.75 | 3 | 0.75 | 1 | M | −1.151 | 42.380 | 2 | 5.003 | 2.790 | 14.801 | 22 |
| 7 | 6 | 1 | 2 | F | −6.667 | 153.298 | 7 | 11.956 | 4.190 | 30.835 | 129 |
| 3.25 | 2.5 | 1 | 1 | M | −2.945 | 39.808 | 3 | 5.341 | 3.309 | 20.053 | 27.75 |
| 10 | 8 | 1.5 | 2 | F | −41.436 | 141.537 | 4 | 8.502 | 4.074 | 30.037 | 225 |
| 0.5 | 0.5 | 0.5 | 0.5 | S | −0.356 | 4.473 | 0.680 | 1.026 | 1.088 | 5.333 | 0.375 |
| 9 | 6 | 1 | 2 | F | −30.599 | 224.604 | 6 | 9.886 | 4.433 | 35.230 | 177 |
| K | 1 | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|---|
| Accuracy | 0.6682 | 0.7792 | 0.8551 | 0.7317 | 0.7529 | 0.7261 |
| Classification rate | 66.82% | 77.92% | 85.51% | 73.17% | 75.29% | 72.61% |
| ( = 0.45, = 0.30, = 0.25, = 0.25) | ||||
| RMSE1 | 0.00058383 | 2.555940 × 10 | 0.00009207 | 0.00012196 |
| RMSE2 | 0.00080584 | 2.516683 × 10 | 0.00081257 | 0.0007324230 |
| ( = 3.5, = 2.5, = 1, = 0.5) | ||||
| RMSE1 | 4.063446 × 10 | 0.00293710 | 0.02806451 | 0.001025312 |
| RMSE2 | 3.870385 × 10 | 0.09642984 | 0.03979212 | 0.005082687 |
| ( = 10, = 4, = 1.5, = 0.75) | ||||
| RMSE1 | 0.001231534 | 2.9477285 × 10 | 0.001239473 | 0.000463153 |
| RMSE2 | 0.003269308 | 2.936155 × 10 | 0.001256060 | 0.0006779552 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belhaj Salem, M.; Fouladirad, M.; Deloux, E. Prognostic and Classification of Dynamic Degradation in a Mechanical System Using Variance Gamma Process. Mathematics 2021, 9, 254. https://doi.org/10.3390/math9030254
Belhaj Salem M, Fouladirad M, Deloux E. Prognostic and Classification of Dynamic Degradation in a Mechanical System Using Variance Gamma Process. Mathematics. 2021; 9(3):254. https://doi.org/10.3390/math9030254
Chicago/Turabian StyleBelhaj Salem, Marwa, Mitra Fouladirad, and Estelle Deloux. 2021. "Prognostic and Classification of Dynamic Degradation in a Mechanical System Using Variance Gamma Process" Mathematics 9, no. 3: 254. https://doi.org/10.3390/math9030254
APA StyleBelhaj Salem, M., Fouladirad, M., & Deloux, E. (2021). Prognostic and Classification of Dynamic Degradation in a Mechanical System Using Variance Gamma Process. Mathematics, 9(3), 254. https://doi.org/10.3390/math9030254