A Systematic Review on Healthcare Analytics: Application and Theoretical Perspective of Data Mining


Abstract
:1. Introduction
Motivation and Scope
2. Methodology
2.1. Input Literature
- Inclusion criteria: The phase 1 search resulted in thousands of articles which was then narrowed down using the phase 2 keywords within the initial search space. Second phase resulted in 129 articles in Web of Science, and 5255 articles in PubMed. Search in Google Scholar search engine was conducted with phase 2 keywords which resulted in 700 articles. The title, abstract, and keywords of those articles were screened and those discussing the application of data mining and big data in the healthcare decision-making process were retained for full-text review. To make the screening process efficient, duplicate articles were removed at the eligibility phase instead of screening phase of the PRISMA review process (Figure 1).
- Exclusion criteria: This included articles reporting on results of: qualitative study, survey, focus group study, feasibility study, monitoring device, team relationship measurement, job satisfaction, work environment, “what-if” analysis, data collection technique, editorials or short report, merely mention data mining, and articles not published in international journals. Duplicates were removed (33 articles). Finally, 117 articles were retained for the review. Figure 1 provides a PRISMA [28] flow diagram of the review process and Supplementary Information File S1 (Table S1) provides the PRISMA checklist.
2.2. Quality Assessment and Processing Steps
2.3. Results
2.3.1. Methodological Quality of the Studies
2.3.2. Distribution by Publication Year
2.3.3. Distribution by Journal
3. Healthcare Analytics
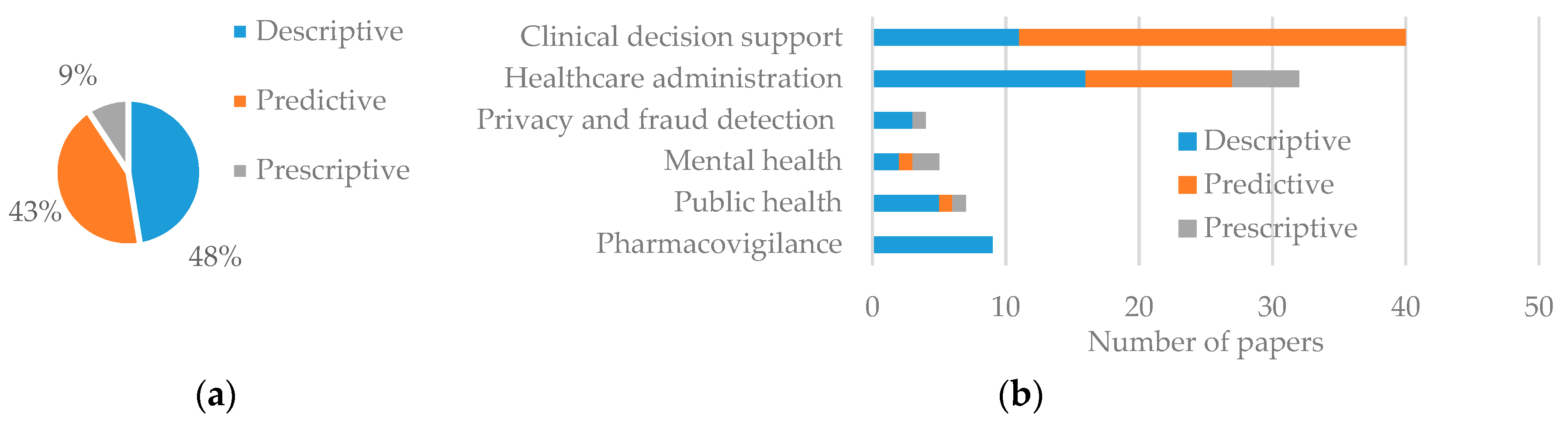
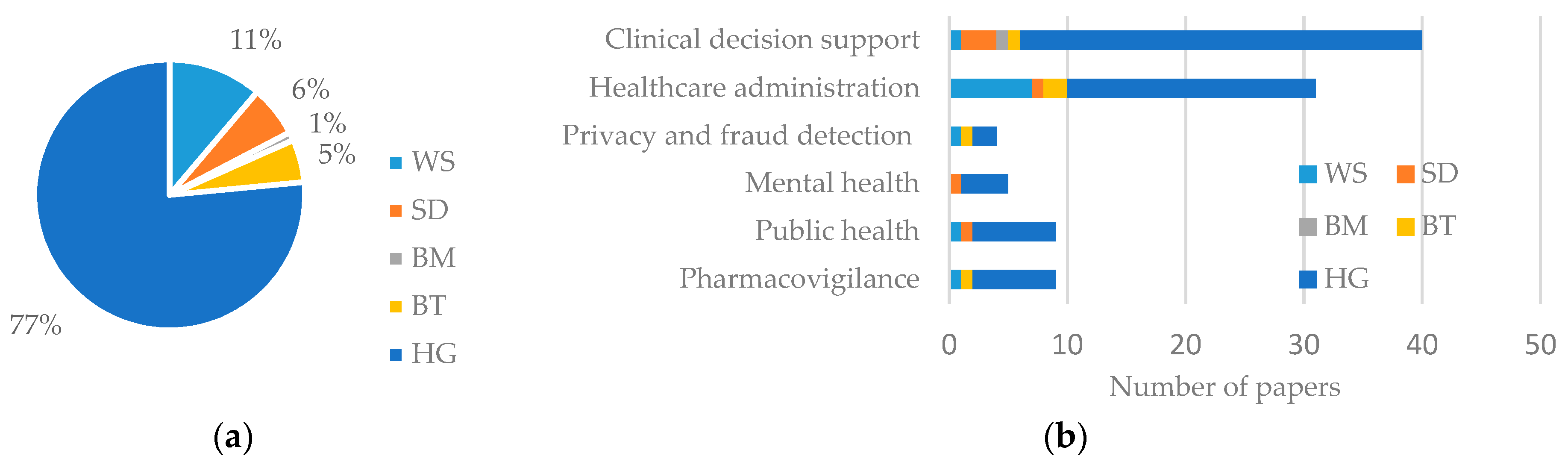
3.1. Types of Analytics
3.2. Types of Data
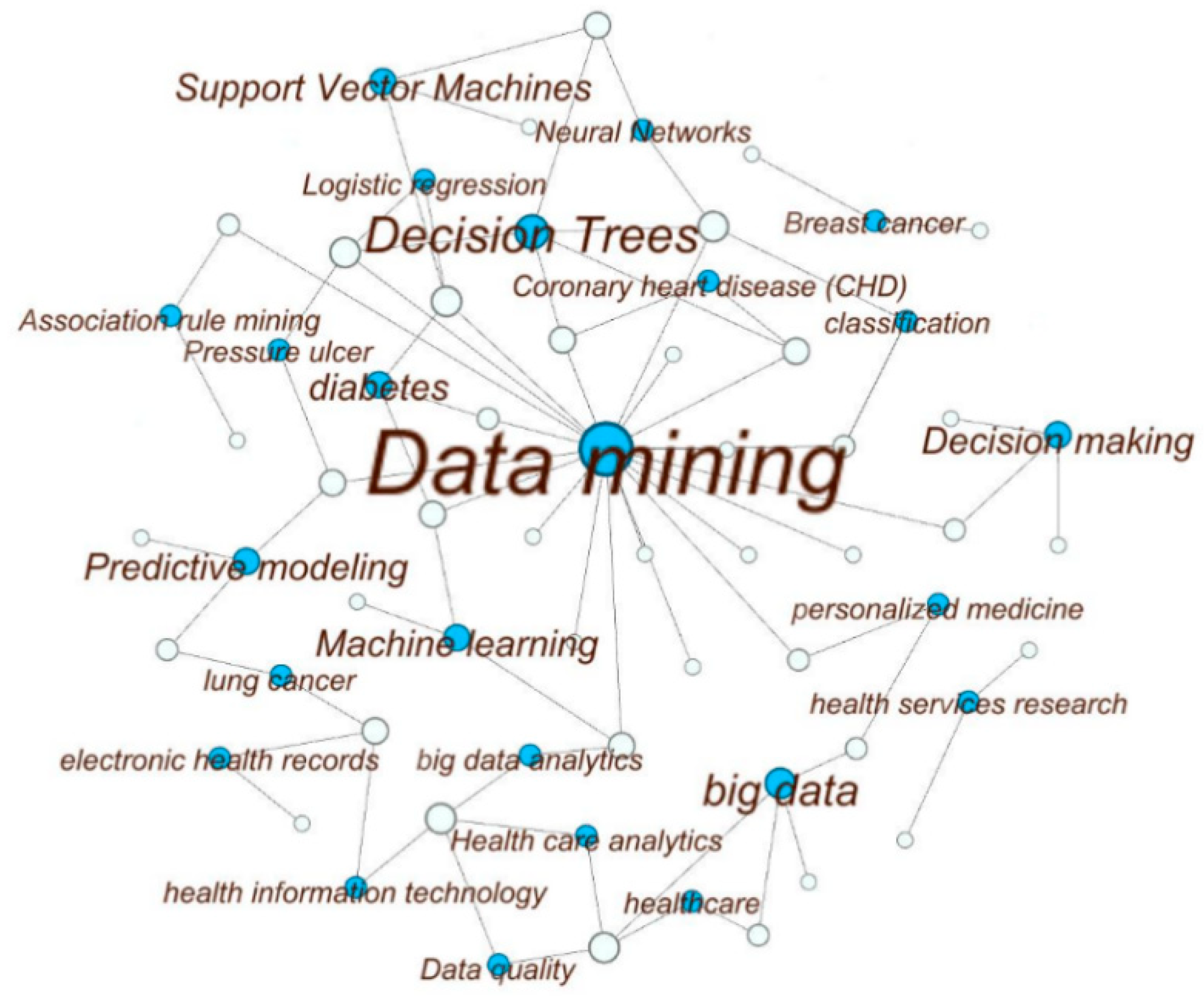
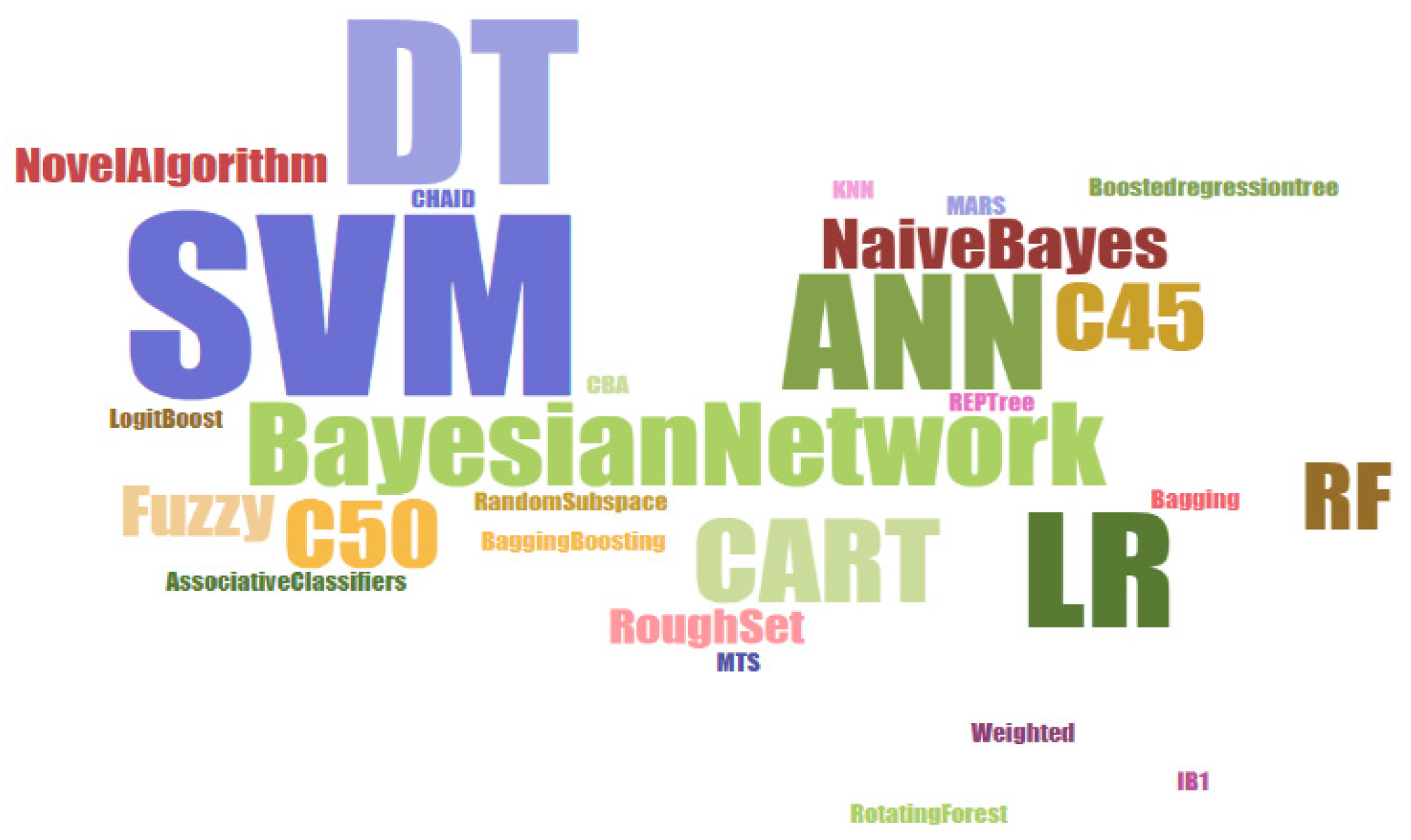
3.3. Data Mining Techniques
4. Application of Analytics in Healthcare
4.1. Clinical Decision Support
4.1.1. Cardiovascular Disease (CVD)
4.1.2. Diabetes
4.1.3. Cancer
4.1.4. Emergency Care
4.1.5. Intensive Care
4.1.6. Other Applications
4.2. Healthcare Administration
4.2.1. Data Warehousing and Cloud Computing
4.2.2. Healthcare Cost, Quality and Resource Utilization
4.2.3. Patient Management
4.2.4. Other Applications
4.3. Healthcare Privacy and Fraud Detection
4.4. Mental Health
4.5. Public Health
4.6. Pharmacovigilance
5. Theoretical Study
6. Future Research and Challenges
- Personalized care
- Loss of information in pre-processing
- Collecting healthcare data for research purpose
- Automation of data mining process for non-expert users
- Interdisciplinary nature of study and domain expert knowledge
- Integration in healthcare system
- Prediction error and “The Black Swan” effect
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Yang, J.-J.; Li, J.; Mulder, J.; Wang, Y.; Chen, S.; Wu, H.; Wang, Q.; Pan, H. Emerging information technologies for enhanced healthcare. Comput. Ind. 2015, 69, 3–11. [Google Scholar] [CrossRef]
- Cortada, J.W.; Gordon, D.; Lenihan, B. The Value of Analytics in Healthcare; Report No.: GBE03476-USEN-00; IBM Institute for Business Value: Armonk, NY, USA, 2012. [Google Scholar]
- Center for Medicare and Medicaid Services. Available online: https://www.cms.gov/Research-Statistics-Data-and-Systems/Statistics-Trends-andReports/NationalHealthExpendData/NationalHealthAccountsHistorical.html (accessed on 1 August 2017).
- Berwick, D.M.; Hackbarth, A.D. Eliminating waste in US health care. J. Am. Med. Assoc. 2012, 307, 1513–1516. [Google Scholar] [CrossRef]
- Makary, M.A.; Daniel, M. Medical error-the third leading cause of death in the US. Br. Med. J. 2016, 353, i2139. [Google Scholar] [CrossRef] [PubMed]
- Prokosch, H.-U.; Ganslandt, T. Perspectives for medical informatics. Methods Inf. Med. 2009, 48, 38–44. [Google Scholar] [CrossRef] [PubMed]
