
A Fusion-Based Machine Learning Approach for the Prediction of the Onset of Diabetes

 ,
,  ,
,  and
and
Abstract
:1. Introduction
- A fusion-based machine learning architecture for the prediction of diabetes has been proposed.
- Two machine learning classifiers Support Vector Machine (SVM) and Artificial Neural Network (ANN) within the architecture have been evaluated.
2. Related Research
3. Materials and Methods
3.1. Datasets
3.2. System Architecture
3.2.1. Data Fusion
3.2.2. Pre-Processing
3.2.3. Cross-Fold Validation
3.2.4. Support Vector Machines
- (i)
- Linear Kernel:
- (ii)
- Radical Kernel:
- (iii)
- Polynomial Kernel:
- (iv)
- Sigmoid Kernel: where and all are constants.
3.2.5. Artificial Neural Networks
3.2.6. Fusion of SVM-ANN
4. Performance Evaluation
4.1. Performance Evaluation Matrix
4.2. Performance Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alberti, K.G.M.M.; Zimmet, P.; Shaw, J. International Diabetes Federation: A consensus on Type 2 diabetes prevention. Diabet. Med. 2007, 24, 451–463. [Google Scholar] [CrossRef]
- Mellitus, D. Diagnosis and classification of diabetes mellitus. Diabetes Care 2005, 28, S5–S10. [Google Scholar]
- WHO. World Health Statistics 2016: Monitoring Health for the SDGs Sustainable Development Goals; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Franciosi, M.; De Berardis, G.; Rossi, M.C.; Sacco, M.; Belfiglio, M.; Pellegrini, F.; Tognoni, G.; Valentini, M.; Nicolucci, A.; For the IGLOO Study Group. Use of the Diabetes Risk Score for Opportunistic Screening of Undiagnosed Diabetes and Impaired Glucose Tolerance: The IGLOO (Impaired Glucose Tolerance and Long-Term Outcomes Observational) study. Diabetes Care 2005, 28, 1187–1194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramezani, R.; Maadi, M.; Khatami, S.M. A novel hybrid intelligent system with missing value imputation for diabetes diagnosis. Alex. Eng. J. 2018, 57, 1883–1891. [Google Scholar] [CrossRef]
- Pourpanah, F.; Lim, C.P.; Saleh, J.M. A hybrid model of fuzzy ARTMAP and genetic algorithm for data classification and rule extraction. Expert Syst. Appl. 2016, 49, 74–85. [Google Scholar] [CrossRef]
- Patil, B.; Joshi, R.; Toshniwal, D. Hybrid prediction model for Type-2 diabetic patients. Expert Syst. Appl. 2010, 37, 8102–8108. [Google Scholar] [CrossRef]
