
Performance of Machine Learning Classifiers in Classifying Stunting among Under-Five Children in Zambia

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Materials and Methods
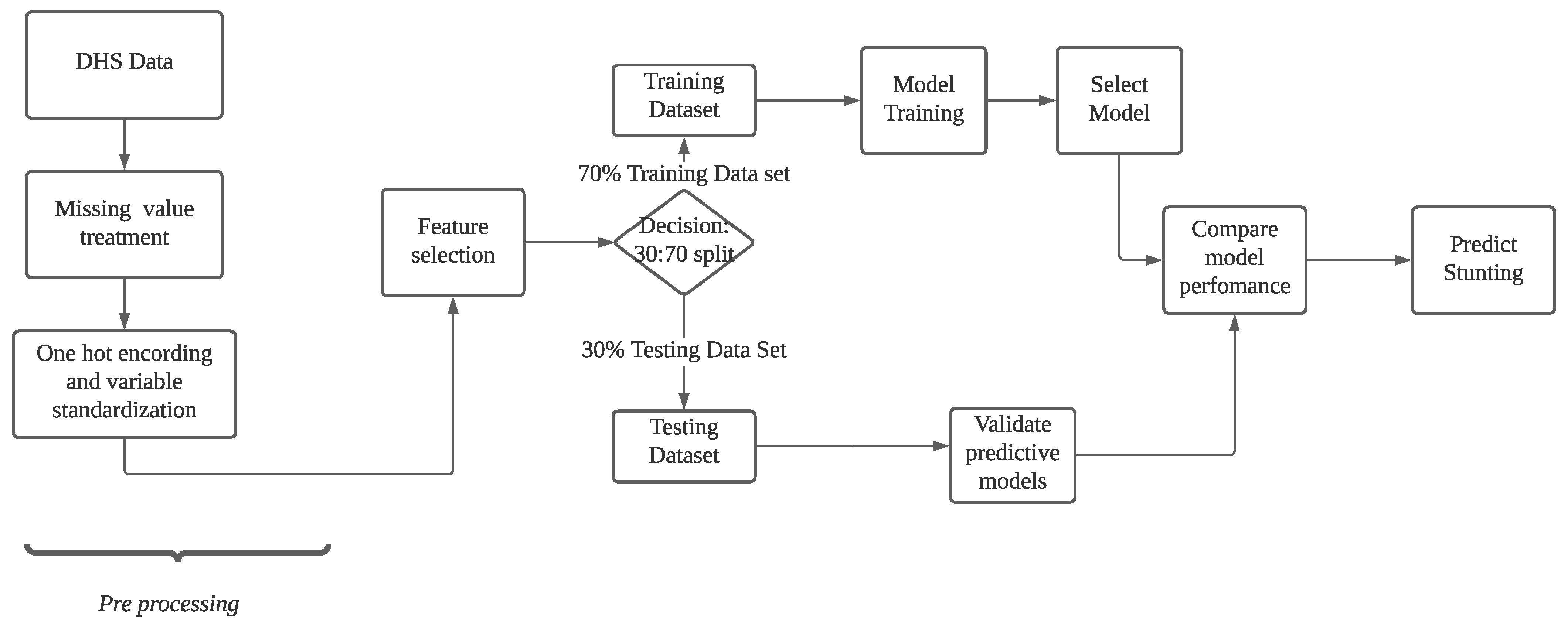
2.1. Data Source and Research Workflow
2.2. Pre-Processing
2.3. Feature Selection
2.4. Model Training
2.4.1. Logistic Regression
2.4.2. Random Forest
2.4.3. Naïve Bayesian (NB)
2.4.4. Support Vector Machine
2.4.5. XG Boost
2.5. Model Performance Evaluation
3. Results
3.1. Characteristics of Participants
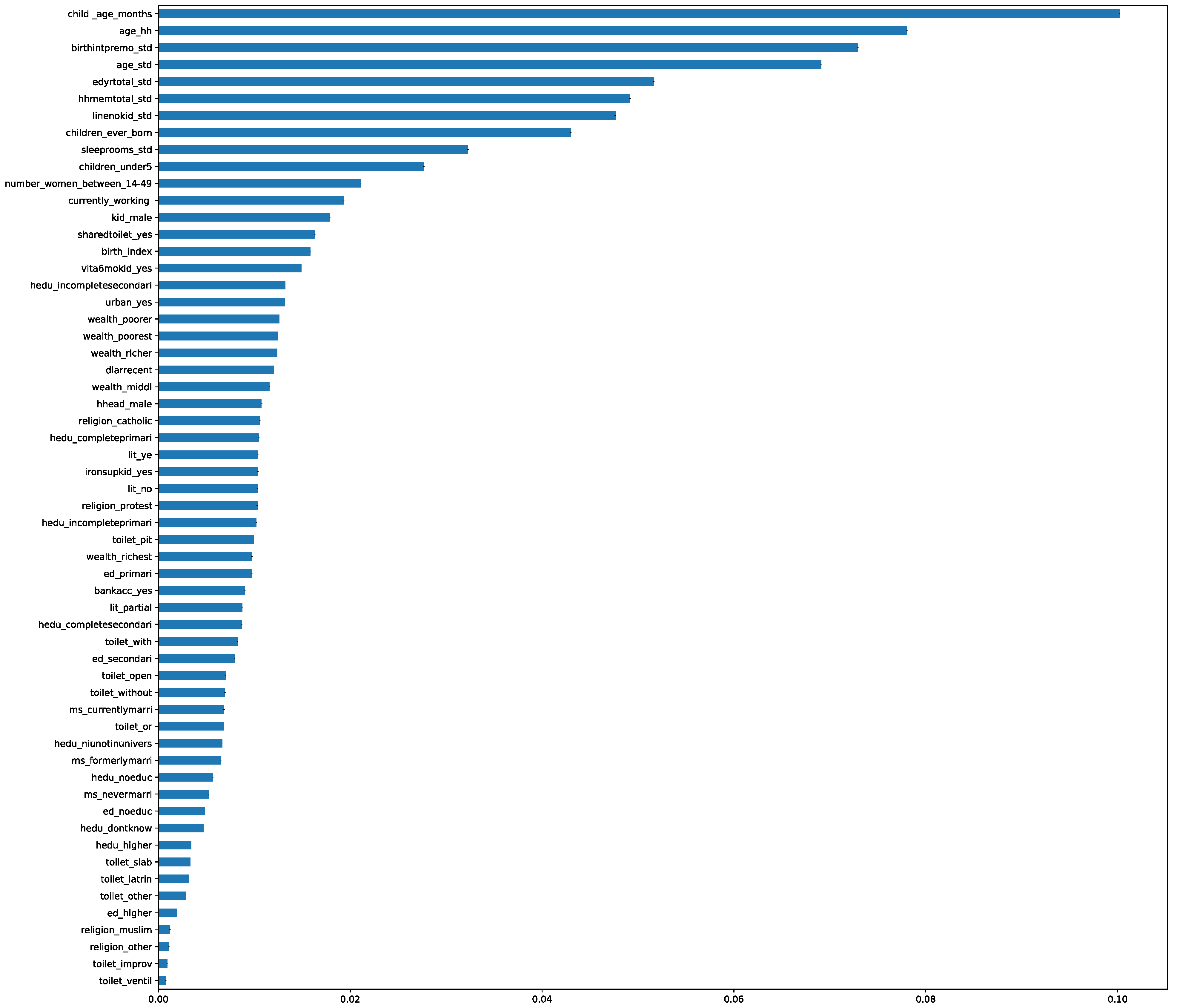
3.2. Features Selected Using Random Forest Feature Selection
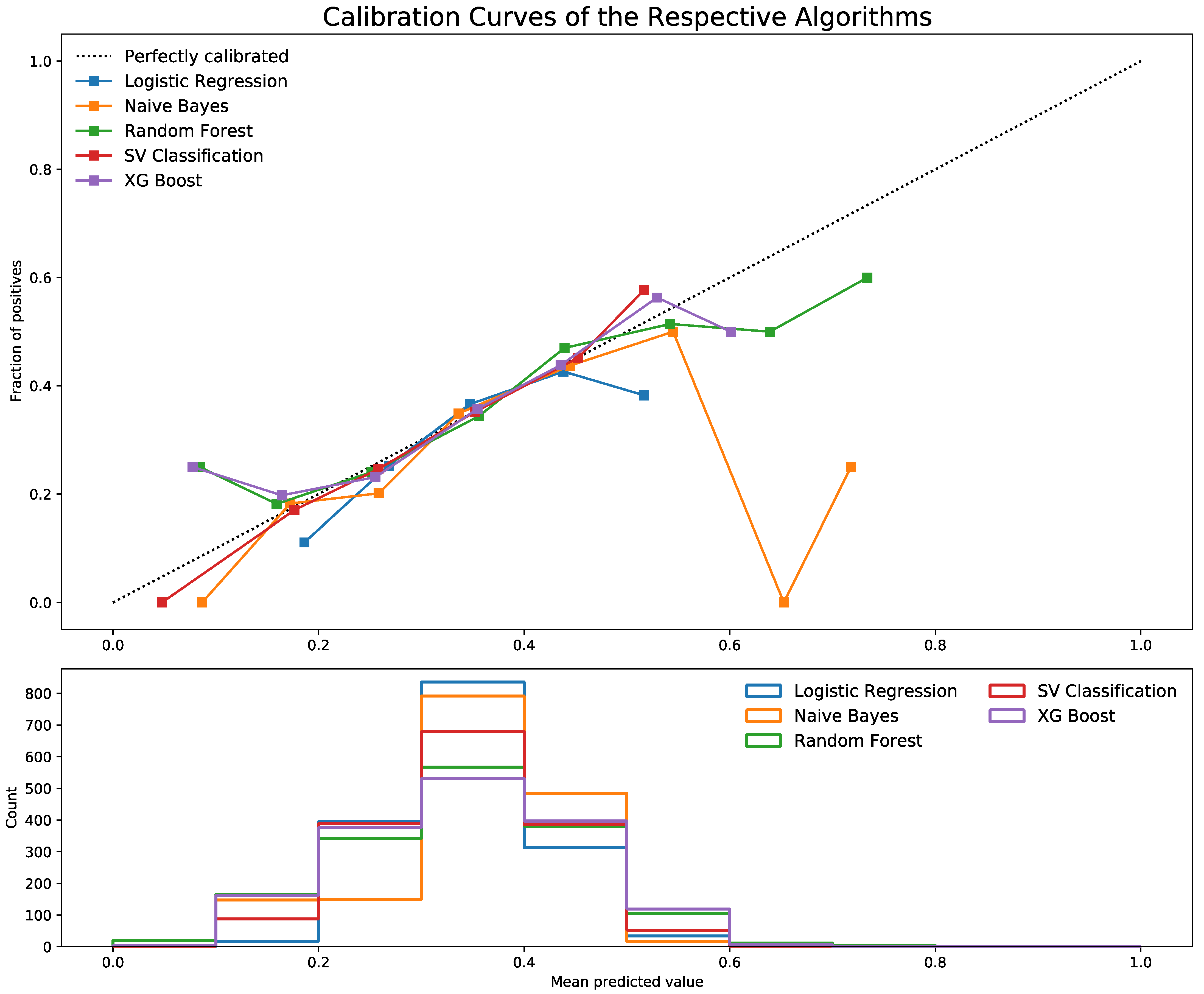
3.3. Comparison of Efficiency of Machine Learning Algorithm
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Levels and Trends in Child Malnutrition: Geneva, 2021; UNICEF: New York, NY, USA, 2021; ISBN 9789240025257. [Google Scholar]
- World Health Organization. Levels and Trends in Child Malnutrition: Geneva, 2020; UNICEF: New York, NY, USA, 2020; ISBN 0259238X. [Google Scholar]
- Quamme, S.H.; Iversen, P.O. Prevalence of child stunting in Sub-Saharan Africa and its risk factors. Clin. Nutr. Open Sci. 2022, 42, 49–61. [Google Scholar] [CrossRef]
- Zambia Statistics Agency; Ministry of Health (MOH) [Zambia]. Zambia Demographic and Health Survey 2018; University Teaching Hospital Virology Laboratory: Lusaka, Zambia; ICF: Rockville, ML, USA, 2019. [Google Scholar]
- De Onis, M.; Borghi, E.; Arimond, M.; Webb, P.; Croft, T.; Saha, K.; De-Regil, L.M.; Thuita, F.; Heidkamp, R.; Krasevec, J.; et al. Prevalence thresholds for wasting, overweight and stunting in children under 5 years. Public Health Nutr. 2019, 22, 175–179. [Google Scholar] [CrossRef] [Green Version]
- Markowitz, D.L.; Cosminsky, S. Overweight and stunting in migrant Hispanic children in the USA. Econ. Hum. Biol. 2005, 3, 215–240. [Google Scholar] [CrossRef]
