1. Introduction
COVID-19 or Coronavirus is a recent disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) [
1]. In February 2021, over 106 billion SARS-CoV-2 infections and a mortality rate of above 2.3 billion were recorded globally, in the worst epidemic to have troubled humans since the Spanish flu occurred in 1918, and has consequently overwhelmed global healthcare systems resulting in serious economic disturbance [
2]. In order to combat this infectious disease, doctors and researchers have tirelessly attempted to gain further knowledge and develop technical devices for the diagnosis of this disease. Attempts include the advancement of drugs and vaccines [
3], the formation of epidemiologic methods for forecasting the spread of the disease among people [
4], the advancement of mobile device apps to track patients who are infected, the enhancement of policies, and the implementation of novel technologies for managing the capacities and resources in clinics [
5]. Owing to the increasing prevalence of coronavirus infection worldwide, many studies analyzed various prospects of this infection. Research includes recognizing the methods of virus detection, the origin of coronavirus along with examining its gene series, early cases in the countries infected, forecasting COVID-19 cases in the epidemiologic pandemic, and patient information [
6].
Machine learning (ML) procedures first accumulate data individually, i.e., from various sources [
7], followed by fixing the preprocessed data to solve data-oriented problems and minimize space size by erasing incorrect data and selecting relevant data. However, in some cases, the dataset value may differ for the system in making decisions, thus, ML methods were devised with the help of other ideas such as probability statistics and theory control for examining data and deriving useful and original information, concealed information, or patterns from past knowledge [
8]. Lastly, the performance assessments of the methods is conducted and model optimization concludes the process, which enhances the method with the help of novel rules and a dataset. ML approaches are utilized in various sectors such as traffic management, medicine, education, manufacturing and production, robotics, engineering, and so on [
9,
10,
11]. Currently, ML methods are utilized in the examination of high dimensional bio-medical structured and unstructured datasets. Malaria Diagnosis, diabetes risk assessment, typhoid, and vascular diseases classification, and genomic and genetic data studies are a few instances of the bio-medical use of ML approaches.
The authors in [
12] developed a novel image processing-based approach for the health care system called “C19D-Net”, for the detection of “COVID-19” in CXR images to assist radiologist in enhancing COVID-19 classification performance. It uses the InceptionV4 model with a multi-SVM classifier for COVID-19 diagnosis in distinct class labels. In [
13], the researchers present a solution to analyze the COVID-19 pandemic dataset. Specifically, the solution focuses on analyzing useful knowledge and valuable information (for example, frequency, distribution, and pattern) of healthcare statuses and characteristics in populations. The availability of knowledge and information assists users (for example, civilians, and researchers) in better understanding the disease, and playing an active role in combating, fighting, or controlling the disease. Li et al. [
14] performed a qualitative and quantitative assessment of Chinese social networking media posts originating in Wuhan City on the Chinese microblogging platform Weibo during the earlier stage of the COVID-19 epidemic.
The researchers in [
15] reviewed the available approaches while anticipating the challenges and difficulties in the improvement of a data-driven strategy to combat the COVID-19 outbreak. A 3M-analysis was presented, which included making, monitoring, and exhibiting decisions. The emphasis was placed on the potential of a familiar data-driven scheme to tackle various problems which increased following the outbreak; firstly, by forecasting and monitoring the spread of the epidemic; secondly, by assessing the efficiency of government decisions; and lastly, by making appropriate decisions. Every step of the roadmap may be exhaustive for an analysis of consolidated theoretic outcomes and the potential applications in the COVID-19 context. Supervised ML methods for COVID-19 infection were designed in [
16] with learning algorithms including DT, LR, NB, ANN, and SVM using epidemiology labeled data for negative and positive COVID-19 cases. A correlation coefficient (CC) analysis between independent features and dependent features was performed to determine stronger relationships among every dependent and independent feature of the prior dataset to develop the model.
The researchers in [
17] processed available information on US states to create an incorporated dataset on potential factors which cause the epidemic to spread. Then, the researchers made use of the supervised ML approach to reach a consensus and rank the crucial factor. The author performed a regression analysis to identify the crucial pre-lockdown factors that affected post-lockdown contamination and death to inform lockdown-related policy making. Kim et al. [
18] aimed to examine the relationship between obesity, as determined by the body mass index (BMI), with mortality and morbidity owing to COVID-19. Information from 5628 approved COVID-19 patients were gathered by the Center for Disease Control and Prevention of Korea. The odds ratio (OR) of diabetes and morbidity in the BMI groups was examined using LR models attuned for similar covariates. Hawkins et al. [
19] designed a nationwide COVID-19 dataset at the county level that was coupled with the Distressed Communities Index (DCI) and their constituent metrics of socio-economic status.
This study developed an Enhanced Gravitational Search Optimization with Hybrid Deep Learning Model (EGSO-HDLM) for COVID-19 diagnosis using epidemiology data. The proposed EGSO-HDLM model employs a hybrid convolutional neural network with gated recurrent unit based fusion (HCNN-GRUF) model. In addition, the hyperparameter optimization of the HCNN-GRUF model was improved by the use of the EGSO algorithm, which was derived by including the concepts of cat map and the traditional GSO algorithm. To assure the enhanced performance of the EGSO-HDLM model, an extensive set of experimental validation processes on a benchmark dataset was performed. In short, the paper’s contribution is summarized as follows.
