
Automatic Detection and Measurement of Renal Cysts in Ultrasound Images: A Deep Learning Approach

 , ,
, ,
Abstract
:1. Introduction
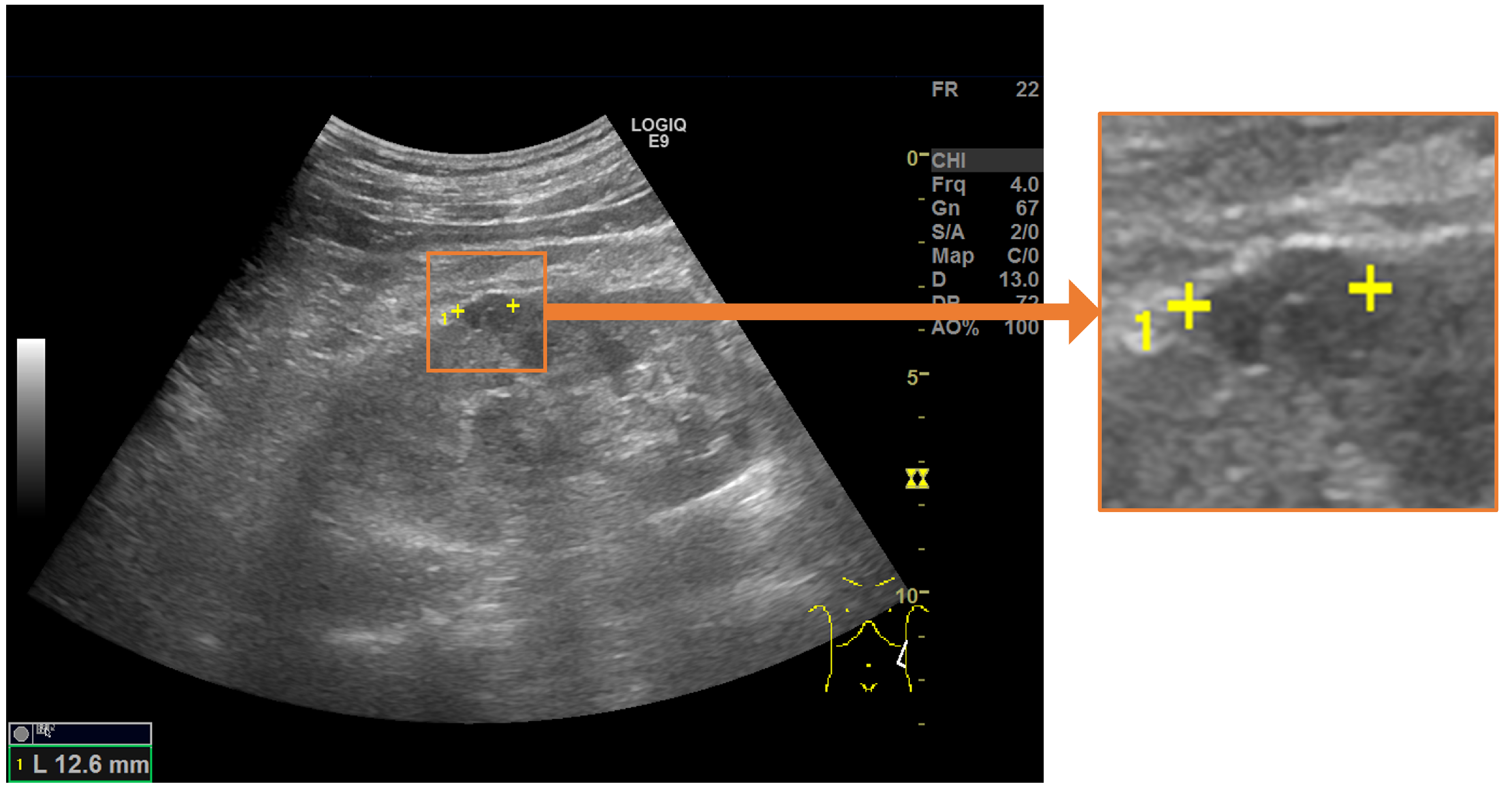
- We developed a measurement assistance function for ultrasonic images using deep learning with the aim of supporting the measurement of renal cysts using measurement markers.
