1. Introduction
The average human lifespan has been increasing consistently throughout the developed nations in the last hundred years or so.
Oeppen and Vaupel (
2002) reported that the highest female period life expectancy at birth around the world each year has been growing by about 0.24 years annually for more than a century. In Australia, period life expectancy at age 60 has grown from 16.5 years in 1950 to 25.0 years in 2017; in New Zealand, it has increased from 16.9 years in 1950 to 24.0 years in 2013. Life expectancy is one of the major indicators of a country’s wellbeing. Forecasting life expectancies accurately is of critical importance for government social planners as well as demographic researchers and industry practitioners (e.g.,
Lee et al. 1995;
Nikolaevich 2019).
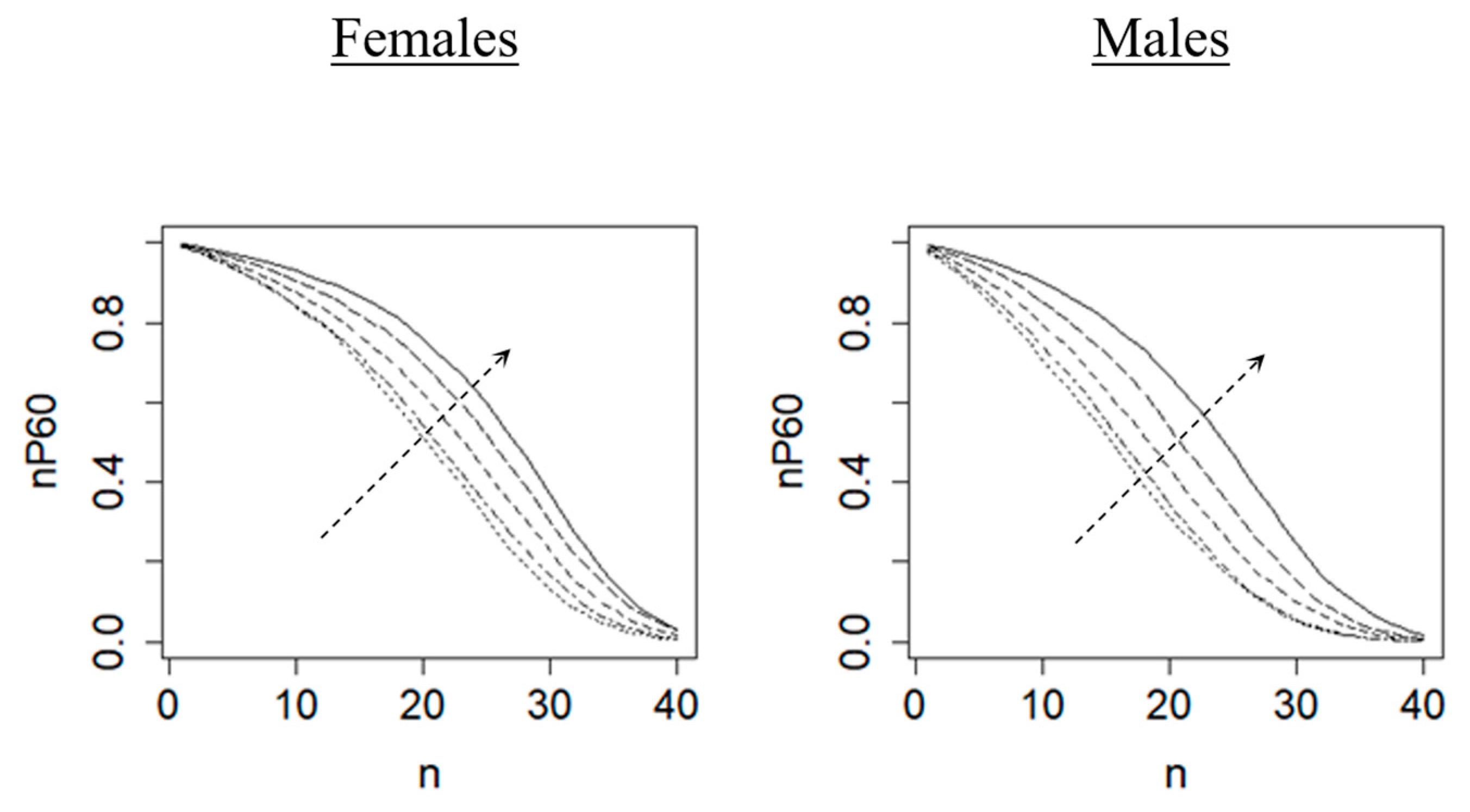
The continuous mortality decline, together with the lack of clear improvement in the maximum lifespan, has caused the common phenomenon of a “rectangularisation” of the survival curve. This kind of observations has been well documented in earlier studies (e.g.,
Fries 1980;
Cheung et al. 2005). As shown in
Figure 1, it can be characterised by an upward and rightward shift of the period survival curve across successive time periods. The increasing area under the survival curve over time refers to the extent of rectangularisation. This concept is one of the major analytical frameworks in demographic research and can actually be further adapted to describe past changes in survival levels and predict future survival rates. The recent developments in mortality projection methods can provide a useful reference for this direction of exploiting the trends in survival probabilities.
While there is a vast literature on modelling and projecting mortality rates (e.g.,
Lee and Carter 1992;
Booth and Tickle 2008), relatively less attention has been paid on forecasting survival probabilities directly. Amongst the few previous works,
De Jong and Marshall (
2007) applied the probit link function to the survival probabilities of Australian females and assumed that it is driven by a single time trend.
Hatzopoulos and Haberman (
2015) used the complementary log-log link function and age-cohort effects within the GLM (generalised linear model) framework for the cohort survival probabilities of a few European countries.
Wong and Tsui (
2015) proposed a new survival function for US women and men and modelled the changes of its parameters over time by autoregressive processes.
Tan et al. (
2016) constructed a hybrid survival curve and applied the logit link function to the annualised survival probabilities with two or three sets of time-varying parameters using Swedish and Bulgarian data.
There are potential advantages of modelling and projecting the survival probabilities rather than the mortality rates. First, when producing life expectancy forecasts, it would be more convenient to work with the survival probabilities directly without having to compound the mortality rates to form the survival rates. In a similar vein, when pricing pensions or annuities, the future probabilities of survival are a major input for the calculation process, and so it would be more natural to build a projection model that focuses on the survival probabilities. Moreover, as shown in the following sections, the survival probability patterns and trends are generally quite stable, which make their forecasting more straightforward than otherwise. We will show in our empirical analysis that some of these survival rate projection models can actually outperform the more conventional approach of a mortality rate projection model.
