1. Introduction
Longevity risk is the now well-recognised risk that the overall survival probability of a reference population is higher than expected (
Cairns et al. 2006a). Improvements in mortality experienced in recent decades show significant volatility, as evidenced by the impact of COVID-19. Life insurance companies and pension funds, as the holders of substantial longevity risk, are significantly impacted by mortality trends and uncertainty (
Blake et al. 2014). The
Continuous Mortality Investigation (
2018) highlighted the potential impact of the underestimation of longevity risk, estimating that an extra
$450 billion would be required in pension payments per year (
The Joint Forum 2013). Mortality uncertainty requires increase capital requirements for insurers (
Barrieu et al. 2012). The quantification of longevity risk is fundamental to the successful operation of life insurance companies and pension funds.
Insurers and pension funds can manage the risk of mortality uncertainty by transferring longevity risk to counterparties using longevity swaps and to capital markets using securitization (
The Joint Forum 2013). Capital markets are expected to be increasingly important in longevity risk management, arising from the potential for a more efficient and effective approach (
Blake et al. 2018). Longevity-linked securities, including longevity bonds (
Blake and Burrows 2001), longevity swaps (
Dowd et al. 2006), and q-forwards (
Coughlan et al. 2007), have been proposed. Risk quantification and fair pricing are challenging aspects of these developments. The
Life and Longevity Markets Association (
2010) acknowledges that mortality improvements and uncertainty are important inputs in pricing longevity risk, but modelling and forecasting improvement trends and uncertainty continue to attract significant research interest.
Stochastic mortality models capture the stochastic evolution of mortality rates at an aggregate population level. Models include the single-factor Lee–Carter model (
Lee and Carter 1992) and numerous extensions and improvements.
Cairns et al. (
2009) provide a comprehensive summary and comparison of these extensions. The Cairns–Blake–Dowd model (
Cairns et al. 2006b), a two-factor model, and the age-period-cohort model (
Renshaw and Haberman 2006) are popular models. Many of these models do not have closed-form solutions for survival curves, requiring simulation to compute future expected survival probabilities for applications.
Continuous-time affine mortality models, based on mathematical finance models for interest rate and credit risk, were introduced in
Milevsky and Promislow (
2001),
Dahl (
2004), and
Cairns et al. (
2006a), amongst others. Continuous-time mortality models apply diffusion processes to the dynamics of mortality intensities. They are designed to be incorporated into the modelling of longevity risk using consistent model frameworks for mortality and financial risks with applications in the valuation of longevity-linked securities (
Jevtic et al. 2013). A general framework for continuous time mortality models for multiple populations is provided in
Jevtić and Regis (
2019) with applications in UK and Dutch mortality data.
We confine our comparison of mortality models to the continuous-time arbitrage-free modelling framework. The Lee–Carter model is a popular, simple, one-factor model (which is affine in the log mortality rates). A comparison of the Lee–Carter model with three continuous time models, which include two single factor affine mortality models, is found in
Novokreshchenova (
2016). The single-factor affine mortality models in that study have lower mean absolute prediction error for UK and Australian mortality data compared with the Lee–Carter model. We consider three factor affine mortality models that provide better fit and prediction compared to single-factor models.
SriDaran et al. (
2022) consider extensions to the Lee–Carter mortality model in the form of generalized age-period-cohort mortality models using regularization to select factors from a large number of factors. The empirical results show that a combination of level, slope, and curvature factors can explain the dynamics of many of the countries in the Human Mortality Database. Although these models differ from ours, the results motivate our use of affine mortality models and the inclusion of an affine mortality model with level, slope, and curvature factors.
Affine mortality models apply concepts underlying Affine Term Structure Models (ATSMs) for interest rate modelling, as in
Duffie and Kan (
1996) and
Dai and Singleton (
2000), to mortality rates. Affine mortality models are similar to interest-rate models, provide an integrated pricing framework (
Barrieu et al. 2012), and allow the derivation of closed-form solutions for survival probabilities (
Dahl 2004). Affine processes provide flexibility and analytical tractability. We develop models with consistency between the dynamics and the functional form of the survival curve. We also impose consistency in the cross-sectional survival probabilities through the arbitrage-free assumption applied to these probabilities. Models that satisfy a consistency requirement (
Björk and Christensen 1999) have stable parameters and ensure consistency between the dynamics of mortality rates and the functional form for the survival curve. Projected survival curves are consistent with the dynamics of mortality rates as discussed in
De Rossi (
2004) and demonstrated empirically in
Blackburn and Sherris (
2013). Survival curves are exponential affine functions of factors, with factor loadings determining how the risk factors impact differing ages through time.
