

Scenario Generation for Market Risk Models Using Generative Neural Networks

Abstract
:1. Introduction
- Expand scenario generation by a GAN to a complete market risk calculation for Solvency 2 purposes in insurance companies;
- Compare the results of a GAN-based ESG to ESG approaches implemented in regulatory-approved market risk models in Europe.
2. Background
2.1. Market Risk Calculation under Solvency 2
- The underlying data in the financial market are publicly available and equal for all insurers;
- Market risk forms a major part of the SCR of an insurance company (EIOPA (2021b, p. 22), which states that market risk accounts for 53% of the net solvency capital requirement before diversification benefits; this varies between life (59%) and non-life (43%) insurers);
- A comprehensive benchmark exercise, called “market and credit risk comparison study” MCRCS conducted by EIOPA, is available for a comparison of the results.
2.2. Introduction to the MCRCS Study
- Asset-only benchmark portfolios: BMP1, BMP2, …, BMP10;
- Liability-only benchmark portfolios: L1 and L2;
- Combined portfolios: BMP1+L1, BMP3+L1, BMP7+L1, BMP9+L1, BMP10+L1, BMP1+L2, BMP3+L2, BMP7+L2, BMP9+L2 and BMP10+L2.
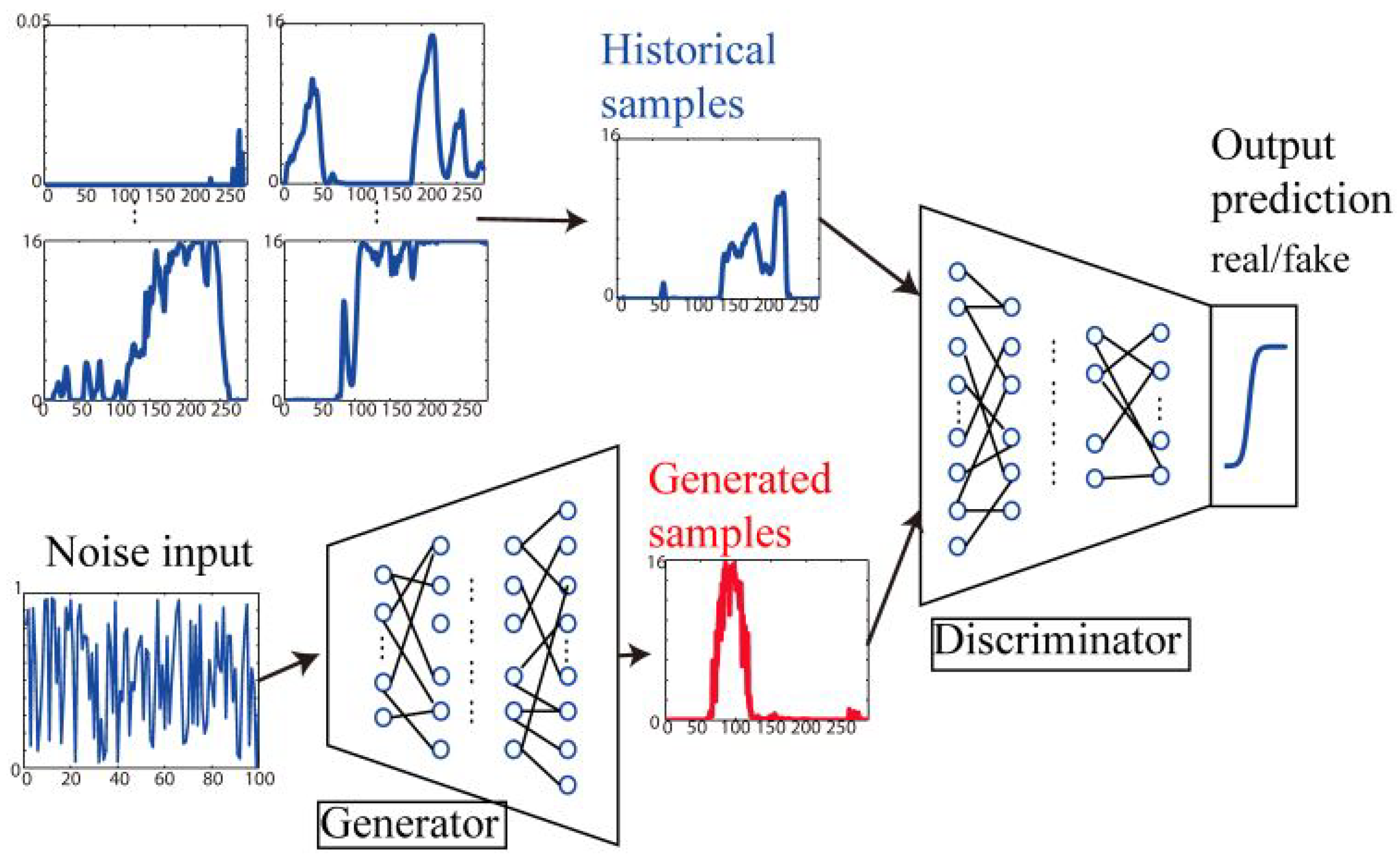
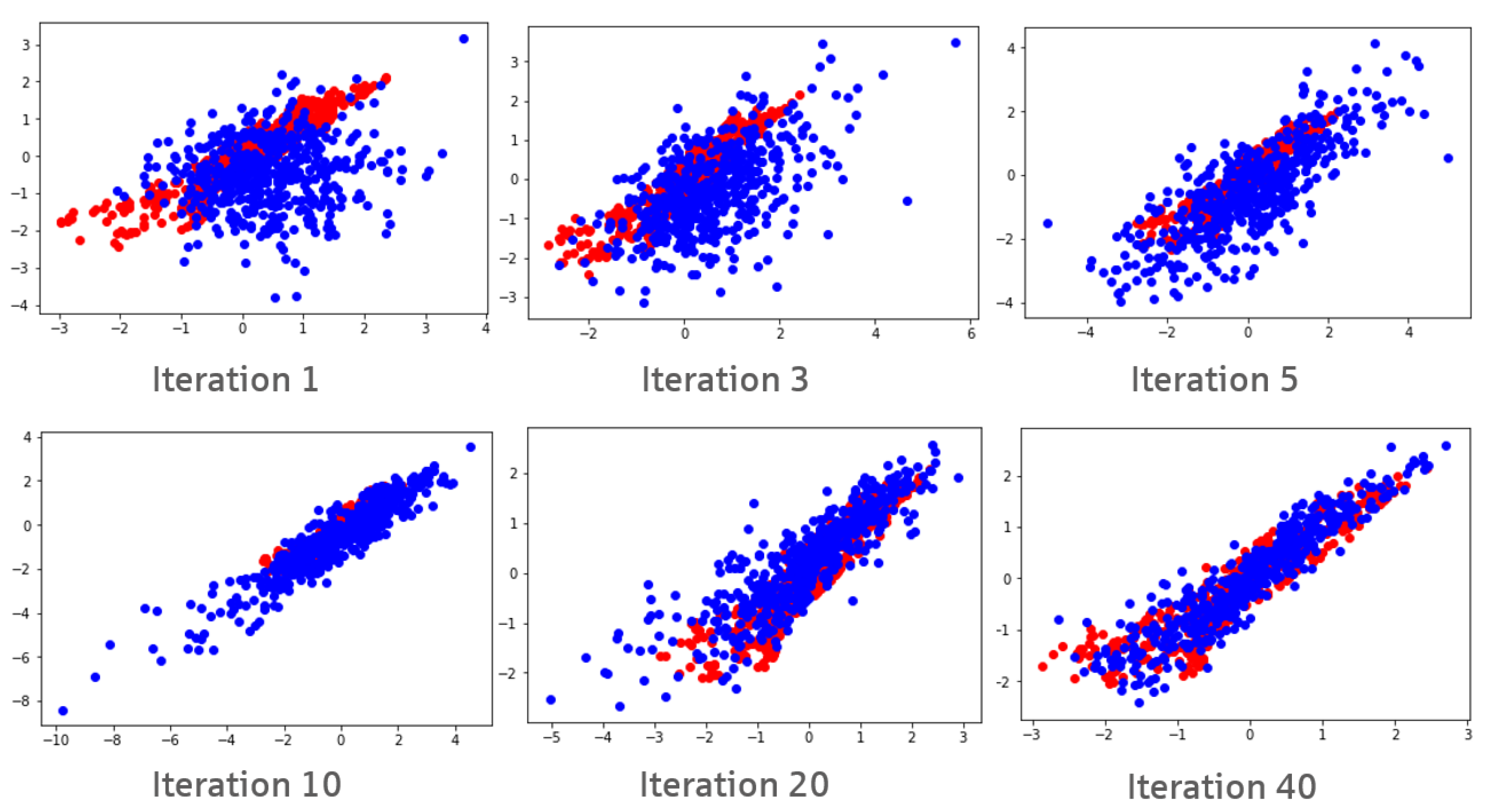
2.3. Generative Adversarial Networks
| Algorithm 1 Algorithm for GAN training with SGD (stochastic gradient descent) as an optimizer; see Goodfellow et al. (2014, Chapter 4, Algorithm 1) |
| The discriminator is trained k times more often than the generator, the dimension of the latent space Z is , is the batch size. All are hyperparameters of the GAN. The learning rates of the SGD algorithm are and .
|
3. Results of a GAN-Based Internal Model
3.1. Workflow of a GAN-Based Internal Model
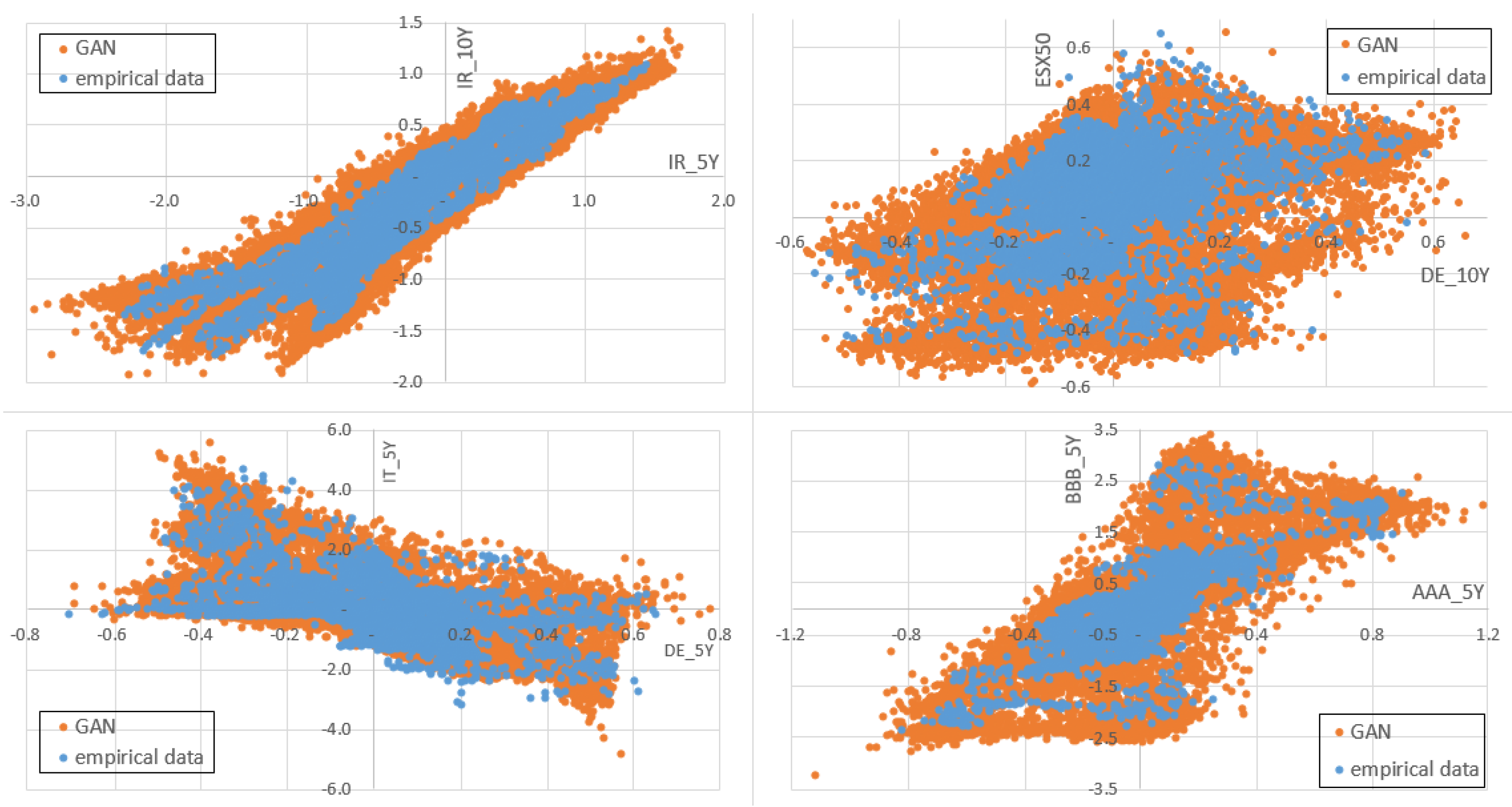
3.2. Comparison of GAN Results with the Results of the MCRCS Study
3.3. Comparison on Risk-Factor Level
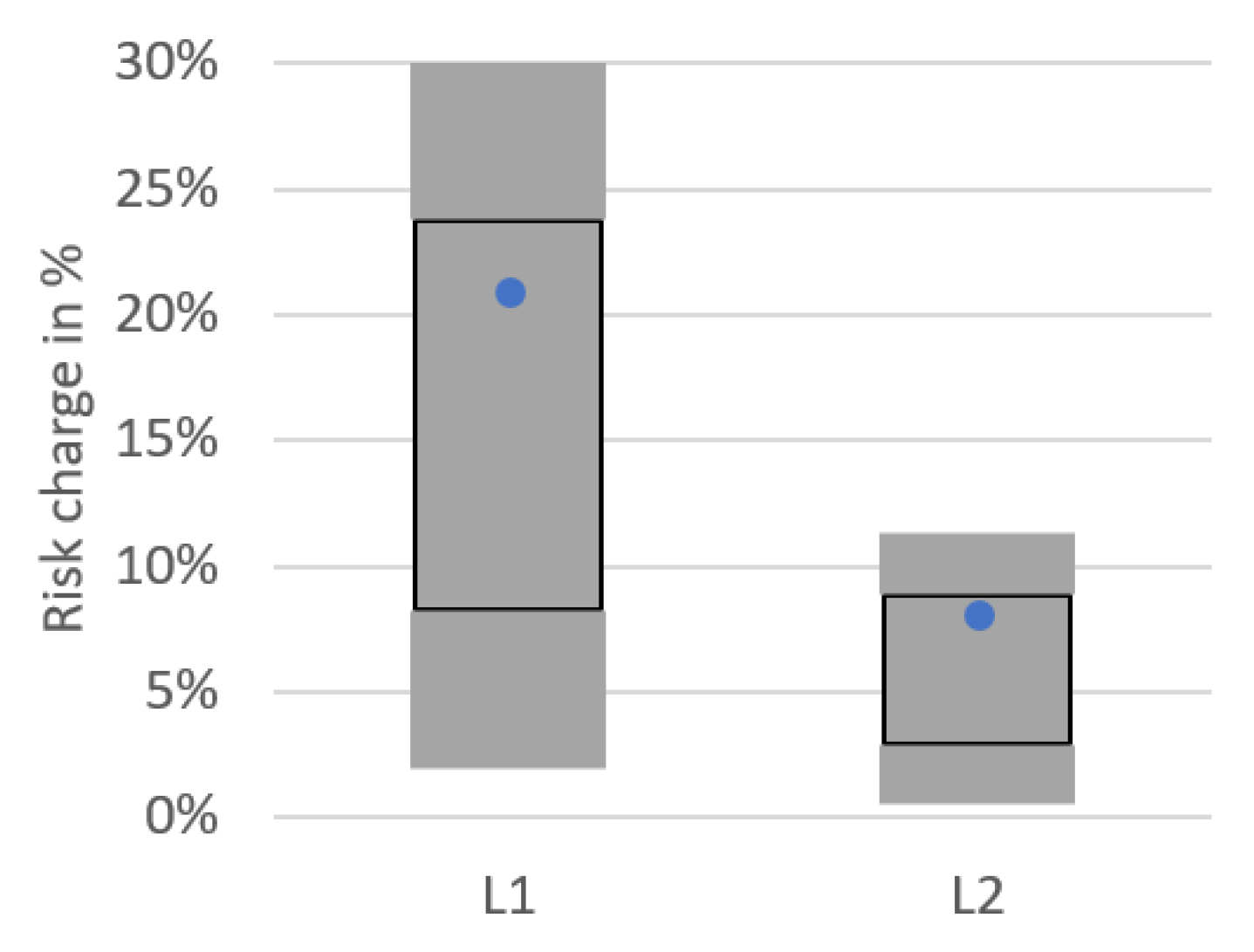
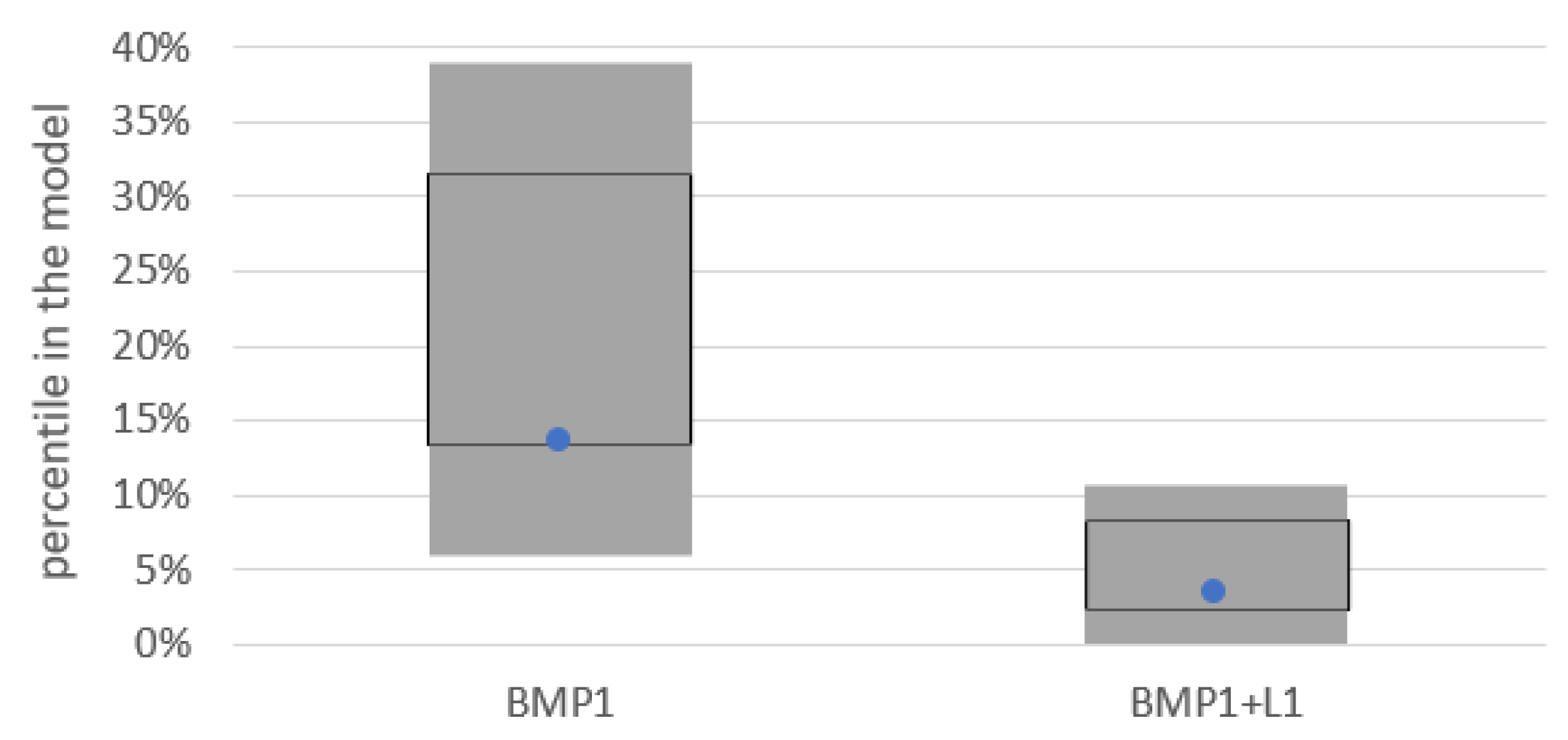
3.4. Comparison on the Portfolio Level
3.5. Comparison of the COVID-19 Backtesting Results
3.6. Comparison of Joint Quantile Exceedance Results
3.7. Stability of GAN Results
4. Methodology and Data
4.1. Data Selection
4.2. Data Preparation
4.3. Implementation of a GAN-Based ESG
- 4 layers for discriminator and generator;
- 400 neurons per layer in the discriminator and 200 in the generator;
- training iterations for the generator in each discriminator training;
- Batch size is ;
- Dimension of the latent space is 200, and the distribution of Z is a multivariate normal with mean = 0 and std = ;
- Initialization of the generator and discriminator using multivariate normal distribution with mean = 0 and std = ;
- We use LeakyReLu as activation functions except for the output layers, which use sigmoid (for discriminator) and linear (for generator) activation functions. We use the Adam optimizer and regulation technique batch normalization after each hidden layer in the network. The loss function is binary crossentropy.
