Non-Parametric Integral Estimation Using Data Clustering in Stochastic dynamic Programming: An Introduction Using Lifetime Financial Modelling


Abstract
:1. Introduction
2. The Basic Model
3. The Single Stochastic Asset Setting
3.1. Alternative Calculations of
3.1.1. Normal Distribution Quadrature (NQ)
3.1.2. Lognormal Distribution Quadrature (LQ)
3.1.3. Data-Driven with Equal-Interval Nodes (DE)
3.1.4. Data-Driven with Unequal-Interval Nodes (DU)
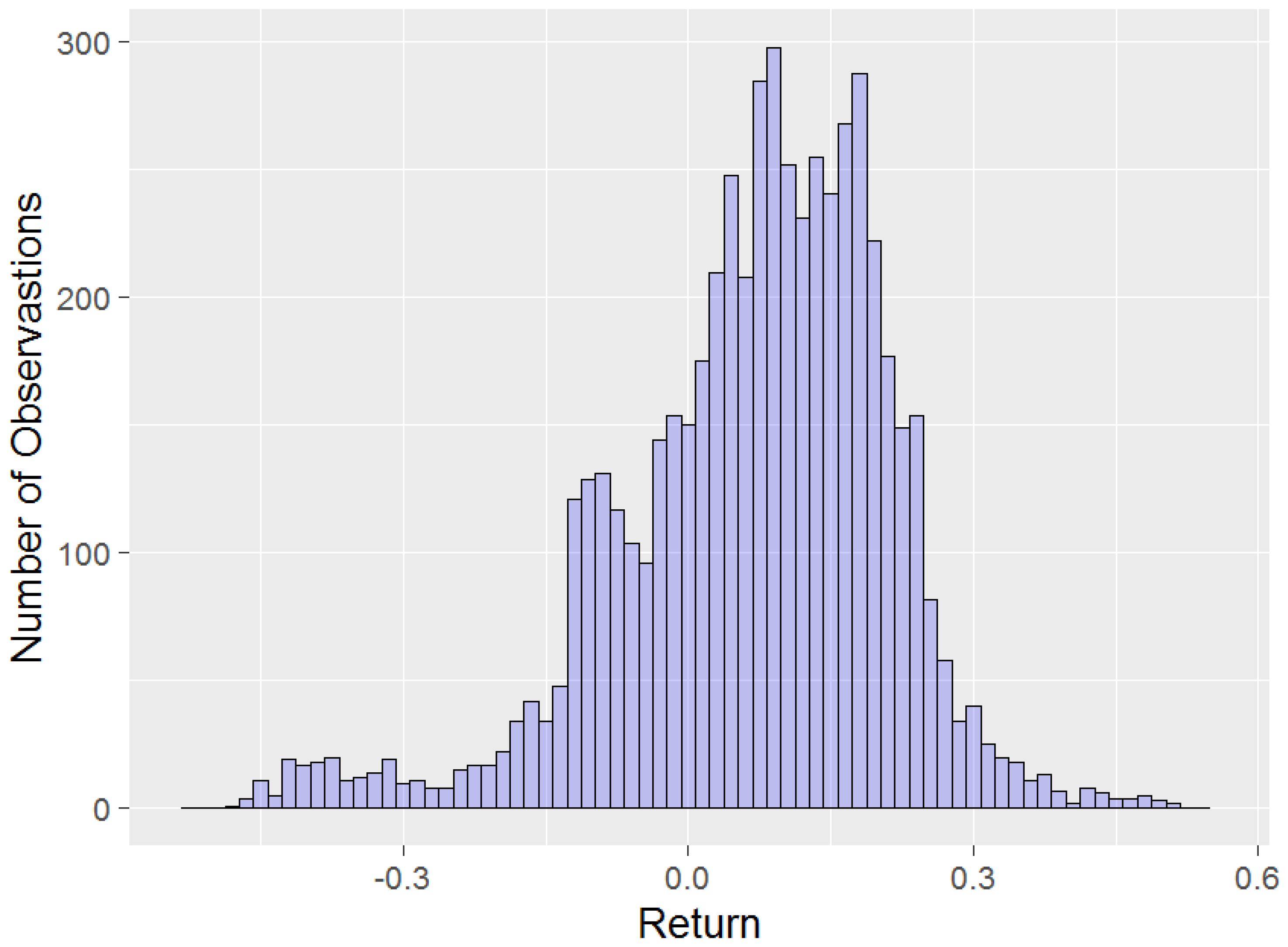
3.2. Results
4. The Multiple Stochastic Asset Setting
4.1. Alternative Calculations of
4.1.1. Weighted Nodes—Quadrature
Weighted Nodes—Normal Distribution Quadrature (WN-NQ)
Weighted Nodes—Lognormal Distribution Quadrature (WN-LQ)
4.1.2. Weighted Nodes—Data-Driven
Weighted Nodes—Data-Driven and Equal-Interval Grid (WN-DE-G)
Weighted Nodes—Data-Driven and Equal-Interval Hierarchy (WN-DE-H)
Weighted Nodes—Data-Driven and Unequal-Interval Grid (WN-DU)
4.1.3. Quasi-Monte Carlo
Quasi-Monte Carlo—Normal Distribution (QMC-N)
Quasi-Monte Carlo—Lognormal Distribution (QMC-L)
Quasi-Monte Carlo—Data-Driven (QMC-D)
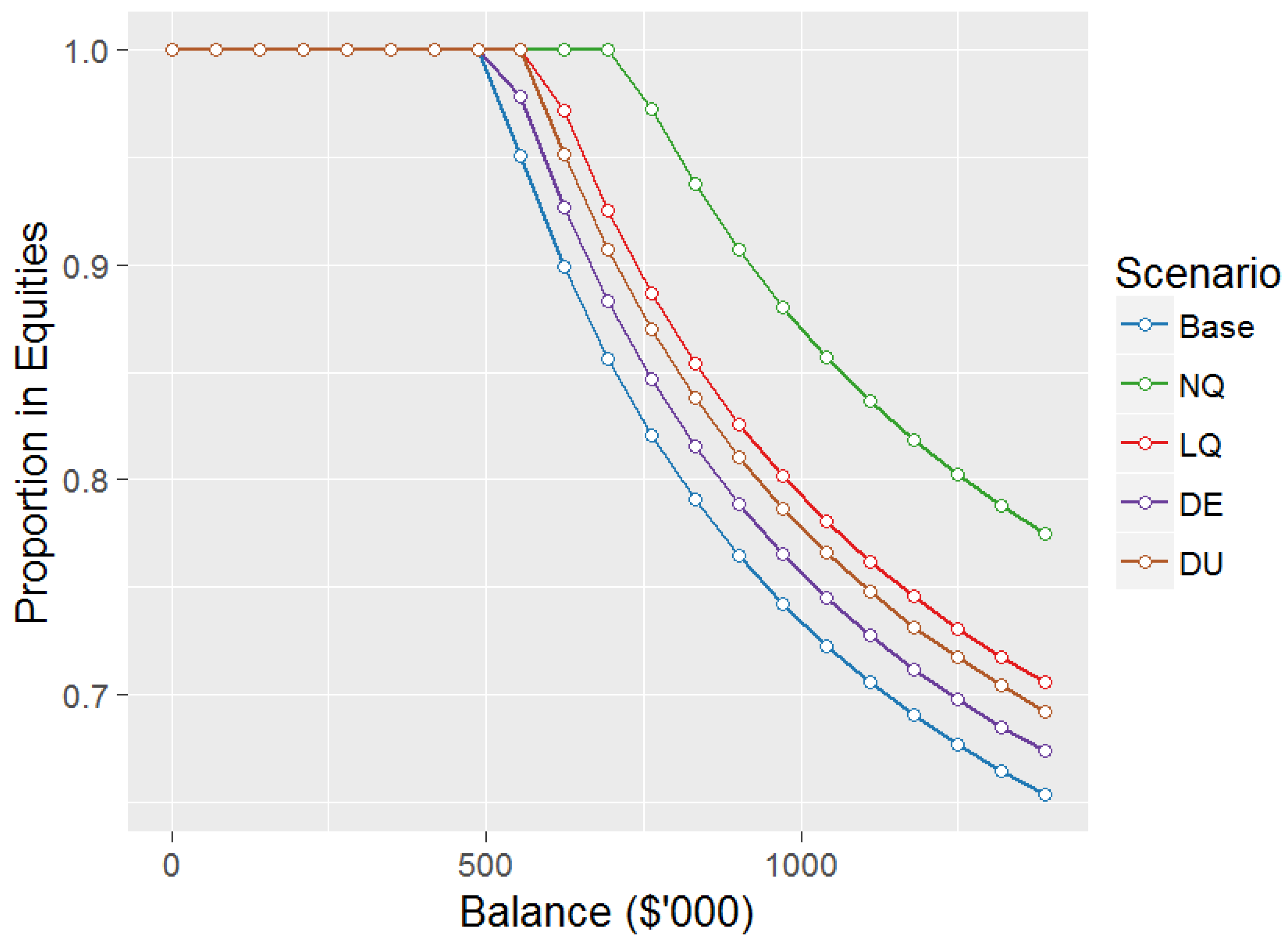
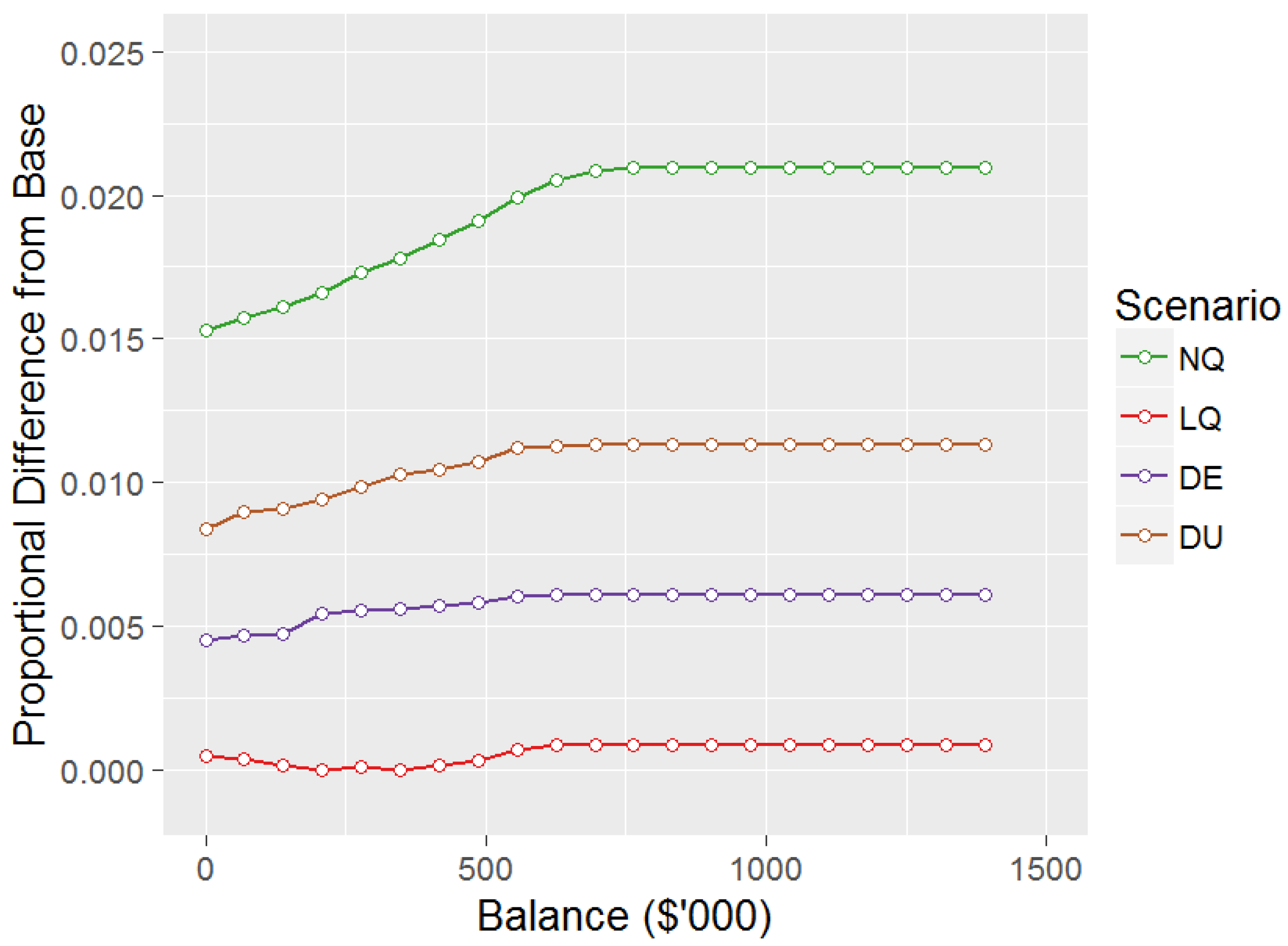
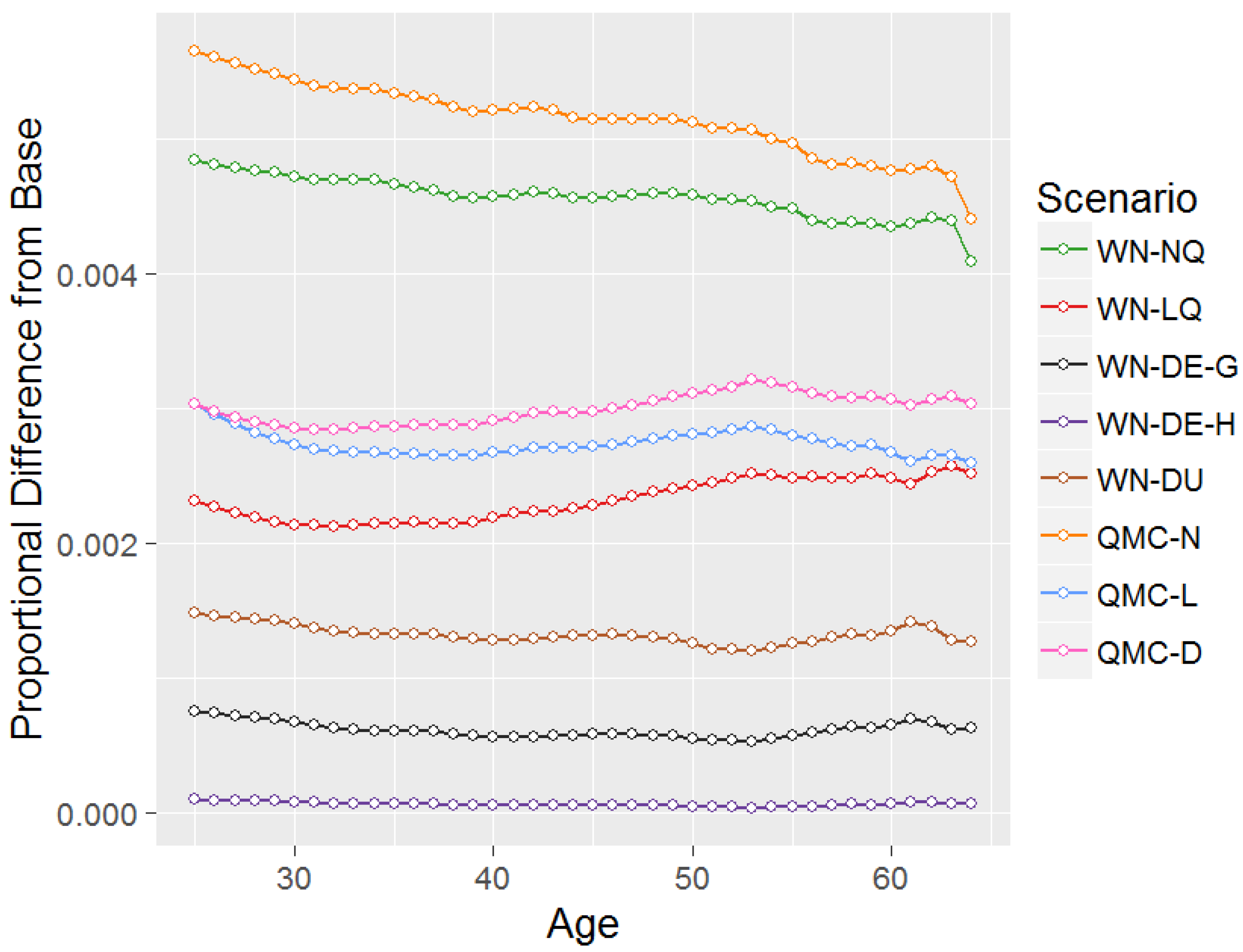
4.2. Results
5. Conclusions and Future Research
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ASX | Australian Stock Exchange |
| AU | Australia |
| AWE | AverageWeekly Earnings |
| CRRA | Constant Relative Risk Aversion |
| DE | Data-driven with Equal-interval nodes |
| DU | Data-driven with Unequal-interval nodes |
