
A Review of Machine Learning and Deep Learning Approaches on Mental Health Diagnosis

 ,
, 
 and
and
Abstract
:1. Introduction
2. Review Background
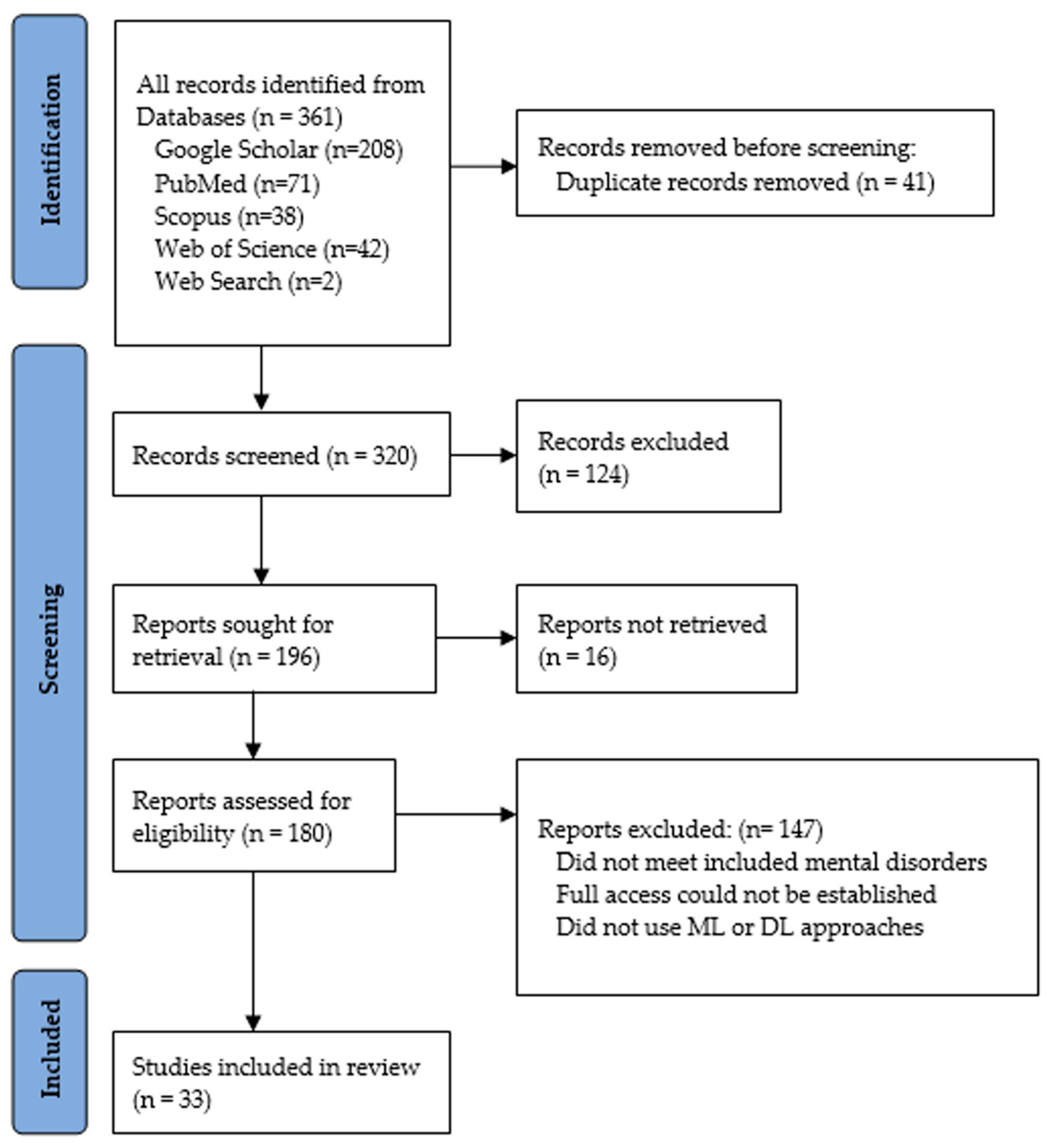
3. Method of Data Selection, Extraction, and Analysis
- the research did not examine at least one of the mental health issues included in this study,
- full access to the article could not be established, and
- the proposed approach did not use an ML or DL approach.
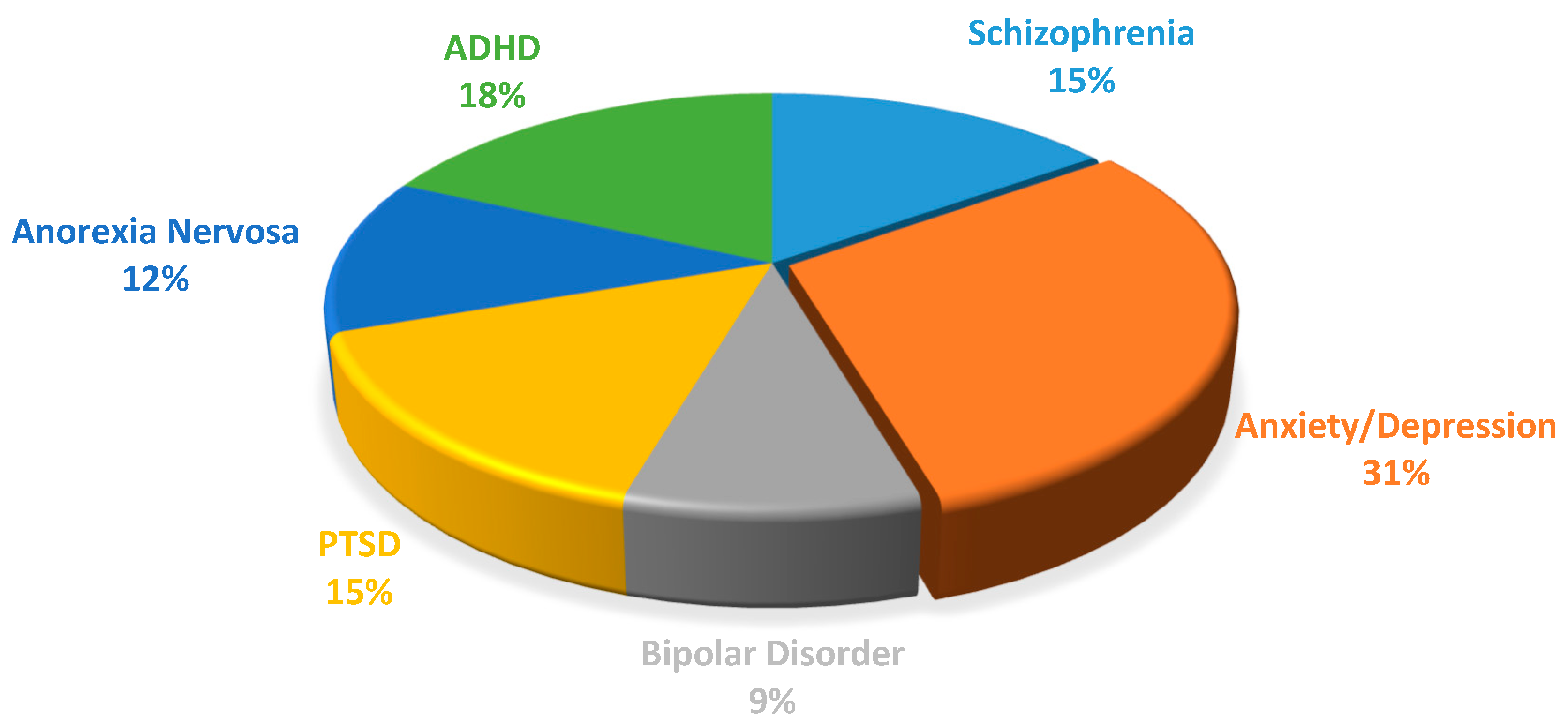
4. ML and DL Methodologies Applied
4.1. Approaches for Schizophrenia Prediction
4.2. Approaches for Depression and Anxiety Detection
4.3. Approaches for Bipolar Disorder Detection
4.4. Approaches for Post-Traumatic Stress Disorder (PTSD) Detection
4.5. Approaches for Anorexia Nervosa Detection
4.6. Approaches for Attention Deficit Hyperactivity Disorder (ADHD) Detection

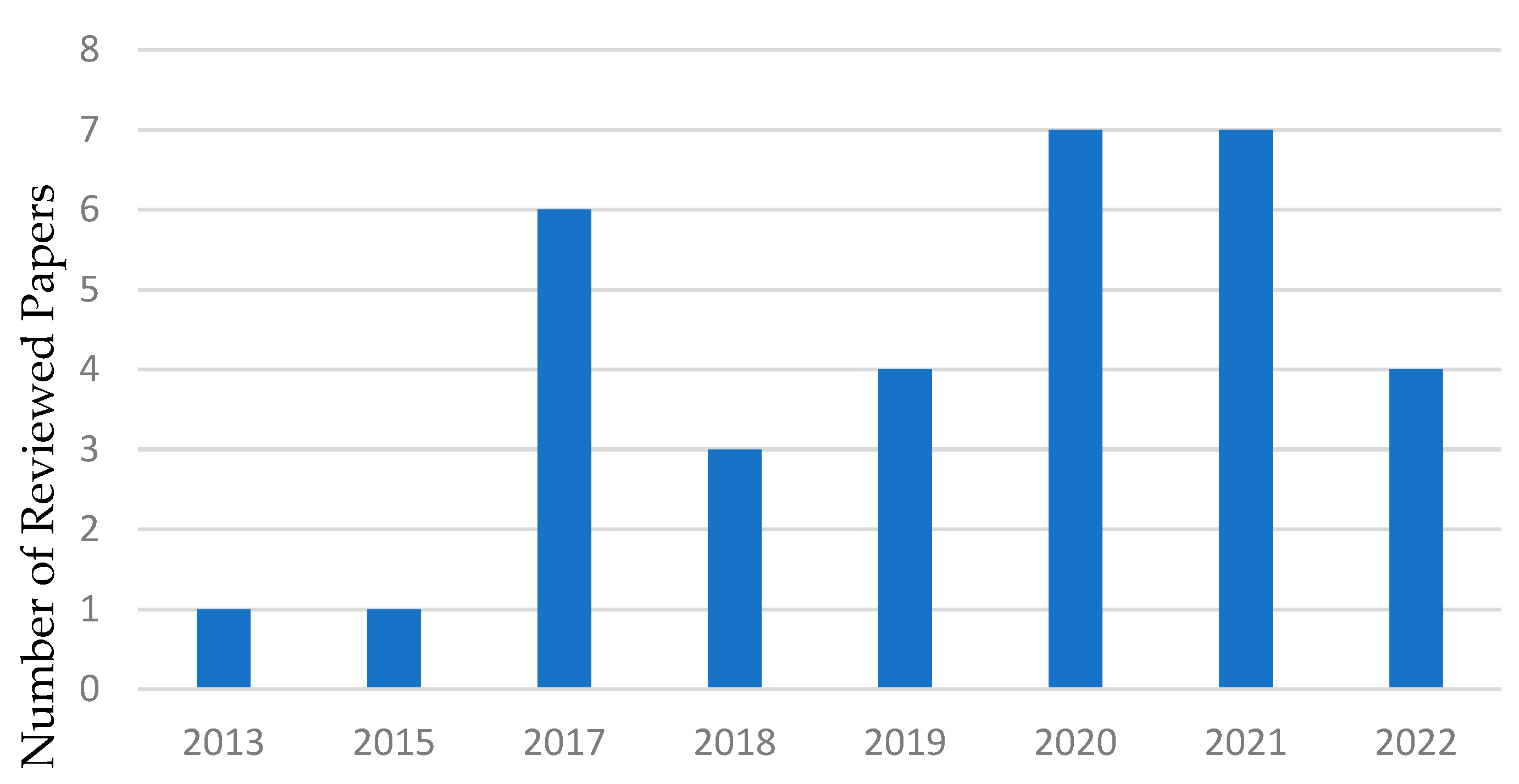{kind=link}
{kind=link}
{kind=link}
{kind=link}
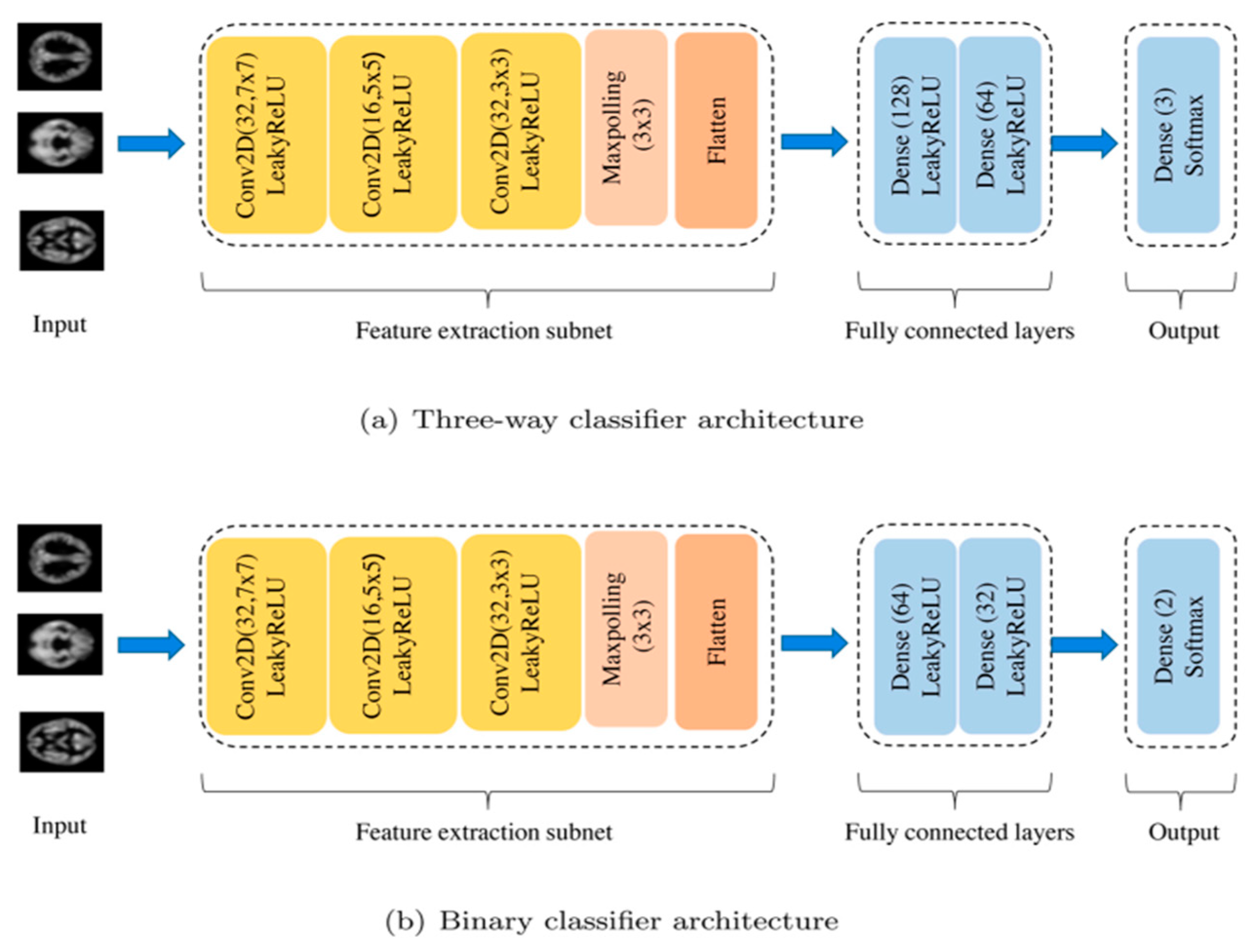{kind=link}
| No | Dataset | Application | Author | Data Type | Year |
|---|---|---|---|---|---|
| 1 | Distress Analysis Interview Corpus (DAIC) [40] | Anxiety, Depression, PTSD | Gratch et al. | Audio/Video | 2014 |
| 2 | Turkish Audio-visual Bipolar Disorder Corpus [52] | Bipolar Disorder | Çiftçi et al. | Audio/Video | 2018 |
| 3 | eRISK [60] | Anorexia Nervosa | CLEF | Text | 2018 |
| 4 | Spanish Anorexia Dataset (SAD) [63] | Anorexia Nervosa | López Úbeda et al. | Text | 2019 |
| 5 | ADHD-200 [71] | ADHD | The ADHD-200 consortium [72] | Images | 2012 |
| 6 | Danish Depression Database [73] | Depression | Videbech et al. | Audio/Video/Reported | 2011 |
| 7 | Reddit Self-reported Depression Diagnosis (RSDD) dataset [74] | Depression | MacAvaney et al. | Text | 2017 |
| 8 | Penn-dataset [75] | Schizophrenia | Hamm et al. | Video/Images | 2014 |
| 9 | AVEC 2013 Audio-visual Depressive Language corpus (AViD Corpus) [76] | Depression | Valstar et al. | Audio/Video | 2013 |
| 10 | AVEC 2014 [77] | Depression | Valstar et al. | Audio/Video | 2014 |
| 11 | AVEC 2016 [78] | Depression | Vasltar et al. | Audio/Video | 2016 |
| 12 | Crisis Text Line [79] | Depression | Lieberman and Meyer | Text | 2013 |
| 13 | DementiaBank Database [80] | Depression | Becker et al. | Audio/Video | 1994 |
| 14 | SemEval-2014 Task 7 [81] | Depression | Pradhan et al. | Text | 2014 |
| 15 | Emotional Audio-Textual Depression Corpus (EATD-Corpus) [82] | Depression | Shen et al. | Audio/Text (Chinese) | 2022 |
| Author | Target | Data Domain | Data Size | Methodology | Model Performance | Model Validation | Motivation |
|---|---|---|---|---|---|---|---|
| Srinivasagopalan et al. [31] (2019) | Schizophrenia | Image (fMRI, sMRI) | 144 subjects (75 controls 69 patients) | LR SVM RF NN (3 hidden layers) | Accuracy: LR: 82.77% SVM: 82.68% RF: 83.33% NN: 94.44% | CV | To automatically diagnose schizophrenia from brain MRI scans. |
| Zeng et al. [32] (2018) | Schizophrenia | Image (MRI.) | 1000+ subjects 474 patients 607 controls | Deep discriminant auto-encoder network: Multi-site pooling classification, Leave-site-out transfer classification. | Accuracy: Multi-site pooling classification: 85.0% Leave-site-out transfer classification: 81.0% | 10-fold CV Cross-site CV | To distinguish schizophrenia patients from healthy controls in a large multi-site sample. |