As mentioned above, forecasting survival probabilities are much less explored in the literature when compared to forecasting mortality rates. In this paper, we attempt to reduce this knowledge gap by examining extensively a number of link functions on survival probabilities and modelling the evolution of the parameters and so the survival rates over time. The link functions considered include the probit, complementary log-log, logit, gevit functions, and a new link function based on the theory of minima, and both the age and period effects are incorporated. Furthermore, we illustrate how the survival rate projection models can be extended to include additional explanatory variables such as the GDP (gross domestic product) per capita. Some previous examples of incorporating macroeconomic factors into mortality rate projection models are
Hanewald (
2011);
Niu and Melenberg (
2014);
French and O’Hare (
2014); and
Seklecka et al. (
2019). To the best of our knowledge, our paper provides the first attempt to incorporate macroeconomic factors into the survival rate projection models.
The remainder of the papers is as follows.
Section 2 gives an introduction of the various survival rate projection models being considered.
Section 3 compares the fitting performances of the models for Australian and New Zealand data.
Section 4 sets forth an out-of-sample analysis for measuring the forecasting performances of the models.
Section 5 studies the potential link between the survival probabilities and the economic growth.
Section 6 concludes.
2. Survival Rate Projection Models
Suppose
is the mortality rate at age
in year
, and
is the corresponding period survival probability in year
for a surviving period of at least
years. The first link function we consider is the probit function used by
De Jong and Marshall (
2007). We set the model structure as
, in which
is the inverse standard normal cdf (cumulative distribution function) and
is a regression structure allowing for the age and period effects with
. If one treats
as the cdf of the future lifetime (within
years) of a life aged
in year
,
as the survival function of that future lifetime, and
as a certain constant for
, it can be deduced that
and so
. It then means that under this probit model structure, the future death rates can be seen as a Wang transform (
Wang 2000) of the past death rates, with the parameter
capturing the mortality decline. Note that the probit link function ensures that the survival rates are between 0 and 1, regardless of the values of
, and that it is a symmetric link as
approaches 0 and 1 at the same pace.
The next one is the complementary log-log link function used by
Hatzopoulos and Haberman (
2015). We follow their model structure as
, that is, the link function is being applied on
, but not
. Unlike the probit function, the complementary log-log function is an asymmetric link, which would be useful for the rectangularisation patterns as in
Figure 1. This asymmetry may suit survival modelling better when compared to a symmetric one. The survival rates under this link function are between 0 and 1.
We apply the logit link function from
Tan et al. (
2016) as
. It is a symmetric link like the probit function, and it constrains the survival rates between 0 and 1. Its inverse function
is actually the cdf of the logistic distribution with the location parameter equal to 0 and the scale parameter equal to 1. Both the probit and logit functions are used extensively in binary response models.
Recently,
Medford and Vaupel (
2019) proposed the so-called gevit link function for modelling mortality rates. We apply this link function differently here as
; that is, it is being applied on the survival probability but not on the death rate. This link is asymmetric and it constrains the survival rates like those above. Its inverse function
is indeed the cdf of the GEV (generalised extreme value) distribution for
maxima with the location parameter equal to 0 and the scale parameter equal to 1. The extra shape parameter
provides more flexibility to manage the extent of asymmetry.
Inspired by the gevit link function, which is based on maxima, we exploit the GEV distribution for “
minima” instead (e.g.,
Liu and Li 2019) as an alternative. The cdf of the minima GEV distribution is specified as
. Accordingly, we consider a new model structure
. It is straightforward to deduce that this new link is also asymmetric and the resulting survival rates are within the valid range. We refer to it as the “gevmin” model structure in the following analysis.
If this new link is applied on instead of , the model structure becomes . Then if , it reduces to , which means that the complementary log-log model structure above can effectively be seen as a specific example of this alternative model structure from minima.
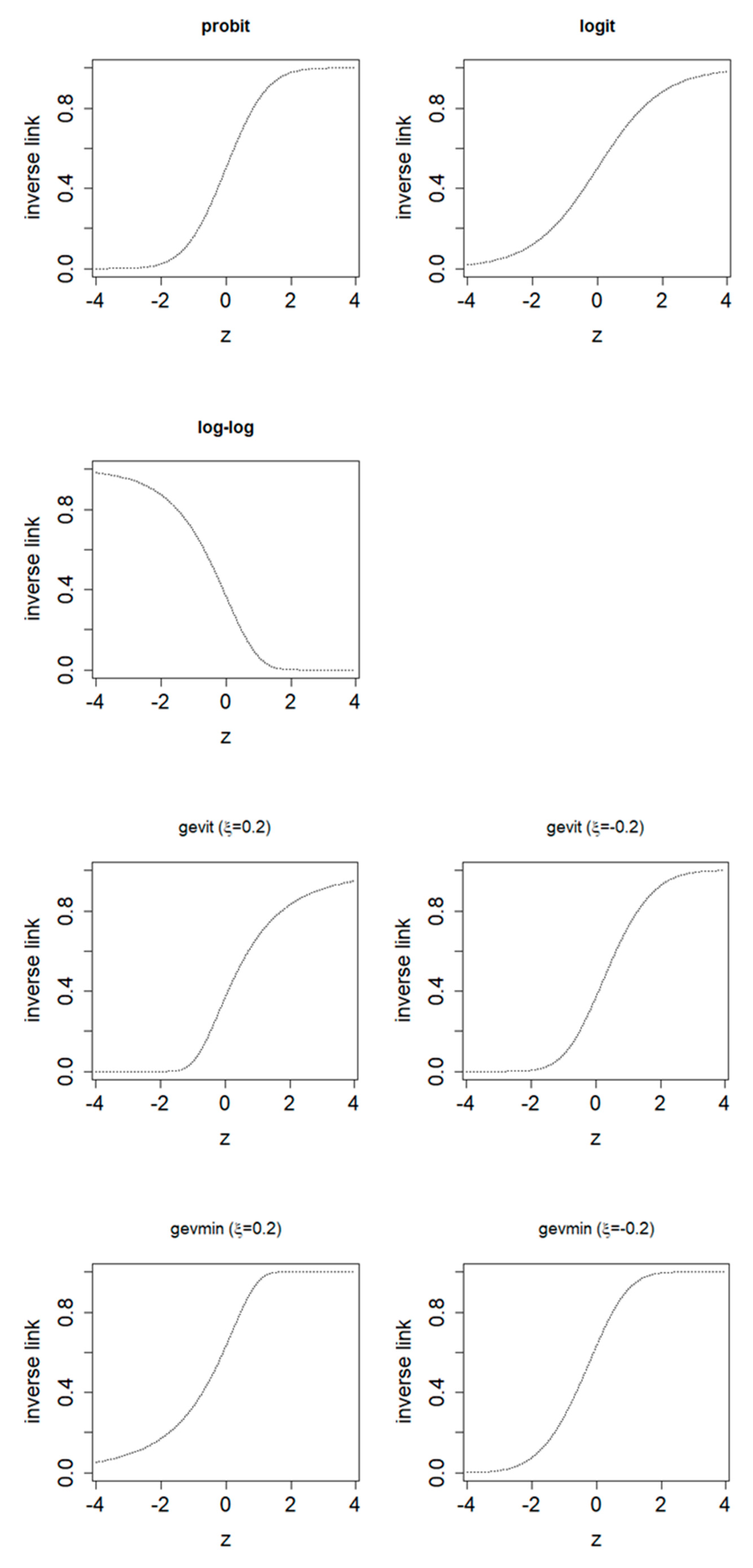
Figure 2 compares the symmetry of the probit and logit functions with the asymmetry of the complementary log-log, gevit, and gevmin functions as described above. For the symmetric ones, the response approaches 0 and 1 at the same pace. For the asymmetric complementary log-log and gevit functions, the response approaches 1 slower than reaching 0. By contrast, under the new gevmin model structure, the response of the (inverse) link approaches 1 faster than reaching 0, which is an opposite situation. As reflected in
Figure 1, as the rectangularisation continues to occur, the survival rates of more and more ages
rise above 0.5 and get closer to 1 over time
, while the rates drop more and more sharply at the progressively narrowing highest end. This phenomenon may make one or more of the asymmetric candidates more suitable for modelling how the survival rates evolve over time. More details of the maxima and minima GEV distributions are given in the
Appendix A.
