The Impact of Sovereign Yield Curve Differentials on Value-at-Risk Forecasts for Foreign Exchange Rates

Abstract
:1. Introduction
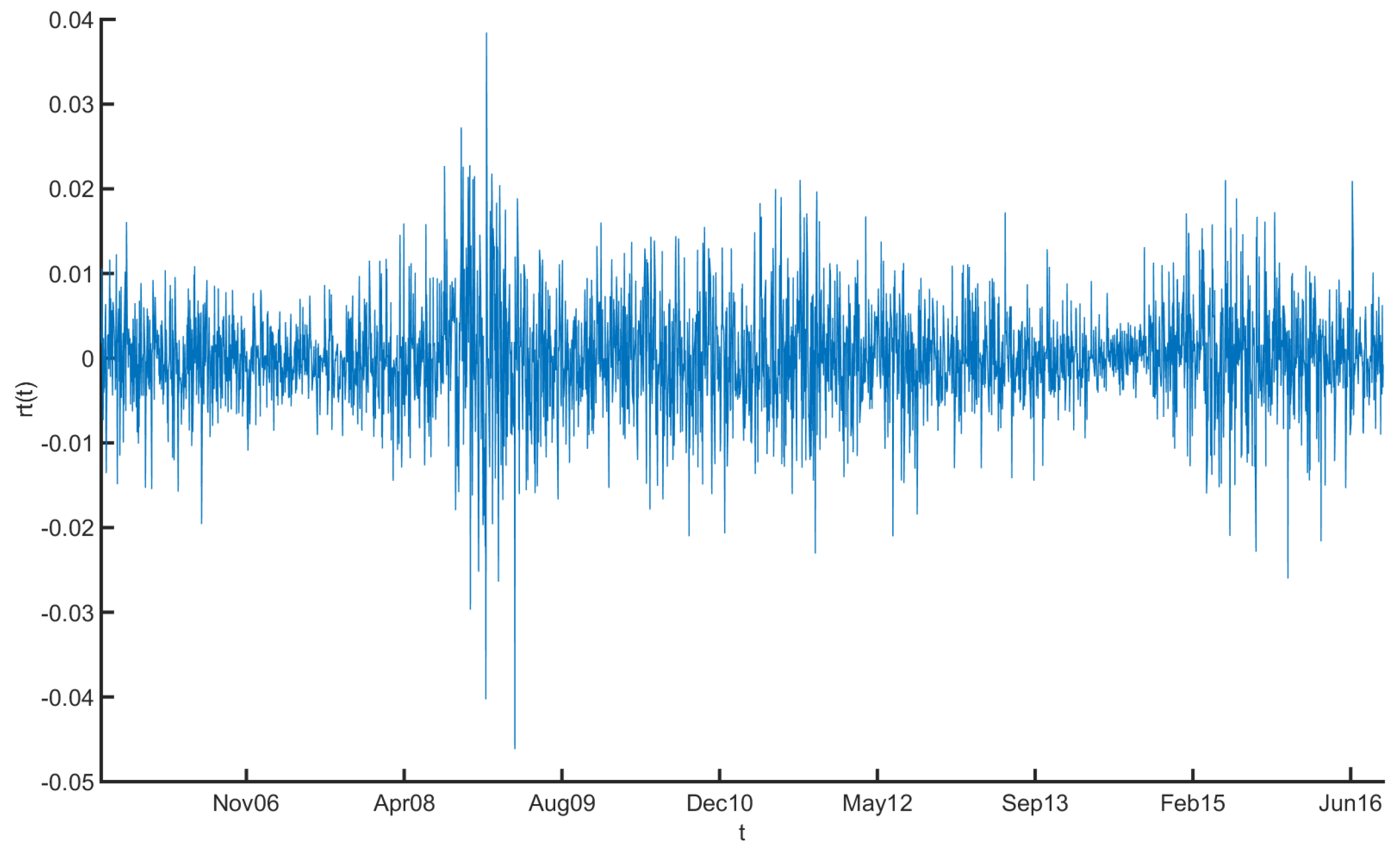
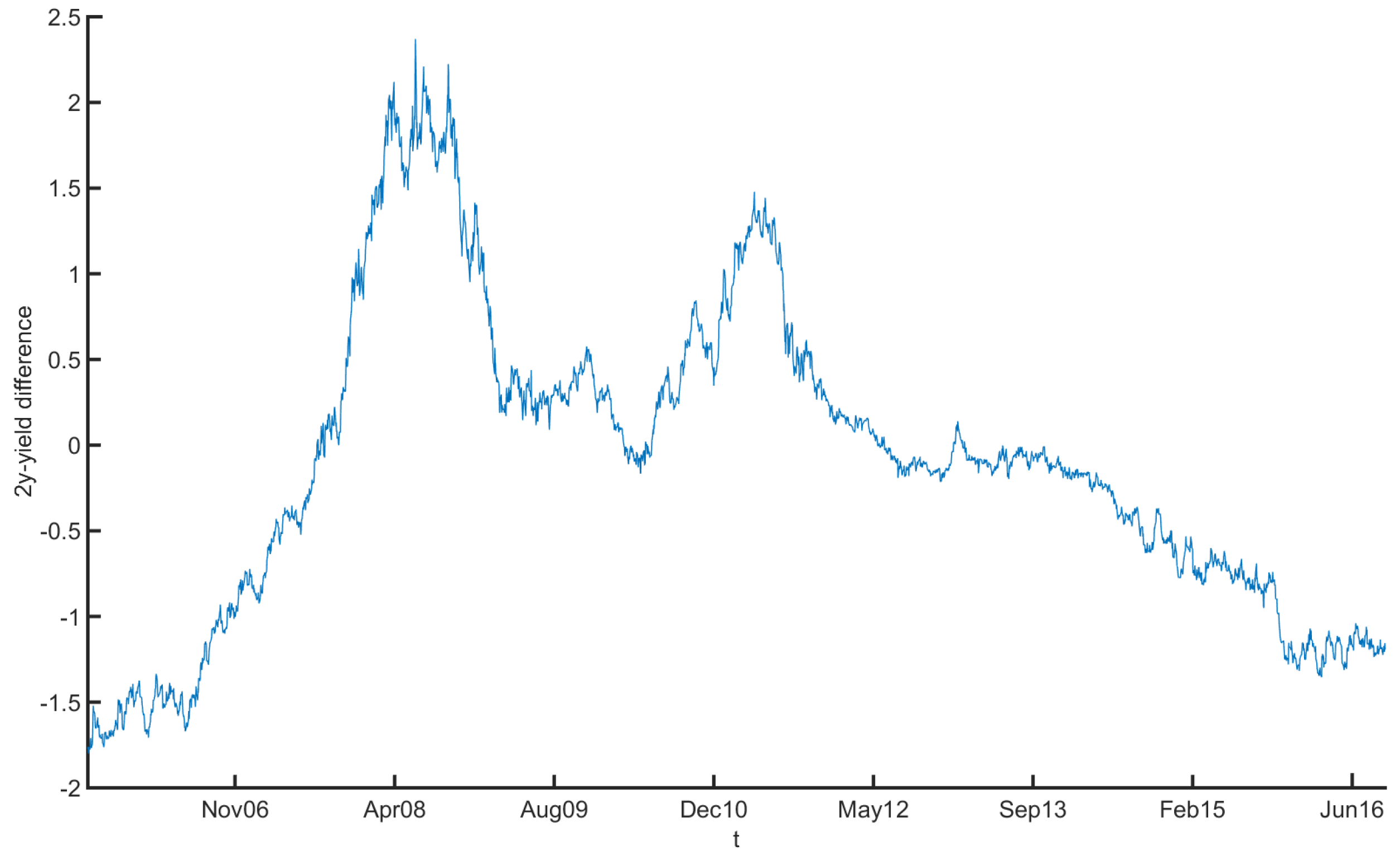
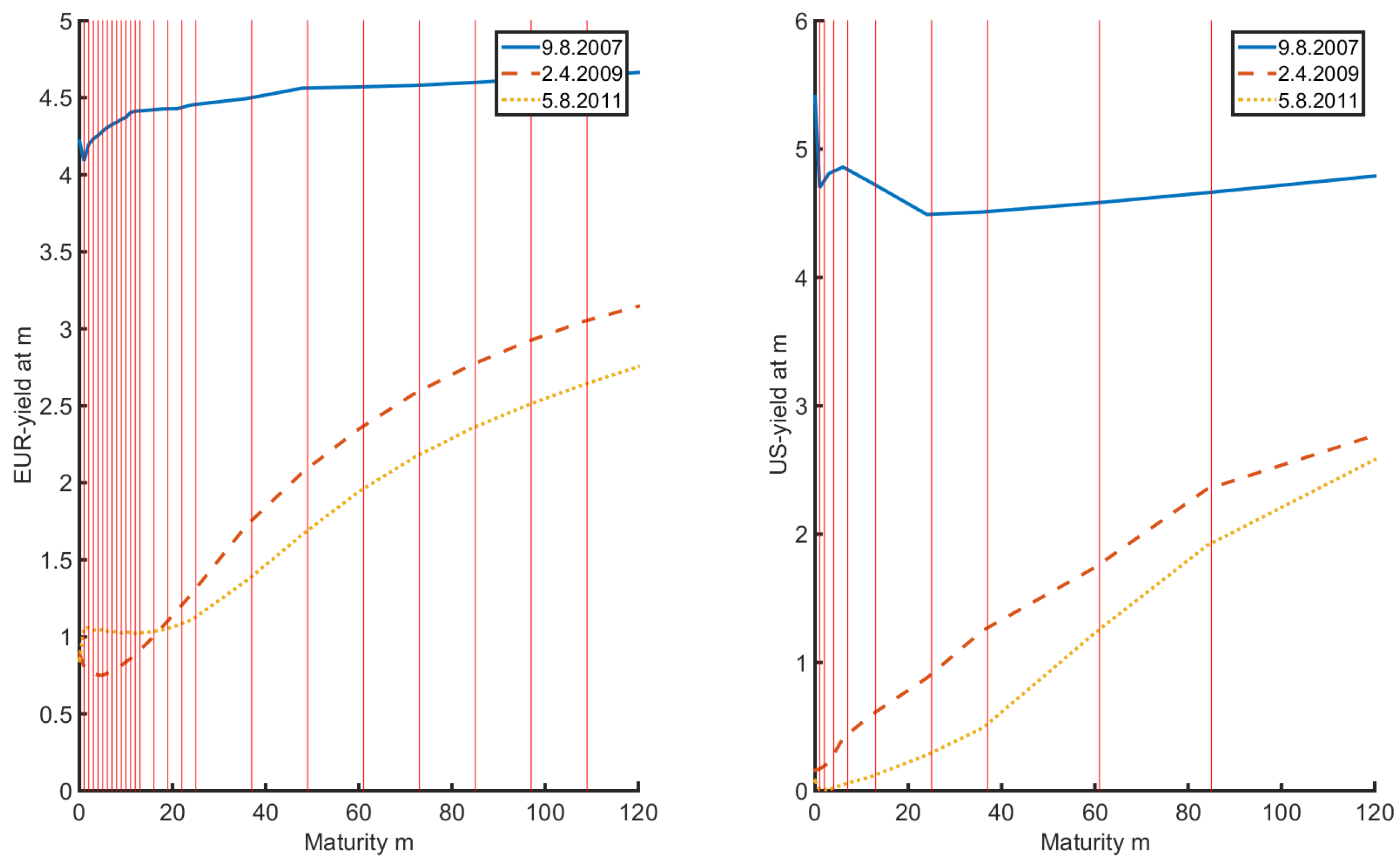
2. Data
3. Theory and Methods
3.1. Functional Principal Components
3.2. Econometric Model
- is the FX rate EURUSD
- is the sovereign rate curve for the US
- is the sovereign rate curve for EUR.
- Estimation of the curved valued process via an orthonormal FPC expansion:where the true values of and are unknown and the are obtained via numerical integration (see Section 3.1).
- Estimation of the ARMA-FunX parameters using the scores for and from Step 1 and the return data by Gaussian QML.
