

Disease Prediction Using Graph Machine Learning Based on Electronic Health Data: A Review of Approaches and Trends



Abstract
:1. Introduction
1.1. Comparisons with the Existing Literature Reviews
1.2. Motivations and Contributions
- We review and classify different levels of graph machine-learning approaches.
- The applications of disease prediction in different graph ML approaches are summarised.
- We highlight the shortcomings in the present research, pointing to future research directions and opportunities.
2. Overview and Search Strategy
3. Graph Machine-Learning Approaches
3.1. Shallow Embedding
3.1.1. Hand-Crafted Features
3.1.2. Random Walk-Based Methods
3.2. Graph Neural Network-Based Methods
3.2.1. Graph Convolutional Networks
3.2.2. Graph Attention Networks
3.2.3. Graph Auto-Encoders
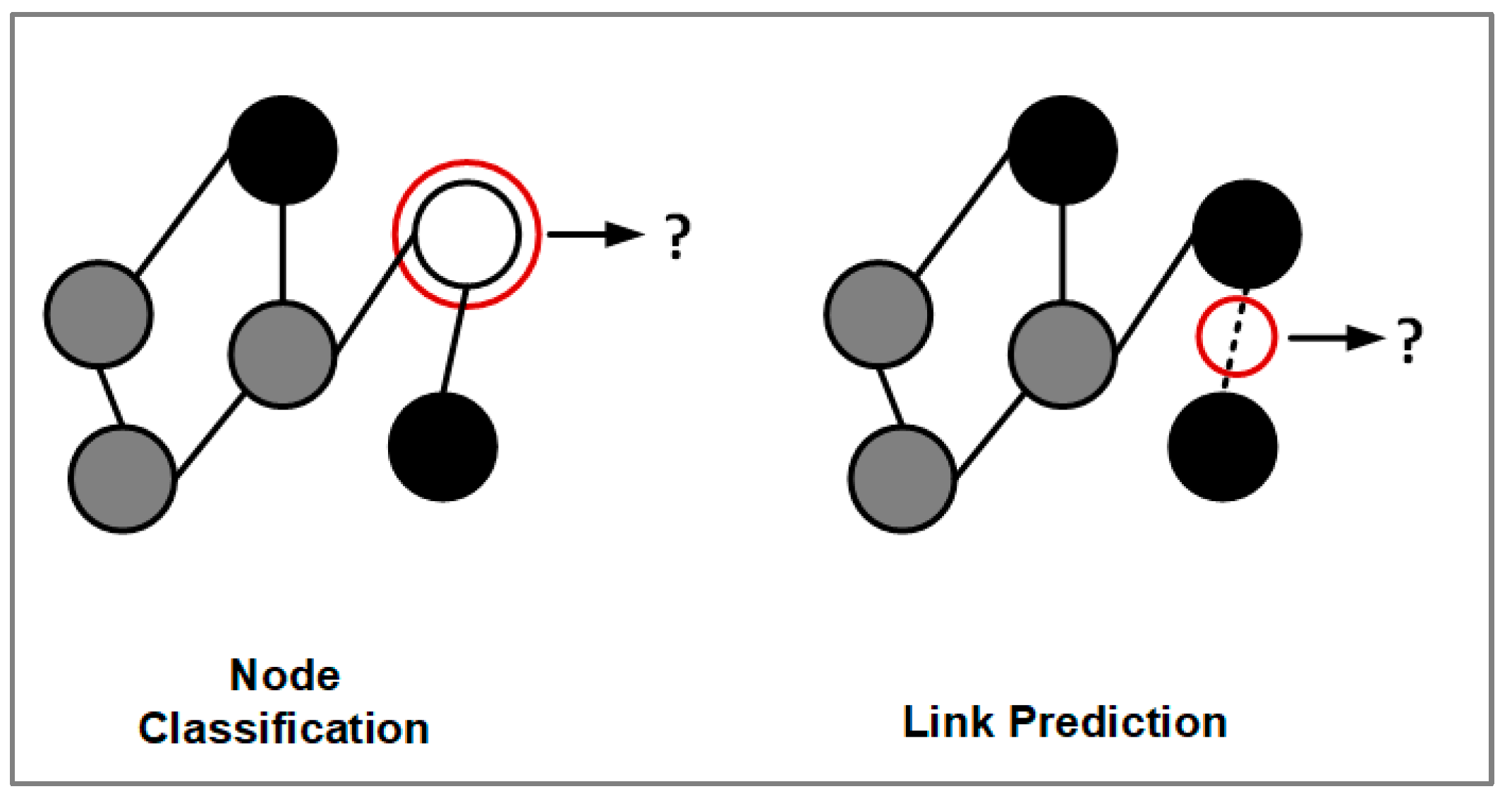
4. Applications in Disease Prediction
4.1. Node Classification
4.2. Link Prediction
5. Findings


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Disease Predicted | Type of Data | Data Size | Task | Methods | Prediction Performance | Source Code |
|---|---|---|---|---|---|---|---|
| Liu et al. (2015) [53] | One-year hospitalisation prediction and congestive heart failure (CHF) | Real-world electronic health records over four years | 319,650 | Node classification | Shallow embedding (hand-crafted) | Accuracy: 76% (CHF), 65% (hospitalisation) | - |
| Khan et al. (2019) [8] | Type 2 diabetes | Administrative claim data from an Australian insurance company | 2300 | Node classification | Shallow embedding (hand-crafted) | Accuracy: 82–87% (for different machine-learning methods) | - |
| Hossain et al. (2020) [54] | Cardiovascular disease in patients with type 2 diabetes | Administrative claim data from an Australian insurance company | 172 | Node classification | Shallow embedding (hand-crafted) | Accuracy: 79–88% (for different machine-learning methods) | - |
| Lu et al. (2021) [12] | Type 2 diabetes | Administrative claim data from an Australian insurance company | 2056 | Node classification | Shallow embedding (hand-crafted) | Area under curve (AUC): 0.79–0.91 (for different machine-learning methods) | - |
| Choi et al. (2017) [55] | Heart failure | Three different datasets (Sutter PAMF, Medical Information Mart for Intensive Care (MIMIC)-III, and Sutter Heart failure cohort) | 258,555, 7499, and 30,737, respectively | Node classification | Shallow embedding (hand-crafted and random walk) | AUC: 0.7970–0.8448 (using different training ratios) | https://github.com/mp2893/gram (accessed on 3 March 2023) |
| Zhang et al. (2017) [56] | Chronic disease comorbidity in patients | Anonymised electronic healthcare records data from a major medical centre | 381,169 | Node classification | Shallow embedding (hand-crafted) | F1 score: 0.26–0.48 (for different comorbidities) | - |