- Simpao, A.F.; Ahumada, L.M.; Gálvez, J.A.; Rehman, M.A. A review of analytics and clinical informatics in health care. J. Med. Syst. 2014, 38, 45. [Google Scholar] [CrossRef] [PubMed]
- Ghassemi, M.; Celi, L.A.; Stone, D.J. State of the art review: The data revolution in critical care. Crit. Care 2015, 19, 118. [Google Scholar] [CrossRef] [PubMed]
- Tomar, D.; Agarwal, S. A survey on Data Mining approaches for Healthcare. Int. J. Bio-Sci. Bio-Technol. 2013, 5, 241–266. [Google Scholar] [CrossRef]
- Herland, M.; Khoshgoftaar, T.M.; Wald, R. A review of data mining using big data in health informatics. J. Big Data 2014, 1, 2. [Google Scholar] [CrossRef]
- Sigurdardottir, A.K.; Jonsdottir, H.; Benediktsson, R. Outcomes of educational interventions in type 2 diabetes: WEKA data-mining analysis. Patient Educ. Couns. 2007, 67, 21–31. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Huang, K.-Y.; Jin, J.; Shi, J. A survey on statistical methods for health care fraud detection. Health Care Manag. Sci. 2008, 11, 275–287. [Google Scholar] [CrossRef] [PubMed]
- Bellazzi, R.; Zupan, B. Predictive data mining in clinical medicine: Current issues and guidelines. Int. J. Med. Inform. 2008, 77, 81–97. [Google Scholar] [CrossRef] [PubMed]
- Yoo, I.-H.; Song, M. Biomedical ontologies and text mining for biomedicine and healthcare: A survey. J. Comput. Sci. Eng. 2008, 2, 109–136. [Google Scholar] [CrossRef]
- Ting, S.; Shum, C.; Kwok, S.K.; Tsang, A.H.; Lee, W. Data mining in biomedicine: Current applications and further directions for research. J. Softw. Eng. Appl. 2009, 2, 150–159. [Google Scholar] [CrossRef]
- Iavindrasana, J.; Cohen, G.; Depeursinge, A.; Müller, H.; Meyer, R.; Geissbuhler, A. Clinical data mining: A review. Yearb. Med. Inform. 2009, 2009, 121–133. [Google Scholar]
- Bellazzi, R.; Ferrazzi, F.; Sacchi, L. Predictive data mining in clinical medicine: A focus on selected methods and applications. WIRE 2011, 1, 416–430. [Google Scholar] [CrossRef]
- Barati, E.; Saraee, M.; Mohammadi, A.; Adibi, N.; Ahmadzadeh, M. A survey on utilization of data mining approaches for dermatological (skin) diseases prediction. J. Sel. Areas Health Inform. 2011, 2, 1–11. [Google Scholar]
- Jacob, S.G.; Ramani, R.G. Data mining in clinical data sets: A review. Int. J. Appl. Inf. Syst. 2012, 4, 15–26. [Google Scholar] [CrossRef]
- Yoo, I.; Alafaireet, P.; Marinov, M.; Pena-Hernandez, K.; Gopidi, R.; Chang, J.-F.; Hua, L. Data mining in healthcare and biomedicine: A survey of the literature. J. Med. Syst. 2012, 36, 2431–2448. [Google Scholar] [CrossRef] [PubMed]
- Shukla, D.; Patel, S.B.; Sen, A.K. A literature review in health informatics using data mining techniques. Int. J. Softw. Hardw. Res. Eng. 2014, 2, 123–129. [Google Scholar]
- Mohammed, E.A.; Far, B.H.; Naugler, C. Applications of the MapReduce programming framework to clinical big data analysis: Current landscape and future trends. BioData Min. 2014, 7, 22. [Google Scholar] [CrossRef] [PubMed]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Belle, A.; Thiagarajan, R.; Soroushmehr, S.; Navidi, F.; Beard, D.A.; Najarian, K. Big data analytics in healthcare. BioMed Res. Int. 2015, 2015, 370194. [Google Scholar] [CrossRef] [PubMed]
- Sarker, A.; Ginn, R.; Nikfarjam, A.; O’Connor, K.; Smith, K.; Jayaraman, S.; Upadhaya, T.; Gonzalez, G. Utilizing social media data for pharmacovigilance: A review. J. Biomed. Inform. 2015, 54, 202–212. [Google Scholar] [CrossRef] [PubMed]
- Karimi, S.; Wang, C.; Metke-Jimenez, A.; Gaire, R.; Paris, C. Text and data mining techniques in adverse drug reaction detection. ACM Comput. Surv. 2015, 47, 56. [Google Scholar] [CrossRef]
- Dinov, I.D. Methodological challenges and analytic opportunities for modeling and interpreting Big Healthcare Data. Gigascience 2016, 5, 12. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Group, P. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- The Joanna Briggs Institute. Available online: http://joannabriggs.org/research/critical-appraisal-tools.html (accessed on 7 September 2017).
