2.1. A Univariate Model for Losses
One can model the losses up to time
t as
where
are independent and identically distributed random variables representing the severity of damage from each attack and
is an independent Poisson process with intensity
giving the frequency of attacks. That is, losses can be modelled by a Compound Poisson Process. A description of this process and its properties can be found in, e.g.,
Ross (
2010). One can think of this as the more general setting of ALE, because
which we can recall is how ALE is defined. The advantage of using such a model over ALE is that we can easily change the specifics of how
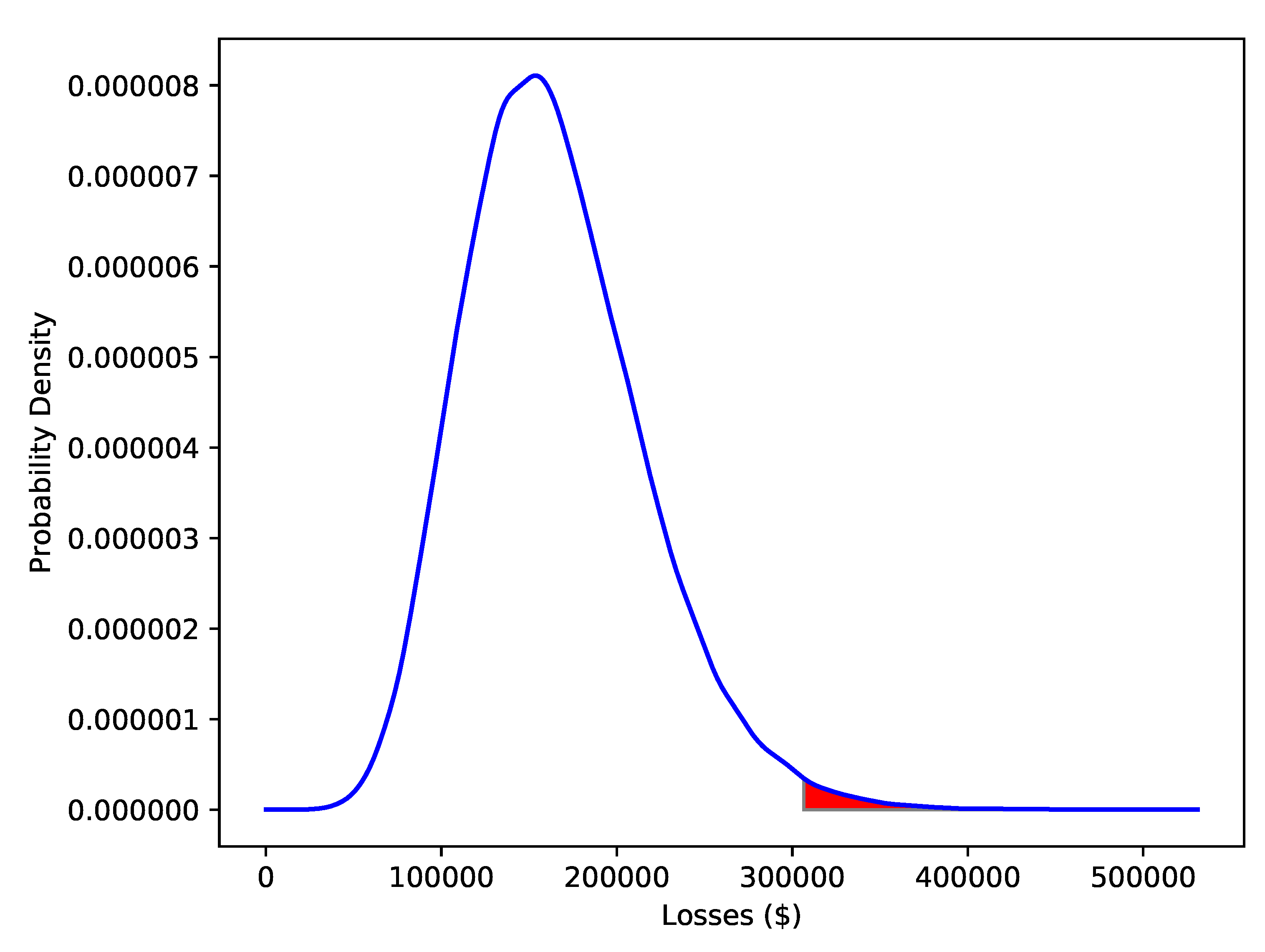
is constructed and still get such expressions. Further, there is no reason we have to look at averages. To this end, in the results section in addition to considering expected values, we will calculate various VaR values. Note that this is just another name for a quantile. We use the methodology outlined in
Shevchenko (
2010) in simulation.
Using a compound Poisson process gives a natural way to model the effect of mitigations on the frequency of attack. If spending z means that attacks succeed with some probability (instead of always succeeding), the total losses up to time t is still a compound Poisson process, but with intensity .
In choosing the parameters of a compound Poisson process, one would first want to find
. But the Poisson random variable has the property that its mean is equal to its variance and the data we have is overdispersed. Instead, we will use a counting process that has a Negative Binomial distribution at time
t. The Negative Binomial distribution is often used for fitting to count data, and is well known in operational risk. The application of the negative binomial distribution to real world data is done in a cybersecurity context in
Leslie et al. (
2018).