| Xu et al. (2020) [57] | Post-discharge self-harm incidents | Electronic healthcare records collected from Hong Kong residents | 2323 self-harm samples and 46,460 counterparts | Node classification | Shallow embedding (tandom walk) | C-statistic: 0.89 | - |
| Yang et al. (2022) [70] | Ischemic heart disease | Hospital discharge records from China | 72,668 | Node classification | Shallow embedding (hand-crafted) | AUC: 0.864–0.900 | |
| Sun et al. (2020) [58] | Multiple diseases | Real-world electronic healthcare records: private patient clinical record dataset collected from local hospitals | 806 | Node classification | GNN based (GAT and graph auto-encoder) | F1-score: 0.457 (all diseases), 0.442 (rare diseases) | https://github.com/zhchs/Disease-Prediction-via-GCN (accessed on 3 March 2023) |
| Wang et al. (2020) [59] | Cancer | Electronic healthcare records collected from the US | 159 for breast cancer and 160 for the lung squamous cell cancer | Node classification | GNN based (GCN) | Accuracy: 92.80% (for invasive breast carcinoma), 80.50% (lung squamous cell carcinoma) | - |
| Gao et al. (2020) [60] | Breast cancer | Electronic health records from Memorial Sloan Kettering Cancer Center | 1903 | Node classification | GNN based (graph auto-encoder) | Accuracy: 94% | - |
| Lu and Uddin (2021) [7] | Cardiovascular and chronic pulmonary | Administrative claim data from an Australian insurance company | 2610 for the cardiovascular and 1056 for the chronic pulmonary | Node classification | GNN based (GCN and GAT) | Accuracy: 93.49% (cardiovascular disease), 89.15% (chronic pulmonary disease) | - |
| Li et al. (2020) [61] | Multiple diseases | A real-world longitudinal electronic health records database | 7499 | Node classification | GNN based (GCN) | Accuracy: 81.76% | - |
| Zhu and Razavian (2021) [62] | Alzheimer’s disease and multiple predictive tasks | Electronic health records, MIMIC-III, and eICU | 6028, 6778, and 3250, respectively | Node classification | GNN based (graph auto-encoder) | The area under the precision-recall curve (AUPRC): 0.4580 (AD-HER), 0.7102 (MIMIC-II), and 0.3986 (eICU readmission) | https://github.com/NYUMedML/GNN_for_EHR (accessed on 3 March 2023) |
| Wang et al. (2020) [66] | Multiple diseases | General hospital data from two hospitals in Beijing and Shenzhen, China | 7989 and 4131, respectively | Link prediction | Shallow embedding (hand-crafted) | Mean accuracy: 85.75–89.87 (for the different schemes and datasets) | - |
| del Valle et al. (2021) [67] | Multiple diseases | Electronic health records: DISNET | 5147 | Link prediction | Shallow embedding (tandom walk) | AUC: 0.74 | - |