- Critical Approsal Skills Programme. Available online: http://docs.wixstatic.com/ugd/dded87_25658615020e427 da194a325e7773d42.pdf (accessed on 7 September 2017).
- Levy, Y.; Ellis, T.J. A systems approach to conduct an effective literature review in support of information systems research. Inf. Sci. 2006, 9, 181–212. [Google Scholar] [CrossRef]
- Webster, J.; Watson, R.T. Analyzing the past to prepare for the future: Writing a literature review. Manag. Inf. Syst. Q. 2002, 22, xiii–xxiii. [Google Scholar]
- Russom, P. Big Data Analytics; TDWI Best Practices Report; Fourth Quarter; Report No.: 9.14.2011; TDWI: Renton, WV, USA, 2011. [Google Scholar]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An open source software for exploring and manipulating networks. In Proceedings of the 3rd International AAAI Conference on Weblogs and Social Media, San Jose, CA, USA, 17–19 May 2009; pp. 361–362. [Google Scholar]
- Issa, N.T.; Byers, S.W.; Dakshanamurthy, S. Big data: The next frontier for innovation in therapeutics and healthcare. Expert Rev. Clin. Pharmacol. 2014, 7, 293–298. [Google Scholar] [CrossRef] [PubMed]
- Baldwin, T.; Cook, P.; Lui, M.; MacKinlay, A.; Wang, L. How noisy social media text, how diffrnt social media sources? In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–19 October 2013; pp. 356–364. [Google Scholar]
- Wang, C.; Guo, X.; Wang, Y.; Chen, Y.; Liu, B. Friend or foe?: Your wearable devices reveal your personal pin. In Proceedings of the 11th ACM on Asia Conference on Computer and Communications Security, Xi’an, China, 30 May–3 June 2016; pp. 189–200. [Google Scholar]
- Yeh, W.-C.; Chang, W.-W.; Chung, Y.Y. A new hybrid approach for mining breast cancer pattern using discrete particle swarm optimization and statistical method. Expert Syst. Appl. 2009, 36, 8204–8211. [Google Scholar] [CrossRef]
- jasondavies.com. Available online: https://www.jasondavies.com/wordcloud/ (accessed on 17 July 2017).
- Karaolis, M.; Moutiris, J.A.; Hadjipanayi, D.; Pattichis, C.S. Assessment of the risk factors of coronary heart events based on data mining with decision trees. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 559–566. [Google Scholar] [CrossRef] [PubMed]
- Tsipouras, M.G.; Exarchos, T.P.; Fotiadis, D.I.; Kotsia, A.P.; Vakalis, K.V.; Naka, K.K.; Michalis, L.K. Automated diagnosis of coronary artery disease based on data mining and fuzzy modeling. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 447–458. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.; Khosravi, A.; Creighton, D.; Nahavandi, S. Classification of healthcare data using genetic fuzzy logic system and wavelets. Expert Syst. Appl. 2015, 42, 2184–2197. [Google Scholar] [CrossRef]
- Vock, D.M.; Wolfson, J.; Bandyopadhyay, S.; Adomavicius, G.; Johnson, P.E.; Vazquez-Benitez, G.; O’Connor, P.J. Adapting machine learning techniques to censored time-to-event health record data: A general-purpose approach using inverse probability of censoring weighting. J. Biomed. Inform. 2016, 61, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Bandyopadhyay, S.; Wolfson, J.; Vock, D.M.; Vazquez-Benitez, G.; Adomavicius, G.; Elidrisi, M.; Johnson, P.E.; O’Connor, P.J. Data mining for censored time-to-event data: A Bayesian network model for predicting cardiovascular risk from electronic health record data. Data Min. Knowl. Discov. 2015, 29, 1033–1069. [Google Scholar] [CrossRef]
- Sufi, F.; Khalil, I. Diagnosis of cardiovascular abnormalities from compressed ECG: A data mining-based approach. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 33–39. [Google Scholar] [CrossRef] [PubMed]
- Kusiak, A.; Caldarone, C.A.; Kelleher, M.D.; Lamb, F.S.; Persoon, T.J.; Burns, A. Hypoplastic left heart syndrome: Knowledge discovery with a data mining approach. Comput. Biol. Med. 2006, 36, 21–40. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Lee, N.; Hu, J.; Sun, J.; Ebadollahi, S.; Laine, A.F. A framework for mining signatures from event sequences and its applications in healthcare data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 272–285. [Google Scholar] [CrossRef] [PubMed]
- Antonelli, D.; Baralis, E.; Bruno, G.; Cerquitelli, T.; Chiusano, S.; Mahoto, N. Analysis of diabetic patients through their examination history. Expert Syst. Appl. 2013, 40, 4672–4678. [Google Scholar] [CrossRef]
- Huang, Y.; McCullagh, P.; Black, N.; Harper, R. Feature selection and classification model construction on type 2 diabetic patients’ data. Artif. Intell. Med. 2007, 41, 251–262. [Google Scholar] [CrossRef] [PubMed]
- Tapak, L.; Mahjub, H.; Hamidi, O.; Poorolajal, J. Real-data comparison of data mining methods in prediction of diabetes in Iran. Healthc. Inform. Res. 2013, 19, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Razavian, N.; Blecker, S.; Schmidt, A.M.; Smith-McLallen, A.; Nigam, S.; Sontag, D. Population-level prediction of type 2 diabetes from claims data and analysis of risk factors. Big Data 2015, 3, 277–287. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.-Q.; Leibson, C.L.; Ransom, J.E.; Kho, A.N.; Caraballo, P.J.; Chai, H.S.; Yawn, B.P.; Pacheco, J.A.; Chute, C.G. Impact of data fragmentation across healthcare centers on the accuracy of a high-throughput clinical phenotyping algorithm for specifying subjects with type 2 diabetes mellitus. J. Am. Med. Assoc. 2012, 19, 219–224. [Google Scholar] [CrossRef] [PubMed]
- Barakat, N.; Bradley, A.P.; Barakat, M.N.H. Intelligible support vector machines for diagnosis of diabetes mellitus. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1114–1120. [Google Scholar] [CrossRef] [PubMed]
- Delen, D. Analysis of cancer data: A data mining approach. Expert Syst. 2009, 26, 100–112. [Google Scholar] [CrossRef]
- Iqbal, U.; Hsu, C.-K.; Nguyen, P.A.A.; Clinciu, D.L.; Lu, R.; Syed-Abdul, S.; Yang, H.C.; Wang, Y.C.; Huang, C.Y.; Huang, C.W.; et al. Cancer-disease associations: A visualization and animation through medical big data. Comput. Methods Programs Biomed. 2016, 127, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, A.; Misra, S.; Narayanan, R.; Polepeddi, L.; Choudhary, A. Lung cancer survival prediction using ensemble data mining on SEER data. Sci. Program 2012, 20, 29–42. [Google Scholar] [CrossRef]
- Ha, S.H.; Joo, S.H. A hybrid data mining method for the medical classification of chest pain. Int. J. Comput. Eng. 2010, 4, 33–38. [Google Scholar]
- Ceglowski, R.; Churilov, L.; Wasserthiel, J. Combining data mining and discrete event simulation for a value-added view of a hospital emergency department. J. Oper. Res. Soc. 2007, 58, 246–254. [Google Scholar] [CrossRef]
- Kim, S.; Kim, W.; Park, R.W. A comparison of intensive care unit mortality prediction models through the use of data mining techniques. Healthc. Inform. Res. 2011, 17, 232–243. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Maslove, D.M.; Dubin, J.A. Personalized mortality prediction driven by electronic medical data and a patient similarity metric. PLoS ONE 2015, 10, e0127428. [Google Scholar] [CrossRef] [PubMed]
- Razali, A.M.; Ali, S. Generating treatment plan in medicine: A data mining approach. Am. J. Appl. Sci. 2009, 6, 345–351. [Google Scholar] [CrossRef]
- Su, C.-T.; Wang, P.-C.; Chen, Y.-C.; Chen, L.-F. Data mining techniques for assisting the diagnosis of pressure ulcer development in surgical patients. J. Med. Syst. 2012, 36, 2387. [Google Scholar] [CrossRef] [PubMed]
- Raju, D.; Su, X.; Patrician, P.A.; Loan, L.A.; McCarthy, M.S. Exploring factors associated with pressure ulcers: A data mining approach. Int. J. Nurs. Stud. 2015, 52, 102–111. [Google Scholar] [CrossRef] [PubMed]
- Wright, A.; Chen, E.S.; Maloney, F.L. An automated technique for identifying associations between medications, laboratory results and problems. J. Biomed. Inform. 2010, 43, 891–901. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.-H.; Chen, J.C.-Y.; Tseng, V.S. A novel data mining mechanism considering bio-signal and environmental data with applications on asthma monitoring. Comput. Methods Prog. Biomed. 2011, 101, 44–61. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Davis, D.A. Bringing big data to personalized healthcare: A patient-centered framework. J. Gen. Intern. Med. 2013, 28, S660–S665. [Google Scholar] [CrossRef] [PubMed]
- Roque, F.S.; Jensen, P.B.; Schmock, H.; Dalgaard, M.; Andreatta, M.; Hansen, T.; Søeby, K.; Bredkjær, S.; Juul, A.; Werge, T.; et al. Using electronic patient records to discover disease correlations and stratify patient cohorts. PLoS Comput. Biol. 2011, 7, e1002141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mookiah, M.R.K.; Acharya, U.R.; Lim, C.M.; Petznick, A.; Suri, J.S. Data mining technique for automated diagnosis of glaucoma using higher order spectra and wavelet energy features. Knowl. Based Syst. 2012, 33, 73–82. [Google Scholar] [CrossRef]