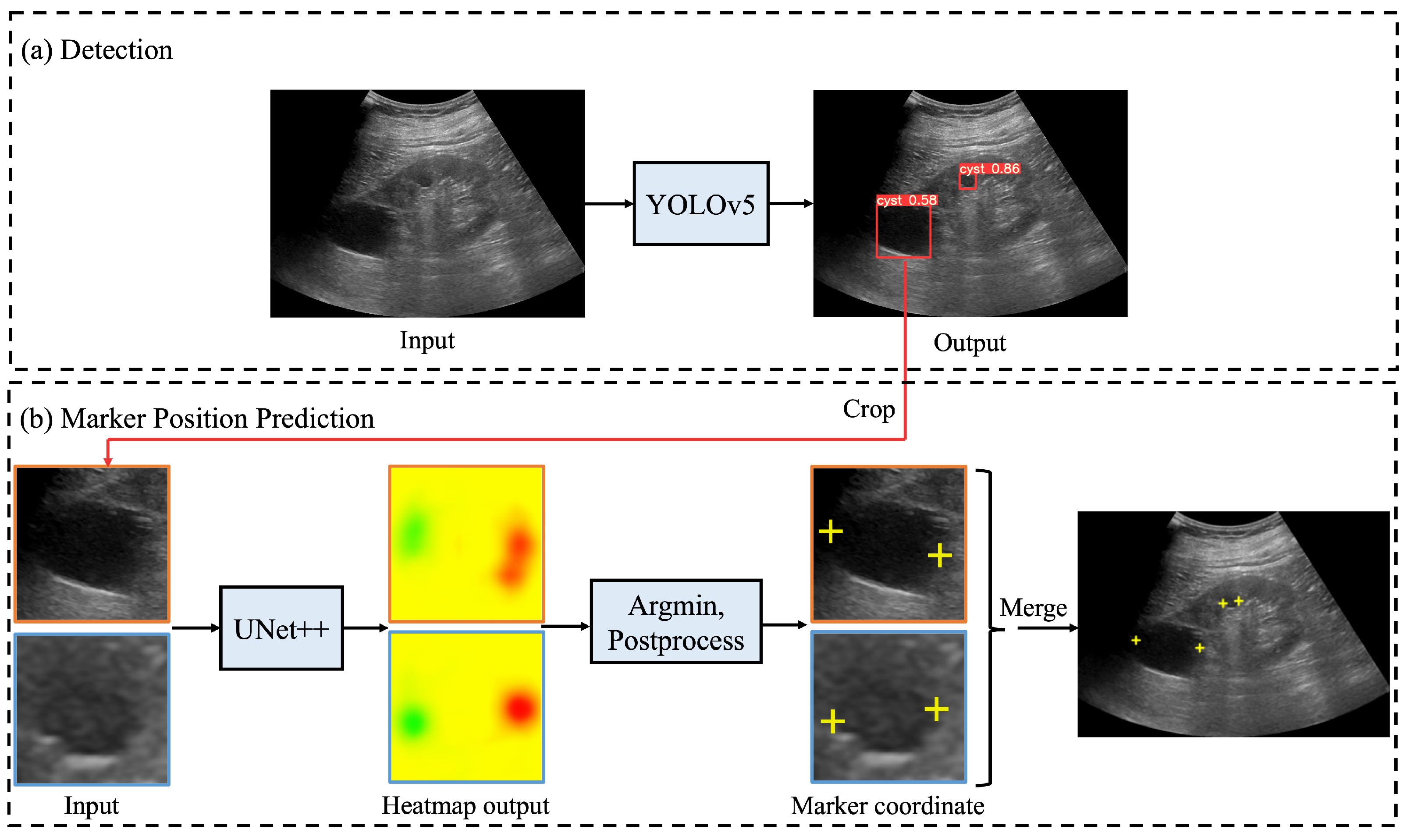
- To predict the landmarks for multiple renal cysts within one image, we developed a system in which all renal cysts in the image were detected prior to saliency map regression. Then, we performed saliency map regression to predict the positions of two salient landmarks for each detected renal cyst.
- Because the proposed method only uses the coordinates of the measurement markers when training the models, it is possible to automate the measurement without performing segmentation, thereby avoiding high annotation costs.
- In comparative tests, our method achieved almost the same accuracy as a radiologist. The errors of the measured length and measurement marker coordinates were used as evaluation indices.
- Our results indicate that the proposed method is able to perform measurements at a higher speed than manual measurement and with an accuracy close to that of sonographers.
2. Materials and Methods
2.1. Automated System for Assigning Salient Landmarks
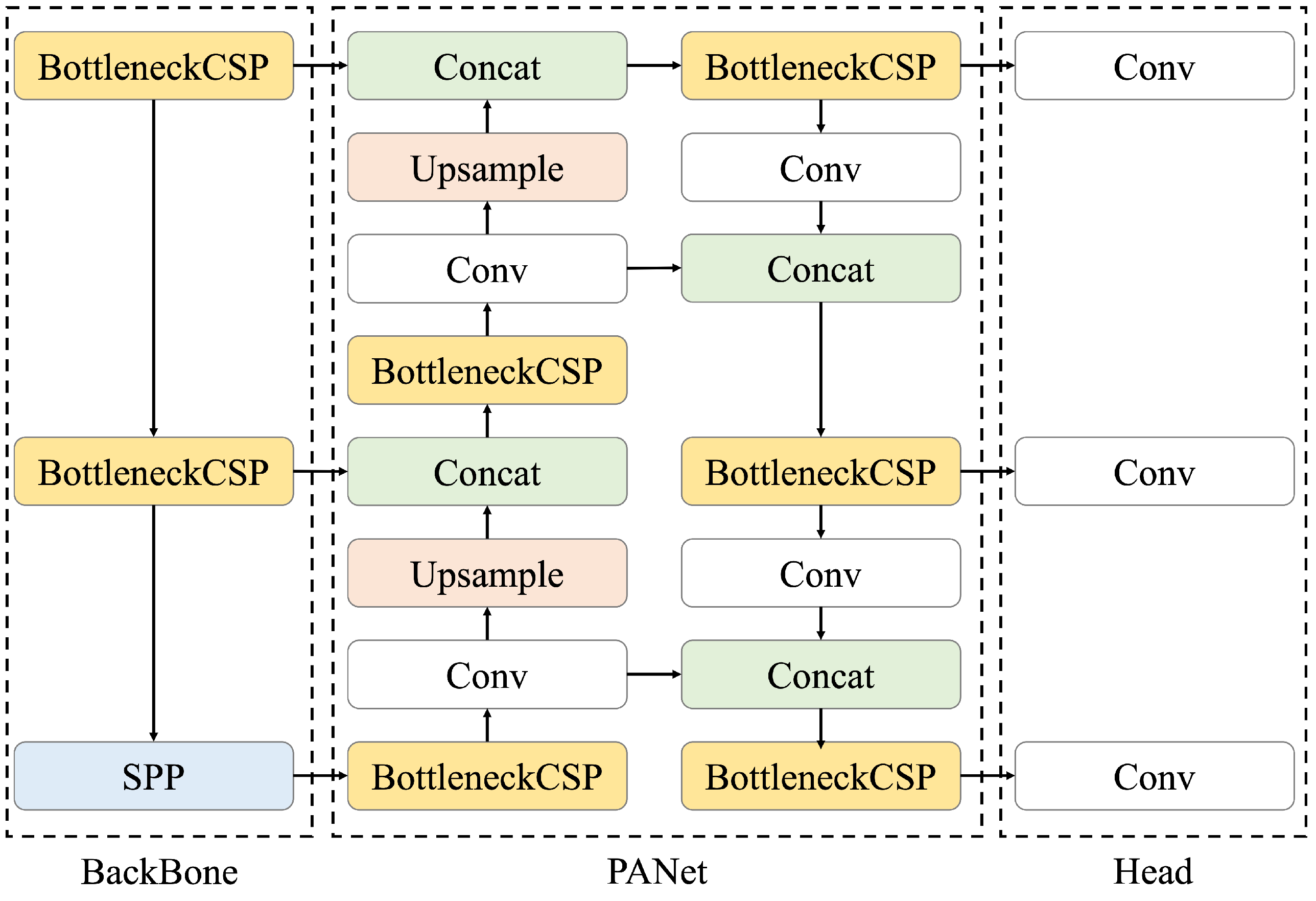
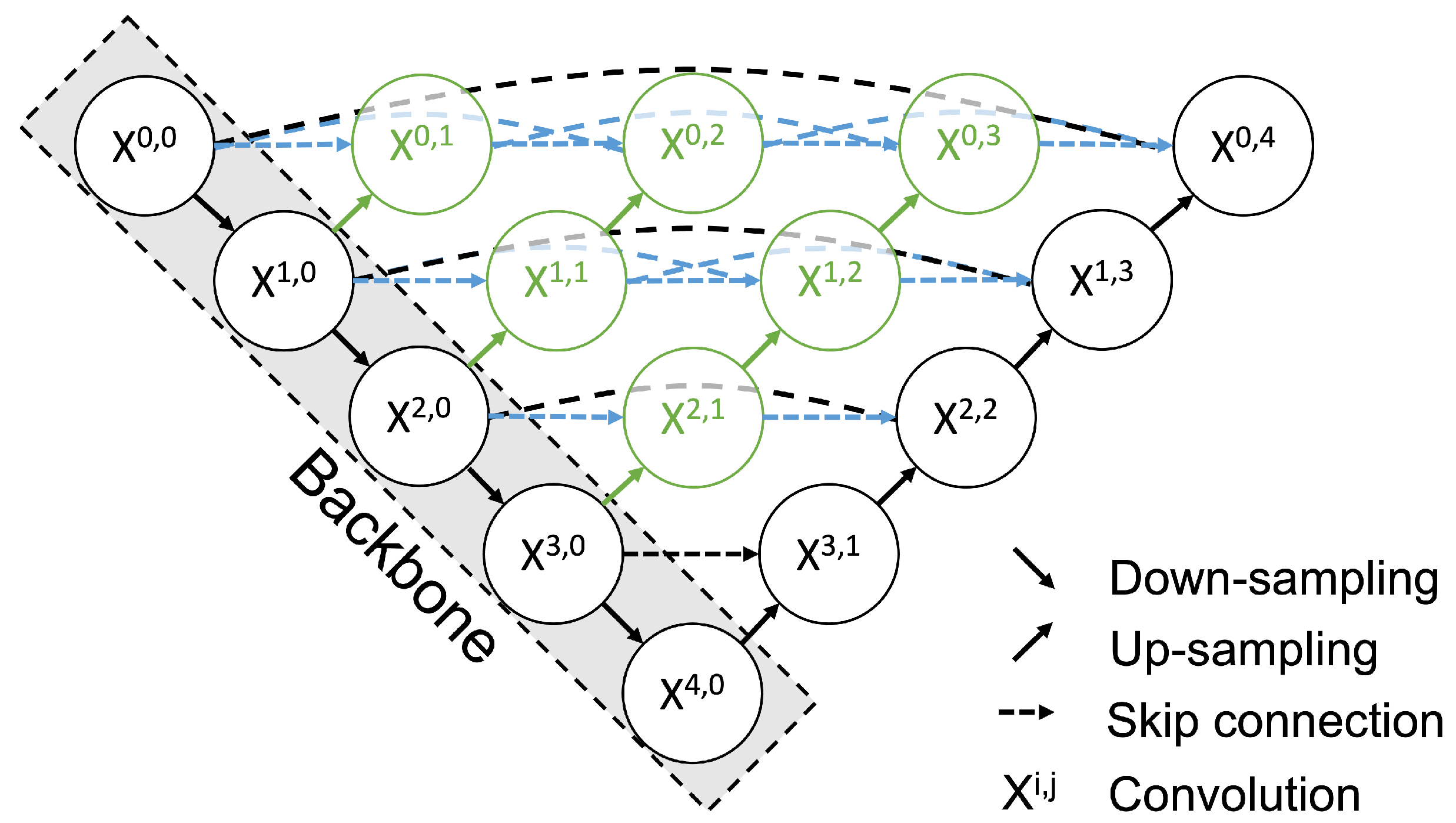
2.2. Renal Cyst Detection Model
