

A Study on Online Health Community Users’ Information Demands Based on the BERT-LDA Model

Abstract
:1. Introduction
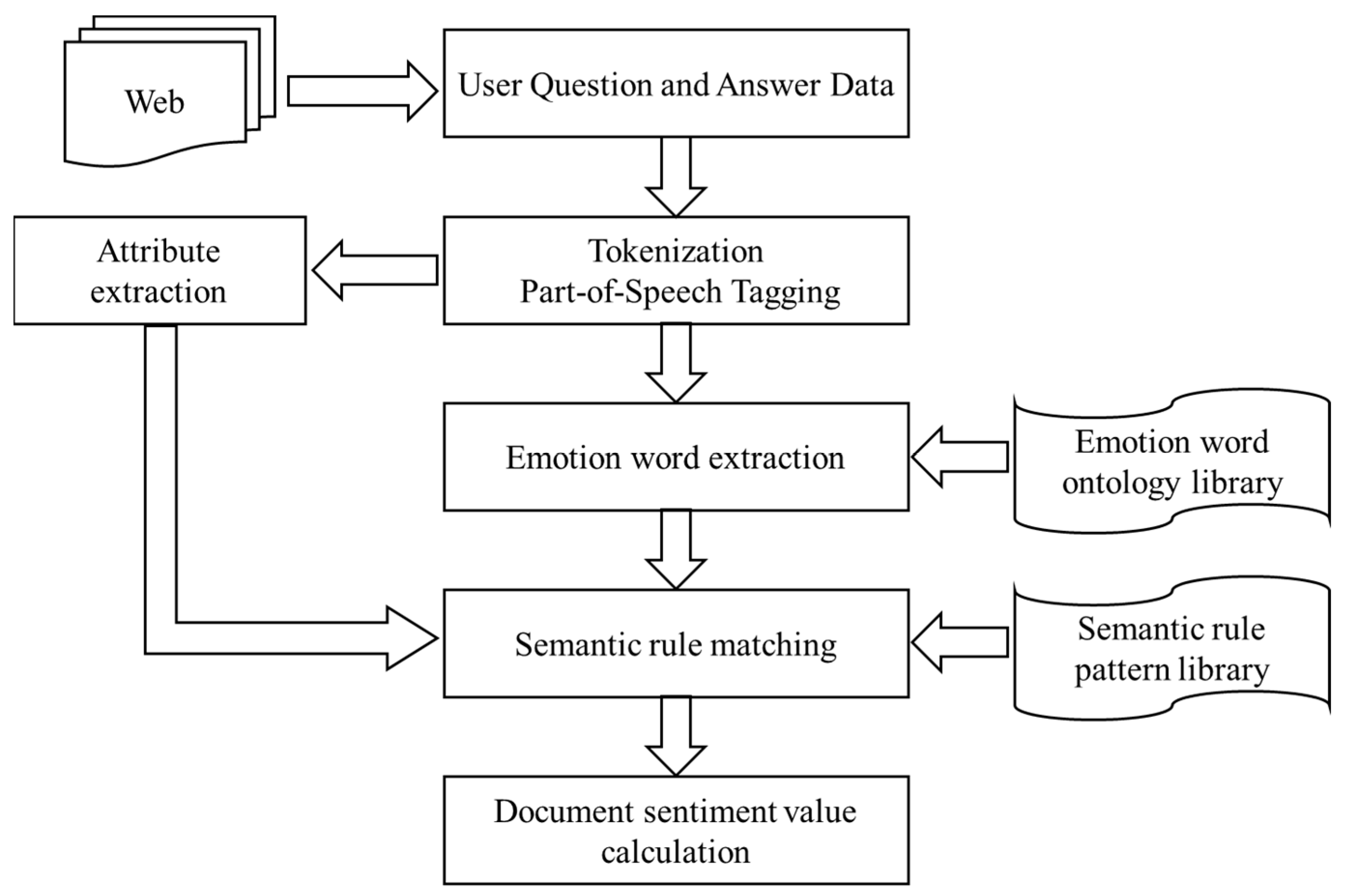
2. Methods
2.1. Dataset Construction and Preprocessing
2.2. Model Construction
2.2.1. LDA Topic Extraction Optimization Model
2.2.2. BERT Deep Learning Model
2.3. Sentiment Analysis
3. Result
3.1. Data Collection and Preprocessing
3.2. Health Information Demands Topic Identification
3.3. The Sentiment Analysis of Health Information Demands Topics
3.3.1. Subject–Emotion Correlation Analysis
3.3.2. Topic Sentiment Orientation Analysis
3.4. Model Comparison Analysis
4. Discussion
- (1)
- This research paper utilizes text mining techniques to investigate the specific health information demands of users in online health communities. The study analyzes the characteristics of the content and emotions expressed in these information demands, as well as the underlying reasons behind them. The findings of the study reveal that users in online health communities have a wide range of health information demands, which can be classified into nine main topics. These topics include causes of illnesses, symptoms and manifestations experienced, examinations and diagnoses, treatment options, self-regulation techniques, the impact of the illness on their lives, prevention strategies, social aspects related to their health, and acquiring knowledge about their condition. The study further highlights that users’ information demands primarily revolve around physical sensations, physiological changes, emotional fluctuations, and information related to their treatment options. However, they show less interest in general health information, such as overall health knowledge and disease prevention. When it comes to topics dominated by symptoms and causes, users tend to express their information demands in an objective manner, using professional terms like examination indices and disease names. Their language is concise, direct, and lacks strong emotional features. On the other hand, topics related to life and emotions reveal a greater emotional diversity among users. In these topics, users use more casual and colloquial language, provide more detailed descriptions, and express a wider range of emotions. As a result, the study finds that users’ emotional expressions exhibit a characteristic of centrality across different topics. This means that most emotions are concentrated and significantly correlated with only a few specific topics.
- (2)
- The examination of user sentiment within online health communities discloses a pronounced predominance of negative emotions. As the study substantiates, this emotive climate significantly shapes users’ information-seeking behaviors, engendering a distinctive nexus between emotions and information demand. Negative emotions, frequently serving as a catalyst, propel users towards the consumption of health-related information. Intriguingly, the study also detects a crucial