- Murphy, D.R.; Meyer, A.N.; Bhise, V.; Russo, E.; Sittig, D.F.; Wei, L.; Wu, L.; Singh, H. Computerized triggers of big data to detect delays in follow-up of chest imaging results. Chest 2016, 150, 613–620. [Google Scholar] [CrossRef] [PubMed]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inform. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef] [PubMed]
- Kusiak, A.; Dixon, B.; Shah, S. Predicting survival time for kidney dialysis patients: A data mining approach. Comput. Biol. Med. 2005, 35, 311–327. [Google Scholar] [CrossRef] [PubMed]
- Stamm, A.M.; Bettacchi, C.J. A comparison of 3 metrics to identify health care-associated infections. Am. J. Infect. Control 2012, 40, 688–691. [Google Scholar] [CrossRef] [PubMed]
- Dinov, I.D.; Heavner, B.; Tang, M.; Glusman, G.; Chard, K.; Darcy, M.; Madduri, R.; Pa, J.; Spino, C.; Kesselman, C.; et al. Predictive big data analytics: A study of Parkinson’s disease using large, complex, heterogeneous, incongruent, multi-source and incomplete observations. PLoS ONE. 2016, 11, e0157077. [Google Scholar] [CrossRef] [PubMed]
- Yeh, J.-Y.; Wu, T.-H.; Tsao, C.-W. Using data mining techniques to predict hospitalization of hemodialysis patients. Desic. Support Syst. 2011, 50, 439–448. [Google Scholar] [CrossRef]
- Mathias, J.S.; Agrawal, A.; Feinglass, J.; Cooper, A.J.; Baker, D.W.; Choudhary, A. Development of a 5 year life expectancy index in older adults using predictive mining of electronic health record data. J. Am. Med. Inform. Assoc. 2013, 20, e118–e124. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Fong, S.; Fiaidhi, J.; Mohammed, S. Real-time clinical decision support system with data stream mining. BioMed Res. Int. 2012. Available online: https://www.hindawi.com/journals/bmri/2012/580186/cta/ (accessed on 11 July 2017). [CrossRef] [PubMed]
- Mozaffarian, D.; Benjamin, E.J.; Go, A.S.; Arnett, D.K.; Blaha, M.J.; Cushman, M.; Das, S.R.; Ferranti, S.D.; Després, J.P.; Fullerton, H.J.; et al. Heart disease and stroke statistics—2016 update. Circulation 2016, 133, e38–e360. [Google Scholar] [CrossRef] [PubMed]
- Sheridan, S.; Pignone, M.; Mulrow, C. Framingham-based tools to calculate the global risk of coronary heart disease. J. Gen. Intern. Med. 2003, 18, 1039–1052. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Hoy, W.E. Is the Framingham coronary heart disease absolute risk function applicable to Aboriginal people? Med. J. Aust. 2005, 182, 66–69. [Google Scholar] [PubMed]
- Rea, T.D.; Heckbert, S.R.; Kaplan, R.C.; Smith, N.L.; Lemaitre, R.N.; Psaty, B.M. Smoking status and risk for recurrent coronary events after myocardial infarction. Ann. Intern. Med. 2002, 137, 494–500. [Google Scholar] [CrossRef] [PubMed]
- Karaolis, M.; Moutiris, J.A.; Papaconstantinou, L.; Pattichis, C.S. Association rule analysis for the assessment of the risk of coronary heart events. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 6238–6241. [Google Scholar]
- Sturgeon, L.P.; Bragg-Underwood, D.; Tonya, M.; Blankenship, D. Practice matters: Prevention and care of individuals with type 2 diabetes. Int. J. Faith Commun. Nurs. 2016, 2, 32–40. [Google Scholar]
- Siegel, R.L.; Miller, K.D.; Jemal, A. Cancer statistics, 2016. CA 2016, 66, 7–30. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.-C.; Hsu, T.-C. A GAs based approach for mining breast cancer pattern. Expert Syst. Appl. 2006, 30, 674–681. [Google Scholar] [CrossRef]
- Sousa, T.; Silva, A.; Neves, A. Particle swarm based data mining algorithms for classification tasks. Parallel Comput. 2004, 30, 767–783. [Google Scholar] [CrossRef]
- National Center for Health Statistics (US). Health, United States, 2012: With Special Feature on Emergency Care; Report No.: 2013-1232; National Center for Health Statistics (US): Hyattsville, MD, USA, 2013.
- Angus, D.C.; Barnato, A.E.; Linde-Zwirble, W.T.; Weissfeld, L.A.; Watson, R.S.; Rickert, T.; Rubenfeld, G.D. Use of intensive care at the end of life in the United States: An epidemiologic study. Crit. Care Med. 2004, 32, 638–643. [Google Scholar] [CrossRef] [PubMed]
- Saeed, M.; Villarroel, M.; Reisner, A.T.; Clifford, G.; Lehman, L.-W.; Moody, G.; Heldt, T.; Kyaw, T.H.; Moody, B.; Mark, R.G. Multiparameter Intelligent Monitoring in Intensive Care II (MIMIC-II): A public-access intensive care unit database. Crit. Care Med. 2011, 39, 952–960. [Google Scholar] [CrossRef] [PubMed]
- Post, A.R.; Kurc, T.; Cholleti, S.; Gao, J.; Lin, X.; Bornstein, W.; Cantrell, D.; Levine, D.; Hohmann, S.; Saltz, J.H. The Analytic Information Warehouse (AIW): A platform for analytics using electronic health record data. J. Biomed. Inform. 2013, 46, 410–424. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Chen, S.; Liu, B.; Zhang, R.; Wang, Y.; Li, P.; Guo, Y.; Zhang, H.; Gao, Z.; Yan, X. Development of traditional Chinese medicine clinical data warehouse for medical knowledge discovery and decision support. Artif. Intell. Med. 2010, 48, 139–152. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Qiu, M.; Tsai, C.-W.; Hassan, M.M.; Alamri, A. Health-CPS: Healthcare cyber-physical system assisted by cloud and big data. IEEE Syst. J. 2015, 11, 88–95. [Google Scholar] [CrossRef]
- Erinjeri, J.P.; Picus, D.; Prior, F.W.; Rubin, D.A.; Koppel, P. Development of a Google-based search engine for data mining radiology reports. J. Digit. Imaging 2009, 22, 348–356. [Google Scholar] [CrossRef] [PubMed]
- Mullins, I.M.; Siadaty, M.S.; Lyman, J.; Scully, K.; Garrett, C.T.; Miller, W.G.; Muller, R.; Robson, B.; Apte, C.; Weiss, S.; et al. Data mining and clinical data repositories: Insights from a 667,000 patient data set. Comput. Biol. Med. 2006, 36, 1351–1377. [Google Scholar] [CrossRef] [PubMed]
- Praveenkumar, B.; Suresh, K.; Nikhil, A.; Rohan, M.; Nikhila, B.; Rohit, C.; Srinivas, A. Geospatial Technology in Disease Mapping, E-Surveillance and Health Care for Rural Population in South India. Int. Arch. Photogr. Remote Sens. Spat. Inf. Sci. 2014, 40, 221. [Google Scholar] [CrossRef]
- Shen, C.-P.; Jigjidsuren, C.; Dorjgochoo, S.; Chen, C.-H.; Chen, W.-H.; Hsu, C.-K.; Muller, R.; Robson, B.; Apte, C.; Weiss, S.; et al. A data-mining framework for transnational healthcare system. J. Med. Syst. 2012, 36, 2565–2575. [Google Scholar] [CrossRef] [PubMed]
- Bertsimas, D.; Bjarnadóttir, M.V.; Kane, M.A.; Kryder, J.C.; Pandey, R.; Vempala, S.; Wang, G. Algorithmic prediction of health-care costs. Oper. Res. 2008, 56, 1382–1392. [Google Scholar] [CrossRef]
- Phillips-Wren, G.; Sharkey, P.; Dy, S.M. Mining lung cancer patient data to assess healthcare resource utilization. Expert Syst. Appl. 2008, 35, 1611–1619. [Google Scholar] [CrossRef]
- Hachesu, P.R.; Ahmadi, M.; Alizadeh, S.; Sadoughi, F. Use of data mining techniques to determine and predict length of stay of cardiac patients. Healthc. Inform. Res. 2013, 19, 121–129. [Google Scholar] [CrossRef] [PubMed]
- Pur, A.; Bohanec, M.; Lavrač, N.; Cestnik, B. Primary health-care network monitoring: A hierarchical resource allocation modeling approach. Int. J. Health Plan. Manag. 2010, 25, 119–135. [Google Scholar] [CrossRef] [PubMed]
- Robinson, J.W. Regression tree boosting to adjust health care cost predictions for diagnostic mix. Health Serv. Res. 2008, 43, 755–772. [Google Scholar] [CrossRef] [PubMed]
- Cercone, N.; An, X.; Li, J.; Gu, Z.; An, A. Finding best evidence for evidence-based best practice recommendations in health care: The initial decision support system design. Knowl. Inf. Syst. 2011, 29, 159–201. [Google Scholar] [CrossRef]
- Zhuang, Z.Y.; Churilov, L.; Burstein, F.; Sikaris, K. Combining data mining and case-based reasoning for intelligent decision support for pathology ordering by general practitioners. Eur. J. Oper. Res. 2009, 195, 662–675. [Google Scholar] [CrossRef]
- Delen, D.; Fuller, C.; McCann, C.; Ray, D. Analysis of healthcare coverage: A data mining approach. Expert Syst. Appl. 2009, 36, 995–1003. [Google Scholar] [CrossRef]
- Greaves, F.; Ramirez-Cano, D.; Millett, C.; Darzi, A.; Donaldson, L. Use of sentiment analysis for capturing patient experience from free-text comments posted online. J. Med. Internet Res. 2013, 15, e239. [Google Scholar] [CrossRef] [PubMed]
- Glowacka, K.J.; Henry, R.M.; May, J.H. A hybrid data mining/simulation approach for modelling outpatient no-shows in clinic scheduling. J. Oper. Res. Soc. 2009, 60, 1056–1068. [Google Scholar] [CrossRef]
- Duan, L.; Street, W.N.; Xu, E. Healthcare information systems: Data mining methods in the creation of a clinical recommender system. Enterp. Inf. Syst. 2011, 5, 169–181. [Google Scholar] [CrossRef]
- Koskela, T.-H.; Ryynanen, O.-P.; Soini, E.J. Risk factors for persistent frequent use of the primary health care services among frequent attenders: A Bayesian approach. Scand. J. Prim. Health Care 2010, 28, 55–61. [Google Scholar] [CrossRef] [PubMed]
- Cubillas, J.J.; Ramos, M.I.; Feito, F.R.; Ureña, T. An Improvement in the Appointment Scheduling in Primary Health Care Centers Using Data Mining. J. Med. Syst. 2014, 38, 89. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.-T.; Liu, C.-Y.; Kuo, Y.-H.; Mills, M.E.; Fong, J.-G.; Hung, C. Application of data mining to the identification of critical factors in patient falls using a web-based reporting system. Int. J. Med. Inf. 2011, 80, 141–150. [Google Scholar] [CrossRef] [PubMed]