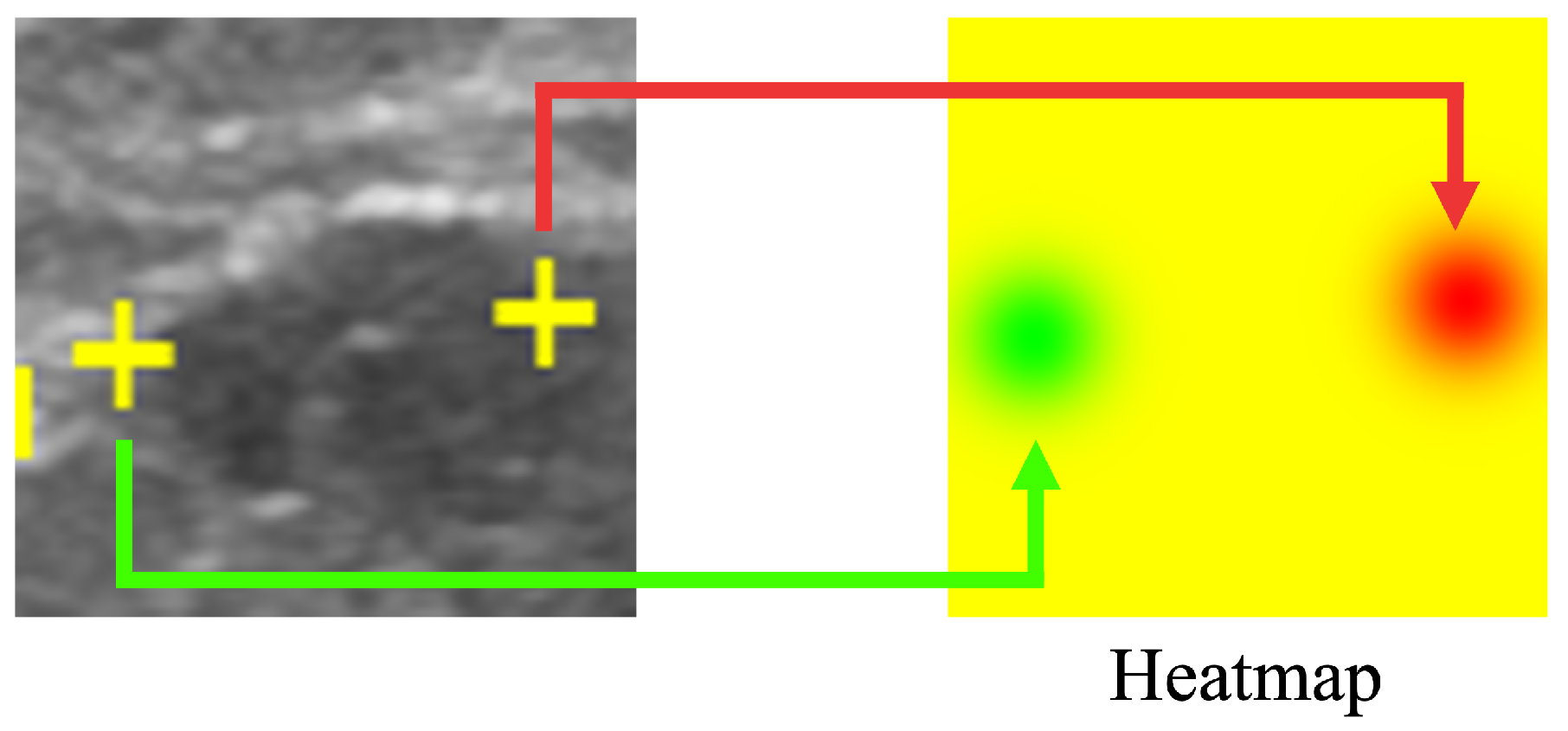
2.3. Saliency Map Representing the Location of Salient Landmarks
2.4. Salient Landmark Position Prediction Model
2.5. Post-Processing
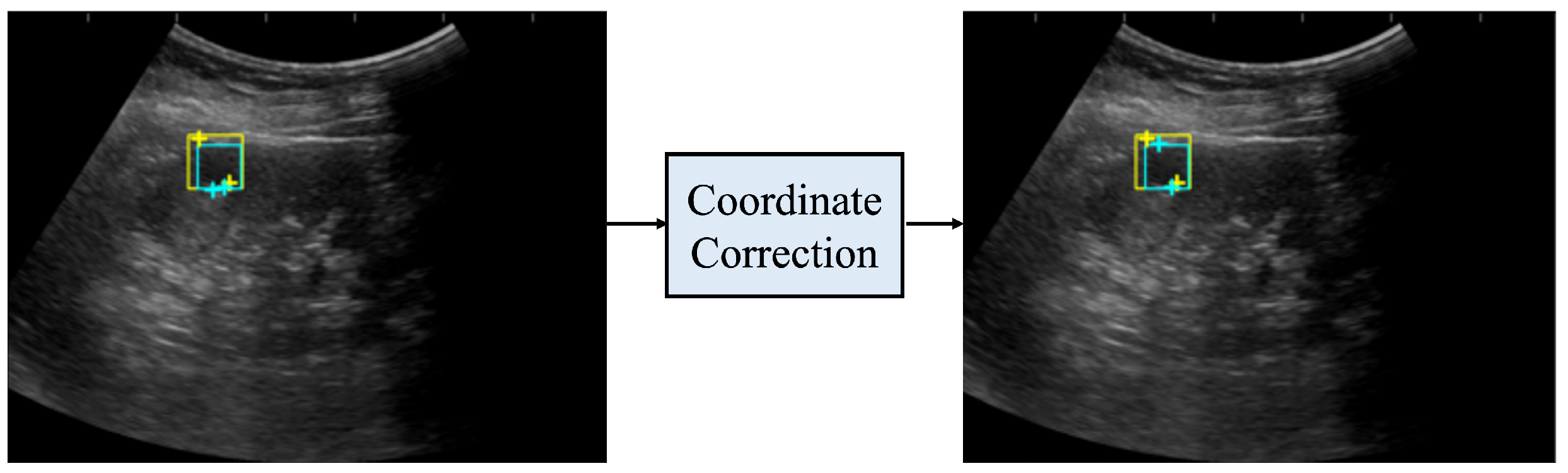
2.6. Coordinate Correction
2.7. Evaluation Metrics
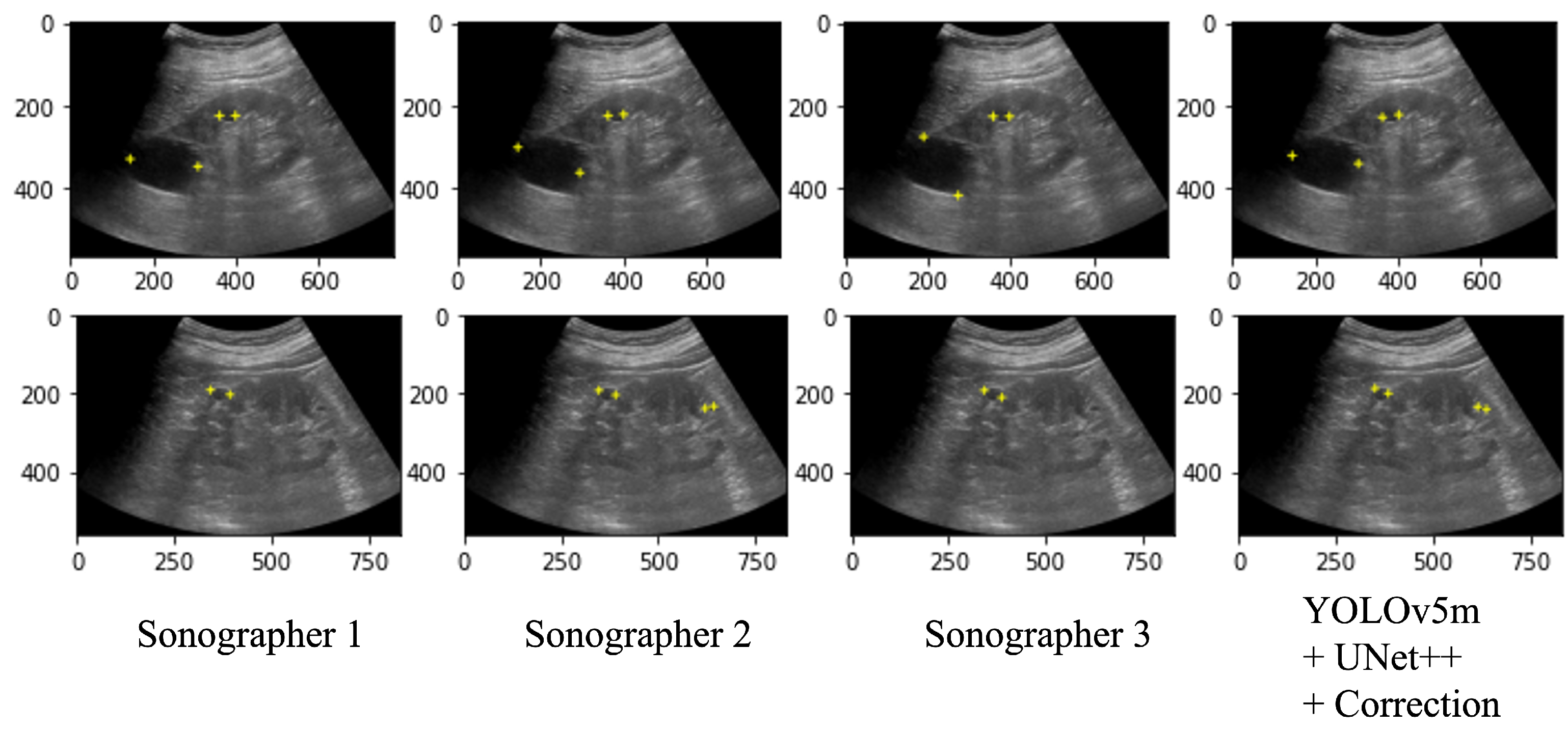
2.8. Performance Comparison of Model and Sonographers
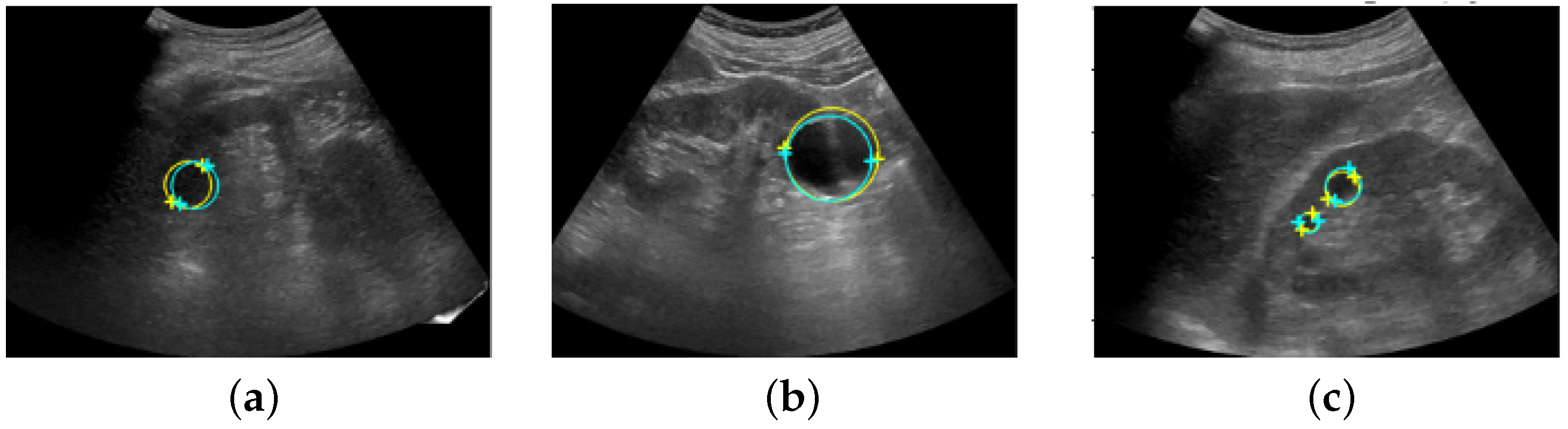
2.9. Post Hoc Evaluation by a Radiologist
2.10. Deep Learning Framework and Computation Time
2.11. Materials
2.12. Ethics
3. Result
3.1. Performance Comparison of Model and Sonographers
3.2. Post Hoc Evaluation by Radiologist
3.3. Computational Time
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarris, I.; Ioannou, C.; Chamberlain, P.; Ohuma, E.; Roseman, F.; Hoch, L.; Altman, D.G.; Papageorghiou, A.T. Intra- and interobserver variability in fetal ultrasound measurements. Ultrasound Obstet. Gynecol. 2012, 39, 266–273. [Google Scholar] [CrossRef] [PubMed]
- Akkus, Z.; Cai, J.; Boonrod, A.; Zeinoddini, A.; Weston, A.D.; Philbrick, K.A.; Erickson, B.J. A Survey of Deep-Learning Applications in Ultrasound: Artificial Intelligence-Powered Ultrasound for Improving Clinical Workflow. J. Am. Coll. Radiol. 2019, 16, 1318–1328. [Google Scholar] [CrossRef]