| LQ | Lognormal distribution Quadrature |
| MDPI | Multidisciplinary Digital Publishing Institute |
| MSCI | Morgan Stanley Capital International |
| NQ | Normal distribution Quadrature |
| QMC | Quasi-Monte Carlo |
| QMC-D | Quasi-Monte Carlo - Data-driven |
| QMC-L | Quasi-Monte Carlo - Lognormal distribution |
| QMC-N | Quasi-Monte Carlo - Normal distribution |
| S&P | Standard & Poor’s |
| UBS | Union Bank of Switzerland |
| US | the United States of America |
| WN-DE-G | Weighted Nodes-Data-driven and Equal-interval Grid |
| WN-DE-H | Weighted Nodes-Data-driven and Equal-interval Hierarchy |
| WN-DU | Weighted Nodes-Data-driven and Unequal-interval grid |
| WN-LQ | Weighted Nodes-Lognormal distribution Quadrature |
| WN-NQ | Weighted Nodes-Normal distribution Quadrature |
References
- Australian Government Actuary. 2014. Australian Life Tables 2010-12; Canberra: Commonwealth of Australia.
- Bellman, Richard. 1957. Dynamic Programming, 1st ed. Princeton: Princeton University Press. [Google Scholar]
- Blake, David, Douglas Wright, and Yumeng Zhang. 2013. Target-driven investing: Optimal investment strategies in defined contribution pension plans under loss aversion. Journal of Economic Dynamics and Control 37: 195–209. [Google Scholar] [CrossRef]
- Bodie, Zvi, Robert C. Merton, and William F. Samuelson. 1992. Labor supply flexibility and portfolio choice in a life cycle model. Journal of Economic Dynamics and Control 16: 427–49. [Google Scholar] [CrossRef]
- Boyle, Phelim, Junichi Imai, and Ken Seng Tan. 2002. Asset Allocation Using Quasi Monte Carlo Methods. Working paper, University of Waterloo, Waterloo, ON, Canada. [Google Scholar]