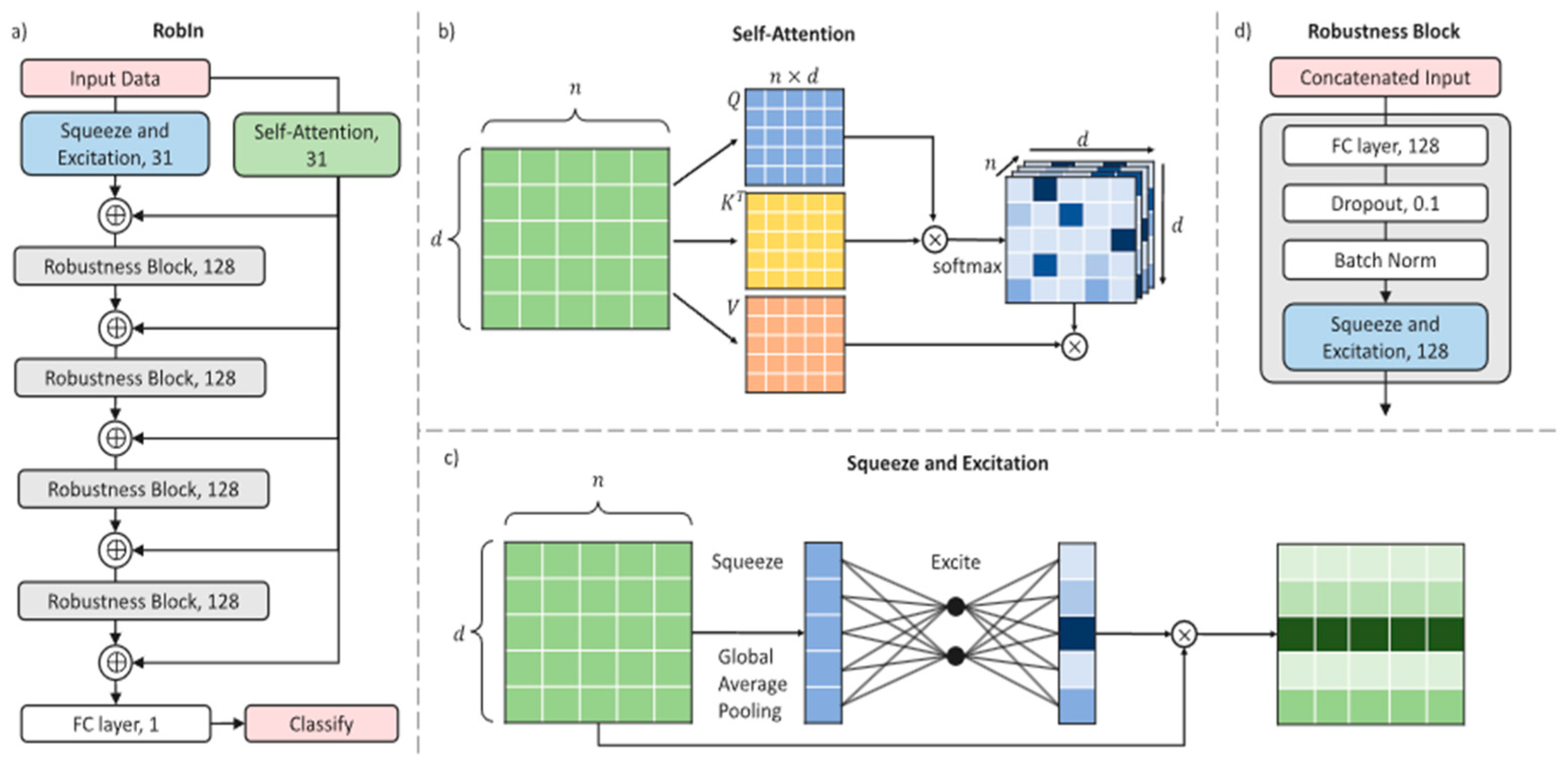
| Organisciak et al. [33] (2022) | Schizophrenia | Clinical observations data | 97 patients 54 controls | Robust, interpretable framework based on Squeeze and Excitation and Self-Attention with 10-fold cross-validation. | Accuracy: 98% | 10-fold CV | To improve the interpretability of DNNs for the diagnosis of schizophrenia. |
| Birnbaum et al. [34] (2017) | Schizophrenia | Text (Twitter) | 671 users | Gaussian naïve Bayes RF LR SVMs | AUC Score: RF: 88.0% | 10-fold CV | To accurately diagnose schizophrenic patients from noisy inference diagnosis. |
| Jo et al. [35] (2020) | Schizophrenia | Image | 48 Schizophrenic 25 healthy controls | SVM Multinomial naïve Bayes RF XGBoost | ML model: Global RF: Accuracy: 68.0% AUC: 0.680 ML model: Four per Nodal network XGBoost: Accuracy: 66.3% AUC: 0.656 | 10-fold CV | To analyze brain network properties in patients with schizophrenia from healthy controls. |
| Sau and Bhakta [37] (2017) | Anxiety | Clinical data | 510 geriatric patients | BN, logistic, multiple layer perceptron, NB, RF, random tree, J48, SMO, random subspace, KS | RF: Accuracy: 89%, TP rate: 89%, Precision: 89.1%, F-measure: 89%, AUC: 94.3% FP rate: 10.9 | 10-fold CV | Development of an automated predictive model for the prediction of anxiety in geriatric patients. |
| Sau and Bhakta [38] (2019) | Anxiety and Depression | Text (Interview based) | 470 seafarers | Catboost LR Naïve Bayes RF SVM | Accuracy: Catboost: 89.3% LR: 87.5% Naïve Bayes: 82.1% RF: 78.6% SVM: 82.1% | 10-fold CV | To detect depression in seafarers due to their susceptibility to mental health disorders. |
| Niu et al. [39] (2021) | Depression | Text and Audio | DAIC-WOZ dataset | Hierarchical Context-Aware Graph Attention Model | F1-Score: 0.92 M.A.E.: of 2.94 RMSE: 3.80 | 57%:19%:25% RS | To grasp sufficient logical and relational interview questions for automatic depression detection. |
| Yoon et al. [41] (2022) | Depression | Visual and Audio | 961 YouTube Vlogs | Multimodal cross-attention mechanism | Precision: 65.40 Recall: 65.57 F1-Score: 63.50 | 70%:10%:20% RS | To detect depression from non-verbal behaviors. |
| Xezonaki et al. [42] (2020) | Depression | Text (Interview and therapy) | i. GPC 1,262 therapy sessions: 881 “not-depressed” 381 “depressed.” ii. DAIC-WOZ transcripts | Hierarchical attention networks | F1-Score: GPC dataset: 71.6 DAIC-WOZ: 68.6 | 5-fold CV | To predict depression levels with the use of data retrieved from psychotherapy sessions. |
| Cho et al. [43] (2020) | Depression | Clinical medical checkup data | 433,190 subjects 10,824 depressed 422,364 non-depressed | RF | AUC: 0.849, Sensitivity: 0.737, Specificity: 0.824, PPV: 0.097, NPV: 0.992, Accuracy: 0.780 | 5-fold CV | To predict the onset of depression for easier and more effective treatment. |
