
A Comparison of Veterans with Problematic Opioid Use Identified through Natural Language Processing of Clinical Notes versus Using Diagnostic Codes

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Cohort
2.2. Annotation Guideline
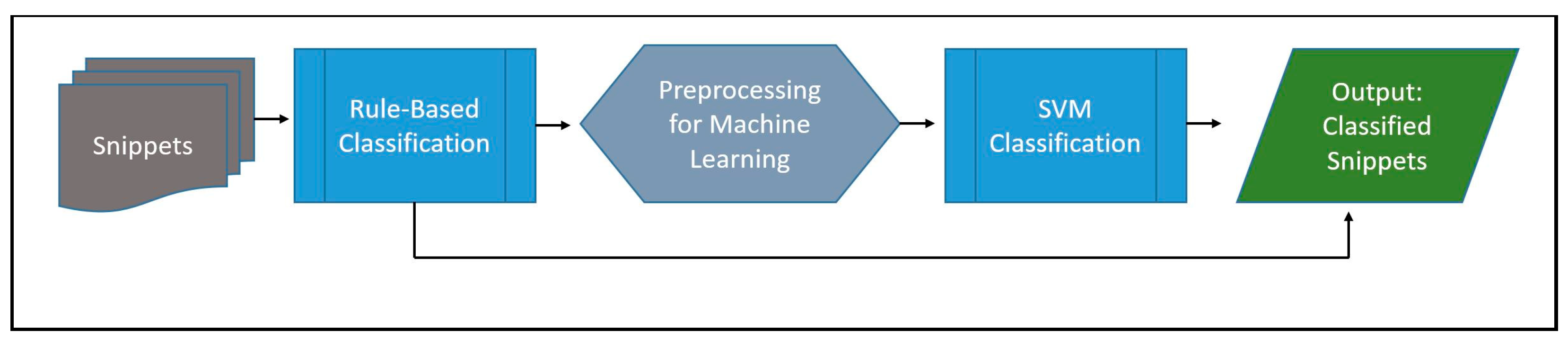
2.3. NLP Tool Development
2.4. Evaluation
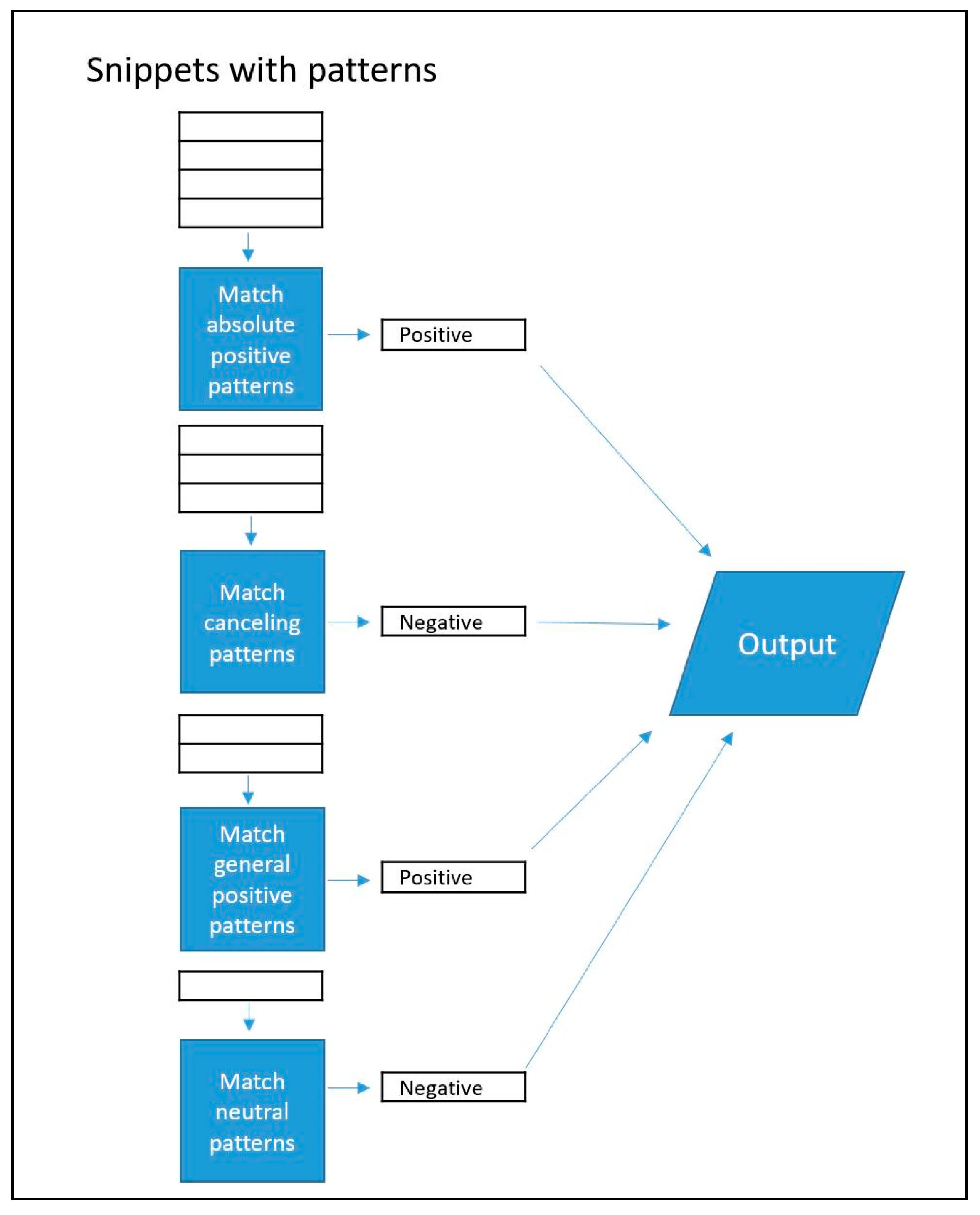
2.5. Classifying Cohort Notes
2.6. Statistical Analysis
2.7. Grouping Patients by Identification Method
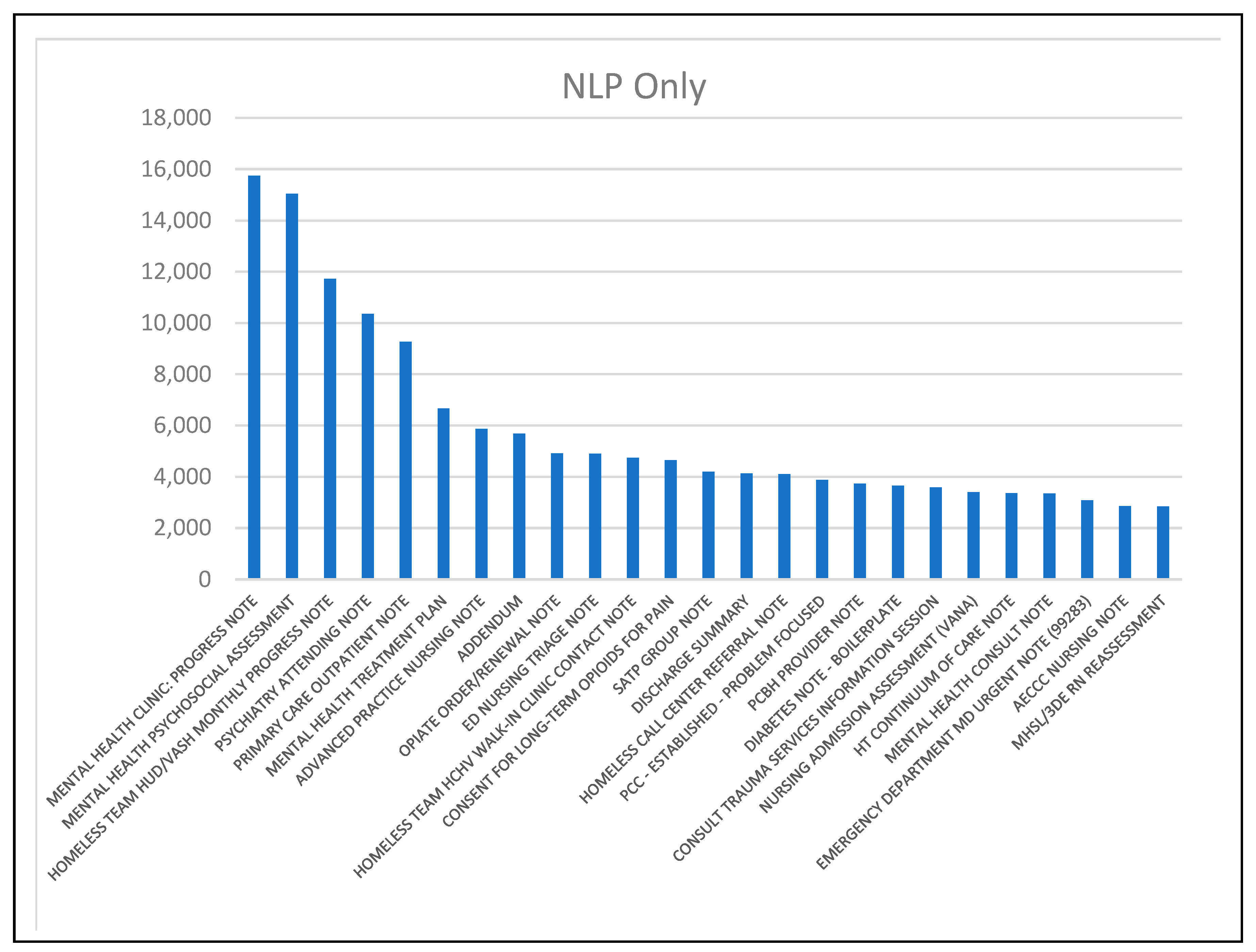
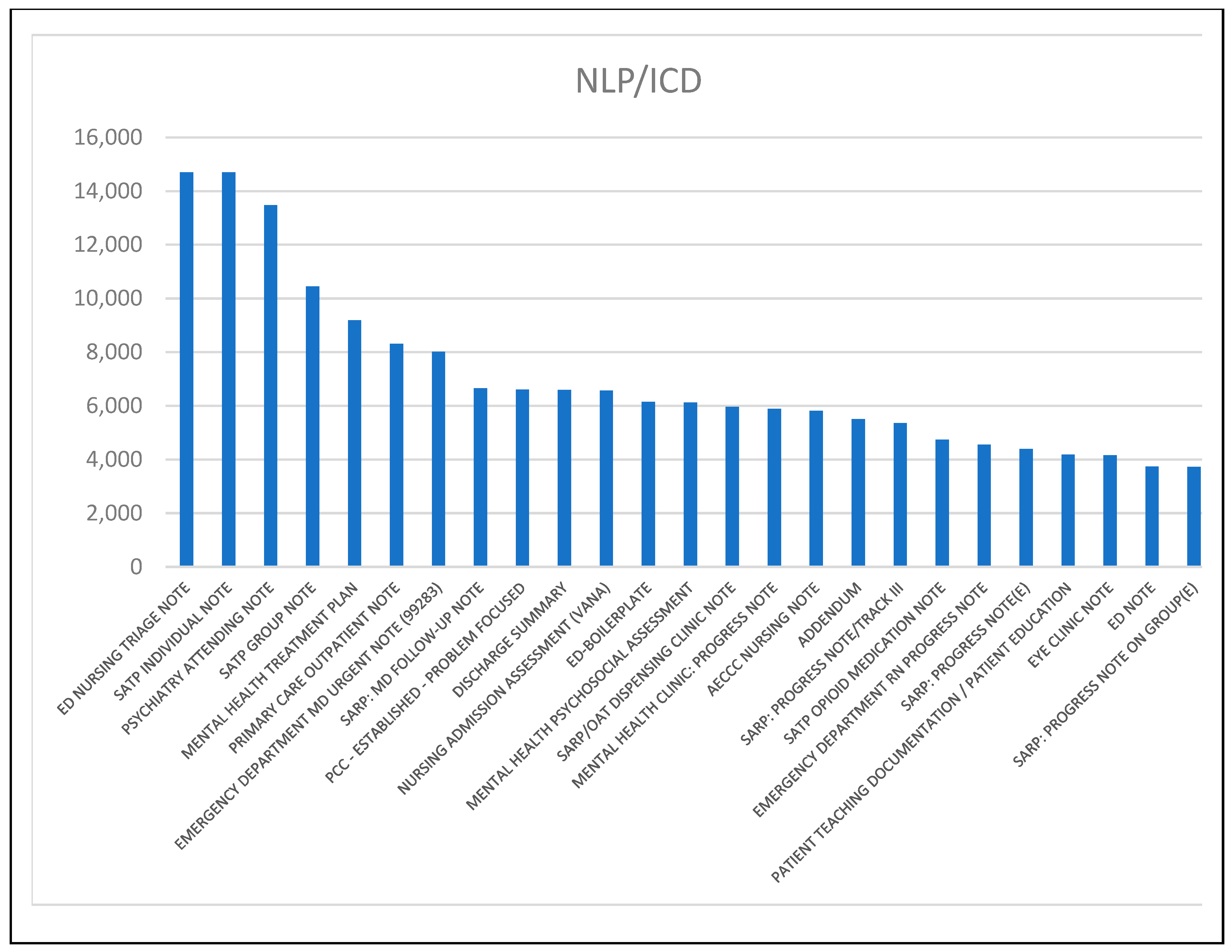
2.8. Prominent Note Types among Patient Groups
3. Results
3.1. Key Phrases
3.2. Classifier Performance
3.3. Clinical Note Classification
3.4. Problematic Opioid Use in Patients
3.5. NLP Classifications among Notes
3.6. Predominant Note Types
4. Discussion
4.1. Limitations
4.2. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keyword/Key Phrase Occurrence Counts in Notes | |||||
|---|---|---|---|---|---|
| abstral: 4 | duragesic: 2950 | hysingla: 75 | methadose: 46 | oxaydo: 6 | withdrawal: 975,669 |
| actiq: 587 | exalgo: 92 | kadian: 173 | morphine: 478,508 | oxycodone: 1,359,993 | zohydro:79 |
| demerol: 25,370 | fentanyl: 221,602 | lorcet: 145 | norco: 1555 | oxycontin: 72,111 | opioid dependence: 241,746 |
| dependence: 2,163,120 | fentora: 126 | lortab: 2888 | opiate: 402,730 | percocet: 581,122 | polysubstance abuse: 102,912 |
| dilaudid: 115,808 | hydrocodone: 199,524 | meperidine: 2788 | opiate abuse: 42,273 | roxicet: 298 | substance abuse: 1,403,341 |
| dolophine: 15 | hydromorphone: 212,451 | methadone: 648,154 | opioid: 899,720 | vicodin: 66,044 | substance dependence: 38,911 |
| Keyword/Key Phrase Occurrence Counts by Patient | |||||
|---|---|---|---|---|---|
| abstral: 2 | duragesic: 1241 | hysingla: 9 | methadose: 15 | oxaydo: 3 | withdrawal: 69,210 |
| actiq: 4 | exalgo: 29 | kadian: 33 | morphine: 25,252 | oxycodone: 41,943 | zohydro: 12 |
| demerol: 5952 | fentanyl: 36,664 | lorcet: 24 | norco: 851 | oxycontin: 10,197 | opioid dependence: 4482 |
| dependence: 54,712 | fentora: 10 | lortab: 1201 | opiate: 26,358 | percocet: 37,951 | polysubstance abuse: 8031 |
| dilaudid: 16,515 | hydrocodone: 20,937 | meperidine: 352 | opiate abuse: 2500 | roxicet: 96 | substance abuse: 77,072 |