- Fanzo, J.; Hawkes, C.; Udomkesmalee, E.; Afshin, A.; Allemandi, L.; Assery, O.; Baker, P.; Battersby, J.; Bhutta, Z.; Chen, K. Global Nutrition Report: Shining a Light to Spur Action on Nutrition; Development Initiatives Poverty Research Ltd.: Bristal, UK, 2018; ISBN 9780896295643. [Google Scholar]
- Myatt, M.; Khara, T.; Schoenbuchner, S.; Pietzsch, S.; Dolan, C.; Lelijveld, N. Children who are both wasted and stunted are also underweight and have a high risk of death: A descriptive epidemiology of multiple anthropometric deficits using data from 51 countries. Arch. Public Health 2018, 76, 28. [Google Scholar] [CrossRef] [Green Version]
- Ong, K.K.; Hardy, R.; Shah, I.; Kuh, D. Childhood stunting and mortality between 36 and 64 years: The british 1946 birth cohort study. J. Clin. Endocrinol. Metab. 2013, 98, 2070–2077. [Google Scholar] [CrossRef] [Green Version]
- Dewey, K.G.; Begum, K. Long-term consequences of stunting in early life. Matern. Child Nutr. 2011, 7, 5–18. [Google Scholar] [CrossRef]
- Mzumara, B.; Bwembya, P.; Halwiindi, H.; Mugode, R.; Banda, J. Factors associated with stunting among children below five years of age in Zambia: Evidence from the 2014 Zambia demographic and health survey. BMC Nutr. 2018, 4, 51. [Google Scholar] [CrossRef] [Green Version]
- Rakotomanana, H.; Gates, G.E.; Hildebrand, D.; Stoecker, B.J. Determinants of stunting in children under 5 years in Madagascar. Matern. Child Nutr. 2017, 13, e12409. [Google Scholar] [CrossRef]
- Das, S.; Gulshan, J. Different forms of malnutrition among under five children in Bangladesh: A cross sectional study on prevalence and determinants. BMC Nutr. 2017, 3, 1. [Google Scholar] [CrossRef] [Green Version]
- Rajula, H.S.R.; Verlato, G.; Manchia, M.; Antonucci, N.; Fanos, V. Comparison of conventional statistical methods with machine learning in medicine: Diagnosis, drug development, and treatment. Medicina 2020, 56, 455. [Google Scholar] [CrossRef]
