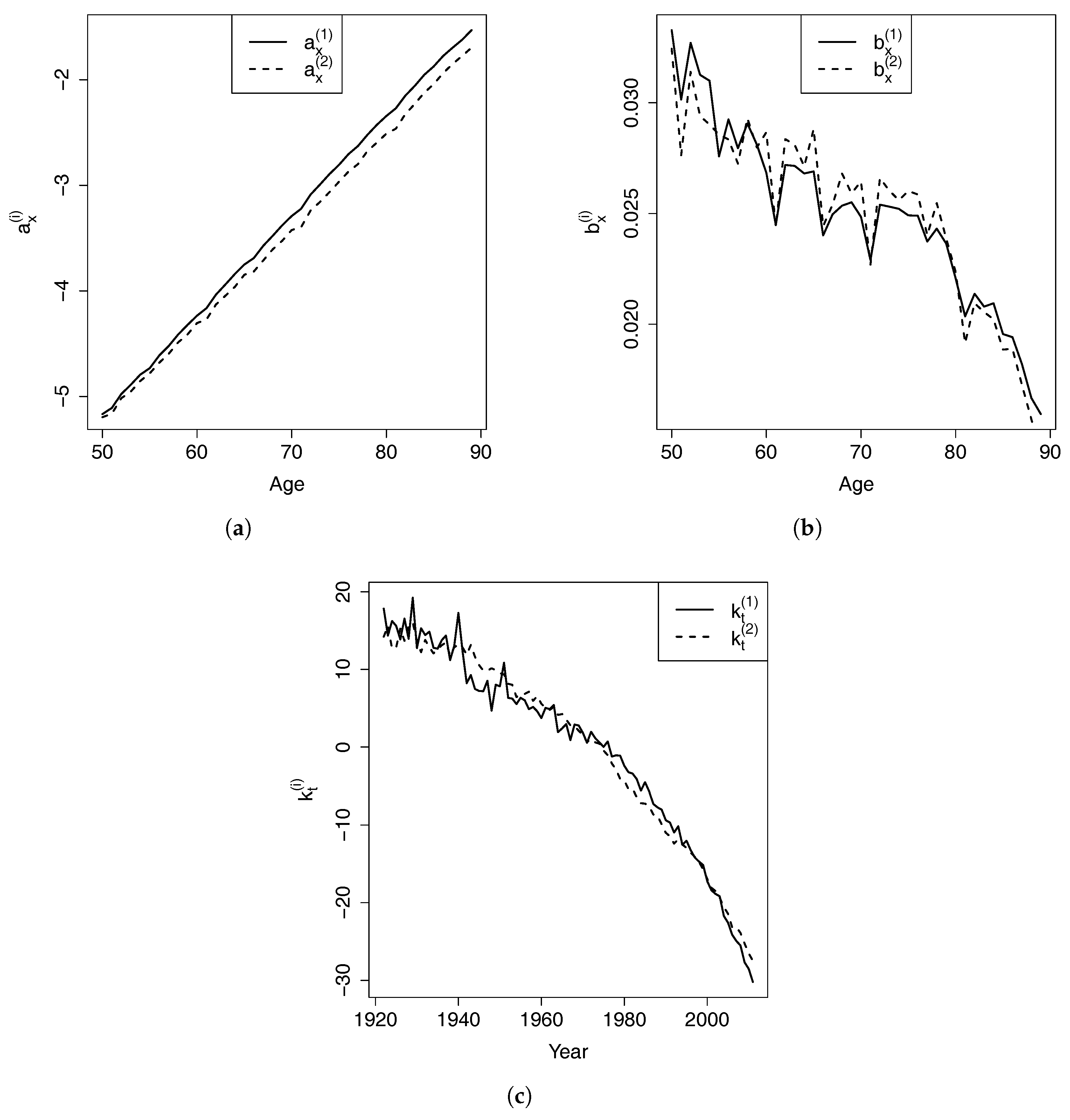
4.2. VECM Model
VECM is a special case of vector autoregressive (VAR) model with cointegration relationship taken into consideration. A VAR model with lag order
p can be written as
where
c is a
constant vector,
is a
loading matrix for lag
i, and
follows bivariate normal distribution.
A
p-order VAR can be written as a
-order VECM, as shown below:
where
is a
long-term loading matrix and
is a
short-term loading matrix for lag
i.