| dolophine: 11 | hydromorphone: 11,675 | methadone: 20,805 | opioid: 27,979 | vicodin: 18,326 | substance dependence: 11,327 |
References
- Centers for Disease Control and Prevention. Drug Overdose Deaths. 2 June 2022. Available online: https://www.cdc.gov/drugoverdose/deaths/index.html (accessed on 5 April 2024).
- NCS Injury Facts. Drug Overdoses. Available online: https://injuryfacts.nsc.org/home-and-community/safety-topics/drugoverdoses/ (accessed on 5 April 2024).
- Bohnert, A.S.; Ilgen, M.A.; Galea, S.; McCarthy, J.F.; Blow, F.C. Accidental poisoning mortality among patients in the Department of Veterans Affairs Health System. Med. Care 2011, 49, 393–396. [Google Scholar] [CrossRef] [PubMed]
- Warfield, S.C.; Bharat, C.; Bossarte, R.M.; DePhilippis, D.; Farrell, M.; Hoover, M., Jr.; Larney, S.; Marshalek, P.; McKetin, R.; Degenhardt, L. Trends in comorbid opioid and stimulant use disorders among Veterans receiving care from the Veterans Health Administration, 2005–2019. Drug Alcohol Depend. 2022, 232, 109310. [Google Scholar] [CrossRef] [PubMed]
- Peltzman, T.; Ravindran, C.; Schoen, P.M.; Morley, S.W.; Drexler, K.; Katz, I.R.; McCarthy, J.F. Brief Report: Opioid-Involved Overdose Mortality in United States Veterans. Am. J. Addict. 2020, 29, 340–344. [Google Scholar] [CrossRef] [PubMed]
- Ruhm, C.J. Geographic Variation in Opioid and Heroin Involved Drug Poisoning Mortality Rates. Am. J. Prev. Med. 2017, 53, 745–753. [Google Scholar] [CrossRef] [PubMed]
- Palumbo, S.A.; Adamson, K.M.; Krishnamurthy, S.; Manoharan, S.; Beiler, D.; Seiwell, A.; Young, C.; Metpally, R.; Crist, R.C.; Doyle, G.A.; et al. Assessment of Probable Opioid Use Disorder Using Electronic Health Record Documentation. JAMA Netw. Open 2020, 3, e2015909. [Google Scholar] [CrossRef] [PubMed]
- Blackley, S.V.; MacPhaul, E.; Martin, B.; Song, W.; Suzuki, J.; Zhou, L. Using Natural Language Processing and Machine Learning to Identify Hospitalized Patients with Opioid Use Disorder. AMIA Annu. Symp. Proc. 2020, 2020, 233–242. [Google Scholar]
- Carrell, D.S.; Cronkite, D.; Palmer, R.E.; Saunders, K.; Gross, D.E.; Masters, E.T.; Hylan, T.R.; Von Korff, M. Using natural language processing to identify problem usage of prescription opioids. Int. J. Med. Inform. 2015, 84, 1057–1064. [Google Scholar] [CrossRef] [PubMed]