Pricing of longevity-linked cash flows requires risk-adjusted survival probabilities for a cohort in a reference population (
Xu et al. 2020a). Affine mortality models have been predominantly considered for capturing the mortality dynamics of a single cohort, as in
Dahl and Møller (
2006),
Biffis (
2005) and
Luciano et al. (
2008). Affine models have been calibrated to age-period mortality data for a reference population, as in
Schrager (
2006). Gaussian affine mortality models fit age-period mortality data well, although less so at older ages
Blackburn and Sherris (
2013).
Blackburn and Sherris (
2013) shows how three-factor affine mortality models in canonical form capture older-age mortality variation better than two-factor models. Gaussian models do not capture mortality heterogeneity at older ages (
Pitacco 2016).
Alai et al. (
2019) show that the Gamma distribution fits mortality intensities well, which is consistent with mortality heterogeneity, suggesting non-Gaussian models may improve model fit at older ages.
Jevtić and Regis (
2021) develop square-root latent factor affine mortality models and show how these models provide a good fit to UK mortality data. Cohort effects have been observed in age-period data for many countries, as discussed, for example, in
Willets (
2004),
Cairns et al. (
2009) and
Gallop (
2008).
This motivates our modelling of age-cohort mortality data. We focus on a single-cohort mortality curve. Extensions to multiple-cohort affine age-cohort mortality models are found in
Jevtic et al. (
2013),
Chang and Sherris (
2018),
Jevtić and Regis (
2019),
Xu et al. (
2020a), and
Jevtić and Regis (
2021). We model the older ages of a single cohort using age-cohort mortality data. We develop mortality models in a risk-adjusted framework and, through a change of measure, mortality dynamics that can be calibrated to real-world or historical data. We estimate and compare five continuous-time affine cohort mortality models using age-cohort mortality data from the USA for males from ages 50 to 100 for cohorts with complete data born from 1883 to 1915.
Blackburn and Sherris (
2013) shows how three-factor models perform well in explaining mortality variations at the ages we consider, so we focus on three-factor affine mortality models.
The five models we consider and compare include a canonical affine mortality model; an Arbitrage-Free Nelson–Siegel (AFNS) mortality model (
Christensen et al. 2011) with identifiable factors of level, slope, and curvature of the mortality curve; and a mortality model based on the Cox–Ingersoll–Ross (CIR) model (
Cox et al. 1985;
Jevtić and Regis 2021), allowing for a gamma distribution for mortality rates. We also investigate the impact of incorporating factor dependence to capture correlations for the Gaussian mortality models, giving another two models. We capture cohort effects directly using age-cohort data to calibrate and assess the model survival curve fit and forecasting performance. The continuous dynamics of mortality rates are discretized for estimation and implementation. Maximum likelihood with a Kalman filter are used to estimate model parameters. We estimate parameters for the factor dynamics in the real world or historical measure and the cross sectional survival curve parameters in the Q, or pricing measure, in the Kalman filter measurement equation.
Our contributions to mortality modelling are to provide empirical support for Gaussian affine mortality models based on USA data, to provide a detailed comparison of a number of multi-factor affine mortality models for the first time, and to investigate how modelling age-cohort data with affine mortality models can capture mortality dynamics. We show that, empirically, the independent-factor AFNS mortality model performs well. It better captures the variation in cohort mortality rates in USA data and produces a better fit at older ages than the independent-factor canonical Blackburn–Sherris model. Incorporating dependence in the factors for the Blackburn–Sherris mortality model improves in-sample model fit and out-of-sample forecasting performance. We also show that, for the 1916 birth cohort, the independent-factor AFNS mortality model has better predictive performance compared to the other models. Negative mortality rates, a potential limitation of Gaussian mortally models, have very low empirical probabilities for the AFNS mortality models. The CIR mortality model has the best in-sample model fit but performs poorly in predictive performance for the 1916 birth cohort.
This paper is structured as follows.
Section 2 summarizes the framework for affine mortality models and specifies the structure of the continuous-time cohort mortality models.
Section 3 describes the US mortality data we use for calibration.
Section 4 outlines the estimation methodology using the Kalman filter and provides an analysis of the estimation results and model comparison. In
Section 5, we estimate the out-of-sample expected survival probabilities for the latest cohort with full mortality data and assess the out-of-sample forecasting ability of the different models. In
Section 6, we discuss the implications of the results for mortality modelling as well as further research.
Section 7 concludes the paper with a summary and major findings.
4. Model Assessment and Comparison
We use the Kalman filter to estimate the model parameters for all the models. We then compare the fitted models using a number of model selection criteria. When using the Kalman filter, we estimate the parameters of the latent factor dynamics in the real-world or historical measure and estimate the Q measure parameters in the measurement equation that links the cross-sectional survival probabilities to the latent factors.
4.1. Parameter Estimation
We follow
Christensen et al. (
2011) and
Blackburn and Sherris (
2013) and use the Kalman filter with maximum-likelihood estimation to estimate the parameters in the affine mortality models. Our models capture the volatility of the underlying mortality rates but observed deaths are used to estimate historical mortality rates from the data. These historical mortality rates also include Poisson variation based on the number of individuals in each age. Our model needs to include this. We do so by including an exponentially increasing Poisson variation term in the measurement equation of the Kalman filter (
Xu et al. 2020b).