| Sharma et al. [44] (2020) | Depression | Biomarkers and self-reported depression data | 11,081 samples | XGBoost | Xgb.O Accuracy: 0.9729, B. Accuracy 0.9765, Precision:0.9548, Recall: 0.9987, F1-Score: 0.9762 | CV | To cut the prolonged process of patient interviews and time cost. |
| Deshpande et al. [46] (2017) | Depression | Text (Twitter) | 10,000 tweets | MNB SVM | MNB Precision: 0.836 Recall: 0.83 F1-Score: 0.8329 Accuracy: 83% SVM Precision: 0.804 Recall: 0.79 F1-Score: 0.7973 Accuracy: 79% | No Cross Validation | To detect depression by applying supervised learning algorithms on a text dataset. |
| Hilbert et al. [47] (2017) | Anxiety/ Depression | Image (MRI.) | 19 GAD. 14 MD 24 Healthy controls | SVM | Case-classification: Accuracy: 90.10% Disorder-classification Accuracy: 67.46% | LOOCV | To prove the possibility of using biomarkers in the diagnosis of mental disorders. |
| Richter et al. [48] (2021) | Anxiety/ Depression | Clinical data Questionnaires | 101 participants | RF | Anxiety/Depression/Mixed groups vs. control Specificity: 76.81%, Sensitivity: 69.66% Anxiety vs. Depression Specificity: 80.50%, Sensitivity: 66.46% | LOOCV | To provide a novel psychiatric diagnostic tool for differentiating between anxiety and depression patients. |
| Li et al. [49] (2020) | Bipolar disorder | MRI and Clinical evaluation | 44 patients 36 controls | SVM | Accuracy: 87.5% Sensitivity: 86.4% Specificity: 88.9% | LOOCV | To differentiate patients with bipolar disorder from controls through the use of multimodal MRI data. |
| Li et al. [50] (2021) | Bipolar disorder/ first-episode psychosis (FEP.) | Image (sMRI) | 89 FEP. 40 BD. 83 Healthy controls | CNN | Precision: 99.76% Recall: 99.74% F1-Score: 99.75% Accuracy: 99.72% AUC: 99.75% on the 3-way classification task | 10-fold CV | To effectively increase the classification accuracy of mental disorders by extracting deep information from neuroimaging data. |
| Abaei and Osman [51] (2020) | Bipolar Disorder | Video | 47 subjects 208 video recording | Hybrid CNN-LSTM model. | UAR: 60.67% Accuracy: 63.32% | RS | To discriminate between different levels of bipolar disorder through visual clues. |
| Rosellini et al. [54] (2018) | PTSD | Text (survey) | 23,907 subjects | Super learner algorithm used on 39 individual algorithms. | AUC: 79.04 | 10-fold CV | To use machine learning in developing a post-earthquake PTSD risk score estimator. |
| Schultebraucks et al. [55] (2021) | PTSD | Clinical data | 473 subjects | RF SVM | AUC: RF: 78% SVM: 88% | 75%:25% RS | To determine if a pre-collected set of variables can be informative in the prediction of PTSD development over the course of time in active-duty army personnel. |
| Reece et al. [56] (2017) | Depression/ PTSD | Text (Twitter) | 279,951 tweets from 204 users for depression/ 243,775 tweets from 174 users for PTSD | Various Supervised learning algorithms: 1200-tree RF classifier | Performance is shown in Table 1 | 5-fold CV | To forecast the onset of depression and PTSD among Twitter users. |
| Campbell et al. [57] (2019) | PTSD | Text (Survey) | 2290 subjects | Decision tree analysis | Individual predictions in development samples: Sensitivity: 0.425 Specificity: 0.880 | Independent Testing | To show how data from consecutive survey years can be used to create and validate an algorithm for the prediction of PTSD risks. |