- Afshar, M.; Sharma, B.; Bhalla, S.; Thompson, H.M.; Dligach, D.; Boley, R.A.; Kishen, E.; Simmons, A.; Perticone, K.; Karnik, N.S. External validation of an opioid misuse machine learning classifier in hospitalized adult patients. Addict. Sci. Clin. Pract. 2021, 16, 19. [Google Scholar] [CrossRef] [PubMed]
- Zhu, V.J.; Lenert, L.A.; Barth, K.S.; Simpson, K.N.; Li, H.; Kopscik, M.; Brady, K.T. Automatically identifying opioid use disorder in non-cancer patients on chronic opioid therapy. Health Informatics J. 2022, 28, 14604582221107808. [Google Scholar] [CrossRef]
- Sharma, B.; Dligach, D.; Swope, K.; Salisbury-Afshar, E.; Karnik, N.S.; Joyce, C.; Afshar, M. Publicly available machine learning models for identifying opioid misuse from the clinical notes of hospitalized patients. BMC Med. Inform. Decis. Mak. 2020, 20, 79. [Google Scholar] [CrossRef]
- Poulsen, M.N.; Freda, P.J.; Troiani, V.; Davoudi, A.; Mowery, D.L. Classifying Characteristics of Opioid Use Disorder From Hospital Discharge Summaries Using Natural Language Processing. Front. Public. Health 2022, 10, 850619. [Google Scholar] [CrossRef] [PubMed]
- Kashyap, A.; Callison-Burch, C.; Boland, M.R. A deep learning method to detect opioid prescription and opioid use disorder from electronic health records. Int. J. Med. Inform. 2023, 171, 104979. [Google Scholar] [CrossRef] [PubMed]
- Gabriel, R.A.; Park, B.H.; Mehdipour, S.; Bongbong, D.N.; Simpson, S.; Waterman, R.S. Leveraging a Natural Language Processing Model (Transformers) on Electronic Medical Record Notes to Classify Persistent Opioid Use After Surgery. Anesth. Analg. 2023, 137, 714–716. [Google Scholar] [CrossRef] [PubMed]
- Huang, K.; Altosaar, J.; Ranganath, R. Clinicalbert: Modeling clinical notes and predicting hospital readmission. arXiv 2019, arXiv:1904.05342. [Google Scholar]
- VA Informatics and Computing Infrastructure (VINCI). Available online: https://www.hsrd.research.va.gov/for_researchers/vinci/ (accessed on 5 April 2024).
- Workman, T.E.; Shao, Y.; Kupersmith, J.; Sandbrink, F.; Goulet, J.L.; Shaar, N.M.; Spevak, C.; Brandt, C.; Blackman, M.R.; Zeng-Treitler, Q. Explainable deep learning applied to understanding opioid use disorder and its risk factors. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4883–4888. [Google Scholar]