- Tremblay, M.C.; Berndt, D.J.; Luther, S.L.; Foulis, P.R.; French, D.D. Identifying fall-related injuries: Text mining the electronic medical record. Inf. Technol. Manag. 2009, 10, 253–265. [Google Scholar] [CrossRef]
- Feldman, K.; Chawla, N.V. Does Medical School Training Relate to Practice? Evidence from Big Data. Big Data 2015, 3, 103–113. [Google Scholar] [CrossRef] [PubMed]
- Hao, H.; Zhang, K. The voice of chinese health consumers: A text mining approach to web-Based physician reviews. J. Med. Internet Res. 2016, 18. [Google Scholar] [CrossRef] [PubMed]
- Christodoulakis, A.; Karanikas, H.; Billiris, A.; Thireos, E.; Pelekis, N. “Big data” in health care Assessment of the performance of Greek NHS hospitals using key performance and clinical workload indicators. Arch. Hellenic Med. 2016, 33, 489–497. [Google Scholar]
- Torosyan, Y.; Hu, Y.; Hoffman, S.; Luo, Q.; Carleton, B.; Marinac-Dabic, D. An in silico framework for integrating epidemiologic and genetic evidence with health care applications: Ventilation-related pneumothorax as a case illustration. J. Am. Med. Inform. Assoc. 2016, 23, 711–720. [Google Scholar] [CrossRef] [PubMed]
- Callahan, A.; Pernek, I.; Stiglic, G.; Leskovec, J.; Strasberg, H.R.; Shah, N.H. Analyzing information seeking and drug-safety alert response by health care professionals as new methods for surveillance. J. Med. Internet Res. 2015, 17, e204. [Google Scholar] [CrossRef] [PubMed]
- Madigan, E.A.; Curet, O.L. A data mining approach in home healthcare: Outcomes and service use. BMC Health Serv. Res. 2006, 6, 18. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.-H.; Huang, L.-C.; Chou, S.-C.T.; Liu, C.-H.; Cheng, H.-F.; Chiang, I.-J. Temporal event tracing on big healthcare data analytics. Big Data Appl. Use Cases 2016, 95–108. [Google Scholar] [CrossRef]
- Liu, K.; Kargupta, H.; Ryan, J. Random projection-based multiplicative data perturbation for privacy preserving distributed data mining. IEEE Trans. Knowl. Data Eng. 2006, 18, 92–106. [Google Scholar]
- Youssef, A.E. A framework for secure healthcare systems based on big data analytics in mobile cloud computing environments. Int. J. Ambient Syst. Appl. 2014, 2, 1–11. [Google Scholar] [CrossRef]
- Li, F.; Zou, X.; Liu, P.; Chen, J.Y. New threats to health data privacy. BMC BioInform. 2011, 12, S7. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.-S.; Hwang, S.-Y. A process-mining framework for the detection of healthcare fraud and abuse. Expert Syst. Appl. 2006, 31, 56–68. [Google Scholar] [CrossRef]
- Mohammed, N.; Fung, B.C.M.; Hung, P.C.K.; Lee, C.-K. Centralized and Distributed Anonymization for High-Dimensional Healthcare Data. ACM Trans. Knowl. Discov. Data 2010, 4, 1–33. [Google Scholar] [CrossRef]
- Chong, S.A.; Abdin, E.; Vaingankar, J.A.; Heng, D.; Sherbourne, C.; Yap, M.; Lim, Y.W.; Wong, H.B.; Ghosh-Dastidar, B.; Kwok, K.W.; et al. A population-based survey of mental disorders in Singapore. Ann. Acad. Med. Singap. 2012, 41, 49–66. [Google Scholar] [PubMed]
- Walker, E.R.; Druss, B.G. Cumulative burden of comorbid mental disorders, substance use disorders, chronic medical conditions, and poverty on health among adults in the USA. Psychol. Health Med. 2017, 22, 727–735. [Google Scholar] [CrossRef] [PubMed]
- Panagiotakopoulos, T.C.; Lyras, D.P.; Livaditis, M.; Sgarbas, K.N.; Anastassopoulos, G.C.; Lymberopoulos, D.K. A contextual data mining approach toward assisting the treatment of anxiety disorders. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 567–581. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.-L. A study of applying data mining to early intervention for developmentally-delayed children. Expert Syst. Appl. 2007, 33, 407–412. [Google Scholar] [CrossRef]
- Candás, J.L.C.; Peláez, V.; López, G.; Fernández, M.Á.; Álvarez, E.; Díaz, G. An automatic data mining method to detect abnormal human behaviour using physical activity measurements. Perv. Mob. Comput. 2014, 15, 228–241. [Google Scholar] [CrossRef]
- Diederich, J.; Al-Ajmi, A.; Yellowlees, P.E. X-ray: Data mining and mental health. Appl. Softw. Comput. 2007, 7, 923–928. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-Aware Recommender Systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 191–226. [Google Scholar]
- Nimmagadda, S.L.; Dreher, H.V. On robust methodologies for managing public health care systems. Int. J. Environ. Res. Public Health 2014, 11, 1106–1140. [Google Scholar] [CrossRef] [PubMed]
- Buczak, A.L.; Baugher, B.; Guven, E.; Moniz, L.; Babin, S.M.; Chretien, J.-P. Prediction of Peaks of Seasonal Influenza in Military Health-Care Data. Biomed. Eng. Copmut. Biol. 2016, 7, 15–26. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, Z.Z.; Mohammadzadeh, M. Knowledge discovery from patients’ behavior via clustering-classification algorithms based on weighted eRFM and CLV model: An empirical study in public health care services. Iran. J. Pharm. Res. 2016, 15, 355–367. [Google Scholar]
- Kostkova, P.; Fowler, D.; Wiseman, S.; Weinberg, J.R. Major infection events over 5 years: How is media coverage influencing online information needs of health care professionals and the public? J. Med. Internet Res. 2013, 15, e107. [Google Scholar] [CrossRef] [PubMed]
- Santos, R.S.; Malheiros, S.M.; Cavalheiro, S.; De Oliveira, J.P. A data mining system for providing analytical information on brain tumors to public health decision makers. Comput. Methods Prog. Biomed. 2013, 109, 269–282. [Google Scholar] [CrossRef] [PubMed]
- Lavrač, N.; Bohanec, M.; Pur, A.; Cestnik, B.; Debeljak, M.; Kobler, A. Data mining and visualization for decision support and modeling of public health-care resources. J. Biomed. Inform. 2007, 40, 438–447. [Google Scholar] [CrossRef] [PubMed]
- Rathore, M.M.; Ahmad, A.; Paul, A.; Wan, J.; Zhang, D. Real-time Medical Emergency Response System: Exploiting IoT and Big Data for Public Health. J. Med. Syst. 2016, 40, 283. [Google Scholar] [CrossRef] [PubMed]
- Ma, B.L.W.H.Y.; Liu, B. Integrating classification and association rule mining. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998. [Google Scholar]
- Harpaz, R.; Vilar, S.; DuMouchel, W.; Salmasian, H.; Haerian, K.; Shah, N.H.; Chase, H.S.; Friedman, C. Combing signals from spontaneous reports and electronic health records for detection of adverse drug reactions. J. Am. Med. Inform. Assoc. 2012, 20, 413–419. [Google Scholar] [CrossRef] [PubMed]
- Harpaz, R.; Chase, H.S.; Friedman, C. Mining multi-item drug adverse effect associations in spontaneous reporting systems. BMC BioInform. 2010, 11, S7. [Google Scholar] [CrossRef] [PubMed]
- Akay, A.; Dragomir, A.; Erlandsson, B.-E. Network-based modeling and intelligent data mining of social media for improving care. IEEE J. Biomed. Health Inform. 2015, 19, 210–218. [Google Scholar] [CrossRef] [PubMed]
- Eriksson, R.; Werge, T.; Jensen, L.J.; Brunak, S. Dose-specific adverse drug reaction identification in electronic patient records: Temporal data mining in an inpatient psychiatric population. Drug Saf. 2014, 37, 237–247. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kadoyama, K.; Kuwahara, A.; Yamamori, M.; Brown, J.; Sakaeda, T.; Okuno, Y. Hypersensitivity reactions to anticancer agents: Data mining of the public version of the FDA adverse event reporting system, AERS. J. Exp. Clin. Cancer Res. 2011, 5, 93. [Google Scholar] [CrossRef] [PubMed]
- Sakaeda, T.; Kadoyama, K.; Okuno, Y. Statin-associated muscular and renal adverse events: Data mining of the public version of the FDA adverse event reporting system. PLoS ONE 2011, 6, e28124. [Google Scholar] [CrossRef] [PubMed]
- Trifirò, G.; Pariente, A.; Coloma, P.M.; Kors, J.A.; Polimeni, G.; Miremont-Salamé, G.; Catania, M.A.; Salvo, F.; David, A.; Moore, N.; et al. Data mining on electronic health record databases for signal detection in pharmacovigilance: Which events to monitor? Pharmacoepidemiol. Drug Saf. 2009, 18, 1176–1184. [Google Scholar] [CrossRef] [PubMed]
- Choi, N.K.; Chang, Y.; Choi, Y.K.; Hahn, S.; Park, B.J. Signal detection of rosuvastatin compared to other statins: Data-mining study using national health insurance claims database. Pharmacoepidemiol. Drug Saf. 2010, 19, 238–246. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Chen, J.; He, H.; Williams, G.J.; Kelman, C.; O’Keefe, C.M. Mining unexpected temporal associations: Applications in detecting adverse drug reactions. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 488–500. [Google Scholar] [PubMed]
- Celi, L.A.; Zimolzak, A.J.; Stone, D.J. Dynamic clinical data mining: Search engine-based decision support. JMIR Med. Inform. 2014, 2, e13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pittet, D. Infection control and quality health care in the new millenium. Am. J. Infect. Control 2005, 33, 258–267. [Google Scholar] [CrossRef] [PubMed]