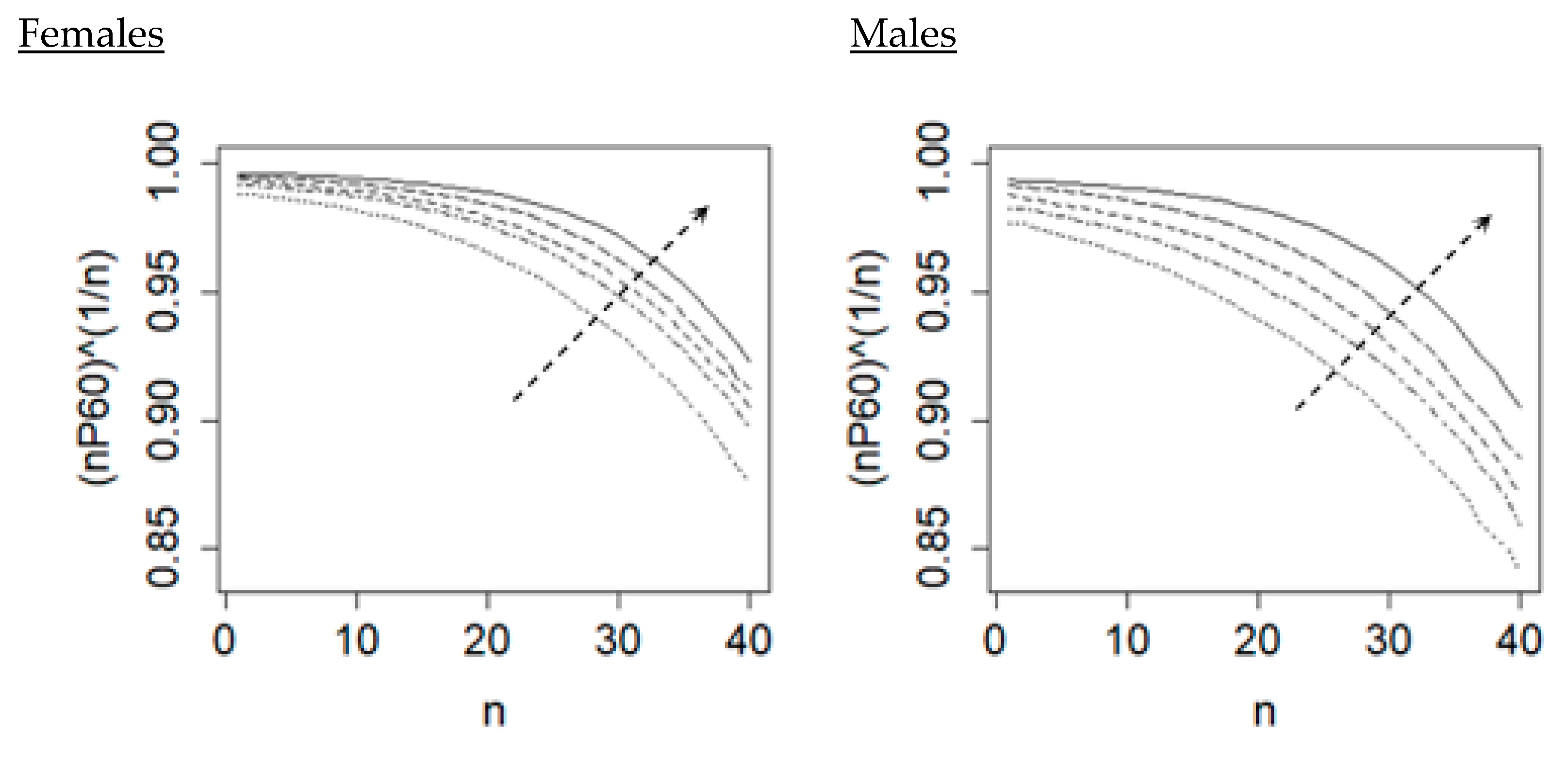
In addition to
, we also follow
Tan et al. (
2016) and consider another response
, that is, the “annualised” survival probability for comparison.
Figure 3 shows that the resulting annualised survive curve also displays an upward and rightward shift over successive time periods. Regarding the regression structure
, we employ both the
Lee and Carter (
1992) structure and the
Cairns et al. (
2009) structure to allow for the age and period effects. The first one is taken as
, and the second one as
, where
is the age effect,
is the “survival index” with age-specific sensitivity
,
to
are three time-varying parameters,
is the average of the age range, and
is the average of
over the age range considered. Altogether, there are 5 (links) × 2 (responses) × 2 (structures) = 20 combinations under our consideration. This coverage is much more comprehensive than those of the few earlier papers on projecting the survival rates directly. Subsequently, we will also explore adding macroeconomic factors into the regression structure to see whether it can improve the performances. The
Appendix A provides the parameter estimation methods for the models tested.
