
Modeling Recidivism through Bayesian Regression Models and Deep Neural Networks


Abstract
:1. Introduction
2. Background
3. Materials and Methods
3.1. Data Source
3.2. Statistical Models
3.2.1. Logistic Regression Model
3.2.2. Cox Regression Model
3.2.3. Cure Rate Model
3.2.4. Assumtions
3.3. Bayesian Analysis
3.4. Predictive Models: Deep Neural Networks and Random Survival Forest
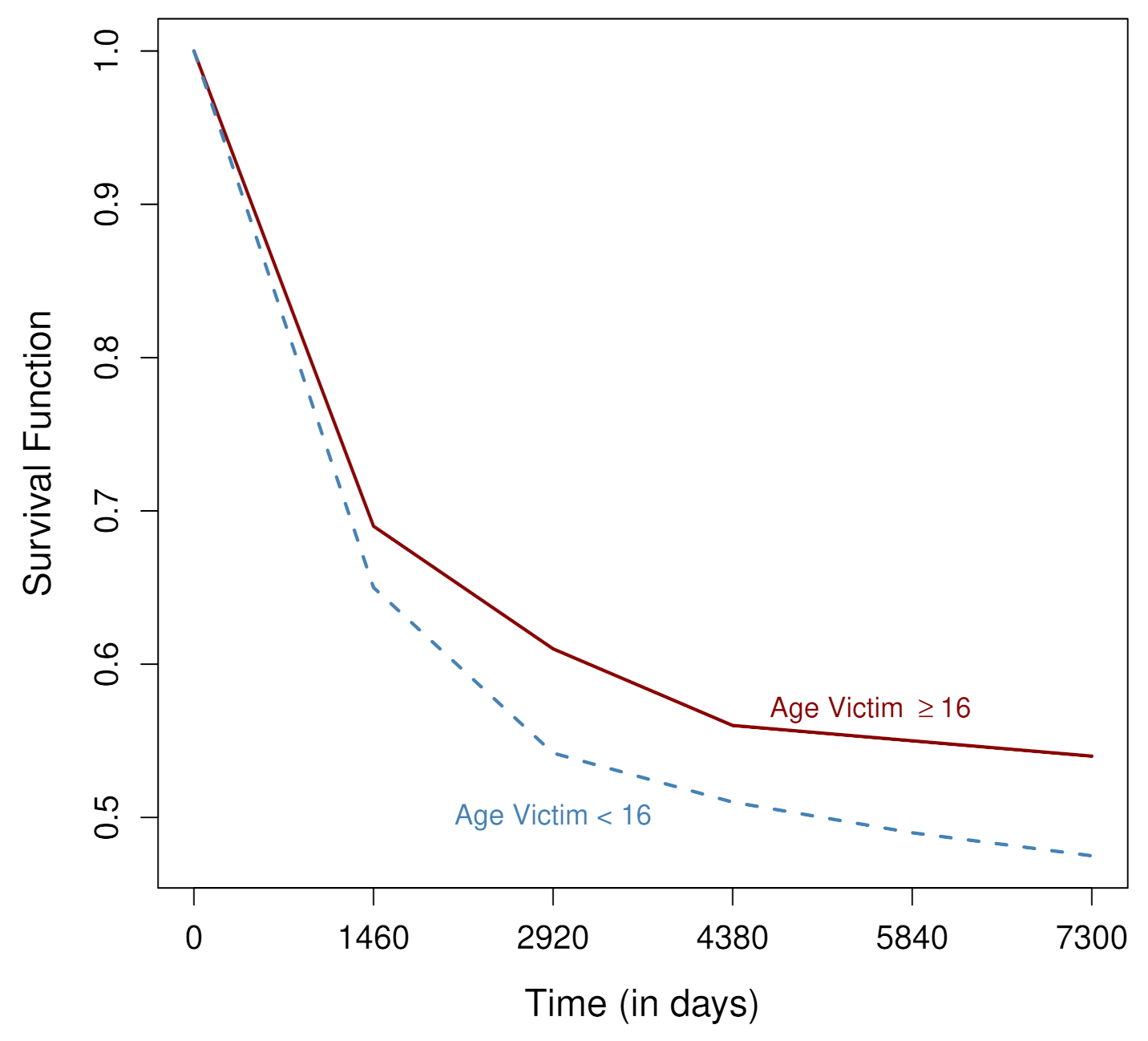
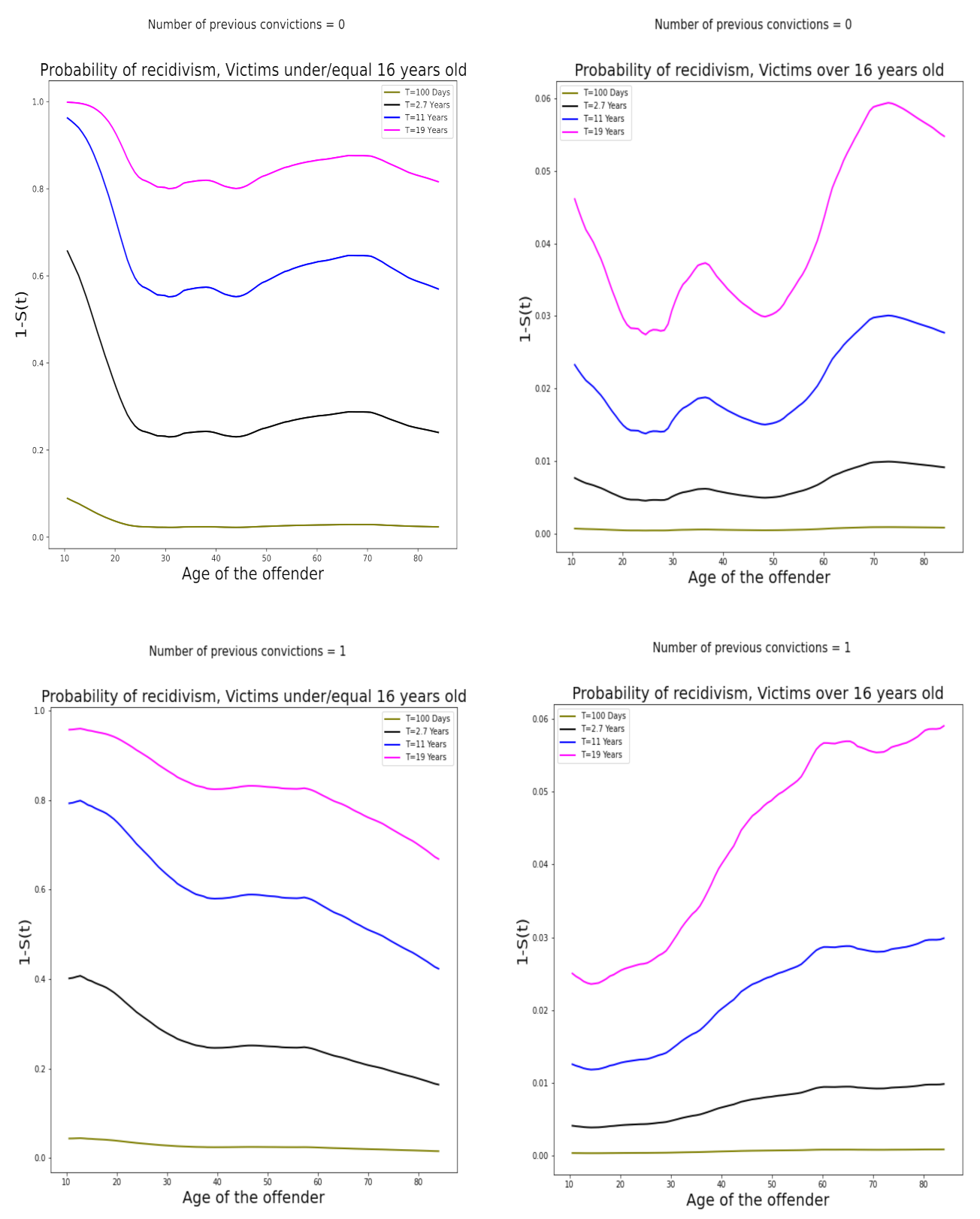
4. Results and Discussion
4.1. Statistical Models
4.2. Prediction Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ross, S.; Guarnieri, T. Recidivism Rates in a Custodial Population: The Influence of Criminal History, Offence & Gender Factors. Available online: https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.421.3985&rank=1 (accessed on 11 November 2020).
- Gensheimer, M.F.; Narasimhan, B. A scalable discrete-time survival model for neural networks. PeerJ 2019, 7, e6257. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.W.; Lee, S.; Kwon, S.; Nam, W.; Cha, I.H.; Kim, H.J. Deep learning-based survival prediction of oral cancer patients. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Katzman, J.L.; Shaham, U.; Cloninger, A.; Bates, J.; Jiang, T.; Kluger, Y. DeepSurv: Personalized treatment recommender system using a Cox proportional hazards deep neural network. BMC Med. Res. Methodol. 2008, 18, 24. [Google Scholar] [CrossRef] [PubMed]
- Hoffman, P.B.; Stone-Meierhoefer, B. Reporting recidivism rates: The criterion and follow-up issues. J. Crim. Justice 1980, 8, 53–60. [Google Scholar] [CrossRef]
- Beck, A.J.; Shipley, B.E. Recidivism of Prisoners Released in 1983. Available online: https://www.bjs.gov/content/pub/pdf/rpr83.pdf (accessed on 17 June 2020).