An intelligent EGSO-HDLM model which includes pre-processing, HCNN-GRUF classification, and EGSO-based parameter optimization is presented. To the best of our knowledge, the EGSO-HDLM model has not previously been presented in the literature.
Hyperparameter optimization of the HCNN-GRU model with the EGSO algorithm using cross-validation helps to boost the predictive outcome of the EGSO-HDLM model for unseen data.
Validating the performance of the proposed EGSO-HDLM model on a benchmark dataset from the Kaggle repository.
2. The Proposed Model
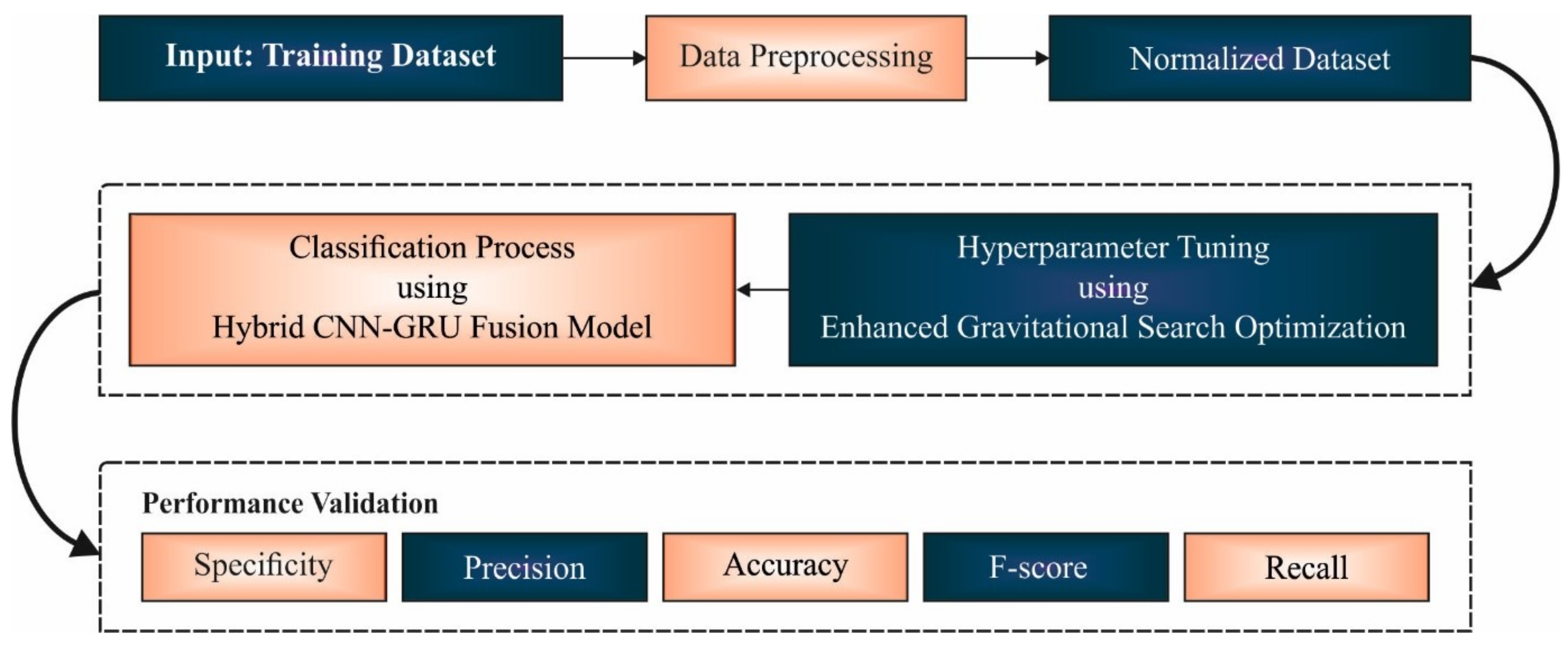
In this study, a new EGSO-HDLM model was designed for the identification and classification of COVID-19 using epidemiology data. Primarily, the presented EGSO-HDLM model applied data normalization to pre-process the actual data. Then, the HCNN-GRUF model was applied for the classification process. Moreover, the hyperparameter optimization of the HCNN-GRUF model was improved by the use of the EGSO algorithm.
Figure 1 depicts the overall process of the EGSO-HDLM algorithm.
2.1. Data Pre-processing
When the numerical processing was executed, a huge variance in magnitude amongst the values became apparent. This condition can cause problems such as minimal convergence of networks and saturation of neuron outcomes [
20]; therefore, normalized original data were required. The following Min-Max normalized approach (Equation (1)) can be used for normalizing the data to intervals of zero and one:
where
signifies the normalized data,
represents the original data,
implies the minimal data values from the present element, and
denotes the maximal data value from the present elements.