The estimation process is as follows:
Represent the affine mortality models in the state space form, which consists of two components, the measurement equation and the state transition Equation (
Xu et al. 2020a;
Shumway and Stoffer 2017).
The measurement equation describes the affine relationship between the average force of mortality and the state variables (
Xu et al. 2020a;
Durbin and Koopman 2012). Based on
Blackburn and Sherris (
2013) and
Xu et al. (
2020a), the measurement equation in terms of the average forces of mortality is
where the measurement error
is independently and identically distributed noise with the covariance matrix of the measurement error,
H, being diagonal. We use the Q or pricing measure parameters in the measurement equation to ensure cross-sectional consistency in the survival probabilities.
To capture the increasing nature of the Poisson variation, the parametric form assumed for the diagonal of the covariance matrix
H is
where the values of
,
and
are estimated from the data.
The state transition equation represents the unobserved dynamics of the state variables (
Xu et al. 2020a;
Durbin and Koopman 2012) and is given by:
where
is the transition error vector with diagonal matrix
R, the covariance matrix of the transition error. We use the real-world or historical parameters for the latent factor dynamics in the state transition equation to capture the real-world dynamics.
The matrix
R has the following structure:
Use the Kalman filter to evaluate the likelihood function of affine mortality models and to extract the values of the state variables. The information available at time t is denoted by , and the model parameters are given by .
In the forecasting step, we use the state update
and its mean square error
obtained at
to obtain
where
.
In the update step, the information at time
t,
, is used to update the forecasts
, and we obtain:
where
Evaluate the following log-likelihood function with the values obtained in the previous step:
where
N is the number of observed average forces of mortality.
The log-likelihood function is maximized with respect to
to obtain the optimal parameter set. For the CIR mortality model we use quasi-maximum likelihood estimation.
Jevtić and Regis (
2021) estimate similar models using the Kalman filter and quasi-maximum likelihood estimation. The estimation uses the Gaussian Kalman filter with the moments from the CIR model in the likelihood for parameter estimation.
4.2. Model Parameter Estimation Results
Parameter estimates for each model, along with the standard errors are summarized in
Table 2. Risk neutral model parameter values are reported along with the historical or real world parameter values. Transitions are based on the historical parameters to reflect the dynamics driving the underlying factors and the measurement equation is based on measurement equation to ensure the arbitrage-free structure of the survival curves.
The parameters in determine the impact of each of the factors and the significance of the factor loadings for mortality rates at different ages. We see that the diagonal components are largely negative. The s in the dependent-factor AFNS model are smaller in absolute value than for the independent-factor AFNS model. For the two AFNS models, s are both negative, impacting the sensitivity for the slope factor at older ages.
The mean reversion parameters, giving the speed of reversion to long-term means, vary across the models. There are different rates of mean reversion in the real world measure. There are negative correlations between factors in the two dependent-factor models, which only impacts the adjustment term .
All the long-term mean
parameters in the CIR model are positive. This ensures the factors are positive and positive mortality rates in the model. The second factor,
, has the largest mean reversion speed,
, and largest volatility,
. This factor has more impact on the short term (
Geyer and Pichler 1999). The mean reversion rate
and the volatility
of
are lowest, compared with the other two factors, so the first factor has less impact on mortality dynamics and is less volatile.
As seen in the structure of the measurement error matrix
H in Equation (
35), the measurement errors are age-dependent and exponentially increasing with age. For the
, the scalar in the exponential function in matrix
H, the independent-factor Blackburn–Sherris model has the largest
, and the largest estimated measurement error volatility. For the CIR model, the values of all the parameters in matrix
H are negligible. These smaller measurement errors reflects in a better in-sample model fit.
4.3. Assessing Model Goodness-of-Fit
Table 3 shows, for each model, the Root Mean Square Error (RMSE), the Akaike information criterion (AIC), and the Bayesian information criterion (BIC). Since the models with Gaussian processes allow for negative mortality, we show the probabilities of negative mortality for these models.
The CIR model has the highest log-likelihood and the smallest RMSE. Although it has more parameters, the AIC and the BIC of the CIR model indicate this is a better model. As noted earlier, the CIR model precludes the probability of negative mortality.
We note that the Gaussian models perform well, particularly the dependent-factor models. The dependent factor Blackburn–Sherris model and the AFNS models all have low probabilities of negative mortality rates. The dependent-factor Blackburn–Sherris model has the largest log-likelihood and better AIC and BIC than the other Gaussian models.
4.4. Factors and Factor Loadings
It is interesting to consider the factors and the factor loadings for the cohort survival curves for the independent AFNS mortality model, where the factors for level, slope, and curvature have a direct interpretation, and the CIR mortality model which, based on the criteria used, is the best-performing model.