- Workman, T.E.; Kupersmith, J.; Goulet, J.L.; Spevak, C.; Brandt, C.; Sandbrink, F.; Blackman, M.R.; Shara, N.M.; Zeng-Treitler, Q. Identifying and understanding opioid use disorder in clinical notes. In Proceedings of the 12th IADIS International Conference e-Health 2020, EH 2020, Part of the 14th Multi Conference on Computer Science and Information Systems, MCCSIS 2020, Virtual, 21–23 July 2020; pp. 143–150. [Google Scholar]
- Wilson, R.C.; Shenhav, A.; Straccia, M.; Cohen, J.D. The eighty five percent rule for optimal learning. Nat. Commun. 2019, 10, 4646. [Google Scholar] [CrossRef] [PubMed]
- Austin, P.C. Balance diagnostics for comparing the distribution of baseline covariates between treatment groups in propensity-score matched samples. Stat. Med. 2009, 28, 3083–3107. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Lawrence Erlbaum Associates Publishers: Hillsdale, NJ, USA, 1988. [Google Scholar]
- Castaldelli-Maia, J.M.; Andrade, L.H.; Keyes, K.M.; Cerda, M.; Pilowsky, D.J.; Martins, S.S. Exploring the latent trait of opioid use disorder criteria among frequent nonmedical prescription opioid users. J. Psychiatr. Res. 2016, 80, 79–86. [Google Scholar] [CrossRef] [PubMed]
- Boscarino, J.A.; Rukstalis, M.R.; Hoffman, S.N.; Han, J.J.; Erlich, P.M.; Ross, S.; Gerhard, G.S.; Stewart, W.F. Prevalence of prescription opioid-use disorder among chronic pain patients: Comparison of the DSM-5 vs. DSM-4 diagnostic criteria. J. Addict. Dis. 2011, 30, 185–194. [Google Scholar] [CrossRef]
- Green, T.C.; Grimes Serrano, J.M.; Licari, A.; Budman, S.H.; Butler, S.F. Women who abuse prescription opioids: Findings from the Addiction Severity Index-Multimedia Version Connect prescription opioid database. Drug Alcohol Depend. 2009, 103, 65–73. [Google Scholar] [CrossRef]
- Hirschtritt, M.E.; Delucchi, K.L.; Olfson, M. Outpatient, combined use of opioid and benzodiazepine medications in the United States, 1993–2014. Prev. Med. Rep. 2018, 9, 49–54. [Google Scholar] [CrossRef]
- Cicero, T.J.; Wong, G.; Tian, Y.; Lynskey, M.; Todorov, A.; Isenberg, K. Co-morbidity and utilization of medical services by pain patients receiving opioid medications: Data from an insurance claims database. Pain 2009, 144, 20–27. [Google Scholar] [CrossRef]