- Gaussian QML estimation of the GARCH-FunX parameters using the scores for , from Step 1 and the estimated errors from Step 2.
- We force past volatility to influence present volatility positively, so we choose (see Francq et al. (2013).)
- Past errors should positively influence present volatility, leading to the choice
4. Results
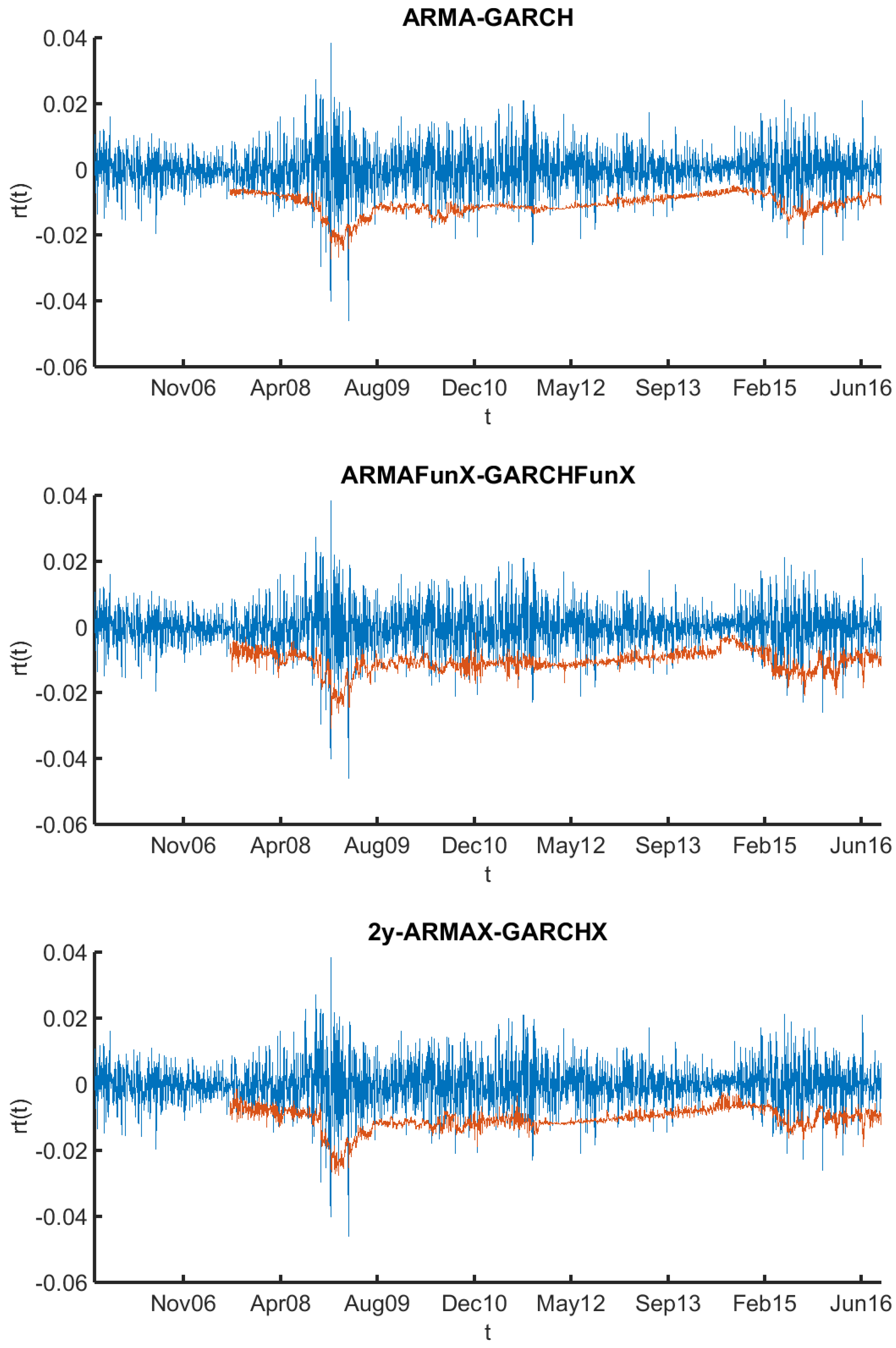
4.1. Model Fit
4.2. VaR Backtesting
- Firstly, we have the unconditional coverage (uc) test, which assumes the independence of the violations and tests the hypothesis that the empirical percentage of violations is equal to the expected p.