Figure 3 and
Figure 4 show the fitted values of the factors and factor loadings of the independent AFNS model. For the factor loading
, the impact of the level factor
L is constant across all ages. We see an increase in the factor level for all ages for the cohorts born around 1900 onwards. This increase in the level factor is offset by the reduction in the slope factor. The interaction is impacted by the factor loadings for these factors and the resulting changes in mortality curves for cohorts born later.
The slope factor loading increases exponentially, so it impacts older ages more than younger ages. Mortality rates at older ages are more sensitive to the slope factor S. For cohorts born after 1900, corresponding to the rise in the level factor L, there is a decline in the slope factor S. These factors interact to fit the changes in the historical age-cohort survival curves.
The factor loading is negative and decreasing across all ages. As a result, the convexity of the survival curve at older ages decreases faster than at younger ages. For cohorts born after 1900, the decline in C results in mortality rate curves that are less convex across age. As a result, mortality improvement at older ages is larger than for the younger ages in the age-cohort curves.
The adjustment term A in the survival curve is negative and decreasing.
The estimated latent factors and factor loadings for the CIR mortality model are shown in
Figure 5 and
Figure 6. As expected, the factors and factor loadings differ from those of the independent AFNS mortality model, reflecting the different model assumptions.
The first factor is relatively stable for cohorts born before 1900, then increases, followed by a moderate decline for cohorts born around 1910 and after. The factor loading, , is positive and increases with age. The interaction between the factor dynamics and the factor loading for the first factor results in older ages in the age-cohort mortality curve being affected more by the first factor than for younger ages. Since is the largest factor throughout the time period and the factor loadings are largest for this factor, it is the dominant factor impacting changes in mortality in the CIR model.
The second factor has a downward trend over time. The factor loading is decreasing with age and smaller than . As a result, younger ages have mortality improvement from the second factor, but the size of improvement from this factor is smaller than for the first factor. As a result, it has a much smaller overall impact compared to .
The third factor is relatively constant for cohorts born before 1900, decreasing afterwards, with a reduction in the rate of decrease for cohorts born after around 1910. The factor loading has a convex shape, is positive, and impacts older ages more than younger ages. This results in curvature changes in the age-cohort survival curve.
The adjustment term A, which produces the consistency in the age-cohort survival curves, is negative and, following a small increase for younger ages, is then decreasing.
