

Transforming Healthcare Analytics with FHIR: A Framework for Standardizing and Analyzing Clinical Data
 , , ,
, , ,
Abstract
:1. Background
1.1. Healthcare Data Analytics
- Descriptive: Refers to standard reporting types that depict current situations and problems.
- Predictive: Refers to simulation and modeling techniques that forecast trends and anticipate the outcomes of implemented actions.
- Prescriptive: Concerns financial, clinical optimization, and other outcomes.
1.2. Healthcare Data Analytics Using FHIR Data Standard
2. Literature Review
3. Materials
3.1. Required Outcomes
3.2. User Research and Inputs
3.3. Challenges
3.4. The Clinical Data Analysis Workflow Design
3.5. FHIR REST APIs Working Mechanism
4. FHIR Data Analytics Framework
- FHIR database
- FHIR Query Engine
- Mapping Algorithm
- FHIR Compliant Database (Relational Database model)
- Analytic Engine
- User Interface
4.1. FHIR Database
4.2. FHIR Query Engine Layer
| Algorithm 1. Algorithm to retrieved resources from FHIR database. |
| 1: Function Retrive_Resources() 2: define resource type, e.g., patient 3: define search parameters, e.g., resource id or any other attribute(s) 4: value = Read resource id 5: while (resources are available) do 6: GET [base-url]/RsourceName?id = value 7: end while 8: end function ** Retrive_Resources function ** |
Read (GET) Operation
4.3. Mapping Agent/Algorithm
4.3.1. Need of Mapping Algorithm
4.3.2. Role of Mapping Algorithm
| Algorithm 2. Mapping Algorithm (Transform JSON data to EMR format). |
| 1: Function void main () 2: Create Tables in MySQL database, once table for each resources type data and link these tables 3: Resource = Read (FHIR API resource) 4: Templet = Resource-Templet (Resource) 5: counter = Count(Temple) 6: while (counter > 0) do 7: If (Templet.Tag == Resource.Tag) then 8: Table. attribute = Resource.Tag.Value 9: end if 10: counter = counter − 1 11: end while 12: end function ** main function ** 13: ** This function used to compare Resource type ** 14: Function string Resource-Templet (Resource type) 15: ** Create one dimension array for all resources and stored their tags. This is pre-defined templet for all resources ** 16: define string Result 17: String Array List = [Patient, Condition, AllergyIntolerance, Practitioner, ServiceRequest, DiagnosticReport, Appointment, ………] 18: String Patient [] = [“identifier”, “name”, “telecom”, “address“, “gender” …………] 19: String Condition [] = [“identifier”, “clinical status”, “category”, “code” …………] 20: String AllergyIntolerance [] = [“identifier”, “clinical status”, “code”, …………] 21: String Practitioner [] = [“identifier”, “name”, “address”, “qualification”, …………] 22: String DiagnosticReport [] = [“identifier”, “baseOn” status”, “category”, “code”,…….…] 23: String ServiceRequest [] = [“identifier”, “baseOn” status”, “category”, “requester”,……] 24: String Appointment [] = [“identifier”, “status”, “appointmentType”, “priority”, …………] 25: If (type == Patient) then 26: Result = “Patient” 27: else if (type == Condition) then 28: Result = “Condition” 29: else if (type == AllergyIntolerance) then 30: Result = “AllergyIntolerance” 31: else if (type == Practitioner) then 32: Result = “Practitioner” 33: else if (type == DiagnosticReport) then 34: Result = ” DiagnosticReport” 35: else if (type == ServiceRequest) then 36: Result = “ServiceRequest” 37: else 38: Result = “Appointment” 39: end if 40: return (Result) 41: end function ** Resource-Templet function ** 42: ** This function used to count the total number of tags in the resource ** 43: Function int Count(String Templet) 44: int counter = Templet.length 45: return (counter) 46: end function ** Count function ** |
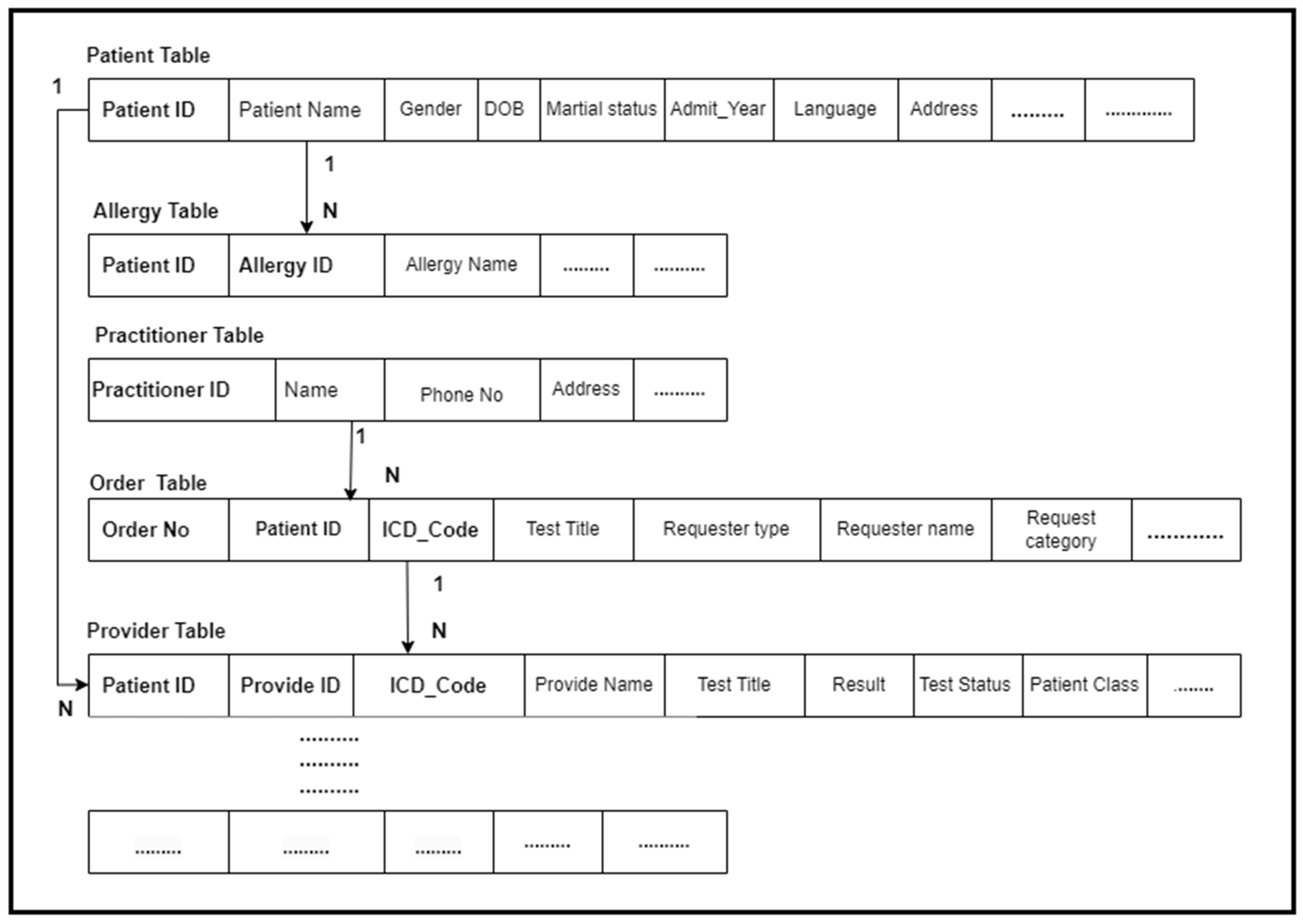
4.4. FHIR Compliant Database
4.5. Data Analytic Engine
4.6. User Interface
5. Methods/Implementation
6. Experiments
- Phase 1: In this step, we implemented our FHIR APIs and executed algorithms to retrieve the FHIR resources from the Mongo DB. Furthermore, we also executed a mapping algorithm to transform the FHIR resource data into the relational database tables.
- Phase 2: In this step, we executed various SQL queries to perform highly precise data analytics based on the defined use-cases and generate the required results.
7. Results
7.1. Use-Case 1
7.2. Use-Case 2
7.3. Use-Case 3
7.4. Use-Case 4
7.5. Use-Case 5
8. Limitations
- Our framework is currently developed under the FHIR R4 version and needs to be upgraded to the official FHIR R5 version when it gets finalized and released by HL7.