4.4. Valuation of Financial Instruments and Portfolio Aggregation
- (1).
- Zero-coupon bond valuation
- (2).
- Equity and property instrument valuation
- (3).
- Valuation of the liabilities
- (4).
- Portfolio aggregation
5. Conclusions and Discussion of Results
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Table of Risk Factors and Data Sources Used for the MCRCS Study

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Asset Class | Subtype | Maturity | Bloomberg Ticker | CQV, 0.5perc. | CQV, 99.5perc. |
|---|---|---|---|---|---|
| Government bond | Austria | 5 years | GTATS5Y Govt | 9.2% | 4.8% |
| Austria | 10 years | GTATS10Y Govt | 4.3% | 3.2% | |
| Belgium | 5 years | GTBEF5Y Govt | 4.1% | 4.0% | |
| Belgium | 10 years | GTBEF10Y Govt | 5.5% | 5.7% | |
| Germany | 5 years | GTDEM5Y Govt | 1.4% | 4.8% | |
| Germany | 10 years | GTDEM10Y Govt | 3.3% | 4.5% | |
| Spain | 5 years | GTESP5Y Govt | 10.0% | 1.9% | |
| Spain | 10 years | GTESP10Y Govt | 2.5% | 4.0% | |
| France | 5 years | GTFRF5Y Govt | 2.3% | 9.5% | |
| France | 10 years | GTFRF10Y Govt | 3.6% | 4.8% | |
| Ireland | 5 years | GIGB5Y Index | 2.7% | 4.0% | |
| Ireland | 10 years | GIGB10Y Index | 2.2% | 7.8% | |
| Italy | 5 years | GTITL5Y Govt | 4.0% | 8.0% | |
| Italy | 10 years | GTITL10Y Govt | 2.0% | 2.7% | |
| Netherlands | 5 years | GTNLG5Y Govt | 4.8% | 1.4% | |
| Netherlands | 10 years | GTNLG10Y Govt | 3.1% | 6.5% | |
| Portugal | 5 years | GSPT5YR Index | 3.1% | 3.3% | |
| UK | 5 years | C1105Y Index | 5.6% | 4.3% | |
| US | 5 years | H15T5Y Index | 3.0% | 5.3% | |
| Covered bond | AA-rated issuer | 5 years | C9235Y Index | 2.6% | 4.3% |
| AA-rated issuer | 10 years | C92310Y Index | 3.2% | 4.3% | |
| Corporate bond | bond, rating AA | 5 years | C6675Y Index | 1.9% | 4.4% |
| bond, rating AA | 10 years | C66710Y Index | 2.8% | 1.6% | |
| bond, rating A | 5 years | C6705Y Index | 1.6% | 3.2% | |
| bond, rating A | 10 years | C67010Y Index | 3.5% | 2.5% | |
| bond, rating BBB | 5 years | C6735Y Index | 5.5% | 5.0% | |
| bond, rating BBB | 10 years | C67310Y Index | 4.9% | 3.4% | |
| high yield bonds | 5 years | ML HP00 Swap Spread | 1.4% | 4.4% | |
| Interest rates, risk-free | EUR | 1 year | S0045Z 1Y BLC2 Curncy | 1.9% | 0.5% |
| EUR | 3 years | S0045Z 3Y BLC2 Curncy | 2.6% | 2.0% | |
| EUR | 5 years | S0045Z 5Y BLC2 Curncy | 2.1% | 1.0% | |
| EUR | 7 years | S0045Z 7Y BLC2 Curncy | 3.5% | 1.0% | |
| EUR | 10 years | S0045Z 10Y BLC2 Curncy | 4.8% | 2.6% | |
| EUR | 15 years | S0045Z 15Y BLC2 Curncy | 4.4% | 3.2% | |
| EUR | 20 years | S0045Z 20Y BLC2 Curncy | 3.0% | 1.6% | |
| EUR | 25 years | S0045Z 25Y BLC2 Curncy | 2.2% | 3.3% | |
| EUR | 30 years | S0045Z 30Y BLC2 Curncy | 4.6% | 2.4% | |
| EUR | 40 years | S0045Z 40Y BLC2 Curncy | 4.4% | 2.5% | |
| EUR | 50 years | S0045Z 50Y BLC2 Curncy | 1.7% | 3.2% | |
| USD | 5 years | USSW5 Index | 1.4% | 2.2% | |
| GBP | 5 years | BPSW5 Index | 4.6% | 3.3% | |
| Equity | EuroStoxx50 | - | SX5T Index | 6.1% | 5.6% |
| MSCI Europe | - | MSDEE15N Index | 4.2% | 3.0% | |
| FTSE100 | - | TUKXG Index | 4.1% | 3.2% | |
| S&P500 | - | SPTR500N Index | 4.7% | 6.8% | |
| Real-estate | Europe, commercial | - | EXUK Index | 2.8% | 4.5% |
Appendix B. Table of Instruments Used for the MCRCS Study
| Instrument | Maturity | Risk Factors Used for Valuation |
|---|---|---|
| EUR risk-free interest rate | 1 year | EUR swap rate, 1 year |
| EUR risk-free interest rate | 3 years | EUR swap rate, 3 years |
| EUR risk-free interest rate | 5 years | EUR swap rate, 5 years |
| EUR risk-free interest rate | 7 years | EUR swap rate, 7 years |
| EUR risk-free interest rate | 10 years | EUR swap rate, 10 years |
| EUR risk-free interest rate | 15 years | EUR swap rate, 15 years |
| EUR risk-free interest rate | 20 years | EUR swap rate, 20 years |
| EUR risk-free interest rate | 25 years | EUR swap rate, 25 years |
| EUR risk-free interest rate | 30 years | EUR swap rate, 30 years |
| EUR risk-free interest rate | 40 years | EUR swap rate, 40 years |
| EUR risk-free interest rate | 50 years | EUR swap rate, 50 years |
| EUR risk-free interest rate | 60 years | EUR swap rate, 60 years |
| Austrian Sovereign bond | 5 years | EUR interest rate, 5 years & AT_Spread, 5 years |
| Austrian Sovereign bond | 10 years | EUR interest rate, 10 years & AT_Spread, 10 years |
| Austrian Sovereign bond | 20 years | EUR interest rate, 20 years & AT_Spread, 10 years |
| Belgium Sovereign bond | 5 years | EUR interest rate, 5 years & BE_Spread, 5 years |
| Belgium Sovereign bond | 10 years | EUR interest rate, 10 years & BE_Spread, 10 years |
| Belgium Sovereign bond | 20 years | EUR interest rate, 20 years & BE_Spread, 10 years |
| German Sovereign bond | 5 years | EUR interest rate, 5 years & DE_Spread, 5 years |
