Analysis and Correction of the Attack against the LPN-Problem Based Authentication Protocols


Abstract
:1. Introduction
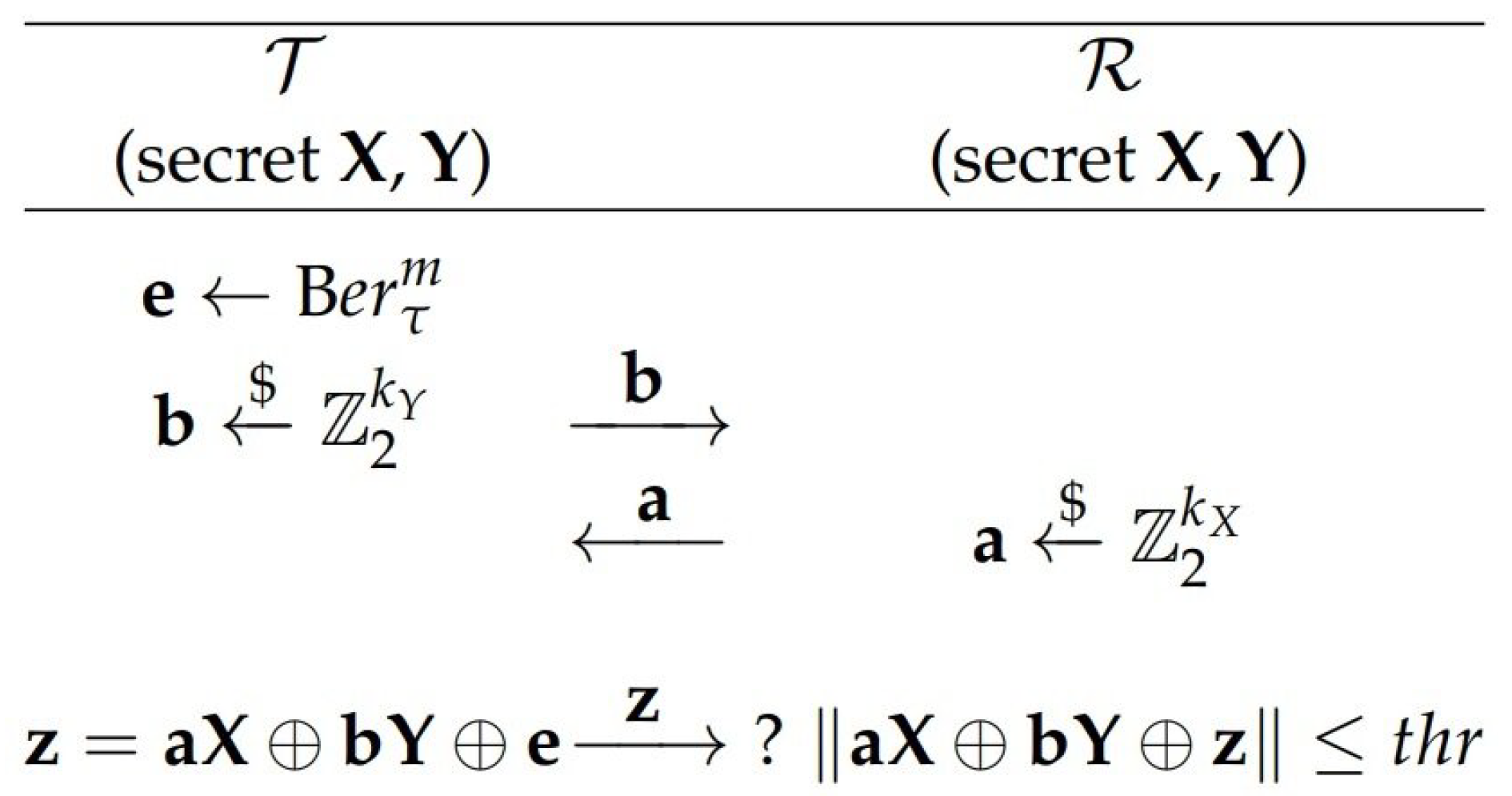
2. Preliminaries
- Variables are denoted with normal, bold or capital bold letters (e.g., x, and ) if they represent single elements, vectors, or matrices, respectively
- : set of all m-dimensional binary vectors
- : set of all -dimensional binary matrices
- : i-th element of binary vector
- : binary vector with all zeros, except on the position i
- : bitwise XOR operation of two binary vectors and
- : the Hamming weight of binary vector (sum of its elements)
- : sampling a value x which follows uniform distribution over a finite set X
- : probability of an event A
- : Bernoulli distribution with parameter . is sampling of value x such that ,
- : Binomial distribution of n experiments with success probability p of each experiment
- : sampling binary vector such that
- : Normal distribution with mean and variance
- : standard normal cumulative distribution function
- : complementary error function
- : sequence of random variables converges weakly (in distribution) to a distribution as
- : probability of acceptance during the OOV attack when the Adversary adds noise vector to a regular noise vector in a protocol session, that is,
- : approximation of used in the OOV attack [12].