- Our framework might face issues in the coming FHIR version. HL7 FHIR specification requirements are changing over time, and the current resources might be replaced with any other new resources in the coming FHIR version. Additionally, the resource nature (from non-normative to normative) is changing over time. In this case, our framework might face challenges. Therefore, it needs to be updated in the coming FHIR versions if any of the mentioned cases happen. However, if none of these changes happen in the FHIR R5 version, it will work perfectly.
- Our framework executed multiple algorithms, such as the algorithm for accessing the FHIR resources via the RESTful APIs and the algorithm to map data from the FHIR resources to the EMR data format, and executed queries to perform data analytics for the end users. Therefore, the performance might not be ideal for every dataset. It worked excellently for our dataset (which is small), but the performance might be affected when dealing with large datasets, for example, when the number of resources and data elements in the dataset is in the billions or trillions.
- The interface of our framework works for our dataset (patient data used in patient registration systems and laboratory information systems); therefore, it would update if the workflow changed and included the data from other hospital information systems.
9. Discussion
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Safran, C.; Bloomrosen, M.; Hammond, W.E.; Labkoff, S.; Markel-Fox, S.; Tang, P.C.; Detmer, D.E. Toward a National Framework for the Secondary Use of Health. J. Am. Med. Inform. Assoc. 2007, 14, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trotter, F. Who Owns Patient Data? The Health Care Blog. 20 August 2012. Available online: http://thehealthcareblog.com/blog/2012/08/20/who-owns-patient-data/ (accessed on 4 December 2013).
- Hersh, W.R. Healthcare Data Analytics Learning Objectives. In Health Informatics: Practical Guide for Healthcare and Information Technology Professionals; Lulu: Morrisville, NC, USA, 2014. [Google Scholar]
- Hersh, W.R. Healthcare Data Analytics Learning Objectives. 2014. Available online: https://dmice.ohsu.edu/hersh/hoyt-14-analytics.pdf (accessed on 4 December 2022).
- Davenport, T.H.; Harris, J.G. Competing on Analytics: The New Science of Winning; Harvard Business School Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Anonymous. The Value of Analytics in Healthcare—From Insights to Outcomes; IBM Global Services: Somers, NY, USA, 2012; Available online: https://www-935.ibm.com/services/us/gbs/thoughtleadership/ibvhealthcare-analytics.html (accessed on 4 December 2022).
- Adams, J.; Klein, J. Business Intelligence and Analytics in Health Care—A Primer; The Advisory Board Company: Washington, DC, USA, 2011; Available online: https://www.advisory.com/Research/IT-Strategy-Council/Research-Notes/2011/Business-Intelligence-and-Analytics-in-Health-C (accessed on 6 December 2022).
- Gardner, E. The HIT Approach to Big Data. Health Data Management. 1 March 2013. Available online: http://www.healthdatamanagement.com/issues/21_3/The-HIT-Approach-to-Big-Data-Anayltics-45735-1.html (accessed on 30 November 2022).
- Sledge, G.W.; Miller, R.S.; Hauser, R. CancerLinQ and The Future of Cancer Care; ASCO Educational Book: Alexandria, VA, USA, 2013; pp. 430–434. Available online: http://meetinglibrary.asco.org/content/58-132 (accessed on 2 December 2022).
- Ayaz, M.; Pasha, M.F.; Alzahrani, M.Y.; Budiarto, R.; Stiawan, D. The Fast Health Interoperability Resources (FIHR) Standard: Systematic literature review of implementations, applications, challenges and opportunities. JMIR Med. Inform. 2021, 9, 1–21. [Google Scholar] [CrossRef]
- FHIR®—Fast Healthcare Interoperability Resources®. Available online: https://ecqi.healthit.gov/fhir (accessed on 10 February 2023).
- Braunstein, M.L. SMART on FHIR. Health Informatics on FHIR: How HL7’s New API Is Transforming Healthcare. 2018. Available online: https://link.springer.com/chapter/10.1007/978-3-319-93414-3_10 (accessed on 9 December 2022).
- Analytics and Data-Driven Healthcare to Be Fuelled by FHIR Interoperability Boost: InterSystems ANZ Study. Available online: https://healthcareasiamagazine.com/co-written-partner/analytics-and-data-driven-healthcare-be-fuelled-fhir-interoperability-boost-intersystems-anz-study (accessed on 4 December 2022).
- What Is FHIR: A Brief Overview of Its Role in Interoperability. Available online: https://edenlab.io/blog/what-is-fhir-a-brief-overview-of-its-role-in-interoperability (accessed on 4 December 2022).