The combination of the factor dynamics for all the factor dynamics along with the factor loadings determine the shape and dynamics of the age-cohort survival curves. These dynamics are estimated from the age-cohort mortality data and allow an analysis of the underlying trends and changes in the age-cohort survival curve over time. The more complex dynamics than single factor models explain the variation at older ages better.
4.5. Residual Analysis
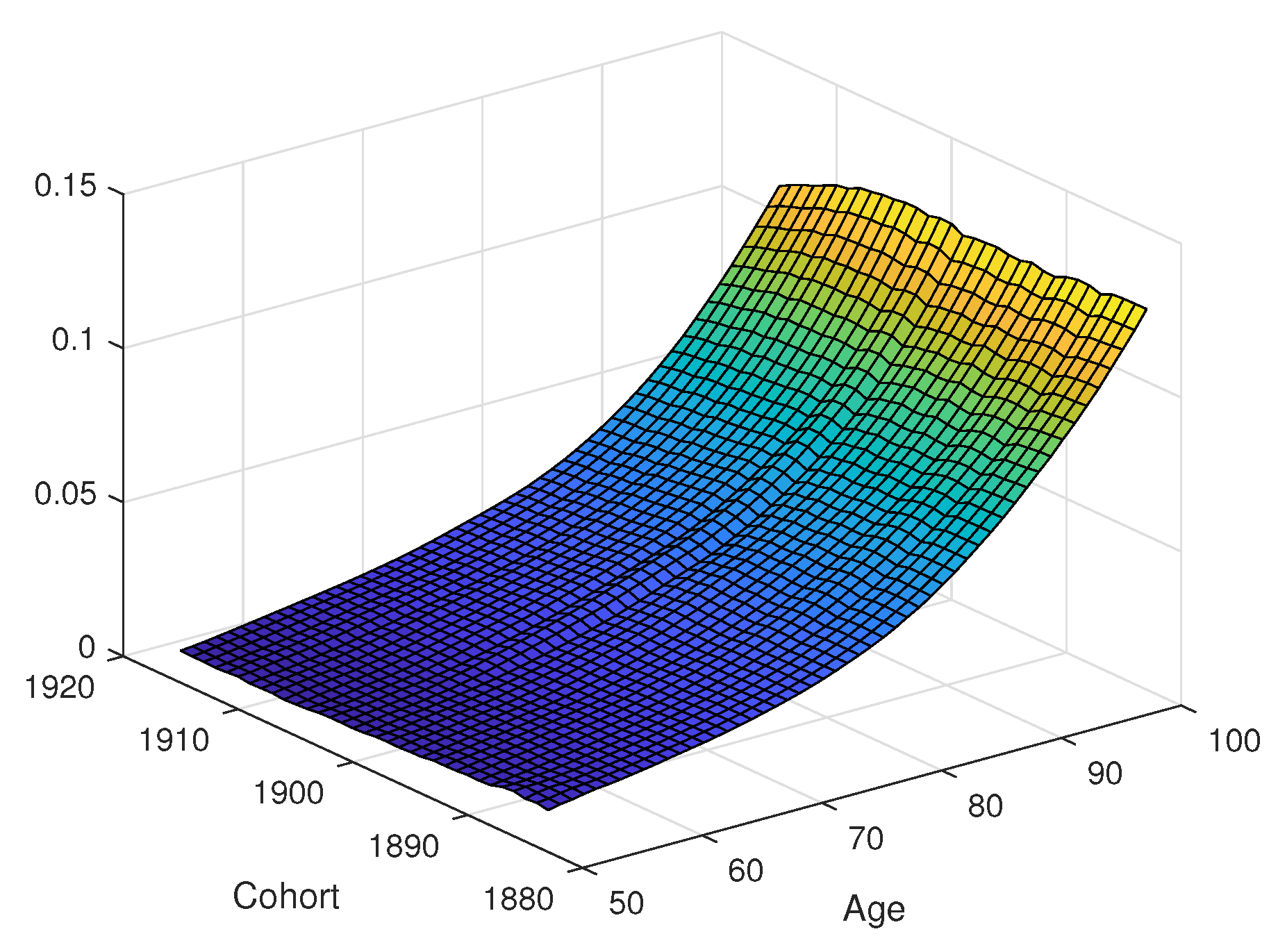
The residuals or the affine mortality models are shown in
Figure 7. The residuals shown are the differences between the average force of mortality from the historical mortality data and those determined from the fitted mortality models. Plots are on the same scale on the z-axis, except for the independent Blackburn–Sherris model, which has large residuals at older ages, reflecting a poorer fit at these ages.
Excluding the independent Blackburn–Sherris model, all of the other affine age-cohort mortality models show similar residuals. With three factors for level, slope, and curvature, we see that the independent AFNS model (
Figure 7c) fits well. The AFNS model reduces the magnitude of residuals at the older ages compared to the independent Blackburn–Sherris model without adding additional parameters. This shows how, by using factors for level, slope, and curvature factors, the mortality model can capture variation in mortality curves, especially at older ages.
We see how factor dependence in the Blackburn–Sherris model produces a better fitting model, reducing the size of residuals, and accounting better for mortality variation at older ages. This is seen by comparing the dependent Blackburn–Sherris model (
Figure 7b) with the independent model (
Figure 7a). Although including dependence in the factors of the Blackburn–Sherris model improves the residuals of the model fit, we do not see this for the independent AFNS model in
Figure 7c. The residuals in the dependent AFNS model (
Figure 7d) are larger, particularly at older ages. This highlights how the independent AFNS model captures mortality variability better than the dependent AFNS model, in contrast to the dependent Blackburn–Sherris model.
The CIR model has lower residuals at older ages and residuals similar to those of the independent AFNS model in
Figure 7c. The CIR model has slightly smaller residuals at older ages and ages younger than 60, compared with the other models.
We see a hump shape running diagonally across the cohorts in all of the residual plots. Diagonal effects in an age-cohort model correspond to period effects. The residuals highlight a period mortality effect that impacts all of the cohorts around the year 1970. This corresponds to when period mortality improvement trends in age-period models showed a change to a higher level of improvement. We also see that for later cohorts at older ages, the residuals are higher, which would be indicative of a slowing of mortality-improvement rates in recent years.
4.6. In-Sample Analysis
We now consider an in-sample model performance analysis. We compare estimated cohort survival probabilities from the fitted mortality models with the cohort survival probabilities from the historical data.