Note that some of these stochastic projection models can be seen as modifications of those standard static mortality or survival functions. Suppose
and
represent the force of mortality and the
t-year survival rate of a life aged
x for a static one-year life table. For instance, the Gompertz law states that
, which can be transformed into the survival function
and a regression structure
. The old-age component of the Heligman–Pollard curve can be taken as
, which can be expressed as the survival function
and a regression structure
. The famous Lee–Carter model (
Lee and Carter 1992) and the CBD model (
Cairns et al. 2006) can be seen in some way as adding time-varying components into the two regression structures above (log and logit) in order to turn them from being static to stochastic. While the stochastic Lee–Carter and CBD models deal with mortality rates, as compared to our approach of modelling survival probabilities, we will include them in the following analysis for comparison.
3. Fitting Performances
In this section, we apply the 20 models (combinations) to female and male populations in Australia and New Zealand. The mortality data of ages 60 to 99 and years 1970 to 2017 of Australia (1970 to 2013 for New Zealand) are extracted from the Human Mortality Database (
HMD 2020). For demonstration purposes, we consider the survival probabilities for a life aged 60 and set
(for surviving periods
= 1, 2, 3, …, 40), as the mortality rates below age 60 have already reached very low levels and have relatively little impact on the overall survival rates. In fact, the survival rate of a newborn for a surviving period up to 60 years is now very close to one, and the corresponding movements over time look too insignificant for a meaningful projection. By contrast, there is still much room for the survival rates at ages 60 and above to improve, and as shown below, the resulting patterns and