- Alic, B.; Gurbeta, L.; Badnjevic, A. Machine learning techniques for classification of diabetes and cardiovascular diseases. In Proceedings of the 2017 6th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 11–15 June 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Nadeem, M.W.; Ghamdi, M.A.A.; Hussain, M.; Khan, M.A.; Khan, K.M.; Almotiri, S.H.; Butt, S.A. Brain tumor analysis empowered with deep learning: A review, taxonomy, and future challenges. Brain Sci. 2020, 10, 118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nadeem, M.W.; Goh, H.G.; Ali, A.; Hussain, M.; Khan, M.A. Bone Age Assessment Empowered with Deep Learning: A Survey, Open Research Challenges and Future Directions. Diagnostics 2020, 10, 781. [Google Scholar] [CrossRef]
- Fernández-Caramés, T.M.; Froiz-Míguez, I.; Blanco-Novoa, O.; Fraga-Lamas, P. Enabling the Internet of Mobile Crowdsourcing Health Things: A Mobile Fog Computing, Blockchain and IoT Based Continuous Glucose Monitoring System for Diabetes Mellitus Research and Care. Sensors 2019, 19, 3319. [Google Scholar] [CrossRef] [Green Version]
- Dhillon, V.; Metcalf, D.; Hooper, M. Blockchain in healthcare. In Blockchain-Enabled Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 201–220. [Google Scholar]
- Yaqoob, I.; Salah, K.; Jayaraman, R.; Al-Hammadi, Y. Blockchain for healthcare data management: Opportunities, challenges, and future recommendations. Neural Comput. Appl. 2021, 33, 1–16. [Google Scholar]
- Cichosz, S.L.; Stausholm, M.; Kronborg, T.; Vestergaard, P.; Hejlesen, O. How to Use Blockchain for Diabetes Health Care Data and Access Management: An Operational Concept. J. Diabetes Sci. Technol. 2018, 13, 248–253. [Google Scholar] [CrossRef]
- Bhardwaj, R.; Datta, D. Development of a Recommender System HealthMudra Using Blockchain for Prevention of Diabetes; Scrivener Publishing LLC: Hoboken, NJ, USA, 2020; pp. 313–327. [Google Scholar] [CrossRef]
- Bhavin, M.; Tanwar, S.; Sharma, N.; Tyagi, S.; Kumar, N. Blockchain and quantum blind signature-based hybrid scheme for healthcare 5.0 applications. J. Inf. Secur. Appl. 2021, 56, 102673. [Google Scholar]
- Nadeem, M.W.; Goh, H.G.; Khan, M.A.; Hussain, M.; Mushtaq, M.F.; Ponnusamy, V.A. Fusion-Based Machine Learning Architecture for Heart Disease Prediction. Comput. Mater. Contin. 2021, 67, 2481–2496. [Google Scholar] [CrossRef]
- Maniruzzaman, M.; Rahman, J.; Ahammed, B.; Abedin, M. Classification and prediction of diabetes disease using machine learning paradigm. Health Inf. Sci. Syst. 2020, 8, 7. [Google Scholar] [CrossRef]