component of support-seeking behavior within these communities. Users exhibit a noticeable inclination for supportive and uplifting sentiments, highlighting the emotional role these online communities fulfill in tandem with their function as health information platforms. This intricate interconnection between users’ information demands, their emotional state, and the supportive environment they aspire to foster within online health communities accentuates the multifaceted nature of these platforms. Their role transcends the bounds of mere repositories of health information, morphing into a sanctuary offering empathy and emotional succor. This revelation necessitates a reassessment of strategies for managing and moderating online health communities, suggesting an increased need for empathetic and emotionally intelligent AI models, alongside personalized health information services. Acknowledging the emotional undercurrent in the information-seeking process and provisioning an environment responsive to this requirement could be instrumental in bolstering user engagement and enhancing the overall user experience within online health communities.
- (3)
- Within online health communities, users frequently confront numerous challenges in their pursuit of disease-related information. The current dissemination of disease-associated knowledge is somewhat constrained, resulting in a narrow understanding of relevant illnesses among community members. Therefore, patients’ information requirements typically gravitate towards symptoms and diagnostic results pertinent to their conditions. Regarding emotional and psychological issues potentially implicating personal privacy, users have demonstrated a preference for leveraging online health communities [48,49], as evidenced by data harvested from the “Haodf” platform. However, the information-seeking journey within these communities is not devoid of difficulties. Users regularly grapple with an overwhelming abundance of data related to obscure illnesses, which presents a significant obstacle to the pinpointing of germane information. Inquiries lodged by users often go unaddressed or receive contributions from non-expert sources, leading to the proliferation of unverified information. Additionally, users’ shared experiences with various diseases frequently go unnoticed, culminating in incomplete information. As users seek disease information, they often encounter issues such as nebulous sources, insufficient evidence, misinformation, or even malevolent rumors. These factors precipitate information confusion and undermine reliability, thwarting the complete integration and utilization of the vast resources accessible within online health communities. Nevertheless, despite these impediments, the preference for online health communities for information procurement, especially in privacy-sensitive matters, underscores the pivotal role these platforms occupy in health information dissemination [50,51].
