1. Introduction
Popular GARCH (
Bollerslev 1986) models have been extensively used by practitioners and scholars to account for well-known stylized facts of energy commodities such as asymmetry, leptokurtosis, leverage effect, and volatility clustering. For instance,
Lv and Shan (
2013) compare the performance of different specifications of GARCH models to forecast natural gas volatility, whereas
Laporta et al. (
2018) investigate the performance of different GARCH specifications for modeling the Value-at-Risk of seven energy commodities. However, univariate models are not able to explain dependences in the dynamics of the volatility of energy commodities. For this reason, many studies employ multivariate GARCH models (surveyed by
Bauwens et al. 2006;
Silvennoinen and Teräsvirta 2009) to study the comovements of commodities returns, capturing time-varying volatilities and correlations. The Dynamic Conditional Correlation (DCC) class of models (
Engle 2002) achieves such a goal, and it has been widely applied to energy markets. For instance,
Sadorsky (
2012) finds that the DCC model performs better than other multivariate GARCH models in capturing the interdependencies among the West Texas Intermediate (WTI) oil returns and two weighted returns’ indexes of clean energy and technology companies.
Wang and Wu (
2012) use the DCC model to forecast the volatility and correlations among the returns of crude oil, gasoline, heating oil, and jet fuel.
Behmiri et al. (
2019) investigate the relationships among natural gas, oil and other non-energy commodities,
Mishra (
2019) studies the correlation between oil and foreign exchange markets, whereas
Basher and Sadorsky (
2016|) focus on the connection between stock indices and oil returns.
The rapid spread of COVID-19 favored the transmission of shocks from the real economy to the financial markets, emphasizing the importance of developing accurate analytic models to assess and quantify such shocks. Recently, many contributions investigated the effects of the recent COVID-19 outbreak to understand the real effects of the pandemic on energy commodity returns. For instance,
Ghorbel and Jeribi (
2021) investigate the interconnections between the volatilities of crude oil, gas, energy index, and financial assets’ returns during the COVID-19 pandemic through a Markov Switching multivariate GARCH model;
Narayan (
2020) evaluates the effect of COVID-19 infections and oil price news on oil prices;
Gil-Alana and Monge (
2020) study the persistence of the outbreak shock on oil prices;
Iyke (
2020) and
Foglia and Angelini (
2020) identify the volatility spillovers between oil and clean energy companies;
Gil-Alana and Monge (
2020) and
Bouazizi et al. (
2021) study the effect of the pandemic on the volatility of oil returns;
Corbet et al. (
2020),
Lin and Su (
2021), and
De Blasis and Petroni (
2021) study the connected relationship between oil and other energy markets, such as renewables and coal, employing the DCC model. This strand of literature is particularly relevant since it studies both the behavior of energy commodities in the extraordinary and unexpected circumstances of the pandemic, which caused a strong rise in volatility levels, as well as in the unprecedented situation of negative prices. In April 2020, crude oil recorded a 300% drop in price, assuming a negative price for the first time in the history. The rise in volatility of these commodities is found to be mainly due to government restrictions (such as the lockdown and travel restrictions), which lowered the global demand of energy commodities, such as crude oil and Kerosene-Type Jet Fuel, and, in turn, significantly affected their prices.
The aim of our paper is to investigate the time-varying correlations of energy commodities during the whole pandemic period in order to understand the deep impact of the COVID-19. The period considered starts from the first wave in March 2020 until the midst of the vaccination campaign in June 2021, corresponding to the beginning of the economic upturn and the consequent recovery of energy commodities’ prices. We investigate daily returns of six of the main energy commodities: WTI crude oil, Brent crude oil, Heating oil #2, Propane, New York Harbor Conventional Gasoline Regular, and Kerosene-Type Jet Fuel, by means of a set of DCC-GARCH models, which is the corrected DCC (cDCC,
Aielli 2013), the DCC-MIDAS (
Colacito et al. 2011), and the Dynamic Equicorrelation (DECO,
Engle and Kelly 2012). A distinctive feature of the DCC class of models is the possibility to split the estimation phase into two steps: one for the univariate volatilities and another for the correlations.