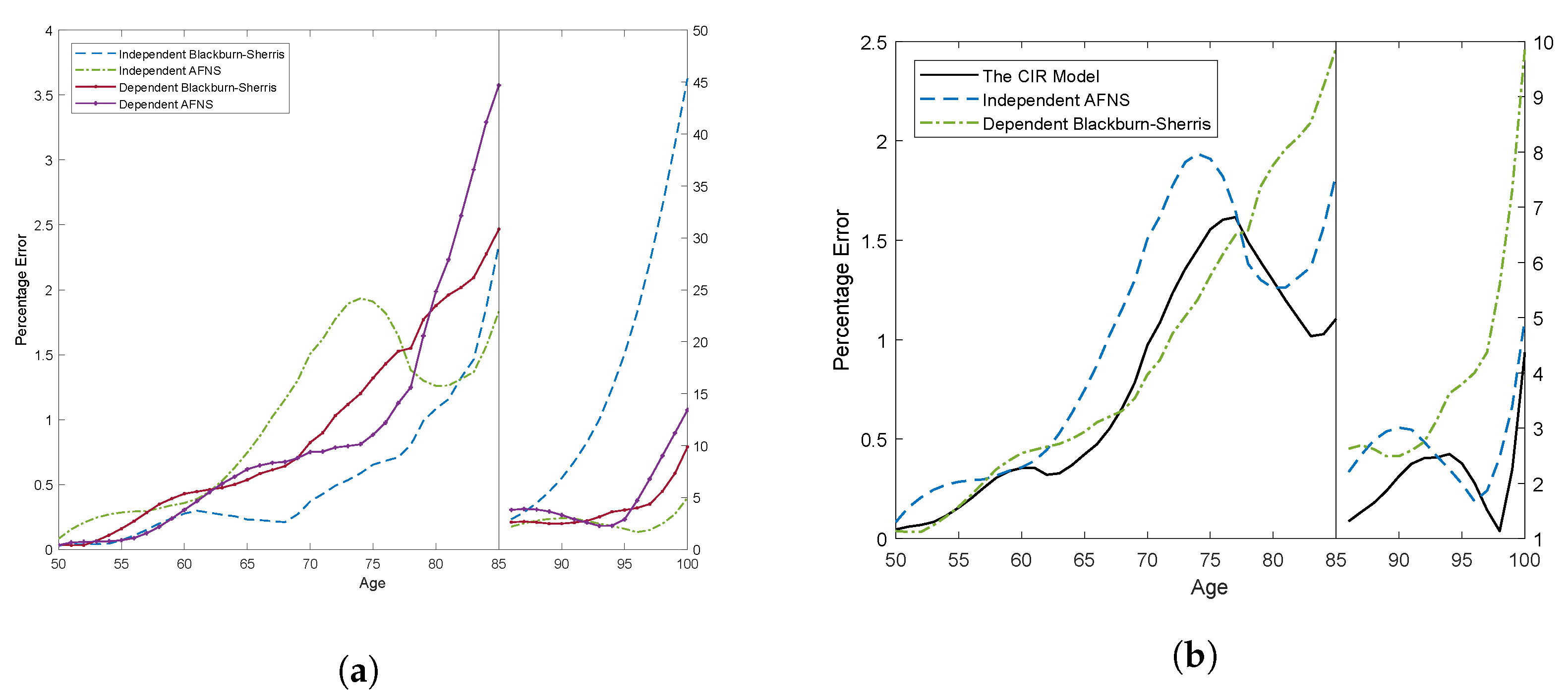
Figure 8 summarizes the in-sample model fit using the Mean Absolute Percentage Error (MAPE) for each age across all cohorts. The scale of the percentage error is different above and below age 85 because of the significant differences in the size of the errors.
Figure 8a shows the MAPE for the affine mortality models with Gaussian processes. Below age 85, all models have similar performance, and the differences between the percentage errors of the different mortality models are relatively small. What is more interesting is the fit above age 85. The independent Blackburn–Sherris model has significantly larger percentage errors. The other affine age-cohort Gaussian mortality models, the dependent Blackburn–Sherris model and the independent AFNS model, have similar and improved model fit at these older ages.
We compare the MAPE of these better performing Gaussian mortality models with the CIR age-cohort mortality model in
Figure 8b. We see that the CIR mortality model and the independent AFNS mortality model are similar. The latter has only slightly larger percentage errors at most ages. The dependent Blackburn–Sherris model is similar to the CIR model below age 75, but the percentage errors increase after age 75 with values as high as 10%.
Based on MAPE, we see that both the independent AFNS mortality model and the CIR mortality model have similar and satisfactory performance for the historical age-cohort data for complete cohorts in the USA historical mortality.
5. Forecasts of Survival Probabilities
We compare the predictive performance of the affine mortality models using an out-of-sample forecast with the fitted parameter values estimated from the cohorts born 1883 to 1915 for ages 50 to 100 used to forecast the survival curve of the cohort born in 1916. For this cohort we have full historical mortality data.
Following
Christensen et al. (
2011), who use optimal forecasts to predict yields to maturity, we use optimal forecasts, also referred to as best-estimate forecasts, to project average forces of mortality and survival probabilities.
At time
t, the average force of mortality over
periods at time
for cohort
i,
, is
where
and
only depend on
.
The forecasts of survival probabilities are then
Since the factor dynamics under measure
P in the independent Blackburn–Sherris model and the three-factor independent AFNS model are the same, the conditional expectations of state variables for these two models are as follows:
For the independent AFNS model, the conditional mean has the same structure but with
.
The SDEs describing the
P-dynamics of the dependent Blackburn–Sherris model and the dependent AFNS model are the same as for the independent factor model in Equation (
47).