- The independence test (ind) checks for the independence of violations or detects clustering, respectively.
- Finally, there is the conditional coverage (cc) test that compares the empirical percentage of violations and the expected percentage as the unconditional coverage test does, but considers a possible dependence structure of the violations. We may treat it as a combination of the former two tests.
- The statistics and for the uc test and the ind test are -distributed with one degree of freedom, whereas the , the one for the cc test, is -distributed with two degrees of freedom.
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Ang, Andrew, and Chen Joseph. 2010. Yield Curve Predictors of Foreign Exchange Returns. Paper presented at AFA 2011 Denver Meetings, Denver, CO, USA, January 7–9. [Google Scholar] [Green Version]
- Aue, Alexander, Diogo Dubart Norinho, and Siegfried Hörmann. 2015. On the prediction of stationary functional time series. Journal of the American Statistical Association 110: 378–92. [Google Scholar] [CrossRef]
- Baillie, Richard T., and Tim Bollerslev. 1991. Intra-day and inter-market volatility in foreign exchange rates. The Review of Economic Studies 58: 565–85. [Google Scholar] [CrossRef]
- Baillie, Richard T., Tim Bollerslev, and Hans Ole Mikkelsen. 1996. Fractionally integrated generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 74: 3–30. [Google Scholar] [CrossRef]
- Bauwens, Luc, and Genaro Sucarrat. 2010. General-to-specific modelling of exchange rate volatility: A forecast evaluation. International Journal of Forecasting 26: 885–907. [Google Scholar] [CrossRef] [Green Version]
- Benavides, Guillermo, and Carlos Capistràn. 2012. Forecasting exchange rate volatility: The superior performance of conditional combinations of time series and option implied forecasts. Journal of Empirical Finance 19: 627–39. [Google Scholar] [CrossRef]
- Bjørnland, Hilde C., and Håvard Hungnes. 2006. The importance of interest rates for forecasting the exchange rate. Journal of Forecasting 25: 209–21. [Google Scholar] [CrossRef]
- Bosq, Denis. 2000. Linear Processes in Function Spaces: Theory and Applications. Berlin: Springer. [Google Scholar]
- Brockhaus, Sarah, Andreas Fuest, Andreas Mayr, and Sonja Greven. 2017. Signal regression models for location, scale and shape with an application to stock returns. Journal of the Royal Statistical Society/Series C (Applied Statistics) 67: 665–86. [Google Scholar] [CrossRef]
- Campbell, John Y., and Richard H. Clarida. 1987. The dollar and real interest rates. Carnegie-Rochester Conference Series on Public Policy 27: 103–39. [Google Scholar] [CrossRef] [Green Version]
- Chen, Yu-chin, and Kwok Ping Tsang. 2013. What does the yield curve tell us about exchange rate predictability? Review of Economics and Statistics 95: 185–205. [Google Scholar] [CrossRef]
- Chinn, Menzie D., and Richard A. Meese. 1995. Banking on currency forecasts: How predictable is change in money? Journal of International Economics 38: 161–78. [Google Scholar] [CrossRef]
- Christiansen, Charlotte, Maik Schmeling, and Andreas Schrimpf. 2012. A comprehensive look at financial volatility prediction by economic variables. Journal of Applied Econometrics 27: 956–77. [Google Scholar] [CrossRef]
- Christoffersen, Peter F. 1998. Evaluating interval forecasts. International Economic Review 39: 841–62. [Google Scholar] [CrossRef]