- Malik, S.; Harous, S.; El-Sayed, H. Comparative Analysis of Machine Learning Algorithms for Early Prediction of Diabetes Mellitus in Women. In Proceedings of the 2020, International Symposium on Modelling and Implementation of Complex Systems, Batna, Algeria, 24–26 October 2020; Springer: Cham, Switzerland, 2020; Volume 156, pp. 95–106. [Google Scholar] [CrossRef]
- Kayaer, K.; Yildirim, T. Medical diagnosis on Pima Indian diabetes using general regression neural networks. In Proceedings of the International Conference on Artificial Neural Networks and Neural Information Processing (ICANN/ICONIP), Istambul, Turkey, 27 June 2003; Volume 181, p. 184. [Google Scholar]
- Temurtas, H.; Yumusak, N.; Temurtas, F. A comparative study on diabetes disease diagnosis using neural networks. Expert Syst. Appl. 2009, 36, 8610–8615. [Google Scholar] [CrossRef]
- Polat, K.; Güneş, S. An expert system approach based on principal component analysis and adaptive neuro-fuzzy inference system to diagnosis of diabetes disease. Digit. Signal. Process. 2007, 17, 702–710. [Google Scholar] [CrossRef]
- Sagir, A.M.; Sathasivam, S. Design of a modified adaptive neuro fuzzy inference system classifier for medical diag-nosis of Pima Indians Diabetes. AIP Conf. Proc. 2017, 1870, 40048. [Google Scholar]
- Polat, K.; Güneş, S.; Arslan, A. A cascade learning system for classification of diabetes disease: Generalized discri-minant analysis and least square support vector machine. Expert Syst. Appl. 2008, 34, 482–487. [Google Scholar] [CrossRef]
- Guo, Y.; Bai, G.; Hu, Y. Using bayes network for prediction of type-2 diabetes. In Proceedings of the 2012 International Conference for Internet Technology and Secured Transactions, London, UK, 10–19 December 2012; pp. 471–472. [Google Scholar]
- Aslam, M.W.; Zhu, Z.; Nandi, A.K. Feature generation using genetic programming with comparative partner se-lection for diabetes classification. Expert Syst. Appl. 2013, 40, 5402–5412. [Google Scholar] [CrossRef]
- Wettayaprasit, W.; Sangket, U. Linguistic knowledge extraction from neural networks using maximum weight and frequency data representation. In Proceedings of the Conference on Cybernetics and Intelligent Systems, Bangkok, Thailand, 7 June 2006; pp. 1–6. [Google Scholar] [CrossRef]
- Ganji, M.F.; Abadeh, M.S. Using fuzzy ant colony optimization for diagnosis of diabetes disease. In Proceedings of the 18th Iranian Conference on Electrical Engineering, Isfahan, Iran, 11–13 May 2010; pp. 501–505. [Google Scholar] [CrossRef]
- Beloufa, F.; Chikh, M. Design of fuzzy classifier for diabetes disease using Modified Artificial Bee Colony algorithm. Comput. Methods Programs Biomed. 2013, 112, 92–103. [Google Scholar] [CrossRef] [PubMed]