While it is straightforward to relate a Poisson distribution to the Poisson process, it is not immediately obvious what process has a Negative Binomial distribution. Such a process can be constructed several ways. For instance, one can relate it to a pure birth process, see
Toscas and Faddy (
2003) for details. A good overview of this distribution is given in
Gurland (
1959); the following result is read from there with the addition of a thinning probability.
Proposition 1 (Poisson Process with Gamma Intensity is Negative Binomial). Suppose Λ is a Gamma random variable with parameters and and q is a probability. If is a (thinned) Poisson Process with intensity , then its distribution at time t is Negative Binomial with parameters and .
Recall that the probability density function of the Gamma distribution is given by
and the probability mass function of the Negative Binomial is given by
Suppose that we have some count data telling us the number of successful incidents over some time periods
and the probability
q that a given incident is successful. If we find estimates for the parameters as
and
, we can find
and
as
In the sequel, we will change the parameters of the probability of successful attack q by varying the amount spent on different mitigations. The idea we use here is as follows. We find p and r from the data and assume some baseline q. This implies some baseline and for that assumed q. When we change the spending and hence q, the new p and r that apply are given in terms of those baseline and by Proposition 1.
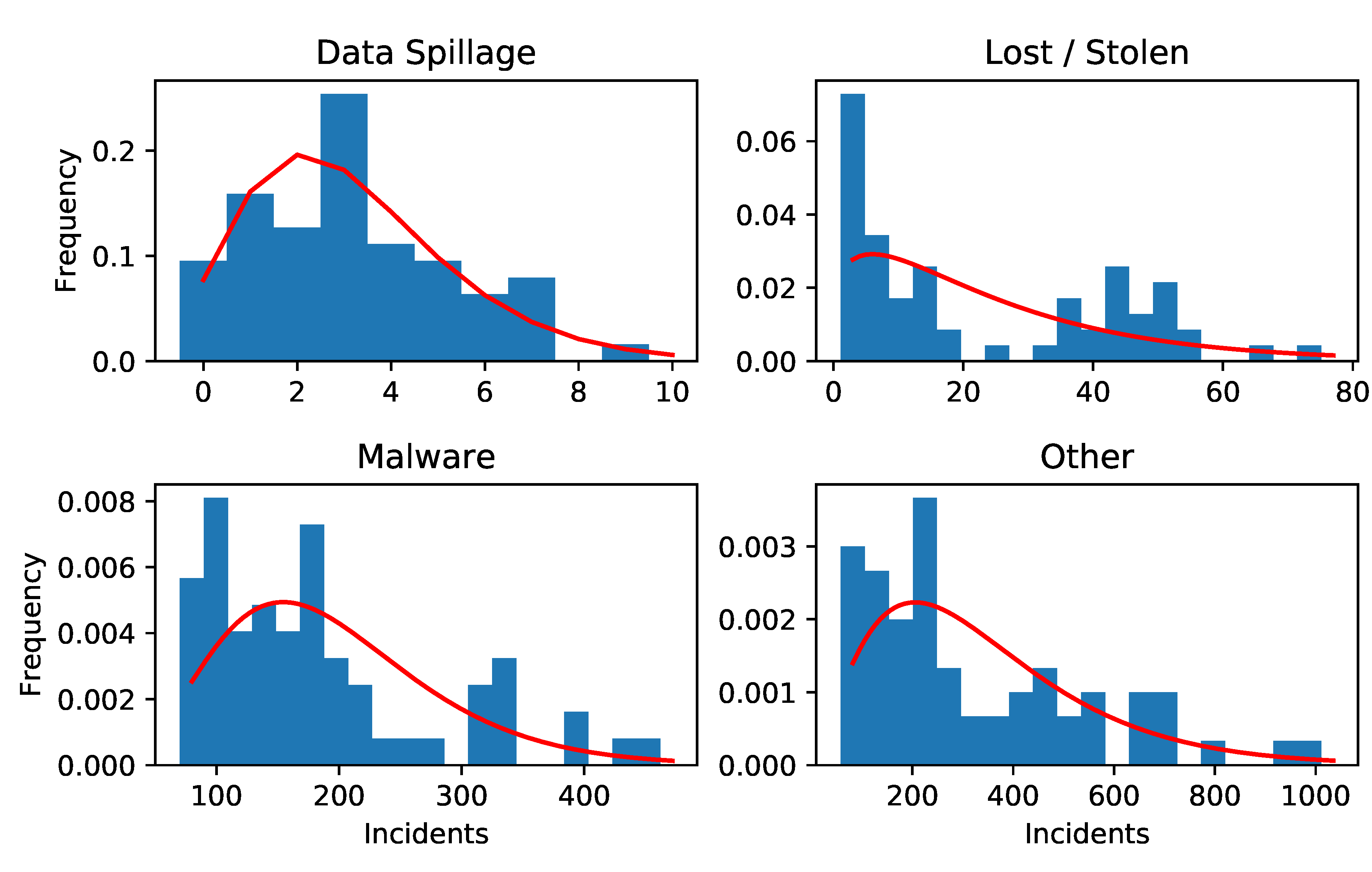
To this point we have only described how to model the frequency of attacks. In order to have a complete univariate model for losses we need a model for the severities. Good choices here would include the Lognormal (see for instance
Hubbard and Seiersen 2016), Weibull or Power distributions. Due to lack of data, we will use a very simple model for severities described in the Results section.