- Iniesta, R.; Stahl, D.; McGuffin, P. Machine learning, statistical learning and the future of biological research in psychiatry. Psychol. Med. 2016, 46, 2455–2465. [Google Scholar] [CrossRef] [Green Version]
- Shahriar, M.; Iqubal, M.S.; Mitra, S.; Das, A.K. A deep learning approach to predict malnutrition status of 0-59 month’s older children in Bangladesh. In Proceedings of the 2019 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), Bali, Indonesia, 1–3 July 2019; pp. 145–149. [Google Scholar] [CrossRef]
- Jin, Z.; Shang, J.; Zhu, Q.; Ling, C.; Xie, W.; Qiang, B. RFRSF: Employee Turnover Prediction Based on Random Forests and Survival Analysis. In Web Information Systems Engineering—WISE 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; 12343 LNCS; pp. 503–515. [Google Scholar] [CrossRef]
- Markos, Z.; Doyore, F.; Yifiru, M.; Haidar, J. Predicting Under Nutrition Status of Under-Five Children Using Data Mining Techniques: The Case of 2011 Ethiopian Demographic and Health Survey. J. Health Med. Inform. 2014, 5, 1000152. [Google Scholar] [CrossRef] [Green Version]
- Talukder, A.; Ahammed, B. Machine learning algorithms for predicting malnutrition among under-five children in Bangladesh. Nutrition 2020, 78, 110861. [Google Scholar] [CrossRef]
- Bitew, F.H.; Sparks, C.S.; Nyarko, S.H. Machine learning algorithms for predicting undernutrition among under-five children in Ethiopia. Public Health Nutr. 2021, 25, 269–280. [Google Scholar] [CrossRef]
- Boyle, E.H.; King, M.; Sobek, M. IPUMS-Demographic and Health Surveys: Version 8 [dataset]; IPUMS: Minneapolis, MN, USA; ICF: Rockville, ML, USA, 2020. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. Scikit-Learn. Mach. Learn. Python 2011, 12, 282. [Google Scholar]
- Lee, W. Python® Machine Learning, 1st ed.; John Wiley & Sons, Inc.: Indianapolis, IN, USA, 2019; ISBN 978-1-119-54563-7. [Google Scholar]
- Cox, D.R. The Regression Analysis of Binary Sequences. J. R. Stat. Soc. Ser. B 1958, 20, 215–232. [Google Scholar] [CrossRef]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. AAAI-98 Workshop Learn. Text Categ. 1998, 752, 41–48. [Google Scholar]
