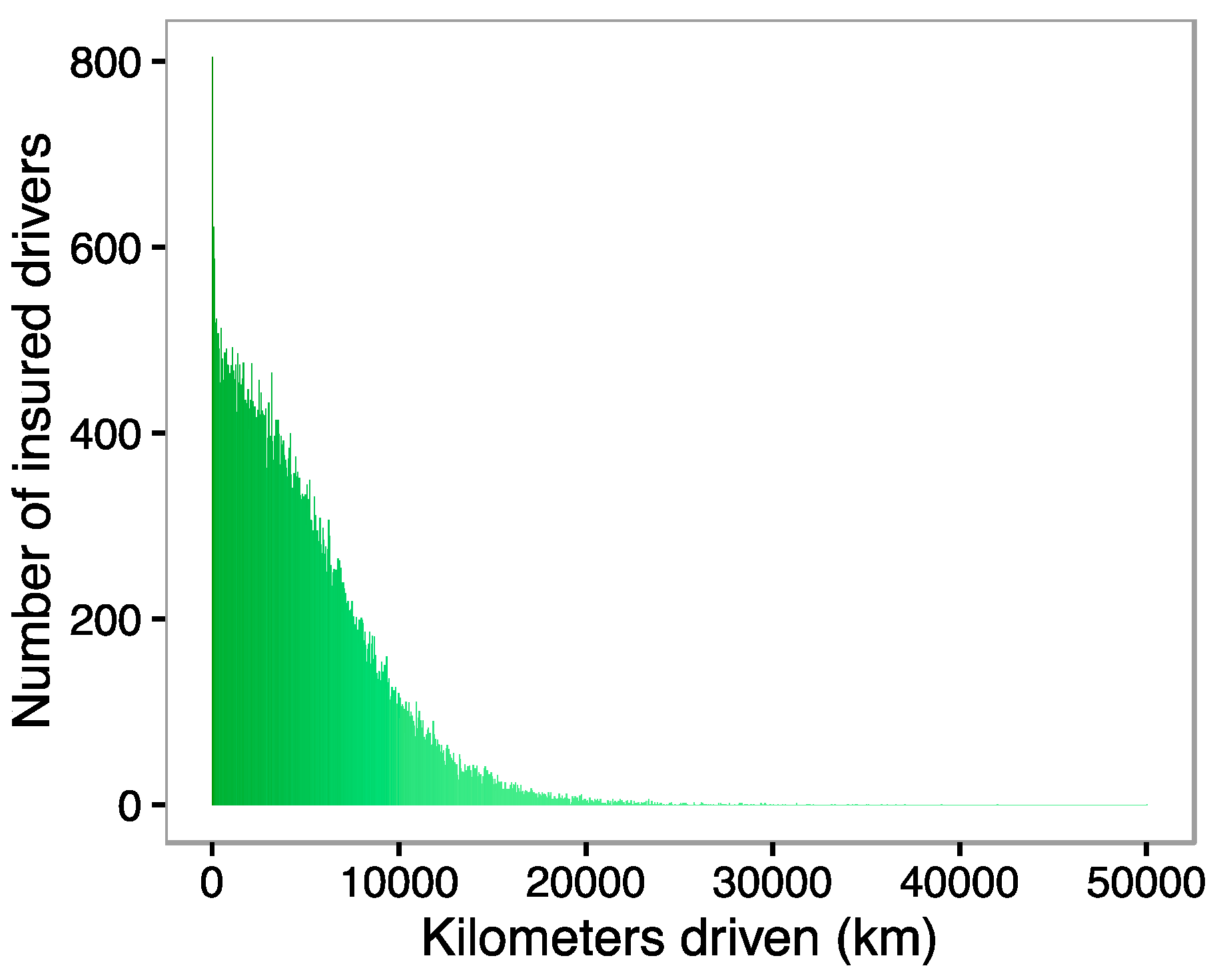
The number of claims is analyzed by using different GAMs. The GAM approach allows a better understanding of the impact of the distance traveled and the exposure duration on the number of claims. Our data are separated into two different databases: training and validation data. The first database is used to carry out the estimation, while the validation database is used in to assess the predictive performance of the model in a different sample than the one used in the estimation. The separation of the data in these two samples is done totally at random: 5000 observations are assigned to the validation sample, while the rest are used to build the different models.
2.2.1. Model with Independent Cubic Splines
First, the number of claims is modeled by using a GAM where independent cubic splines are adjusted for the number of kilometers (km) and the duration of the insurance contract (
d). Let us assume that the number of claims (
nb2) reported by the insuree
i, follows a Poisson distribution with expected value equal to
. A logarithmic function is used to link the expectation of the response variable with the linear predictor. Therefore, the GAM approach described herein can be formulated by the following equation
where
is the independent term in the model. Functions
and
are cubic splines, which are defined as univariate smoothing functions, with the following linear form
where
is the vector of parameters to be estimated and
,
k = 1, …,
q are functions created by a cubic spline basis with dimension given by
q. The details of the expression of the functions ,
k = 1, …,
q can be found in
Wood (
2006, Section 4.1.2). By doing this, the techniques used to estimate a GLM could also be used to estimate a GAM.
For the moment, there are no regressors capturing possible differences between the characteristics of the insured risk, such as age, sex of the driver, etc. That is, we are not going to use these variables in this first model. This allows us to make a more interesting graphical analysis as all insurees are observed simultaneously, because we believe that it is important to perform an initial analysis of the general profile. However, as we will see in the next section, we are going to incorporate these regressors for pricing, and then we will see that, in general, the results of this section are still valid when the heterogeneity of the insurees is considered.
For the parametrization defined by Equation (1), now this model will be simply called model 1, we select 7 and 3 nodes for
and
, respectively. The choice of the number of nodes is done manually and depends on the desired degree of flexibility. We note that the number of knots is rather low, so we expect smoother shapes, but usually more knots are selected using quantiles of the observed values. However, this is an important stage in the modeling process, since very few nodes produce an adjustment that cannot capture important trends in the data, while too many nodes can lead to an over-fitting. It seems that there is no consensus among the scientific community regarding the determination of the optimal number of nodes. Therefore, the choice of the number of nodes is an important part of the modeling process and may depend on the proficiency in the application.
Table 4 shows the results for model 1.
The concept of degrees of freedom, which is generally used in statistics, is adapted in the context of GAM and is known as the effective degrees of freedom (EDF). If the smoothing parameters are zero, then the number of degrees of freedom for a smoothing function is simply the number of parameters to estimate minus one (due to the constraint that the function should add up to 1 for any given observation). If the smoothing parameters are not zero, the number of degrees of freedom is necessarily reduced and then the concept of effective degrees of freedom is considered in order to quantify the flexibility of a smoothing function or a general model. The
F value shown in
Table 4 is the result of a statistical test similar to the Wald test to verify the significance of nonparametric terms. Finally, the generalized cross validation (GCV) is a method associated to the minimization of a score in order to find the smoothing parameters. For more details we refer to
Wood (
2006), Sections 3.2.3 and 4.8.5.
The low
p-values in
Table 4 show that both the parametric and the nonparametric effects in model 1 are significant. The GCV score is equal to 0.38412, but does not let us conclude anything at the moment, since it must be compared to another model. The GCV score is a statistical measure that only makes sense when several models are compared.