In order to assess the impact of the COVID-19 outbreak on the volatility of energy markets, we include in the analysis the number of weekly deaths in the United States (US) caused by the COVID-19, which is the variable most used by governments to impose restrictive measures. The use of such a variable sampled at a lower frequency than daily energy prices leads us to rely on the class of MIDAS models (
Ghysels et al. 2007). In particular, we exploit the number of US weekly deaths in the univariate specifications of the GARCH-MIDAS (GM,
Engle et al. 2013) and Double Asymmetric GARCH-MIDAS (DAGM,
Amendola et al. 2019). The inclusion of the DAGM model allows us to evaluate the effects of positive and negative variations of the COVID-19-related deaths in the US on the daily volatility of commodity returns. To the best of our knowledge, the assessment of the potential effect of the COVID-19 pandemic on the interdependences of daily commodity returns through low-frequency variables has not yet been explored in the literature.
We evaluate the performance of our approach comparing the DCC models employed using the GM and DAGM specifications with GARCH model and the GJR (
Glosten et al. 1993) specification, which includes an asymmetric term related to negative daily returns. In order to choose the best model able to detect the phenomena under investigation, we perform a model selection procedure. In particular, we consider the Model Confidence Set of
Hansen et al. (
2011) to create a Set of Superior Models (SSM) relying on a particular loss function. Due to the correlation structure of the models, we consider three robust loss functions (
Laurent et al. 2013) based on the distance between the predicted conditional covariance matrix and its proxy, built as the cross-products of the daily log-returns. The same loss functions have also been used in
Amendola et al. (
2020), among others.
Regardless of the models applied in the multivariate step, our empirical results show that for two out of three loss functions only models with the DAGM specification enter in the SSM. The time-varying conditional correlations estimated with the models belonging to the SSM remain constant through the whole pandemic period, ranging between 0.6 and 0.9, which indicates strong comovements among commodities. Considering the importance of energy commodities in stock markets and macroeconomic fundamentals, the presence of a strong correlation between energy markets is translated in high risks of spillovers effects from commodities to financial markets and to the real economy. The results obtained in this paper confirm that the proposed methodology represents a valuable approach, which is statistically superior to others to discover fragilities in the economic and financial systems that, regardless of the economic upturn, still need to be addressed at the present time.
The contribution of our paper to the literature is two-fold. First, our paper considers for the first time the impact of the COVID-19 on six of the main energy commodities. The choice of energy commodities depends on the fact that they are exploited in industrial applications and used for hedging financial risks as discussed in (
Abid et al. 2020). As a matter of fact, the COVID-19 epidemic threatened the stability of the oil and gas industries, which were already weakened by the increasing use of renewables. Moreover, the mobility restrictions imposed during the first and second COVID-19 waves (
Arenas et al. 2020;
Nouvellet et al. 2021;
Sadowski et al. 2021) shocked the aviation and transportation sectors, which represent 60% of the demand of oil and other commodities, including Propane and Kerosene-Type Jet Fuel used in our analysis (
IEA 2020). Previous studies, instead, mainly focus on the effects of COVID-19 on oil and natural gas (
De Blasis and Petroni 2021;
Gil-Alana and Monge 2020;
Lin and Su 2021;
Narayan 2020). In particular,
Nyga-ukaszewska and Aruga (
2020) investigate the impact of the COVID-19 cases in the US and Japan on the crude oil and natural gas markets by means of Auto-Regressive Distributive Lag approach.