- Gendreau, P.; Little, T.; Goggin, C. A Meta-analysis of the predictors of adult offender recidivism: What works! Criminology 1996, 34, 575–608. [Google Scholar] [CrossRef]
- Piquero, A.R. Assessing the relationships between gender, chronicity, seriousness, and offense skewness in criminal offending. J. Crim. Justice 2000, 28, 103–115. [Google Scholar] [CrossRef]
- Andrews, D.A. Recidivism is predictable and can be influenced: Using risk assessment to reduce recidivism. IARCA 1989, 1, 11–17. [Google Scholar]
- Hanson, R.K.; Bussiere, M.T. Predicting relapse: A meta-analysis of sexual offender recidivism studies. J. Consult. Clin. Psychol. 1998, 66, 348–362. [Google Scholar] [CrossRef]
- Schmidt, P.; Dryden, W.A. Predicting Criminal Recidivism using ‘Split Population’ Survival Time Models. J. Econom. 1989, 40, 141–159. [Google Scholar] [CrossRef] [Green Version]
- Barton, R.R.; Turnbull, B.W. A failure rate regression model for the study of recidivism. In Models in Quantitative Criminology; Fox, J.A., Ed.; Academic Press: New York, NY, USA, 1981. [Google Scholar]
- Schell, T.L.; Chan, K.S.; Morral, A.R. Predicting DUI recidivism: Personality, attitudinal, and behavioral risk factors. Drug Alcohol Depend. 2006, 82, 33–40. [Google Scholar] [CrossRef]
- Bierens, H.J.; Carvalho, J.R. Semi-Nonparametric Competing Risks Analysis of Recidivism. J. Appl. Econ. 2007, 22, 971–993. [Google Scholar] [CrossRef] [Green Version]
- Padilla, O.; De la Cruz, R. Bayesian split-population models for estimating recidivism. Chil. J. Stat. 2021, in press. [Google Scholar]
- Escarela, G.; Francis, B.; Soothill, K. Competing Risks, Persistence, and Desistance in Analyzing Recidivism. J. Quant. Criminol. 2000, 16, 385–414. [Google Scholar] [CrossRef]
- Hosmer, D.; Lemeshow, S. Applied Logistic Regression, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]
- Marshall, G.; Shroyer, A.L.W.; Grover, F.L.; Hammermeister, K.E. Bayesian-logit model for risk assessment in coronary artery bypass grafting. Ann. Thorac. Surg. 1994, 57, 1492–1500. [Google Scholar] [CrossRef]
- Ntzoufras, I. Bayesian Modeling Using Winbugs, 1st ed.; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar]
- Congdon, P. Applied Bayesian Modelling, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2014. [Google Scholar]
- Maller, R.; Zhou, X.S. Survival Analysis with Long—Term Survivors; John Wiley & Sons: New York, NY, USA, 1996. [Google Scholar]
- Ibrahim, J.G.; Chen, M.H.; Sinha, D. Bayesian Survival Analysis; Springer: New York, NY, USA, 2005. [Google Scholar]
- Martin, A.; Kevin, M.; Quinn, K.; Hee-Park, J. Markov Chain Monte Carlo in R. J. Stat. Softw. 2011, 42, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Raftery, A.; Hoeting, J.; Volinsky, C.; Painter, I.; Yee Yeung, K. BMA: Package for Bayesian Model Averaging and Variable Selection for Linear Models, Generalized Linear Models and Survival Models. R Package Version 3.18.14. Available online: https://cran.r-project.org/web/packages/BMA/BMA.pdf (accessed on 23 January 2021).
- Plummer, M. rjags: Bayesian Graphical Models Using MCMC. R Package Version 3-10. Available online: https://cran.r-project.org/web/packages/rjags/rjags.pdf (accessed on 23 January 2021).