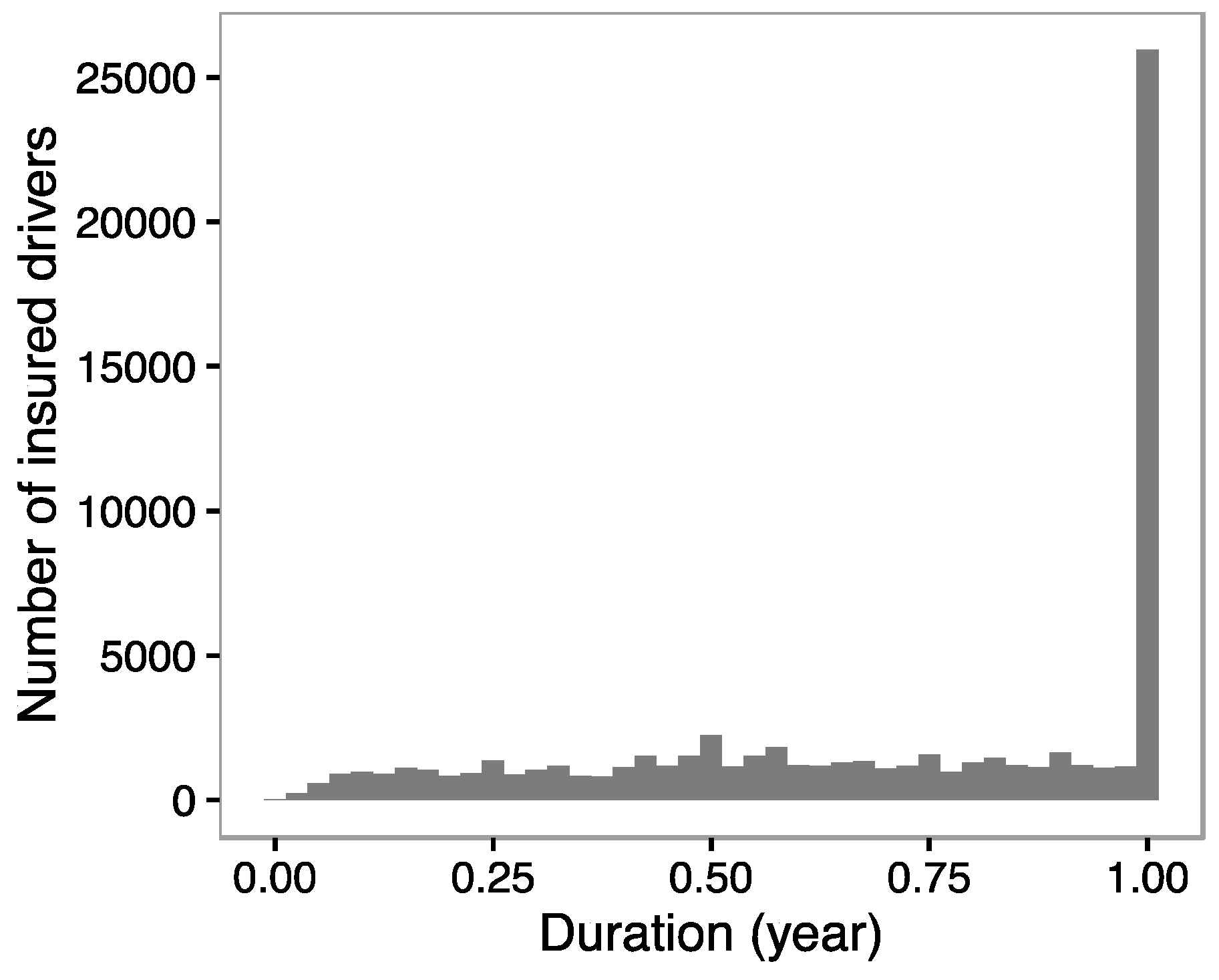
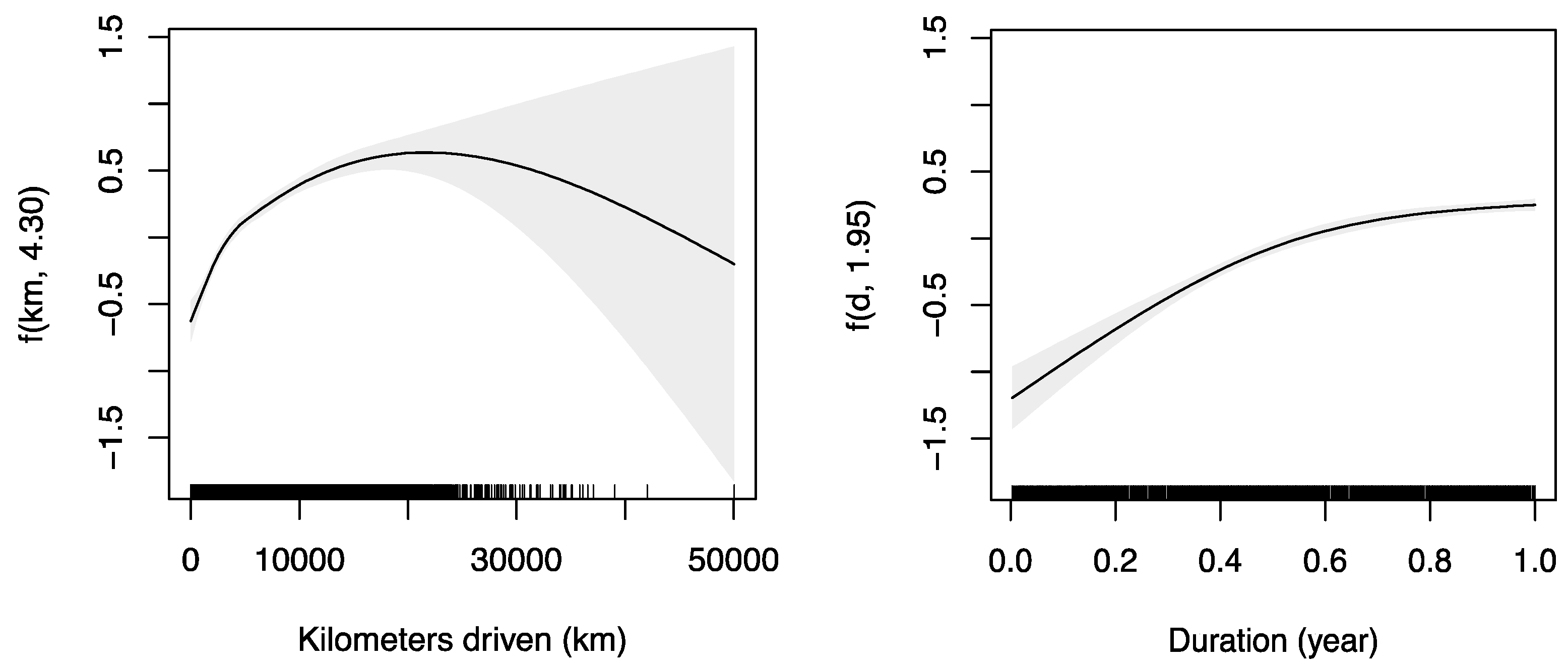
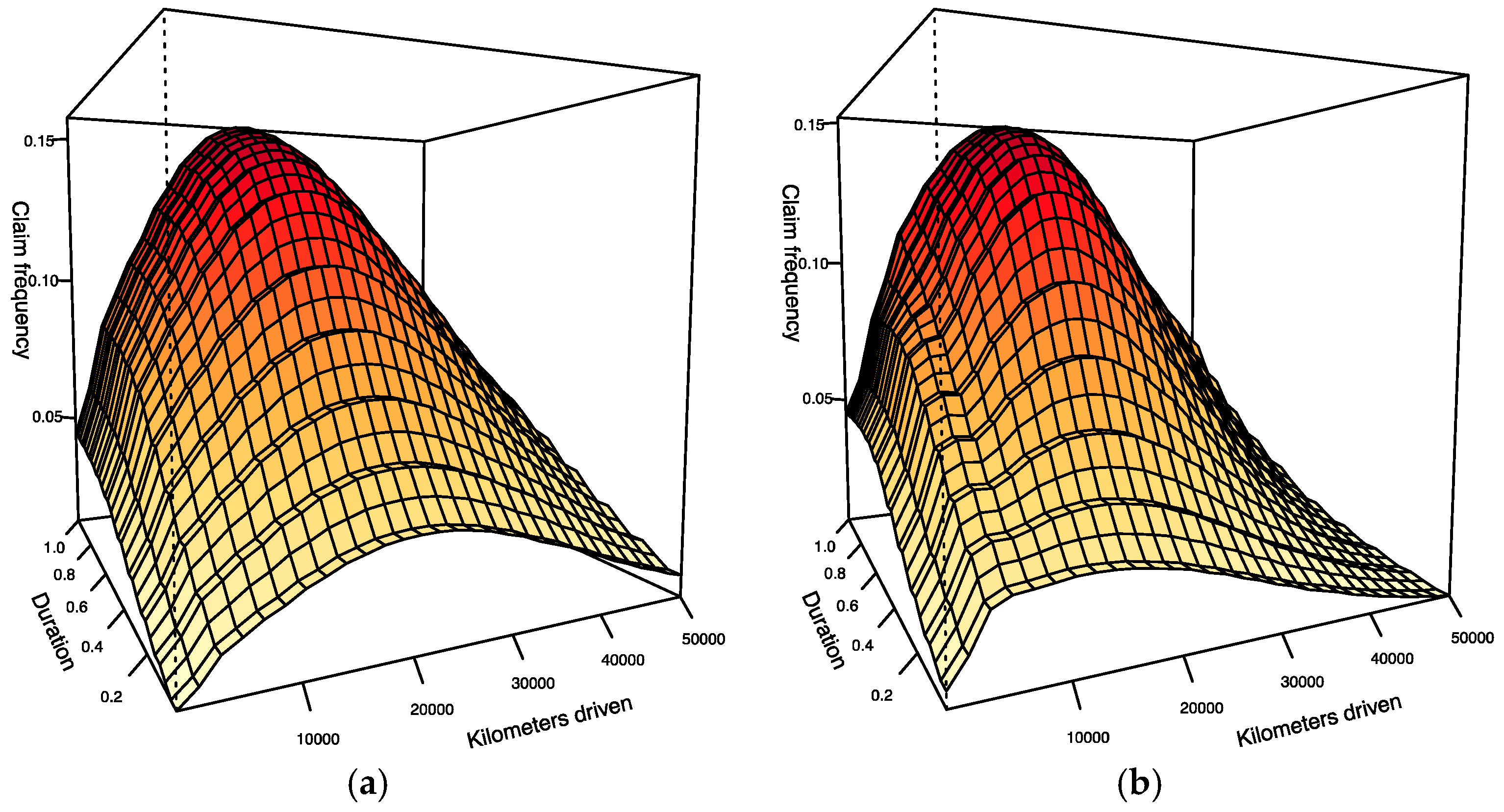
Figure 5 visualizes the adjusted smoothing functions obtained after estimating model 1. The black curves in both illustrations correspond to the predicted values for each function. The grey areas correspond to the 95% confidence intervals for the predictions. At the bottom of the graph, the density of observations that were used in the model is shown. Note also, that the effects are presented on the scale of the linear predictor instead of on the scale of the response level.
In
Figure 5 we see that
increases very fast for the first 10,000 km. Subsequently, the increase continues but not so sharply and stabilizes at 20,000 km. Finally, we observe a decreasing pattern but the confidence in the predicted values is very low because there are only a few contracts with such a large number of kilometers.
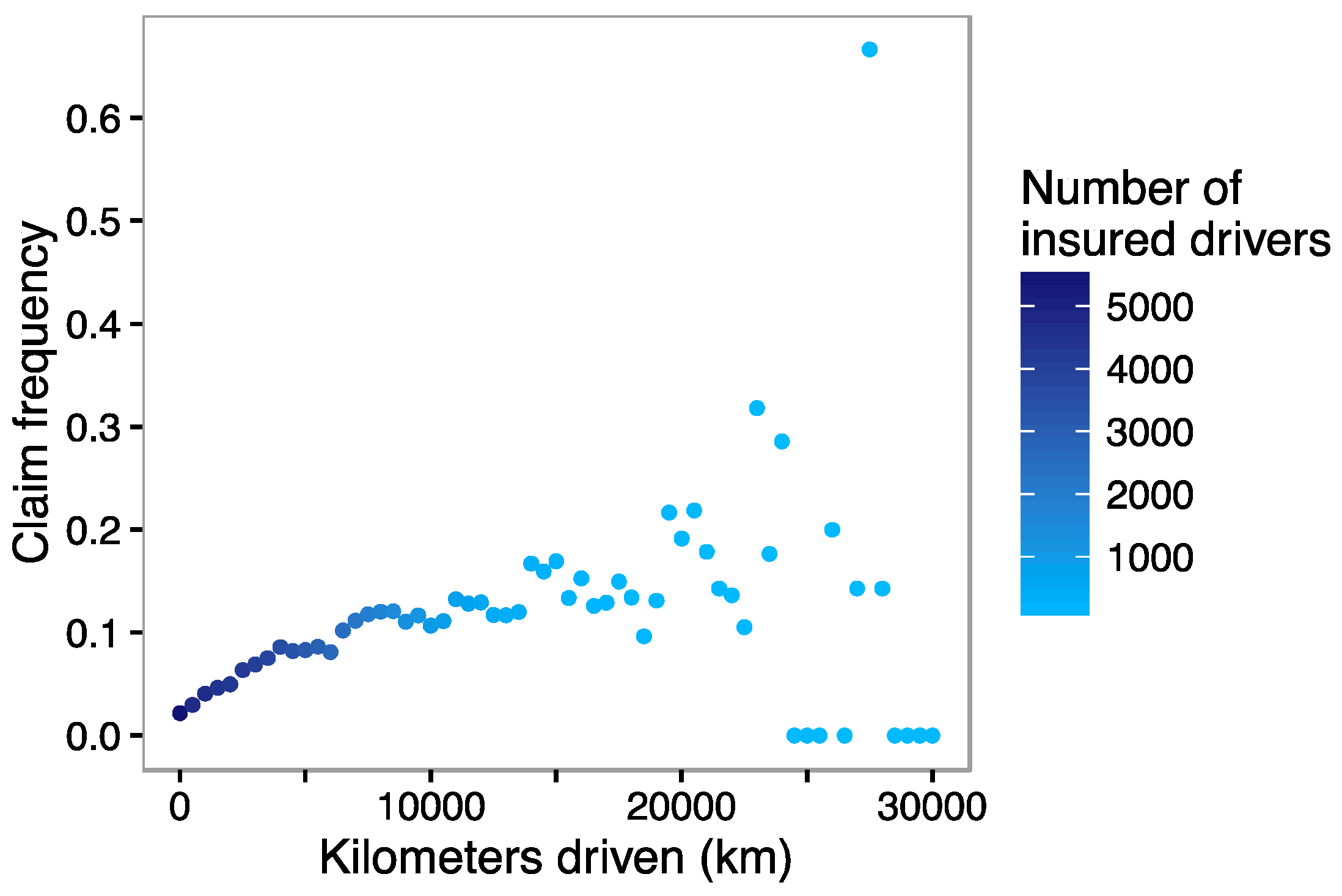
In addition,
Figure 5 shows the lack of proportionality between the log-accident rates and the number of kilometers. The fact that the slope of the curve gradually decreases as the number of kilometers increase, lets us confirm that there are factors that mitigate the risk of accident of more experienced