- Collects a triplet of messages exchanged between the Tag and the Reader by eavesdropping one of their communication sessions
- Replaces each triplet of messages between the Tag and the Reader during n following communication sessions with a triplet
- Counts the number c of “ACCEPT” decisions of the Reader at the end of those n sessions.
3. Revision of the OOV Attack
3.1. Revision of the Theoretical Analysis behind the OOV Weight Estimate
3.1.1. Incorrect Claim that Cumulative Noise Vector Follows Binomial Distribution
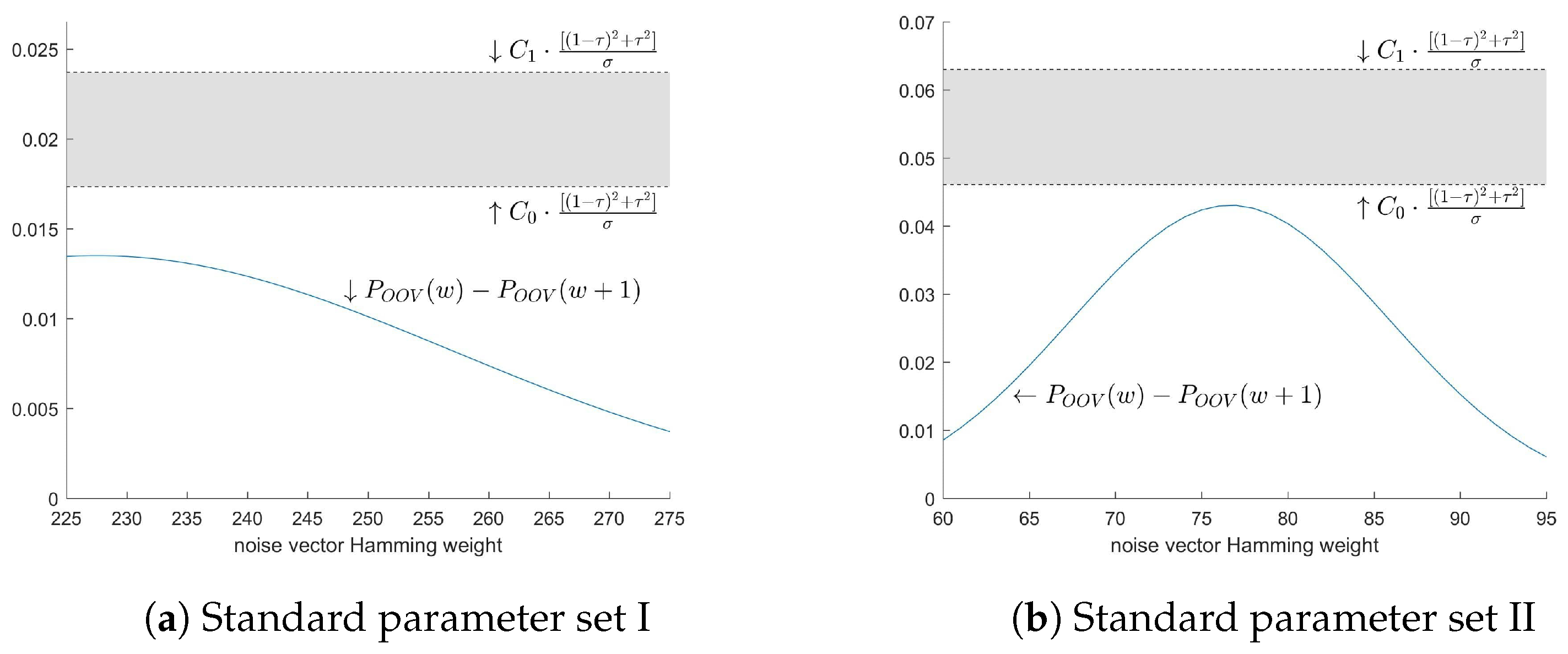
3.1.2. Approximation of Acceptance Rates without Error Estimation
3.1.3. Unknown Error Bound of the Weight Estimate Process
3.1.4. Main Conclusions
- The distribution of the Hamming weight of cumulative noise vector is wrongly assessed as Binomial,
- Approximation lacks error estimation,
- The error of the weight estimate procedure is unknown. Since error bound of is unknown, this consequently also stands for the final approximation which produces the output of weight estimate procedure.