| Wang et al., (2020) [69] | Multiple diseases | Electronic health records from New York State Medicaid | 596,574 | Link prediction | GNN based (GCN) | RMSE: 0.8622 | - |
| Lu and Uddin (2022) [71] | Multiple diseases | Administrative claim data from an Australian insurance company | 19,828 | Link prediction | Shallow embedding (hand-crafted and random walk) and GNN based (GCN) | AUC: 0.7964 to 0.8969. | - |
6. Discussions and Future Directions
6.1. Benefits and Drawbacks
6.2. Data Processing
6.3. Challenges and Trends
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| AUC | Area under curve |
| AUPRC | The area under the precision-recall curve |
| CHF | Congestive heart failure |
| CNN | Convolutional neural network |
| DL | Deep learning |
| GAE | Graph auto-encoders |
| GAT | Graph attention network |
| GCN | Graph convolutional network |
| GNN | Graph neural networks |
| HCNN | Heterogeneous convolution neural network |
| MIMIC | Medical Information Mart for Intensive Care |
| ML | Machine learning |
| LSTM | Long short-term memory |
| T2D | Type 2 diabetes |
| VGAE | Variation graph auto-encoder |
References
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.E.; Khan, A.; Moni, M.A.; Uddin, S. Use of electronic health data for disease prediction: A comprehensive literature review. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 18, 745–758. [Google Scholar] [CrossRef] [PubMed]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 281. [Google Scholar] [CrossRef]
- Ravì, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.Z. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 2016, 21, 4–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Q.; Boueiz, A.; Bozkurt, A.; Masoomi, A.; Wang, A.; DeMeo, D.L.; Weiss, S.T.; Qiu, W. Deep Learning Methods for Predicting Disease Status Using Genomic Data. J. Biom. Biostat. 2018, 9, 417. [Google Scholar] [PubMed]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, H.; Uddin, S. A weighted patient network-based framework for predicting chronic diseases using graph neural networks. Sci. Rep. 2021, 11, 22607. [Google Scholar] [CrossRef]
- Khan, A.; Uddin, S.; Srinivasan, U. Chronic disease prediction using administrative data and graph theory: The case of type 2 diabetes. Expert Syst. Appl. 2019, 136, 230–241. [Google Scholar] [CrossRef]
- Nicholson, D.N.; Greene, C.S. Constructing knowledge graphs and their biomedical applications. Comput. Struct. Biotechnol. J. 2020, 18, 1414–1428. [Google Scholar] [CrossRef]
- Ghosh, A. Electronic structure of corrole derivatives: Insights from molecular structures, spectroscopy, electrochemistry, and quantum chemical calculations. Chem. Rev. 2017, 117, 3798–3881. [Google Scholar] [CrossRef]
