
Text Mining and Determinants of Sentiments towards the COVID-19 Vaccine Booster of Twitter Users in Malaysia


Abstract
:1. Introduction
Related Works
2. Materials and Methods
2.1. Dataset with Sentiment Extracts
2.2. Topic Modelling with LDA
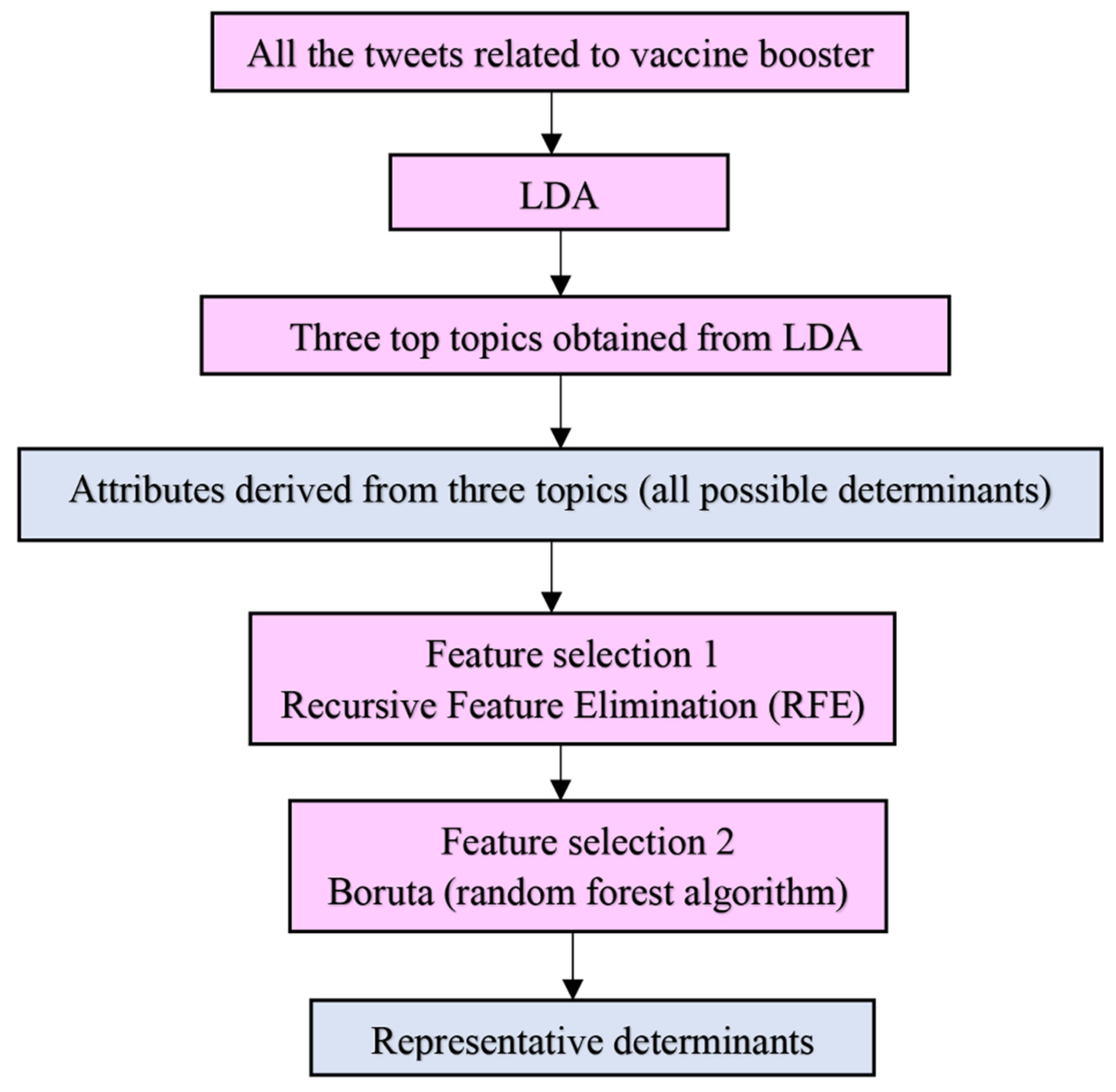
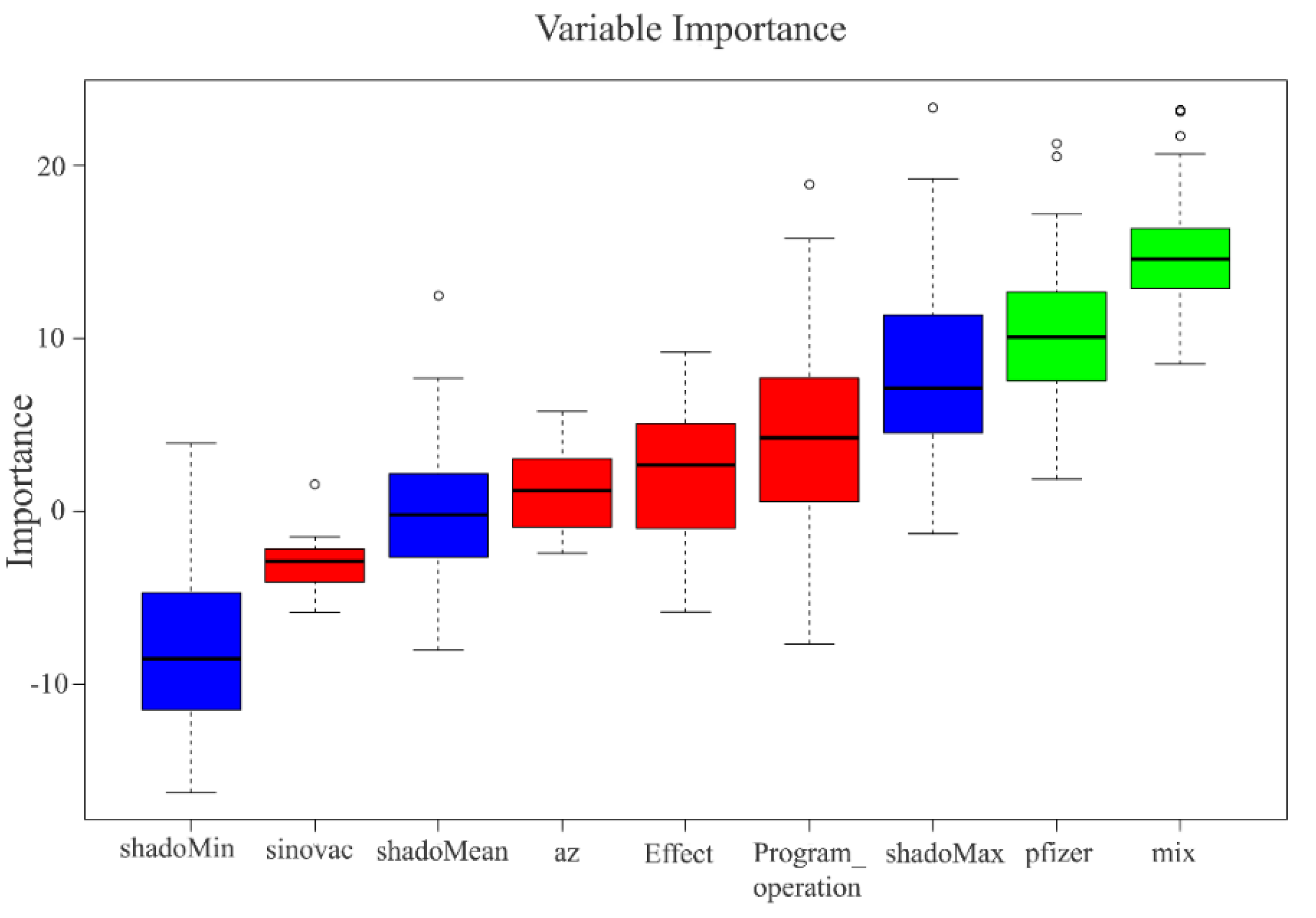
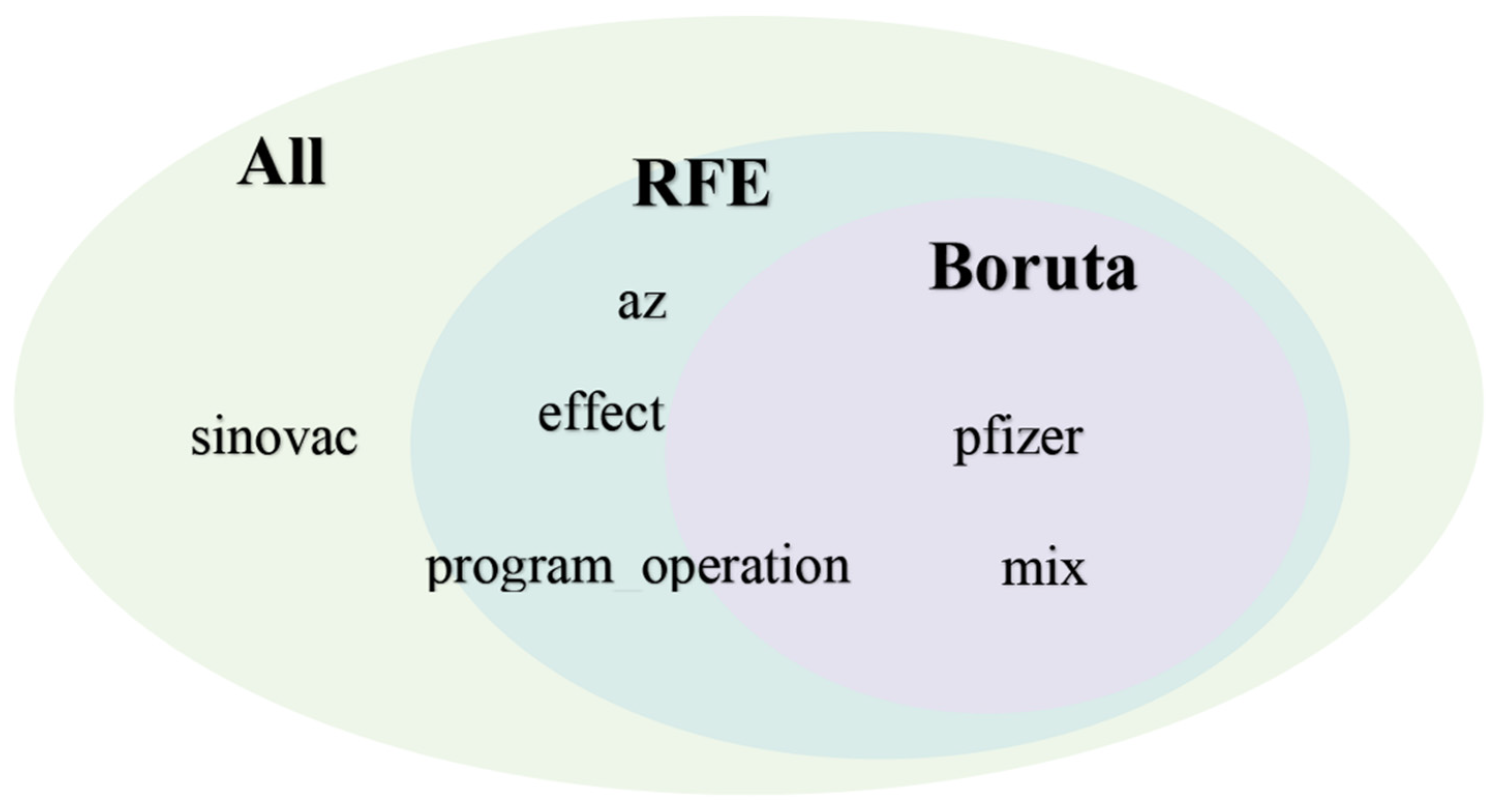