- Ma, J.; Wu, F.; Jiang, T.; Zhu, J.; Kong, D. Cascade convolutional neural networks for automatic detection of thyroid nodules in ultrasound images. Med. Phys. 2017, 44, 1678–1691. [Google Scholar] [CrossRef]
- Li, X.; Zhang, S.; Jiang, Q.; Wei, X.; Pan, Y.; Zhao, J.; Xin, X.; Qin, C.; Wang, X.; Li, J.; et al. Diagnosis of thyroid cancer using deep convolutional neural network models applied to sonographic images: A retrospective, multicohort, diagnostic study. Lancet Oncol. 2017, 20, 193–201. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Byra, M.; Galperin, M.; Ojeda-Fournier, H.; Olson, L.; O’Boyle, M.; Comstock, C.; Andre, M. Breast mass classification in sonography with transfer learning using a deep convolutional neural network and color conversion. Med. Phys. 2018, 46, 746–755. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Song, J.L.; Wang, S.H.; Chen, Y.Q. Learning to diagnose cirrhosis with liver capsule guided ultrasound image classification. Sensors 2017, 17, 149. [Google Scholar] [CrossRef] [PubMed]
- Muresan, M.P.; Barbura, A.R.; Nedevschi, S. Teeth Detection and Dental Problem Classification in Panoramic X-ray Images using Deep Learning and Image Processing Techniques. In Proceedings of the IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; pp. 457–463. [Google Scholar]
- Pang, S.; Pang, C.; Zhao, L.; Chen, Y.; Su, Z.; Zhou, Y.; Huang, M.; Yang, W.; Lu, H.; Feng, Q. SpineParseNet: Spine Parsing for Volumetric MR Image by a Two-Stage Segmentation Framework With Semantic Image Representation. IEEE Trans. Med. Imaging 2021, 40, 262–273. [Google Scholar] [CrossRef] [PubMed]
- Gu, R.; Wang, G.; Song, T.; Huang, R.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. CA-Net: Comprehensive Attention Convolutional Neural Networks for Explainable Medical Image Segmentation. IEEE Trans. Med. Imaging 2021, 40, 699–711. [Google Scholar] [CrossRef] [PubMed]
- Takeuchi, M.; Seto, T.; Hashimoto, M.; Ichihara, N.; Morimoto, Y.; Kawakubo, H.; Suzuki, T.; Jinzaki, M.; Kitagawa, Y.; Miyata, H.; et al. Performance of a deep learning-based identification system for esophageal cancer from CT images. Esophagus 2021, 18, 612. [Google Scholar] [CrossRef]