- Coughlin, Cletus C., and Kees Koedijk. 1990. What do we know about the long-run real exchange rate? Federal Reserve Bank of St. Louis Review 72. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Canlin Li. 2006. Forecasting the term structure of government bond yields. Journal of Econometrics 130: 337–64. [Google Scholar] [CrossRef]
- Dominguez, Kathryn M. 1998. Central bank intervention and exchange rate volatility. Journal of International Money and Finance 17: 161–90. [Google Scholar] [CrossRef]
- Dunis, Christian L., and Xuehuan Huang. 2002. Forecasting and trading currency volatility: An application of recurrent neural regression and model combination. Journal of Forecasting 21: 317–54. [Google Scholar] [CrossRef]
- Edison, Hali J., and B. Dianne Pauls. 1993. A re-assessment of the relationship between real exchange rates and real interest rates: 1974–1990. Journal of Monetary Economics 31: 165–87. [Google Scholar] [CrossRef]
- European Banking Federation (FBE). 2008. EONIA Swap Index: The Derivatives Market Reference Rate for the Euro. Brussels: European Banking Federation. [Google Scholar]
- Fama, Eugenel. 1970. Efficient capital markets: A review of theory and empirical work. The Journal of Finance 25: 383–417. [Google Scholar] [CrossRef]
- Filipović, Damir, and Anders B. Trolle. 2013. The term structure of interbank risk. Journal of Financial Economics 109: 707–33. [Google Scholar] [CrossRef]
- Francq, Christian, Olivier Wintenberger, and Jean-Michael Zakoïan. 2013. GARCH models without positivity constraints: Exponential or log GARCH? Journal of Econometrics 177: 34–46. [Google Scholar] [CrossRef] [Green Version]
- Frankel, Jeffrey A., and Andrew K. Rose. 1995. Empirical research on nominal exchange rates. In Handbook of International Economics. Edited by G. M. Grossman and Kenneth Rogoff. Amsterdam: North Holland Publishing Company, vol. 3, pp. 1689–729. [Google Scholar]
- Fuest, Andreas, and Stefan Mittnik. 2015. Modeling Liquidity Impact on Volatility: A GARCH-FunXL Approach. Available online: http://dx.doi.org/10.2139/ssrn.3038947 (accessed on 16 August 2018).
- Grisse, Christian, and Thomas Nitschka. 2015. On financial risk and the safe haven characteristics of swiss franc exchange rates. Journal of Empirical Finance 32: 153–64. [Google Scholar] [CrossRef]
- Han, Heejon. 2015. Asymptotic properties of GARCH-X processes. Journal of Financial Econometrics 13: 188–221. [Google Scholar] [CrossRef]
- Han, Heejon, and Dennis Kristensen. 2014. Asymptotic theory for the QMLE in GARCH-X models with stationary and nonstationary covariates. Journal of Business & Economic Statistics 32: 416–29. [Google Scholar]
- Hannan, Edward J., William T. M. Dunsmuir, and Manfred Deistler. 1980. Estimation of vector ARMAX models. Journal of Multivariate Analysis 10: 275–95. [Google Scholar] [CrossRef]
- Hansen, Peter Reinhard, Zhuo Huang, and Howard Howan Shek. 2012. Realized GARCH: A joint model for returns and realized measures of volatility. Journal of Applied Econometrics 27: 877–906. [Google Scholar] [CrossRef]
- Hörmann, Siegfried, Lajos Horváth, and Ron Reeder. 2013. A functional version of the ARCH model. Econometric Theory 29: 267–88. [Google Scholar] [CrossRef]
- Hörmann, Siegfried, and Piotr Kokoszka. 2010. Weakly dependent functional data. The Annals of Statistics 38: 1845–84. [Google Scholar] [CrossRef]