- Butt, Adam, and Gaurav Khemka. 2015. The effect of objective formulation on retirement decision making. Insurance: Mathematics and Economics 64: 385–95. [Google Scholar] [CrossRef]
- Cai, Yongyang, and Kenneth L. Judd. 2010. Stable and efficient computational methods for dynamic programming. Journal of the European Economic Association 8: 626–34. [Google Scholar] [CrossRef]
- Campbell, John Y., Yeung Lewis Chan, and Luis M. Viceira. 2003. A multivariate model of strategic asset allocation. Journal of Financial Economics 67: 41–80. [Google Scholar] [CrossRef] [Green Version]
- Carroll, Christopher D. 2006. The method of endogenous gridpoints for solving dynamic stochastic optimization problems. Economics Letters 91: 312–20. [Google Scholar] [CrossRef]
- Dick, Josef, Frances Y. Kuo, and Ian H. Sloan. 2013. High-dimensional integration: The quasi-monte carlo way. Acta Numerica 22: 133–288. [Google Scholar] [CrossRef]
- Efron, Bradley, and Robert J. Tibshirani. 1994. An Introduction to the Bootstrap. Boca Raton: CRC Press. [Google Scholar]
- Fama, Eugene F. 1965. The behavior of stock-market prices. The Journal of Business 38: 34–105. [Google Scholar] [CrossRef]
- Fraley, Chris, and Adrian E. Raftery. 1998. How Many Clusters? Which Clustering Method? Answers via Model-Based Cluster Analysis. The Computer Journal 41: 578–88. [Google Scholar] [CrossRef]
- Gerrard, Russell, Steven Haberman, and Elena Vigna. 2006. The management of decumulation risks in a defined contribution pension plan. North American Actuarial Journal 10: 84–110. [Google Scholar] [CrossRef]