| Gokten and Uyulan [58] (2021) | PTSD/ Depression | Clinical data | 482 Children and adolescents | RF | AUC: Depression: 88.0% PTSD: 76.0% | 10-fold CV | To determine the effect of various factors in the development of mental disorders. |
| Paul et al. [59] (2018) | Anorexia/Depression | Text (Reddit) | 472 users 253,752 posts [60] | Ada Boost LR RF SVM | Overall performance: SVM on BOW: Precision: 0.97, Recall: 0.98, F-measure: 0.98. UMLS features: SVM: F-measure: 0.55 BOW and UMLS: Ada boost classifier: F-measure: 0.47 | 10-fold CV | To recognize anorexia in a timely manner in order to help professionals intervene. |
| Guo et al. [61] (2015) | Anorexia Nervosa | Genome genotyping data | 3940 AN cases 9266 controls | LR SVM Gradient Boosted Trees | AUC: LR: 0.693 SVM: 0.691 Gradient Boosted Trees: 0.623 | 10-fold CV | To use genetic information in determining the risk factors of anorexia nervosa. |
| Ranganathan et al. [62] (2019) | Anorexia Nervosa | Text (Reddit) | 472 Users [60] | i. Neural Machine Translator (Seq2Seq) ii. Traditional learning approach: SVM classifier with SGD optimization using TF-IDF | Overall Performance: Precision: 0.48 Recall: 0.26 F1-Score: 0.34 ERDE-50: 0.07 | Independent Testing | To apply natural language processing methods to accomplish the detection and management of anorexia nervosa in its rudimentary stage. |
| López-Úbeda et al. [64] (2021) | Anorexia Nervosa | Text (Spanish Tweets) | 5707 tweets [63] | i. Transfer learning methods: BETO M-BERT XLM ii. NN methods: LSTM BiLSTM CNN | Best performance (BETO): F1-Score: 94.1% | 10-fold CV | To use machine learning classification algorithms to detect anorexia from Twitter comments in Spanish with a transfer learning technique. |
| Mikolas et al. [65] (2022) | ADHD | Clinical data | 299 participants | SVM | Performance on 30 features: Accuracy: 66.1% Without demographic features: Accuracy: 65.1% Without missing data: Accuracy: 68.8% | 10-fold CV | To appropriately distinguish ADHD in children or teenagers from a variety of other mental health issues. |
| Tan et al. [66] (2017) | ADHD | Image (fMRI) | 265 subjects (NYU; ADHD-200 dataset [71]) | SVM | Accuracy: 67.7% | 10-fold CV (10 iterations) | To test if fMRI images can give additional information on brain volume abnormalities in ADHD patients that are not included in anatomical images, and hence may lead to a better classification model for the automatic diagnosis of ADHD. |
| Tachmazidis et al. [67] (2021) | ADHD | Questionnaires and Clinical data | 69 patients | A hybrid model consisting of a Machine Learning and knowledge-based model | Accuracy: 95% | LOOCV | To find a way through which clinical information can create a decision tool to automate the process of diagnosis. |
| Peng et al. [68] (2013) | ADHD | Image (MRI) | 55 patients 55 controls (Peking University; ADHD-200 dataset ) | SVM-Linear SVM-RBF ELM learning algorithm | Accuracy: SVM-Linear: 84.73% SVM-RBF: 86.55% ELM: 90.18% | LOOCV | To establish a method for diagnosing ADHD that is automated, effective, quick, and accurate in order to address the shortcomings of traditional methods. |