- Edlund, M.J.; Steffick, D.; Hudson, T.; Harris, K.M.; Sullivan, M. Risk factors for clinically recognized opioid abuse and dependence among veterans using opioids for chronic non-cancer pain. Pain 2007, 129, 355–362. [Google Scholar] [CrossRef] [PubMed]
- Santoro, T.N.; Santoro, J.D. Racial Bias in the US Opioid Epidemic: A Review of the History of Systemic Bias and Implications for Care. Cureus 2018, 10, e3733. [Google Scholar] [CrossRef] [PubMed]
- Lagisetty, P.A.; Ross, R.; Bohnert, A.; Clay, M.; Maust, D.T. Buprenorphine Treatment Divide by Race/Ethnicity and Payment. JAMA Psychiatry 2019, 76, 979–981. [Google Scholar] [CrossRef] [PubMed]
- Goedel, W.C.; Shapiro, A.; Cerda, M.; Tsai, J.W.; Hadland, S.E.; Marshall, B.D.L. Association of Racial/Ethnic Segregation With Treatment Capacity for Opioid Use Disorder in Counties in the United States. JAMA Netw. Open 2020, 3, e203711. [Google Scholar] [CrossRef]
- Hansen, H.B.; Siegel, C.E.; Case, B.G.; Bertollo, D.N.; DiRocco, D.; Galanter, M. Variation in use of buprenorphine and methadone treatment by racial, ethnic, and income characteristics of residential social areas in New York City. J. Behav. Health Serv. Res. 2013, 40, 367–377. [Google Scholar] [CrossRef] [PubMed]
- Karamouzian, M.; Cui, Z.; Hayashi, K.; DeBeck, K.; Milloy, M.J.; Buxton, J.A.; Kerr, T. Longitudinal latent polysubstance use patterns among a cohort of people who use opioids in Vancouver, Canada. Drug Alcohol. Rev. 2023, 42, 1493–1503. [Google Scholar] [CrossRef] [PubMed]
- Singleton, J.; Li, C.; Akpunonu, P.D.; Abner, E.L.; Kucharska-Newton, A.M. Using natural language processing to identify opioid use disorder in electronic health record data. Int. J. Med. Inform. 2023, 170, 104963. [Google Scholar] [CrossRef] [PubMed]
- Barnett, M.L.; Olenski, A.R.; Jena, A.B. Opioid-Prescribing Patterns of Emergency Physicians and Risk of Long-Term Use. N. Engl. J. Med. 2017, 376, 663–673. [Google Scholar] [CrossRef]
- Goulet, J.; Cheng, Y.; Becker, W.; Brandt, C.; Sandbrink, F.; Workman, T.E.; Ma, P.; Libin, A.; Shara, N.; Spevak, C.; et al. Opioid use and opioid use disorder in mono and dual-system users of veteran affairs medical centers. Front. Public. Health 2023, 11, 1148189. [Google Scholar] [CrossRef]