3.2. Error Estimation of Acceptance Rates Approximation
3.2.1. Standard Upper Error Bound for CLT Approximations
3.2.2. The Exact Distribution of the Acceptance Rates
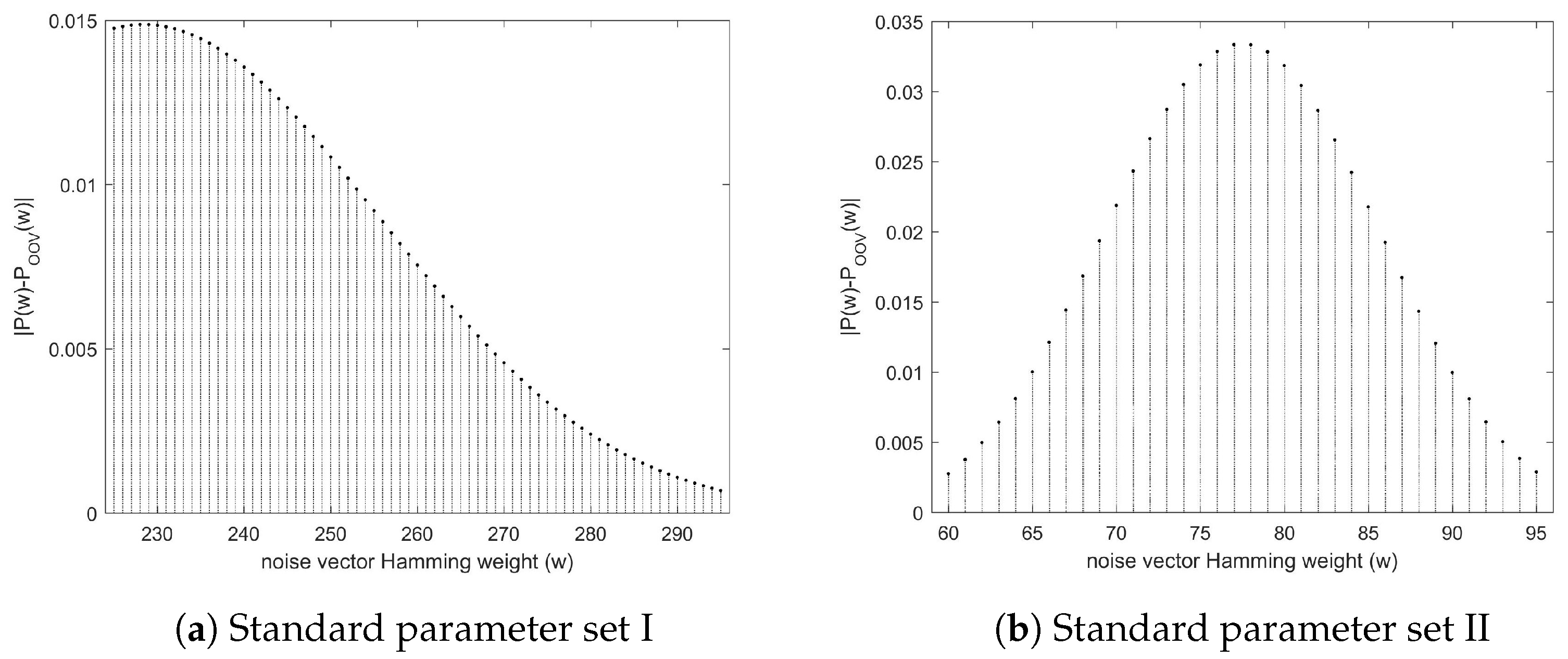
3.2.3. Exact Error of the Approximation
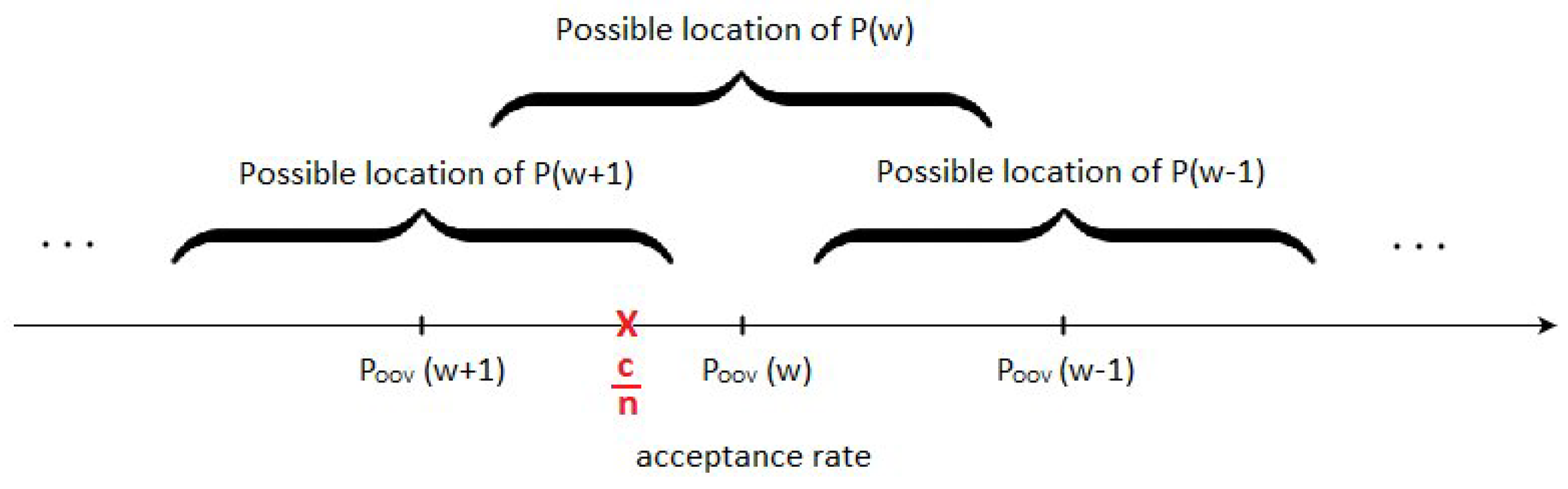
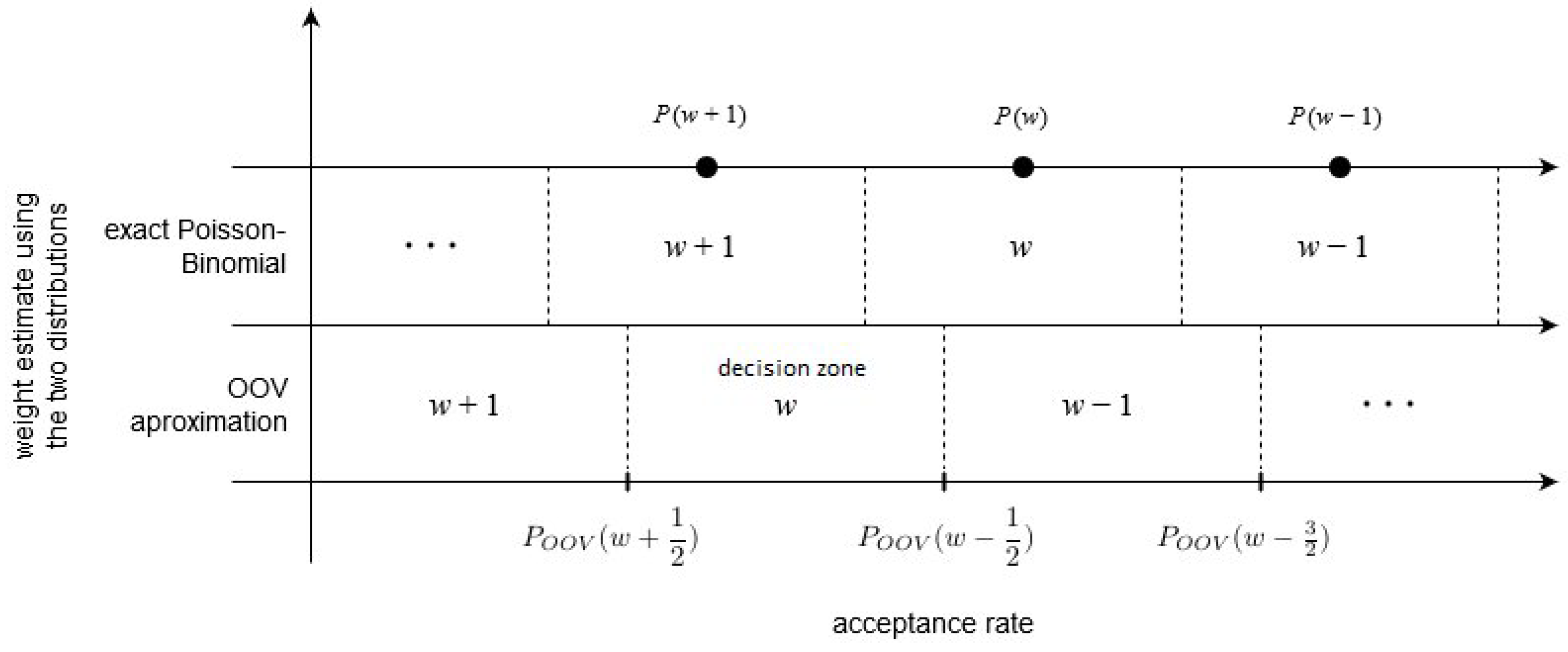
3.3. Proper Decision Zones
- the inverse function might not preserve the ratios of distances, so, for example, it could be possible that is closer to than to , while is actually closer to than to ,
- is used as an approximation of exact acceptance rates P with unknown precision,
- should be determined by considering which of the possible distributions is most likely sampled from, i.e., by probabilistic reasoning, instead of simply applying the inverse function to value.