- Chambers, D.A.; Rupp, A. Sharing state mental health data for research: Building toward ongoing learning in mental health care systems. Adm. Policy Ment. Health Serv. Res. 2015, 42, 586–587. [Google Scholar] [CrossRef] [PubMed]
- Schilsky, R.L.; Michels, D.L.; Kearbey, A.H.; Yu, P.P.; Hudis, C.A. Building a rapid learning health care system for oncology: The regulatory framework of CancerLinQ. J. Clin. Oncol. 2014, 32, 2373–2379. [Google Scholar] [CrossRef] [PubMed]
- Reiner, B. Uncovering and improving upon the inherent deficiencies of radiology reporting through data mining. J. Digit. Imaging 2010, 23, 109–118. [Google Scholar] [CrossRef] [PubMed]
- Sukumar, S.R.; Natarajan, R.; Ferrell, R.K. Quality of Big Data in health care. Int. J. Qual. Health Care 2015, 28, 621–634. [Google Scholar] [CrossRef] [PubMed]
- Viceconti, M.; Hunter, P.; Hose, R. Big data, big knowledge: Big data for personalized healthcare. IEEE J. Biomed. Health Inform. 2015, 19, 1209–1215. [Google Scholar] [CrossRef] [PubMed]
- Roski, J.; Bo-Linn, G.W.; Andrews, T.A. Creating value in health care through big data: Opportunities and policy implications. Health Aff. 2014, 33, 1115–1122. [Google Scholar] [CrossRef] [PubMed]
- Westra, B.L.; Latimer, G.E.; Matney, S.A.; Park, J.I.; Sensmeier, J.; Simpson, R.L.; Swanson, M.J.; Warren, J.J.; Delaney, C.W. A national action plan for sharable and comparable nursing data to support practice and translational research for transforming health care. J. Am. Med. Inform. Assoc. 2015, 22, 600–607. [Google Scholar] [CrossRef] [PubMed]
- Heitmueller, A.; Henderson, S.; Warburton, W.; Elmagarmid, A.; Darzi, A. Developing public policy to advance the use of big data in health care. Health Aff. 2014, 33, 1523–1530. [Google Scholar] [CrossRef] [PubMed]
- Cohen, I.G.; Amarasingham, R.; Shah, A.; Xie, B.; Lo, B. The legal and ethical concerns that arise from using complex predictive analytics in health care. Health Aff. 2014, 33, 1139–1147. [Google Scholar] [CrossRef] [PubMed]
- Hiller, J.S. Healthy Predictions? Questions for Data Analytics in Health Care. Am. Bus. Law J. 2016, 53, 251–314. [Google Scholar] [CrossRef]
- Lu, R.; Lin, X.; Shen, X. SPOC: A secure and privacy-preserving opportunistic computing framework for mobile-healthcare emergency. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 614–624. [Google Scholar] [CrossRef]
- Orentlicher, D. Prescription data mining and the protection of patients’ interests. J. Law Med. Ethics 2010, 38, 74–84. [Google Scholar] [CrossRef] [PubMed]
- Soroushmehr, S.R.; Najarian, K. Transforming big data into computational models for personalized medicine and health care. Dialogues Clin. Neurosci. 2016, 18, 339–343. [Google Scholar]
- Martin, C.M.; Félix-Bortolotti, M. Person-centred health care: A critical assessment of current and emerging research approaches. J. Eval. Clin. Pract. 2014, 20, 1056–1064. [Google Scholar] [CrossRef] [PubMed]
- Estape, E.S.; Mays, M.H.; Sternke, E.A. Translation in Data Mining to Advance Personalized Medicine for Health Equity. Intell. Inf. Manag. 2016, 8, 9–16. [Google Scholar] [CrossRef] [PubMed]
- Kimberly, J.; Cronk, I. Making value a priority: How this paradigm shift is changing the landscape in health care. Ann. N. Y. Acad. Sci. 2016, 1381, 162–167. [Google Scholar] [CrossRef] [PubMed]
- Marshall, D.A.; Burgos-Liz, L.; IJzerman, M.J.; Crown, W.; Padula, W.V.; Wong, P.K.; Pasupathy, K.S.; Higashi, M.K.; Osgood, N.D. Selecting a dynamic simulation modeling method for health care delivery research—Part 2: Report of the ISPOR Dynamic Simulation Modeling Emerging Good Practices Task Force. Value Health 2015, 18, 147–160. [Google Scholar] [CrossRef] [PubMed]
- Reiner, B.I. Transforming health care service delivery and provider selection. J. Digit. Imaging 2011, 24, 373–377. [Google Scholar] [CrossRef] [PubMed]
- Bates, D.W.; Saria, S.; Ohno-Machado, L.; Shah, A.; Escobar, G. Big data in health care: Using analytics to identify and manage high-risk and high-cost patients. Health Aff. 2014, 33, 1123–1131. [Google Scholar] [CrossRef] [PubMed]
- Auffray, C.; Balling, R.; Barroso, I.; Bencze, L.; Benson, M.; Bergeron, J.; Bergeron, J.; Bernal-Delgado, E.; Blomberg, N.; Bock, C.; et al. Making sense of big data in health research: Towards an EU action plan. Genome Med. 2016, 8, 71–83. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Janke, A.T.; Overbeek, D.L.; Kocher, K.E.; Levy, P.D. Exploring the potential of predictive analytics and big data in emergency care. Ann. Emerg. Med. 2016, 67, 227–236. [Google Scholar] [CrossRef] [PubMed]
- Vie, L.L.; Griffith, K.N.; Scheier, L.M.; Lester, P.B.; Seligman, M.E. The Person-Event Data Environment: Leveraging big data for studies of psychological strengths in soldiers. Front. Psychol. 2013, 4, 934. [Google Scholar] [CrossRef] [PubMed]
- Andreu-Perez, J.; Poon, C.C.; Merrifield, R.D.; Wong, S.T.; Yang, G.-Z. Big data for health. IEEE J. Biomed. Health Inform. 2015, 19, 1193–1208. [Google Scholar] [CrossRef] [PubMed]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From data mining to knowledge discovery in databases. AI Mag. 1996, 17, 37–55. [Google Scholar]
- Koh, H.C.; Tan, G. Data mining applications in healthcare. J. Healthc. Inform. Manag. 2011, 19, 65–73. [Google Scholar]
- Aguinis, H.; Gottfredson, R.K.; Joo, H. Best-practice recommendations for defining, identifying, and handling outliers. Organ. Res. Meth. 2013, 16, 270–301. [Google Scholar] [CrossRef]
- John, U.; Hensel, E.; Lüdemann, J.; Piek, M.; Sauer, S.; Adam, C.; Adam, C.; Born, G.; Alte, D.; Greiser, E.; et al. Study of Health In Pomerania (SHIP): A health examination survey in an east German region: Objectives and design. Sozial-und Präventivmedizin 2001, 46, 186–194. [Google Scholar] [CrossRef] [PubMed]
- Nicholas, T.N. The Black Swan: The Impact of the Highly Improbable; Random: New York, NY, USA, 2007. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
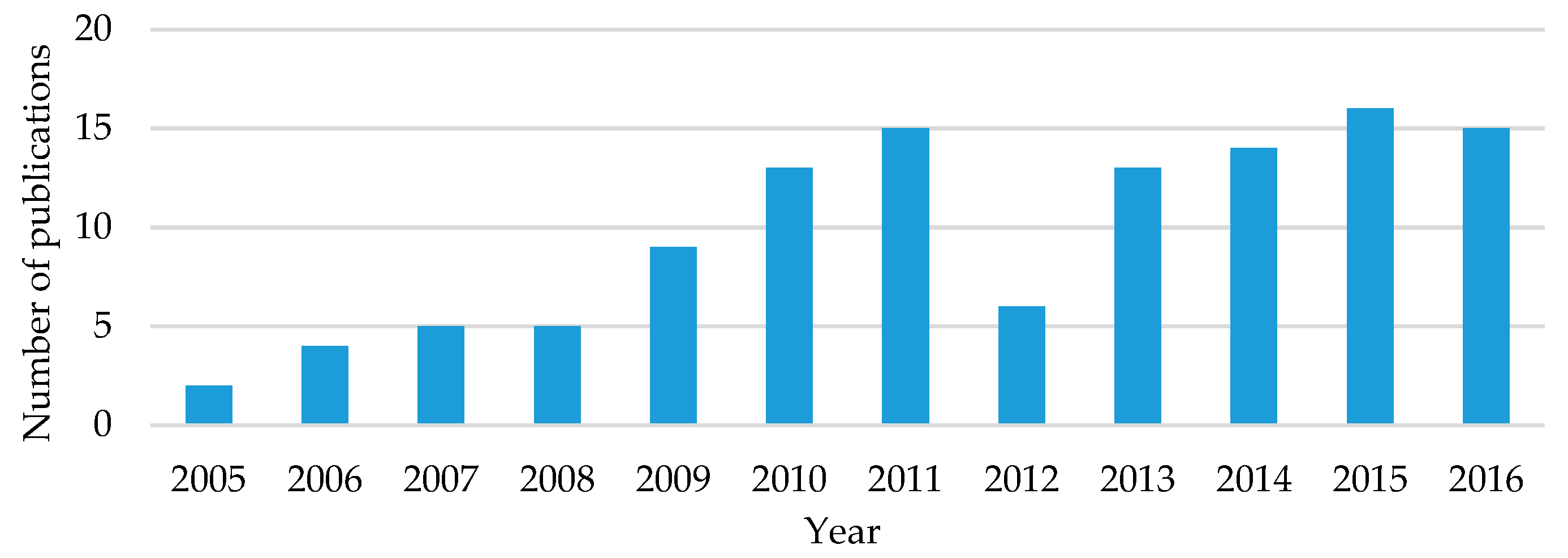{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Scope | Timeframe Considered | Number of Papers Reviewed |
|---|---|---|---|
| [11] | Awareness effect in type 2 diabetes | 2001–2005 | 18 |
| [12] | Fraud detection | N/A | N/A |
| [13] | Data mining techniques and guidelines for clinical medicine | N/A | N/A |
| [14] | Text mining, Ontologies | N/A | N/A |
| [15] | Challenges and future direction | N/A | N/A |
| [16] | Data mining algorithm, their performance in clinical medicine | 1998–2008 | 84 |
| [17] | Clinical medicine | N/A | N/A |
| [18] | Skin diseases | N/A | N/A |
| [19] | Clinical medicine | N/A | 84 |
| [20] | Algorithms, and guideline | N/A | N/A |
| [9] | Data mining process and algorithms | N/A | N/A |
| [21] | Algorithms for locally frequent disease in healthcare administration, clinical care and research, and training | N/A | N/A |
| [7] | Electronic Medical Record (EMR) and Visual analytics | N/A | N/A |
| [10] | Big data, Level of data usage | N/A | N/A |
| [22] | MapReduce architectural framework based big data analytics | 2007–2014 | 32 |
| [23] | Big data analytics and its opportunities | N/A | N/A |
| [24] | Big data analytics in image processing, signal processing, and genomics | N/A | N/A |
| [25] | Social media data mining to detect Adverse Drug Reaction, Natural language processing techniques (NLP) | 2004–2014 | 39 |
| [26] | Text mining, Adverse Drug Reaction detection | N/A | N/A |
| [8] | Big data analytics in critical care | N/A | N/A |
| [27] | Methodology of big data analytics in healthcare | N/A | N/A |
| Our study | Application and theoretical perspective of data mining and big data analytics in whole healthcare domain | 2005–2016 | 117 |
| Phase | Keyword 1 (OR 1) | AND | Keyword 2 (OR 1) |
| 1 | Healthcare, Health care | Data analysis | |
| 2 | Healthcare, Health care, Cancer 2, Disease, Genomics | Data mining, Big data |
| Class | Operational Definition * |
|---|---|
| Analytics | Knowledge discovery by analyzing, interpreting, and communicating data |
| 3A. Types of Analytics | Data Interpretation and Communication method |
| Exploration and discovery of information in the dataset [33] |
| Prediction of upcoming events based on historical data [22] |
| Utilization of scenarios to provide decision support [22] |
| 3B. Types of Data | Type or nature of data used in the study |
| Data extracted from websites, blogs, social media like Facebook, Twitter, LinkedIn [23] |
| Readings from medical devices and sensors [23] |
| “Finger prints, genetics, handwriting, retinal scans, X-ray and other medical images, blood pressure, pulse and pulse-oximetry readings, and other similar types of data” [23] |
| Healthcare bill, insurance claims and transections [23] |
| Semi-structured and unstructured documents like prescription, Electronic Medical Record (EMR), notes and emails [23] |
| 3C. Data mining techniques | Techniques applied to extract and communicate information from the dataset |
| Relationship estimation between variables |
| Finding relation between variables |