- (4)
- The findings of this study are in alignment with existing literature in several aspects, providing a deeper interpretation through the comparison and contrast with previous research. Consistent with studies that focus on online health communities and social media [20,21,22,46], this study explores the impact of individual factors, such as motivation, on users’ willingness to obtain and distribute health information. The results confirm that users primarily seek information related to their specific conditions, such as symptoms, examination results, and treatment options while showing less interest in general health information like disease prevention. This study’s findings are in line with Liu et al.’s research, which found a slight positive relationship between the number of users expressing negative emotions and the size of an online health community. This suggests that negative emotions play a significant role in driving the demand for information in these communities. Additionally, the results align with previous studies on Facebook, which examined the types of users seeking emotional support and highlighted the positive effects of such support. Like these studies, our findings indicate that users prefer to receive supportive and uplifting emotions through online health communities. Moreover, the sentiment tendencies identified in this study are similar to those found by Vydiswaran et al. [26]. This highlights the significance of understanding the connection between users’ health demands and emotional demands in order to improve the efficiency of information retrieval and explain information behavior. In conclusion, this study demonstrates that the results align with previous research and emphasizes the demand to take into account both individual factors and emotional expression when addressing the information demands of users in online health communities.
5. Conclusions
5.1. Possible Research Contributions
5.2. Limitations and Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- CNNIC. The 49th Survey on the Development of the Internet in China. 2022. Available online: https://cnnic.cn/n4/2022/0401/c88-1131.html (accessed on 24 April 2023).
- Yip, W.; Fu, H.; Chen, A.T.; Zhai, T.; Jian, W.; Xu, R. 10 years of health-care reform in China: Progress and gaps in Universal Health Coverage. Lancet 2019, 394, 1192–1204. [Google Scholar] [CrossRef]
- Hesse, B.W.; Nelson, D.E.; Kreps, G.L.; Croyle, R.T.; Arora, N.K.; Rimer, B.K. Trust and sources of health information: The impact of the Internet and its implications for health care providers: Findings from the first Health Information National Trends Survey. Arch. Intern. Med. 2005, 165, 2618–2624. [Google Scholar] [CrossRef] [Green Version]
- Chung, J.E. Social networking in online support groups for health: How online social networking benefits patients. J. Health Commun. 2014, 19, 639–659. [Google Scholar] [CrossRef]
- Zhang, X.; Guo, X.; Lai, K.H.; Guo, F.; Li, C. Understanding gender differences in m-health adoption: A modified theory of reasoned action model. Telemed. e-Health 2014, 20, 39–46. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, F.; Hsieh, P.A. Adoption of an online health community for mental health: The influence of the social network on mental health self-disclosure. Health Inform. J. 2018, 24, 268–278. [Google Scholar]
- Eysenbach, G. Medicine 2.0: Social networking, collaboration, participation, apomediation, and openness. J. Med. Internet Res. 2008, 10, e22. [Google Scholar] [CrossRef]
- Oh, H.J.; Ozkaya, E.; LaRose, R. How does online social networking enhance life satisfaction? The relationships among online supportive interaction, affect, perceived social support, sense of community, and life satisfaction. Comput. Human Behav. 2014, 30, 69–78. [Google Scholar] [CrossRef]