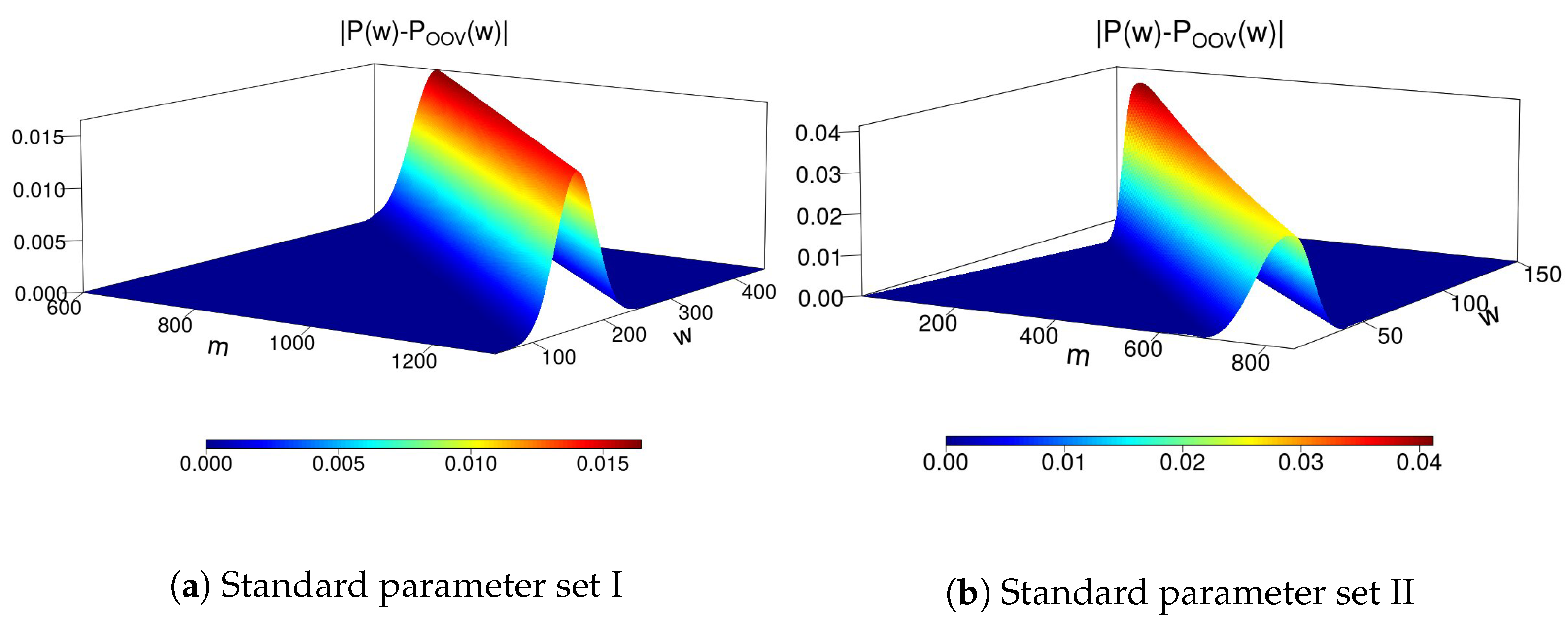
3.4. The Exact and the Approximate Probability Distribution Relation
4. Correction of the OOV Attack
4.1. Correction of the OOV Attack Algorithm
| Algorithm 1PB-OOV weight estimate alg. Approximating |
|
4.2. Comparison of the OOV and PB-OOV Attack Success
4.2.1. Noise Vector Hamming Weight Estimate
4.2.2. Noise Vector Bits Recovery
4.2.3. Secret Keys Recovery Comparison
- -
- whole m-bit noise vectors—which happens with probability ,
- -
- and then the remaining bits, by guessing incorrectly one more noise vector weight, and recovering each one of them—which happens with probability for parameter set II andfor parameter set I, since .