| Mapping to predefined class based on shared characteristics |
| Identification of groups and categories in data |
| Detection of out-of-pattern events or incidents |
| A large storage of data to facilitate decision-making |
| Identification of statistically significant patterns in a sequence of data |
| 3D. Application Area | Different areas in healthcare where data mining is applied for knowledge discovery and/or decision support |
| Analytics applied to analyze, extract and communicate information about diseases, risk for clinical use |
| Application of analytics to improve quality of care, reduce the cost of care and to improve overall system dynamics |
| Privacy: Protection of patient identity in the dataset; Fraud detection: Deceptive and unauthorized activity detection |
| Analytical decision support for psychiatric patients or patient with mental disorder |
| Analysis of problems which affect a mass population, a region, or a country |
| Post market monitoring of Adverse Drug Reaction (ADR) |
| 3E. Theoretical study | Discusses impact, challenges, and future of data mining and big data analytics in healthcare |
| Journal | Number of Articles | |
|---|---|---|
| 1. | Expert Systems with Applications | 7 |
| 2. | IEEE Transection on Information Technology in Biomedicine | 6 |
| 3. | Journal of Medical Internet Research | 5 |
| 4. | Journal of Medical Systems | 4 |
| 5. | Journal of the American Medical Informatics Association | 4 |
| 6. | Health Affairs | 4 |
| 7. | Journal of Biomedical Informatics | 4 |
| 8. | Healthcare Informatics Research | 3 |
| 9. | Journal of Digital Imaging | 3 |
| 10. | PLoS ONE | 3 |
| Reference | Major Disease | Topic Investigated | Data Source |
|---|---|---|---|
| [40] | Cardiovascular disease (CVD) | Risk factors associated with Coronary heart disease (CHD) | Department of Cardiology, at the Paphos General Hospital in Cyprus |
| [41] | Diagnosis of CHD | Invasive Cardiology Department, University Hospital of Ioannina, Greece | |
| [42] | Classification of uncertain and high dimensional heart disease data | UCI machine learning laboratory repository | |
| [43] | Risk prediction of Cardiovascular adverse event | U.S. Midwestern healthcare system | |
| [44] | Cardiovascular event risk prediction | HMO Research Network Virtual Data Warehouse | |
| [45] | Mobile based cardiovascular abnormality detection | MIT BIH ECG database | |
| [46] | Management of infants with hypoplastic left heart syndrome | The University of Iowa Hospital and Clinics | |
| [47] | Diabetes | Identification of pattern in temporal data of diabetic patients | Synthetic and real world data (not specified) |
| [48] | Exploring the examination history of Diabetic patients | National Health Center of Asti Providence, Italy | |
| [49] | Important factors to identify type 2 diabetes control | The Ulster Hospital, UK | |
| [50] | Comparison of classification accuracy of algorithms for diabetes | Iranian national non-communicable diseases risk factors surveillance | |
| [51] | Type 2 diabetes risk prediction | Independence Blue Cross Insurance Company | |
| [52] | Evaluation of HTCP algorithm in classifying type 2 diabetes patients from non-diabetic patient | Olmsted Medical Center and Mayo Clinic in Rochester, Minnesota, USA | |
| [53] | Predicting and risk diagnosis of patients for being affected with diabetes. | 1991 National Survey of Diabetes data | |
| [54] | Cancer | Survival prediction of prostate cancer patients | The Surveillance, Epidemiology, and End Results (SEER) Program of the National Cancer Institute, USA |
| [38] | Classification of breast cancer patients with novel algorithm | Wisconsin Breast cancer data set, UCI machine learning laboratory repository | |
| [42] | Classification of uncertain and high dimensional breast cancer data | UCI machine learning laboratory repository | |
| [55] | Visualization tool for cancer | Taiwan National Health Insurance Database | |
| [56] | Lung cancer survival prediction with the help of a predictive outcome calculator | SEER Program of the National Cancer Institute, USA | |
| [57] | Emergency Care | Classification of chest pain in emergency department | Hospital (unspecified) emergency department EMR |
| [58] | Grouping of emergency patients based on treatment pattern | Melbourne’s teaching metropolitan hospital | |
| [59] | Intensive care | Mortality rate of ICU patients | University of Kentucky Hospital |
| [60] | Prediction of 30 day mortality of ICU patients | MIMIC-II database | |
| [61] | Other applications | Treatment plan in respiratory infection disease | Various health center throughout Malaysia |
| [62] | Pressure ulcer prediction | Cathy General Hospital (06–07), Taiwan | |
| [63] | Pressure ulcer risk prediction | Military Nursing Outcomes Database (MilNOD), US | |
| [64] | Association of medication, laboratory and problem | Brigham and Women’s Hospital, US | |
| [65] | Chronic disease (asthma) attack prediction | Blue Angel 24 h Monitoring System, Tainan; Environmental Protection Administration Executive, Yuan; Central Weather Bureau Tainan, Taiwan | |
| [66] | Personalized care, predicting future disease | No specified | |
| [67] | Correlation between disease | Sct. Hans Hospital | |
| [68] | Glaucoma prediction using Fundus image | Kasturba Medical college, Manipal, India | |
| [69] | Reducing follow-up delay from image analysis | Department of Veterans Affairs health-care facilities | |
| [70] | Disease risk prediction in imbalanced data | National Inpatient Sample (NIS) data, available at http://www.ahrq.gov by Healthcare Cost and Utilization Project (HCUP) | |
| [71] | Survivalist prediction of kidney disease patients | University of Iowa Hospital and Clinics | |
| [72] | Comparison surveillance techniques for health care associated infection | University of Alabama at Birmingham Hospital | |
| [73] | Parkinson disease prediction based on big data analytics | Big data archive by Parkinson’s Progression Markers Initiative (PPMI) | |
| [74] | Hospitalization prediction of Hemodialysis patients | Hemodialysis center in Taiwan | |
| [75] | 5 year Morbidity prediction | Northwestern Medical Faculty Foundation (NMFF) | |
| [76] | Algorithm development for real-time disease diagnosis and prognosis | Not specified |
| Reference | Focusing Area | Problem Analyzed | Data Source |
|---|---|---|---|
| [89] | Data warehousing and cloud computing | Developing a platform to analyze the causes of readmission | Emory Hospital, US |
| [90] | Development of a clinical data warehouse and analytical tools for traditional Chinese medicine | Traditional Chinese Medicine hospitals/wards | |
| [91] | Cloud and big data analytics based cyber-physical system for patient-centric healthcare applications and services | Not specified | |
| [92] | Repository of radiology reports | Not specified | |
| [93] | Creation of large data repository and knowledge discovery with unsupervised learning | University of Virginia University Health System | |
| [94] | Development of a mobile application to gather, store and provide data for rural healthcare | Not specified | |
| [95] | Healthcare cost, quality and resource utilization | Treatment error prevention to improve quality and reduce cost | National Taiwan University Hospital |
| [96] | Healthcare cost prediction | US health insurance company | |
| [97] | Healthcare resource utilization by lung cancer patients | Medicare beneficiaries for 1999, US | |
| [98] | Length of stay prediction of Coronary Artery Disease (CAD) | Rajaei Cardiovascular Medical and Research Center, Tehran, Iran | |
| [99] | Methodology for structured development of monitoring systems and a primary HC network resource allocation monitoring model | National Institute of Public Health; Health Care Institute, Celje; Slovenian Social Security Database, and Slovenian Medical Chamber | |
| [100] | Assess the ability of regression tree boosting to risk-adjust health care cost predictions | Thomson Medstat’s Commercial Claims and Encounters database. | |
| [101] | Evidence based recommendation in prescribing drugs | Dalhousie University Medical Faculty | |
| [102] | Efficient pathology ordering system | Pathology company in Australia | |
| [103] | Identifying people with or without insurance based on demographic and socio-economic factors | Behavioral Risk Factor Surveillance System 2004 Survey Data | |
| [104] | Predicting care quality from patient experience | English National Health Service website | |
| [105] | Patient management | Scheduling of patients | A south-east rural U.S. clinic |
| [106] | Care plan recommendation system | A community hospital in the Mid-West U.S. | |
| [107] | Examination of risk factors to predict persistent healthcare frequent attendance | Tampere Health Centre, Finland | |
| [108] | Forecasting number of patient visit for administrative task | Health care center in Jaen, Spain | |
| [109] | Critical factors related to fall | 1000 bed hospital in Taiwan | |
