



A Robust Design-Based Expert System for Feature Selection and COVID-19 Pandemic Prediction in Japan

Abstract
:1. Introduction
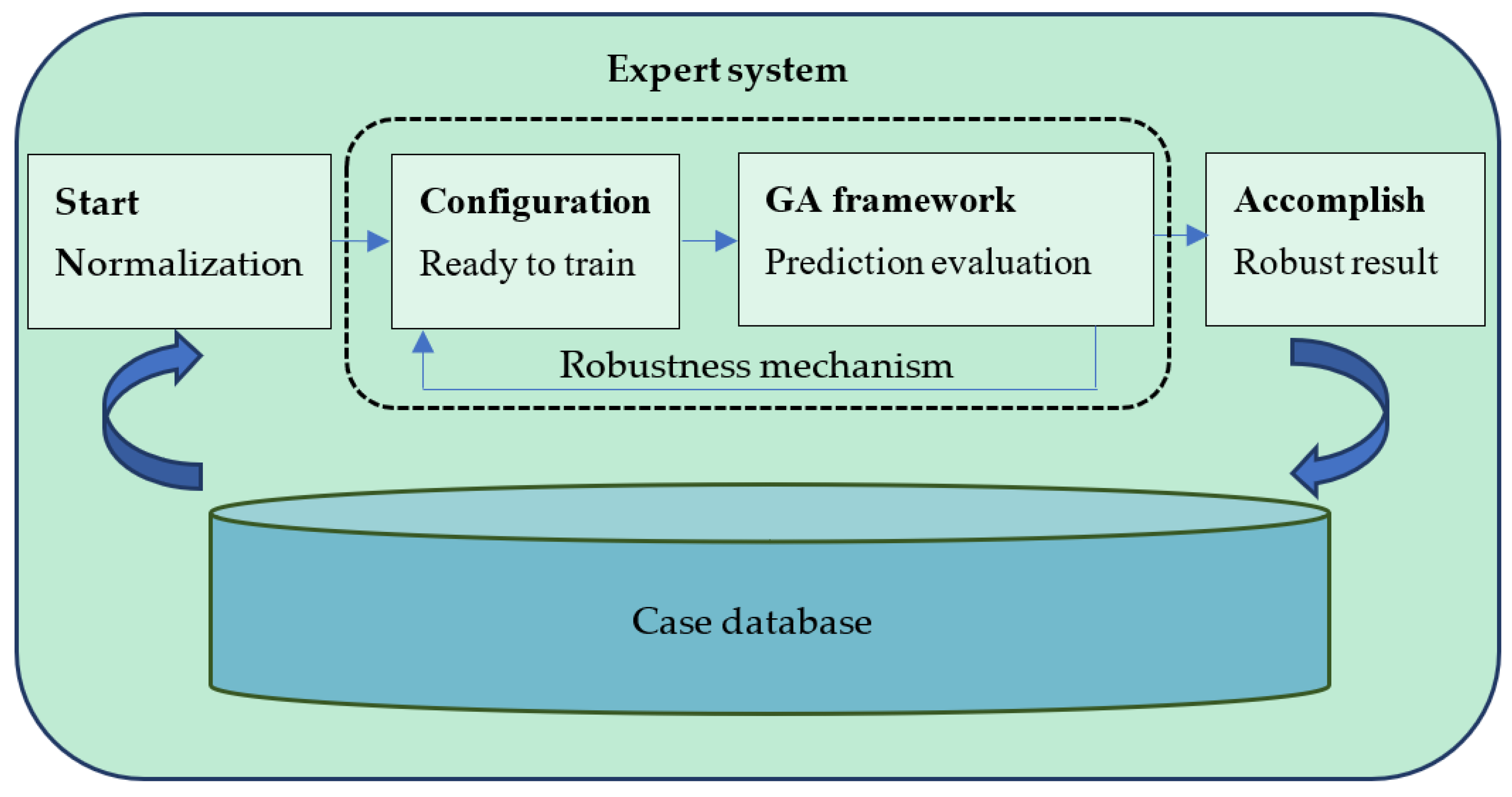
2. The Expert System with Robust Design
2.1. System Architecture
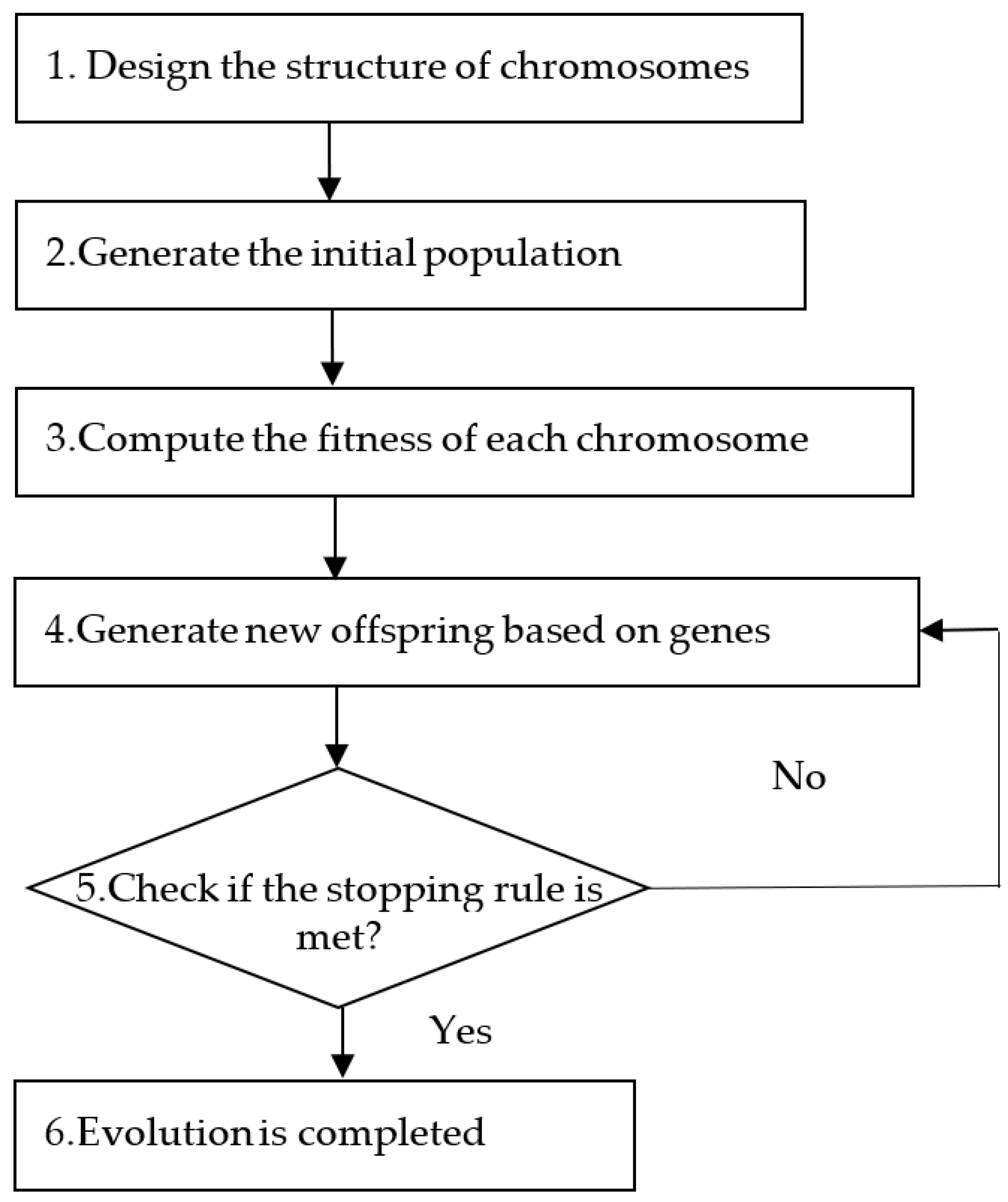
2.2. Optimization of the System
- (1)
- Compute the predicted level (PL) for each case in the test dataset. For each case in the test dataset, we apply the nearest neighbor method to find the most similar case in the training dataset to predict the level of this case (the level is represented by ). The similarity between cases is measured using Euclidean distance.
