In order to validate research hypotheses (the relationship between socioeconomic factors and crude birth rate), comparisons among income groups and bivariate correlation analysis between the independent variables were in the first instance used in the current paper. Comparisons among groups were made by p-value (one-way analysis of variance for normally distributed data or Kruskal–Wallis test for non-normally distributed data).
Of the three variables analyzed, only female mean BMI follows approximately a normal distribution, which is why in order to compare the world countries over the four income groups we used unifactorial ANOVA (Fisher), and the result was F(3.167) = 22.755, p < 0.001. For female alcohol consumption per capita and cigarette consumption per capita, variables that do not follow normal distributions, we used the non-parametric Kruskal–Wallis test (H(3) = 59.398 for female alcohol consumption per capita and H(3) = 37.382 for cigarette consumption, both with p < 0.001). Comparing the averages of the three independent variables for each income group, we immediately notice that at least two categories differ significantly in terms of the average values of the three independent variables studied (p < 0.001 for each variable).
Next, to see which pairs differed significantly, we had to carry out post hoc tests to compare all income groups with each other for all three independent variables in the model. For each pair of groups, we only added significant differences to the table (p < 0.01).
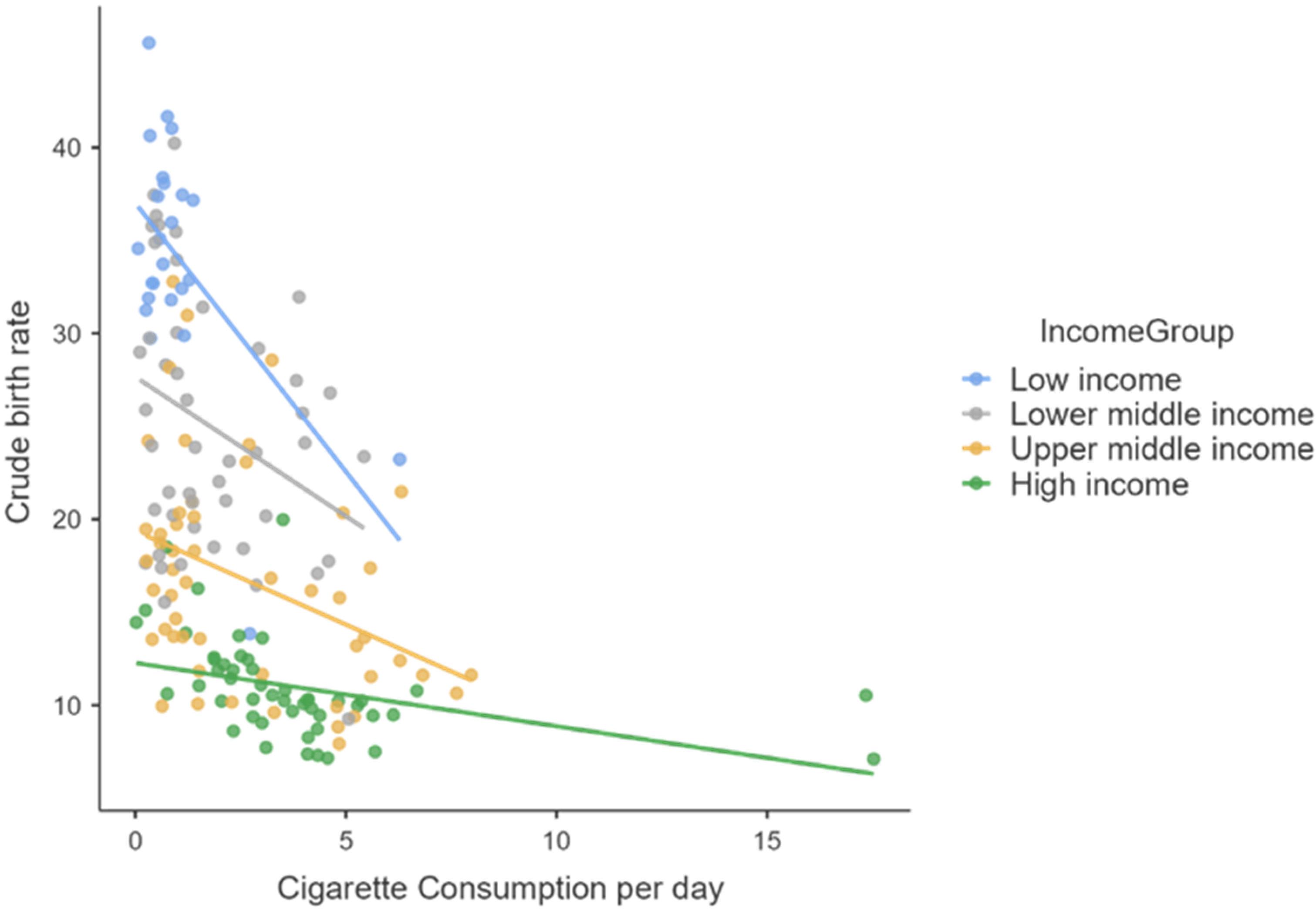
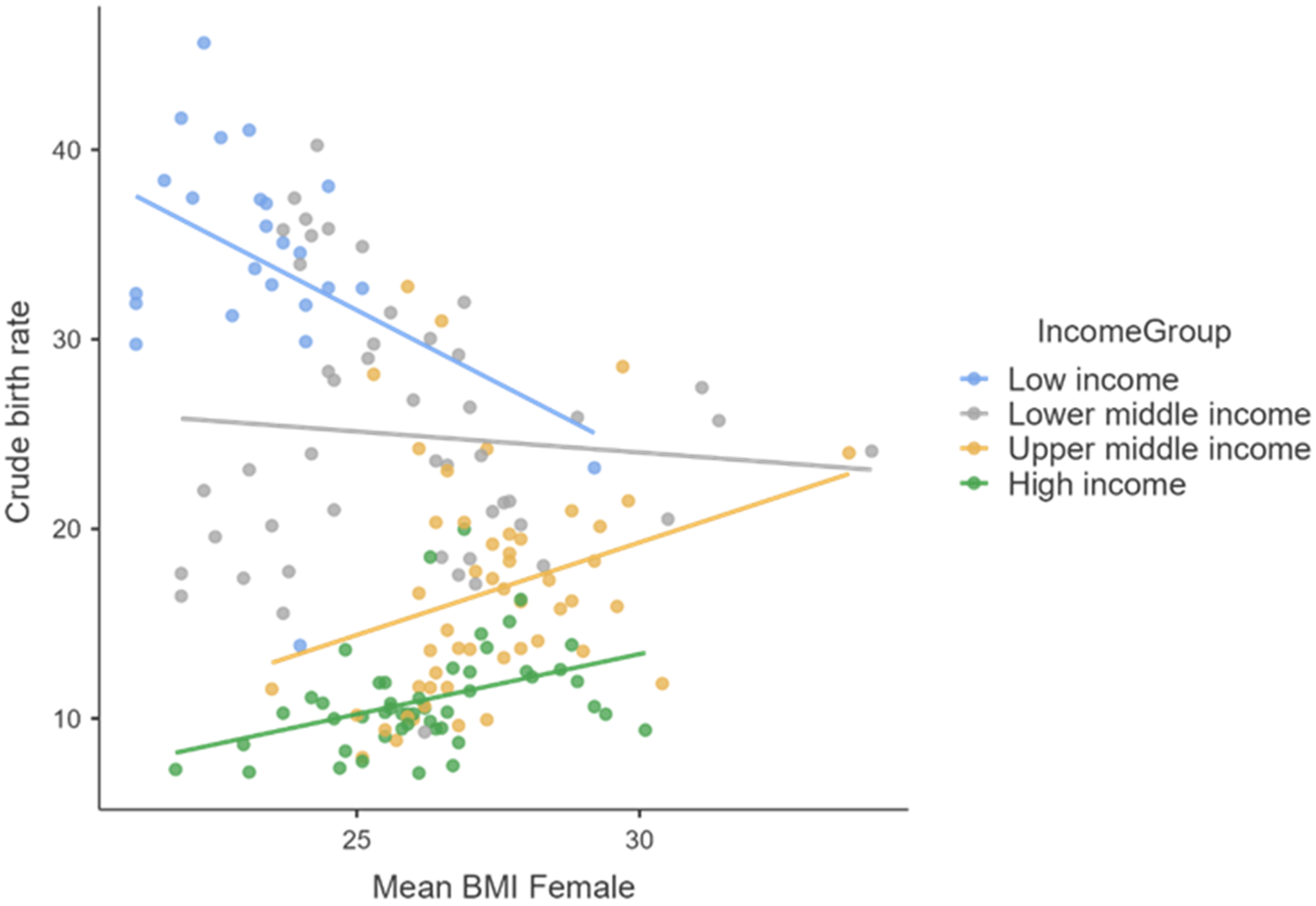
Next, to verify the correlation between the dependent variable (Birth rate) and each of the three predictors, for all the four income groups considered, we used Spearman’s or Kendall’s (only for the “low-income” small data set) correlation coefficients, because our data violated parametric assumptions as non-normally distributed data. In the “low-income” countries case we observe a negative correlation of the crude birth rate with BMI-female, and for “lower middle income” countries also a negative correlation with the average amount of cigarettes smoked in a day by one person, both statistically significant. For countries in higher income categories, the gross birth rate is negatively correlated with cigarette and alcohol consumption and positively correlated with BMI Female (all statistically significant).