2.2. Design of HCNN-GRUF Based Classification
CNN [
21] is a hierarchical FFNN approach that is dependent upon convolutional as well as pooling functions. Convolution was utilized to extract local features for further processing with subsequent layers. Primarily, the resultant input layers are convoluted with several
filters (convolutional kernel). Next, the resultant convolutional layer was created by linking the outcomes of the convolutional function that differs with filter size
In Equation (2),
refers the
feature extracted with convolutional function,
denotes the non-linear function,
signifies the weighting of filters,
denotes the filtering window size, and
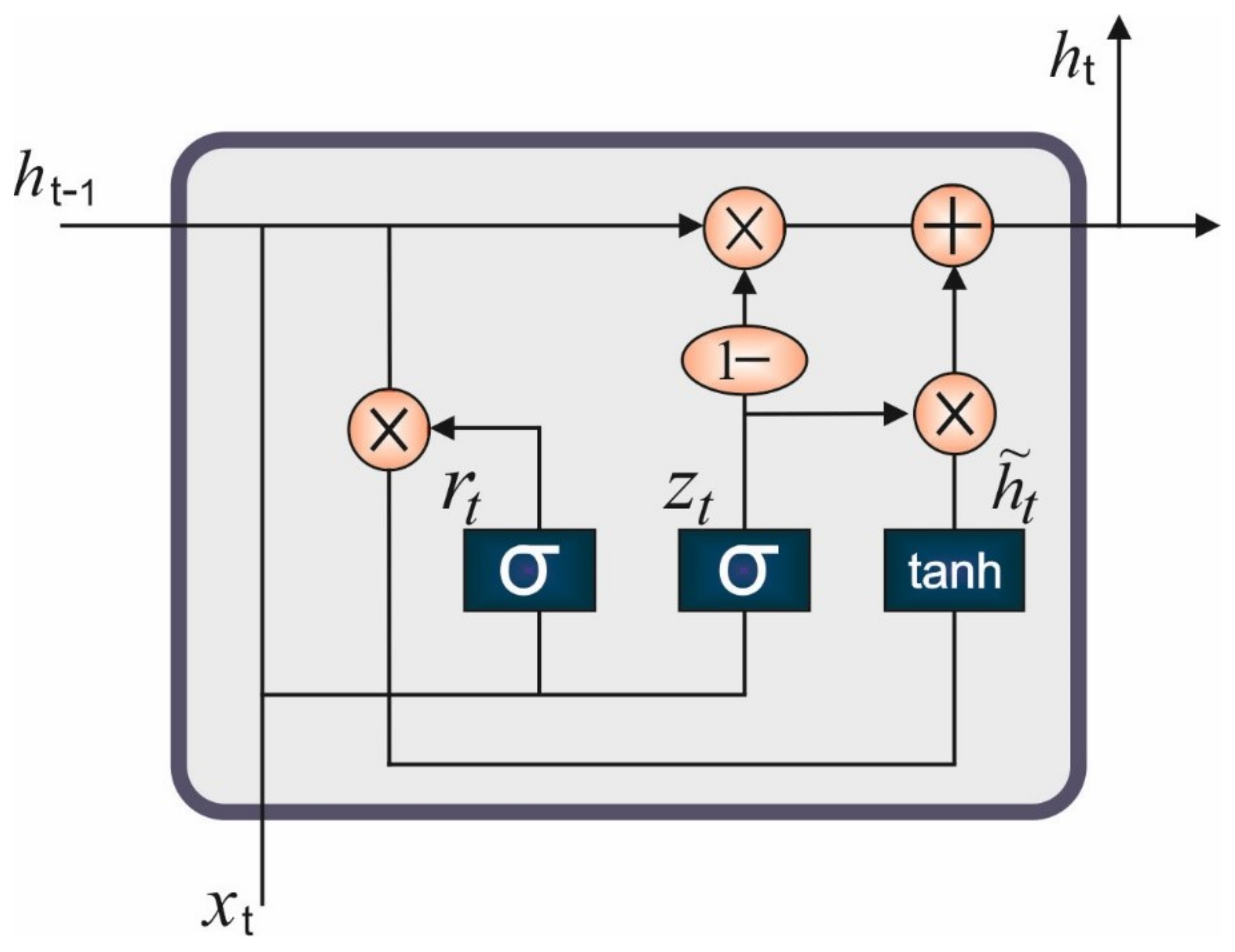
implies the bias. A combination of GRU and LSTM was applied for a gated recurrent neural network (RNN) which remembers a long order of data and thus decreases data loss. Related to LSTM, GRU decreases the amount of gated units that reduces the processing time but preserves the accuracy. GRU has two gated sub-units, namely reset as well as update gates. In every moment, the GRU receives the existing as well as hidden states in the preceding moment with their update gate, and defines the activation state of their individual neurons. Additionally, the reset gate receives both states and defines if any input data are forgotten.
Figure 2 depicts the framework of the GRU technique. Input at the present moment is then integrated with the weighted and resultant reset gate to obtain the memory contents at the present moment with activation functions. Next, the upgrade gate obtains the memory content at the present moment and hidden state in the preceding moment for determining the output and hidden state at the present moment. The function of GRU is summarized in the following formulas.
In Equation (4),
signifies the upgrade gate,
and
imply the weighting of
stands for the activation function,
indicates the input at present moment, and
represents the hidden output in the preceding moment.
stands for the reset gate, and
and
refer the weighting of
defines the memory satisfied at the present moment,
implies the activation functions, and
and
represent the weighting at the present moment.
defines the outcome at the present moment. Pooling is the procedure of extracting data for the purpose of reducing the size of the resultant GRU layer. The maximal pooling approach was utilized for extracting the maximal vector value of all the inputs as the result of pooling layers.
where
denotes the typical vector in the GRU to pooling layers,
. implies the maximal of
signifies the output resultant in the pooling layer, and
denotes the amount of features input to pooling layers. The fusion layer was planned to merge more than 2 layers of tensors; during this case, it integrates several tensors in the polling layer as opposed to one tensor. It can be executed by the “Concatenate” approach that receives the final bit as axis, and splices all the resultant polling layers for creating the result of this layer.