2.3. Feature Selection
2.4. Sentiment Determinant Association Study
3. Results
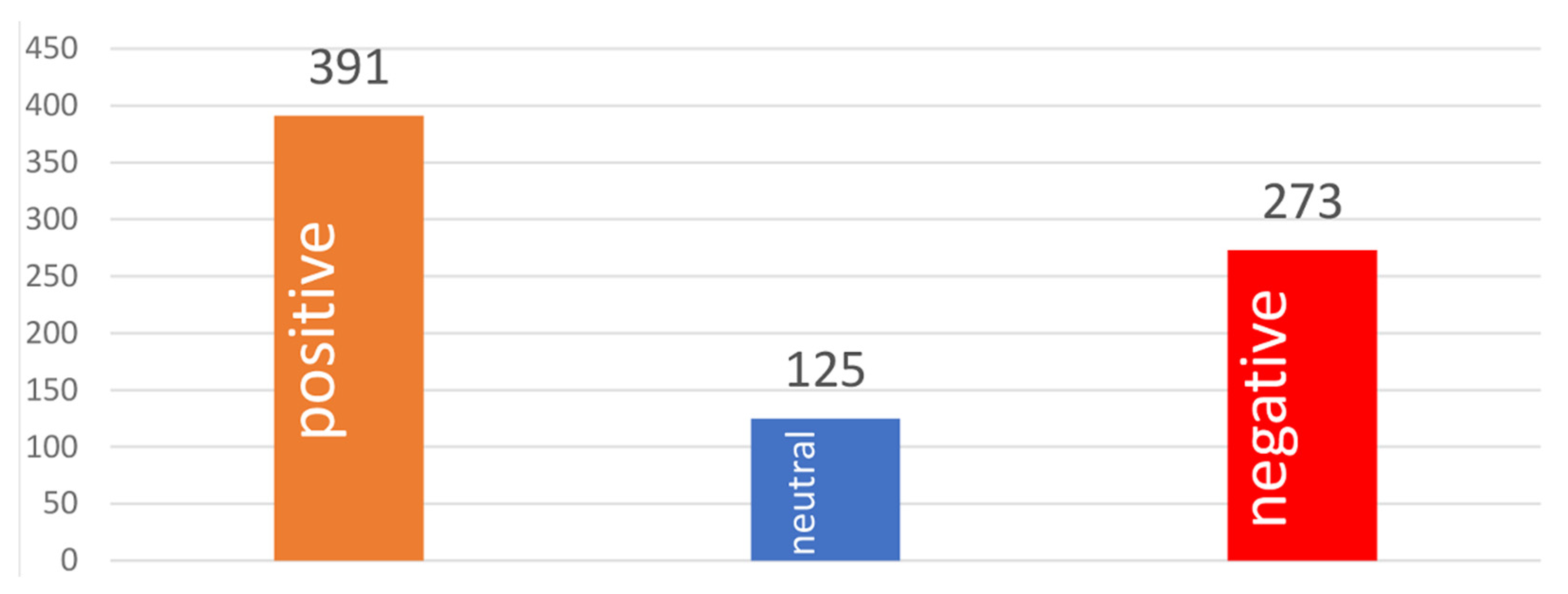
3.1. Sentiment Polarity Distribution
3.2. Topic Modelling with LDA
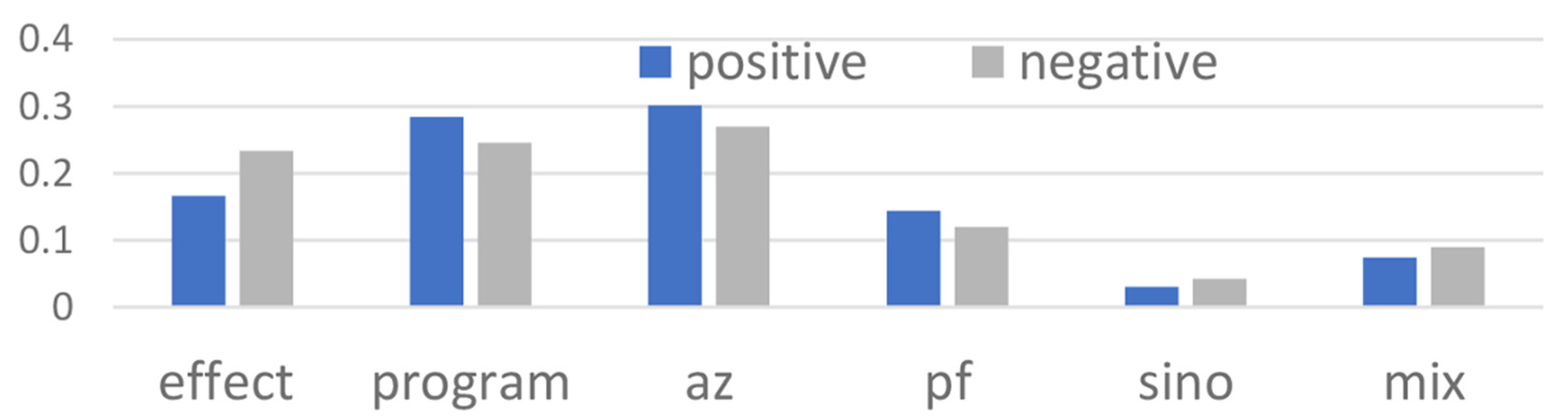
3.3. Feature Selection
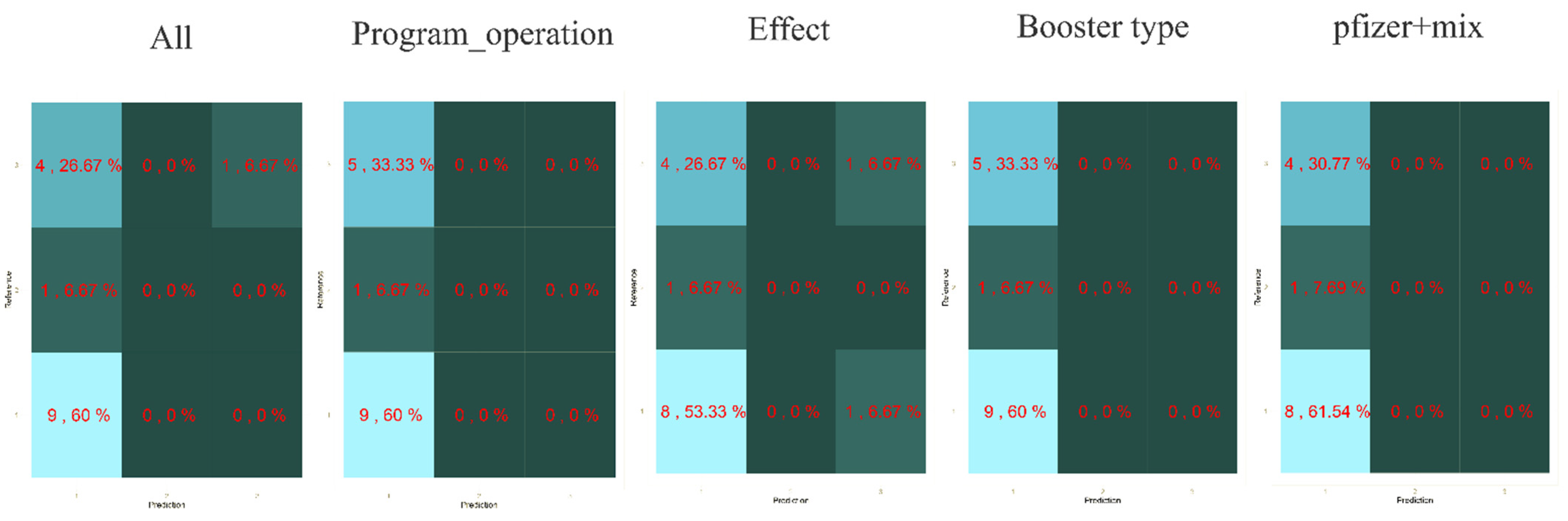
3.4. Multinomial Logistics Regression Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization (WHO). Coronavirus Disease (COVID-19) Dashboard; World Health Organization: Geneva, Switzerland, 2020. Available online: https://covid19.who.int/ (accessed on 2 January 2022).
- Debata, B.; Patnaik, P.; Mishra, A. COVID-19 pandemic. It’s impact on people, economy, and environment. J. Public Aff. 2020, 20, e2372. [Google Scholar] [CrossRef]
- Song, L.; Zhou, Y. The COVID-19 pandemic and its impact on the global economy: What does it take toturn crisis into opportunity? China World Econ. 2020, 28, 1–25. [Google Scholar] [CrossRef]
- Reported Cases and Deaths by Country or Territory. Available online: https://www.worldometers.info/coronavirus/ (accessed on 2 January 2022).
- The Economist. The Omicron Variant Advances at an Incredible Rate. Available online: https://www.economist.com/international/2021/12/18/the-omicron-variant-advances-at-an-incredible-rate (accessed on 2 January 2022).
- Malaysia Floods Hit Seven States Forcing Thousands to Evacuate. 2022. Available online: https://edition.cnn.com/2022/01/02/asia/malaysia-floods-evacuation-intl-hnk/index.html (accessed on 2 January 2022).