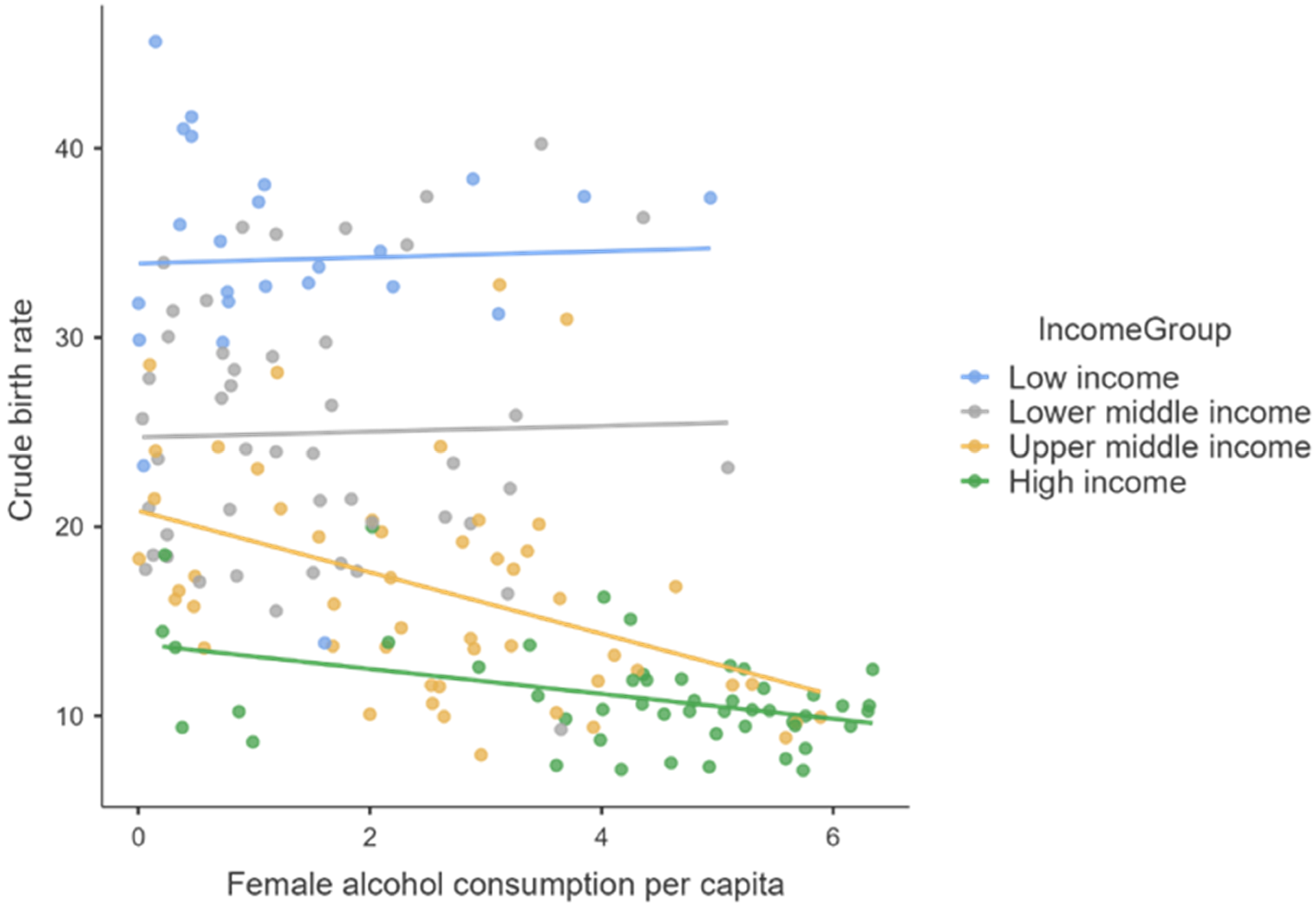
Regarding the influence of women’s alcohol consumption on female fertility, there is a statistically significant negative influence of the increase in alcohol consumption for middle- and high-income countries and the absence of any correlation in the situation of low-income countries, probably due to extremely low alcohol consumption and cigarettes that appear in official statistical reports (official bans on their consumption, unfavorable climate, lack of material possibilities to purchase them, and statistical reports with low fidelity).