| Yin et al. [69] (2022) | ADHD | Resting state fMRI | 360 ADHD and TDC subjects | XGBoost | Differentiating ADHD from TDC; Accuracy: 77% (CV), 74.46% (IT) Predicting ADHD severity; R2: 0.2794 (CV), 0.156 (IT) | 10-fold CV (10 iterations) | To determine if neural flexibility can serve as a biomarker to differentiate children with ADHD from typically developing children (TDC). |
| Liu et al. [70] (2020) | ADHD | Image (fMRI) | ADHD-200 dataset (Table 2) | CDAE-AdaDT model | Accuracy: 75.64%, Sensitivity: 76.92%, Specificity: 73.08% | No Cross Validation | To improve the result of ADHD classification in fMRI data. |
5. Analysis and Discussion
5.1. Datasets
5.2. Evaluation Metrics
5.3. Challenges
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hamilton, M. Development of a Rating Scale for Primary Depressive Illness. Br. J. Soc. Clin. Psychol. 1967, 6, 278–296. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997; Volume 1. [Google Scholar]
- Cunningham, P.; Cord, M.; Delany, S. Supervised Learning. In Machine Learning Techniques for Multimedia; Springer: Berlin/Heidelberg, Germany, 2008; pp. 21–49. [Google Scholar]
- Torrey, L.; Shavlik, J. Transfer Learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Wongkoblap, A.; Vadillo, M.A.; Curcin, V. Researching Mental Health Disorders in the Era of Social Media: Systematic Review. J. Med. Internet Res. 2017, 19, e228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Graham, S.; Depp, C.; Lee, E.E.; Nebeker, C.; Tu, X.; Kim, H.-C.; Jeste, D.V. Artificial Intelligence for Mental Health and Mental Illnesses: An Overview. Curr. Psychiatry Rep. 2019, 21, 116. [Google Scholar] [CrossRef]
- Shamshirband, S.; Fathi, M.; Dehzangi, A.; Chronopoulos, A.T.; Alinejad-Rokny, H. A review on deep learning approaches in healthcare systems: Taxonomies, challenges, and open issues. J. Biomed. Inform. 2020, 113, 103627. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Teo, J. Mental Health Prediction Using Machine Learning: Taxonomy, Applications, and Challenges. Appl. Comput. Intell. Soft Comput. 2022, 2022, 9970363. [Google Scholar] [CrossRef]
- Librenza-Garcia, D.; Kotzian, B.J.; Yang, J.; Mwangi, B.; Cao, B.; Lima, L.N.P.; Bermudez, M.B.; Boeira, M.V.; Kapczinski, F.; Passos, I.C. The impact of machine learning techniques in the study of bipolar disorder: A systematic review. Neurosci. Biobehav. Rev. 2017, 80, 538–554. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Niu, M.; Tiwari, P.; Marttinen, P.; Su, R.; Jiang, J.; Guo, C.; Wang, H.; Ding, S.; Wang, Z.; et al. Deep learning for depression recognition with audiovisual cues: A review. Inf. Fusion 2021, 80, 56–86. [Google Scholar] [CrossRef]
- Ramos-Lima, L.F.; Waikamp, V.; Antonelli-Salgado, T.; Passos, I.C.; Freitas, L.H.M. The use of machine learning techniques in trauma-related disorders: A systematic review. J. Psychiatr. Res. 2020, 121, 159–172. [Google Scholar] [CrossRef]
- WHO. Mental Disorders. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/mental-disorders (accessed on 18 August 2022).