- Grimes, J.; Szul, P.; Metke-Jimenez, A.; Lawley, M.; Loi, K. Pathling: Analytics on FHIR. J. Biomed. Semant. 2022, 13, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Lehne, M.; Luijten, S.; Vom Felde Genannt Imbusch, P.; Thun, S. The use of FHIR in digital health—A review of the scientific literature. Stud. Health Technol. Inform. 2019, 267, 52–58. [Google Scholar] [CrossRef] [PubMed]
- FHIR Analytics in Healthcare. Available online: https://qrvey.com/fhir-healthcare-analytics/ (accessed on 5 December 2022).
- Ajibade, S.-S.M.; Ayaz, M.; Ngo-Hoang, D.-L.; Tabuena, A.C.; Rabbi, F.; Tilaye, G.F.; Bassey, M.A. Analysis of Improved Evolutionary Algorithms Using Students’ Datasets. In Proceedings of the 2022 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Shah Alam, Malaysia, 25 June 2022; pp. 180–185. [Google Scholar] [CrossRef]
- Rabbi, F.; Ayaz, M.; Dayupay, J.P.; Oyebode, O.J.; Gido, N.G.; Adhikari, N.; Tabuena, A.C.; Ajibade, S.-S.M.; Bassey, M.A. Gaussian Map to Improve Firefly Algorithm Performance. In Proceedings of the 2022 IEEE 13th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 23 July 2022; pp. 88–92. [Google Scholar] [CrossRef]
- Ajibade, S.-S.M.; Zaidi, A.; Tapales, C.P.; Ngo-Hoang, D.-L.; Ayaz, M.; Dayupay, J.P.; Dodo, Y.A.; Chaudhury, S.; Adediran, A.O. Data Mining Analysis of Online Drug Reviews. In Proceedings of the 2022 IEEE 10th Conference on Systems, Process & Control (ICSPC), Malacca, Malaysia, 17 December 2022; pp. 247–251. [Google Scholar] [CrossRef]
- Giannangelo, K.; Fenton, S.H. SNOMED CT survey: An assessment of implementation in EMR/EHR applications. Perspect. Health Inf. Manag. 2008, 5, 7. [Google Scholar]
- Ayaz, M. Cloud Computing Base Electronic Health Record System Architecture for Disabled Children. Int. J. Multidiscip. Sci. Eng. 2017, 8, 24–28. [Google Scholar]
- 48% of Businesses, Including Healthcare, Face Big Data Skills Gap. Available online: https://healthitanalytics.com/news/48-of-businesses-including-healthcare-face-big-data-skills-gap (accessed on 6 December 2022).
- Ayaz, M. A Novel Model of Software Process Improvements for Small and Medium Scale Enterprises by using the Big Data Analytics Approach. Int. J. Multidiscip. Sci. Eng. 2017, 8, 1–10. Available online: www.ijmse.org (accessed on 12 December 2022).
- Ayaz, M. A Seminal Hybrid Business Process Management Model. Int. J. Multidiscip. Sci. Eng. 2017, 8, 38–42. [Google Scholar]
- Hong, N.; Prodduturi, N.; Wang, C.; Jiang, G. Shiny FHIR: An integrated framework leveraging shiny R and HL7 FHIR to empower standards-based clinical data applications. Stud. Health Technol. Inform. 2017, 245, 868–872. [Google Scholar] [CrossRef] [PubMed]
- Ayaz, M.; Pasha, M.F.; Le, T.Y.; Alahmadi, T.J.; Abdullah, N.N.B.; Alhababi, Z.A. A Framework for Automatic Clustering of EHR Messages Using a Spatial Clustering Approach. Healthcare 2023, 11, 390. [Google Scholar] [CrossRef] [PubMed]
- Shortliffe, E.H.; Cimino, J.J. Biomedical Informatics: Computer Applications in Health Care and Biomedicine; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Reddy, C.C.A.; Chandan, K. Healthcare Data Analytics; CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Hripcsak, G.; Duke, J.D.; Shah, N.H.; Reich, C.G.; Huser, V.; Schuemie, M.J.; Suchard, M.A.; Park, R.W.; Wong, I.C.K.; Rijnbeek, P.R.; et al. Observational Health Data Sciences and Informatics (OHDSI): Opportunities for Observational Researchers. Stud. Health Technol. Inform. 2015, 216, 574–578. [Google Scholar] [CrossRef] [PubMed]
- Observational Health Data Sciences and Informatics (OHDSI). ATLAS- A. Unified, Interface for The OHDSI Tools. 2018. Available online: https://www.ohdsi.org/software-tools/ (accessed on 16 December 2022).