- Haberman, Steven, and Elena Vigna. 2002. Optimal investment strategies and risk measures in defined contribution pension schemes. Insurance: Mathematics and Economics 31: 35–69. [Google Scholar] [CrossRef]
- Halton, John H. 1964. Algorithm 247: Radical-inverse quasi-random point sequence. Communications of the ACM 7: 701–2. [Google Scholar] [CrossRef]
- Hanewald, Katja, John Piggott, and Michael Sherris. 2013. Individual post-retirement longevity risk management under systematic mortality risk. Insurance: Mathematics and Economics 52: 87–97. [Google Scholar] [CrossRef]
- Heiss, Florian, and Viktor Winschel. 2008. Likelihood approximation by numerical integration on sparse grids. Journal of Econometrics 144: 62–80. [Google Scholar] [CrossRef] [Green Version]
- Horneff, Vanya, Raimond Maurer, Olivia S. Mitchell, and Ralph Rogalla. 2015. Optimal life cycle portfolio choice with variable annuities offering liquidity and investment downside protection. Insurance: Mathematics and Economics 63: 91–107. [Google Scholar] [CrossRef]
- Hulley, Hardy, Rebecca Mckibbin, Andreas Pedersen, and Susan Thorp. 2013. Means-tested public pensions, portfolio choice and decumulation in retirement. Economic Record 89: 31–51. [Google Scholar] [CrossRef]
- Kopcke, Richard W., Anthony Webb, and Joshua Hurwitz. 2013. Rethinking Optimal Wealth Accumulation and Decumulation Strategies in the Wake of the Financial Crisis. Working paper, Center for Retirement Research at Boston College, Chestnut Hill, MA, USA. [Google Scholar]