2.2. A Multivariate Model for Losses
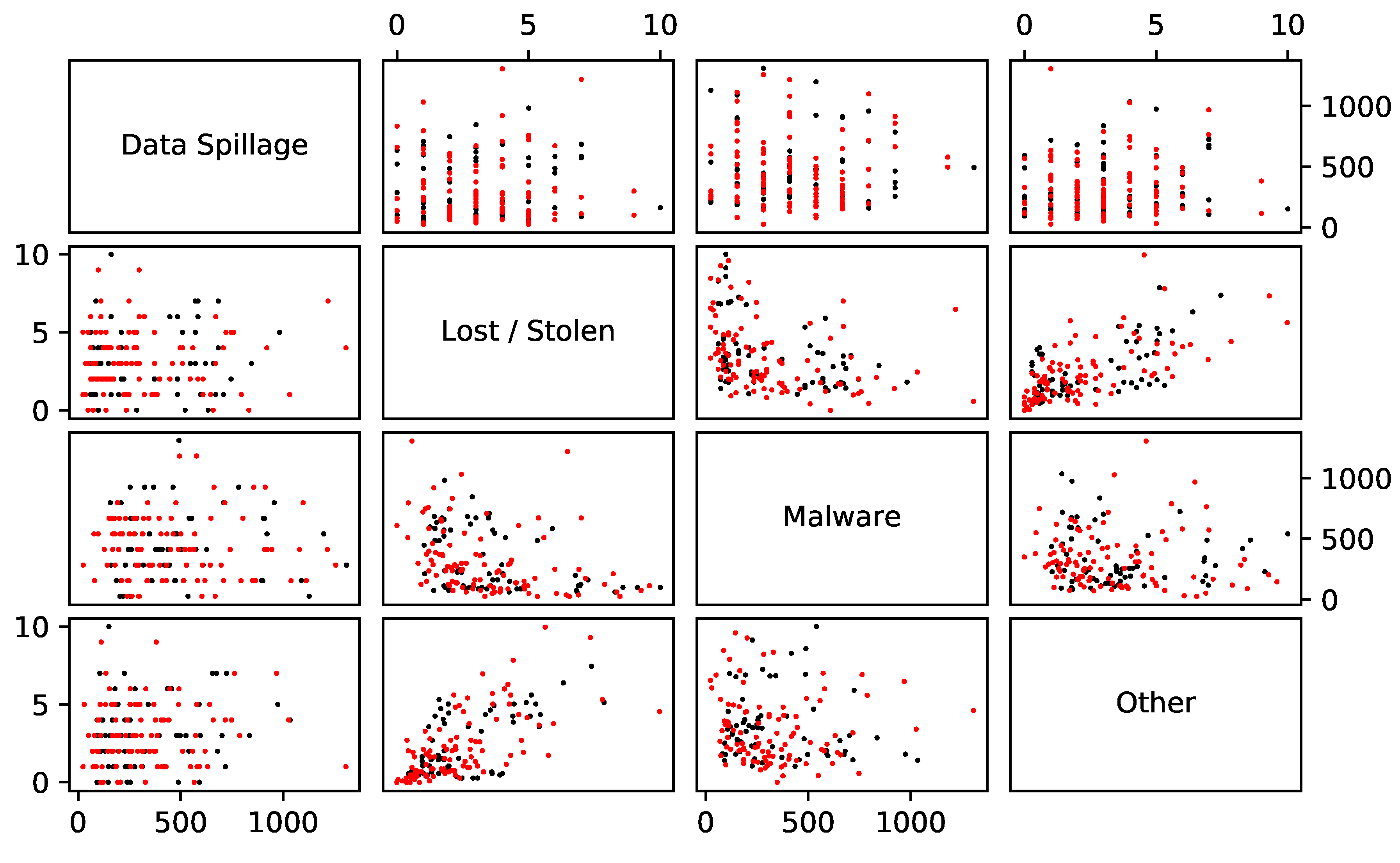
We require a model that is able to handle different, but dependent, categories of damages. There are two components of that requirement. Firstly, we need to handle more than one damage type. For instance, it might be that an organisation faces two types of incidents: an incident of malware or a data spillage event. One would imagine that the first would happen frequently, but have a small impact and that the second would happen rarely but have a large impact. It makes sense to model these incidents separately. The second component of the requirement is an ability to handle dependence between the incidents. For example, it could be that a malware incident sometimes causes a data spillage event.
We suppose there are
categories of damage. It is trivial to make a multivariate model. This can be done by fitting an independent model to each category and summing them. That is, for
we have
where the
j subscripts relate to the
type of damage. Our object of interest is then
If the marginal models are all compound Poisson processes, their sum will also be a compound Poisson process. This is very useful because numerical methods can be used to great effect; see
Shevchenko (
2010), particularly the Fast Fourier Transform based method. Unfortunately simply adding the
will not introduce dependence between incident types in our model.
A simple way to include dependence is suggested in
Chavez-Demoulin et al. (
2006), who look at multivariate operational risk models. Among the ideas presented there is to use a copula function on the marginal frequencies. That is, we have exactly the model in Equations (
2) and (
3), but we have a multivariate distribution for
. Ultimately, we will use Monte Carlo simulation to look at the output of such a multivariate model. Because of this, we will restrict our attention to the simulation of a Gaussian copula, rather than looking at the deeper theory of copula functions. For further details on copula functions we note the excellent treatise of
Nelsen (
1999) and a very practical introduction in
Genest and Favre (
2007).