- Faraggi, D.; Simon, R. A neural network model for survival data. Stat. Med. 1995, 14, 73–82. [Google Scholar] [CrossRef]
- Xiang, A.; Lapuerta, P.; Ryutov, A.; Buckley, J.; Azen, S. Comparison of the performance of neural network methods and Cox regression for censored survival data. Comput. Stat. Data Anal. 2001, 34, 243–257. [Google Scholar] [CrossRef]
- Sargent, D.J. Comparison of artificial neural networks with other statistical approaches. Cancer 2001, 91, 1636–1642. [Google Scholar] [CrossRef]
- Harrell, F.E.; Califf, R.M.; Pryor, D.B.; Lee, K.L.; Rosati, R.A. Evaluating the yield of medical tests. JAMA 1982, 247, 2543–2546. [Google Scholar] [CrossRef]
- Ishwaran, H.; Kogalur, U.B.; Blackstone, E.H.; Lauer, M.S. Random survival forests. Ann. Appl. Stat. 2008, 2, 841–860. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2018, 15, 1929–1958. [Google Scholar]
- Huang, Z.; Johnson, T.S.; Han, Z.; Helm, B.; Cao, S.; Zhang, C.; Salama, P.; Rizkalla, M.; Yu, C.Y.; Cheng, J.; et al. Deep learning-based cancer survival prognosis from RNA-seq data: Approaches and evaluations. BMC Med. Genom. 2020, 13, 41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Street, W.N. A Neural Network Model for Prognostic Prediction. In Proceedings of the International Conference on Machine Learning (ICML), Madison, WI, USA, 24–27 July 1998; pp. 540–546. [Google Scholar]
- Palocsay, S.W.; Wang, P.; Brookshire, R.G. Predicting criminal recidivism using neural networks. Socio-Econ. Plan. Sci. 2000, 34, 271–284. [Google Scholar] [CrossRef]
- Tollenaar, N.; Van Der Heijden, P.G. Optimizing predictive performance of criminal recidivism models using registration data with binary and survival outcome. PLoS ONE 2019, 14, e0213245. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Freitas, A.A. Comprehensible classification models: A position paper. ACM SIGKDD Explor. Newsl. 2014, 15, 1–10. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Variable | Parameter | 95% Credible Interval | ||
|---|---|---|---|---|
| Probability of Recidivism | Intercept | 0.573 | 0.357 | 0.794 |
| NP | 0.532 | 0.459 | 0.611 | |
| NPS | 0.167 | −0.064 | 0.416 | |
| AGE | −0.405 | −0.466 | −0.344 | |
| Av_u16 | 0.314 | 0.135 | 0.493 | |
| Temporal | Intercept | 0.665 | −1.079 | 2.434 |
| NP | 1.097 | 0.867 | 1.318 | |
| NPS | −0.786 | −1.842 | 0.147 | |
| AGE | −1.614 | −2.251 | −1.015 | |
| Av_u16 | 0.061 | −1.189 | 1.345 | |
| Real | Logistic Regression | Cox Regression Model | Cure Rate Model (Weibull) | |
|---|---|---|---|---|
| Recidivism general | 51.9 | 52 | 47.8 | 52.6 |
| Recidivism at 10 years | 47.5 | 47.3 | 47.7 | 48.1 |
| Recidivism at 3 years | 33.4 | 33.3 | 33.3 | 31.7 |
| Recidivism by groups at 10 years | ||||
| NP = 0 | 33.1 | 35.9 | 40 | 36.8 |
| NP = 5 | 89.9 | 86 | 74.4 | 86.2 |
| NPS = 0 | 45.4 | 47.4 | 47.3 | 47.9 |
| NPS > 0 | 66 | 63.4 | 60.7 | 66.5 |
| AGE < 25 | 59.1 | 57.3 | 58.9 | 58.7 |
| AGE > 35 | 29.5 | 27.9 | 27.2 | 27.6 |
| Recidivism by groups at 3 years | ||||
| NP = 0 | 21.4 | 24.8 | 26.4 | 22.5 |
| NP = 5 | 59.4 | 63.2 | 57.3 | 63.6 |
| NPS = 0 | 31.9 | 33.3 | 32.9 | 31.8 |
| NPS > 0 | 46.7 | 45.4 | 45.5 | 44.6 |
| AGE < 25 | 44.1 | 42.1 | 41.8 | 39.8 |
| AGE > 35 | 17.8 | 16.9 | 17.7 | 16.2 |
| Model | Train Set | Test Set |
|---|---|---|
| CPH | 0.696 (0.690, 0.701) | 0.693 (0.669, 0.716) |
| RSF | 0.749 (0.745, 0.754) | 0.687 (0.665, 0.708) |
| DeepSurv | 0.800 (0.793, 0.806) | 0.789 (0.774, 0.800) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de la Cruz, R.; Padilla, O.; Valle, M.A.; Ruz, G.A. Modeling Recidivism through Bayesian Regression Models and Deep Neural Networks. Mathematics 2021, 9, 639. https://doi.org/10.3390/math9060639
de la Cruz R, Padilla O, Valle MA, Ruz GA. Modeling Recidivism through Bayesian Regression Models and Deep Neural Networks. Mathematics. 2021; 9(6):639. https://doi.org/10.3390/math9060639
Chicago/Turabian Stylede la Cruz, Rolando, Oslando Padilla, Mauricio A. Valle, and Gonzalo A. Ruz. 2021. "Modeling Recidivism through Bayesian Regression Models and Deep Neural Networks" Mathematics 9, no. 6: 639. https://doi.org/10.3390/math9060639
APA Stylede la Cruz, R., Padilla, O., Valle, M. A., & Ruz, G. A. (2021). Modeling Recidivism through Bayesian Regression Models and Deep Neural Networks. Mathematics, 9(6), 639. https://doi.org/10.3390/math9060639