| German Sovereign bond | 10 years | EUR interest rate, 10 years & DE_Spread, 10 years |
| German Sovereign bond | 20 years | EUR interest rate, 20 years & DE_Spread, 10 years |
| Spain Sovereign bond | 5 years | EUR interest rate, 5 years & ES_Spread, 5 years |
| Spain Sovereign bond | 10 years | EUR interest rate, 10 years & ES_Spread, 10 years |
| Spain Sovereign bond | 20 years | EUR interest rate, 20 years & ES_Spread, 10 years |
| France Sovereign bond | 5 years | EUR interest rate, 5 years & FR_Spread, 5 years |
| France Sovereign bond | 10 years | EUR interest rate, 10 years & FR_Spread, 10 years |
| France Sovereign bond | 20 years | EUR interest rate, 20 years & FR_Spread, 10 years |
| Ireland Sovereign bond | 5 years | EUR interest rate, 5 years & IE_Spread, 5 years |
| Ireland Sovereign bond | 10 years | EUR interest rate, 10 years & IE_Spread, 10 years |
| Ireland Sovereign bond | 20 years | EUR interest rate, 20 years & IE_Spread, 10 years |
| Italia Sovereign bond | 5 years | EUR interest rate, 5 years & IT_Spread, 5 years |
| Italia Sovereign bond | 10 years | EUR interest rate, 10 years & IT_Spread, 10 years |
| Italia Sovereign bond | 20 years | EUR interest rate, 20 years & IT_Spread, 10 years |
| Netherlands Sovereign bond | 5 years | EUR interest rate, 5 years & NE_Spread, 5 years |
| Netherlands Sovereign bond | 10 years | EUR interest rate, 10 years & NE_Spread, 10 years |
| Netherlands Sovereign bond | 20 years | EUR interest rate, 20 years & NE_Spread, 10 years |
| Portugal Sovereign bond | 5 years | EUR interest rate, 5 years & PT_Spread, 5 years |
| UK Sovereign bond | 5 years | GBP interest rate, 5 years & UK_Spread, 5 years |
| US Sovereign bond | 5 years | USD interest rate, 5 years & US_Spread, 5 years |
| Bond issued by ESM | 10 years | EUR interest rate, 10 years & DE_Spread, 10 years |
| Covered bond rated AAA | 5 years | EUR interest rate, 5 years & COV_Spread, 5 years |
| Covered bond rated AAA | 10 years | EUR interest rate, 10 years & COV_Spread, 10 years |
| Financial bond, rated AAA | 5 years | EUR interest rate, 5 years & COV_Spread, 5 years |
| Financial bond, rated AAA | 10 years | EUR interest rate, 10 years & COV_Spread, 10 years |
| Financial bond, rated AA | 5 years | EUR interest rate, 5 years & AA_Spread, 5 years |
| Financial bond, rated AA | 10 years | EUR interest rate, 10 years & AA_Spread, 10 years |
| Financial bond, rated A | 5 years | EUR interest rate, 5 years & A_Spread, 5 years |
| Financial bond, rated A | 10 years | EUR interest rate, 10 years & A_Spread, 10 years |
| Financial bond, rated BBB | 5 years | EUR interest rate, 5 years & BBB_Spread, 5 years |
| Financial bond, rated BBB | 10 years | EUR interest rate, 10 years & BBB_Spread, 10 years |
| Financial bond, rated BB | 5 years | EUR interest rate, 5 years & HY_Spread, 5 years |
| Financial bond, rated BB | 10 years | EUR interest rate, 10 years & HY_Spread, 10 years |
| Non-Financial bond, rated AAA | 5 years | EUR interest rate, 5 years & COV_Spread, 5 years |
| Non-Financial bond, rated AAA | 10 years | EUR interest rate, 10 years & COV_Spread, 10 years |
| Non-Financial bond, rated AA | 5 years | EUR interest rate, 5 years & AA_Spread, 5 years |
| Non-Financial bond, rated AA | 10 years | EUR interest rate, 10 years & AA_Spread, 10 years |
| Non-Financial bond, rated A | 5 years | EUR interest rate, 5 years & A_Spread, 5 years |
| Non-Financial bond, rated A | 10 years | EUR interest rate, 10 years & A_Spread, 10 years |
| Non-Financial bond, rated BBB | 5 years | EUR interest rate, 5 years & BBB_Spread, 5 years |
| Non-Financial bond, rated BBB | 10 years | EUR interest rate, 10 years & BBB_Spread, 10 years |
| Non-Financial bond, rated BB | 5 years | EUR interest rate, 5 years & HY_Spread, 5 years |
| Non-Financial bond, rated BB | 10 years | EUR interest rate, 10 years & HY_Spread, 10 years |
| Equity Index, Eurostoxx 50 | - | Equity Index, Eurostoxx 50 |
| Equity Index, MSCI Europe | - | Equity Index, MSCI Europe |
| Equity Index, FTSE100 | - | Equity Index, FTSE100 |
| Equity Index, S&P500 | - | Equity Index, S&P500 |
| Residential real estate in Netherlands | - | Diversified European REIT index |
| Commercial real estate in France | - | Diversified European REIT index |
| Commercial real estate in Germany | - | Diversified European REIT index |
| Commercial real estate in UK | - | Diversified European REIT index |
| Commercial real estate in Italy | - | Diversified European REIT index |
- As most participants in the study, we do not distinguish between different types of corporate bond spreads, i.e., financial and non-financial corporates are modeled with the same data. As written in EIOPA (2021a, p. 24), this is a simplification used by two-thirds of participants.