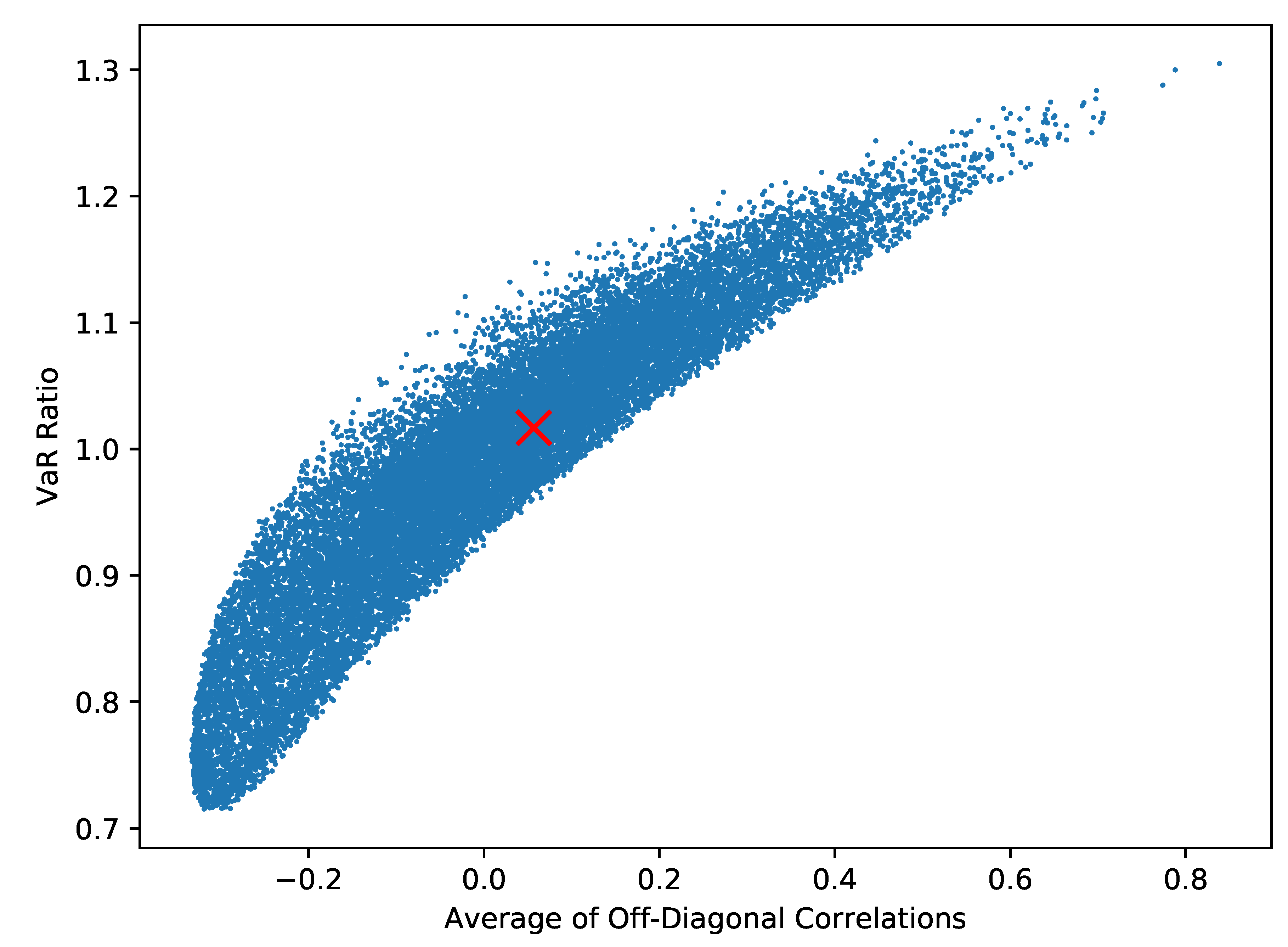
A multivariate distribution encodes not only the marginal distributions but their dependence. A copula function is one way of encoding that dependence only. Sklar’s Theorem gives us that combining a copula function with marginal distributions is one way of building a multivariate distribution. Conversely, it also gives us that a given multivariate distribution characterises a copula function. In this vein, a Gaussian copula is the dependence that comes from a multivariate Gaussian distribution; in essence this is equivalent to using linear correlation. Simulating a Negative Binomial random variable under this copula is quite simple.