drivers who use more the car, compared to those who drive only occasionally. An intuitive interpretation of this result is that people who drive regularly tend to develop better reflexes and driving skills. Moreover, a large proportion of the distance traveled of the big drivers is done on the road where accidents are less frequent than in urban areas. It would be interesting to carry out further analysis and research that could confirm why we observe this result. The empirical study of
Verbelen et al. (
2017) shows that the proportionality assumption for both exposure duration and distance traveled is too restrictive and that the best model is obtained by simultaneously modeling the effect of the exposure duration and distance traveled using additive splines. By also taking the composition of the distance traveled on different road types, time slots and week vs. weekend into account, these authors obtain a more linear effect for the distance traveled compared to
Figure 5 and
Figure 6. We also note that there are several differences between the approach by these authors and ours. While they have a more general setting with respect to the inclusion of more risk factors into the model, such as the type of road, day of the week and time slot, they somehow evolve from pure distance driven towards to driving habits, i.e., where and when is the vehicle driven. We find this point essential in analyzing the differences between these approaches and moreover, this has an impact on the implementation of telematics pricing. This is discussed in the last section.
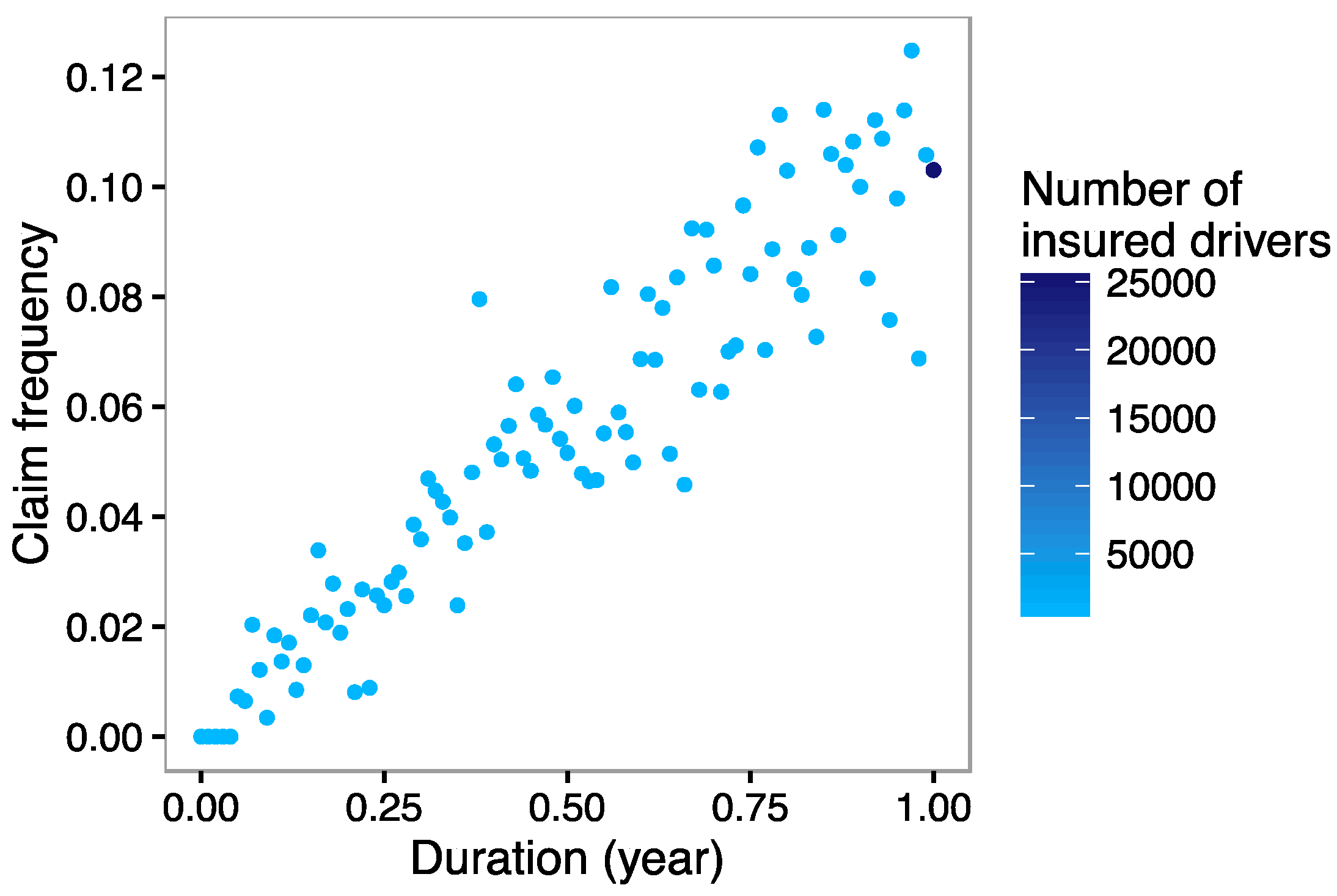
Regarding the second graph in
Figure 5, we observe that the exposure time basically has a linear effect on the liner predictor during the first six months. Thereafter, exposure time still has a positive effect on the risk of accident but it is less pronounced, and finally it has almost no impact after 10 months of observation. These findings may contradict what is applied nowadays in the vast majority of insurance companies, i.e., assuming that the number of accidents is directly proportional to the exposure duration. Therefore, we conclude that it is wrong to say that an insuree covered for a year is twice risky compared to one a covered only for 6 months, if the rest of risk factors are the same. It seems that this statement is not correct. It is interesting to see that this result confirms the conclusions obtained by
Boucher and Denuit (
2007), at least for this sample and given that the drivers know that they are being monitored.