trends are rather stable and can readily be projected into the future. Moreover, longevity of retirees is a serious concern for governments, insurers selling annuities, and pension funds because of the increasing financial burden. It would be of high practical interest to focus on the mortality of retirement ages.
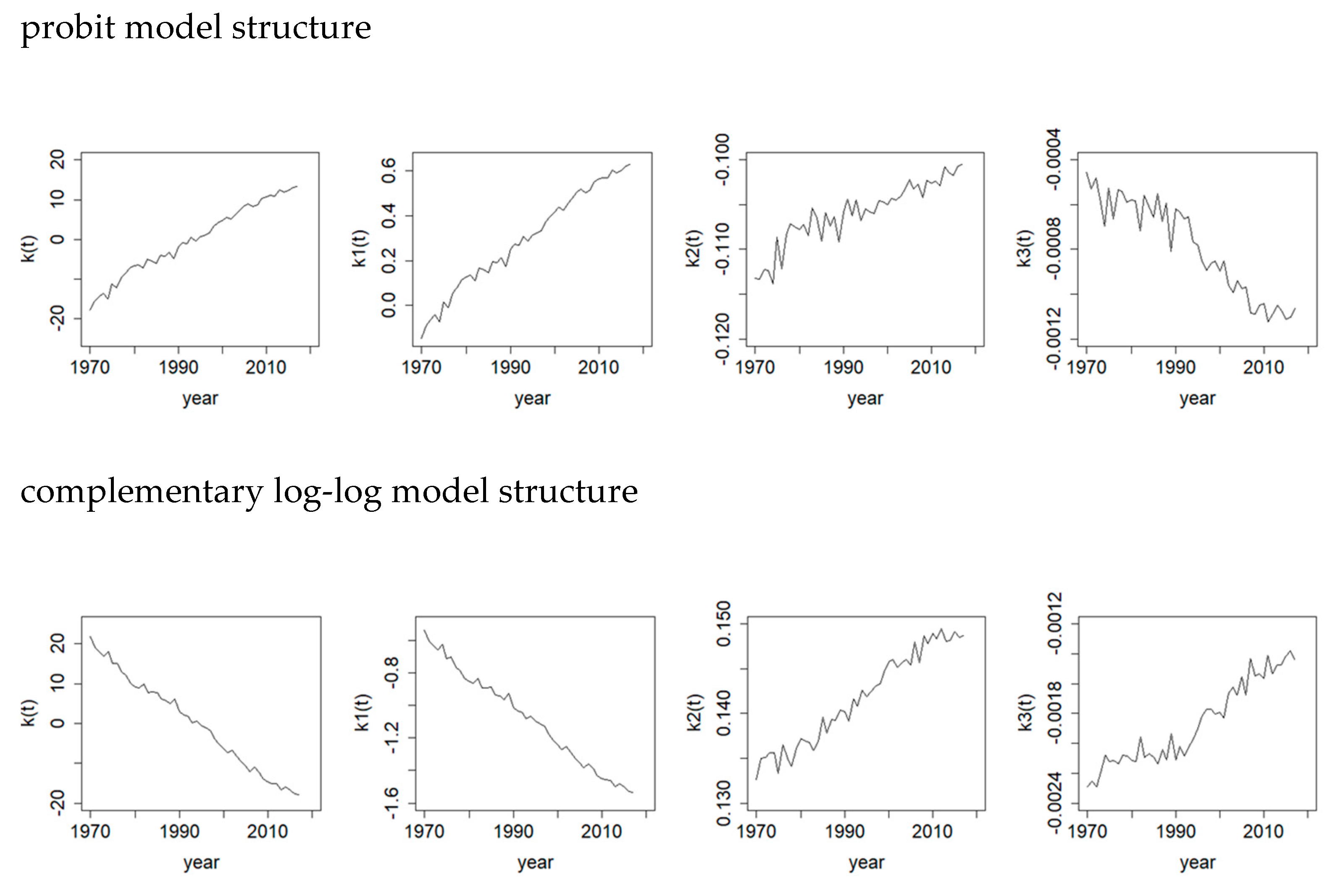
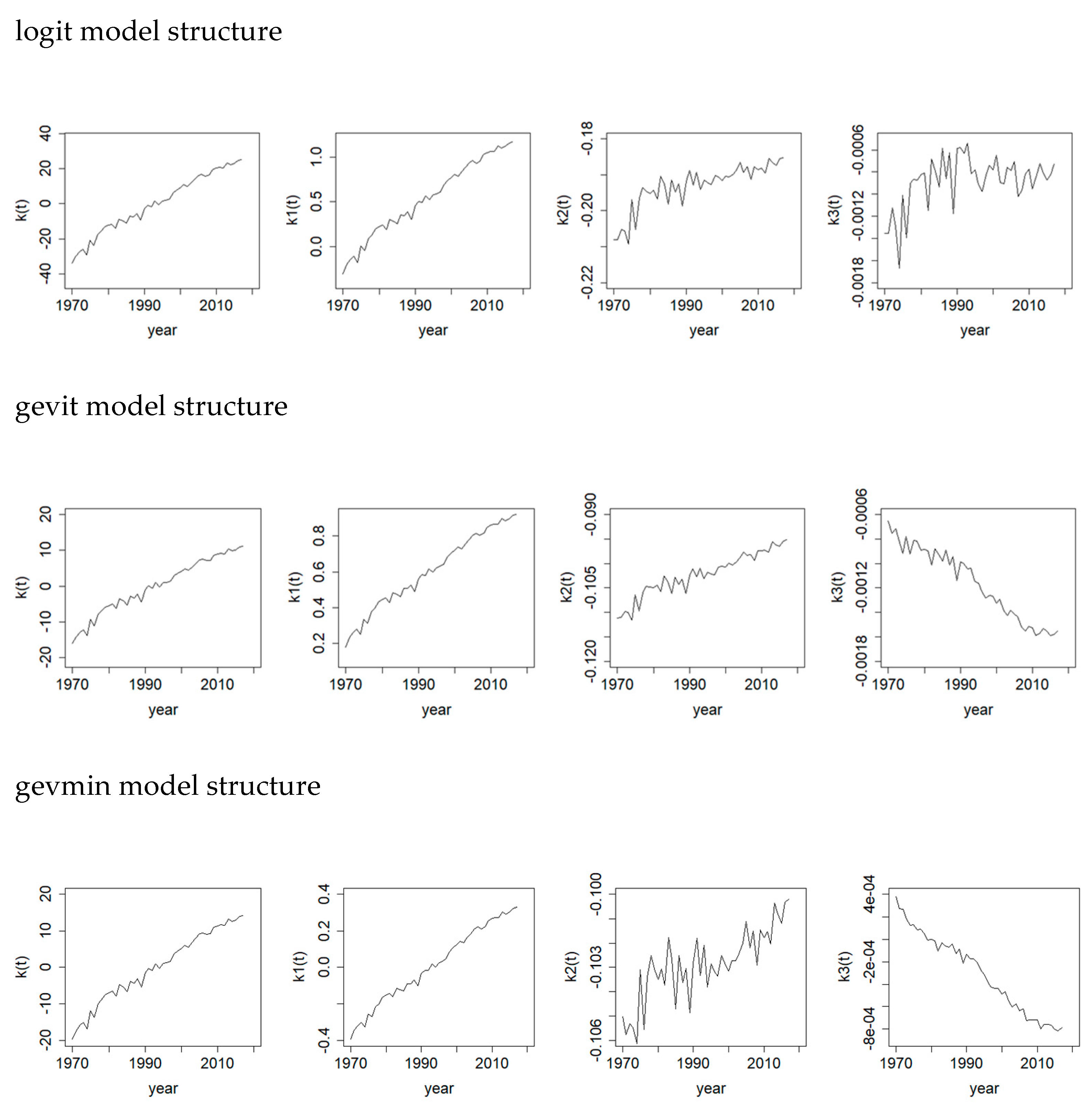
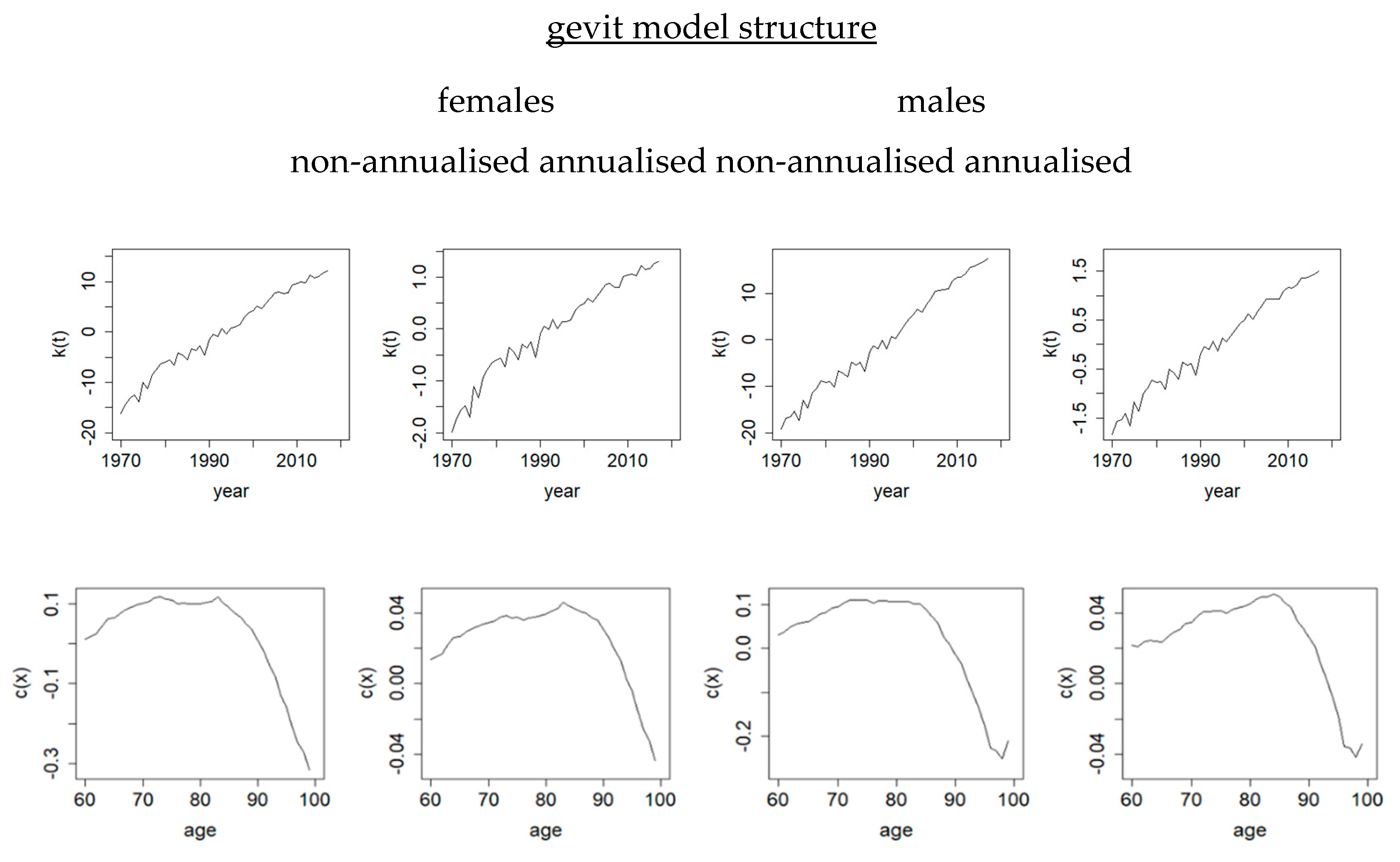
Figure 4 plots the survival index
of the first regression structure and also the time-varying parameters
to
of the second regression structure based on the five different link functions for the survival probabilities of Australian females. It is interesting to see that all the temporal parameters of
and
demonstrate a strong linearly increasing trend. It reflects clearly the continually improving survival rates at old ages as a whole. (For the complementary log-log model structure,
Figure 2 displays a negative relationship between the response and the argument in contrast to the others. The resulting major trends of
and
in
Figure 4 are then inverted, but the implication on mortality decline is the same.) The time-varying parameters
and
of the second regression structure refer to the slope and curvature in year
. While the directions of their trends are different because of the differences in how the link functions operate on the survival rates, a high level of linearity can largely be observed. We can then use the (univariate or multivariate) random walk with drift to project all these linear trends. Compared to the time-varying trends usually seen when modelling the mortality rates (e.g.,
Cairns et al. 2009), modelling the survival rates here generates more linear trends, which make the use of the random walk with drift more justifiable than otherwise. The observations for Australian male and New Zealand populations (not shown here) exhibit similar patterns.