- (2)
- Compute the fitness of chromosome . The fitness of chromosome can be expressed using the following function:
3. Results
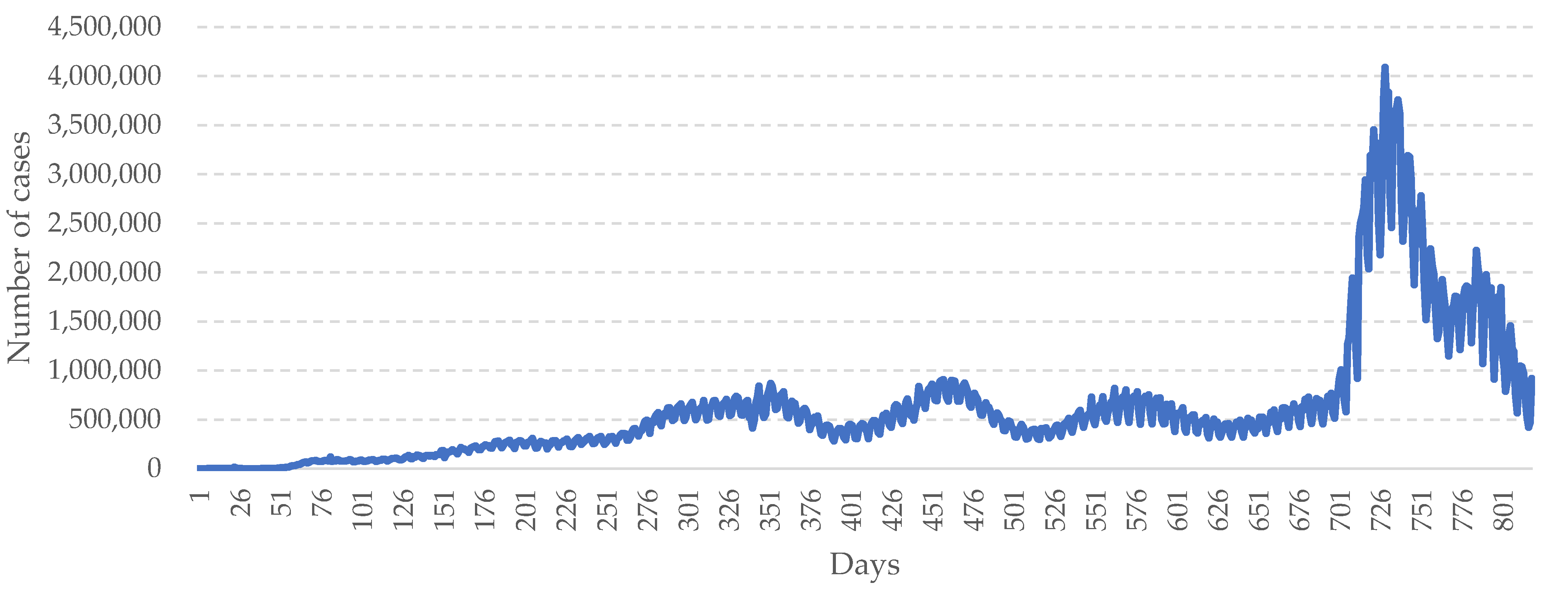
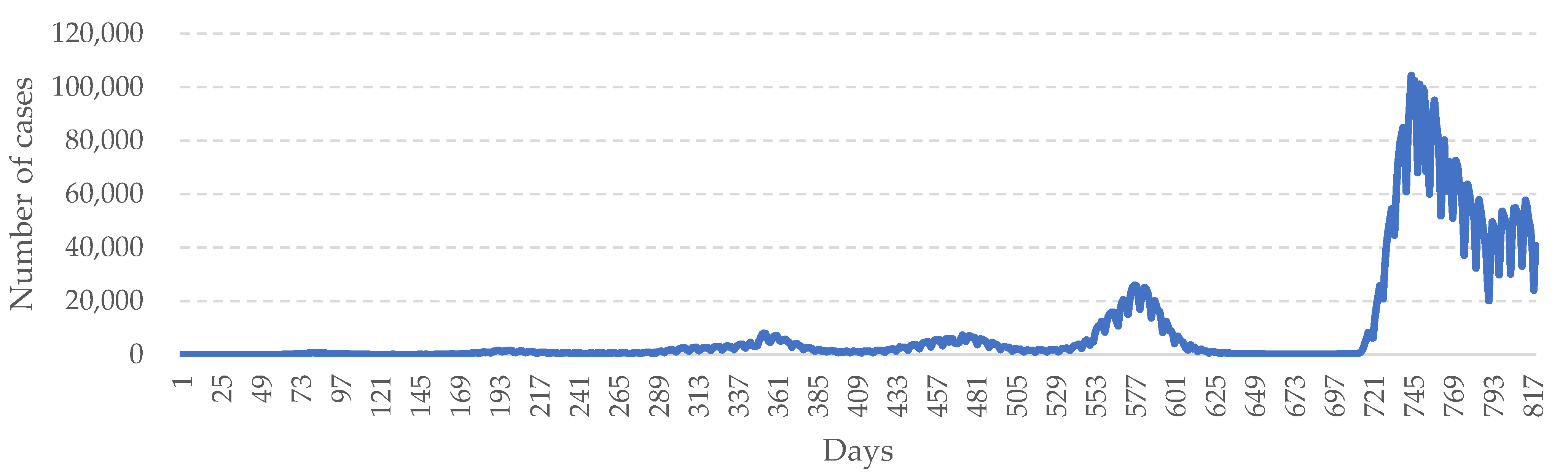
3.1. Data Collection
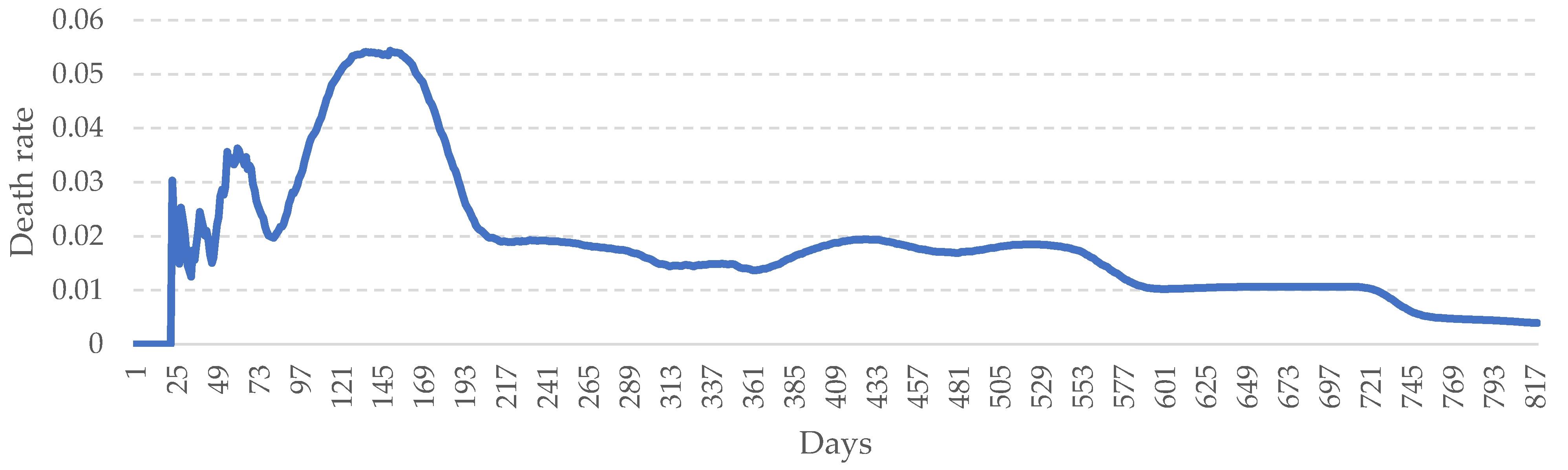
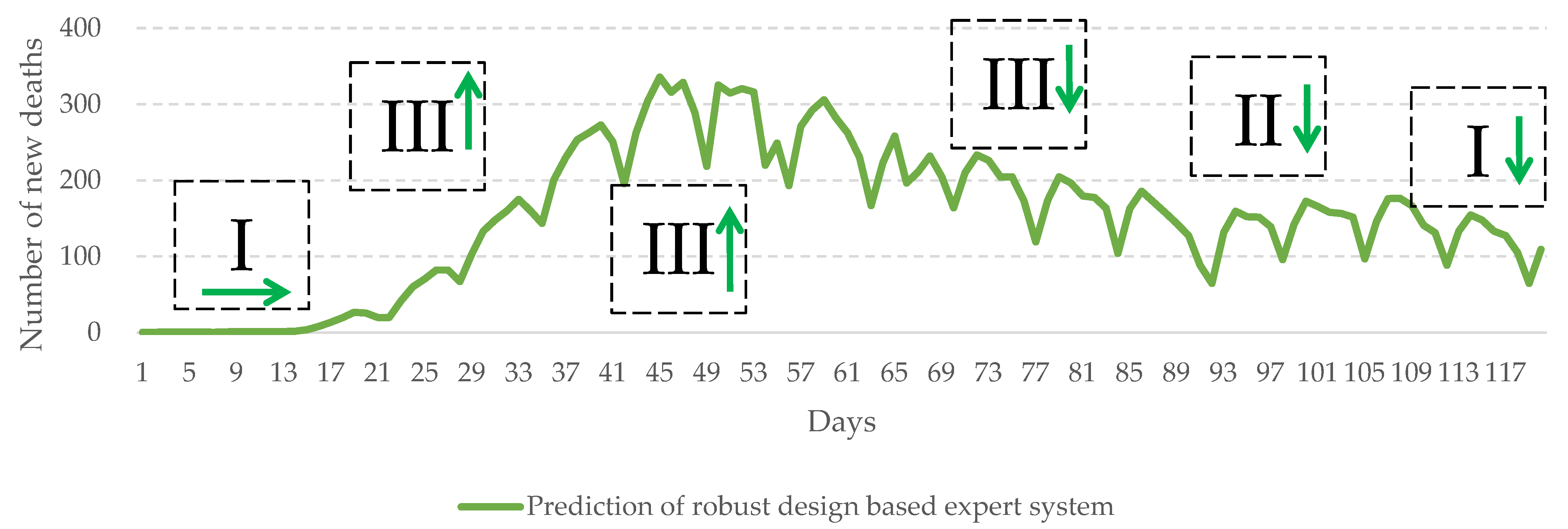
3.2. Performance of the System
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Guan, X.; Wu, P.; Wang, X.; Zhou, L.; Tong, Y.; Ren, R.; Leung, K.S.M.; Lau, E.H.Y.; Wong, J.Y.; et al. Early Transmission Dynamics in Wuhan, China, of Novel Coronavirus–Infected Pneumonia. N. Engl. J. Med. 2020, 382, 1199–1207. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Horby, P.W.; Hayden, F.G.; Gao, G.F. A novel coronavirus outbreak of global health concern. Lancet 2020, 395, 470–473. [Google Scholar] [CrossRef]
- World Health Organization. Looking Back at a Year That Changed the World: WHO’s Response to COVID-19; WHO: Geneva, Switzerland, 2021.
- Rousset, S.; Level, A.; François, F.; Muller, L. Behavioral and Emotional Changes One Year after the First Lockdown Induced by COVID-19 in a French Adult Population. Healthcare 2022, 10, 1042. [Google Scholar] [CrossRef]
- Karako, K.; Song, P.; Chen, Y.; Tang, W. Analysis of COVID-19 infection spread in Japan based on stochastic transition model. BioSci. Trends 2020, 14, 134–138. [Google Scholar] [CrossRef]
- Shimizu, K.; Negita, M. Lessons Learned from Japan’s Response to the First Wave of Covid-19: A Content Analysis. Healthcare 2020, 8, 426. [Google Scholar] [CrossRef] [PubMed]
- Sumikawa, Y.; Honda, C.; Yoshioka-Maeda, K.; Yamamoto-Mitani, N. Characteristics of COVID-19-Related Free Telephone Consultations by Public Health Nurses in Japan: A Retrospective Study. Healthcare 2021, 9, 1022. [Google Scholar] [CrossRef]
- Tomar, A.; Gupta, N. Prediction for the spread of COVID-19 in India and effectiveness of preventive measures. Sci. Total Environ. 2020, 728, 138762. [Google Scholar] [CrossRef]
- Tuli, S.; Tuli, S.; Tuli, R.; Gill, S.S. Predicting the growth and trend of COVID-19 pandemic using machine learning and cloud computing. Internet Things 2020, 11, 100222. [Google Scholar] [CrossRef]
- Araja, D.; Berkis, U.; Murovska, M. COVID-19 Pandemic-Revealed Consistencies and Inconsistencies in Healthcare: A Medical and Organizational View. Healthcare 2022, 10, 1018. [Google Scholar] [CrossRef]