The rank of
indicates whether
and
have a cointegration relationship. If the rank of
is 0, then there is no long-term equilibrium and the differenced
series are stationary. If the rank of
is full, then the original time series
must be stationary. Otherwise,
and
are cointegrated. Since we only have two time series in our study, the full rank is 2. Cointegration relationship exists only when the rank of
is equal to 1. In the case that cointegration exists, VECM can be rewritten as follows:
where
is the
adjustment coefficient vector and
is the cointegrating value. VECM incorporates both the long-term equilibrium relationship and the short-term relationship. In the long run, the two time series are expected to follow the relationship
. If there is deviation from this equilibrium, the error correction term
pulls the time series towards the equilibrium. In the short-term, the two time series are affected by their autoregressive terms. We can also allow constant and time trend in the cointegration term. However, we find that these terms are not necessary for our dataset during the process of model building described in the following section.
4.3. Model Building
We used the following procedures to build and estimate VECM:
Test if and follow process.
Determine the lag order of VECM.
Perform cointegration tests to examine if a cointegration relationship exists.
Estimate the VECM with selected lag order.
Check residual diagnostics.
We used the Augmented Dickey–Fuller (ADF) test to check whether the two time series are processes. The null hypothesis of ADF test is that unit roots exist. The existence of unit roots indicates that the tested time series is non-stationary. We expect that the null hypothesis is accepted for the original process and rejected for the first-order difference of the process. In other words, we expect and to be non-stationary processes but their first-order differences to be stationary.
Table 2 summarizes the ADF test results for
,
,
, and
. The tests include a drift and use Akaike Information Criteria to select lag order in the test regression. The test statistics for both
and
have
p-value greater than 10%, indicating that we cannot reject the null hypothesis that
and
are non-stationary at 10% significance level. The test statistics for
and
are both smaller than 1%, suggesting that we reject the null hypothesis at 1% significance level. Therefore, both
and
are stationary. According to the definition of
process, we can conclude that both
and
are
processes.
To select the lag order for VECM, we first determine the lag order for VAR, and then deduct the order by one for VECM. In the lag order selection for VAR, we consider two criteria: Akaike Information Criteria (AIC), and Bayes Information Criteria (BIC). Since the VAR models are estimated by Ordinary Least Square (OLS) method, AIC and BIC are calculated using the following equations:
where
,
denotes the determinant of a matrix
X,
T is the sample size,
p is the lag order, and
K is the dimension of the time series data. The lower the criteria values, the better the goodness of fit.
Table 3 shows that lag order 4 has the lowest AIC, while lag order 2 has the lowest BIC. The two criteria lead to different conclusions since they penalize extra parameters to different extents. It is often believed that AIC selects the model that most adequately describes the data and BIC tries to find the true model among the set of candidates. As a result, the model selected by AIC tends to overfit while the one selected by BIC may underfit. We fit both VECM(1) and VECM(3) one lag less than the corresponding VAR model, and check residual diagnostics to select an adequate model.
Next, we test whether
and
are cointegrated using the Engle–Granger test. We first perform a linear regression of
on
, and then conduct ADF test on the regression residuals. The estimated linear regression model is shown below:
where the numbers in parentheses are the standard deviations of the estimated parameters. The ADF test on the regression residuals returns a
p-value smaller than 5%, indicating that we reject the null hypothesis of the existence of unit roots at 5% significance level. Therefore, the regression residuals are stationary and
and
are cointegrated. Since the constant term in the regression model is insignificant, we choose not to include a constant in the cointegration term.