In Equation (10),
refers the output of this layer,
denotes the resultant in the polling layers. The softmax classification is usually employed for several classifier problems. The fully connected (FC) layer was utilized to connect an input in the fusion layer and the value of all the neurons was computed utilizing the softmax function. Additionally, the maximal value of every neuron output was obtained as the classifier outcome.
In Equation (11), signifies the probability of forecast labels. and denote the weights as well as biases. In Equation (12), denotes the last forecast label.
2.3. Hyperparameter Tuning
At this stage, the hyperparameter tuning of the HCNN-GRUF model can be tuned by the design of the EGSO algorithm. Rashedi [
22] developed a GSO algorithm, which is an optimization algorithm that gained popularity in the past few decades. It depends on the second law of motion, as illustrated in Equation (15), and the law of gravity, as demonstrated in Equation (13). Additionally, it depends on the physical concepts of passive gravitational mass, inertial mass, and active gravitational mass. The second law of motion states that once a force (F) is applied to all the particles, the (a) acceleration is defined by the mass (M) and force. The law of gravity says that all the particles attract all the other particles with a gravitational force (F). The gravitational force (F) between these particles is directly proportionate to the product of (
and
) masses and inversely proportionate to the square of
distance.
indicates the gravitational constant that reduces with increasing time, and it is evaluated by the following expression:
The GSA algorithm is briefly described in the following steps:
An isolated scheme with
number of particles is assumed, where the location of
-
particles is represented as follows:
In Equation (16), indicates the location of
-particles in dimension.
Here, the best and worst fitness values are evaluated using Equations (17) and (18) correspondingly. Minimization and maximization problems are evaluated by Equations (19) and (20).
In the equation, refers to the fitness of - particles at time.
Here, the
gravitational constant at
time can be evaluated using Equation (21):
where
is the primary value of the gravitational constant initialized at a random fashion,
indicates the present time, and
denotes the overall time.
Here, the gravitational and inertia mass are upgraded with the help of the fitness function. Equality of gravitational and inertia masses is assumed, and the masses value is evaluated using the following expression:
In the expression, represent the fitness of - particles at time and denotes the mass of -particles at time.
Here, the complete force
that is exerted on the
-
particles in a
-
dimension at
time is evaluated by the following equation:
In Equation (25),
represent a random integer
, and k
is the set of initial particles with the biggest masses and the best fitness value. The force applied from mass ‘
j’ on mass ‘
i’ at ‘
t’ time can be expressed as
and is evaluated using Equation (26):
Consider that
refers to the passive gravitational mass correlated to
-
particles
denotes the active gravitational mass interrelated to
-
particles.
indicates a smaller positive constant to avoid division by 0, and
indicates the Euclidian distance between
-
and
-
particles:
Here,
, the acceleration of
-
particles;
at
time in the
direction; and the velocity of
-
particles in the
-
direction,
, are evaluated by:
From the expression, refers to the inertial mass of - particles, and indicates an arbitrary integer
Here, the location of
-
particles in the
-
direction,
, is evaluated by the following expression:
In the EGSO algorithm, the GSO algorithm is integrated into the cat map concept to reduce the ergodic problem, avoid premature convergence and enhance the algorithm’s efficiency. In optimization algorithms, the grouping of SI optimization algorithms and chaotic mapping improves the outcomes of SI optimization. This concept was confirmed by several instances and depends on Chaos features including sensitivity, randomness, and ergodicity to the initial condition. Hence, an attempt was made to integrate the Chaos concept with GSO to attain good accuracy and efficiency [
23]. Until now, the SI optimization approach was generally integrated into tent or logistic mapping models to accomplish a certain amount of progress. However, the chaotic sequence produced from the logistic mapping is of a non-uniform distribution. This follows Chebyshev’s Distribution, where density is lower at the center and is higher at both ends. These features have some level of impact on the ergodicity of optimization solution space. The chaotic sequence made from tent mapping models follows uniform distribution; however, the values rapidly fall into the smaller cycle due to the impact of word length. It therefore lacks better randomness. This method could generate a uniformly distributed chaotic sequence, to enhance GSO single distribution and might improve the model searching efficacy. A chaotic algorithm, Cat Map, is generally utilized in image encryption.
Here, the chaotic sequence produced by the higher dimensional Cat Map at the range of [0, 1] is fixed as an arbitrary value rather than the rand function to determine individual distribution. The mapping value lies within the range of [0, 1] when building the multi-dimension chaotic sequence Cat(i,j). The sequential dataset in the dimension is independent of others and has stronger ergodicity. These features decrease the ergodic problem carried by random distribution and assures the ergodicity of individuals flying in the solution space. This technique might improve the algorithm performance and prevent premature convergence.
3. Results and Discussion
This section describes the experimental validation of the EGSO-HDLM technique, which was carried out with the help of the benchmark epidemiology dataset from Kaggle repository [
24]. In this article, a set of 5000 samples in positive class and 5000 samples in negative classes were considered. The proposed model was simulated using the Python 3.6.5 tool on PC i5-8600k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The parameter settings were as follows: dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU.