- Zhang, D. Bayesian Classification. In Fundamentals of Image Data Mining; Texts in Computer Science; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Pisner, D.A.; Schnyer, D.M. Support Vector Machine; Elsevier Inc.: London, UK, 2019; ISBN 9780128157398. [Google Scholar] [CrossRef]
- Lewes, G.H. Support Vector Machines for Classification. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Awad, M., Khanna, R., Eds.; Springer: Cham, Switzerland, 2015; pp. 39–66. [Google Scholar] [CrossRef]
- Friedman, J.; Tibshirani, R.; Hastie, T. Additive logistic regression: A statistical view of boosting (With discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Nokeri, T.C. Data Science Solutions with Python; Apress: Pretoria, South Africa, 2022; ISBN 978-1-4842-7761-4. [Google Scholar]
- Sheridan, R.P.; Wang, W.M.; Liaw, A.; Ma, J.; Gifford, E.M. Extreme Gradient Boosting as a Method for Quantitative Structure-Activity Relationships. J. Chem. Inf. Model. 2016, 56, 2353–2360. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. Predicting good probabilities with supervised learning. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 4943–4947. [Google Scholar] [CrossRef]
- Python Software Foundation. Python Language Reference. Available online: http://www.python.org (accessed on 23 June 2020).
- Mediani, H.S. Predictors of Stunting Among Children Under Five Year of Age in Indonesia: A Scoping Review. Glob. J. Health Sci. 2020, 12, 83. [Google Scholar] [CrossRef]
- Bwalya, B.B.; Lemba, M.; Mapoma, C.C.; Mutombo, N. Factors Associated with Stunting among Children Aged 6–23 Months in Zambian: Evidence from the 2007 Zambia Demographic and Health Survey. Int. J. Adv. Nutr. Health Sci. 2015, 3, 116–131. [Google Scholar] [CrossRef] [Green Version]
- Perumal, N.; Bassani, D.G.; Roth, D.E. Use and misuse of stunting as a measure of child health. J. Nutr. 2018, 148, 311–315. [Google Scholar] [CrossRef] [Green Version]