- Hörmann, Siegfried, and Piotr Kokoszka. 2012. Functional time series. In Handbook of Statistics: Time Series Analysis: Methods and Applications, 1st ed. Edited by Tata Subba Rao, Suhasini Subba Rao and C. R. Rao. Amsterdam: North Holland Publishing Company, vol. 30, p. 157. [Google Scholar]
- Hull, John, and Alan White. 1998. Value at risk when daily changes in market variables are not normally distributed. Journal of Derivatives 5: 9–19. [Google Scholar] [CrossRef]
- Hull, John, and Alan White. 2012. Libor VS OIS: The derivatives discounting dilemma. Journal of Investment Management 11: 14–27. [Google Scholar] [CrossRef]
- Hyndman, Rob J., and Han Lin Shang. 2009. Forecasting functional time series. Journal of the Korean Statistical Society 38: 199–211. [Google Scholar] [CrossRef]
- Ichiue, Hibiki, and Kentaro Koyama. 2011. Regime switches in exchange rate volatility and uncovered interest parity. Journal of International Money and Finance 30: 1436–50. [Google Scholar] [CrossRef]
- Klepsch, Johannes, Claudia Klüppelberg, and Taoran Wei. 2017. Prediction of functional ARMA processes with an application to traffic data. Econometrics and Statistics 1: 128–49. [Google Scholar] [CrossRef]
- Kočenda, Evžen, and Tigran Poghosyan. 2009. Macroeconomic sources of foreign exchange risk in new EU members. Journal of Banking & Finance 33: 2164–73. [Google Scholar]
- Kowal, Daniel R., David S. Matteson, and David Ruppert. 2017. A Bayesian multivariate functional dynamic linear model. Journal of the American Statistical Association 112: 733–44. [Google Scholar] [CrossRef]
- Kowal, Daniel R., David S. Matteson, and David Ruppert. 2017. Functional autoregression for sparsely sampled data. Journal of Business & Economic Statistics. [Google Scholar] [CrossRef]
- Kuester, Keith, Stefan Mittnik, and Marc S. Paolella. 2006. Value-at-risk prediction: A comparison of alternative strategies. Journal of Financial Econometrics 4: 53–89. [Google Scholar] [CrossRef]
- Markiewicz, Agnieszka. 2012. Model uncertainty and exchange rate volatility. International Economic Review 53: 815–44. [Google Scholar] [CrossRef]
- Meese, Richard, and Kenneth Rogoff. 1983. Empirical exchange rate models of the seventies-Do they fit out of sample? Journal of International Economics 14: 3–24. [Google Scholar] [CrossRef]
- Meese, Richard, and Kenneth Rogoff. 1988. Was it real? The exchange rate-interest differential relation over the modern floating-rate period. The Journal of Finance 43: 933–48. [Google Scholar] [CrossRef]
- Mittnik, Stefan, and Marc S. Paolella. 2000. Conditional density and value-at-risk prediction of Asian currency exchange rates. Journal of Forecasting 19: 313–33. [Google Scholar] [CrossRef]
- Morana, Claudio. 2009. On the macroeconomic causes of exchange rate volatility. International Journal of Forecasting 25: 328–50. [Google Scholar] [CrossRef]
- Neely, Christopher J. 1999. Target zones and conditional volatility: The role of realignments. Journal of Empirical Finance 6: 177–92. [Google Scholar] [CrossRef]
- Ramsay, James O. 2014. FDA Toolbox. Available online: http://www.psych.mcgill.ca/misc/fda/index.html (accessed on 16 August 2018).
- Ramsay, James O., and Bernard W. Silverman. 2005. Functional Data Analysis. New York: Springer. [Google Scholar]
- Sheppard, Kevin. 2013. MFE Toolbox. Available online: https://www.kevinsheppard.com/MFE_Toolbox (accessed on 16 August 2018).