- Ma, C.; Frankel, H.; Beale, T.; Heard, S. EHR query language (EQL)-A query language for archetype-based health records. Stud. Health Technol. Inform. 2007, 129, 397–401. [Google Scholar] [PubMed]
- The openehr Foundation. OpenEHR—Archetype Query Language (AQL). 2008. Available online: https://specifications.openehr.org/releases/QUERY/latest/AQL.html (accessed on 10 August 2022).
- Rezaul, K.M.D.; Nguyen, B.-P.; Zimmermann, L.; Kirsten, T.; Löbe, M.; Meineke, F.; Stenzhorn, H.; Kohlbacher, O.; Decker, S.; Beyan, O. A distributed analytics platform to execute fhir-based phenotyping algorithms. CEUR Workshop Proc. 2018, 2275, 1–10. [Google Scholar]
- Lakshman, V.; Amrollahi, F.; Koppisetty, V.S.; Shashikumar, S.P.; Sharma, A.; Nemati, S. DeepAISE on FHIR—An Interoperable Real-Time Predictive Analytic Platform for Early Prediction of Sepsis. In Proceedings of the AMIA Annual Symposium, Washington, DC, USA, 8–12 November 2018; pp. 1–3. Available online: https://par.nsf.gov/servlets/purl/10084140 (accessed on 12 December 2022).
- Khalilia, M.; Choi, M.; Henderson, A.; Iyengar, S.; Braunstein, M.; Sun, J. Clinical Predictive Modeling Development and Deployment through FHIR Web Services. In Proceedings of the MIA Annual Symposium, San Francisco, CA, USA, 14–18 November 2015; Volume 2015, pp. 717–726. [Google Scholar]
- doc.ai Is on FHIR. Available online: https://medium.com/@docai/doc-ai-is-on-fire-oops-we-mean-fhir-ea2912b2864b (accessed on 30 January 2023).
- Semler, S.C.; Wissing, F.; Heyder, R. German Medical Informatics Initiative. Methods Inf. Med. 2018, 57, e50–e56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kreuzthaler, M.; Martínez-Costa, C.; Kaiser, P.; Schulz, S. Semantic technologies for re-use of clinical routine data. Stud. Health Technol. Inform. 2017, 236, 24–31. [Google Scholar] [CrossRef] [PubMed]
- Franz, B. Applying FHIR in an Integrated Health Monitoring System. Eur. J. Biomed. Inform. 2015, 11, 51–56. [Google Scholar] [CrossRef]
- Liu, D.; Sahu, R.; Ignatov, V.; Gottlieb, D.; Mandl, K.D. High Performance Computing on Flat FHIR Files Created with the New SMART/HL7 Bulk Data Access Standard. In Proceedings of the AMIA Annual Symposium, Washington, DC, USA, 16–20 November 2019; Volume 2019, pp. 592–596. [Google Scholar]
- Apache Software Foundation. Apache Parquet. 2015. Available online: https://parquet.apache.org/ (accessed on 10 August 2022).
- Dunn, T.; Cosgun, E. A cloud-based pipeline for analysis of FHIR and long-read data. Bioinforma. Adv. 2023, 3, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Gruendner, J.; Gulden, C.; Kampf, M.; Mate, S.; Prokosch, H.U.; Zierk, J. A framework for criteria-based selection and processing of fast healthcare interoperability resources (FHIR) data for statistical analysis: Design and implementation study. JMIR Med. Inform. 2021, 9, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Cerner Innovation. Cerner/Bunsen: Explore, Transform, and Analyze FHIR Data with Apache Spark. 2017. Available online: https://github.com/cerner/bunsen (accessed on 10 August 2022).
- IZaharia, S.M.; Chowdhury, M.; Franklin, M.J.; Shenker, S. Spark: Cluster Computing with Working Sets. 2010, pp. 1–7. Available online: https://www1.icsi.berkeley.edu/pubs/networking/ICSI_sparkclustercomputing10.pdf (accessed on 21 December 2022).