- Jencks, S.F. Recognition of mental distress and diagnosis of mental disorder in primary care. JAMA 1985, 253, 1903–1907. [Google Scholar] [CrossRef]
- Schizophrenia. Available online: https://www.who.int/news-room/fact-sheets/detail/schizophrenia (accessed on 27 December 2022).
- Patel, K.R.; Cherian, J.; Gohil, K.; Atkinson, D. Schizophrenia: Overview and treatment options. Peer Rev. J. Formul. Manag. 2014, 39, 638–645. [Google Scholar]
- Costantini, L.; Pasquarella, C.; Odone, A.; Colucci, M.E.; Costanza, A.; Serafini, G.; Aguglia, A.; Murri, M.B.; Brakoulias, V.; Amore, M.; et al. Screening for depression in primary care with Patient Health Questionnaire-9 (PHQ-9): A systematic review. J. Affect. Disord. 2020, 279, 473–483. [Google Scholar] [CrossRef]
- Shorey, S.; Ng, E.D.; Wong, C.H.J. Global prevalence of depression and elevated depressive symptoms among adolescents: A systematic review and meta-analysis. Br. J. Clin. Psychol. 2021, 61, 287–305. [Google Scholar] [CrossRef]
- Harmer, B.; Lee, S.; Duong, T.V.H.; Saadabadi, A. Suicidal Ideation. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2022. [Google Scholar]
- SingleCare, T. Anxiety Statistics 2022. 2022. Available online: https://www.singlecare.com/blog/news/anxiety-statistics/ (accessed on 27 December 2022).
- SingleCare, T. Bipolar Disorder Statistics 2022. 2022. Available online: https://www.singlecare.com/blog/news/bipolar-disorder-statistics/ (accessed on 27 December 2022).
- Taylor-Desir, M. What Is Posttraumatic Stress Disorder (PTSD)? 2022. Available online: https://www.psychiatry.org/patients-families/ptsd/what-is-ptsd (accessed on 27 December 2022).
- Anad. Eating Disorder Statistics. 2021. Available online: https://anad.org/eating-disorders-statistics/ (accessed on 27 December 2022).
- Spinczyk, D.; Bas, M.; Dzieciątko, M.; Maćkowski, M.; Rojewska, K.; Maćkowska, S. Computer-aided therapeutic diagnosis for anorexia. Biomed. Eng. Online 2020, 19, 53. [Google Scholar] [CrossRef]
- Clinic, M. Anorexia Nervosa. 1998–2022. Available online: https://www.mayoclinic.org/diseases-conditions/anorexia-nervosa/symptoms-causes/syc-20353591 (accessed on 17 August 2022).
- Bhargava, H.D. Attention Deficit Hyperactivity Disorder in Adults. 2021. Available online: https://www.webmd.com/add-adhd/adhd-adults (accessed on 26 August 2022).
- Moher, D.; Cook, D.J.; Eastwood, S.; Olkin, I.; Rennie, D.; Stroup, D.F. Improving the quality of reports of meta-analyses of randomised controlled trials: The QUOROM statement. Lancet 1999, 354, 1896–1900. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; PRISMA Group. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. Ann. Intern. Med. 2009, 151, 264–269. [Google Scholar] [CrossRef] [Green Version]
- Katarya, R.; Maan, S. Predicting mental health disorders using machine learning for employees in technical and non-technical companies. In Proceedings of the 2020 IEEE International Conference on Advances and Developments in Electrical and Electronics Engineering, ICADEE 2020, Coimbatore, India, 10–11 December 2020. [Google Scholar]
- Prout, T.A.; Zilcha-Mano, S.; Doorn, K.A.-V.; Békés, V.; Christman-Cohen, I.; Whistler, K.; Kui, T.; Di Giuseppe, M. Identifying Predictors of Psychological Distress During COVID-19: A Machine Learning Approach. Front. Psychol. 2020, 11, 586202. [Google Scholar] [CrossRef]
- Srinivasagopalan, B.J.; Gurupur, V.; Thankachan, S. A deep learning approach for diagnosing schizophrenic patients. J. Exp. Theor. Artif. Intell. 2019, 31, 803–816. [Google Scholar] [CrossRef]
- Zeng, L.-L.; Wang, H.; Hu, P.; Yang, B.; Pu, W.; Shen, H.; Chen, X.; Liu, Z.; Yin, H.; Tan, Q.; et al. Multi-Site Diagnostic Classification of Schizophrenia Using Discriminant Deep Learning with Functional Connectivity MRI. Ebiomedicine 2018, 30, 74–85. [Google Scholar] [CrossRef] [Green Version]
- Organisciak, D.; Shum, H.P.; Nwoye, E.; Woo, W.L. RobIn: A robust interpretable deep network for schizophrenia diagnosis. Expert Syst. Appl. 2022, 201, 117158. [Google Scholar] [CrossRef]
- Birnbaum, M.L.; Ernala, S.K.; Rizvi, A.F.; De Choudhury, M.; Kane, J.M. A Collaborative Approach to Identifying Social Media Markers of Schizophrenia by Employing Machine Learning and Clinical Appraisals. J. Med. Internet Res. 2017, 19, e289. [Google Scholar] [CrossRef]
- Jo, Y.T.; Joo, S.W.; Shon, S.; Kim, H.; Kim, Y.; Lee, J. Diagnosing schizophrenia with network analysis and a machine learning method. Int. J. Methods Psychiatr. Res. 2020, 29, e1818. [Google Scholar] [CrossRef] [PubMed]
- Aleem, S.; Huda, N.U.; Amin, R.; Khalid, S.; Alshamrani, S.S.; Alshehri, A. Machine Learning Algorithms for Depression: Diagnosis, Insights, and Research Directions. Electronics 2022, 11, 1111. [Google Scholar] [CrossRef]
- Sau, A.; Bhakta, I. Predicting anxiety and depression in elderly patients using machine learning technology. Health Technol. Lett. 2017, 4, 238–243. [Google Scholar] [CrossRef]
- Sau, A.; Bhakta, I. Screening of anxiety and depression among the seafarers using machine learning technology. Inform. Med. Unlocked 2019, 16, 100149. [Google Scholar] [CrossRef]
- Niu, M.; Chen, K.; Chen, Q.; Yang, L. HCAG: A Hierarchical Context-Aware Graph Attention Model for Depression Detection. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 4235–4239. [Google Scholar] [CrossRef]
- Gratch, J.; Artstein, R.; Lucas, G.; Stratou, G.; Scherer, S.; Nazarian, A.; Wood, R.; Boberg, J.; DeVault, D.; Marsella, S.; et al. The distress analysis interview corpus of human and computer interviews. 2014, University of Southern California Los Angeles. Available online: http://www.lrec-conf.org/proceedings/lrec2014/pdf/508_Paper.pdf (accessed on 16 August 2022).