The confusion matrices generated by the EGSO-HDLM model on the test data are demonstrated in
Figure 3. For 70% of the training (TR) data, the EGSO-HDLM model identified 3330 samples in the positive class and 3465 samples in the negative class. Additionally, for 30% of the testing (TS) data, the EGSO-HDLM system identified 1425 samples in the positive class and 1496 samples in the negative class. In addition, for 80% of the TR data, the EGSO-HDLM method identified 3885 samples as positive class and 3896 samples as negative class. Finally, on 20% of TS data, the EGSO-HDLM system identified 977 samples in the positive class and 974 samples in the negative class.
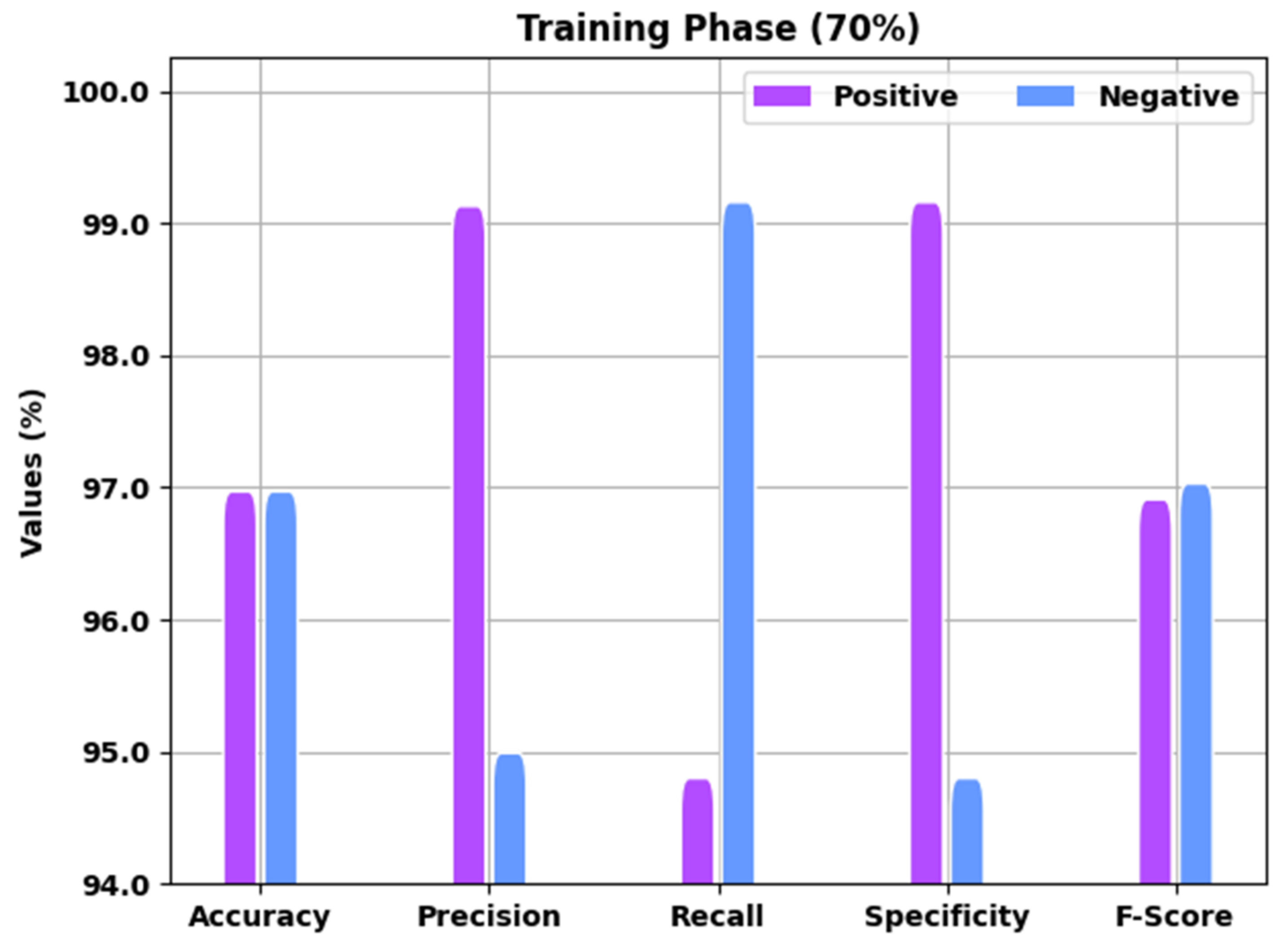
Table 1 offers detailed COVID-19 recognition outcomes of the EGSO-HDLM model for 70% of the TR and 30% of the TS data. A brief result analysis of the EGSO-HDLM model in the identification of COVID-19 for 70% of the TR data is depicted in
Figure 4. The results implied that the EGSO-HDLM model classified all the samples into corresponding positive and negative classes. For instance, the EGSO-HDLM model identified positive samples with
of 97.07%,
of 99.23%,
of 94.90%,
of 99.26%, and
of 97.01%. Additionally, the EGSO-HDLM technique identified negative samples with
of 97.07%,
of 95.09%,
of 99.26%,
of 94.90%, and
of 97.13%.