- Lezon, T.R.; Banavar, J.R.; Cieplak, M.; Maritan, A.; Fedoroff, N.V. Using the principle of entropy maximization to infer genetic interaction networks from gene expression patterns. Proc. Natl. Acad. Sci. USA 2006, 103, 19033–19038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, H.; Uddin, S.; Hajati, F.; Moni, M.A.; Khushi, M. A patient network-based machine learning model for disease prediction: The case of type 2 diabetes mellitus. Appl. Intell. 2021, 52, 2411–2422. [Google Scholar] [CrossRef]
- Stamile, C.; Marzullo, A.; Deusebio, E. Graph Machine Learning: Take Graph Data to the Next Level by Applying Machine Learning Techniques and Algorithms; Packt Publishing Ltd.: Birmingham, UK, 2021. [Google Scholar]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. 2017, 18, 851–869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, M.; Zhao, S.; Gilvary, C.; Elemento, O.; Zhou, J.; Wang, F. Graph convolutional networks for computational drug development and discovery. Brief. Bioinform. 2020, 21, 919–935. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.M.; Liang, L.; Liu, L.; Tang, M.J. Graph neural networks and their current applications in bioinformatics. Front. Genet. 2021, 12, 690049. [Google Scholar] [CrossRef]
- Ahmedt-Aristizabal, D.; Armin, M.A.; Denman, S.; Fookes, C.; Petersson, L. Graph-based deep learning for medical diagnosis and analysis: Past, present and future. Sensors 2021, 21, 4758. [Google Scholar] [CrossRef]
- Xiaoai, G.; Yujing, X.; Lin, L.; Lin, T. An Overview of Disease Prediction based on Graph Convolutional Neural Network. In Proceedings of the 6th International Conference on Intelligent Information Processing, Xi’an, China, 9–11 April 2021. [Google Scholar]
- Yue, X.; Wang, Z.; Huang, J.; Parthasarathy, S.; Moosavinasab, S.; Huang, Y.; Lin, S.M.; Zhang, W.; Zhang, P.; Sun, H. Graph embedding on biomedical networks: Methods, applications and evaluations. Bioinformatics 2020, 36, 1241–1251. [Google Scholar] [CrossRef] [Green Version]
- Waikhom, L.; Patgiri, R. A survey of graph neural networks in various learning paradigms: Methods, applications, and challenges. Artifical Intell. Rev. 2022, 1–70. [Google Scholar] [CrossRef]
- National Library of Medicine. PubMed. 2022. Available online: https://pubmed.ncbi.nlm.nih.gov (accessed on 27 October 2022).
- ELSEVIER, Scopus. 2022. Available online: https://www.elsevier.com/en-au (accessed on 27 October 2022).
- ACM Digital Library. ACM Digital Library. 2022. Available online: https://dl.acm.org (accessed on 27 October 2022).
- IEEE, IEEEXplore. 2022. Available online: https://ieeexplore.ieee.org/Xplore/home.jsp (accessed on 27 October 2022).