- Coulson, N.S. Sharing, supporting and sobriety: A qualitative analysis of messages posted to alcohol-related online discussion forums in the United Kingdom. J. Subst. Use 2014, 19, 176–180. [Google Scholar] [CrossRef]
- Wang, T.H.; Zhou, X.F.; Ni, Y.; Pan, Z.G. Health information demands regarding diabetes mellitus in China: An internet based analysis. BMC Public Health 2020, 20, 990. [Google Scholar] [CrossRef]
- Park, A.; Conway, M.; Chen, A.T. Examining thematic similarity, difference, and membership in three online mental health communities from Reddit: A text mining and visualization approach. Comput. Human Behav. 2018, 78, 98–112. [Google Scholar] [CrossRef]
- Roberts, K.; Kilicoglu, H.; Fiszman, M.; Demner-Fushman, D. Automatically classifying question types for consumer health questions. AMIA Annu. Symp. Proc. 2014, 2014, 1018–1027. [Google Scholar] [PubMed]
- Sereku, P.; Deirmenciler, B.; Sevgizkan, O. Internet use by pregnant women seeking childbirth information. J. Gynecol. Obstet. Hum. Reprod. 2021, 50, 102144. [Google Scholar]
- Demiris, G. The diffusion of virtual communities in health care: Concepts and challenges. Patient Educ. Couns. 2006, 62, 178–188. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, Y.; Zhu, Q. An empirical study on health information demands of elderly users in online health communities. Libr. Inf. Serv. 2019, 63, 87–96. [Google Scholar]
- Xu, W.W.; Chiu, I.H.; Chen, Y.; Mukherjee, T. Twitter hashtags for health: Applying network and content analyses to understand the health knowledge sharing in a Twitter-based community of practice. Qual. Quant. 2015, 49, 1361–1380. [Google Scholar] [CrossRef]
- Shih, S.N.; Gau, M.L.; Tsai, J.C. A health need satisfaction instrument for Taiwan′s single-living older people with chronic disease in the community. J. Clin. Nurs. 2008, 17, 67–77. [Google Scholar] [CrossRef]
- Xu, X.; Yang, M.; Song, X. Exploring the impact of physicians’ word of mouth on patients’ selection in online health community: Taking the website of www.haodf.com as an example. J. Mod. Inf. 2019, 39, 20–28. [Google Scholar]
- Li, C.; Li, H.; Suomi, R.; Liu, Y. Knowledge sharing in online smoking cessation communities: A social capital perspective. Internet Res. 2022, 32, 111–138. [Google Scholar] [CrossRef]
- Wu, X.; Kuang, W. Exploring influence factors of wechat users’ health information sharing behavior: Based on an integrated model of TPB, UGT, and SCT. Int. J. Hum.-Comput. Interact. 2021, 37, 1243–1255. [Google Scholar] [CrossRef]
- Hong, Y.; Wan, M.; Li, Z. Understanding the health information sharing behavior of social media users: An empirical study on WeChat. J. Organ. End User Comput. 2021, 33, 180–203. [Google Scholar] [CrossRef]
- Lin, H.C.; Ho, W.H. Cultural effects on use of online social media for health-related information acquisition and sharing in Taiwan. Int. J. Hum. Comput. Interact. 2018, 34, 1063–1076. [Google Scholar] [CrossRef]
- Liu, C.; Lu, X. Analyzing hidden populations online: Topic, emotion, and social network of HIV-Related users in the largest Chinese online community. BMC Med. Inform. Decis. Mak. 2018, 18, 2. [Google Scholar] [CrossRef] [Green Version]
- Wright, K.B. Emotional support and perceived stress among college students using facebook.com: An exploration of the relationship between source perceptions and emotional support. Commun. Res. Rep. 2012, 29, 175–184. [Google Scholar] [CrossRef]
- Zhang, Y.; He, D.; Sang, Y. Facebook as a platform for health information and communication: A case study of a diabetes group. J. Med. Syst. 2013, 37, 9942. [Google Scholar] [CrossRef]