Wang and Su (
2021) examine the asymmetric causal relationship between COVID-19 and fossil energy prices and find that COVID-19 influences oil, natural gas, and coal prices. Second, we apply the mixed-frequency methodology, as in
Candila (
2021b), to the energy sector to evaluate the impact of COVID-19. Specifically, we investigate the effects of weekly deaths in the US due to COVID-19 on the daily energy commodities volatilities. We, therefore, contribute to the existing literature regarding the application of multivariate GARCH (
Ku et al. 2007;
Yousfi et al. 2021) to energy commodities (
Chang et al. 2011;
Chkili et al. 2014;
Silvennoinen and Thorp 2013) where time series data are sampled only at the daily frequency. To the best of our knowledge, this is the first attempt to study the impact of COVID-19 to energy sector using a mixed-frequency approach.
The rest of the paper is organized as follows.
Section 2 presents the models and different specifications used.
Section 3 shows the empirical study and discusses the results obtained.
Section 4 concludes.
2. Methodology
We denote with
the vector of daily log-returns observed at time
i of period
t, where
t has a lower frequency than
i. We consider
T low-frequency periods, each composed of
days. Denoting with
the multivariate normal distribution
1, we model the returns as in
Engle (
2002):
where
is the
conditional covariance matrix of returns, and
is obtained by the Cholesky decomposition of
. In addition,
is the
-vector of standardized residuals obtained through a univariate volatility model, and
is an
identity matrix. Within the DCC-GARCH model, the conditional covariance matrix
can be decomposed as follows:
where
is the diagonal matrix containing the conditional standard deviations, and
is the conditional correlation matrix of returns. The standardized residuals can be then expressed in terms of
:
From Equation (
4),
is estimated as:
In the DCC-GARCH model, the estimation procedure of the time-varying
and
is performed in two steps. First, a univariate volatility model is used to estimate the standardized residuals
, and then
is estimated according to a pre-specified correlation model. As a result, the model is governed by the parameter space
, where
is the parameter space of the volatility model and
that of the correlation model. The estimation of
is based on the global log-likelihood function
:
In this paper, we consider: three specifications of the correlation model (DECO, cDCC, and DCCMIDAS) and four univariate specifications of the volatility model (GARCH, GJR, GM, and DAGM) for a total of twelve parametric models. Regarding the univariate specifications of the volatility model, the GARCH model is described as follows:
The GJR specification is aimed at modeling the so-called leverage effect for which negative shocks have a higher impact on return volatility than positive shocks. Specifically:
In the GM and DAGM models, the volatility is decomposed into a long-term and short-term component. The long-term component is denoted with
and varies at the same frequency as the low-frequency variable
. The short-term component is
and varies on a daily basis. The difference between the GM and the DAGM model relies on the specifications of the long-term component. Formally,
and the short-term component for both the GM and DAGM models are:
where
, and
is the parameter that accounts for the skewness. The long-run term for the GM model is:
whereas, in the DAGM model, the contributions of positive and negative values of
are estimated separately, decomposing
in Equation (
13) into two parameters
and
:
Regarding the correlation models, the functional forms of the cDCC, DCC-MIDAS, and DECO are shown in
Table 1.
Model Selection
We select the best-performing models in terms of correlation estimation exploiting the Model Confidence Set (MCS) methodology (
Hansen et al. 2003), which allows us to select an SSM from those considered in the analysis. Starting from a set of models
, the MCS procedure allows us to select a subset of best models, the SSM, denoted with
of dimension
, with a given confidence level
. The MCS procedure consists of three steps: (i) collect the initial set of models
used in the analysis; (ii) select the loss function and perform the test of equal predictive ability (EPA) for each model in
with respect to that loss function; (iii) select the SSM according to the result of the EPA test. If the null hypothesis of the EPA test for a given subset of models is accepted, that subset is the SSM
. If the null hypothesis is rejected, rule out the worst performing model and return to step (ii) until the set
is defined.