- As for the required supranational paper issued by ESM (European Stability Mechanism), there is no long time series to be found, we use the approximation of the German spreads instead.
- There is no reliable daily data source for AAA and high yield bonds in Bloomberg. For AAA-rated bonds, as most participants in the study, we use the covered bond spreads, which are also rated AAA instead; see EIOPA (2021a, p. 24). The most frequent data for high yield bonds that we found can be derived from the Meryll Lynch spread index, which is a weekly index.
- For real estate, there is no direct transaction-based data available at high frequencies. The most frequent direct real-estate data are available on a monthly basis. We will therefore use an index representing Real Estate Investment Trusts (REITs) and stocks from Real Estate Holding and Development Companies. As there is no index to be found that is geography-specific for the real estate holdings in the study, we will use a diversified European index for all real estate instruments.
- As the liquidity of government bonds becomes thin with longer maturities, we use 10-year spreads for 10- and 20-year bonds in the study.
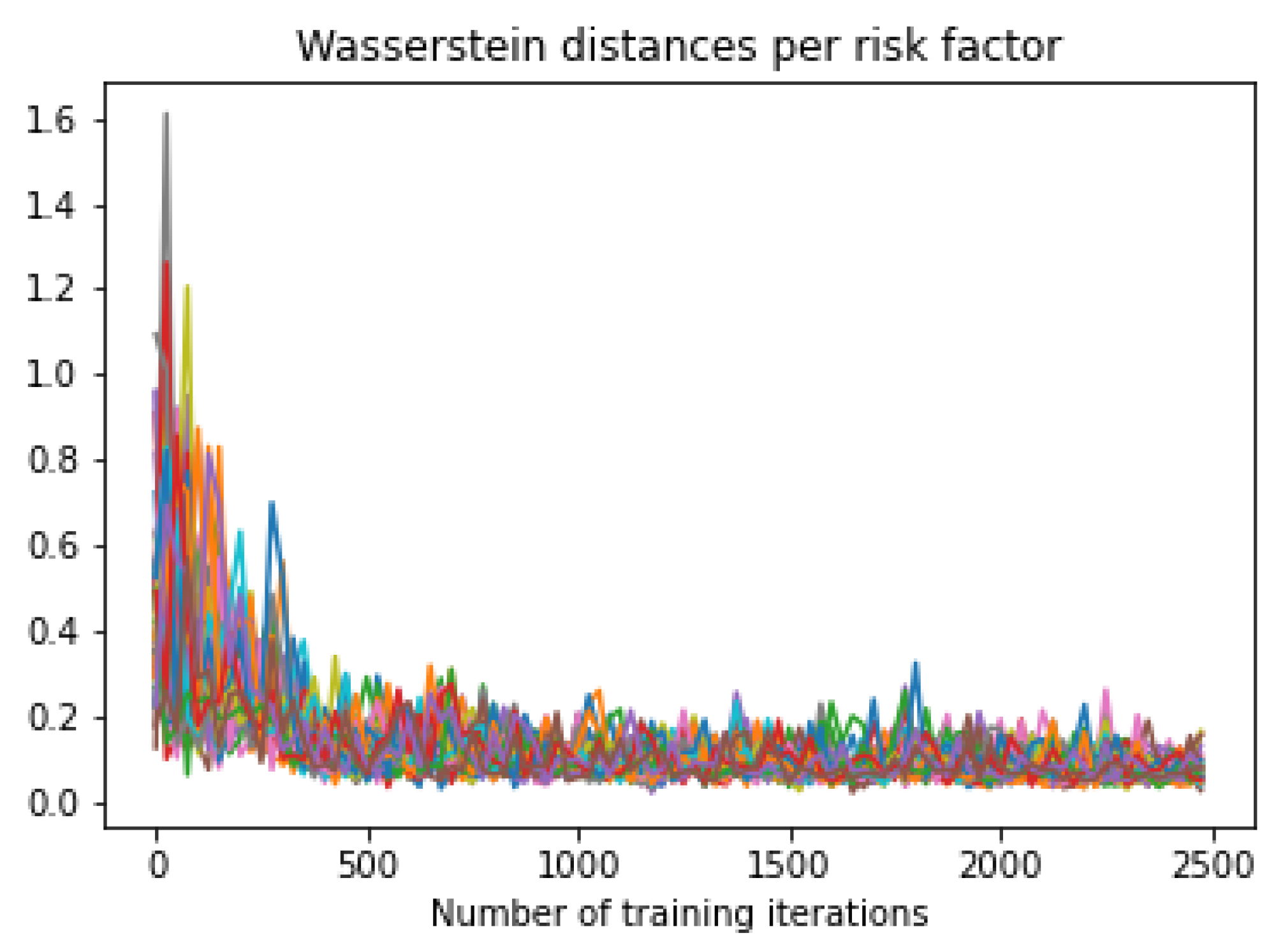
Appendix C. Optimization of GAN Architecture Using Wasserstein Distances
- The number of layers for generator and discriminator varying between 2, 4, 6 and 8;
- The number of neurons for generator and discriminator varying between 100, 200 and 400.
- Batch size is
- training iterations for the generator in each discriminator training;
- Dimension of the latent space is 200, and distribution of Z is multivariate normal with mean = 0 and std = 0.02;
- Initialization of generator and discriminator using multivariate normal distribution with mean = 0 and std = 0.02.
- We use LeakyReLu with as activation functions except for the output layers, which use Sigmoid (for discriminator) and linear (for generator) activation functions. Additionally, we apply the regulation technique batch normalization after each of the hidden layers in the network.