- Yoon, J.; Kang, C.; Kim, S.; Han, J. D-vlog: Multimodal Vlog Dataset for Depression Detection. Proc. Conf. AAAI Artif. Intell. 2022, 36, 12226–12234. [Google Scholar] [CrossRef]
- Xezonaki, D.; Paraskevopoulos, G.; Potamianos, A.; Narayanan, S. Affective Conditioning on Hierarchical Attention Networks Applied to Depression Detection from Transcribed Clinical Interviews. arXiv 2020, arXiv:2006.08336. [Google Scholar] [CrossRef]
- Cho, S.-E.; Geem, Z.W.; Na, K.-S. Prediction of depression among medical check-ups of 433,190 patients: A nationwide population-based study. Psychiatry Res. 2020, 293, 113474. [Google Scholar] [CrossRef]
- Sharma, A.; Verbeke, W.J.M.I. Improving Diagnosis of Depression with XGBOOST Machine Learning Model and a Large Biomarkers Dutch Dataset (n = 11,081). Front. Big Data 2020, 3, 15. [Google Scholar] [CrossRef]
- Jiang, T.; Gradus, J.L.; Rosellini, A.J. Supervised Machine Learning: A Brief Primer. Behav. Ther. 2020, 51, 675–687. [Google Scholar] [CrossRef]
- Deshpande, M.; Rao, V. Depression detection using emotion artificial intelligence. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Hilbert, K.; Lueken, U.; Muehlhan, M.; Beesdo-Baum, K. Separating generalized anxiety disorder from major depression using clinical, hormonal, and structural MRI data: A multimodal machine learning study. Brain Behav. 2017, 7, e00633. [Google Scholar] [CrossRef]
- Richter, T.; Fishbain, B.; Fruchter, E.; Richter-Levin, G.; Okon-Singer, H. Machine learning-based diagnosis support system for differentiating between clinical anxiety and depression disorders. J. Psychiatr. Res. 2021, 141, 199–205. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Cui, L.; Cao, L.; Zhang, Y.; Liu, Y.; Deng, W.; Zhou, W. Identification of bipolar disorder using a combination of multimodality magnetic resonance imaging and machine learning techniques. BMC Psychiatry 2020, 20, 488. [Google Scholar] [CrossRef]
- Li, Z.; Li, W.; Wei, Y.; Gui, G.; Zhang, R.; Liu, H.; Chen, Y.; Jiang, Y. Deep learning based automatic diagnosis of first-episode psychosis, bipolar disorder and healthy controls. Comput. Med Imaging Graph. 2021, 89, 101882. [Google Scholar] [CrossRef] [PubMed]
- Abaei, N.; Al Osman, H. A Hybrid Model for Bipolar Disorder Classification from Visual Information. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4107–4111. [Google Scholar] [CrossRef]
- Çiftçi, E.; Kaya, H.; Güleç, H.; Salah, A.A. The turkish audio-visual bipolar disorder corpus. In Proceedings of the 2018 First Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cowie, R.; Kaya, H.; Schmitt, M.; Amiriparian, S.; Cummins, N.; Lalanne, D.; Michaud, A.; et al. AVEC 2018 Workshop and Challenge: Bipolar Disorder and Cross-Cultural Affect Recognition. In Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, Seoul, Republic of Korea, 22 October 2018. [Google Scholar]
- Rosellini, A.J.; Dussaillant, F.; Zubizarreta, J.R.; Kessler, R.C.; Rose, S. Predicting posttraumatic stress disorder following a natural disaster. J. Psychiatr. Res. 2017, 96, 15–22. [Google Scholar] [CrossRef]
- Schultebraucks, K.; Qian, M.; Abu-Amara, D.; Dean, K.; Laska, E.; Siegel, C.; Gautam, A.; Guffanti, G.; Hammamieh, R.; Misganaw, B.; et al. Pre-deployment risk factors for PTSD in active-duty personnel deployed to Afghanistan: A machine-learning approach for analyzing multivariate predictors. Mol. Psychiatry 2020, 26, 5011–5022. [Google Scholar] [CrossRef]
- Reece, A.G.; Reagan, A.J.; Lix, K.L.M.; Dodds, P.S.; Danforth, C.M.; Langer, E.J. Forecasting the onset and course of mental illness with Twitter data. Sci. Rep. 2017, 7, 13006. [Google Scholar] [CrossRef] [Green Version]
- Campbell, J.S.; Wallace, M.L.; Germain, A.; Koffman, R.L. A predictive analytic approach to planning combat stress control operations. Int. J. Stress Manag. 2019, 26, 120–131. [Google Scholar] [CrossRef]
- Gokten, E.S.; Uyulan, C. Prediction of the development of depression and post-traumatic stress disorder in sexually abused children using a random forest classifier. J. Affect. Disord. 2020, 279, 256–265. [Google Scholar] [CrossRef]
- Paul, S.; Jandhyala, S.; Basu, T. Early Detection of Signs of Anorexia and Depression Over Social Media using Effective Machine Learning Frameworks. In Proceedings of the CLEF (Working Notes), Avignon, France, 10–14 September 2018. [Google Scholar]
- Losada, D.E.; Crestani, F.; Parapar, J. Overview of eRisk: Early risk prediction on the internet. In Proceedings of the International Conference of the Cross-Language Evaluation Forum for European Languages, Avignon, France, 10–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Guo, Y.; Wei, Z.; Keating, B.J.; Hakonarson, H. Machine learning derived risk prediction of anorexia nervosa. BMC Med. Genom. 2015, 9, 4. [Google Scholar] [CrossRef] [Green Version]
- Ranganathan, A.; Haritha, A.; Thenmozhi, D.; Aravindan, C. Early Detection of Anorexia using RNN-LSTM and SVM Classifiers. In Proceedings of the CLEF (Working Notes), Lugano, Switzerland, 9–12 September 2019. [Google Scholar]
- Úbeda, P.L.; del Arco, F.M.P.; Galiano, M.C.D.; Lopez, L.A.U.; Martin, M. Detecting anorexia in Spanish tweets. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019. [Google Scholar]
- López-Úbeda, P.; Plaza-del-Arco, F.M.; Díaz-Galiano, M.C.; Martín-Valdivia, M.-T. How Successful Is Transfer Learning for Detecting Anorexia on Social Media? Appl. Sci. 2021, 11, 1838. [Google Scholar] [CrossRef]
- Mikolas, P.; Vahid, A.; Bernardoni, F.; Süß, M.; Martini, J.; Beste, C.; Bluschke, A. Training a machine learning classifier to identify ADHD based on real-world clinical data from medical records. Sci. Rep. 2022, 12, 12934. [Google Scholar] [CrossRef]
- Tan, L.; Guo, X.; Ren, S.; Epstein, J.N.; Lu, L.J. A Computational Model for the Automatic Diagnosis of Attention Deficit Hyperactivity Disorder Based on Functional Brain Volume. Front. Comput. Neurosci. 2017, 11, 75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tachmazidis, I.; Chen, T.; Adamou, M.; Antoniou, G. A hybrid AI approach for supporting clinical diagnosis of attention deficit hyperactivity disorder (ADHD) in adults. Health Inf. Sci. Syst. 2020, 9, 1. [Google Scholar] [CrossRef]
- Peng, X.; Lin, P.; Zhang, T.; Wang, J. Extreme Learning Machine-Based Classification of ADHD Using Brain Structural MRI Data. PLoS ONE 2013, 8, e79476. [Google Scholar] [CrossRef] [PubMed]
- Yin, W.; Li, T.; Mucha, P.J.; Cohen, J.R.; Zhu, H.; Zhu, Z.; Lin, W. Altered neural flexibility in children with attention-deficit/hyperactivity disorder. Mol. Psychiatry 2022, 27, 4673–4679. [Google Scholar] [CrossRef]
- Liu, S.; Zhao, L.; Wang, X.; Xin, Q.; Zhao, J.; Guttery, D.S.; Zhang, Y.-D. Deep Spatio-Temporal Representation and Ensemble Classification for Attention Deficit/Hyperactivity Disorder. IEEE Trans. Neural Syst. Rehabilitation Eng. 2020, 29, 1–10. [Google Scholar] [CrossRef] [PubMed]
- ADHD-200-Webpage. The ADHD-200 Sample. 2011. Available online: http://fcon_1000.projects.nitrc.org/indi/adhd200/index.html (accessed on 16 September 2022).