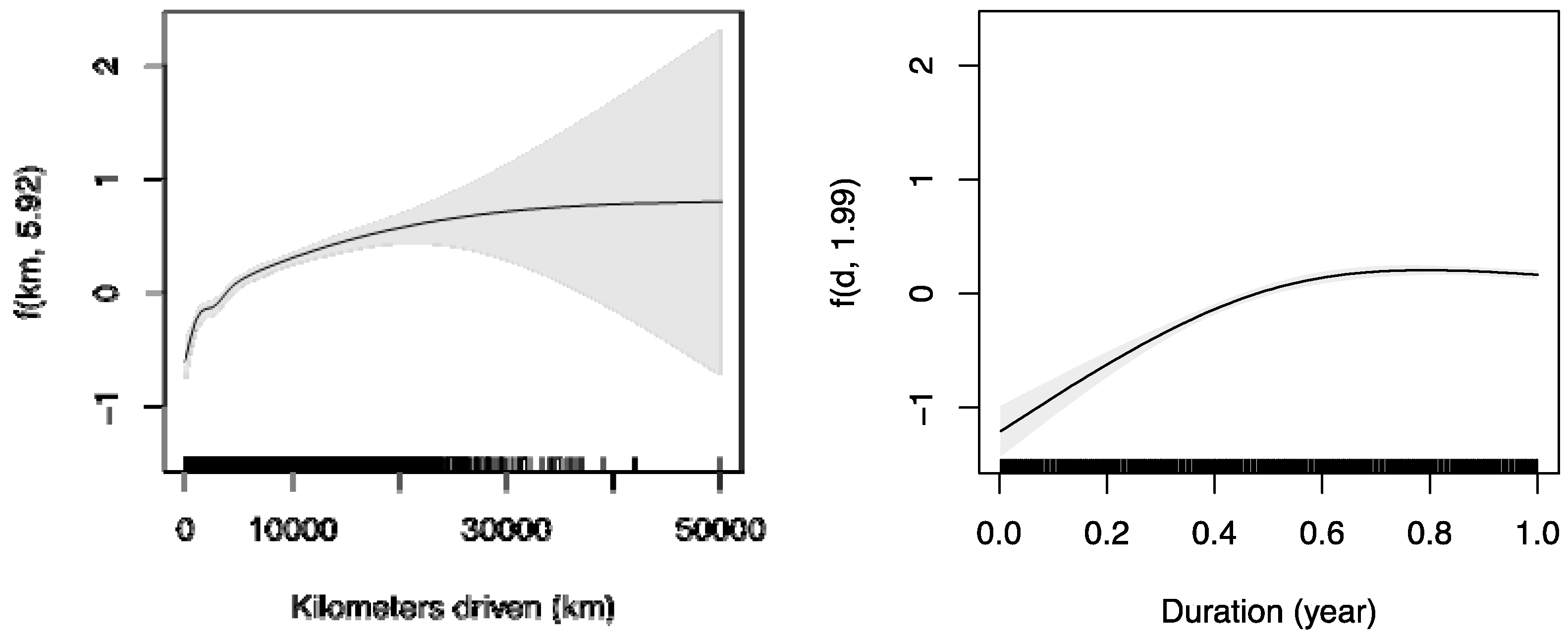
Finally, for comparison,
Figure 6 shows also the adjusted smoothing functions for the claims at fault. Therefore, the conclusions regarding the impact of the duration and distance traveled also seem to be valid for accidents at fault with property damage (
nb1). Once a certain number of traveled kilometers is reached, i.e., from approximately 20,000 km on, we observe a certain difference between the trend of
nb1 and
nb2. However, the corresponding confidence intervals do not seem to confirm a statistically significant difference.
2.2.2. Tensor Product Smoothing Model
For model 1, the distance traveled and exposure duration were introduced as explanatory variables by using cubic smoothing splines. Firstly, they were parameterized completely independently, and later they were estimated.
Now, we are going to show how the addition of an interaction term between the distance traveled and the exposure time changes the results obtained from model 1. We will use the same modeling procedure, i.e., GAM with cubic splines. The difference is that instead of using two separate cubic splines to include the distance traveled and exposure time in the model, we will use a smoothing tensor product base. Broadly speaking, the idea is to introduce a smoothing function for the interaction. It is then possible to evaluate the improvement of the GCV score.
Similarly to model 1, only the distance traveled and exposure duration are used, as these are the variables explaining the number of claims (
nb2) of each insuree. We will denote the number of claims by
and assume that it follows a Poisson distribution. A multiplicative link function is used to relate the expectation with the linear predictor. As mentioned above, the tension product smoothing base is used to define a two-variable function, which is introduced in the GAM. Specifically, the model is formulated as:
where
corresponds to the independent term of the model and
is a smoothing function which depends on the distance (
km) and the duration (
d). The tensor product smoothing base is implemented both in R and SAS software. However, it is also possible to apply the technique by using the procedure described by
Wood (
2006, Section 4.1.8).
Similarly to the model with independent cubic splines, the function is also parameterized by using seven nodes for the distribution of the distance traveled and 3 nodes for the exposure duration. The model defined by Equation (2) will be called model 2.
Table 5 shows the estimation results.
The low
p-values found in
Table 5 show that the nonparametric part of the model 2 is important to explain the number of claims of the policyholders. The value of the GCV score, which is equal to 0.38403, suggests a slight improvement of model 2 with respect to model 1, which provided a GCV score equal to 0.38412. In other words, the added flexibility provided by the tensor product smoothing base results in a slight improvement in the adjustment of the frequency of claims. There are 13.69 effective degrees of freedom in model 2, against 6.25 (4.30 + 1.95) for model 1.