| [110] | Verification of structured data, and codes in EMR of fall related injuries from unstructured data | Veterans Health Administration database, US | |
| [111] | Other applications | Relation between medical school training and practice | Center for Medicare and Medicaid Service (CMS) |
| [112] | Analysis of physician reviews from online platform | Good Doctor Online health community | |
| [113] | Evaluation of Key Performance Indicator (KPIs) of hospital | Greek National Health Systems for the year of 2013 | |
| [114] | Post market performance evaluation of medical devices | HCUPNet data (2002–2011) | |
| [115] | Feasibility of measuring drug safety alert response from HC professional’s information seeking behavior | UpToDate, an online medical resource | |
| [116] | Influencing factors of home healthcare service outcome | U.S. home and hospice care survey (2000) | |
| [117] | Compilation of various data types for tracing, and analyzing temporal events and facilitating the use of NoSQL and cloud computing techniques | Taiwan’s National Health Insurance Research Database (NHIRD) |
| Reference | Problem Analyzed | Data Source |
|---|---|---|
| [119] | Cloud based big data framework to ensure data security | Not specified |
| [120] | Weakness in de-identification or anonymization of health data | MedHelp and Mp and Th1 (Medicare social networking sites) |
| [121] | Automatic and systematic detection of fraud and abuse | Bureau of National Health Insurance (BNHI) in Taiwan. |
| [122] | Novel algorithm to protect data privacy | Hong Kong Red Cross Blood Transfusion Service (BTS) |
| Reference | Problem Analyzed | Data Source |
|---|---|---|
| [126] | Identification and intervention of developmental delay of children | Yunlin Developmental Delay Assessment Center |
| [125] | Personalized treatment for anxiety disorder | Volunteer participants |
| [127] | Abnormal behavior detection | Through experiment with human subject |
| [128] | Mental health diagnosis and exploration of psychiatrist’s everyday practice | Queensland Schizophrenia Research center |
| Reference | Problem Analyzed | Data Source |
|---|---|---|
| [130] | Designing preventive healthcare programs | World Health Organization (WHO) |
| [131] | Predicting the peak of health center visit due to influenza | Military Influenza case data provided by US Armed Forces Health Surveillance Center and Environmental data from US National Climate Data Center |
| [132] | Contrast patient and customer loyalty, estimating Customer lifetime value, and identifying the targeted customer | Iranian Public Hospital data extracted from Hospital information system |
| [133] | Understanding the information seeking behavior of public and professionals on infectious disease | National electronic Library of Infection and National Resource of Infection Control, Google Trends, and relevant media coverage (LexisNexis). |
| [134] | Knowledge extraction for non-expert user through automation of data mining process | Brazilian health ministry |
| [135] | Innovative use of data mining and visualization techniques for decision-making | Slovenian national Institute of Public Health |
| [136] | Real-time emergency response method using big data and Internet of Things | UCI machine learning repository |
| Reference | Problem Analyzed | Data Source |
|---|---|---|
| [140] | Sentiment and network analysis based on social media data to find ADR signal | Cancer discussion forum websites |
| [138] | ADR signal detection from multiple data sources | Food and Drug Administration (FDA) database and publicly available electronic health record (HER) in US |
| [141] | ADR detection from EPR through temporal data analysis | Danish psychiatric hospital |
| [142] | ADR (hypersensitivity) signal detection of six anticancer agents | FDA released AERS reports (2004–2009), US |
| [139] | ADR caused by multiple drugs | FDA released AERS reports, US |
| [143] | ADR due to Statins used in Cardiovascular disease (CVD) and muscular and renal failure treatment | FDA released AERS reports, US |
| [144] | Creating a ranked list of Adverse Events (AEs) | EHR form European Union |
| [145] | Detecting ADR signals of Rosuvastatins compared to other statins users | Health Insurance Review and Assessment Service claims database (Seoul, Korea) |
| [146] | Unexpected and rare ADR detection technique | Medicare Benefits Scheme (MBS) and Queensland Linked Data Set (QLDS) |
| Sector Highlight | Reference | Problem Analyzed |
|---|---|---|
| Disease Control, Current situation of different diseases (infection, epidemic, cancer, mental health) | [147] | Proposed an idea for dynamic clinical decision support |
| [148] | Described current situation of infection control and predicted future challenges in this sector | |
| [149] | Described activities taken by national organization to control disease and provide better health care | |
| [150] | Reviewed efficient collection and aggregation of big data and proposed an intelligence based learning framework to help prevent cancer | |
| Data quality, database framework and uncertainty quantification | [151] | Considered the management of uncertainty originating from data mining. |
| [152] | Contemplated the quality of the data when collected from multimodal sources | |
| [150] | Provided the structure of the database of CancerLinQ that comprised of 4 key steps | |
| [153] | Described five major problems that need to be tackled in order to have an effective integration of big data analytics and VPH modeling in healthcare | |
| [152] | Discuss the issues of data quality in the context of big data health care analytics | |
| [154] | Discussed the necessity of proper management and confidentiality of healthcare data along with the benefit of big data analytics | |
| Healthcare policy making | [155,156,157] | Addressed the challenges faced in implementing health care policies and considered the ethical and legal issues of performing predictive analysis on health care big data |
| [150] | Focused on the US federal regulatory pathway by which CancerLinQ will have legislative authority to use the patients’ records and the approach of ASCO toward the organizing and supervising the information | |
| Patient Privacy | [158] | Focused on ensuring patient privacy while collecting data, storing them and using them for analysis aimed to eliminate discrimination in the health care provided to patients. |
| [159] | Spotted light on ensuring Privacy and security while collecting Personal Health care Information (PHI) | |
| [160] | Highlighted those strategies appropriate for data mining from physicians’ prescriptions while maintaining the patient’s privacy | |
| Personalized health care | [161] | Transforming big data into computational models to provide personalized health care |
| [162] | Development of informed decision-making frameworks for person centered health care | |
| [163] | Looked into the availability of big data and the role of biomedical informatics on the personalized medicine. Also, emphasized on the ethical concerns related to personalized medicines | |
| Others | [164] | Finding the aspects of big data that are most relevant to Health care |
| [165] | Selecting dynamic simulation modeling approach based on the availability and type of big data | |
| [166] | Quantifying performance in the delivery of medical services | |
| [167] | Identifying high risk patients to ensure better care, and explored the analytics procedure, algorithms and challenges to implement analytics | |
| [168] | Addressed barriers for the exploitation of health data in Europe | |
| [169] | Analyzed the opportunity and obstacles in applying predictive analytics based on big data in case of evaluating emergency care | |
| [170] | Provided an overview of the uses of the Person-Event Data Environment to perform command surveillance and policy analysis for Army leadership | |
| [171] | Development of big data analytics in healthcare and future challenges |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.S.; Hasan, M.M.; Wang, X.; Germack, H.D.; Noor-E-Alam, M. A Systematic Review on Healthcare Analytics: Application and Theoretical Perspective of Data Mining. Healthcare 2018, 6, 54. https://doi.org/10.3390/healthcare6020054
Islam MS, Hasan MM, Wang X, Germack HD, Noor-E-Alam M. A Systematic Review on Healthcare Analytics: Application and Theoretical Perspective of Data Mining. Healthcare. 2018; 6(2):54. https://doi.org/10.3390/healthcare6020054
Chicago/Turabian StyleIslam, Md Saiful, Md Mahmudul Hasan, Xiaoyi Wang, Hayley D. Germack, and Md Noor-E-Alam. 2018. "A Systematic Review on Healthcare Analytics: Application and Theoretical Perspective of Data Mining" Healthcare 6, no. 2: 54. https://doi.org/10.3390/healthcare6020054
APA StyleIslam, M. S., Hasan, M. M., Wang, X., Germack, H. D., & Noor-E-Alam, M. (2018). A Systematic Review on Healthcare Analytics: Application and Theoretical Perspective of Data Mining. Healthcare, 6(2), 54. https://doi.org/10.3390/healthcare6020054