- Vydiswaran, V.G.V.; Zhai, C.X.; Roth, D. Gauging the internet doctor: Ranking medical claims based on community knowledge. In Proceedings of the International Workshop on Data Mining for Medicine and Healthcare, San Diego, CA, USA, 21 August 2011; pp. 42–512. [Google Scholar]
- Bekhuis, T.; Kreinacke, M.; Spallek, H.; Song, M.; O′Donnell, J.A. Using natural language processing to enable in-depth analysis of clinical messages posted to an internet mailing list: A feasibility study. J. Med. Internet Res. 2011, 13, 98. [Google Scholar] [CrossRef] [Green Version]
- Chen, A.T. Exploring online support spaces: Using cluster analysis to examine breast cancer, diabetes and fibromyalgia support groups. Patient Educ. Couns. 2012, 87, 250–257. [Google Scholar] [CrossRef]
- Madzin, H.; Zainuddin, R.; Sharef, N.M. IFM3IRS: Information fusion retrieval system with knowledge-assisted text and visual features based on medical conceptual model. Multimed. Tools Appl. 2015, 74, 3651–3674. [Google Scholar] [CrossRef]
- Balakrishnan, A.; Idicula, S.M.; Jones, J. Deep learning based analysis of sentiment dynamics in online cancer community forums: An experience. Health Inform. J. 2021, 27, 14604582211007537. [Google Scholar] [CrossRef]
- Zhang, S.; Grave, E.; Sklar, E.; Elhadad, N. Longitudinal analysis of discussion topics in an online breast cancer community using convolutional neural networks. J. Biomed. Inform. 2017, 69, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Chang, J.; Boyd-Graber, J.; Wang, C.; Gerrish, S.; Blei, D.M. Reading tea leaves: How humans interpret topic models. In Proceedings of the 23rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 288–296. [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Guo, J.; Lan, Y.; Cheng, X. A biterm topic model for short texts. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1445–1456. [Google Scholar]
- Jo, Y.; Oh, A.H. Aspect and sentiment unification model for online review analysis. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 815–824. [Google Scholar]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF-IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Kumari, R.; Jeong, J.Y.; Lee, B.H.; Choi, K.N.; Choi, K. Topic modelling and social network analysis of publications and patents in humanoid robot technology. J. Inf. Sci. 2021, 47, 658–676. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Tan, X.; Zhuang, M.; Lu, X.; Mao, T. An analysis of the emotional evolution of large-scale Internet public opinion events based on the BERT-LDA hybrid model. IEEE Access 2021, 9, 15860–15871. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Korsvold, L.; Mellblom, A.V.; Finset, A.; Ruud, E.; Lie, H.C. A content analysis of emotional concerns expressed at the time of receiving a cancer diagnosis: An observational study of consultations with adolescent and young adult patients and their family members. Eur. J. Oncol. Nurs. 2017, 26, 1–8. [Google Scholar] [CrossRef]
- Chuang, J.; Manning, C.D.; Heer, J. Termite: Visualization techniques for assessing textual topic models. Proc. Int. Work. Conf. Adv. Vis. Interfaces 2012, 5, 74–77. [Google Scholar]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. Proc. Int. Joint Conf. Nat. Lang. Process. 2014, 2, 63–72. [Google Scholar]
- Zhang, X.; Liu, S.; Deng, Z.; Chen, X. Knowledge sharing motivations in online health communities: A comparative study of health professionals and normal users. Comput. Hum. Behav. 2017, 75, 797–810. [Google Scholar] [CrossRef]
- Liu, W.; Chen, X.; Lu, X.; Fan, X. Corrigendum: Exploring the Relationship Between Users’ Psychological Contracts and Their Knowledge Contribution in Online Health Communities. Front. Psychol. 2021, 12, 716702. [Google Scholar]