Table 1 reports the MAPE (mean absolute percentage error) values on
of fitting the 20 models, with the original Lee–Carter model (
Lee and Carter 1992) and the CBD model with curvature (
Cairns et al. 2009) for the death rates also included for comparison. The major observations are stated below:
- (1)
For the first regression structure, the MAPE values are often smaller when the response is . By contrast, for the second regression structure, the MAPEs are much smaller when the response is .
- (2)
When the response is , the MAPE values from the first regression structure are clearly smaller. However, when the response is , the situation is mostly reversed.
- (3)
For the complementary log-log model structure with the first regression form, the MAPE remains the same regardless of the response (i.e., or ). The underlying reason is that is indeed equivalent to , where . Hence, they produce the same fitted values of and so the same MAPEs.
- (4)
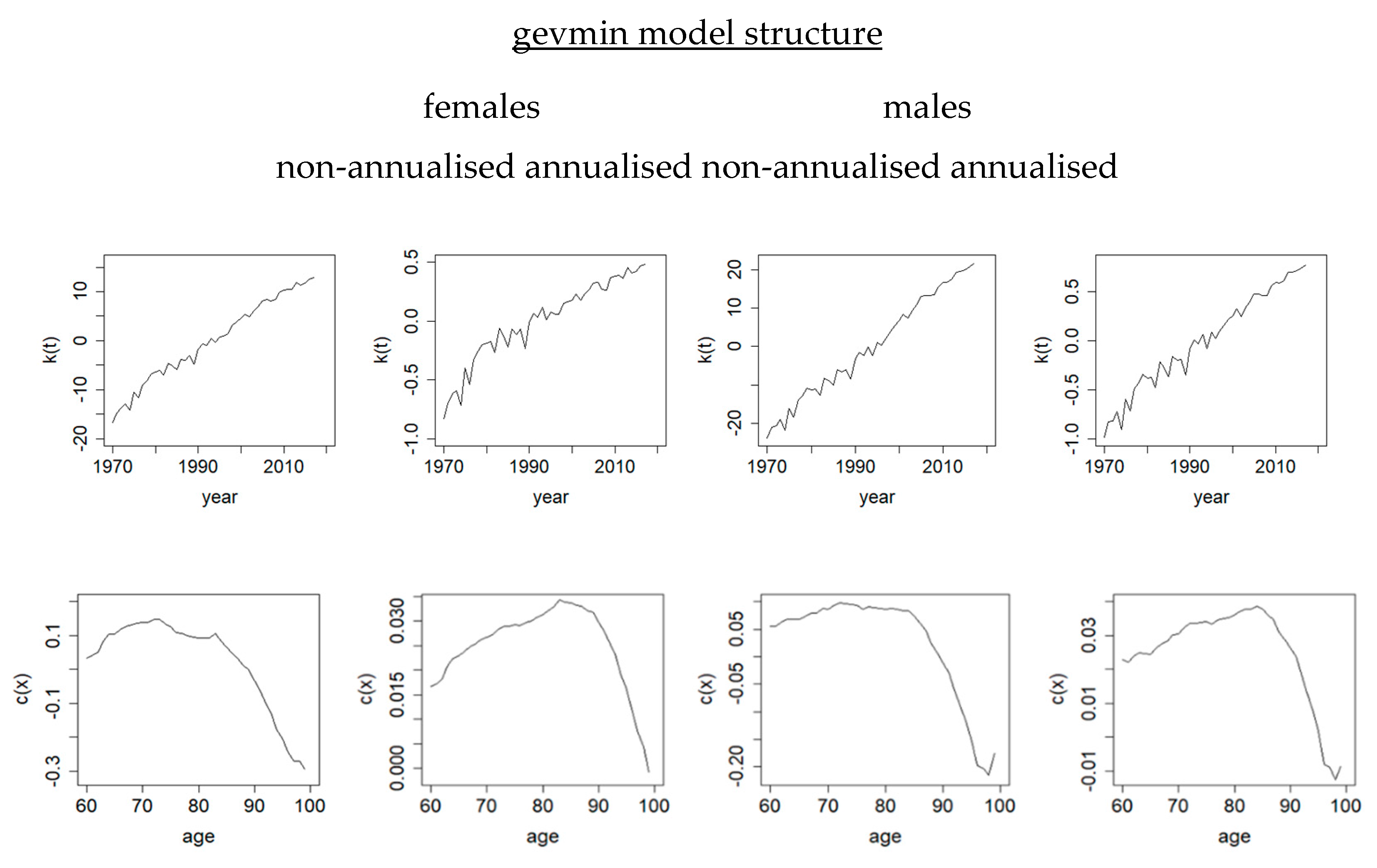
Overall, the combination of the response and the second regression structure (i.e., ) gives the better MAPEs. In particular, the gevmin model structure, based on the newly proposed gevmin link, leads to the smallest MAPEs consistently for all the populations (0.73, 0.93, 1.20, 1.68) considered.
- (5)
The best gevmin model structures noted above outperform the more traditional approaches of the Lee–Carter and CBD models in modelling the mortality rates (with MAPEs of 1.39 to 3.02).
Compared with the traditional link functions, the additional shape parameter
in the gevmin and gevit link functions makes them a lot more flexible in capturing different degrees of asymmetry. For each population in
Table 1, the two smallest MAPEs are all generated from either the gevmin or gevit model structure. The empirical advantage of using these two newer links is apparent here. Note also that the response
(see
Figure 3 again) has a simpler shape over
than the response
(see
Figure 1). Hence, a simple regression structure in terms of merely
(i.e.,
) would suffice for the former, while a more dedicated allowance for the age effect (i.e.,
) would be needed for the latter.