- Sucarrat, Genaro, Steffen Grønneberg, and Alvaro Escribano. 2016. Estimation and inference in univariate and multivariate log-GARCH-x models when the conditional density is unknown. Computational Statistics & Data Analysis 100: 582–94. [Google Scholar]
- Vilasuso, Jon. 2002. Forecasting exchange rate volatility. Economic Letters 76: 59–64. [Google Scholar] [CrossRef]
- West, Kenneth D., Hali J. Edison, and Dongchul Cho. 1993. A utility-based comparison of some models of exchange rate volatility. Journal of International Economics 35: 23–45. [Google Scholar] [CrossRef]
- Wied, Dominik, George N.F. Weiß, and Daniel Ziggel. 2016. Evaluating value-at-risk forecasts: A new set of multivariate backtests. Journal of Banking & Finance 72: 121–32. [Google Scholar]
- Ziggel, Daniel, Tobias Berens, Geroge N. F. Weiß, and Dominis Wied. 2014. A new set of improved value-at-risk backtests. Journal of Banking & Finance 48: 29–41. [Google Scholar]
| 1 | “Observed” yield curves are actually estimates obtained from observed bond prices. In the present paper, as in almost all of the literature (see for example Diebold and Li (2006)), we treat the yield curve data as if they had been observed directly. |
| 2 | To simplify notation, we write instead of . |
| 3 | Traces of this assumption are scattered all over the Internet, but we restrain from quoting web pages. |
| 4 | Note that we will work with the full models in the following, as explained in Section 4.2. |
| 5 | The peculiarity of having a higher logL for the nested model in comparison to the full model of Table 3 arises due to using a two-step procedure instead of estimating jointly. |
| 6 | Although, since then, various alternative backtests have been established as, e.g., in Ziggel et al. (2014) or Wied et al. (2016). However, such new approaches would deviate too much from the core idea of the present paper, which is why we stick to the classical procedure of Christoffersen (1998). |
| 7 | We also take daily differences to ensure the stationarity of our yield curve process. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ARMA-GARCH | ARMAFunX-GARCHFunX | 2y-ARMAX-GARCHX | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Parameters | Estimate | Mean | Confidence Interval | Estimate | Mean | Confidence Interval | Estimate | Mean | Confidence Interval |
| − | − | − | |||||||
| − | − | − | − | − | − | ||||
| − | − | − | − | − | − | ||||
| − | − | − | |||||||
| − | − | − | − | − | − | ||||
| − | − | − | − | − | − | ||||
| ARMA-GARCH | ARMAFunX-GARCHFunX | 2y-ARMAX-GARCHX | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Parameters | Estimate | Mean | Confidence Interval | Estimate | Mean | Confidence Interval | Estimate | Mean | Confidence Interval |
| − | − | − | − | − | − | ||||
| − | − | − | − | − | − | − | − | − | |
| − | − | − | − | − | − | ||||
| − | − | − | − | − | − | − | − | − | |
| − | − | − | − | − | − | − | − | − | |
| − | − | − | − | − | − | ||||
| − | − | − | − | − | − | ||||
| − | − | − | − | − | − | − | − | − | |
| Model | logL | AIC | BIC |
|---|---|---|---|
| ARMA-GARCH | 10,826 | −21,639 | −21,604 |
| ARMAFunX-GARCHFunX | 10,868 | −21,711 | −21,640 |
| 2y-ARMAX-GARCHX | 10,841 | −21,666 | −21,619 |
| Model | logL | AIC | BIC |
|---|---|---|---|
| ARMA-GARCH | 10,8325 | −21,656 | −21,632 |
| ARMAFunX-GARCHFunX | 10,863 | −21,712 | −21,670 |
| 2y-ARMAX-GARCHX | 10,829 | −21,649 | −21,619 |
| Model | p | % Viol. | |||
|---|---|---|---|---|---|
| ARMA-GARCH | |||||
| ARMAFunX- | |||||
| GARCHFunX | |||||
| 2y-ARMAX-GARCHX | |||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fink, H.; Fuest, A.; Port, H. The Impact of Sovereign Yield Curve Differentials on Value-at-Risk Forecasts for Foreign Exchange Rates. Risks 2018, 6, 84. https://doi.org/10.3390/risks6030084
Fink H, Fuest A, Port H. The Impact of Sovereign Yield Curve Differentials on Value-at-Risk Forecasts for Foreign Exchange Rates. Risks. 2018; 6(3):84. https://doi.org/10.3390/risks6030084
Chicago/Turabian StyleFink, Holger, Andreas Fuest, and Henry Port. 2018. "The Impact of Sovereign Yield Curve Differentials on Value-at-Risk Forecasts for Foreign Exchange Rates" Risks 6, no. 3: 84. https://doi.org/10.3390/risks6030084
APA StyleFink, H., Fuest, A., & Port, H. (2018). The Impact of Sovereign Yield Curve Differentials on Value-at-Risk Forecasts for Foreign Exchange Rates. Risks, 6(3), 84. https://doi.org/10.3390/risks6030084