- Zangooei, M.H.; Habibi, J.; Alizadehsani, R. Disease Diagnosis with a hybrid method SVR using NSGA-II. Neurocomputing 2014, 136, 14–29. [Google Scholar] [CrossRef]
- Perveen, S.; Shahbaz, M.; Saba, T.; Keshavjee, K.; Rehman, A.; Guergachi, A. Handling Irregularly Sampled Longitudinal Data and Prognostic Modeling of Diabetes Using Machine Learning Technique. IEEE Access 2020, 8, 21875–21885. [Google Scholar] [CrossRef]
- Rehman, A.; Athar, A.; Khan, M.A.; Abbas, S.; Fatima, A.; Saeed, A. Modelling, simulation, and optimization of dia-betes type II prediction using deep extreme learning machine. J. Ambient Intell. Smart Environ. 2020, Preprint. 1–14. [Google Scholar]
- Cahn, A.; Shoshan, A.; Sagiv, T.; Yesharim, R.; Goshen, R.; Shalev, V.; Raz, I. Prediction of progression from pre-diabetes to diabetes: Development and validation of a machine learning model. Diabetes Metab. Res. Rev. 2019, 36, e3252. [Google Scholar] [CrossRef]
- White, F.E. Data Fusion Lexicon; Joint Directors of Labs: Washington, DC, USA, 1991. [Google Scholar]
- Llinas, J.; Hall, D. An introduction to multi-sensor data fusion. In Proceedings of the IEEE International Symposium on Circuits and Systems (Cat. No. 98CH36187), Baltimore, MD, USA, 7–9 June 1998. [Google Scholar] [CrossRef]
- Luo, R.C.; Kay, M. Multisensor Integration And Fusion: Issues And Approaches. Proc. SPIE 1988, 0931. [Google Scholar] [CrossRef]
- Luo, R.C.; Yih, C.-C.; Su, K.L. Multisensor fusion and integration: Approaches, applications, and future research directions. IEEE Sens. J. 2002, 2, 107–119. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Krstajic, D.; Buturovic, L.J.; Leahy, D.E.; Thomas, S. Cross-validation pitfalls when selecting and assessing regression and classification models. J. Chemin. 2014, 6, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Zeng, X.; Martinez, T.R. Distribution-balanced stratified cross-validation for accuracy estimation. J. Exp. Theor. Artif. Intell. 2000, 12, 1–12. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Springer Nature: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Sands, T.M.; Tayal, D.; Morris, M.E.; Monteiro, S.T. Robust stock value prediction using support vector machines with particle swarm optimization. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC). IEEE, Cancun, Mexico, 20–23 June 2015; pp. 3327–3331. [Google Scholar] [CrossRef]