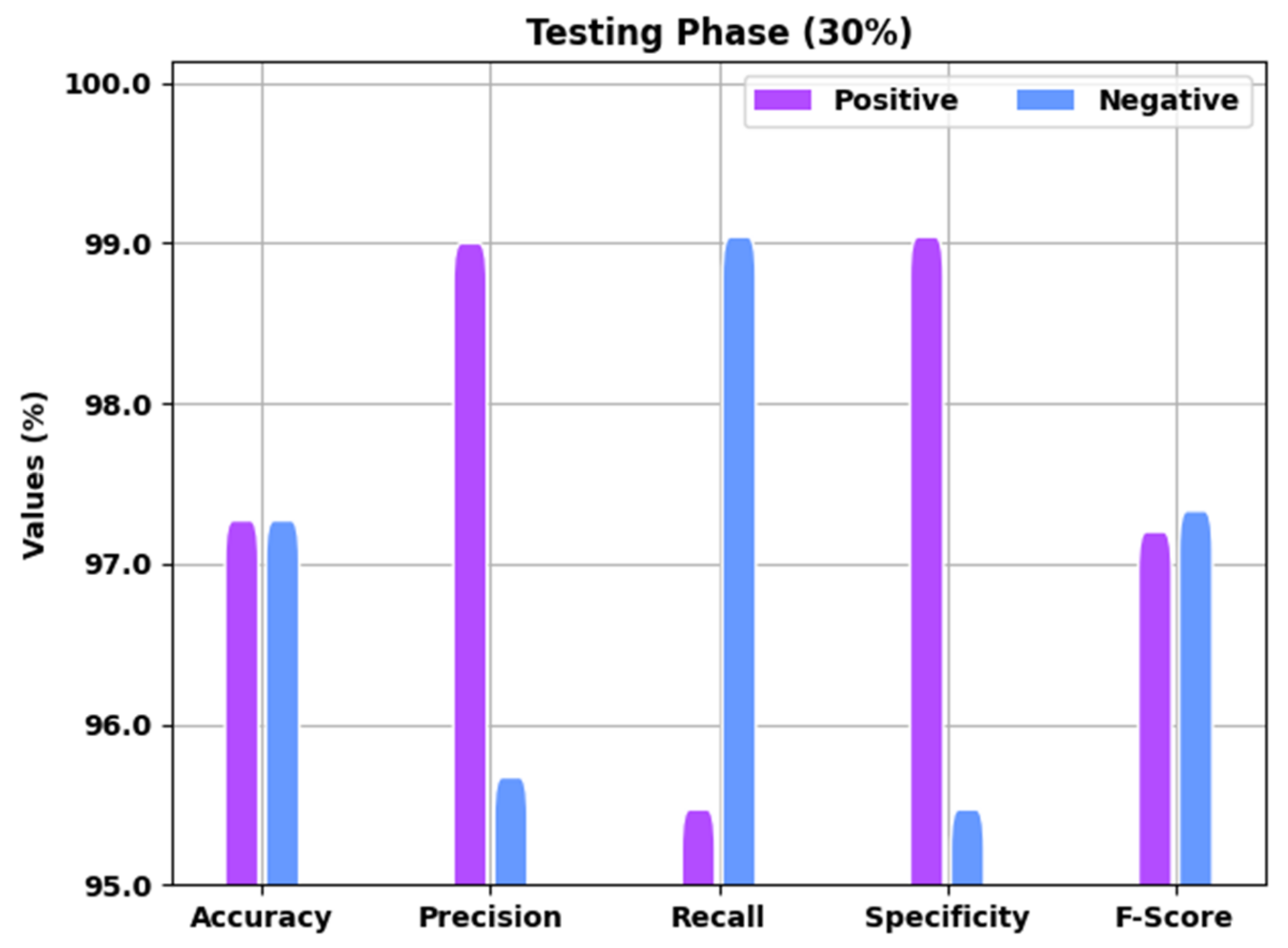
A brief overview of the EGSO-HDLM technique in the identification of COVID-19 under 30% the TS data is shown in
Figure 5. The results implied that the EGSO-HDLM methodology recognized all the samples as corresponding positive and negative classes. For example, the EGSO-HDLM system identified positive samples with
of 97.37%,
of 99.10%,
of 95.57%,
of 99.14%, and
of 97.30%. Moreover, the EGSO-HDLM approach identified negative samples with
of 97.37%,
of 95.77%,
of 99.14%,
of 95.57%, and
of 97.43%.
Table 2 presents detailed COVID-19 identification outcomes of the EGSO-HDLM system for 80% of the TR and 20% of the TS data. A brief analysis of the EGSO-HDLM approach in the identification of COVID-19 for 80% of the TR data is portrayed in
Figure 6. The results implied that the EGSO-HDLM model identified all the samples into corresponding positive and negative classes. For example, the EGSO-HDLM methodology identified positive samples with
of 97.26%,
of 97.34%,
of 97.17%,
of 97.35%, and
of 97.26%. Additionally, the EGSO-HDLM model identified negative samples with
of 97.26%,
of 97.18%,
of 97.35%,
of 97.17%, and
of 97.27%.
A brief overview of the EGSO-HDLM approach in the identification of COVID-19 for 20% of the TS data is depicted in
Figure 7. The results implied that the EGSO-HDLM technique identified all the samples as corresponding positive and negative classes. For example, the EGSO-HDLM method identified positive samples with
of 97.55%,
of 97.60%,
of 97.50%,
of 97.60%, and
of 97.55%. Additionally, the EGSO-HDLM system identified negative samples with
of 97.55%,
of 97.50%,
of 97.60%,
of 97.50%, and
of 97.55%.