- Li, L.; Hua, L.; Gao, F. What We Ask about When We Ask about Quarantine? Content and Sentiment Analysis on Online Help-Seeking Posts during COVID-19 on a Q&A Platform in China. Int. J. Environ. Res. Public Health 2022, 20, 780. [Google Scholar] [PubMed]
- Gao, Y.; Gong, L.; Liu, H.; Kong, Y.; Wu, X.; Guo, Y.; Hu, D. Research on the influencing factors of users’ information processing in online health communities based on heuristic-systematic model. Front. Psychol. 2022, 13, 966033. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Chen, X.; Hong, Y. Evolutionary Game—Theoretic Approach for Analyzing User Privacy Disclosure Behavior in Online Health Communities. Appl. Sci. 2022, 12, 6603. [Google Scholar] [CrossRef]
- Wu, B.; Luo, P.; Li, M.; Hu, X. The Impact of Health Information Privacy Concerns on Engagement and Payment Behaviors in Online Health Communities. Front. Psychol. 2022, 13, 861903. [Google Scholar] [CrossRef]
- Lu, Y.; Luo, S.; Liu, X. Development of Social Support Networks by Patients with Depression Through Online Health Communities: Social Network Analysis. JMIR Med. Inform. 2021, 9, e24618. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic | Top 5 High Probability Keywords | Topic | Top 5 High Probability Keywords |
|---|---|---|---|
| Topic 1 | Chemotherapy, Over a month, Nasal congestion, Runny nose | Topic 19 | Hospitalization, Adjustment, Diabetes, Phone call, Patients |
| Topic 2 | Body, Abdomen, Solutions, Cervix, Joints | Topic 20 | Epidemic, Outpatient, Report, Myoma, Taking medication |
| Topic 3 | Ears, Complete blood count, Location, Issues, Lymph nodes | Topic 21 | Follow-up examination, Examination, Timing, Fetal bud, Condition |
| Topic 4 | Symptoms, Common, Abdominal pain, Discharge, Brownish | Topic 22 | Attack, Indicators, Doctor, Urine protein, Kidney disease |
| Topic 5 | Skin, Hyperthyroidism, Medication, Diseases, Fingers | Topic 23 | small blister, Red, Child, Etiology, Tongue |
| Topic 6 | Pain, Patients, Guidance, Unable to, Triggers | Topic 24 | Plan, Surgery, Examination, Hepatitis B, Family members |
| Topic 7 | Results, Asthma, Hypertension, Blood lipid, Calcium supplements | Topic 25 | Eczema, Anus, Prostatitis, Lymph nodes, Buttocks |
| Topic 8 | Doctor, Cell, Pathology, Doubt, Premature baby | Topic 26 | Rash, Doctor, Red rash, Nerves, Weight, Endocrine |
| Topic 9 | Glass, Month, Nodules, Ovaries, Whole body | Topic 27 | Condition, Doctor, Pop-up window, Blood pressure, Severity, Stress |
| Topic 10 | Results, Examination, Father, Affected child, Hours | Topic 28 | Hospital, Feeling, Patient, Vitiligo, Laryngoscope |
| Topic 11 | Nodules, Patients, Lungs, Headache, Films | Topic 29 | Bladder, Sperm, Test tube, Chin, Syndrome |
| Topic 12 | Child, Fracture, Positive, Patients, Pain | Topic 30 | Medication, Influence, Rhinitis, Child, Taking medication, Feeling |
| Topic 13 | Examination, Recommendation, Patients, Face, Lips | Topic 31 | Disorder, Eyes, Traditional Chinese medicine, Emotion, Bipolar |
| Topic 14 | Causes, Testing, Discharge, Professor, Development | Topic 32 | Consultation, Question, Doctor, Cyst, Throat |
| Topic 15 | Menstruation, Vagina, Lower abdomen, Quantitative, pain | Topic 33 | Time, Doctor, Menstruation, Lump, Endometrium |
| Topic 16 | Medication, Recommendation, Doctor, Mosquitoes, Severe | Topic 34 | Dizziness, Patients, Heart, Prescription, Weakness |
| Topic 17 | Doctor, Condition, Surgery, Recommendation, Medication | Topic 35 | Surgery, Patients, Breast cancer, Nose, Tumor |
| Topic 18 | Pneumonia, Mucus gland carcinoma, Bronchus, Child, Constitution | Topic 36 | Lump, Redness, Effect, Acne, Location |
| Category | Topics | Description | Number of Documents | Proportion (%) |
|---|---|---|---|---|