- McCarthy, J. Recursive functions of symbolic expressions and their computation by machine, part I. Commun. ACM 1960, 3, 184–195. [Google Scholar] [CrossRef] [Green Version]
- Feigenbaum, E.A.; Buchanan, B.G.; Lederberg, J. On generality and problem solving: A case study using the DENDRAL program. Mach. Intell. 1971, 6, 165–190. [Google Scholar]
- Aliev, R.A.; Pedrycz, W.; Huseynov, O.H.; Eyupoglu, S.Z. Approximate reasoning on a basis of Z-number-valued if–then rules. IEEE Trans. Fuzzy Syst. 2017, 25, 1589–1600. [Google Scholar] [CrossRef]
- Tang, Y.; Pedrycz, W. Oscillation-bound estimation of perturbations under Bandler-Kohout subproduct. IEEE Trans. Cybern. 2022, 52, 6269–6282. [Google Scholar] [CrossRef]
- Michael, N. Artificial Intelligence, 2nd ed.; Addison-Wesley: Boston, MA, USA, 2005. [Google Scholar]
- Pandit, M. Expert system–A review article. Int. J. Eng. Sci. Res. Technol. 2013, 2, 1583–1585. [Google Scholar]
- Alma, Z.; Mansiya, K.; Torgyn, M.; Marzhan, M.; Kanat, N. The methodology of expert systems. Int. J. Comput. Sci. Netw. Secur. 2014, 14, 62–63. [Google Scholar]
- Ahmed, I.M.; Alfonse, M.; Aref, M.; Salem, A.-B.M. Reasoning Techniques for Diabetics Expert Systems. Procedia Comput. Sci. 2015, 65, 813–820. [Google Scholar] [CrossRef]
- Bennett, C.C.; Doub, T.W. Chapter 2—Expert Systems in Mental Health Care: AI Applications in Decision-Making and Consultation. In Artificial Intelligence in Behavioral and Mental Health Care; Academic Press: Cambridge, MA, USA, 2016; pp. 27–51. [Google Scholar]
- Bullon, J.; González Arrieta, A.; Hernández Encinas, A.; Queiruga Dios, A. Manufacturing processes in the textile industry. Expert Systems for fabrics production. Adv. Distrib. Comput. Artif. Intell. J. 2017, 6, 41–50. [Google Scholar]
- Ahmed, K.; Shahid, S.; Haroon, S.B.; Wang, X.J. Multilayer perceptron neural network for downscaling rainfall in arid region: A case study of Baluchistan, Pakistan. J. Earth Syst. Sci. 2015, 124, 1325–1341. [Google Scholar] [CrossRef]
- Deng, Y.; Zhou, X.; Shen, J.; Xiao, G.; Hong, H.; Lin, H.; Wu, F.; Liao, B.Q. New methods based on back propagation (BP) and radial basis function (RBF) artificial neural networks (ANNs) for predicting the occurrence of haloketones in tap water. Sci. Total Environ. 2021, 772, 145534. [Google Scholar] [CrossRef]