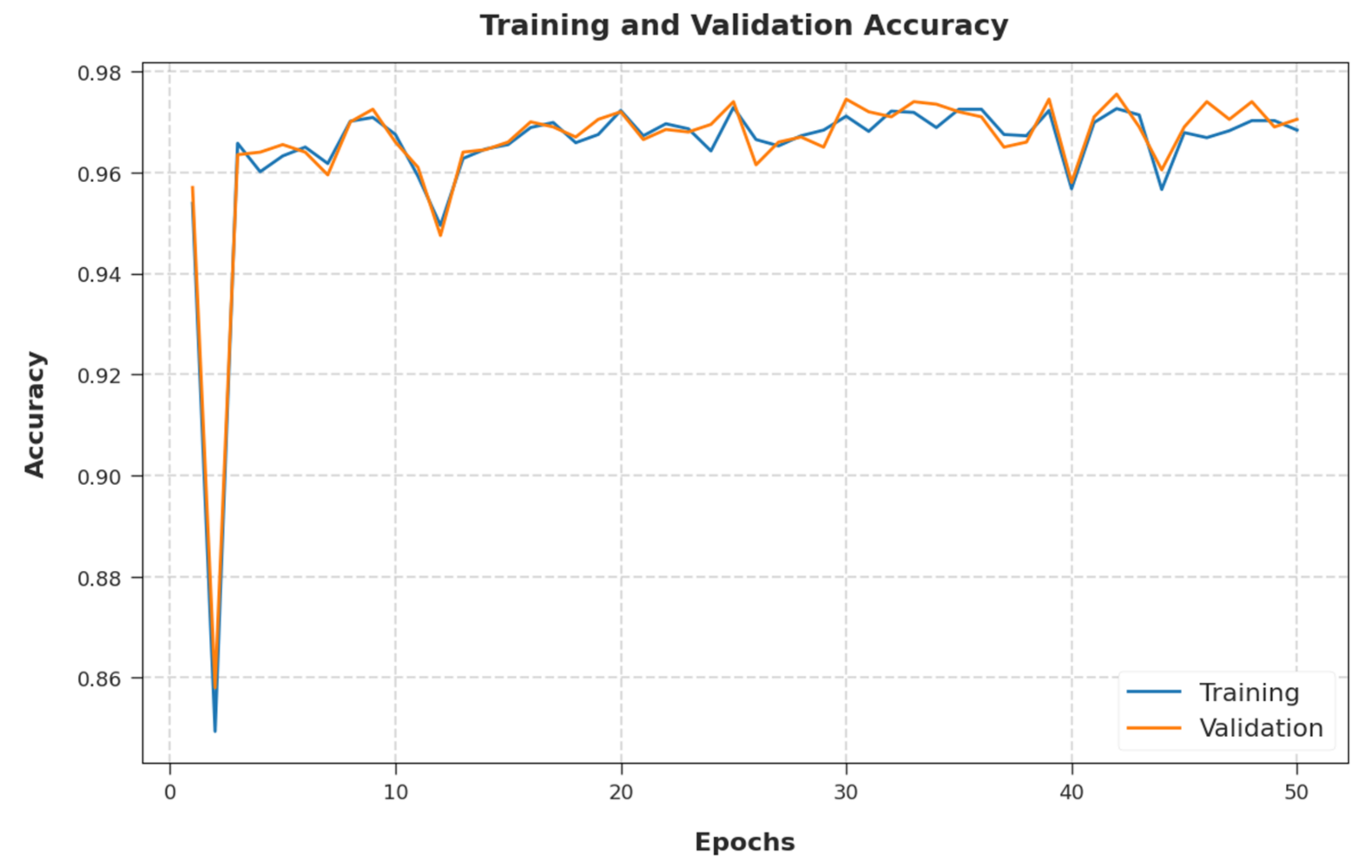
The training accuracy (TA) and validation accuracy (VA) attained by the EGSO-HDLM method on test dataset are illustrated in
Figure 8. The experimental outcome implied that the EGSO-HDLM system gained maximum values of TA and VA. Particularly, the VA seemed to be higher than TA.
The training loss (TL) and validation loss (VL) achieved by the EGSO-HDLM system on test dataset are established in
Figure 9. The experimental outcome implied that the EGSO-HDLM methodology had the lowest values of TL and VL. In particular, the VL was lower than TL.