As noted earlier, if the new gevmin link is applied on rather than , the model structure turns into . It can further be rearranged as , which then becomes the gevit model structure effectively. Consequently, they generate the same fitted values of and the same MAPEs, though the resulting signs and trends of their parameters are opposite to each other. However, the increasing survival index based on the gevmin link on has a more natural interpretation in terms of improving survival over time.
4. Forecasting Performances
In this section, we perform an out-of-sample analysis to assess the forecast accuracy of the survival rate projection models. We apply the models to four fitting periods of 1970 to 1989 (20 years), 1970 to 1994 (25 years), 1970 to 1999 (30 years), and 1970 to 2004 (35 years) and then forecast the survival rates for the remaining periods until the very last year of available data. Here we focus on the annualised response and the second regression structure since they give the better fitting performances in
Table 1. In addition to continuing to use the Lee–Carter and CBD models for comparison, we also apply the multivariate random walk with drift to the survival probabilities as a benchmark, naive model. The MAPEs of not only the projected
but also the projected life expectancies at age 60 are examined to compare the performances. They are calculated as
and
respectively, where
and
(
and
) are the projected and observed survival probabilities (life expectancies) in year
,
is the number of data points, and
is the number of years in the testing period. For each case (column) in
Table 2, the three lowest MAPE values are highlighted (in grey). We notice the following patterns within the results in
Table 2:
- (1)
Out of the 16 cases (4 fitting periods × 2 countries × 2 sexes), the gevit and gevmin model structures produce the three lowest MAPEs in 12 cases. Their performances are the most consistent ones amongst all the candidates.
- (2)
For the gevit and gevmin model structures, the average MAPE is 6.10. For the probit, complementary log-log, and logit model structures, the average MAPE is 6.29. For the LC and CBD models, the average MAPE is 6.53. For the naive random walk model, the average MAPE is 7.95.
- (3)
The MAPE values tend to be lower for females (4.04 on average) than for males (8.98 on average).
- (4)
The MAPE values tend to be lower for Australia (5.65 on average) than for New Zealand (7.36 on average).
- (5)
The naive random walk model leads to the highest MAPE values in 10 cases.
Overall, the gevit and gevmin model structures deliver the best and the most consistent forecasting performances among the eight alternatives. Moreover, the survival rate projection models as a whole also tend to outperform the usual Lee–Carter and CBD models in this out-of-sample analysis of the survival rates. These results highlight the potential usefulness of projecting the survival rates directly when the focus is on the survival probabilities. The generally poor performances by the naive random walk model also emphasise the importance of having a proper model structure for modelling the survival rates.
Regarding the MAPEs of the projected life expectancies in
Table 3, the gevit and gevmin model structures continue to perform well relative to the others. Their average MAPE is 2.31, compared to 2.56 for the probit, complementary log-log, and logit model structures and 2.81 for the LC and CBD models. It highlights again the flexibility offered by the extra shape parameter and the potential benefits. Moreover, the survival rate projection models still perform better than the Lee–Carter and CBD models in general. Projecting the survival rates directly would be a useful strategy or alternative if the main task is to forecast future life expectancies. It is also interesting to note that the average MAPE for the naive random walk model is only 2.44. We conjecture that their larger errors as shown in
Table 2 may have coincidently offset one another to some extent across different ages as life expectancy is effectively an aggregate measure of survival probabilities. Anyway, the advantages of imposing an appropriate model structure are obvious in modelling the survival rates.
In addition to the MAPE values, the sMAPE (symmetric mean absolute percentage error) values are also calculated and given in the
Appendix A. The major implications are largely the same as those discussed above.
5. The Effect of Economic Growth
There have been previous studies in the area of demography and macroeconomics showing the impact of economic fluctuations on mortality levels (e.g.,
Ruhm 2000;
Brenner 2005). A few earlier papers in mortality projection that incorporated exogenous economic factors include
Hanewald (
2011),
Niu and Melenberg (
2014), and
Boonen and Li (
2017). They showed that the Gross Domestic Product (GDP) of a nation may serve as an explanatory factor of a country’s mortality rates. Furthermore, they demonstrated that it may be integrated into extrapolative mortality models such as the Lee–Carter model or its extensions to improve the fitting quality. In this section, we experiment with embedding such macroeconomic factor into the survival rate projection models. As a preliminary analysis, we find some positive correlation (
= 0.17 for Australian females, 0.10 for Australian males, 0.08 for New Zealand females, 0.15 for New Zealand males) between the annual change in survival index
and the annual growth in real GDP per capita for the period from 1970 onwards (for Australia and New Zealand respectively). The survival index
can be seen as an underlying driver of the survival probabilities and so an indicator of how life expectancy changes, and the GDP trend is a very important indicator of economic growth. This observation provides some incentive for putting the survival trend and the economic trend together into the modelling framework. By doing so, the extended model may produce more interpretable implications on the projected survival rates based on the projected economic growth. In effect, such a model can be regarded as partly extrapolative (using past survival trends) and partly explanatory (using exogenous GDP figures). Note that the GDP can be regarded as an overall indicator of the quality of life. As the focus of our study is the use of new link functions in modelling survival probabilities and the aggregate data used are of country level, we deem that the GPD itself would be sufficient for our analysis
1.
Accordingly, we modify the first regression structure as
, in which
is the (log) real GDP per capita in year
and
is the (age-specific) associated coefficient. The values of
are adjusted such that
, and so
still refers to the overall (average over time) age effect. The real GDP per capita data are obtained from World Development Indicators (
WDI 2020), the primary database maintained by World Bank on comparative development indicators across countries worldwide.