- Lau, K.N.; Lee, K.H.; Ho, Y. Text mining for the hotel industry. Cornell Hotel Restaur. Adm. Q. 2005, 46, 344–362. [Google Scholar] [CrossRef]
- Clark, J. Text Mining and Scholarly Publishing; Publishing Research Consortium (PRC): Loosdrecht, The Netherlands, 2013. [Google Scholar]
- Gémar, G.; Jiménez-Quintero, J.A. Text mining social media for competitive analysis. Tour. Manag. Stud. 2015, 11, 84–90. [Google Scholar]
- Zucco, C.; Calabrese, B.; Agapito, G.; Guzzi, P.H.; Cannataro, M. Sentiment analysis for mining texts and social networks data: Methods and tools. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1333. [Google Scholar]
- Sankar, H.; Subramaniyaswamy, V. Investigating sentiment analysis using machine learning approach. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS) IEEE, Palladam, India, 7–8 December 2017; pp. 87–92. [Google Scholar]
- Kwok, S.W.H.; Vadde, S.K.; Wang, G. Tweet topics and sentiments relating to COVID-19 vaccination among Australian Twitter users: Machine learning analysis. J. Med. Internet Res. 2021, 23, e26953. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.S.; Aurpa, T.T.; Anwar, M.M. Detecting sentiment dynamics and clusters of Twitter users for trending topics in COVID-19 pandemic. PLoS ONE 2021, 16, e0253300. [Google Scholar] [CrossRef]
- Ridhwan, K.M.; Hargreaves, C.A. Leveraging Twitter data to understand public sentiment for the COVID-19 outbreak in Singapore. Int. J. Inf. Manag. Data Insights 2021, 1, 100021. [Google Scholar]
- Ansari, M.T.J.; Khan, N. A Worldwide COVID-19 Vaccines Sentiment Analysis Through Twitter Content. Electron. J. Gen. Med. 2021, 18, em329. [Google Scholar] [CrossRef]
- Aygun, I.; Kaya, B.; Kaya, M. Aspect Based Twitter Sentiment Analysis on Vaccination and Vaccine Types in COVID-19 Pandemic with Deep Learning. IEEE J. Biomed. Health Inform. 2021, 26, 2360–2369. [Google Scholar] [CrossRef]
- Marcec, R.; Likic, R. Using Twitter for sentiment analysis towards AstraZeneca/Oxford, Pfizer/BioNTech and Moderna COVID-19 vaccines. Postgrad. Med. J. 2021, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Vyas, V.; Uma, V. An extensive study of sentiment analysis tools and binary classification of tweets using rapid miner. Procedia Comput. Sci. 2018, 125, 329–335. [Google Scholar] [CrossRef]
- Ali, A. Using Google Docs to Enhance Students’ Collaborative Translation and Engagement. J. Inf. Technol. Educ. Res. 2021, 20, 503–528. [Google Scholar] [CrossRef]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Newman, D.; Asuncion, A.; Smyth, P.; Welling, M. Distributed algorithms for topic models. J. Mach. Learn. Res. 2009, 10, 1801–1828. [Google Scholar]
- Nahar, N.; Ara, F.; Neloy, M.; Istiek, A.; Biswas, A.; Hossain, M.S.; Andersson, K. Feature Selection Based Machine Learning to Improve Prediction of Parkinson Disease. In Brain Informatics; Springer: Cham, Switzerland, 2021; pp. 496–508. [Google Scholar]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.A.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the Tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Ong, S.-Q.; Maisarah, B.M.P.; Gan, K.H. Text Mining in Mosquito-Borne Disease: A Systematic Review. Acta Trop. 2022, 231, 106447. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic 1 (Type of Booster) | Topic 2 (Effect of Vaccination) | Topic 3 (Vaccination Program) |
|---|---|---|
| Pfizer | die | Khairykj |
| astrazeneca | Fever | Appointment |
| Sinovac | Effect | Selangor |
| moody | Clinic | |
| Stress | appt | |
| symptoms | Walk-in | |
| tido | mysejahtera | |
| Pain | ||
| Side |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ong, S.-Q.; Pauzi, M.B.M.; Gan, K.H. Text Mining and Determinants of Sentiments towards the COVID-19 Vaccine Booster of Twitter Users in Malaysia. Healthcare 2022, 10, 994. https://doi.org/10.3390/healthcare10060994
Ong S-Q, Pauzi MBM, Gan KH. Text Mining and Determinants of Sentiments towards the COVID-19 Vaccine Booster of Twitter Users in Malaysia. Healthcare. 2022; 10(6):994. https://doi.org/10.3390/healthcare10060994
Chicago/Turabian StyleOng, Song-Quan, Maisarah Binti Mohamed Pauzi, and Keng Hoon Gan. 2022. "Text Mining and Determinants of Sentiments towards the COVID-19 Vaccine Booster of Twitter Users in Malaysia" Healthcare 10, no. 6: 994. https://doi.org/10.3390/healthcare10060994
APA StyleOng, S. -Q., Pauzi, M. B. M., & Gan, K. H. (2022). Text Mining and Determinants of Sentiments towards the COVID-19 Vaccine Booster of Twitter Users in Malaysia. Healthcare, 10(6), 994. https://doi.org/10.3390/healthcare10060994