- Gholipour, C.; Rahim, F.; Fakhree, A.; Ziapour, B. Using an Artificial Neural Networks (ANNs) Model for Prediction of Intensive Care Unit (ICU) Outcome and Length of Stay at Hospital in Traumatic Patients. J. Clin. Diagn. Res. 2015, 9, OC19–OC23. [Google Scholar] [CrossRef]
- Kumari, R.; Kumar, S.; Paonia, R.C.; Singh, V.; Raja, L.; Bhatnagar, V.; Agarwal, P. Analysis and predictions of spread, recovery, and death caused by COVID-19 in India. Big Data Min. Anal. 2021, 4, 65–75. [Google Scholar] [CrossRef]
- Duan, Y.; Edwards, J.S.; Dwivedi, Y.K. Artificial intelligence for decision making in the era of Big Data—evolution, challenges and research agenda. Int. J. Inf. Manag. 2019, 48, 63–71. [Google Scholar] [CrossRef]
- Tkatek, S.; Belmzoukia, A.; Nafai, S.; Abouchabaka, J.; Ibnou-Ratib, Y. Putting the world back to work: An expert system using big data and artificial intelligence in combating the spread of COVID-19 and similar contagious diseases. Work 2020, 67, 557–572. [Google Scholar] [CrossRef] [PubMed]
- Choi, D.; Lee, H.; Bok, K.; Yoo, J. Design and implementation of an academic expert system through big data analysis. J. Supercomput. 2021, 77, 7854–7878. [Google Scholar] [CrossRef]
- Malki, Z.; Atlam, E.S.; Ewis, A.; Dagnew, G.; Ghoneim, O.A.; Mohamed, A.A.; Abdel-Daim, M.M.; Gad, I. The COVID-19 pandemic: Prediction study based on machine learning models. Environ. Sci. Pollut. Res. 2021, 28, 40496–40506. [Google Scholar] [CrossRef]
- Khalilpourazari, S.; Hashemi Doulabi, H. Designing a hybrid reinforcement learning based algorithm with application in prediction of the COVID-19 pandemic in Quebec. Ann. Oper. Res. 2022, 312, 1261–1305. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Khelifi, A.; Khan, W.A.; Raza, H.M.E.; Idrees, M.; Luo, S.; Hameed, I.A. Disease diagnosis system using IoT empowered with fuzzy inference system. Comput. Mater. Contin. 2022, 7, 5305–5319. [Google Scholar]
- Kumar, V.; Minz, S. Feature Selection: A literature Review. Smart Comput. Rev. 2014, 4, 211–229. [Google Scholar] [CrossRef]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1200–1205. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A Survey of Feature Selection and Feature Extraction Techniques in Machine Learning. In Proceedings of the Science and Information Conference 2014, London, UK, 27–29 August 2014. [Google Scholar]