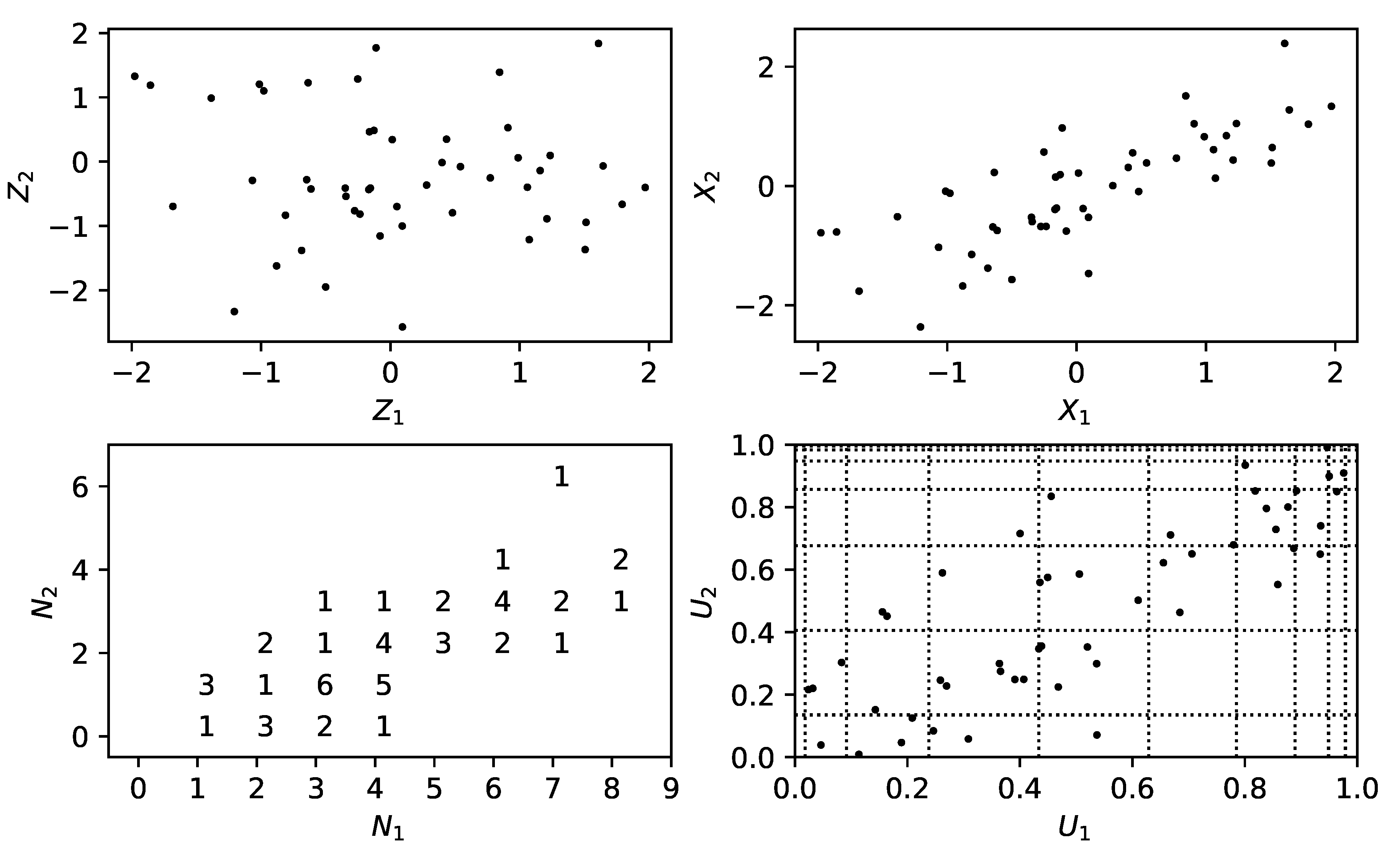
The method is as follows. Given a permissible correlation structure, to simulate a vector of counts:
Simulate a vector
of correlated, standard normal random variables. One can use the Cholesky decomposition of the correlation matrix to move from independent, standard normal random variables to such a correlated vector; see for instance Section 2.3.3 of
Glasserman (
2003).
Transform these values to a dependent vector of uniform random variables . This can be done by setting each component as where is the cumulative distribution function (CDF) of the standard normal distribution.
The output
is given by setting each component to
, where
is the inverse of the
Negative Binomial CDF
1.
We note in passing that the key idea here is the Inverse Transform Method. The above method is illustrated in
Figure 1 for two Poisson random variables.
We close this section by giving a result on the mean and variance of Equation (
3), dropping the
t for convenience, when we know the correlations between the
.
Proposition 2 (Mean and Variance of
L)
. The mean and Variance of L are given byandwhere is the correlation between and . Proof. The expression for the mean of
L comes from the independence of the counting processes and the severities, see for instance Proposition 2.2 of
Shevchenko (
2010). A similar expression for the variance of a random sum of random variables also exists in the same source, reading
However we cannot add these values up to get
because the
are not independent. Rather we will start from
meaning that we also need to calculate the covariance terms for
. By definition we have
Given that we have the means to calculate expected values we can easily calculate the latter term. So we will focus on the first term, for
. We proceed by conditioning on the event
:
where the second line comes from the independence of the different types of severity. Hence using iterated expectations we have
We can rearrange the formula for correlation
to give
in terms of
:
Substituting backwards using the expression for
, for
we have
which gives the result. □
2.3. A Model for Mitigations
In the previous section we detailed a multivariate model for cybersecurity risk. This is valuable in and of itself because it can be used to describe risk, for instance by calculating a VaR value. However, we want to build on the key idea of
Gordon and Loeb (
2002) which is modelling the impact of mitigations on such risk. In this section we look at a simple model for mitigations.