- Mhasawade, V.; Zhao, Y.; Chunara, R. Machine learning and algorithmic fairness in public and population health. Nat. Mach. Intell. 2021, 3, 659–666. [Google Scholar] [CrossRef]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Characteristics | Number of Children (% of Total) | Stunted, n (%) | p-Value |
|---|---|---|---|
| Child’s age | |||
| 12 months | 1546 (22.7) | 350 (22.6) | <0.001 |
| >12 months | 5253 (77.3) | 1977 (37.6) | |
| Gender | |||
| Male | 3421 (50.3) | 1075 (31.4) | <0.001 |
| Female | 3378 (49.7) | 1252 (37.1) | |
| Mother’s Age (years) | |||
| 15–24 | 1938 (28.5) | 697 (36) | 0.088 |
| 25–34 | 3181 (46.8) | 1084 (34.1) | |
| 35–49 | 1680 (24.7) | 546 (32.5) | |
| Region | |||
| Urban | 4875 (71.7) | 1734 (35.6) | <0.001 |
| Rural | 1924 (28.3) | 593 (30.8) | |
| Mother’s Education | |||
| No formal education | 738 (10.9) | 282 (38.2) | <0.001 |
| Primary | 3722 (54.7) | 1390 (37.3) | |
| Secondary | 2045 (30.1) | 615 (30.1) | |
| Higher | 294 (4.3) | 40 (13.6) | |
| Mothers Current work | |||
| No | 3505 (51.6) | 1172 (33.4) | 0.158 |
| Yes | 3294 (48.4) | 1155 (35.1) | |
| Wealth Index | |||
| Poor | 3261 (48) | 1250 (38.3) | <0.001 |
| Middle | 1308 (19.2) | 453 (34.6) | |
| Richer | 2230 (32.8) | 624 (28) | |
| Religion | |||
| Muslim | 39 (0.6) | 17 (43.6) | 0.183 |
| Catholic | 1093 (16.1) | 399 (36.5) | |
| Protestant | 5603 (82.4) | 1891 (33.7) | |
| Other | 64 (0.9) | 20 (31.3) | |
| Toilet type | |||
| Unhygienic | 4265 (62.7) | 1428 (33.5) | 0.094 |
| Hygienic | 2534 (37.3) | 899 (35.5) | |
| Total | 6799 (100) | 2327 (34.2) |
| Model | Train F1 | Test F1 | Train Cohen’s Kappa | Test Cohen’s Kappa | Train PR-AUC | Test PR-AUC | Train Accuracy | Test Accuracy |
|---|---|---|---|---|---|---|---|---|
| Logistic Regression | 0.5298 | 0.5411 | 0.0797 | 0.0833 | 0.3728 | 0.3858 | 0.4471 | 0.4592 |
| Random Forest | 0.717 | 0.4826 | 0.5535 | 0.178 | 0.5992 | 0.4134 | 0.7921 | 0.6162 |