5. Experimental Results and Discussion
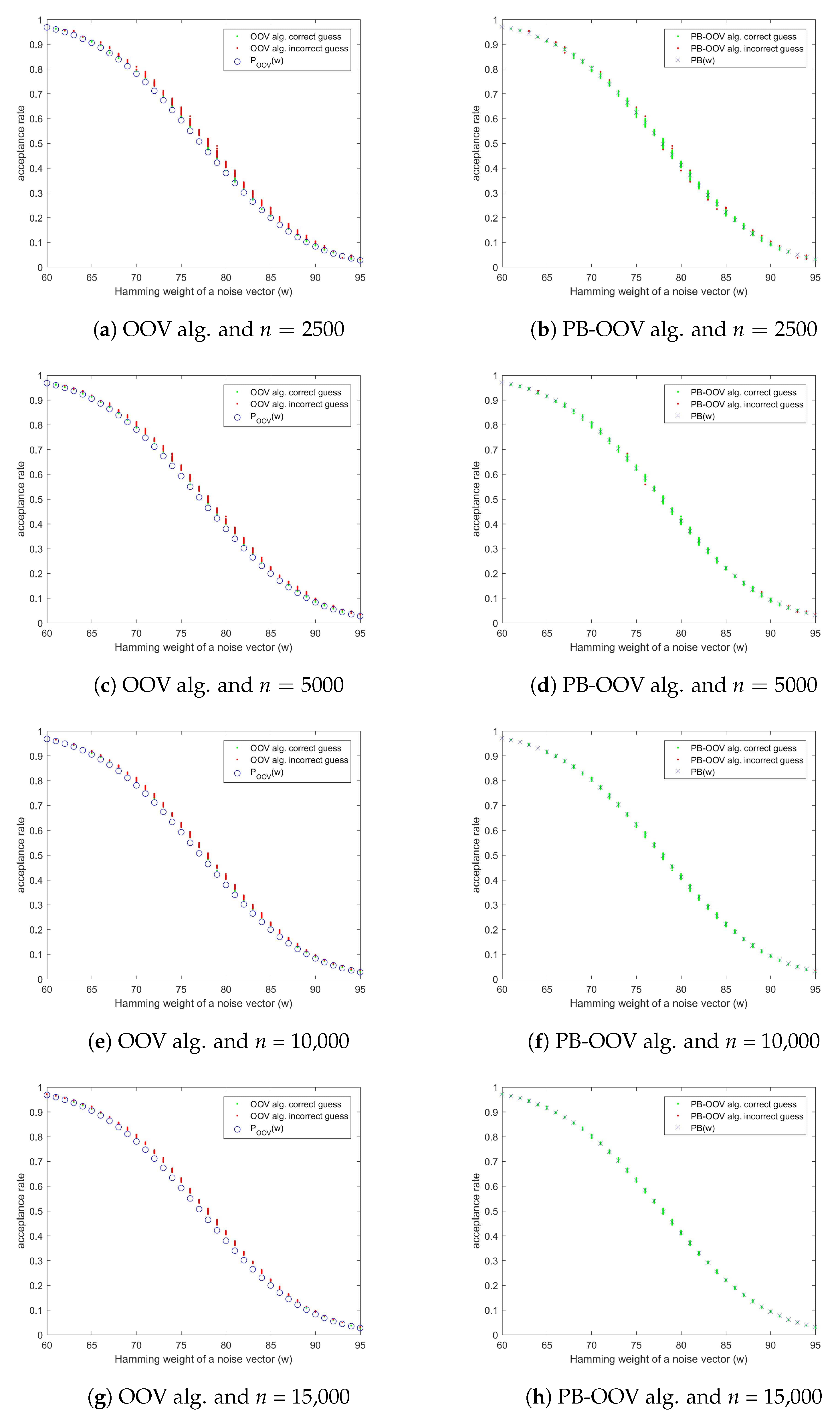
5.1. Evaluation of the Acceptance Rates
5.2. Precision Comparison of the OOV and PB-OOV Weight Estimate: Experimental
5.3. Evaluation of the PB-OOV Attack Precision
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Set I | Parameter Set II | |||
|---|---|---|---|---|
| HB# | Random-HB# | HB# | Random-HB# | |
| 2.401 | 3.308 | 2.265 | 3.164 | |
| 16,780.41 * | 269.39 | |||
| 2742.61 | ||||
| 15,789.60 | 270.95 | |||
| 2743.75 | ||||
| 96,736 | 183,626 | 1382 | 2697 | |
| 15,811 | 30,012 | |||
| 91,024 | 172,783 | 1390 | 2712 | |
| 15,817 | 30,024 | |||
References
- Avoine, G.; Carpent, X.; Hernandez-Castro, J. Pitfalls in ultralightweight authentication protocol designs. IEEE Trans. Mob. Comput. 2015, 15, 2317–2332. [Google Scholar] [CrossRef]
- Baashirah, R.; Abuzneid, A. Survey on prominent RFID authentication protocols for passive tags. Sensors 2018, 18, 3584. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- D’Arco, P. Ultralightweight cryptography. In International Conference on Security for Information Technology and Communications; Springer: Cham, Switzerland, 2018; pp. 1–16. [Google Scholar]
- Hopper, N.J.; Blum, M. Secure Human Identification Protocols. In Advances in Cryptology—ASIACRYPT 2001. ASIACRYPT 2001. Lecture Notes in Computer Science; Boyd, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2248. [Google Scholar]
- Katz, J.; Shin, J.S. Parallel and Concurrent Security of the HB and HB+ Protocols. In Advances in Cryptology—EUROCRYPT 2006. EUROCRYPT 2006. Lecture Notes in Computer Science; Vaudenay, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4004. [Google Scholar]
- Katz, J.; Shin, J.S.; Smith, A. Parallel and concurrent security of the HB and HB+ protocols. J. Cryptol. 2010, 23, 402–421. [Google Scholar] [CrossRef] [Green Version]
- Gilbert, H.; Robshaw, M.; Sibert, H. Active attack against HB+: A provably secure lightweight authentication protocol. Electron. Lett. 2005, 41, 1169–1170. [Google Scholar] [CrossRef] [Green Version]
- Bringer, J.; Chabanne, H.; Dottax, E. HB++: A Lightweight Authentication Protocol Secure against Some Attacks. In Proceedings of the Second International Workshop on Security, Privacy and Trust in Pervasive and Ubiquitous Computing (SecPerU’06), Lyon, France, 29 June 2006; IEEE Computer Society: Washington, DC, USA, 2006; pp. 28–33. [Google Scholar]
- Munilla, J.; Peinado, A. HB-MP: A further step in the HB-family of lightweight authentication protocols. Comput. Netw. 2007, 51, 2262–2267. [Google Scholar] [CrossRef]
- Gilbert, H.; Robshaw, M.J.; Seurin, Y. Good variants of HB+ are hard to find. In Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2008; pp. 156–170. [Google Scholar]
- Gilbert, H.; Robshaw, M.J.B.; Seurin, Y. HB#: Increasing the Security and Efficiency of HB+. In Advances in Cryptology—EUROCRYPT 2008. Lecture Notes in Computer Science; Smart, N., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4965. [Google Scholar]
- Ouafi, K.; Overbeck, R.; Vaudenay, S. On the Security of HB# against a Man-in-the-Middle Attack. In Advances in Cryptology—ASIACRYPT 2008. Lecture Notes in Computer Science; Pieprzyk, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5350. [Google Scholar]