| Q1 Causes | 4, 15, 17, 19 | Ask about the causes of a disease or behavior | 961 | 8.96 |
| Q2 Symptoms and manifestations | 18, 25, 26, 28, 31, 36 | Ask about the symptoms and manifestations of a disease | 1867 | 17.40 |
| Q3 Examination and diagnosis | 9, 21, 32, 33, 34 | Ask if a disease is present and what type of disease it is Ask about the approach, method, or effectiveness of a test for a disease | 1204 | 11.22 |
| Q4 Treatment | 2, 8, 8, 24, 35 | Ask if you should see a doctor or ask for a referral Ask if a treatment is effective and if treatment is needed Ask about other treatment options | 2207 | 20.57 |
| Q5 Self-management and regulation | 13, 20, 30 | Ask how to manage and regulate negative emotions caused by illness | 920 | 8.58 |
| Q6 Impact | 6, 12, 23 | Ask how an illness affects children, spouses, parents Ask how to avoid the impact | 835 | 7.79 |
| Q7 Prevention | 1, 10 | Ask how to prevent or avoid a disease problem | 465 | 4.33 |
| Q8 Social life | 3, 11, 14, 22, 27, 29 | Describe health problems of parents, relatives and children How do you get along with them Ask for the community’s assessment of the phenomenon, behavior, or event resulting from the disease Describe your health problems and ask for understanding and support | 1665 | 15.52 |
| Q9 Knowledge acquisition | 7, 15 | Ask about disease and health | 604 | 5.63 |
| Topic | Number of Documents | Positive Words | Positive Sentiment | Negative Words | Negative Sentiment |
|---|---|---|---|---|---|
| causes (C) | 961 | praise, encouragement, support… | 409 (43%) | blame, worry, suffering… | 552 (57%) |
| symptoms and manifestations (S&M) | 1867 | comfort, improvement, relief… | 504 (27%) | pain, severity, distress… | 1363 (73%) |
| examination and diagnosis (E&D) | 1204 | accurate, professional, efficient… | 529 (44%) | delay, misdiagnosis, inaccuracy… | 675 (56%) |
| treatment (T) | 2207 | effective, significant, innovative… | 1390 (62%) | failure, side effects, expensive… | 817 (38%) |
| self-management and regulation (S&M&R) | 920 | self-discipline, progress, control… | 451 (49%) | struggle, indulgence, difficulty… | 469 (51%) |
| impact (I) | 835 | positive, change, adaptation… | 359 (43%) | negative, destruction, barrier… | 476 (57%) |
| prevention (P) | 465 | effective, prevention, advance… | 260 (56%) | neglect, disregard, oversight… | 205 (44%) |
| social life (S) | 1665 | integration, friendship, support… | 966 (58%) | isolation, discrimination, conflict… | 699 (42%) |
| knowledge acquisition (K) | 604 | learning, improvement, comprehension… | 421 (70%) | confusion, misinformation, misunderstanding… | 183 (30%) |
| Model Type | Precision | Recall | F1 Value |
|---|---|---|---|
| LDA Model | 0.821 | 0.803 | 0.812 |
| Word2Vec Model | 0.863 | 0.848 | 0.855 |
| BERT Model | 0.909 | 0.882 | 0.895 |
| BERT-LDA Model | 0.945 | 0.923 | 0.934 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, M.; Zhong, D.; Han, M.; Lv, K. A Study on Online Health Community Users’ Information Demands Based on the BERT-LDA Model. Healthcare 2023, 11, 2142. https://doi.org/10.3390/healthcare11152142
Xiang M, Zhong D, Han M, Lv K. A Study on Online Health Community Users’ Information Demands Based on the BERT-LDA Model. Healthcare. 2023; 11(15):2142. https://doi.org/10.3390/healthcare11152142
Chicago/Turabian StyleXiang, Minhao, Dongdong Zhong, Minghua Han, and Kun Lv. 2023. "A Study on Online Health Community Users’ Information Demands Based on the BERT-LDA Model" Healthcare 11, no. 15: 2142. https://doi.org/10.3390/healthcare11152142
APA StyleXiang, M., Zhong, D., Han, M., & Lv, K. (2023). A Study on Online Health Community Users’ Information Demands Based on the BERT-LDA Model. Healthcare, 11(15), 2142. https://doi.org/10.3390/healthcare11152142