The influence of mean female body weight (highlighted by the average BMI index) on female fertility takes place in opposite directions for the four major categories of countries by income level. Thus, in the case of the countries from the two upper-income categories, we observe a direct and intense correlation of BMI on the crude birth rate, in the case of the countries with the lowest incomes a negative correlation of medium intensity, while in the case of small- to medium-income countries we notice the absence of any correlation.
Regression Model
The dependent variable (Crude birth rate) is quantitative and each independent variable used in the model is also quantitative or dichotomous. The variable “Income level” was transformed into a dummy variable, which records the value 0 for countries with average per capita income below the global average level in 2019 (median GNI per capita in current USD = 6180) and the value 1 for countries with an average per capita income value above the median value.
Regarding sample size, Samuel B. Green (1991) suggests two rules of thumb for the minimum acceptable sample size, the first to test the overall fit of the regression model (R
2 value), and the second based on testing the individual predictors within the model (b-values of the model). In this case, to test the model overall, the recommended minimum sample size is 50 + 8 × k = 50 + 8 × 4 = 82 and to test the individual predictors, Green suggests a minimum sample size of 104 + k = 108 (where k is the number of predictors, in our study 3) [
11]. Our data contain 171 cases, without any missing observation, so the minimum sample size condition was met (171 > 104).
First, we needed to use a matrix of the correlation coefficients for all the variables in the model and also mark the significance value of each correlation (*
p < 0.05, **
p < 0.01 and ***
p < 0.001). It is immediately noticeable that the crude birth rate is negatively related to income level (−0.670), cigarette consumption per day (−0.480), female alcohol consumption per capita (−0.548), and female mean BMI (−0.318), the significance level being less than 0.01 for all (
Table 4). This significance value tells us that the probability of obtaining a correlation coefficient this big in a sample of 171 countries if the null hypothesis were true (there was no relationship between these variables) is very low.
A multiple linear regression was carried out to ascertain the extent to which income levels (bellow and above median), mean female BMI, female alcohol consumption per capita, and cigarette consumption per day per capita can predict the dependent variable—crude birth rate (
Table 5). For performing the regression analysis, using the stepwise method, we used an initial model that contains only the constant and then the computer searches for the predictor (out of the ones available) that best predicts the outcome variable (has the highest simple correlation with the dependent variable). If this predictor significantly improves the ability of the model to predict the outcome, then this predictor is retained in the model and the computer searches for a second predictor (the variable that has the largest semi-partial correlation with the outcome) and so on. Each time a predictor is added to the equation, a removal test is made of the least useful predictor.
If the first version of our model contains only the first predictor (income level) that has the highest simple correlation with the dependent variable, by using the stepwise method, the final model contains four independent variables, valid for the crude birth rate prediction: income level, cigarette consumption per day, female mean BMI, and female alcohol consumption per capita per year. The fourth model presented in our study had a value of 0.777 for the multiple regression coefficients (R), which grew steadily since the introduction of each predictor, starting with the level of income per capita and ending with female alcohol consumption per capita, in the fourth step. When we used only the level of income per capita as a predictor, the simple correlation with the crude birth rate, our dependent variable was 0.670, as it appeared previously in the matrix of correlation coefficients (
Table 4). To measure how much of the variability in the outcome is accounted for by the predictors, we used the value of R
2. For the first model its value was 0.449, which means that level of income per capita accounts for 44.9% of the variation in crude birth rate. When the other three predictors were also included in the model, this value increased to 0.604 or 60.4% of the variance in crude birth rate. Therefore, if the level of income per capita accounts for 44.9%, we can tell that cigarette consumption per day, female mean BMI, and female alcohol consumption per capita account for an additional 15.5% of the variance in crude birth rate.