More formally, recall that
is the
conditional covariance matrix estimated through the multivariate GARCH in Equation (
4) and denote with
the true conditional variance matrix. Since
is unobservable, the proxy
is considered and computed as the cross-products of
. We apply the MCS procedure to select the SSM according to the loss function
for the model
l, with
, for the day
i of the period
t:
The evaluation of the models is done based on three robust loss functions (
Laurent et al. 2013): Frobenius (FROB), Root Mean Squared Error (RMSE), and Eclidean (EUCL), defined as follows:
where
and
, respectively, denote the trace and norm of the matrix
, and
is the operator that stacks the lower triangular half of
into a single vector of length
.
For ease of notation, we here suppress the double time index to only report the day
i. In order to perform the EPA test, we define
, which is the loss differential of model
l with respect to model
k, and
, which is the average loss differential between model
l and every other competing model contained in the set
M, with
, at time
i:
and
Model
l has a better forecasting performance to model
k when
. The null and alternative hypothesis of the EPA test are:
In particular,
represents the sample loss of model
l related to the average losses across every other model
k,
is the average loss between model
l and
k and
is the bootstrap estimate of
. The EPA hypothesis is tested in Equation (
21) with the statistic:
Large values of
indicate that the distance between the estimates of the model and the actual realizations is greater for model
l than any other model
. This results in the rejection of the
l-th model from the SSM according to an elimination rule. Following
Hansen et al. (
2011), an elimination rule coherent with the statistic (
23) is:
The aim of Equation (
24) is to reject those models increasing
the most. At each iteration of the MCS procedure, if the null hypothesis of Equation (
21) is rejected at the fixed significance level
, the elimination rule in Equation (
24) eliminates the model that delivers the largest standardized excess loss with respect to the average loss (computed across all other models in
M). Then, the statistic from Equation (
23) is recomputed for all
. The procedure stops when the null hypothesis in Equation (
21) is accepted, and the SSM
is determined.
3. Empirical Application