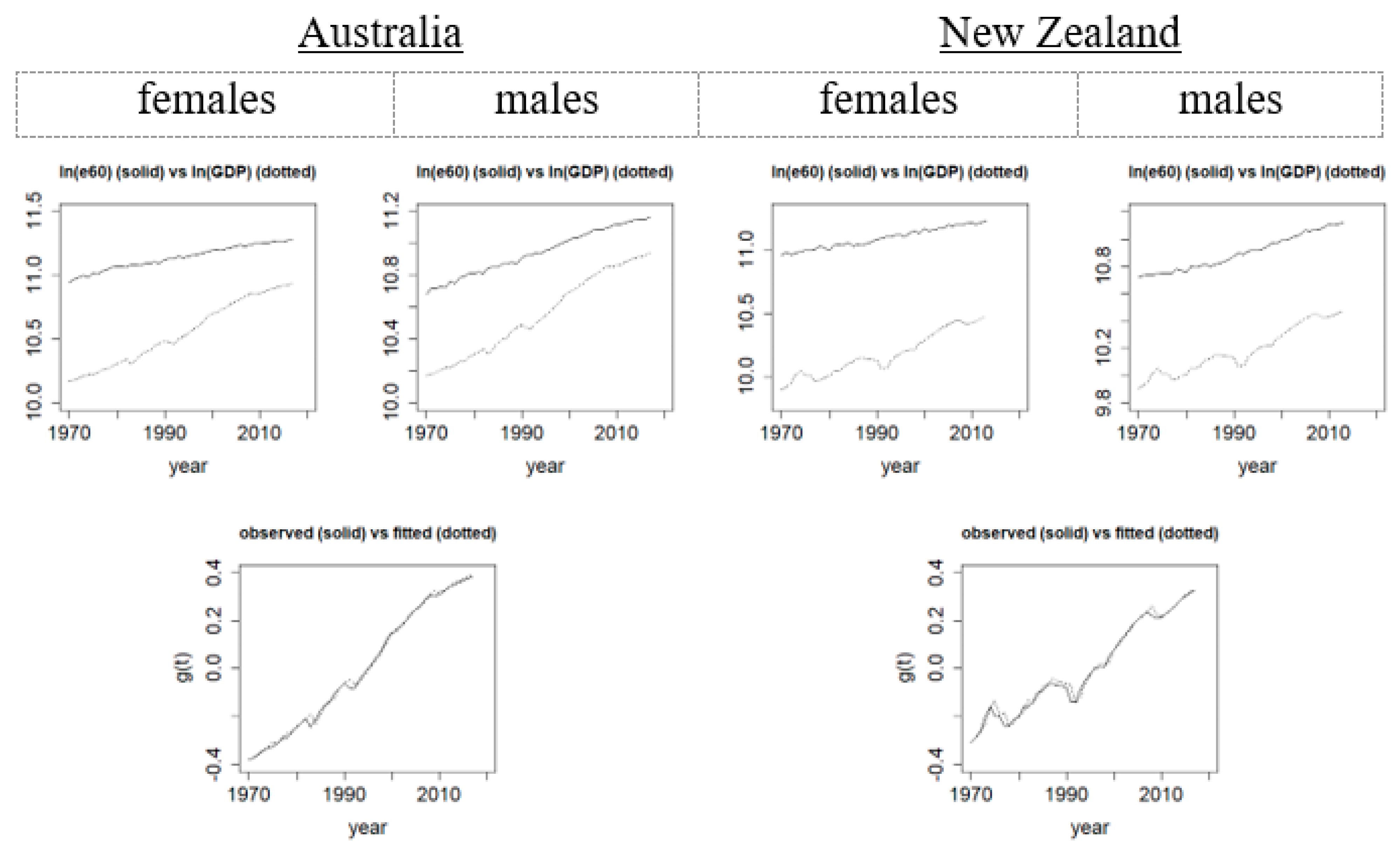
Figure 5 (upper panel) illustrates the increasing trend of the GDP in recent decades, as well as some potential co-movements with the life expectancy trend. Following the
Box and Jenkins (
1976) approach, we find that the ARIMA(1,1,0) process (autoregressive integrated moving-average) provides an adequate description of the dynamics of the GDP process.
Figure 5 (lower panel) also shows that the fitted GDP values from ARIMA(1,1,0) are very close to the observed values.
Figure 6 plots the survival indices under the modified (with GDP) first regression structure with the gevit and gevmin links. While the new factor
is supposed to explain part of the rising survival trend, the computed survival indices still exhibit a clear linearly increasing trend, though their drifts (around 0.37) are smaller than previously (about 0.43 without the GDP factor). It is also interesting to see in
Figure 6 that the age-sensitivity
is high at ages 60 to 80 but it drops drastically after around age 80, reflecting that the very-old-age mortality is still much less responsive to economic growth (likely due to current technological and medical limitations).
Table 4 compares the fitting performances with and without the GDP factor. Interestingly, all the MAPE values become smaller after incorporating the GDP covariate. Furthermore,
Table 5 and
Table 6 present the forecasting performances before and after embedding the GDP covariate under the same out-of-sample test setting as in
Section 4. For both the projected survival probabilities and the projected life expectancies at age 60, adding the GDP factor leads to a clear improvement in forecast accuracy in most of the cases. It is obvious that besides the selection of appropriate link function, age and period effects, and annualisation of the survival rates, integrating a GDP explanatory factor within the model has much potential in further enhancing the performance of a survival rate projection model.
A final note is that while our regression structure here is designed to examine how the economic trend would affect and/or move synchronously along with the survival trend over the long term, we acknowledge that the underlying process can be more complicated in terms of the direction of causation and the lagging effect. These matters are beyond the scope of this paper and we leave them for future research.
6. Concluding Remarks
In this paper, we have conducted a thorough examination on several old and new link functions for their applications in modelling how old-age survival probabilities evolve across time in Australasia. The link functions under investigation include the newly proposed gevit and gevmin links, which are compared against the traditional ones like probit, complementary log-log, and logit links. We use the random walk with drift to project the temporal parameters due to their highly linear trends in the past decades. Future survival probabilities and life expectancies are then projected using the estimated parameters. We notice that many of these survival rate projection models can produce better fitting and forecasting performances than the more conventional approach of modelling mortality rates, in terms of achieving lower MAPE and sMAPE values. Hence, projecting the survival rates directly would serve as a useful strategy or alternative if the objective is to forecast future life expectancies. In particular, the gevmin and gevit links are found to be able to offer extra flexibility in depicting the (annualised or non-annualised) survival curve patterns and improve the model performance. This extra flexibility comes from the additional shape parameter that copes with any extent of asymmetry. Lastly, we illustrate how these survival rate projection models can be modified to incorporate additional explanatory variables, in an attempt to further enhance the model results. We notice that adding a covariate on the real GDP per capita can improve the general fitting performances as well as many of the forecasting performances. Note that our approach can be applied similarly to other ages above 60 for . The focus of this work is on forecasting survival probabilities at ages 60 and above, as the current death rates below age 60 are very low and their impact on the overall survival rates has become much less important. If one is interested in modelling the entire age range, the Lee–Carter model and its various extensions in modelling mortality rates can be used instead.
There are two potential areas for future research. First, since a link function is often constructed from the inverse of a cdf, the use of other cdfs can be explored. There are a range of skewed distributions which may be useful for tackling different levels of asymmetry. Second, while we have used two particular regression forms in our analysis, there are other possible structures that also allow for the age and period effects. Some examples include adding extra time-varying parameters and co-modelling the survival rates of related subpopulations.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