- Brush, R. FHIR/sql-on-fhir: SQL on FHIR Proposal. 2018. Available online: https://github.com/FHIR/sql-on-fhir (accessed on 10 August 2022).
- Google. Protocol Buffers|Google Developers. 2012. Available online: https://developers.google.com/protocol-buffers/ (accessed on 10 August 2022).
- Google. google/fhir: FHIR Protocol Buffers. 2018. Available online: https://github.com/google/fhir (accessed on 10 August 2022).
- Chong, D.; Shi, H. Big data analytics: A literature review. J. Manag. Anal. 2015, 2, 175–201. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Descriptions |
|---|---|
| 1 | Investigate registered patients in healthcare settings |
| 2 | Investigate registered patients in healthcare settings within a specified timeframe |
| 3 | Investigate patients having various types of allergies |
| 4 | Investigate various types of tests ordered by a physician, organization, etc. |
| 5 | Investigate various types of tests ordered by a physician, organization, etc., within a specified timeframe |
| No | Resource Type | Total Resources |
|---|---|---|
| 1 | Patient | 100 |
| 2 | AllergyIntolerance | 100 |
| 3 | Practitioner | 100 |
| 4 | ServiceRequest | 100 |
| 5 | DiagnosticReport | 100 |
| 6 | Condition | 100 |
| 7 | Appointment | 100 |
| Male | Female |
|---|---|
| 55 | 45 |
| Year’s | 1950 | 1951 | 1952 | 1953 | 1955 | ------ | 2013 | 2018 | 2021 |
|---|---|---|---|---|---|---|---|---|---|
| Patient’s No | 3 | 1 | 3 | 2 | 1 | ------ | 3 | 1 | 2 |
| No | Allergy | No’s of Patients |
|---|---|---|
| 1 | Shellfish | 9 |
| 2 | Glyburide | 8 |
| 3 | Latex | 5 |
| 4 | Coal Tar | 6 |
| 5 | Neomycin | 12 |
| 6 | Codeine | 8 |
| 7 | IVP Dye | 10 |
| 8 | Caffeine | 5 |
| 9 | Levaquin | 5 |
| 10 | Seafood | 6 |
| 11 | Rifampin | 3 |
| 12 | Norco | 6 |
| 13 | Penicillium | 5 |
| 14 | Benztropine | 6 |
| 15 | Watermelon | 3 |
| 16 | Metoprolol | 2 |
| 17 | IV Dye | 1 |
| Test Name | HIV | CBC | CT SCAN | X-Ray Ankle | MRI | Blood Culture | COVID | SGPT |
|---|---|---|---|---|---|---|---|---|
| Tests order Percentage | 16 | 15 | 15 | 14 | 12 | 10 | 9 | 9 |
| Year’s | 1951 | 1952 | 1953 | 1955 | ---- | 2010 | 2015 | 2019 | 2020 |
|---|---|---|---|---|---|---|---|---|---|
| Number of tests order | 4 | 4 | 3 | 2 | 5 | 3 | 6 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayaz, M.; Pasha, M.F.; Alahmadi, T.J.; Abdullah, N.N.B.; Alkahtani, H.K. Transforming Healthcare Analytics with FHIR: A Framework for Standardizing and Analyzing Clinical Data. Healthcare 2023, 11, 1729. https://doi.org/10.3390/healthcare11121729
Ayaz M, Pasha MF, Alahmadi TJ, Abdullah NNB, Alkahtani HK. Transforming Healthcare Analytics with FHIR: A Framework for Standardizing and Analyzing Clinical Data. Healthcare. 2023; 11(12):1729. https://doi.org/10.3390/healthcare11121729
Chicago/Turabian StyleAyaz, Muhammad, Muhammad Fermi Pasha, Tahani Jaser Alahmadi, Nik Nailah Binti Abdullah, and Hend Khalid Alkahtani. 2023. "Transforming Healthcare Analytics with FHIR: A Framework for Standardizing and Analyzing Clinical Data" Healthcare 11, no. 12: 1729. https://doi.org/10.3390/healthcare11121729
APA StyleAyaz, M., Pasha, M. F., Alahmadi, T. J., Abdullah, N. N. B., & Alkahtani, H. K. (2023). Transforming Healthcare Analytics with FHIR: A Framework for Standardizing and Analyzing Clinical Data. Healthcare, 11(12), 1729. https://doi.org/10.3390/healthcare11121729