- Chen, Y.K.; Wang, C.Y.; Feng, Y.Y. Application of a 3NN+ 1 based CBR system to segmentation of the notebook computers market. Expert Syst. Appl. 2010, 37, 276–281. [Google Scholar] [CrossRef]
- Siedlecki, W.; Sklanski, J. A note on genetic algorithms for large-scale feature selection. Pattern Recognit. Lett. 1989, 10, 335–347. [Google Scholar] [CrossRef]
- Lin, J.Y.; Ke, H.R.; Chien, B.C.; Yang, W.P. Classifier design with feature selection and feature extraction using layered genetic programming. Expert Syst. Appl. 2008, 34, 1284–1293. [Google Scholar] [CrossRef]
- Quan, C.; Ren, F. Unsupervised product feature extraction for feature-oriented opinion determination. Inf. Sci. 2014, 272, 16–28. [Google Scholar] [CrossRef]
- Zhang, X.L.; Chen, W.; Wang, B.J.; Chen, X.F. Intelligent fault diagnosis of rotating machinery using support vector machine with ant colony algorithm for synchronous feature selection and parameter optimization. Neurocomputing 2015, 167, 260–279. [Google Scholar] [CrossRef]
- Aalaei, S.; Shahraki, H.; Rowhanimanesh, A.; Eslami, S. Feature selection using genetic algorithm for breast cancer diagnosis: Experiment on three different datasets. Iran. J. Basic Med. Sci. 2016, 19, 476. [Google Scholar]
- Aličković, E.; Subasi, A. Breast cancer diagnosis using GA feature selection and Rotation Forest. Neural Comput. Appl. 2017, 28, 753–763. [Google Scholar] [CrossRef]
- Gokulnath, C.B.; Shantharajah, S.P. An optimized feature selection based on genetic approach and support vector machine for heart disease. Clust. Comput. 2019, 22, 14777–14787. [Google Scholar] [CrossRef]
- Khan, M.U.; Aziz, S.; Akram, T.; Amjad, F.; Iqtidar, K.; Nam, Y.; Khan, M.A. Expert Hypertension Detection System Featuring Pulse Plethysmograph Signals and Hybrid Feature Selection and Reduction Scheme. Sensors 2021, 21, 247. [Google Scholar] [CrossRef]
- Kwon, Y.; Lee, J.; Park, J.H.; Kim, Y.M.; Kim, S.H.; Won, Y.J.; Kim, H.-Y. Osteoporosis Pre-Screening Using Ensemble Machine Learning in Postmenopausal Korean Women. Healthcare 2022, 10, 1107. [Google Scholar] [CrossRef]
- Khaire, U.M.; Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1060–1073. [Google Scholar] [CrossRef]