We start by assuming that we have
different mitigations that each cost at most
per year. We assume that we have an overall budget of
z per year and denote the amount that we spend on each mitigation as
, with the restriction
in one year. We fix a time horizon
T of interest and assume that spending scales directly in
T. That is, each mitigation costs at most
over
and we have a budget of
over
. One could view the modelling in
Gordon and Loeb (
2002) as having one mitigation and one damage type and finding the best level of spending given different functional forms of
, the probability of successful attack given spending on that mitigation. Mapping the mitigation models in
Gordon and Loeb (
2002) to our setting gives
as well as
where
is the probability of successful attack in the absence of mitigations and
and
are parameters. Similar modelling, but with more than one mitigation and damage type, is done in
Zhuo and Solak (
2014). Here the effect of mitigations comes in through the expression for total losses as
where
and
are sets of assets, attack types and mitigations,
is a rate of attack,
is the maximum damage from an attack and
is the effectiveness of mitigation
o on attack type
a given spending
. This is given as
where
gives the maximal effectiveness of spending and
gives the rate at which spending approaches that level.
We use a multiplicative model similar to
Zhuo and Solak (
2014), but one that looks at frequency and severity separately. We first look at modelling the effect of spendings
on the probability of success (and hence the frequency) of attack type
j and then on the effect on severities.
The broad idea is that for each attack type
j there is some baseline probability of success when there is no spending on mitigations, denoted
, and that the probability of successful attack goes down as spending increases. This is achieved by a factor that decreases linearly as spending increases to its maximum value
. Finally, the combined effect of all the mitigations is simply the product of those factors. Rather than model the effect of synergies or interference between mitigations as in
Zhuo and Solak (
2014), we use a floor value to ensure that this value does not become unrealistically small.
We will now fill in this broad idea. The linear reduction is achieved through a simple function
f defined as
This function describes a straight line between a start point
and an end point
and a constant
for any
beyond
. We model the effect of spending