- Leng, X.; Mayes, K.; Markantonakis, K. HB-MP+ protocol: An improvement on the HB-MP protocol. In Proceedings of the 2008 IEEE International Conference on RFID, Las Vegas, NV, USA, 16–17 April 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 118–124. [Google Scholar]
- Yoon, B.; Sung, M.Y.; Yeon, S.; Oh, H.S.; Kwon, Y.; Kim, C.; Kim, K.H. HB-MP++ protocol: An ultra lightweight authentication protocol for RFID system. In Proceedings of the 2009 IEEE International Conference on RFID, Orlando, FL, USA, 27–28 April 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 186–191. [Google Scholar]
- Aseeri, A.; Bamasak, O. HB-MP*: Towards a Man-in-the-Middle-Resistant Protocol of HB Family. In 2nd Mosharaka International Conference on Mobile Computing and Wireless Communications (MIC-MCWC 2011); Mosharaka for Research and Studies: Amman, Jordan, 2011; Volume 2, pp. 49–53. [Google Scholar]
- Bringer, J.; Chabanne, H. Trusted-HB: A low-cost version of HB+ secure against man-in-the-middle attacks. IEEE Trans. Inf. Theory 2008, 54, 4339–4342. [Google Scholar] [CrossRef]
- Madhavan, M.; Thangaraj, A.; Sankarasubramanian, Y.; Viswanathan, K. NLHB: A non-linear HopperBlum protocol. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2498–2502. [Google Scholar]
- Bosley, C.; Haralambiev, K.; Nicolosi, A. HBN: An HB-like protocol secure against man-in-the-middle attacks. IACR Cryptol. ePrint Arch. 2011, 2011, 350. [Google Scholar]
- Rizomiliotis, P.; Gritzalis, S. GHB#: A provably secure HB-like lightweight authentication protocol. In International Conference on Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2012; pp. 489–506. [Google Scholar]
- Hammouri, G.; Öztürk, E.; Birand, B.; Sunar, B. Unclonable lightweight authentication scheme. In International Conference on Information and Communications Security; Springer: Berlin/Heidelberg, Germany, 2008; pp. 33–48. [Google Scholar]
- Hammouri, G.; Sunar, B. PUF-HB: A tamper-resilient HB based authentication protocol. In International Conference on Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2008; pp. 346–365. [Google Scholar]
- Deng, G.; Li, H.; Zhang, Y.; Wang, J. Tree-LSHB+: An LPN-based lightweight mutual authentication RFID protocol. Wirel. Pers. Commun. 2013, 72, 159–174. [Google Scholar] [CrossRef]
- Qian, X.; Liu, X.; Yang, S.; Zuo, C. Security and privacy analysis of tree-LSHB+ protocol. Wirel. Pers. Commun. 2014, 77, 3125–3314. [Google Scholar] [CrossRef]
- Karrothu, A.; Scholar, R.; Norman, J. An analysis of LPN based HB protocols. In Proceedings of the 2016 Eighth International Conference on Advanced Computing (ICoAC), Chennai, India, 19–21 January 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 138–145. [Google Scholar]
- Knežević, M.; Tomović, S.; Mihaljević, M.J. Man-In-The-Middle Attack against Certain Authentication Protocols Revisited: Insights into the Approach and Performances Re-Evaluation. Electronics 2020, 9, 1296. [Google Scholar] [CrossRef]
- Koralov, L.; Sinai, Y.G. Theory of Probability and Random Processes; Springer: Berlin/Heidelberg, Germany, 2007; pp. 131–134. [Google Scholar]
- Shiganov, I.S. Refinement of the upper bound of the constant in the central limit theorem. J. Math. Sci. 1986, 35, 2545–2550, (translated from Stab. Probl. Stoch. Models 1982, 105–115.). [Google Scholar] [CrossRef]