- Sheta, A.F.; Ahmed, S.E.M.; Faris, H. A comparison between regression, artificial neural networks and support vector machines for predicting stock market index. Soft Comput. 2015, 7, 2. [Google Scholar]
- Ding, Y.; Song, X.; Zen, Y. Forecasting financial condition of Chinese listed companies based on support vector ma-chine. Expert Syst. Appl. 2008, 34, 3081–3089. [Google Scholar] [CrossRef]
- Luo, L.; Chen, X. Integrating piecewise linear representation and weighted support vector machine for stock trading signal prediction. Appl. Soft Comput. 2013, 13, 806–816. [Google Scholar] [CrossRef]
- Van Cranenburgh, S.; Alwosheel, A. An artificial neural network based approach to investigate travellers’ decision rules. Transp. Res. Part. C Emerg. Technol. 2019, 98, 152–166. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies | Proposed Methods | Dataset | Findings |
|---|---|---|---|
| [5] | Logistic Adaptive Network Fuzzy Inference System (LANFIS) | Pima Indians diabetes | Prediction accuracy = 88.05% Sensitivity = 92.15% Specificity = 81.63% |
| [7] | Hybrid Prediction Model (HPM)+ C 4.5 | Pima Indian diabetes | Prediction accuracy = 92.38% |
| [20] | Artificial Neural Networks (ANN) + General Regression Neural Networks (GRNN) | Pima Indian diabetes | Prediction accuracy = 80% |
| [22] | Principal Component Analysis (PCA) + Adaptive Neuro-Fuzzy Inference System (ANFIS) | Pima Indian diabetes | Prediction accuracy = 89.47% |
| [23] | Adaptive Network-based Fuzzy System (ANFS) + Levenberg–Marquardt Algorithm | Pima Indian diabetes | Prediction accuracy = 82.30% Sensitivity = 66.23% Specificity = 89.78% |
| [24] | Least Square Support Vector Machine (LS-SVM) and Generalization Discriminant Analysis (GDA) | Pima Indian diabetes | Classification accuracy = 82.05% Sensitivity = 83.33% Specificity = 82.05% |
| [25] | Bayesian Network (BN) | Pima Indian diabetes | Prediction accuracy = 72.3% |
| [26] | (1) Genetic Algorithm (GA) + K-Nearest Neighbors (GA-KNN), (2) Genetic Algorithm (GA) + Support Vector Machine (GA-SVM) | Pima Indian diabetes | Prediction accuracy = 80.5%, Prediction accuracy = 87.0%, |
| [31] | Gaussian Hidden Markov Model (GHMM) | CPCSSN clinical dataset | Prediction accuracy = 85.9% |
| [32] | Deep Extreme Learning Machine (DELM) | Pima Indian diabetes | Prediction accuracy = 92.8% |
| [33] | Gradient Boosted Trees (GBTs) | Canadian AppleTree and the Israeli Maccabi Health Services (MHS) | Prediction accuracy = 92.5% |
| Proposed SVM-ANN | Prediction accuracy = 94.67% Sensitivity = 89.23% Specificity = 97.32% |