on the probability of a successful attack of type
j over the period
as
where
is a factor that reduces
if the full spending
is used and
is a floor on this probability. For example,
indicates no effect of mitigation
m on the probability of success of attack type
j and
indicates that the probability is reduced to 0. The interpretation of the expression for
is that the base probability of a successful attack of type
j is modified by the product of different scaling factors, each coming from a different mitigation. The floor is used to ensure that the risk of attack does not become unrealistically small, as aforementioned.
A similar model is used for the effect of spending
on the severities. We assume that we know the distribution of severities
that apply in the absence of spending and model
as a reduction of these values. That is, we set
Here, serves to scale , represents a set reduction to every incident and is a floor on the damage for this attack type. The interpretation of the above expressions is much as for the probability, but rather than only scaling damages includes the idea that a mitigation might give a set reduction to damage for each time an attack occurs.
There are several advantages to the above approach. Firstly, it allows for specific mitigations, rather than spending as a whole as in
Gordon and Loeb (
2002). Secondly, the form of
f in Equation (
9) means it is simple for estimates of the efficacy of mitigations to be translated into a model. That is, it is easier for the impact of a mitigation to be translated into parameters like
and
than it is to translate them into the parameters in Equations (
6)–(
8). Thirdly, as in the models in
Gordon and Loeb (
2002) and
Zhuo and Solak (
2014), the mitigating effect of spending
z is modelled so that increased spending has diminishing effects. Fourthly and finally, the above approach allows for mitigations that affect frequency and severity of attacks separately.
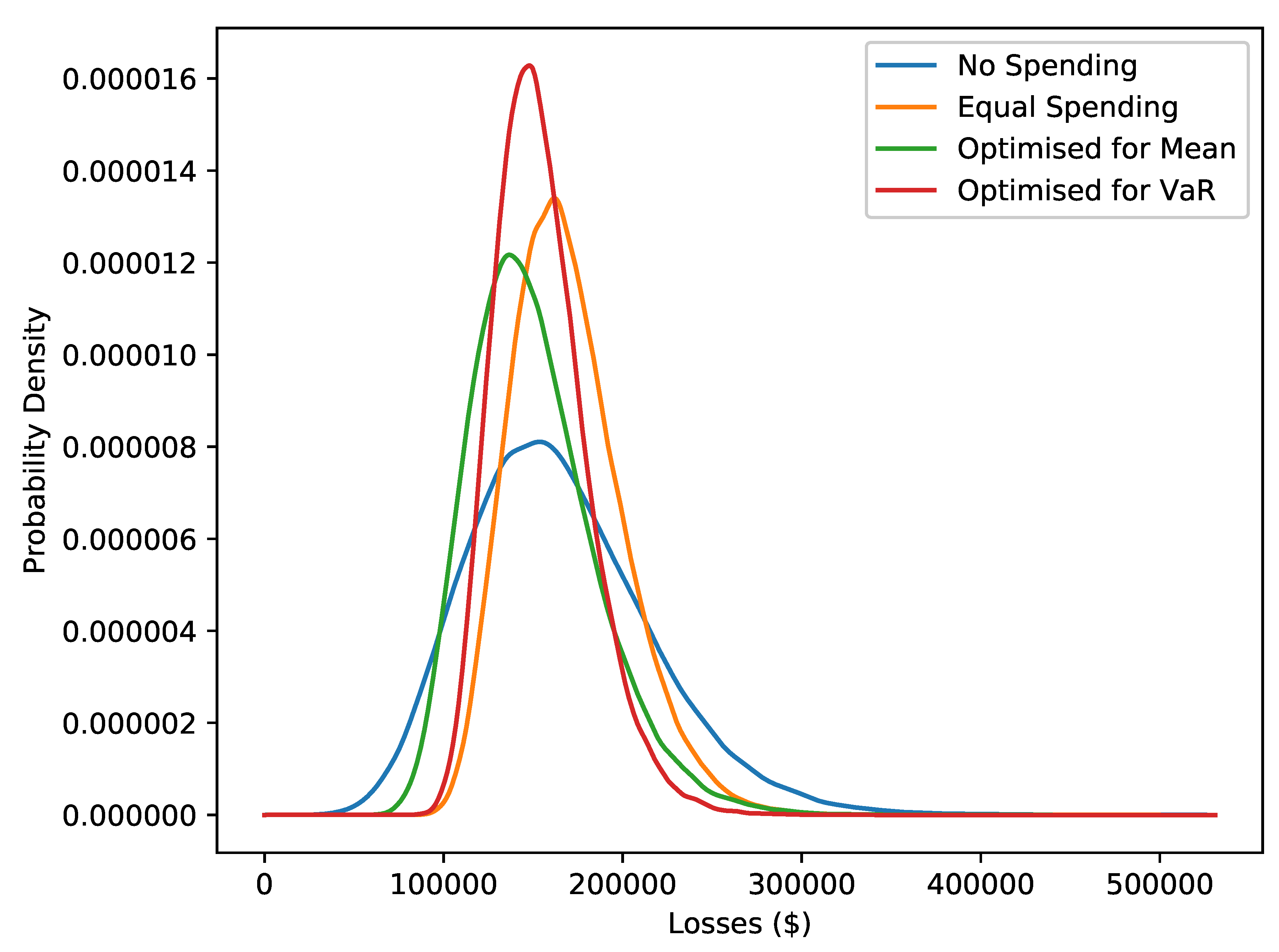
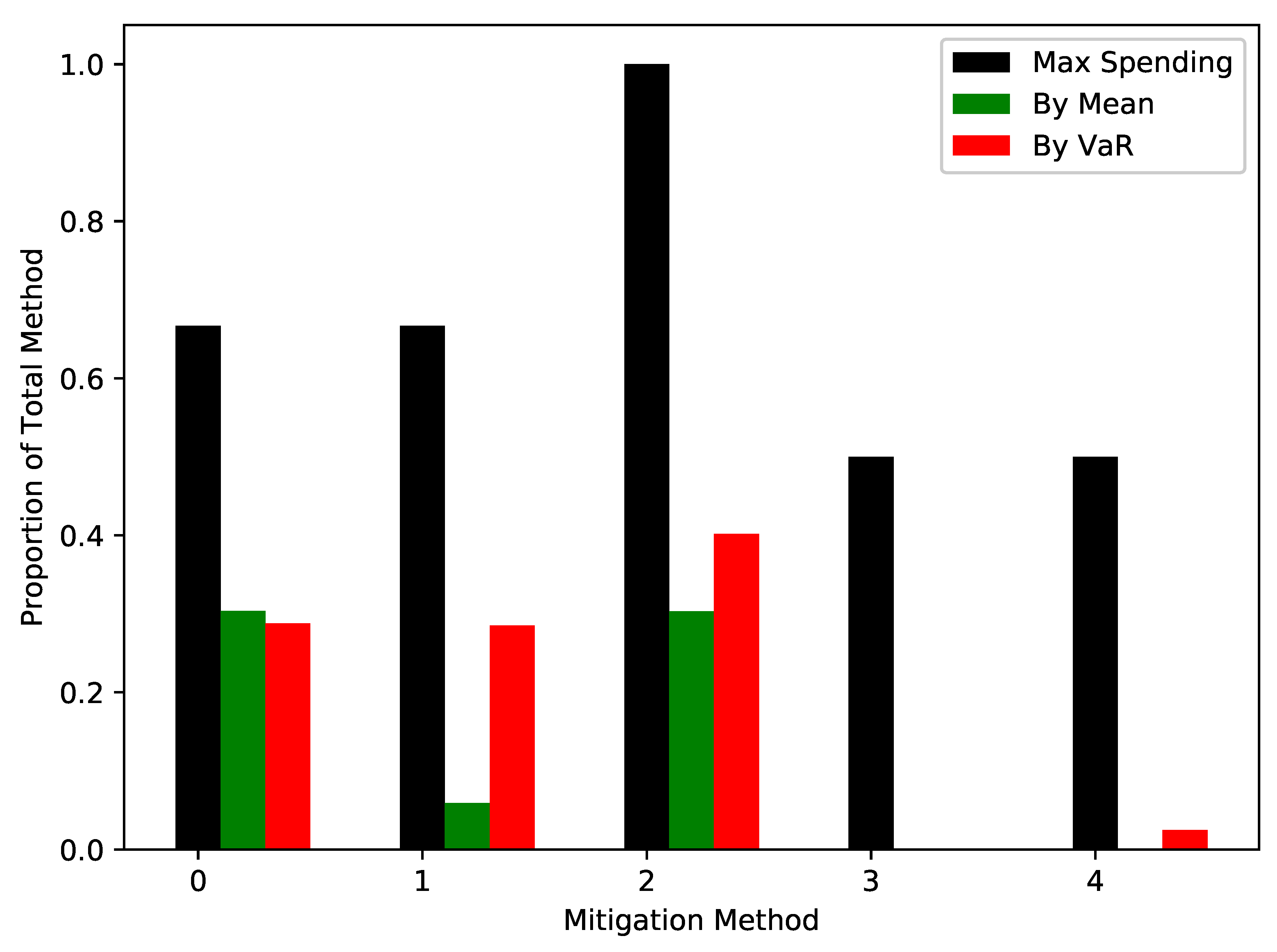
Giving a model for mitigations serves two purposes. Firstly, given assumptions on a given mitigation, one could see what losses might look like with and without that mitigation. This gives a means to judge whether the mitigation is worth implementing. Secondly, given a fixed budget, a specific objective (e.g., minimising the average of or the VaR) and several possible mitigations, one can use numerical optimisation to choose the best choice of those mitigations.