- Kiziloz, H.E. Classifier ensemble methods in feature selection. Neurocomputing 2021, 419, 97–107. [Google Scholar] [CrossRef]
- Yusup, N.; Zain, A.M.; Hashim, S.T.M. Evolutionary techniques in optimizing machining parameters: Review and recent applications (2007–2011). Expert Syst. Appl. 2012, 39, 9909–9927. [Google Scholar] [CrossRef]
- Zahraee, S.M.; Khalaji Assadi, M.; Saidur, R. Application of Artificial Intelligence Methods for Hybrid Energy System Optimization. Renew. Sustain. Energy Rev. 2016, 66, 617–630. [Google Scholar] [CrossRef]
- Li, S.; Fang, H.; Liu, X. Parameter optimization of support vector regression based on sine cosine algorithm. Expert Syst. Appl. 2018, 91, 63–77. [Google Scholar] [CrossRef]
- Krishnamoorthy, C.S.; Rajeev, S. Artificial Intelligence and Expert Systems for Artificial Intelligence Engineers; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Taguchi, G. Taguchi Methods/Design of Experiments; English edition; Dearborn MI/ASI: Tokyo, Japan, 1949. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Issue | Year | Reference |
|---|---|---|---|
| GA-based algorithm | Large set feature extraction | 1989 | [35] |
| GA-based algorithm | Diagnostic classification | 2008 | [36] |
| Comparative domain corpora | Product improvement | 2014 | [37] |
| Ant-colony-based algorithm | Fault diagnosis | 2015 | [38] |
| GA-based algorithm | Breast cancer diagnosis | 2016 | [39] |
| GA-based algorithm | Breast cancer diagnosis | 2017 | [40] |
| GA-based algorithm | Heart disease diagnosis | 2019 | [41] |
| Machine learning | Hypertension Detection | 2021 | [42] |
| Machine learning | Comparison of different classifier ensemble methods | 2021 | [43] |
| Machine learning | Prediction of osteoporosis | 2022 | [45] |
| Parameter | Level 1 | Level 2 | Level 3 |
|---|---|---|---|
| 200 × 100 | 400 × 50 | 100 × 200 | |
| CR | 0.5 | 0.75 | 1.0 |
| MR | 0.05 | 0.075 | 0.1 |
| Experiment | CR | MR | SN | ||||
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 0.0006010890 | 0.0006444215 | 0.0006394203 | −64.0492353808 |
| 2 | 1 | 2 | 2 | 0.0004591344 | 0.0013799845 | 0.0004216040 | −65.6009508154 |
| 3 | 1 | 3 | 3 | 0.0004056524 | 0.0004205735 | 0.0004056524 | −67.7348319371 |
| 4 | 2 | 1 | 2 | 0.0004388614 | 0.0005938607 | 0.0006411313 | −65.4242838171 |
| 5 | 2 | 2 | 3 | 0.0006394203 | 0.0006298676 | 0.0005938010 | −64.1511242272 |