- Korn, Ralf, Tak Kuen Siu, and Aihua Zhang. 2011. Asset allocation for a dc pension fund under regime switching environment. European Actuarial Journal 1: 361–77. [Google Scholar] [CrossRef]
- Lyon, John D., Brad M. Barber, and Chih-Ling Tsai. 1999. Improved methods for tests of long-run abnormal stock returns. The Journal of Finance 54: 165–201. [Google Scholar] [CrossRef]
- Merton, Robert C. 1969. Lifetime portfolio selection under uncertainty: The continuous-time case. The Review of Economics and Statistics 51: 247–57. [Google Scholar] [CrossRef]
- Michaelides, Alexander, and Yuxin Zhang. 2015. Stock market mean reversion and portfolio choice over the life cycle. Journal of Financial and Quantitative Analysis 52: 1183–209. [Google Scholar] [CrossRef]
- Parzen, Emanuel. 1962. On estimation of a probability density function and mode. The Annals of Mathematical Statistics 33: 1065–76. [Google Scholar] [CrossRef]
- Pirvu, Traian A., and Huayue Zhang. 2012. Optimal investment, consumption and life insurance under mean-reverting returns: The complete market solution. Insurance: Mathematics and Economics 51: 303–9. [Google Scholar] [CrossRef]
- Poterba, James M., and Lawrence H. Summers. 1988. Mean reversion in stock prices. Journal of Financial Economics 22: 27–59. [Google Scholar] [CrossRef]
- Samuelson, Paul A. 1969. Lifetime portfolio selection by dynamic stochastic programming. The Review of Economics and Statistics 51: 239–46. [Google Scholar] [CrossRef]