| Key Phrases | |||||
|---|---|---|---|---|---|
| abstral | duragesic | hysingla | methadose | oxaydo | withdrawal |
| actiq | exalgo | kadian | morphine | oxycodone | zohydro |
| demerol | fentanyl | lorcet | norco | oxycontin | opioid dependence |
| dependence | fentora | lortab | opiate | percocet | polysubstance abuse |
| dilaudid | hydrocodone | meperidine | opiate abuse | roxicet | substance abuse |
| dolophine | hydromorphone | methadone | opioid | vicodin | substance dependence |
| Element | Total |
|---|---|
| Years (2012–2019) | 8 |
| Key phrases | 36 |
| Total notes | 3,521,637 |
| Total snippets | 8,804,031 |
| Positive snippets | 1,885,642 |
| Negative snippets | 6,918,389 |
| Mean snippets per document | 2.9 |
| Positive for Problematic Opioid Use and Classification Method | Negative for Problematic Opioid Use and Classification Method | ||
|---|---|---|---|
| …substance abuse treatment…heroin last used: “yesterday”… | Machine learning | …pt has pain mostly at night was on Lorcet and tried to change to morphine but since she developed rash… | Machine learning |
| …4. low back pain…5. opioid dependence…6. homeless single person… | Regular expression | ...hydromorphone 4 mg tab take one tablet every four active hours when needed for pain… | Regular expression |
| …opioid dependence (icd-9-cm 304.00)… | Regular expression | …family hx of substance abuse… | Regular expression |
| Alludes to the possibility of self medicating on the street…opiate withdrawal | Machine learning | …patient requested no Lortab… | Machine learning |
| …would not receive prescription for morphine and oxycodone until next month…reiterated multiple times that taking additional doses of opiates was a patient safety issue and would not be tolerated… | Machine learning | …continue Tylenol and oxycodone as needed per home regimen… | Machine learning |
| ...allergies: darvon, periactin, phenothiazine/related antipsychotics, demerol…opioid dependence (icd-9-cm 304.00) | Regular expression | …9) hydromorphone inj, soln active…give: 0.5 mg/0.5 mL ivp q2h prn…for pain… | Regular expression |
| All ICD | NLP Only | p-Value (All ICD vs. NLP Only) | ASD (All ICD vs. NLP Only) | No Problematic Opioid Use | p-Value (NLP Only vs. No Problematic Opioid Use) | ASD (NLP Only vs. No Problematic Opioid Use) | |