The fourth version of the model is the best, having an R of 0.777, R2 of 0.604, adjusted R2 of 0.594, and a standard estimated error of 6.130. As it can be observed, the value of R (0.777) proves a strong correlation between the level of fertility and the four independent variables (income level, cigarette consumption per day, mean female BMI, and female alcohol consumption per capita per year). The values of R2 (0.604) and adjusted R2 (0.594) indicate a high proportion of variation in the dependent variable explained by the regression model (about 60%).
The difference between adjusted R
2 and R
2 shows us how well our model generalizes. In our final model, the difference between the values is 0.01 (about 1%), meaning that if the model were derived from the entire world population rather than a sample (171 countries in our case), it would account for approximately 1% less variance in the outcome. To check the cross-validity predictive power of the model or how the statistical analysis results will generalize to an independent data set, we used the Stein formula [
12]:
where n is sample size (171), k is the number of predictors (4), and R
2 is the unadjusted value (0.604).
The value of
is very close to the observed value of R
2 (0.604), indicating that the cross-validity of our model is very good. Next, in
Table 6 are presented the results of the ANOVA for the regression model (
Table 6), which tests whether the model is a significant fit of the data overall (
p value less than 0.05).
For all the models from one to four, the p values are 0, therefore the dependent variable (birth rate) is explained through the action of the independent variables. The fourth model is the most appropriate one. For this model, the analysis indicates that the sum of squares for regression is higher than the sum of squared residuals (9495.202 > 6236.942). Therefore, the model explains an important part of the variation in the dependent variable. Still, the value of the test significance F (p = 0.000 < 0.01) indicates that the independent variables largely explain the variation in the dependent variable.
The
p values associated to the regression coefficients for the explicative variables: income level, cigarette consumption per day, female mean BMI, and female alcohol consumption per capita per year are lower than the significance level 0.05 considered, which means that the estimated coefficients are significant for the world population (
Table 7).
Therefore, the equation of the regression model is the following:
Each B-coefficient indicates the average decrease in birth rate associated with a one-unit increase in a predictor, because they are all negative. Thus, for income level (which is “0” for countries below median level and “1” for those above), the only possible one-unit increase is from below “0” to above “1”. Therefore, B = −8.645 simply means that the average birth rate for countries above the median income is lower with 8.645% compared to the birth rate in countries below the median income. On the other hand, one extra cigarette smoked a day reduces the gross birth rate by 1%. The increase in mean female BMI by one-unit results in a decrease in the crude birth rate by approximately 0.8%. Finally, an increase of 1 L in the average amount of pure alcohol consumed annually by a woman (aged 15 and over) results in a 1% decrease in the crude birth rate, an effect relatively similar to that of an extra cigarette smoked per day by a person (male or female) aged 15 and over, as we have seen before. The variation of the crude birth rate is negatively affected by all four predictors considered in the model. Testing multicollinearity is important for checking correlations between independent variables of the regression model.
Tolerance is a useful indicator in testing the multicollinearity of independent variables. Multicollinearity is indicated by tolerance values close to 0. Since we do not have this situation for the variables of the model presented (all tolerance values are above 0.643), we can state that there is no multicollinearity between variables. In the case of VIF (variance inflation factor), a multicollinearity problem would be signaled by values of over 5 or even 10. Simple arithmetic mean of the four VIF’s calculated for our model is equal to 1.372, a value that is very close to 1 and once again confirms that collinearity is not a problem for our model.
Other measures that are useful in discovering whether predictors are dependent are the eigenvalues of the scaled, uncentred cross-products matrix; the condition indexes; and the variance proportions. The variance proportions vary between 0 and 1, and for each predictor it should be distributed across different dimensions (or eigenvalues). For our model, we can see that each predictor has most of its variance loading onto a different dimension (income has 48% of variance of the regression coefficient on dimension 2, cigarette consumption has 83% of variance on dimension 3, female BMI has 99% of variance on dimension 5, and female alcohol consumption has 89% of variance on dimension 4).