- Shevtsova, I.G. An improvement of convergence rate estimates in the Lyapunov theorem. Dokl. Math. 2010, 82, 862–864. [Google Scholar] [CrossRef]














| Parameter Set | m | ||||
|---|---|---|---|---|---|
| I | 80 | 512 | 1164 | 0.25 | 405 |
| II | 80 | 512 | 441 | 0.125 | 113 |
| Parameter Set I | Parameter Set II | |||
|---|---|---|---|---|
| HB# | Random-HB# | HB# | Random-HB# | |
| claimed precision | 0.999315 | 0.999997 | 0.998641 | 0.999992 |
| real precision | 0.087803 | 0.031017 | 0.038852 | 0.006860 |
| 0.912197 | 0.968983 | 0.961146 | 0.993139 | |
| Parameter Set I | Parameter Set II | |||
|---|---|---|---|---|
| HB# | Random-HB# | HB# | Random-HB# | |
| targeted precision | 0.999315 | 0.999997 | 0.998641 | 0.999992 |
| real precision | 0.999506 | 0.999998 | 0.998641 | 0.999992 |
| Parameter Set I | Parameter Set II | |||
|---|---|---|---|---|
| HB# | Random-HB# | HB# | Random-HB# | |
| claimed precision | 0.999658 | 0.9999986 | 0.999320 | 0.999996 |
| 0.858089 | 0.930114 | 0.764623 | 0.843169 | |
| 0.365592 | 0.317990 | |||
| 0.991712 | 0.999518 | 0.993508 | 0.999740 | |
| 0.999908 | ||||
| 0.999997 | 0.999957 | |||
| 0.998863 | 0.999987 | |||
| Parameter Set I | Parameter Set II | |||
|---|---|---|---|---|
| HB# | Random-HB# | HB# | Random-HB# | |
| claimed precision | 0.670720 | 0.998314 | 0.739967 | 0.998306 |
| 0.245168 | 0.932141 | 0.573019 | 0.973427 | |
| Parameter Set I | Parameter Set II | |||
|---|---|---|---|---|
| HB# | Random-HB# | HB# | Random-HB# | |
| targeted precision | 0.999658 | 0.9999986 | 0.999320 | 0.999996 |
| 0.999623 | 0.9999983 | 0.999345 | 0.999996 | |
| 0.999660 | 0.9999986 | |||
| 0.999874 | 0.9999998 | 0.999351 | 0.999996 | |
| 0.999659 | 0.9999986 | |||
| Parameter Set I | Parameter Set II | |||
|---|---|---|---|---|
| HB# | Random-HB# | HB# | Random-HB# | |
| claimed precision | 0.670720 | 0.998314 | 0.739967 | 0.998306 |
| 0.698279 | 0.998538 | 0.749770 | 0.998443 | |
| HB# | Random-HB# | |
|---|---|---|
| num. tests | 2000 | 25,000 |
| targeted OOV weight est. precision | 0.998641 | 0.999992 |
| experimentally obtained weight est. precision | 0.999 | 1 |
| targeted OOV bit precision | 0.999320 | 0.999996 |
| experimentally obtained avg. bit precision | 0.999342 | 0.999996 |
| experimentally obtained 0-bit precision | 0.999344 | 0.999996 |
| experimentally obtained 1-bit precision | 0.999333 | 0.999995 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tomović, S.; Knežević, M.; Mihaljević, M.J. Analysis and Correction of the Attack against the LPN-Problem Based Authentication Protocols. Mathematics 2021, 9, 573. https://doi.org/10.3390/math9050573
Tomović S, Knežević M, Mihaljević MJ. Analysis and Correction of the Attack against the LPN-Problem Based Authentication Protocols. Mathematics. 2021; 9(5):573. https://doi.org/10.3390/math9050573
Chicago/Turabian StyleTomović, Siniša, Milica Knežević, and Miodrag J. Mihaljević. 2021. "Analysis and Correction of the Attack against the LPN-Problem Based Authentication Protocols" Mathematics 9, no. 5: 573. https://doi.org/10.3390/math9050573
APA StyleTomović, S., Knežević, M., & Mihaljević, M. J. (2021). Analysis and Correction of the Attack against the LPN-Problem Based Authentication Protocols. Mathematics, 9(5), 573. https://doi.org/10.3390/math9050573