| 6 | 2 | 3 | 1 | 0.0011535812 | 0.0006116809 | 0.0004205265 | −64.8091223273 |
| 7 | 3 | 1 | 3 | 0.0004344587 | 0.0006110492 | 0.0004362107 | −66.4448913140 |
| 8 | 3 | 2 | 1 | 0.0005938607 | 0.0005989994 | 0.0004195332 | −65.7611583377 |
| 9 | 3 | 3 | 2 | 0.0006485800 | 0.0004341845 | 0.0004500635 | −66.2389340652 |
| CR | MR | ||
|---|---|---|---|
| Level 1 | −197.3850181333 | −195.9184105119 | −194.6195160458 * |
| Level 2 | −194.3845303716 * | −195.5132333803 * | −197.2641686977 |
| Level 3 | −198.4449837169 | −198.7828883296 | −198.3308474783 |
| Feature | Selection |
|---|---|
| Descriptive variables of COVID-19 | |
| New confirmed cases | Selected |
| Hospital patients | Unselected |
| ICU patients | Selected |
| People vaccinated | Selected |
| People fully vaccinated | Selected |
| Stringency_index | Unselected |
| Demographic variables | |
| Population | Selected |
| Population density | Selected |
| Cardiovasc death rate | Unselected |
| Diabetes prevalence | Unselected |
| Hospital beds per thousand | Selected |
| median_age | Selected |
| Aged 65 older | Unselected |
| Aged 70 older | Selected |
| GDP per capital | Selected |
| Sum of Squares | Degree of Freedom | Mean Sum of Square | F-Test | p Value | |
|---|---|---|---|---|---|
| Between groups | 1.1043 × 10−5 | 2 | 5.52149 × 10−6 | 2.776 | 0.102 |
| Within groups | 2.38722 × 10−5 | 12 | 1.98935 × 10−6 | ||
| Total | 3.49152 × 10−5 | 14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ho, C.-T.; Wang, C.-Y. A Robust Design-Based Expert System for Feature Selection and COVID-19 Pandemic Prediction in Japan. Healthcare 2022, 10, 1759. https://doi.org/10.3390/healthcare10091759
Ho C-T, Wang C-Y. A Robust Design-Based Expert System for Feature Selection and COVID-19 Pandemic Prediction in Japan. Healthcare. 2022; 10(9):1759. https://doi.org/10.3390/healthcare10091759
Chicago/Turabian StyleHo, Chien-Ta, and Cheng-Yi Wang. 2022. "A Robust Design-Based Expert System for Feature Selection and COVID-19 Pandemic Prediction in Japan" Healthcare 10, no. 9: 1759. https://doi.org/10.3390/healthcare10091759
APA StyleHo, C. -T., & Wang, C. -Y. (2022). A Robust Design-Based Expert System for Feature Selection and COVID-19 Pandemic Prediction in Japan. Healthcare, 10(9), 1759. https://doi.org/10.3390/healthcare10091759