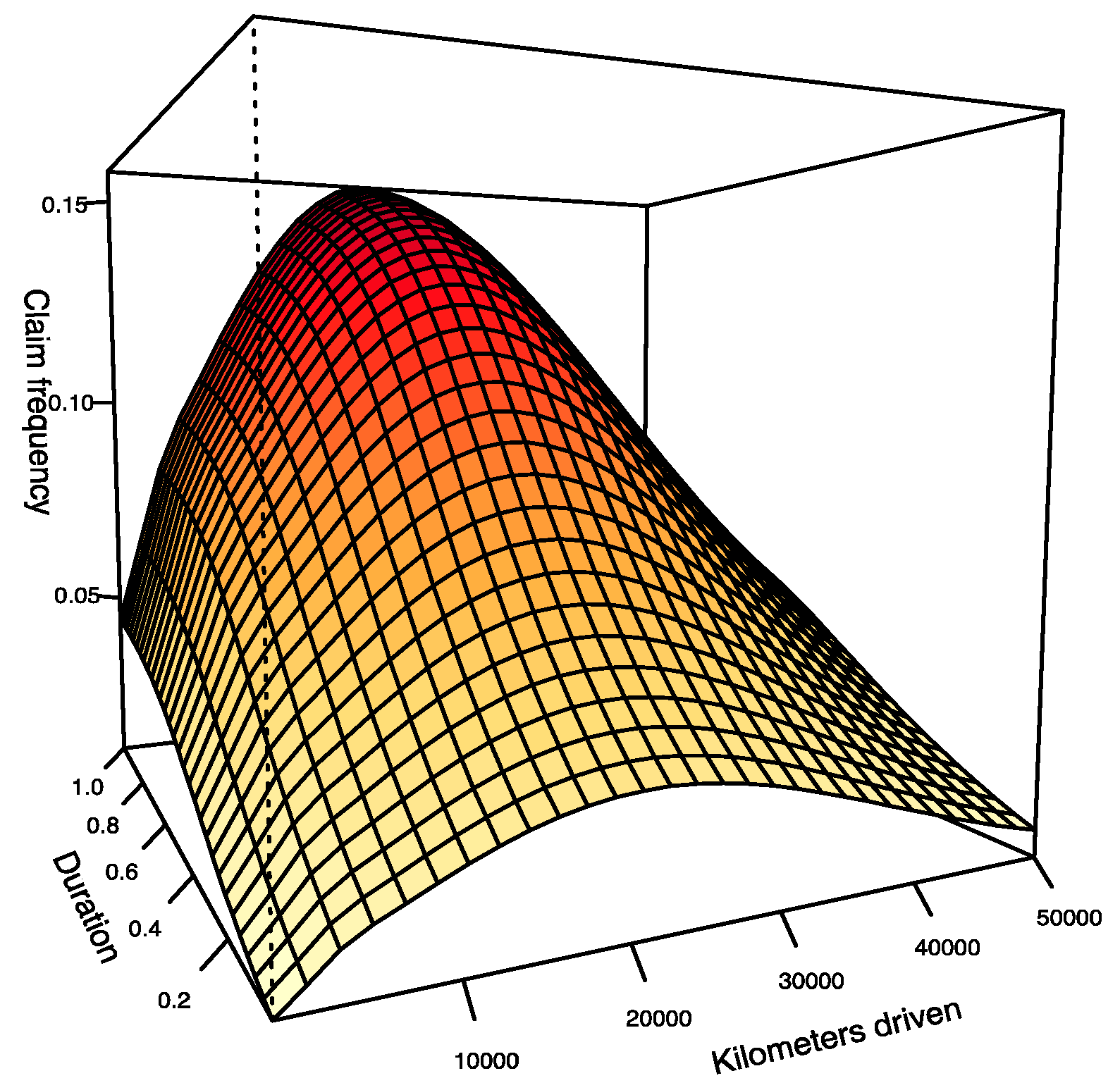
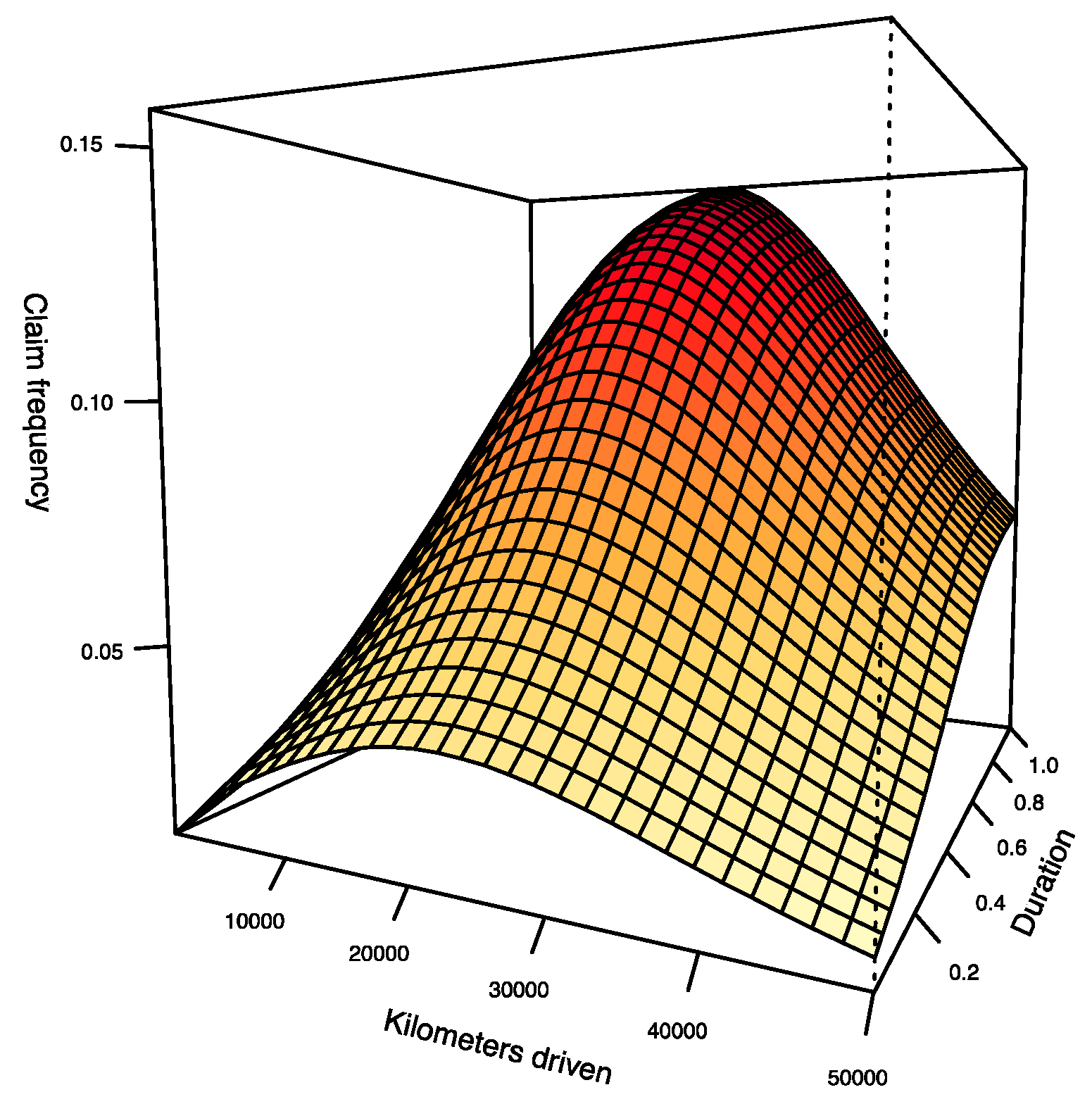
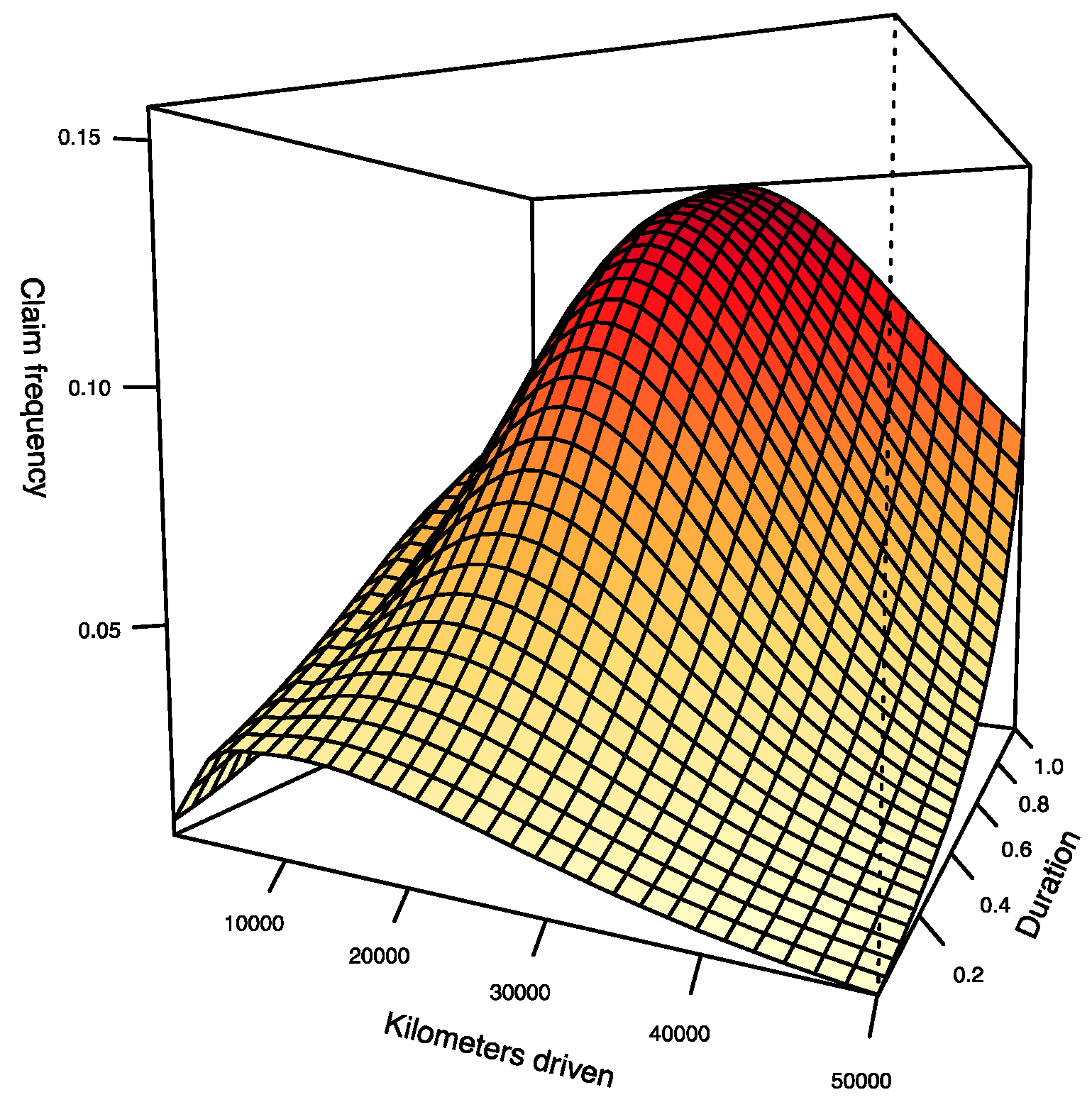
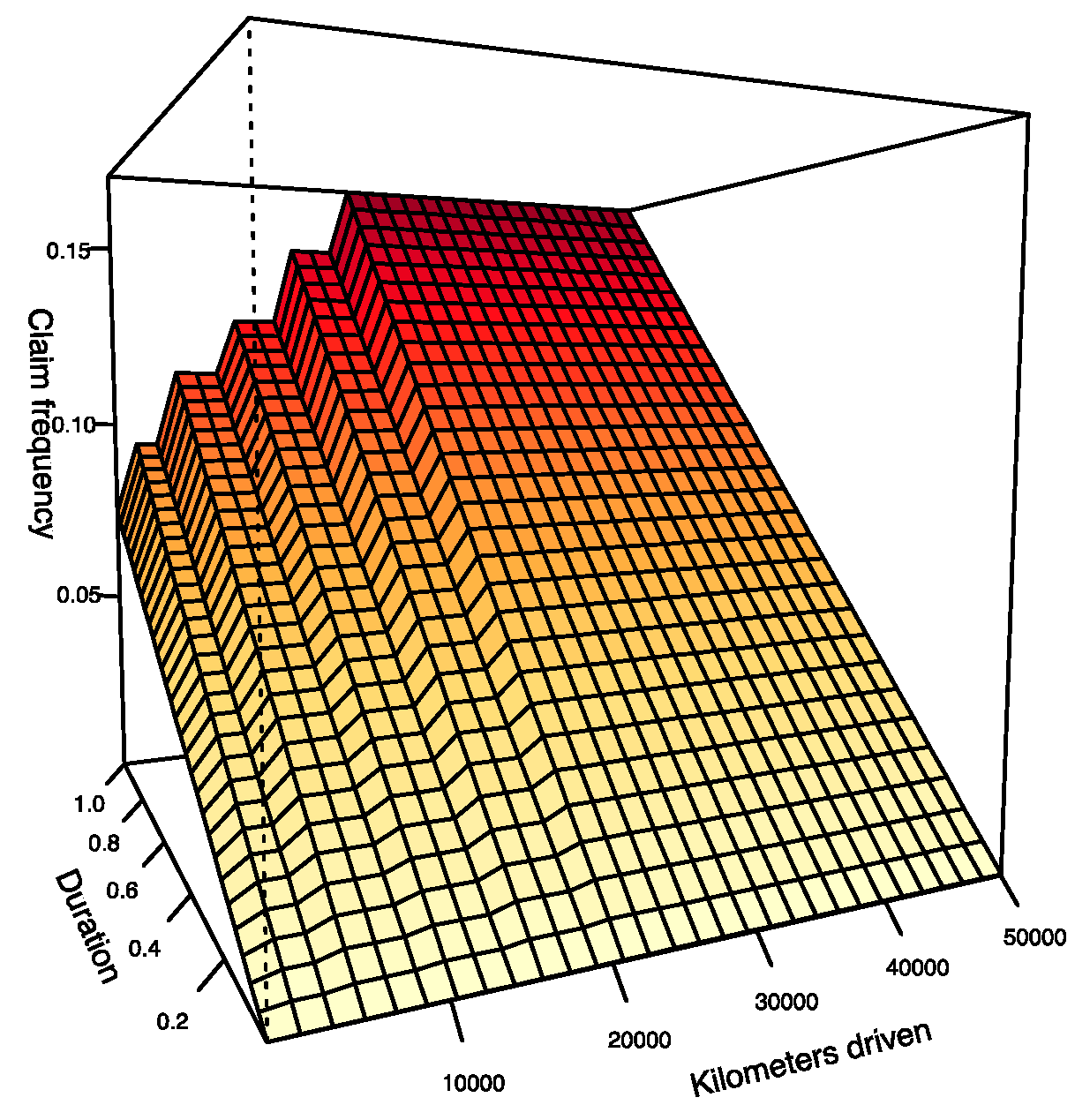
Since function in model 2 is not expressed in terms of km or d separately, it is not possible to analyze the impact of the distance traveled and exposure time independently as we did in model 1. However, Figure 9 shows the surface derived from the predictions produced by the estimation of model 2 for every possible pair . It is interesting to see that the distance traveled has a significant impact for the first 10,000 or 15,000 km in the estimation of the function of model 2. Subsequently, the impact gradually fades. Regarding the duration, we see that the impact seems to be fairly constant on the predicted surface.