| S# | Feature Name | Description | Variable Type |
|---|---|---|---|
| 1 | Glucose (F1) | Plasma glucose concentration at 2 h in an oral glucose tolerance test | Real |
| 2 | Pregnancies (F2) | Number of times pregnant | Integer |
| 3 | Blood Pressure (F3) | Diastolic blood pressure (mm HG) | Real |
| 4 | Skin Thickness (F4) | Triceps skinfold thickness (mm) | Real |
| 5 | Insulin (F5) | 2-h serum insulin (mu U/mL) | Real |
| 6 | BMI (F6) | Body mass index (weight in kg/(height in)2 | Real |
| 7 | Diabetes Pedigree Function (F7) | Diabetes Pedigree Function | Real |
| 8 | Age (F8) | Age (years) | Integer |
| 1 Begin 2 Input Data 3 Apply Data fusion technique 4 Preprocess the data by different techniques 5 Data partitioning using the K-fold cross-validation method 6 Classification of diabetes and healthy peoples using SVM and ANN 7 Fusion of SVM and ANN 8 Computes performance of the architecture using a different evaluation matrix 9 Finish |
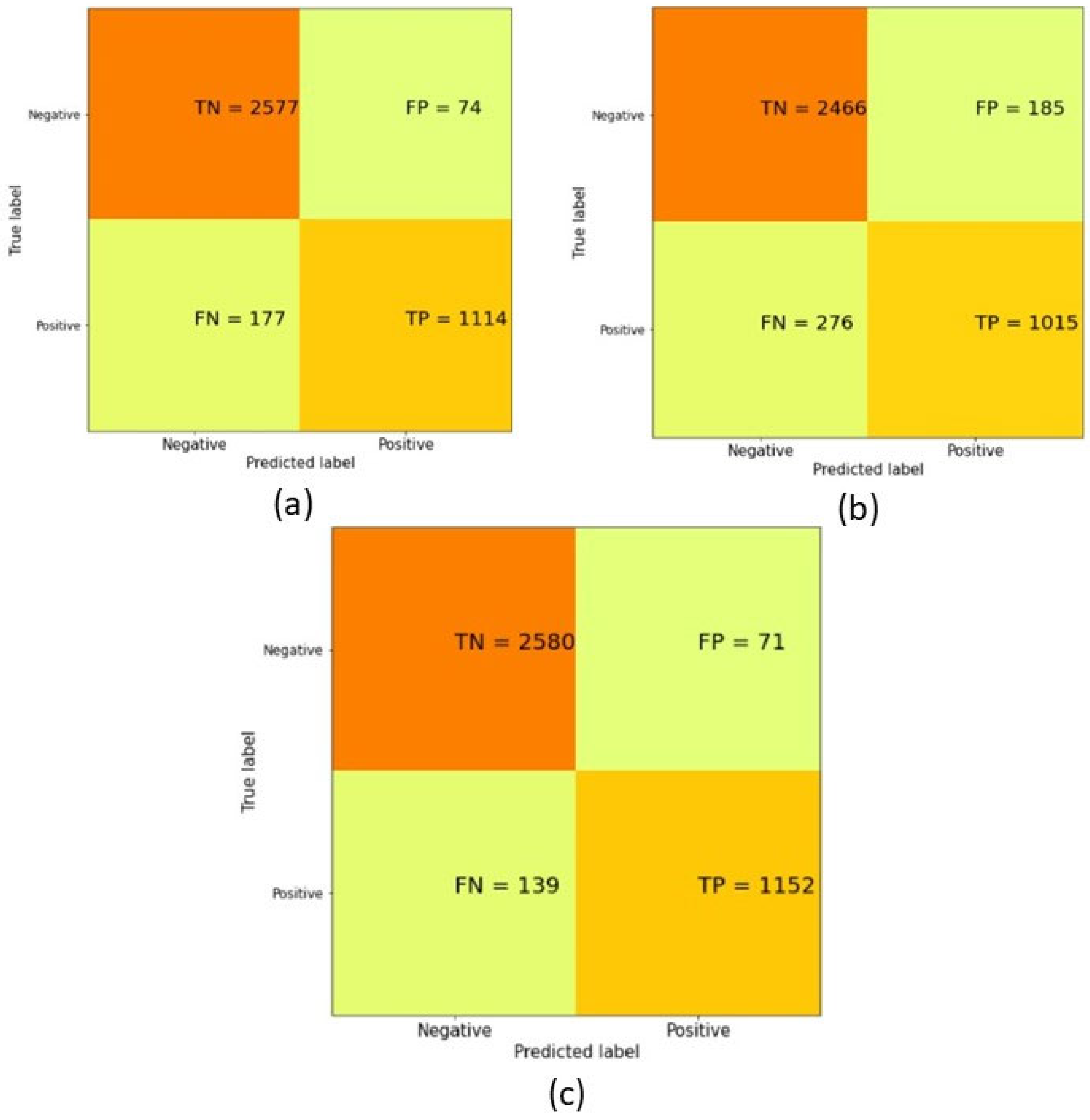
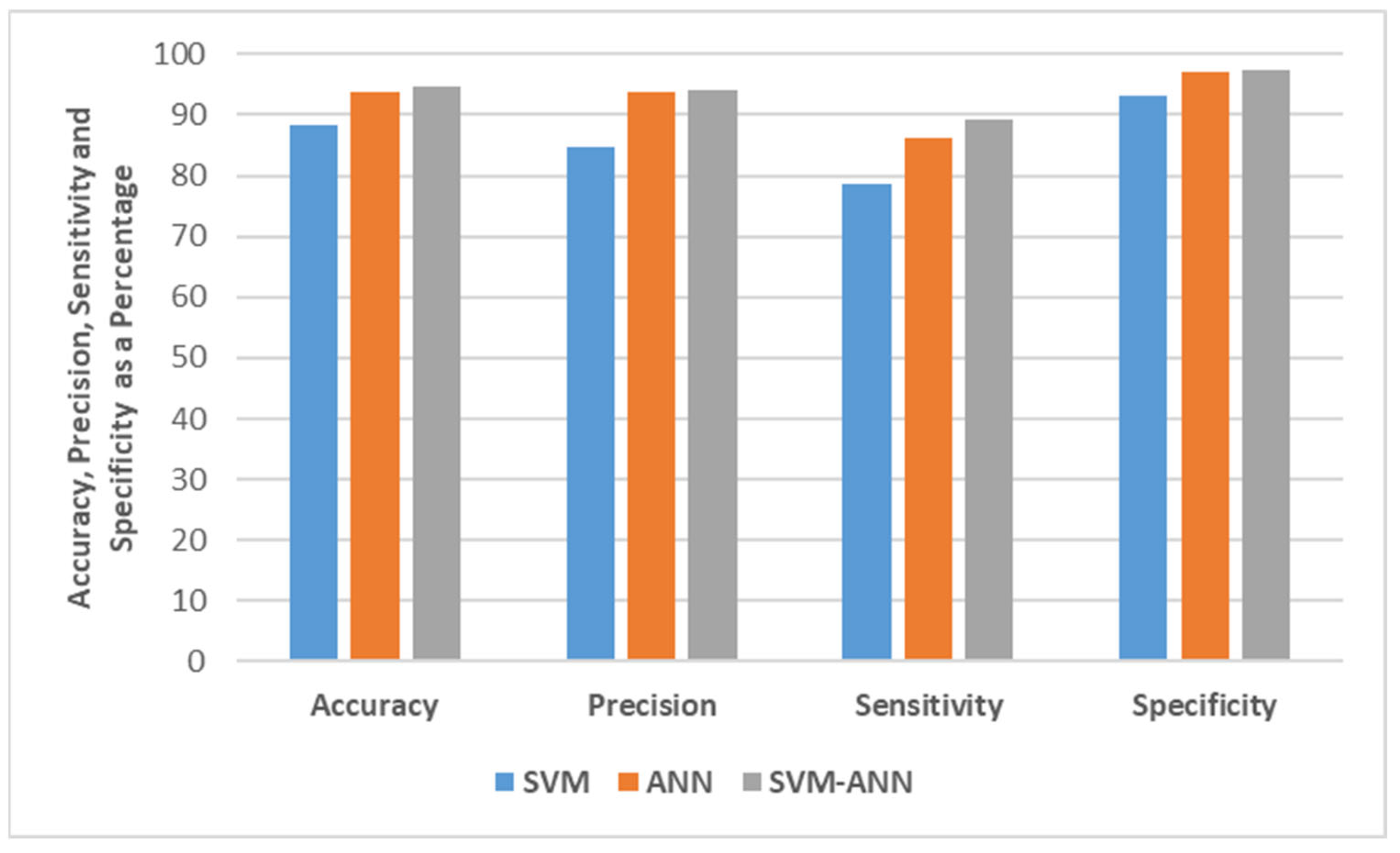
| Evaluation Matrix | SVM | ANN | Fusion of SVM-ANN |
|---|---|---|---|
| Accuracy | 88.30% | 93.63% | 94.67% |
| Specificity | 93.02% | 97.20% | 97.32% |
| Sensitivity | 78.62% | 86.28% | 89.23% |
| Precision | 84.58% | 93.77% | 94.19% |
| Miss rate | 11.70% | 6.37% | 5.33% |
| False Positive Ratio (FPR) | 0.06 | 0.02 | 0.02 |
| False Negative Ratio (FNR) | 0.21 | 0.13 | 0.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nadeem, M.W.; Goh, H.G.; Ponnusamy, V.; Andonovic, I.; Khan, M.A.; Hussain, M. A Fusion-Based Machine Learning Approach for the Prediction of the Onset of Diabetes. Healthcare 2021, 9, 1393. https://doi.org/10.3390/healthcare9101393
Nadeem MW, Goh HG, Ponnusamy V, Andonovic I, Khan MA, Hussain M. A Fusion-Based Machine Learning Approach for the Prediction of the Onset of Diabetes. Healthcare. 2021; 9(10):1393. https://doi.org/10.3390/healthcare9101393
Chicago/Turabian StyleNadeem, Muhammad Waqas, Hock Guan Goh, Vasaki Ponnusamy, Ivan Andonovic, Muhammad Adnan Khan, and Muzammil Hussain. 2021. "A Fusion-Based Machine Learning Approach for the Prediction of the Onset of Diabetes" Healthcare 9, no. 10: 1393. https://doi.org/10.3390/healthcare9101393
APA StyleNadeem, M. W., Goh, H. G., Ponnusamy, V., Andonovic, I., Khan, M. A., & Hussain, M. (2021). A Fusion-Based Machine Learning Approach for the Prediction of the Onset of Diabetes. Healthcare, 9(10), 1393. https://doi.org/10.3390/healthcare9101393