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Shaw, M.E. Group structure and the behavior of individuals in small groups. J. Psychol. 1954, 38, 139–149. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Holland, P.W.; Leinhardt, S. Transitivity in structural models of small groups. Comp. Group Stud. 1971, 2, 107–124. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. IEEE Int. Jt. Conf. Neural Netw. 2005, 2, 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Liu, Z.; Zhou, J. Introduction to graph neural networks. Synth. Lect. Artif. Intell. Mach. Learn. 2020, 14, 1–127. [Google Scholar]
- Duvenaud, D.K.; Maclaurin, D.; Iparraguirre, J.; Bombarell, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional networks on graphs for learning molecular fingerprints. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Vashishth, S.; Yadati, N.; Talukdar, P. Graph-based deep learning in natural language processing. In Proceedings of the 7th ACM IKDD CoDS and 25th COMAD, Hyderabad, India, 5–7 January 2020; pp. 371–372. [Google Scholar]
- Kwak, H.; Lee, M.; Yoon, S.; Chang, J.; Park, S.; Jung, K. Drug-Disease Graph: Predicting Adverse Drug Reaction Signals via Graph Neural Network with Clinical Data. Adv. Knowl. Discov. Data Min. 2020, 12085, 633. [Google Scholar]
- Li, M.M.; Huang, K.; Zitnik, M. Representation learning for networks in biology and medicine: Advancements, challenges, and opportunities. arXiv 2021, arXiv:2104.04883. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep convolutional networks on graph-structured data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Mason, J.C.; Handscomb, D.C. Chebyshev Polynomials; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6 August 2017. PMLR. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Liu, C.; Wang, F.; Hu, J.; Xiong, H. Temporal phenotypingfrom longitudinal electronic health records: A graph based framework. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Hossain, M.E.; Uddin, S.; Khan, A. Network analytics and machine learning for predictive risk modelling of cardiovascular disease in patients with type 2 diabetes. Expert Syst. Appl. 2020, 164, 113918. [Google Scholar] [CrossRef]
- Choi, E.; Bahadori, M.T.; Song, L.; Stewart, W.F.; Sun, J. GRAM: Graph-based attention model for healthcare representation learning. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Zhang, J.; Gong, J.; Barnes, L. HCNN: Heterogeneous convolutional neural networks for comorbid risk prediction with electronic health records. In Proceedings of the IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Philadelphia, PA, USA, 17–19 July 2017. [Google Scholar]
- Xu, Z.; Zhang, Q.; Yip, P.S.F. Predicting post-discharge self-harm incidents using disease comorbidity networks: A retrospective machine learning study. J. Affect. Disord. 2020, 277, 402–409. [Google Scholar] [CrossRef]
- Sun, Z.; Yin, H.; Chen, H.; Chen, T.; Cui, L.; Yang, F. Disease Prediction via Graph Neural Networks. IEEE J. Biomed. Health Inform. 2021, 25, 818–826. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Guo, J.; Zhao, N.; Liu, Y.; Liu, X.; Liu, G.; Guo, M. A Cancer Survival Prediction Method Based on Graph Convolutional Network. IEEE Trans. NanoBiosci. 2020, 19, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Lyu, T.; Xiong, F.; Wang, J.; Ke, W.; Li, Z. MGNN: A Multimodal Graph Neural Network for Predicting the Survival of Cancer Patients. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020. [Google Scholar]
- Li, Y.; Qian, B.; Zhang, X.; Liu, H. Graph neural network-based diagnosis prediction. Big Data 2020, 8, 379–390. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Razavian, N. Variationally regularized graph-based representation learning for electronic health records. In Proceedings of the Conference on Health, Inference, and Learning, Virtual Event, 8–10 April 2021. [Google Scholar]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef] [Green Version]
- Davis, D.A.; Chawla, N.V.; Blumm, N.; Christakis, N.; Barabási, A.-L. Predicting individual disease risk based on medical history. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008. [Google Scholar]