- Payer, C.; Li, D.; Bischof, H.; Urschler, M. Regressing Heatmaps for Multiple Landmark Localization Using CNNs. Med. Image Comput. Comput. Assist. Interv. 2016, 9901, 230. [Google Scholar]
- Zhong, Z.; Li, J.; Zhang, Z.; Jiao, Z. An attention-guided deep regression model for landmark detection in cephalograms. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 540–548. [Google Scholar]
- Chen, X.; He, M.; Dan, T.; Wang, N.; Lin, M.; Lin, Z.; Xian, J.; Cai, H.; Xie, H. Automatic measurements of fetal lateral ventricles in 2D ultrasound images using deep learning. Front. Neurol. 2020, 11, 526. [Google Scholar] [CrossRef]
- Biswas, M.; Kuppli, V.; Araki, T.; Edla, D.R.; Godia, E.C.; Saba, L.; Suri, H.S.; Omerzu, T.; Laird, J.; Khanna, N.N.; et al. Deep learning strategy for accurate carotid intima-media thickness measurement: An ultrasound study on Japanese diabetic cohort. Comput. Biol. Med. 2018, 98, 100–117. [Google Scholar] [CrossRef] [PubMed]
- Leclerc, S.; Smistad, E.; Pedrosa, J.; Østvik, A.; Cervenansky, F.; Espinosa, F.; Espeland, T.; Berg, E.A.R.; Jodoin, P.; Grenier, T.; et al. Deep learning for segmentation using an open large-scale dataset in 2D echocardiography. IEEE Trans. Med. Imaging 2019, 38, 2198–2210. [Google Scholar] [CrossRef] [PubMed]
- Jagtap, J.M.; Gregory, A.V.; Homes, H.L.; Wright, D.E.; Edwards, M.E.; Akkus, Z.; Erickson, B.J.; Kline, T.L. Automated measurement of total kidney volume from 3D ultrasound images of patients affected by polycystic kidney disease and comparison to MR measurements. Abdom. Radiol. 2022, 47, 2408–2419. [Google Scholar] [CrossRef] [PubMed]
- Akkasaligar, P.T.; Biradar, S. Automatic Kidney Cysts Segmentation in Digital Ultrasound Images. In Medical Imaging Methods; Springer: Berlin/Heidelberg, Germany, 2019; pp. 97–117. [Google Scholar]
- Hines, J.J., Jr.; Eacobacci, K.; Goyal, R. The Incidental Renal Mass- Update on Characterization and Management. Radiol. Clin. N. Am. 2021, 59, 631–646. [Google Scholar] [CrossRef] [PubMed]
- YOLOv5 in PyTorch > ONNX > CoreML > TFLite—GitHub. Available online: https://github.com/ultralytics/yolov5 (accessed on 17 January 2022).