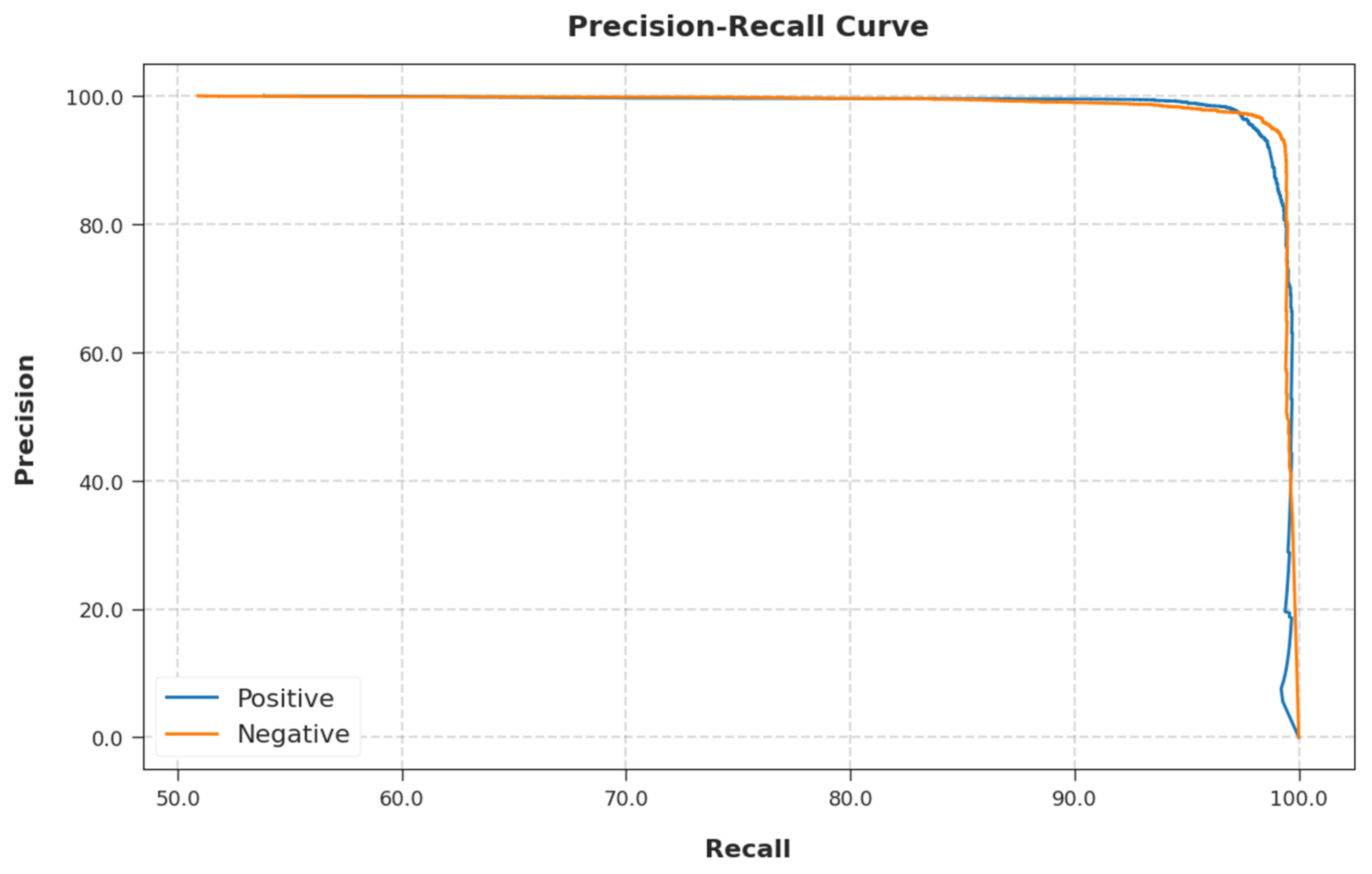
A brief precision-recall analysis of the EGSO-HDLM methodology on test dataset is portrayed in
Figure 10. By observing the figure, it can be seen that the EGSO-HDLM technique accomplished maximum precision-recall performance under all classes.
A detailed ROC inquiry of the EGSO-HDLM algorithm on the test dataset is portrayed in
Figure 11. The results implied that the EGSO-HDLM technique exhibited its ability in categorizing two distinct classes on the test dataset.
Table 3 portrays a detailed comparison study of the EGSO-HDLM model with recent models under several measures [
16].
Figure 12 illustrates an extensive
in the comparison of the EGSO-HDLM model with existing models. The figure indicates that the SGD and ACO models displayed poor performance with minimal
values of 90.01% and 90.67%, respectively. Additionally, the ELM model obtained a slightly enhanced
value of 91.46%. Next, the MLP and LSTM models demonstrated a reasonably closer
of 94.27% and 94.64%, respectively. However, the EGSO-HDLM model offered a maximum
of 97.55%.
Figure 13 demonstrates an extensive
analysis of the EGSO-HDLM technique with existing models. The figure indicates that the SGD and ACO algorithms demonstrated poor performance with minimal
values of 90.08% and 94.40%, respectively. The ELM approach obtained a slightly enhanced
value of 91.18%. Next, the MLP and LSTM models demonstrated a reasonably closer
of 94.58% and 93.18% correspondingly. However, the EGSO-HDLM method provided the maximum
of 97.55%.
Figure 14 illustrates an extensive
inspection of the EGSO-HDLM algorithm in comparison with existing models. The figure indicates that the SGD and ACO systems demonstrated poor performance with minimal
values of 92.37% and 93.36%, respectively. Additionally, the ELM approach gained a slightly enhanced
value of 92.59%. Next, the MLP and LSTM models displayed a reasonably closer
of 93.66% and 94.96%, respectively. However, the EGSO-HDLM system offered the maximum
of 97.55%.
Therefore, the experimental results indicated that the EGSO-HDLM model has the ability to classify COVID-19 in an epidemiology dataset. The enhanced performance of the proposed model is due to the fusion process and EGSO-based hyperparameter tuning process.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}