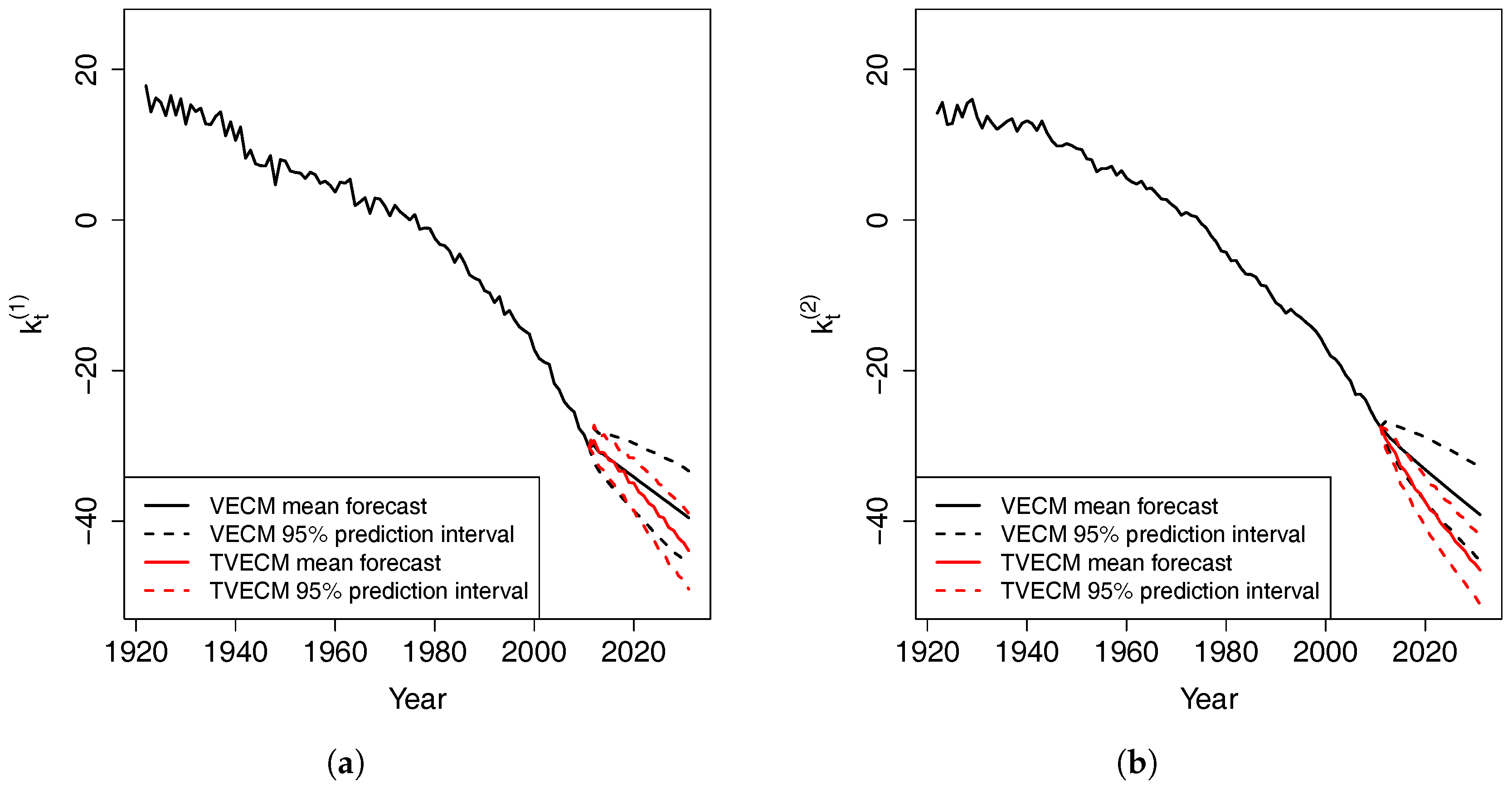
Finally, VECM is estimated by the Engle–Granger two-step ordinary least squares (OLS). The estimation can be conducted in R using the “VECM” function in the “tsDyn” package. The first OLS determines the cointegrating value by a linear regression of on , which has been carried out in the cointegration test. Conditioning on the estimated , the second OLS is performed to obtain other parameters in VECM. VECM can also be estimated by a one-step maximum likelihood estimation (MLE) method. However, in our case, the MLE estimates are very unstable when we use different number of lag orders.
Since AIC and BIC suggest different lag orders, we fit both VECM(1) and VECM(3) and examine the adequacy of the estimated models.
Table 4 presents the results of Ljung–Box autocorrelation test for VECM(1) and VECM(3). The
p-values for both VECM(1) and VECM(3) are all significantly greater than 5%, thereby indicating autocorrelation has been properly captured by the two models.
Table 5 presents the results of univariate and bivariate Doornick–Hansen (DH) normality test for the residuals from VECM(1) and VECM(3). Residuals from VECM(1) fails the bivariate normality test and also the univariate normality test for
at 5% significance level. In contrast, residuals from VECM(3) pass all the normality test at 5% significance level. Overall, the residual diagnostics suggest that VECM(3) is more adequate than VECM(1) for our data. Therefore, we use VECM(3) in the following analysis.