In this work, six energy commodities used in industrial applications are considered: WTI crude oil, Brent crude oil, Heating oil #2, Propane, New York Harbor Conventional Gasoline Regular, and Kerosene-Type Jet Fuel. These commodities are widely traded in financial markets and represent a valid sample to investigate the role of the COVID-19 pandemic on the fluctuations of energy commodities. They are used in portfolio analysis and are highly sought after by academics and practitioners to investigate the transmissions of commodity risks, as discussed in
Naeem et al. (
2021) and
Chevallier and Ielpo (
2013), which demonstrate that oil is a net transmitter of risk to other commodities. Furthermore,
Karali and Ramirez (
2014) discover volatility spillover effects between natural gas and crude oil and between natural gas and heating oil, making the transmission of commodity risks through the financial system more likely. The times series of daily data have been collected from the US Energy Information Administration (EIA) site and span from January 2020 (one month before the start of the COVID-19 pandemic) to June 2021, leading to a total of 276 daily observations. All the estimates have been computed in
R, using the package
dccmidas (
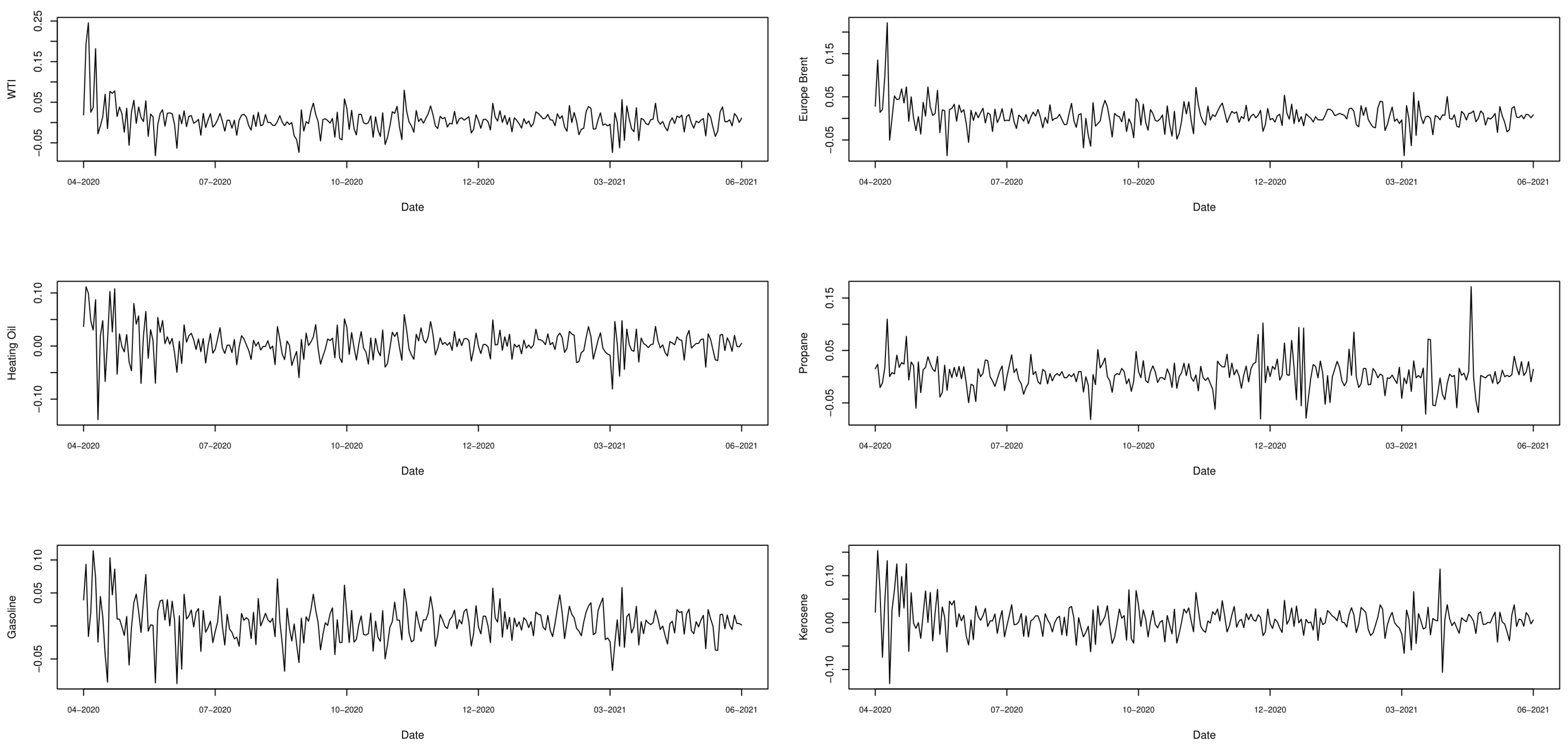
Candila 2021a). The summary statistics of the considered commodities, and the related plots are reported in
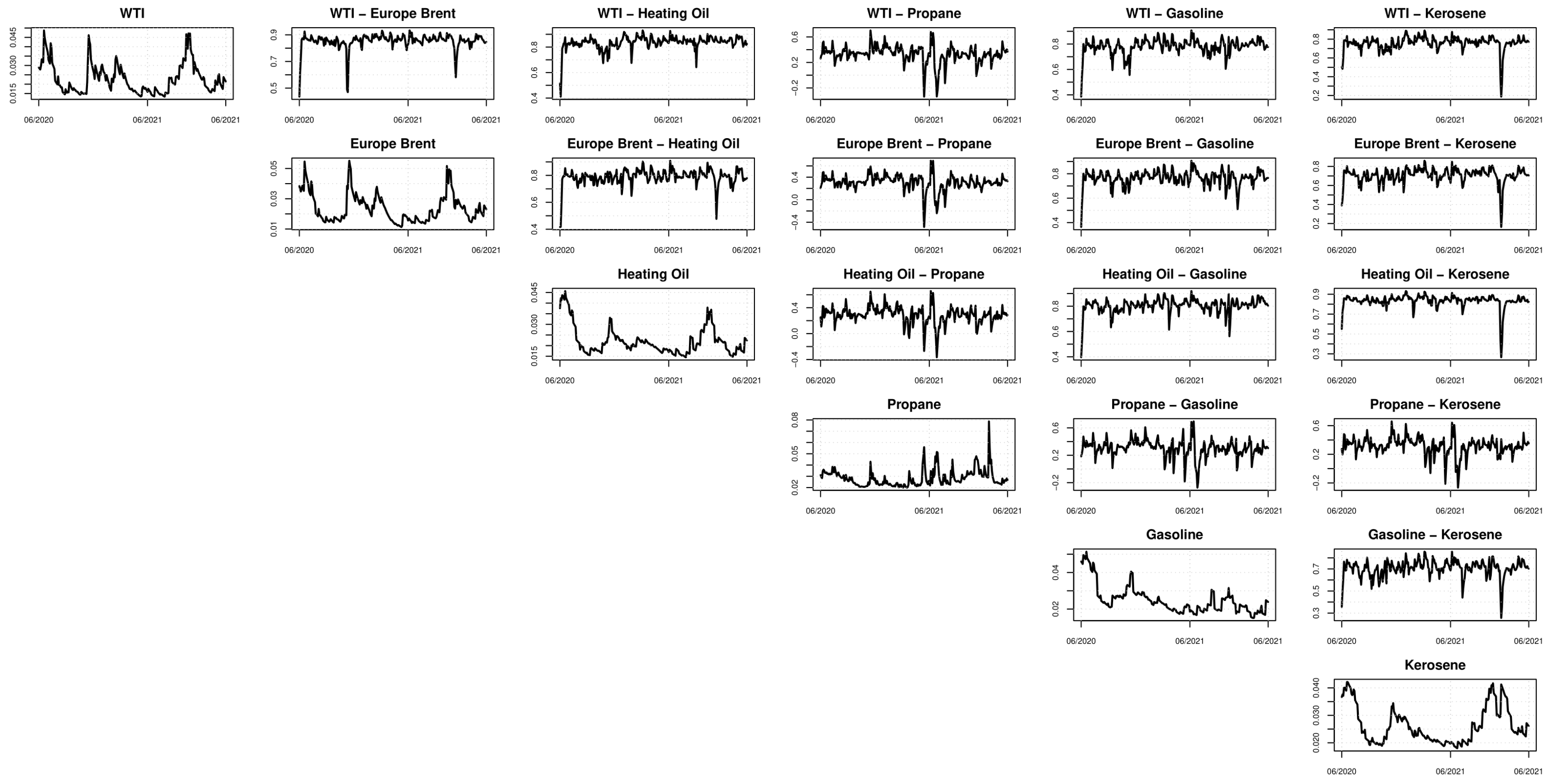
Table 2 and
Figure 1.