|---|---|---|---|---|---|---|---|
| N | 6997 | 57,331 | 158,043 | ||||
| Gender% | <0.0001 | <0.0001 | |||||
| M | 93% | 82% | 34 | 84.9% | 8 | ||
| F | 7% | 18% | 34 | 15.1% | 8 | ||
| Mean Age/Standard deviation (at year patient entered cohort) | 53.3/ 12.2 | 55.4/ 16.1 | <0.0001 | 15 | 58.8/18.7 | <0.0001 | 17 |
| Marital Status% | <0.0001 | <0.0001 | |||||
| Married | 25.7% | 38.5% | 28 | 50.2% | 24 | ||
| Divorced | 31.6% | 25.8% | 13 | 17.1% | 21 | ||
| Never Married/Single | 26.5% | 22.8% | 9 | 15.6% | 18 | ||
| Widowed | 4.5% | 5.1% | 3 | 6.9% | 8 | ||
| Separated | 11.3% | 6.5% | 17 | 3.2% | 16 | ||
| Missing/Other | <1.0% | 1.3% | 9 | 6.9% | 29 | ||
| Race% | <0.0001 | <0.0001 | |||||
| Black/African American | 59.7% | 54% | 11 | 28.2% | 54 | ||
| White | 35.7% | 36.6% | 2 | 51.4% | 30 | ||
| Asian | 0.1% | 1.0% | 12 | 1.2% | 2 | ||
| Native Hawaiian/Pac. Islander | <1.0% | <1.0% | 1 | <1.0% | 2 | ||
| American Indian/Alaska Native | <1.0% | <1.0% | 3 | <1.0% | 1 | ||
| Unknown | 3.6% | 7.2% | 16 | 18.2% | 34 | ||
| Ethnicity% | <0.0001 | <0.0001 | |||||
| Not Hispanic or Latino | 96.5% | 92.3% | 19 | 80.6% | 35 | ||
| Hispanic or Latino | 1.5% | 2.9% | 9 | 2.9% | <1 | ||
| Unknown | 1.9% | 4.9% | 16 | 16.5% | 38 |
| All ICD | NLP Only | p-Value (NLP Only vs. All ICD) | ASD (%) (NLP Only vs. All ICD) | No Problematic Opioid Use (%) | p-Value (NLP Only vs. No Problematic Opioid Use) | ASD (NLP Only vs. No Problematic Opioid Use) | |
|---|---|---|---|---|---|---|---|
| N | 6997 | 57,331 | 158,043 | ||||
| Comorbidities (when or after patient entered cohort) | |||||||
| Hypertension | 57.1% | 53.5% | <0.0001 | 7 | 45.8% | <0.0001 | 15 |
| Diabetes mellitus | 22.1% | 25.0% | <0.0001 | 7 | 20.4% | <0.0001 | 11 |
| Depression | 61.8% | 41.1% | <0.0001 | 42 | 19.6% | <0.0001 | 48 |
| Post-traumatic stress disorder | 39.6% | 25.1% | <0.0001 | 31 | 10.8% | <0.0001 | 38 |
| Cancer | 9.0% | 12.1% | <0.0001 | 10 | 12.9% | <0.0001 | 2 |
| Tobacco | 62.0% | 31.1% | <0.0001 | 65 | 15.4% | <0.0001 | 38 |
| Alcohol | 60.9% | 23.8% | <0.0001 | 81 | 9.2% | <0.0001 | 44 |
| Other drug addictions | 66.6% | 18.6% | <0.0001 | 111 | 4.2% | <0.0001 | 47 |
| Traumatic brain injury | 11.5% | 7.0% | <0.0001 | 16 | 3.6% | <0.0001 | 15 |