We will look at the second idea in the Results section. A note on efficiency is worth making here. In numerically optimising to minimise the mean and VaR, a natural approach would be to use simulation. The problem with this approach is that every step of the optimisation routine would require many simulations. This would make the problem prohibitively expensive. Here we use the results of Proposition 2. While this gives the mean in closed form, it does not give the VaR. For this, we approximate the distribution of by a Normal distribution with the mean and variance of . Given the inverse cumulative distribution function of the Normal distribution is easy to evaluate, we can find an approximation of the VaR.
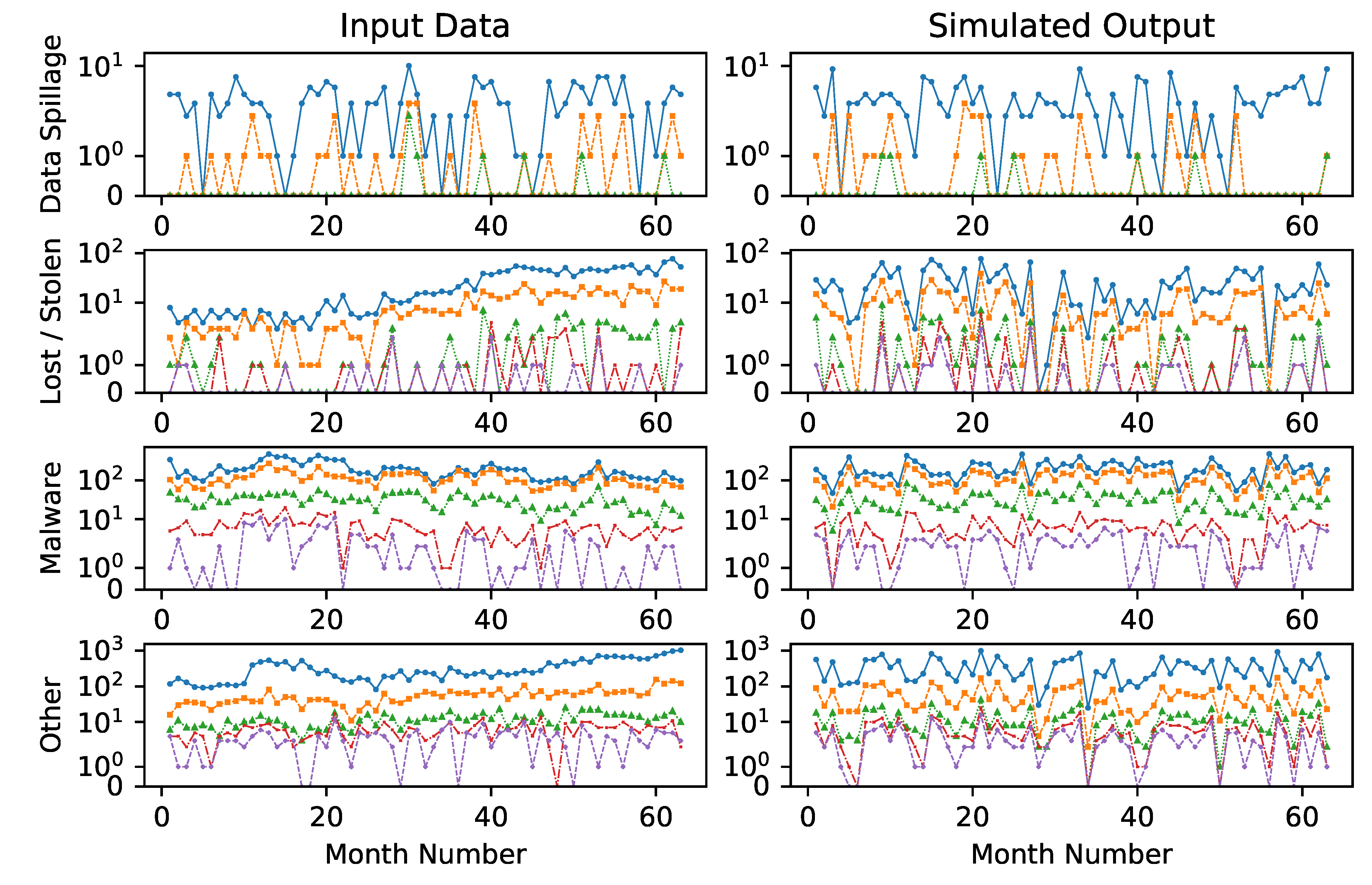
Armed with a multivariate model for cybersecurity risk and a model for the impact of mitigations on the frequencies and severities, we look to apply this to real world data taken from
Kuypers et al. (
2016) and
Paté-Cornell et al. (
2018).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}