- Shapiro, Arnold F. 2010. Post-Retirement Financial Strategies from the Perspective of an Individual Who Is Approaching Retirement Age. Society of Actuaries 71: 74. [Google Scholar]
- Wilkie, A. David. 1995. More on a stochastic asset model for actuarial use. British Actuarial Journal 1: 777–964. [Google Scholar] [CrossRef]
- Yaari, Menahem E. 1987. The dual theory of choice under risk. Econometrica 55: 95–115. [Google Scholar] [CrossRef]
- Zou, Bin, and Abel Cadenillas. 2014. Explicit solutions of optimal consumption, investment and insurance problems with regime switching. Insurance: Mathematics and Economics 58: 159–67. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | NQ | LQ | DE | DU | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | −58.34% | 0.00002 | −45.89% | 0.00002 | −41.35% | 0.01563 | N/A* | 0.00000 |
| 2 | −39.43% | 0.00279 | −34.29% | 0.00279 | −32.25% | 0.01671 | −38.37% | 0.02641 |
| 3 | −23.11% | 0.04992 | −22.28% | 0.04992 | −19.33% | 0.02911 | −21.11% | 0.03414 |
| 4 | −7.88% | 0.24410 | −9.11% | 0.24410 | −9.27% | 0.13223 | −7.00% | 0.19817 |
| 5 | 6.92% | 0.40635 | 5.82% | 0.40635 | 1.84% | 0.23733 | 7.46% | 0.41197 |
| 6 | 21.71% | 0.24410 | 23.20% | 0.24410 | 12.16% | 0.34765 | 19.74% | 0.30004 |
| 7 | 36.95% | 0.04992 | 44.09% | 0.04992 | 21.63% | 0.18829 | 34.29% | 0.02641 |
| 8 | 53.26% | 0.00279 | 70.40% | 0.00279 | 32.55% | 0.02695 | 47.84% | 0.00287 |
| 9 | 72.17% | 0.00002 | 106.95% | 0.00002 | 45.13% | 0.00611 | N/A * | 0.00000 |
| Statistic | Base | NQ | LQ | DE | DU |
|---|---|---|---|---|---|
| Arithmetic mean (p.a.) | 6.92% | 6.92% | 6.99% | 6.92% | 6.92% |