- We use the Adam optimizer with the parameters provided in Section 4.3 in Equation (2).
| Number of Layers in D/G | 2 | 4 | 6 | 8 |
|---|---|---|---|---|
| 2 | 0.143 | 0.252 | 0.636 | 0.799 |
| 4 | 1.036 | 0.118 | 0.235 | 0.435 |
| 6 | 0.947 | 0.172 | 0.197 | 0.281 |
| 8 | 0.807 | 0.188 | 0.171 | 0.178 |
| Number of Neurons per Layer in D/G | 100 | 200 | 400 |
|---|---|---|---|
| 100 | 0.180 | 0.117 | 0.125 |
| 200 | 0.185 | 0.118 | 0.108 |
| 400 | 0.197 | 0.116 | 0.124 |
References
- Aggarwal, Alankrita, Mamta Mittal, and Gopi Battineni. 2021. Generative adversarial network: An overview of theory and applications. International Journal of Information Management Data Insights 1: 100004. [Google Scholar] [CrossRef]
- Albrecht, Peter, and Raimond Maurer. 2016. Investment-und Risikomanagement: Modelle, Methoden, Anwendungen. Stuttgart: Schäffer-Poeschel. [Google Scholar]
- Bennemann, Christoph. 2011. Handbuch Solvency II: Von der Standardformel zum internen Modell, vom Governance-System zu den MaRisk VA. Stuttgart: Schäffer-Poeschel. [Google Scholar]
- Borji, Ali. 2019. Pros and cons of gan evaluation measures. Computer Vision and Image Understanding 179: 41–65. [Google Scholar] [CrossRef] [Green Version]
- Chen, Yize, Pan Li, and Baosen Zhang. 2018. Bayesian renewables scenario generation via deep generative networks. Paper presented at the 2018 52nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, March 21–23; pp. 1–6. [Google Scholar]
- Chollet, Francois. 2018. Deep Learning with Python. New York: Manning Publications. [Google Scholar]
- Cote, Marie-Pier, Brian Hartman, Olivier Mercier, Joshua Meyers, Jared Cummings, and Elijah Harmon. 2020. Synthesizing property & casualty ratemaking datasets using generative adversarial networks. arXiv arXiv:2008.06110. [Google Scholar]
- Danthine, Jean-Pierre. 2017. The interest rate unbound? Comparative Economic Studies 59: 129–48. [Google Scholar] [CrossRef]
- DAV (Deutsche Aktuarsvereinigung e.V.). 2015. Zwischenbericht zur Kalibrierung und Validierung spezieller ESG unter Solvency II. Ergebnisbericht des Ausschusses Investment der Deutschen Aktuarvereinigung e.V. Available online: https://aktuar.de/unsere-themen/fachgrundsaetze-oeffentlich/2015-11-09_DAV-Ergebnisbericht_Kalibrierung%20und%20Validierung%20spezieller%20ESG_Update.pdf (accessed on 26 April 2021).
- Denuit, Michel, Jan Dhaene, Marc Goovaerts, and Rob Kaas. 2006. Actuarial Theory for Dependent Risks: Measures, Orders and Models. Chichester: John Wiley & Sons. [Google Scholar]
- Deutsch, Hans-Peter. 2004. Derivate und Interne Modelle: Modernes Risikomanagement, 3rd ed. Stuttgart: Schäffer-Poeschel. [Google Scholar]
- Eckerli, Florian, and Joerg Osterrieder. 2021. Generative adversarial networks in finance: An overview. arXiv arXiv:2106.06364. [Google Scholar] [CrossRef]
- EIOPA. 2014. The Underlying Assumptions in the Standard Formula for the Solvency Capital Requirement Calculation. Available online: https://www.bafin.de/SharedDocs/Downloads/EN/Leitfaden/VA/dl_lf_solvency_annahmen_standardformel_scr_en.pdf (accessed on 26 April 2021).
- EIOPA. 2019. Technical Documentation of the Methodology to Derive Eiopas Risk-Free Interest Rate Term Structures. Available online: https://www.eiopa.europa.eu/sites/default/files/risk_free_interest_rate/12092019-technical_documentation.pdf (accessed on 26 April 2021).
- EIOPA. 2021a. YE2019 Comparative Study on Market & Credit Risk Modelling. Available online: https://www.eiopa.europa.eu/sites/default/files/publications/reports/2021-study-on-modelling-of-market-and-credit-risk-_mcrcs.pdf (accessed on 26 April 2021).
- EIOPA. 2021b. European Insurance Overview 2021. Available online: https://www.eiopa.europa.eu/sites/default/files/publications/reports/eiopa-21-591-european-insurance-overview-report.pdf (accessed on 26 April 2021).
- EIOPA MCRCS Project Group. 2020a. Specification of Financial Instruments and Benchmark Portfolios of the Year-End 2019 Edition of the Market and Credit Risk Modelling Comparative Study. Available online: https://www.eiopa.europa.eu/sites/default/files/toolsanddata/mcrcs_2019_instruments_and_bmp.xlsx (accessed on 26 April 2021).
- EIOPA MCRCS Project Group. 2020b. Market & Credit Risk Modelling Comparative Study (MCRCS), Year-End 2019 Edition: Instructions to Participating Undertakings for Filling out the Data Request. Available online: https://www.eiopa.europa.eu/sites/default/files/toolsanddata/mcrcs_year-end_2019_instructions_covidpostponed.pdf (accessed on 26 April 2021).
- European Commission. 2015. Commission delegated regulation (EU) 2015/35 of 10 October 2014 supplementing directive 2009/138/EC of the European parliament and of the council on the taking-up and pursuit of the business of insurance and reinsurance (Solvency II). Official Journal of European Union. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32015R0035&from=EN (accessed on 26 April 2021).
- Franco-Pedroso, Javier, Joaquin Gonzalez-Rodriguez, Jorge Cubero, Maria Planas, Rafael Cobo, and Fernando Pablos. 2019. Generating virtual scenarios of multivariate financial data for quantitative trading applications. The Journal of Financial Data Science 1: 55–77. [Google Scholar] [CrossRef]
- Fu, Rao, Jie Chen, Shutian Zeng, Yiping Zhuang, and Agus Sudjianto. 2019. Time series simulation by conditional generative adversarial net. arXiv arXiv:1904.11419. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, Ian. 2016. Nips 2016 tutorial: Generative adversarial networks. arXiv arXiv:1701.00160. [Google Scholar]
- Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial networks. Communications of the ACM 63: 139–44. [Google Scholar] [CrossRef]
- Grasselli, Matheus R., and Alexander Lipton. 2019. On the normality of negative interest rates. Review of Keynesian Economics 7: 201–19. [Google Scholar] [CrossRef]
- Gründl, Helmut, Mirko Kraft, Thomas Post, Roman N Schulze, Sabine Pelzer, and Sebastian Schlütter. 2019. Solvency II-Eine Einführung: Grundlagen der neuen Versicherungsaufsicht, 2nd ed. Karlsruhe: VVW GmbH. [Google Scholar]
- Hallin, Marc, Gilles Mordant, and Johan Segers. 2021. Multivariate goodness-of-fit tests based on wasserstein distance. Electronic Journal of Statistics 15: 1328–71. [Google Scholar] [CrossRef]
- Henry-Labordere, Pierre. 2019. Generative Models for Financial Data. Available at SSRN 3408007. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3408007 (accessed on 26 April 2021).