| SV Classification | 0.6083 | 0.523 | 0.3106 | 0.1486 | 0.4611 | 0.4051 | 0.6402 | 0.5583 |
| XG Boost | 0.6006 | 0.5381 | 0.3019 | 0.188 | 0.4566 | 0.4192 | 0.6385 | 0.5851 |
| Model | Precision Negative | Precision Positive | Average Precision | Recall Negative | Recall Positive | Average Recall |
|---|---|---|---|---|---|---|
| Logistic Regression | 0.78 | 0.39 | 0.585 | 0.22 | 0.89 | 0.555 |
| Random Forest | 0.71 | 0.47 | 0.59 | 0.68 | 0.5 | 0.59 |
| SV Classification | 0.73 | 0.43 | 0.58 | 0.49 | 0.67 | 0.58 |
| XG Boost | 0.75 | 0.45 | 0.6 | 0.54 | 0.67 | 0.605 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chilyabanyama, O.N.; Chilengi, R.; Simuyandi, M.; Chisenga, C.C.; Chirwa, M.; Hamusonde, K.; Saroj, R.K.; Iqbal, N.T.; Ngaruye, I.; Bosomprah, S. Performance of Machine Learning Classifiers in Classifying Stunting among Under-Five Children in Zambia. Children 2022, 9, 1082. https://doi.org/10.3390/children9071082
Chilyabanyama ON, Chilengi R, Simuyandi M, Chisenga CC, Chirwa M, Hamusonde K, Saroj RK, Iqbal NT, Ngaruye I, Bosomprah S. Performance of Machine Learning Classifiers in Classifying Stunting among Under-Five Children in Zambia. Children. 2022; 9(7):1082. https://doi.org/10.3390/children9071082
Chicago/Turabian StyleChilyabanyama, Obvious Nchimunya, Roma Chilengi, Michelo Simuyandi, Caroline C. Chisenga, Masuzyo Chirwa, Kalongo Hamusonde, Rakesh Kumar Saroj, Najeeha Talat Iqbal, Innocent Ngaruye, and Samuel Bosomprah. 2022. "Performance of Machine Learning Classifiers in Classifying Stunting among Under-Five Children in Zambia" Children 9, no. 7: 1082. https://doi.org/10.3390/children9071082
APA StyleChilyabanyama, O. N., Chilengi, R., Simuyandi, M., Chisenga, C. C., Chirwa, M., Hamusonde, K., Saroj, R. K., Iqbal, N. T., Ngaruye, I., & Bosomprah, S. (2022). Performance of Machine Learning Classifiers in Classifying Stunting among Under-Five Children in Zambia. Children, 9(7), 1082. https://doi.org/10.3390/children9071082