In the case of condition indices, values over 15, which may suggest collinearity issues, are on dimension 5 (condition index = 33.787). Still, variance proportions do not indicate multicollinearity issues, because only one predictor (female BMI) has 99% of variance on dimension 5, while the other three predictors have most of their variance distributed on another dimension.
The serial correlations between errors (autocorrelation assumption) were tested with the Durbin–Watson test.
From the output we can see that the test statistic is 1.998 (very close to 2) and the corresponding
p-value is 0.996. Since this
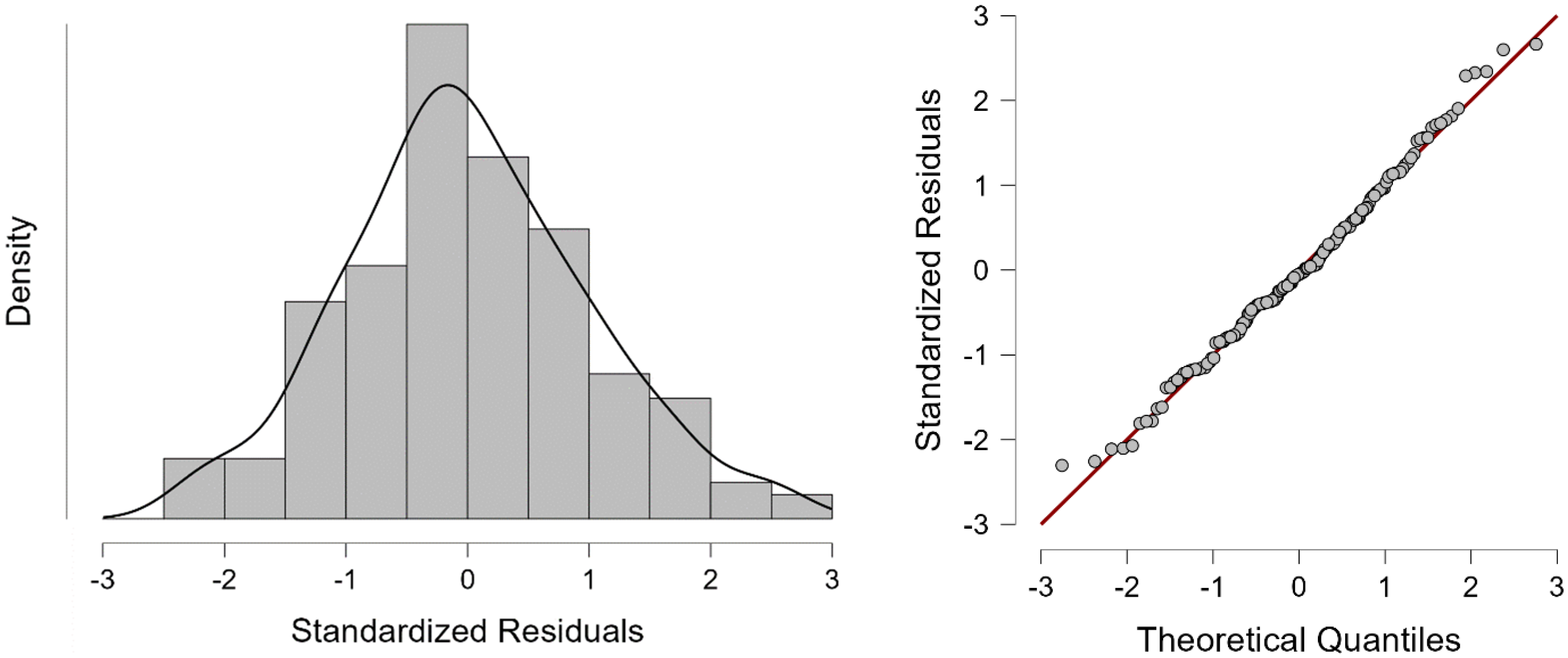
p-value is far above 0.05, we cannot reject the null hypothesis, according to which there is no correlation among the residuals. To test the normality of residuals, we must analyze the histogram and normal Q-Q plot of residuals (
Figure 4).
In the case of our model, the histogram of standardized residuals looks like a normal distribution (almost a bell-shaped curve) and the Quantile−Quantile plot of the standardized residuals is almost a straight line, suggesting that the residuals are normally distributed. Thus, the multiple regression model does not seem to violate the normality assumptions significantly.










{kind=link}
{kind=link}
{kind=link}
{kind=link}