| Anxiety | 39.7% | 27.6% | <0.0001 | 26 | 14.1% | <0.0001 | 34 |
| Neck pain | 39.4% | 31.3% | <0.0001 | 17 | 18.2% | <0.0001 | 31 |
| Back pain | 57.0% | 47.2% | <0.0001 | 20 | 30.7% | <0.0001 | 34 |
| Prior VA opioid prescription | 71.5% | 51.6% | <0.0001 | 42 | 32.1% | <0.0001 | 40 |
| Concurrent benzodiazepine prescriptions | 19.4% | 10.1% | <0.0001 | 26 | 3.9% | <0.0001 | 24 |
| Mean/standard deviation outpatient encounters (since patient entered cohort; max 1 per day) | 50.9/ 49.8 | 33.4/ 31.3 | <0.0001 | 42 | 16.2/23.2 | 62 |
| NLP Only, NLP/ICD Patient Groups, Positive Snippet Classifications | ||
|---|---|---|
| Count of patients having positive snippets with specific drug name | Count of patients having positive snippets with other key phrases | |
| NLP Only | 15,495 | 54,856 |
| NLP/ICD | 5298 | 6175 |
| Positive Snippets Mean/Standard Deviation | ||
| NLP Only | 1.7/1.5 | |
| NLP/ICD | 3.0/2.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Workman, T.E.; Kupersmith, J.; Ma, P.; Spevak, C.; Sandbrink, F.; Cheng, Y.; Zeng-Treitler, Q. A Comparison of Veterans with Problematic Opioid Use Identified through Natural Language Processing of Clinical Notes versus Using Diagnostic Codes. Healthcare 2024, 12, 799. https://doi.org/10.3390/healthcare12070799
Workman TE, Kupersmith J, Ma P, Spevak C, Sandbrink F, Cheng Y, Zeng-Treitler Q. A Comparison of Veterans with Problematic Opioid Use Identified through Natural Language Processing of Clinical Notes versus Using Diagnostic Codes. Healthcare. 2024; 12(7):799. https://doi.org/10.3390/healthcare12070799
Chicago/Turabian StyleWorkman, Terri Elizabeth, Joel Kupersmith, Phillip Ma, Christopher Spevak, Friedhelm Sandbrink, Yan Cheng, and Qing Zeng-Treitler. 2024. "A Comparison of Veterans with Problematic Opioid Use Identified through Natural Language Processing of Clinical Notes versus Using Diagnostic Codes" Healthcare 12, no. 7: 799. https://doi.org/10.3390/healthcare12070799
APA StyleWorkman, T. E., Kupersmith, J., Ma, P., Spevak, C., Sandbrink, F., Cheng, Y., & Zeng-Treitler, Q. (2024). A Comparison of Veterans with Problematic Opioid Use Identified through Natural Language Processing of Clinical Notes versus Using Diagnostic Codes. Healthcare, 12(7), 799. https://doi.org/10.3390/healthcare12070799