- Folino, F.; Pizzuti, C. Link prediction approaches for disease networks. In International Conference on Information Technology in Bio-and Medical Informatics; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Wang, T.; Qiu, R.G.; Yu, M.; Zhang, R. Directed disease networks to facilitate multiple-disease risk assessment modeling. Decis. Support Syst. 2020, 129, 113171. [Google Scholar] [CrossRef]
- del Valle, E.P.G.; Santamaría, L.P.; García, G.L.; Zanin, M.; Ruiz, E.M. A Meta-Path-Based Prediction Method for Disease Comorbidities. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Wang, R.; Chang, M.-C.; Radigan, M. Modeling Latent Comorbidity for Health Risk Prediction Using Graph Convolutional Network. In Proceedings of the Thirty-Third International Flairs Conference, North Miami Beach, FL, USA, 17–20 May 2020. [Google Scholar]
- Yang, P.; Qiu, H.; Wang, L.; Zhou, L. Early prediction of high-cost inpatients with ischemic heart disease using network analytics and machine learning. Expert Syst. Appl. 2022, 210, 118541. [Google Scholar] [CrossRef]
- Lu, H.; Uddin, S. A disease network-based recommender system framework for predictive risk modelling of chronic diseases and their comorbidities. Appl. Intell. 2022, 52, 10330–10340. [Google Scholar] [CrossRef]
- Uddin, S.; Haque, I.; Lu, H.; Moni, M.A.; Gide, E. Comparative performance analysis of k-nearest neighbour (kNN) algorithm and its different variants for disease prediction. Sci. Rep. 2022, 12, 6256. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- Ram Mohan Rao, P.; Murali Krishna, S.; Siva Kumar, A.P. Privacy preservation techniques in big data analytics: A survey. J. Big Data 2018, 5, 33. [Google Scholar] [CrossRef] [Green Version]
- Dai, E.; Wang, S. Towards self-explainable graph neural network. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 302–311. [Google Scholar]
- Almotiri, J.; Elleithy, K.; Elleithy, A. Comparison of autoencoder and principal component analysis followed by neural network for e-learning using handwritten recognition. In Proceedings of the IEEE Long Island Systems, Applications and Technology Conference (LISAT), Farmingdale, NY, USA, 4 May 2018; pp. 1–5. [Google Scholar]
- Park, J.; Lee, M.; Chang, H.J.; Lee, K.; Choi, J.Y. Symmetric graph convolutional autoencoder for unsupervised graph representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Kronk, C.A.; Everhart, A.R.; Ashley, F.; Thompson, H.M.; Schall, T.E.; Goetz, T.G.; Hiatt, L.; Derrick, Z.; Queen, R.; Ram, A.; et al. Transgender data collection in the electronic health record: Current concepts and issues. J. Am. Med. Inform. Assoc. 2022, 29, 271–284. [Google Scholar] [CrossRef] [PubMed]
- Udriștoiu, A.L.; Ghenea, A.E.; Udriștoiu, Ș.; Neaga, M.; Zlatian, O.M.; Vasile, C.M.; Popescu, M.; Țieranu, E.N.; Salan, A.-I.; Turcu, A.A.; et al. COVID-19 and Artificial Intelligence: An Approach to Forecast the Severity of Diagnosis. Life 2021, 11, p1281. [Google Scholar] [CrossRef] [PubMed]
- Vasile, C.M.; Udriștoiu, A.L.; Ghenea, A.E.; Popescu, M.; Gheonea, C.; Niculescu, C.E.; Ungureanu, A.M.; Udriștoiu, Ș.; Drocaş, A.I.; Gruionu, L.G.; et al. Intelligent Diagnosis of Thyroid Ultrasound Imaging Using an Ensemble of Deep Learning Methods. Medicina 2021, 57, 395. [Google Scholar] [CrossRef] [PubMed]






| Graph Machine-Learning Model | Advantage | Disadvantage |
|---|---|---|
| Shallow embedding (hand-crafted features) | ||
| Shallow embedding (deep walk based) | ||
| GCNs |
|
|
| GATs |
| |
| Graph auto-encoder |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; Uddin, S. Disease Prediction Using Graph Machine Learning Based on Electronic Health Data: A Review of Approaches and Trends. Healthcare 2023, 11, 1031. https://doi.org/10.3390/healthcare11071031
Lu H, Uddin S. Disease Prediction Using Graph Machine Learning Based on Electronic Health Data: A Review of Approaches and Trends. Healthcare. 2023; 11(7):1031. https://doi.org/10.3390/healthcare11071031
Chicago/Turabian StyleLu, Haohui, and Shahadat Uddin. 2023. "Disease Prediction Using Graph Machine Learning Based on Electronic Health Data: A Review of Approaches and Trends" Healthcare 11, no. 7: 1031. https://doi.org/10.3390/healthcare11071031
APA StyleLu, H., & Uddin, S. (2023). Disease Prediction Using Graph Machine Learning Based on Electronic Health Data: A Review of Approaches and Trends. Healthcare, 11(7), 1031. https://doi.org/10.3390/healthcare11071031