- Ho, Yaoshiang, and Samuel Wookey. 2019. The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling. IEEE Access 8: 4806–13. [Google Scholar] [CrossRef]
- Kokoska, Stephen, and Daniel Zwillinger. 2000. CRC Standard Probability and Statistics Tables and Formulae. Boca Raton: CRC Press. [Google Scholar]
- Kuo, Kevin. 2019. Generative synthesis of insurance datasets. arXiv arXiv:1912.02423. [Google Scholar]
- Lagerås, Andreas, and Mathias Lindholm. 2016. Issues with the smith–wilson method. Insurance: Mathematics and Economics 71: 93–102. [Google Scholar] [CrossRef] [Green Version]
- Lezmi, Edmond, Jules Roche, Thierry Roncalli, and Jiali Xu. 2020. Improving the robustness of trading strategy backtesting with boltzmann machines and generative adversarial networks. Available at SSRN 3645473. Available online: http://www.thierry-roncalli.com/download/rbm_gan_finance.pdf (accessed on 26 April 2021).
- Li, Ziqiang, Rentuo Tao, and Bin Li. 2020. Regularization and normalization for generative adversarial networks: A review. arXiv arXiv:2008.08930. [Google Scholar]
- Marti, Gautier. 2020. Corrgan: Sampling realistic financial correlation matrices using generative adversarial networks. Paper presented at the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, May 4–8; pp. 8459–63. [Google Scholar]
- Mazumdar, Eric, Lillian J. Ratliff, and S. Shankar Sastry. 2020. On gradient-based learning in continuous games. SIAM Journal on Mathematics of Data Science 2: 103–31. [Google Scholar] [CrossRef] [Green Version]
- Motwani, Tanya, and Manojkumar Parmar. 2020. A novel framework for selection of GANs for an application. arXiv arXiv:2002.08641. [Google Scholar]
- Ngwenduna, Kwanda Sydwell, and Rendani Mbuvha. 2021. Alleviating class imbalance in actuarial applications using generative adversarial networks. Risks 9: 49. [Google Scholar] [CrossRef]
- Ni, Hao, Lukasz Szpruch, Magnus Wiese, Shujian Liao, and Baoren Xiao. 2020. Conditional sig-wasserstein gans for time series generation. arXiv arXiv:2006.05421. [Google Scholar] [CrossRef]
- Pedersen, Hal, Mary Pat Campbell, Stephan L. Christiansen, Samuel H. Cox, Daniel Finn, Ken Griffin, Nigel Hooker, Matthew Lightwood, Stephen M. Sonlin, and Chris Suchar. 2016. Economic Scenario Generators: A Practical Guide. Available online: https://www.soa.org/globalassets/assets/Files/Research/Projects/research-2016-economic-scenario-generators.pdf (accessed on 26 April 2021).
- Pfeifer, Dietmar, and Olena Ragulina. 2018. Generating VaR scenarios under Solvency II with product beta distributions. Risks 6: 122. [Google Scholar] [CrossRef] [Green Version]
- S&P Ratings. 2018. Annual Global Corporate Default and Rating Transition Study. Available online: https://www.spratings.com/documents/20184/774196/2018AnnualGlobalCorporateDefaultAndRatingTransitionStudy.pdf (accessed on 26 April 2021).
- Salimans, Tim, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016. Improved techniques for training gans. arXiv arXiv:1606.03498. [Google Scholar]
- Smith, Andrew, and Tim Wilson. 2001. Fitting Yield Curves with Long Term Constraints. Technical Report. London: Bacon and Woodrow. [Google Scholar]
- Theis, Lucas, Aäron van den Oord, and Matthias Bethge. 2015. A note on the evaluation of generative models. arXiv arXiv:1511.01844. [Google Scholar]
- Viehmann, Thomas. 2019. Variants of the smith-wilson method with a view towards applications. arXiv arXiv:1906.06363. [Google Scholar]
- Wiese, Magnus, Lianjun Bai, Ben Wood, and Hans Buehler. 2019. Deep hedging: Learning to simulate equity option markets. arXiv arXiv:1911.017002019. [Google Scholar] [CrossRef] [Green Version]
- Wiese, Magnus, Robert Knobloch, Ralf Korn, and Peter Kretschmer. 2020. Quant gans: Deep generation of financial time series. Quantitative Finance 20: 1419–40. [Google Scholar] [CrossRef]
- Yoon, Jinsung, Daniel Jarrett, and Mihaela Van der Schaar. 2019. Time-series generative adversarial networks. In Advances in Neural Information Processing Systems. vol. 32, Available online: https://proceedings.neurips.cc/paper/2019/file/c9efe5f26cd17ba6216bbe2a7d26d490-Paper.pdf (accessed on 26 April 2021).
- Yu, Chong Ho. 2002. Resampling methods: Concepts, applications, and justification. Practical Assessment, Research, and Evaluation 8: 19. [Google Scholar]
















| Benchmark Portfolio | WorstCase(P) | |
|---|---|---|
| BMP1 | −2.8% | 13.5% |
| BMP2 | −2.5% | 19.2% |
| BMP3 | −2.8% | 15.6% |
| BMP4 | −2.7% | 19.6% |
| BMP5 | −2.4% | 13.3% |
| BMP6 | −2.8% | 10.9% |
| BMP7 | −7.8% | 2.3% |
| BMP8 | −2.7% | 16.2% |
| BMP9 | −3.7% | 21.6% |
| BMP10 | −6.1% | 5.9% |
| L1 | −15.2% | 5.4% |
| L2 | −4.3% | 15.8% |
| BMP1+L1 | −58.2% | 3.5% |
| BMP3+L1 | −64.5% | 0.9% |
| BMP7+L1 | −67.1% | 6.8% |
| BMP9+L1 | −41.3% | 7.1% |
| BMP10+L1 | −89.9% | 3.4% |
| BMP1+L2 | −30.9% | 3.8% |
| BMP3+L2 | −34.8% | 2.5% |
| BMP7+L2 | −53.4% | 3.9% |
| BMP9+L2 | −26.8% | 13.6% |
| BMP10+L2 | −65.6% | 3.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flaig, S.; Junike, G. Scenario Generation for Market Risk Models Using Generative Neural Networks. Risks 2022, 10, 199. https://doi.org/10.3390/risks10110199
Flaig S, Junike G. Scenario Generation for Market Risk Models Using Generative Neural Networks. Risks. 2022; 10(11):199. https://doi.org/10.3390/risks10110199
Chicago/Turabian StyleFlaig, Solveig, and Gero Junike. 2022. "Scenario Generation for Market Risk Models Using Generative Neural Networks" Risks 10, no. 11: 199. https://doi.org/10.3390/risks10110199
APA StyleFlaig, S., & Junike, G. (2022). Scenario Generation for Market Risk Models Using Generative Neural Networks. Risks, 10(11), 199. https://doi.org/10.3390/risks10110199