The RMSE under each mortality model for projecting the 1916 cohort survival curve are shown in
Table 4. We see that the independent AFNS mortality model performs best on these criteria. The dependent AFNS mortality model and the dependent Blackburn–Sherris models perform similarly. In contrast, the independent Blackburn–Sherris mortality model shows the poorest performance. Although the CIR mortality model has reasonable RMSE, it is outperformed by the AFNS mortality models.
To illustrate these differences,
Figure 9 shows the survival probabilities for the different mortality models using the best estimate forecasts compared to the actual survival probabilities from the historical mortality data. The models produce reasonable survival curve fits, except the independent Blackburn–Sherris mortality model and the CIR mortality model, which both underestimate the survival rates of the 1916 cohort.
Figure 10 shows the absolute percentage errors across ages for all the mortality models. This confirms the better forecasting performance of the independent AFNS mortality model. The dependent Blackburn–Sherris mortality models performs better than the independent Blackburn–Sherris mortality model, showing the benefit in forecasting of including correlations between the factors in this model. The level, slope, and curvature structure of the factors in the AFNS mortality model reduce the need for including dependence in the factors as compared to the Blackburn–Sherris mortality model.
6. Discussion
We have shown how affine mortality models can be applied to age-cohort mortality data using USA mortality data. We show that three-factor versions of these models fit the data well; the Gaussian models produce low probabilities of negative mortality rates; and the AFNS model, with level, slope, and curvature as factors, provides reliable forecasts of full age-cohort survival curves. We model age-cohort data since age-cohort survival curves are required for practical actuarial applications. Most other research uses age-period mortality, often with a cohort effect adjustment. Our analysis has used USA mortality data since the population is large and reflects many developments in mortality improvement expected to be found in other developed countries.
We develop our models in an arbitrage-free pricing framework assuming independence between interest rates and mortality. Correlation between interest rates and mortality rates can be incorporated into the models by an appropriate change in measure. Calibrating the models and estimating the correlation between interest rates and mortality rates would then require mortality-linked security prices that capture both interest rate and mortality risk.
Our results provide interesting insights into age-cohort mortality curve dynamics. Although we have focused on USA data, estimating and comparing age-cohort affine mortality models for other countries will provide a deeper understanding of the models and their ability to capture differing mortality dynamics.
There are a number of directions for which this research provides a foundation. We use the Kalman filter with maximum likelihood to estimate parameters. An area of research that would improve the model estimation is the development of efficient numerical estimation processes for the Kalman filter along with developing code that can be used by other researchers to estimate and implement the models.
We use only historical data for complete cohorts in our age-cohort mortality curve modelling. Incorporating incomplete cohorts into the estimation will allow the use of more recent age-cohort data in the model estimation and forecasting. Age-period data use the latest calendar year mortality data, whereas age-cohort data for later calendar years are incomplete.
We do not focus on parameter stability, and although this has been considered in (
Blackburn and Sherris 2013), assessing this for several other countries would provide additional support for the empirical performance of the multi-factor affine models.
Although we include dependence between the factors by incorporating correlation, we do not include age effects in the factors. In the affine framework, it is possible to capture age dependence in the factors to improve the model fit at older ages with potentially fewer factors in the model. It is also possible to capture age correlations and cohort correlations more effectively using age-dependent factors.
An important issue to also consider is the extension of the models to incorporate jump events such as the COVID-19 pandemic. These events not only have an impact on all ages to a greater or lesser extent in a particular number of periods, but can also have longer lasting impacts, as is occurring with long COVID-19. The affine models we consider do not account for larger jumps that impact several periods across all ages, as would be the case for a pandemic. The models can incorporate jumps such as COVID-19 into the affine mortality framework.
These extensions are all topics that current CEPAR actuarial research is investigating.
7. Conclusions
We have applied several continuous-time affine mortality models to age-cohort survival curve data using USA historical age-cohort data to fit and assess the mortality models. We provide a comprehensive analysis and comparison of the models. We outline, compare, and assess several independent-factor and dependent-factor affine mortality models with Gaussian processes, including the Blackburn–Sherris mortality model (
Blackburn and Sherris 2013;
Christensen et al. 2011), as well as an affine mortality model with square-root processes (the CIR mortality model). The CIR mortality model precludes negative mortality rates that can occur in the Gaussian models. The CIR latent factors and the mortality intensity have non-central Chi-square distributions, which can better reflect mortality heterogeneity. We also assess the performance of an AFNS mortality model with interpretable latent stochastic factors for level, slope, and curvature of the survival curve.
We incorporate dependence in the Blackburn–Sherris mortality model by including correlation between the factors and show how this improves in-sample model fit and out-of-sample forecasting performance. The CIR mortality model shows the best in-sample model fit across a range of criteria, including model residuals. The superior in-sample performance of the CIR mortality model is likely to reflect the more realistic assumption of Gamma-distributed mortality rates compared to the Gaussian models.