The estimated VECM(3) is shown below:
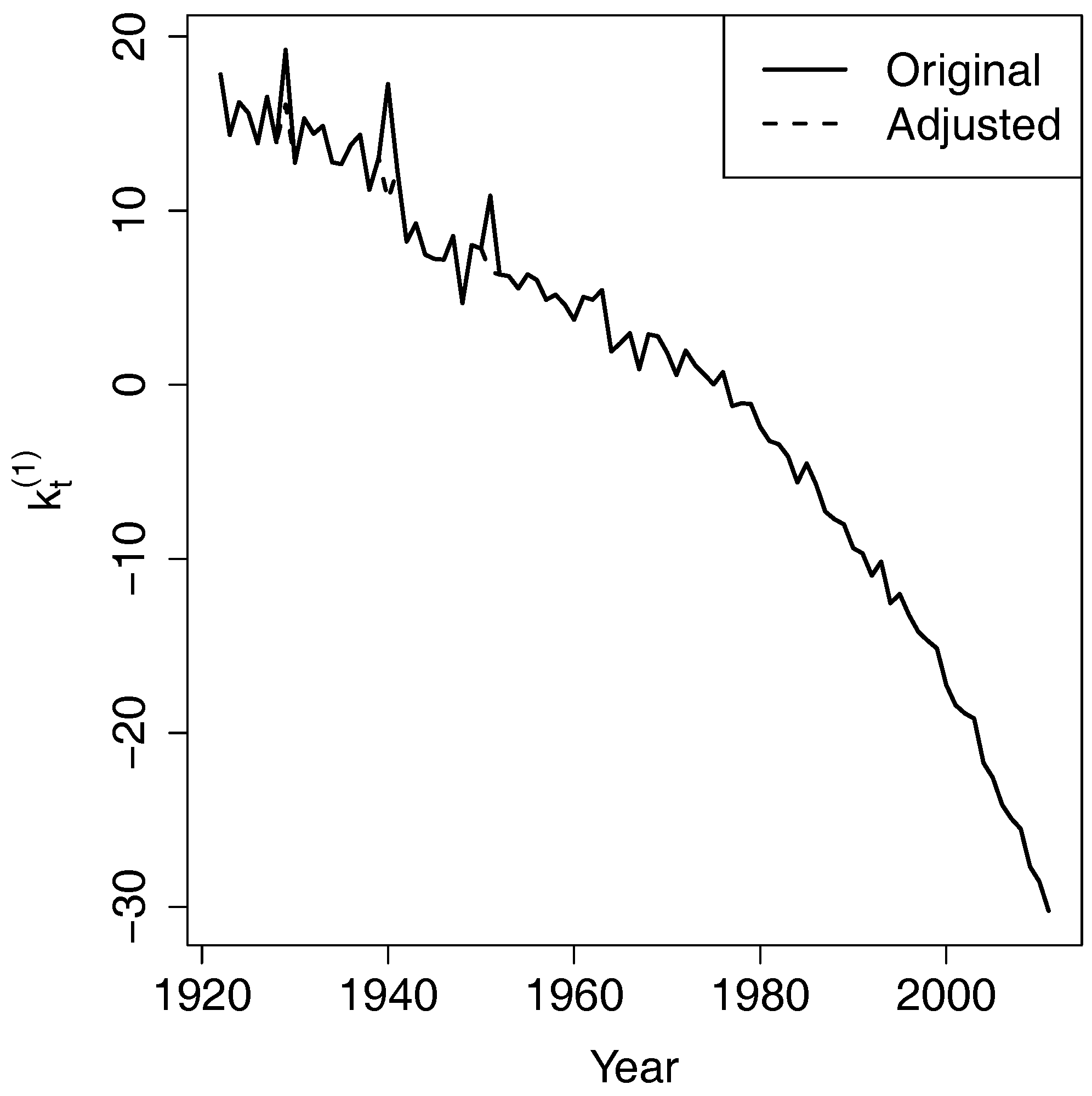
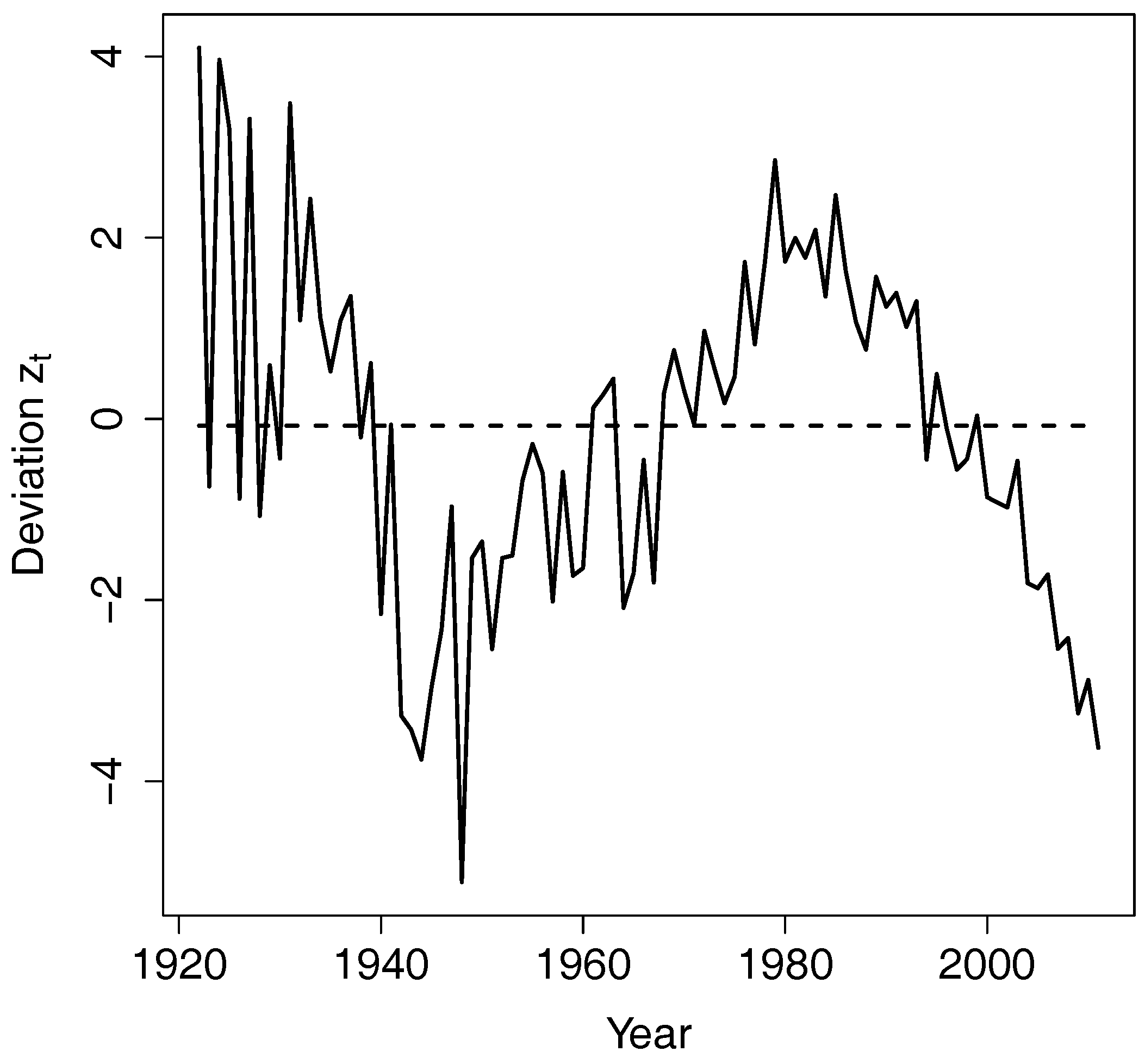
The estimated long-term equilibrium is . The cointegrating value is close to −1, thereby indicating that and are close. However, because of the downward trend in the mortality indexes, the gap between and enlarges over time and and diverge slowly and indefinitely.
When is larger than in year , the deviation from the equilibrium is positive. This deviation is multiplied by for and for , resulting in a reduction of and increase of in year t. Therefore, the expected difference between and in year t narrows. This is how the error correction term forces the two time series to revert to the long-term equilibrium.







{kind=link}
{kind=link}
{kind=link}
{kind=link}