- HD-200 Consortium. The ADHD-200 consortium: A model to advance the translational potential of neuroimaging in clinical neuroscience. Front. Syst. Neurosci. 2012, 6, 62. [Google Scholar]
- Videbech, P.; Deleuran, A. The Danish depression database. Clin. Epidemiol. 2016, 8, 475. [Google Scholar] [CrossRef] [Green Version]
- MacAvaney, S.; Desmet, B.; Cohan, A.; Soldaini, L.; Yates, A.; Zirikly, A.; Goharian, N. RSDD-Time: Temporal Annotation of Self-Reported Mental Health Diagnoses. arXiv 2018, arXiv:1806.07916. [Google Scholar]
- Hamm, J.; Pinkham, A.; Gur, R.C.; Verma, R.; Kohler, C.G. Dimensional Information-Theoretic Measurement of Facial Emotion Expressions in Schizophrenia. Schizophr. Res. Treat. 2014, 2014, 243907. [Google Scholar] [CrossRef]
- Valstar, M.; Schuller, B.; Smith, K.; Eyben, F.; Jiang, B.; Bilakhia, S.; Schnieder, S.; Cowie, R.; Pantic, M. Avec 2013: The continuous audio/visual emotion and depression recognition challenge. In Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, Barcelona, Spain, 21 October 2013. [Google Scholar]
- Valstar, M.; Schuller, B.; Smith, K.; Almaev, T.; Eyben, F.; Krajewski, J.; Cowie, R.; Pantic, M. Avec 2014: 3d dimensional affect and depression recognition challenge. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 7 November 2014. [Google Scholar]
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Lalanne, D.; Torres, M.T.; Scherer, S.; Stratou, G.; Cowie, R.; Pantic, M. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016. [Google Scholar]
- Lieberman, H.A. Visualizations for Mental Health Topic Models. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2014. [Google Scholar]
- Becker, J.T.; Boller, F.; Lopez, O.L.; Saxton, J.; McGonigle, K.L. The natural history of Alzheimer’s disease: Description of study cohort and accuracy of diagnosis. Arch. Neurol. 1994, 51, 585–594. [Google Scholar] [CrossRef]
- Pradhan, S.; Elhadad, N.; Chapman, W.; Manandhar, S.; Savova, G. SemEval-2014 Task 7: Analysis of clinical text. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Shen, Y.; Yang, H.; Lin, L. Automatic Depression Detection: An Emotional Audio-Textual Corpus and A Gru/Bilstm-Based Model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6247–6251. [Google Scholar] [CrossRef]
- Alabandi, G.A. Combining Deep Learning with Traditional Machine Learning to Improve Classification Accuracy on Small Datasets. Master’s Thesis, Texas State University, San Marcos, TX, USA, 2017. [Google Scholar]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Liu, G.; Singha, M.; Pu, L.; Neupane, P.; Feinstein, J.; Wu, H.-C.; Ramanujam, J.; Brylinski, M. GraphDTI: A robust deep learning predictor of drug-target interactions from multiple heterogeneous data. J. Cheminf. 2021, 13, 58. [Google Scholar] [CrossRef]





| Depression | MVR µ | DC µ | Daily µ(σ) | Weekly µ(σ) |
|---|---|---|---|---|
| Recall | 0.510 | 0.614 | 0.518 (0.000) | 0.521 (0.000) |
| Specificity | 0.813 | N/A | 0.958 (0.000) | 0.969 (0.000) |
| Precision | 0.42 | 0.742 | 0.852 (0.000) | 0.866 (0.000) |
| NPV | 0.858 | N/A | 0.812 (0.000) | 0.841 (0.000) |
| F1 | 0.461 | 0.672 | 0.644 (0.000) | 0.651 (0.000) |
| PTSD | TBA µ | NHC µ | Daily µ(σ) | Weekly µ(σ) |
| Recall | 0.249 | 0.82 | 0.683 (0.000) | 0.658 (0.000) |
| Specificity | 0.979 | N/A | 0.988 (0.000) | 0.994 (0.000) |
| Precision | 0.429 | 0.86 | 0.882 (0.000) | 0.934 (0.000) |
| NPV | 0.602 | N/A | 0.959 (0.000) | 0.954 (0.000) |
| F1 | 0.315 | 0.84 | 0.769 (0.000) | 0.772 (0.000) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iyortsuun, N.K.; Kim, S.-H.; Jhon, M.; Yang, H.-J.; Pant, S. A Review of Machine Learning and Deep Learning Approaches on Mental Health Diagnosis. Healthcare 2023, 11, 285. https://doi.org/10.3390/healthcare11030285
Iyortsuun NK, Kim S-H, Jhon M, Yang H-J, Pant S. A Review of Machine Learning and Deep Learning Approaches on Mental Health Diagnosis. Healthcare. 2023; 11(3):285. https://doi.org/10.3390/healthcare11030285
Chicago/Turabian StyleIyortsuun, Ngumimi Karen, Soo-Hyung Kim, Min Jhon, Hyung-Jeong Yang, and Sudarshan Pant. 2023. "A Review of Machine Learning and Deep Learning Approaches on Mental Health Diagnosis" Healthcare 11, no. 3: 285. https://doi.org/10.3390/healthcare11030285
APA StyleIyortsuun, N. K., Kim, S. -H., Jhon, M., Yang, H. -J., & Pant, S. (2023). A Review of Machine Learning and Deep Learning Approaches on Mental Health Diagnosis. Healthcare, 11(3), 285. https://doi.org/10.3390/healthcare11030285