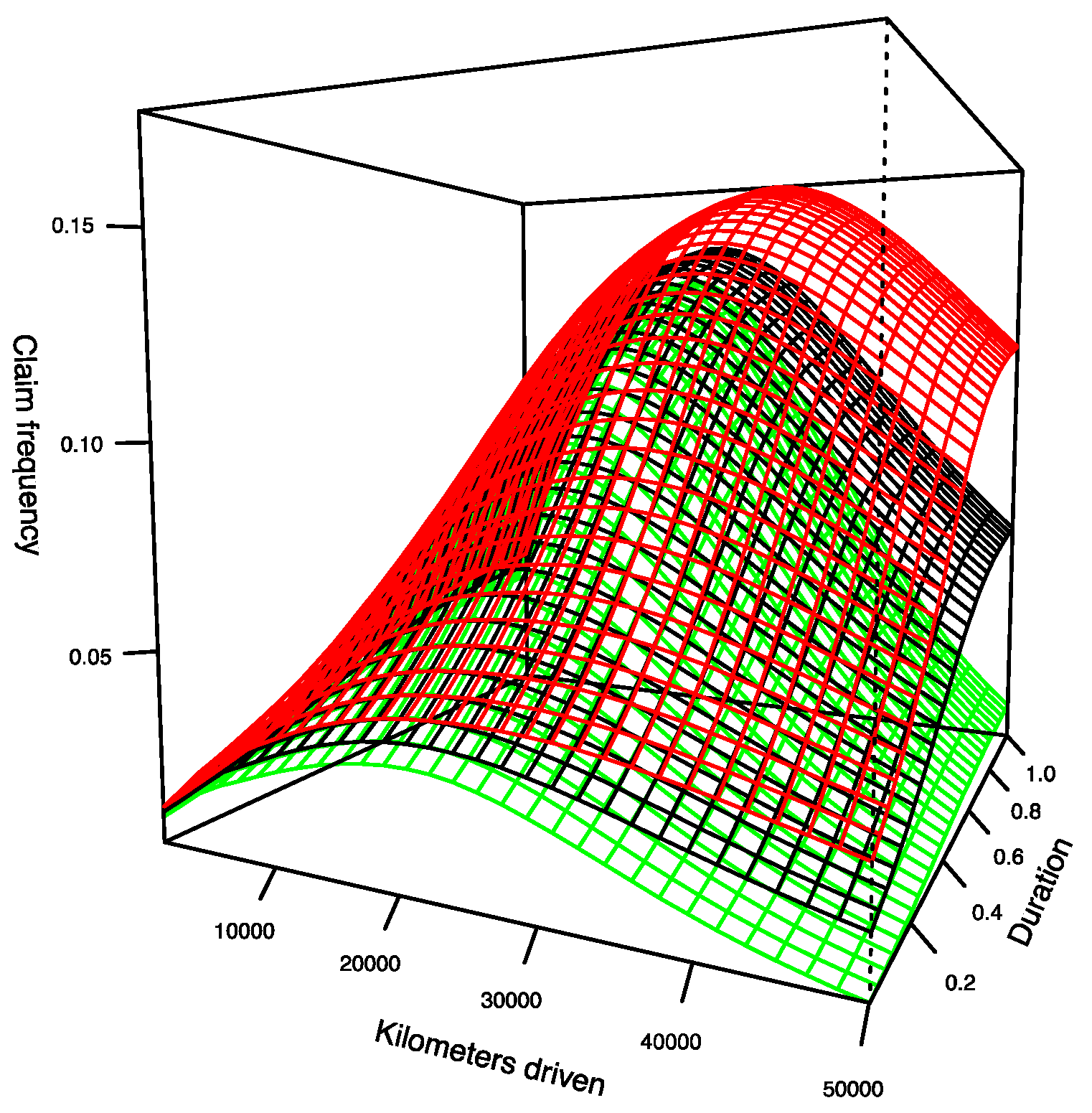
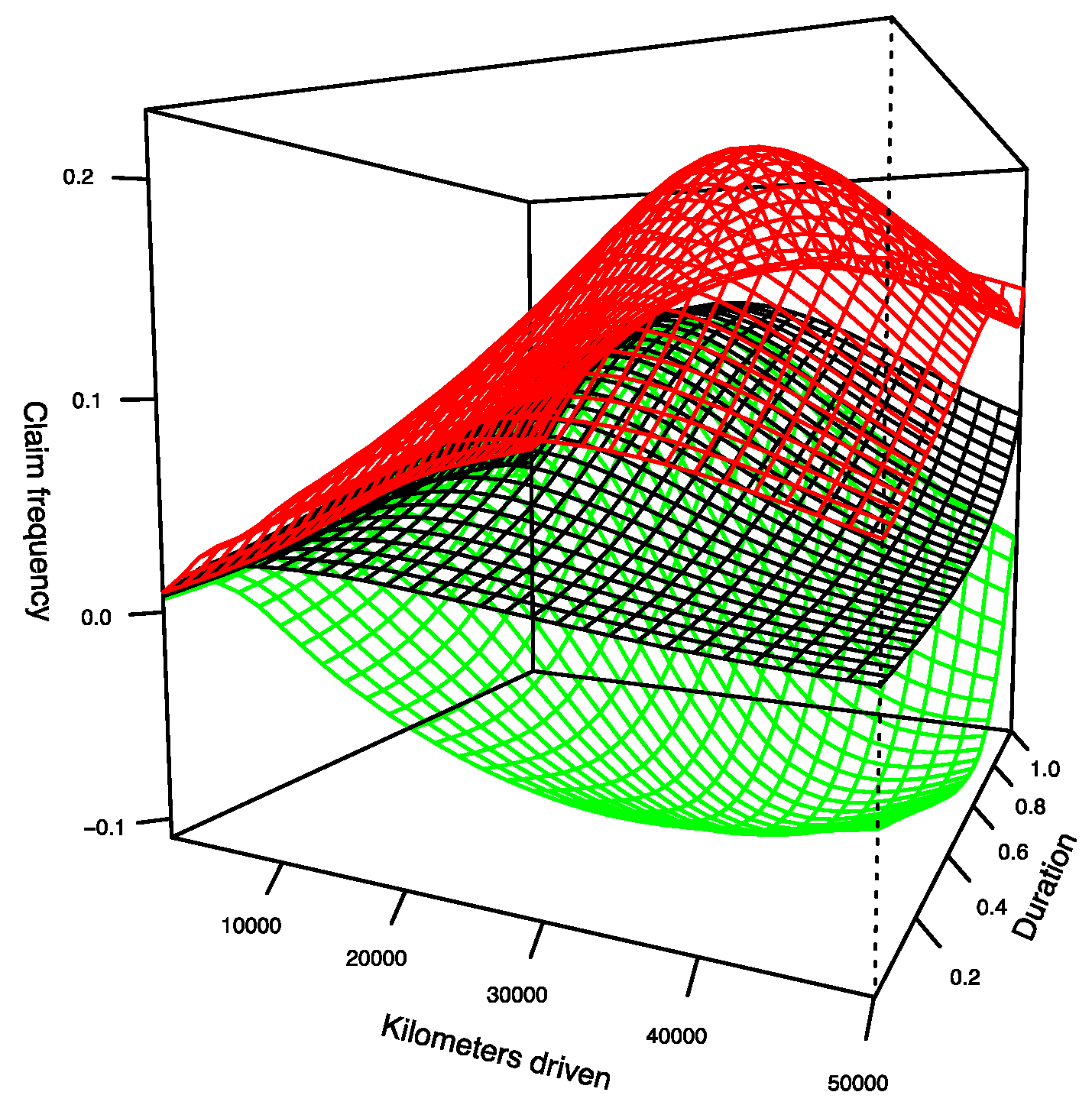
Obviously, when the distance traveled is large, since there are few observations at this level, it is expected that the predictions become much more volatile. In the next section, we compare models 1 and 2 and discuss the differences between them.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}