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Linn, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Remanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Wang, C.-Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Song, Q.; Li, S.; Bai, Q.; Yang, J.; Zhang, X.; Li, Z.; Duan, Z. Object Detection Method for Grasping Robot Based on Improved YOLOv5. Micromachines 2021, 12, 1273. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017. [Google Scholar]
- Kwon, O.; Yong, T.H.; Kang, S.R.; Kim, J.E.; Huh, K.H.; Heo, M.S.; Lee, S.S.; Choi, S.C.; Yi, W.J. Automatic diagnosis for cysts and tumors of both jaws on panoramic radiographs using a deep convolution neural network. Br. Inst. Radiol. Dentomaxillofac. Radiol. 2020, 49, 20200185. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Object | Task |
|---|---|---|
| Ma et al. [3] | thyroid nodules | detection |
| Li et al. [4] | thyroid cancer | classification |
| Byra et al. [6] | breast cancer | classification |
| Liu et al. [7] | liver membrane | detection & classification |
| Chen et al. [14] | fetal lateral ventricles | measurement |
| Biswas et al. [15] | carotid | measurement |
| Leclerc et al. [16] | left ventricular | measurement |
| Jagtap et al. [17] | kidney | measurement |
| Akkasaligar et al. [18] | renal cysts | segmentation |
| Our study | renal cysts | landmark placement |
| Parameter | Range of Parameter to Be Searched |
|---|---|
| CNN architecture | VGG16, ResNet50, densenet121 |
| Decode method | transpose, upsampling |
| Number of decoder filters | (128, 64, 32, 16, 8), (256, 128, 64, 32, 16), (512, 256, 128, 64, 32) |
| Batch size | 8 to 32 (21) |
| Detection Accuracy | Position Error [mm] | DLE [mm] | |||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | p-Value * (of t-Test for IoU Average) | Mean | Median | Mean | Median | |
| YOLOv5s + UNet++ | 0.71 | 0.75 | 0.07 | 3.54 ± 2.81 | 2.54 | 1.22 ± 1.04 | 1.02 |
| YOLOv5s + UNet++ + Correction | 0.78 | 0.82 | 0.07 | 3.59 ± 2.81 | 2.63 | 1.19 ± 1.02 | 0.93 |
| YOLOv5m + UNet++ | 0.81 | 0.81 | 0.26 | 3.15 ± 2.48 | 2.36 | 1.08 ± 0.83 | 0.90 |
| YOLOv5m + UNet++ + Correction | 0.85 | 0.86 | - | 3.22 ± 2.57 | 2.36 | 1.09 ± 0.80 | 0.89 |
| YOLOv5l + UNet++ | 0.74 | 0.78 | 0.07 | 3.19 ± 2.57 | 2.51 | 1.06 ± 1.92 | 0.90 |
| YOLOv5l + UNet++ + Correction | 0.82 | 0.86 | 0.18 | 3.29 ± 2.66 | 2.60 | 1.13 ± 1.00 | 0.88 |
| YOLOv5x + UNet++ | 0.70 | 0.73 | 0.004 | 3.05 ± 2.72 | 2.39 | 1.15 ± 0.87 | 1.05 |
| YOLOv5x + UNet++ + Correction | 0.77 | 0.81 | 0.04 | 3.24 ± 2.73 | 2.63 | 1.13 ± 0.89 | 0.91 |
| Detection Accuracy | Position Error [mm] | DLE [mm] | |||||
| Precision | Recall | Mean | Median | Mean | Median | ||
| Sonographer 2 | 0.86 | 0.87 | 2.56 ± 2.76 | 1.42 | 1.21 ± 1.36 | 0.89 | |
| Sonographer 3 | 0.83 | 0.84 | 2.34 ± 2.63 | 1.53 | 0.95 ± 1.07 | 0.63 | |
| YOLOv5m + UNet++ + Correction | 0.85 | 0.86 | 3.22 ± 2.57 | 2.36 | 1.09 ± 0.8 | 0.89 | |
| False | False | Corrected Coordinates | Position Error [mm] | |||
|---|---|---|---|---|---|---|
| Positive [Pair] | Negative [Pair] | Number of Images [Image] | Number of Landmarks [Point] | Mean | Median | |
| Sonographer 2 | 3 | 3 | 16 | 18 | 9.09 ± 5.90 | 6.80 |
| Sonographer 3 | 1 | 0 | 14 | 21 | 8.65 ± 5.40 | 7.24 |
| YOLOv5m + UNet++ + Correction | 1 | 1 | 16 | 22 | 8.49 ± 8.04 | 5.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanauchi, Y.; Hashimoto, M.; Toda, N.; Okamoto, S.; Haque, H.; Jinzaki, M.; Sakakibara, Y. Automatic Detection and Measurement of Renal Cysts in Ultrasound Images: A Deep Learning Approach. Healthcare 2023, 11, 484. https://doi.org/10.3390/healthcare11040484
Kanauchi Y, Hashimoto M, Toda N, Okamoto S, Haque H, Jinzaki M, Sakakibara Y. Automatic Detection and Measurement of Renal Cysts in Ultrasound Images: A Deep Learning Approach. Healthcare. 2023; 11(4):484. https://doi.org/10.3390/healthcare11040484
Chicago/Turabian StyleKanauchi, Yurie, Masahiro Hashimoto, Naoki Toda, Saori Okamoto, Hasnine Haque, Masahiro Jinzaki, and Yasubumi Sakakibara. 2023. "Automatic Detection and Measurement of Renal Cysts in Ultrasound Images: A Deep Learning Approach" Healthcare 11, no. 4: 484. https://doi.org/10.3390/healthcare11040484
APA StyleKanauchi, Y., Hashimoto, M., Toda, N., Okamoto, S., Haque, H., Jinzaki, M., & Sakakibara, Y. (2023). Automatic Detection and Measurement of Renal Cysts in Ultrasound Images: A Deep Learning Approach. Healthcare, 11(4), 484. https://doi.org/10.3390/healthcare11040484