| Standard deviation (p.a.) | 14.46% | 14.46% | 15.99% | 14.14% | 13.91% |
| Skewness | −0.8023 | 0.0000 | 0.4517 | −0.8619 | −0.8801 |
| Kurtosis (Excess) | 1.3743 | 0.0000 | 0.3649 | 1.5314 | 1.5602 |
| Statistic | Arithmetic Mean (p.a.) | Standard Deviation (p.a.) | Skewness | Kurtosis (Excess) |
|---|---|---|---|---|
| Domestic Equities (ed) | 5.76% | 16.52% | −0.4437 | 0.3886 |
| International Equities (ei) | 7.66% | 23.00% | 0.7391 | 3.5079 |
| Domestic Fixed Interest (fd) | 0.94% | 5.02% | 0.3106 | −0.3217 |
| International Fixed Interest (fi) | 2.99% | 11.90% | 0.0464 | −0.2338 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khemka, G.; Butt, A. Non-Parametric Integral Estimation Using Data Clustering in Stochastic dynamic Programming: An Introduction Using Lifetime Financial Modelling. Risks 2017, 5, 57. https://doi.org/10.3390/risks5040057
Khemka G, Butt A. Non-Parametric Integral Estimation Using Data Clustering in Stochastic dynamic Programming: An Introduction Using Lifetime Financial Modelling. Risks. 2017; 5(4):57. https://doi.org/10.3390/risks5040057
Chicago/Turabian StyleKhemka, Gaurav, and Adam Butt. 2017. "Non-Parametric Integral Estimation Using Data Clustering in Stochastic dynamic Programming: An Introduction Using Lifetime Financial Modelling" Risks 5, no. 4: 57. https://doi.org/10.3390/risks5040057
APA StyleKhemka, G., & Butt, A. (2017). Non-Parametric Integral Estimation Using Data Clustering in Stochastic dynamic Programming: An Introduction Using Lifetime Financial Modelling. Risks, 5(4), 57. https://doi.org/10.3390/risks5040057