We find that the independent-factor AFNS mortality model performs well. It better captures the variation in age-cohort mortality rates in USA data and produces a better fit at older ages than the independent-factor Blackburn–Sherris model. Negative mortality rates have very low probability in the AFNS mortality models.
We project a complete cohort based on the fitted models to assess forecasting performance of the models. We forecast the 1916 cohort in the USA data, for which we have a complete cohort of mortality data. The independent-factor AFNS mortality model shows better predictive performance compared to the other models.
Based on our detailed assessment and comparison of these affine age-cohort mortality models, we show that, for USA age-cohort mortality data, the independent AFNS model provides satisfactory model fit and satisfactory predictive performance. The model is parsimonious relative to other models and can be readily estimated using the Kalman filter, allowing for Poisson mortality variation in the measurement equation. The model has intuitive factor interpretations in terms of level, slope, and curvature for the dynamics of the mortality survival curve and is well suited for financial and insurance applications, including pricing and longevity risk management.














{kind=link}
{kind=link}
{kind=link}
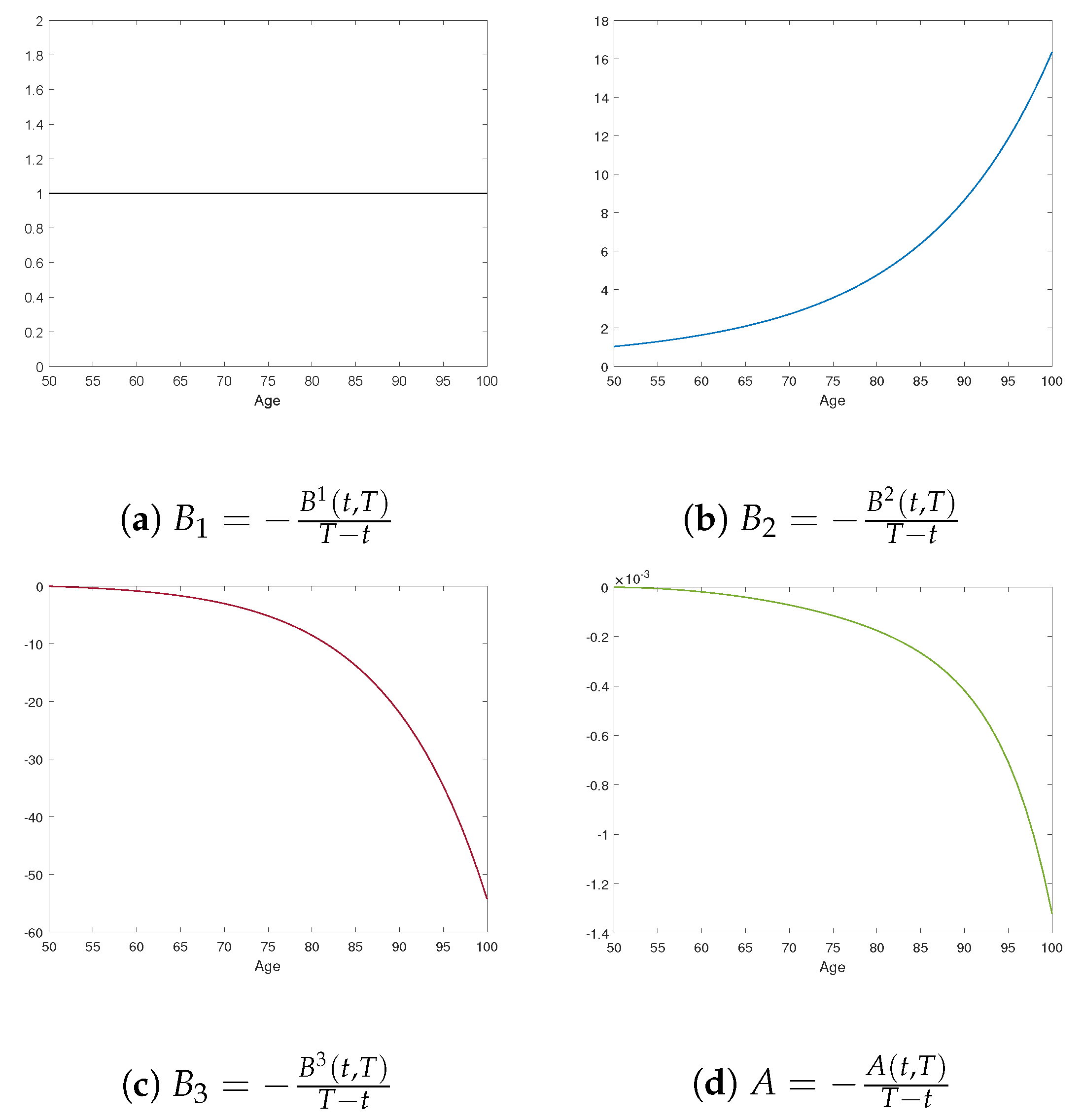{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}