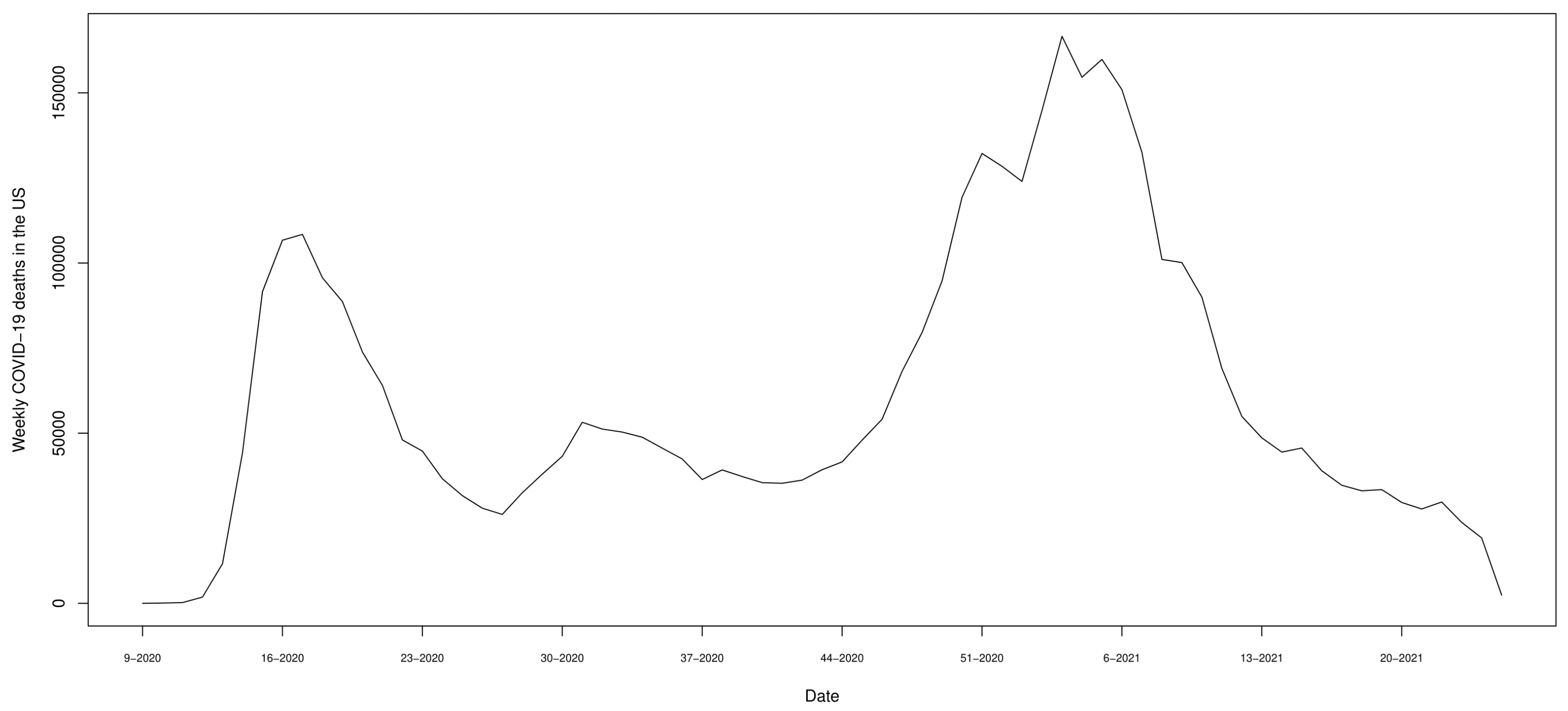
Lin and Su (
2021) points out that the connectedness of energy commodities experienced a peak during the pandemic outbreak. Along this line of research, our goal is to provide a quantitative measure of the impact of the COVID-19 weekly deaths on such commodities. We, therefore, consider the weekly number of deaths in the US related to COVID-19 infections from March 2020 to June 2021 (
Figure 2) as a low-frequency variable. In particular, this variable is used in Equations (
13) and (
14) by taking the first differences.
The empirical application is developed in two parts: the first concerns the detection of structural breaks to investigate the effects of the COVID-19 outbreak on energy commodities. To do so, we apply the Bai–Perron test (
Bai and Perron 1998) to detect both the presence and the number of structural breaks occurred at unknown dates during the period considered. The second part is related to the estimation and the comparison through the MCS procedure of twelve different DCC model specifications. We recall that in the analysis, we employed three specifications of the correlation model (DECO, cDCC, and DCC-GARCH-MIDAS) and four univariate specifications of the volatility model (GARCH, GJR, GM, and DAGM).
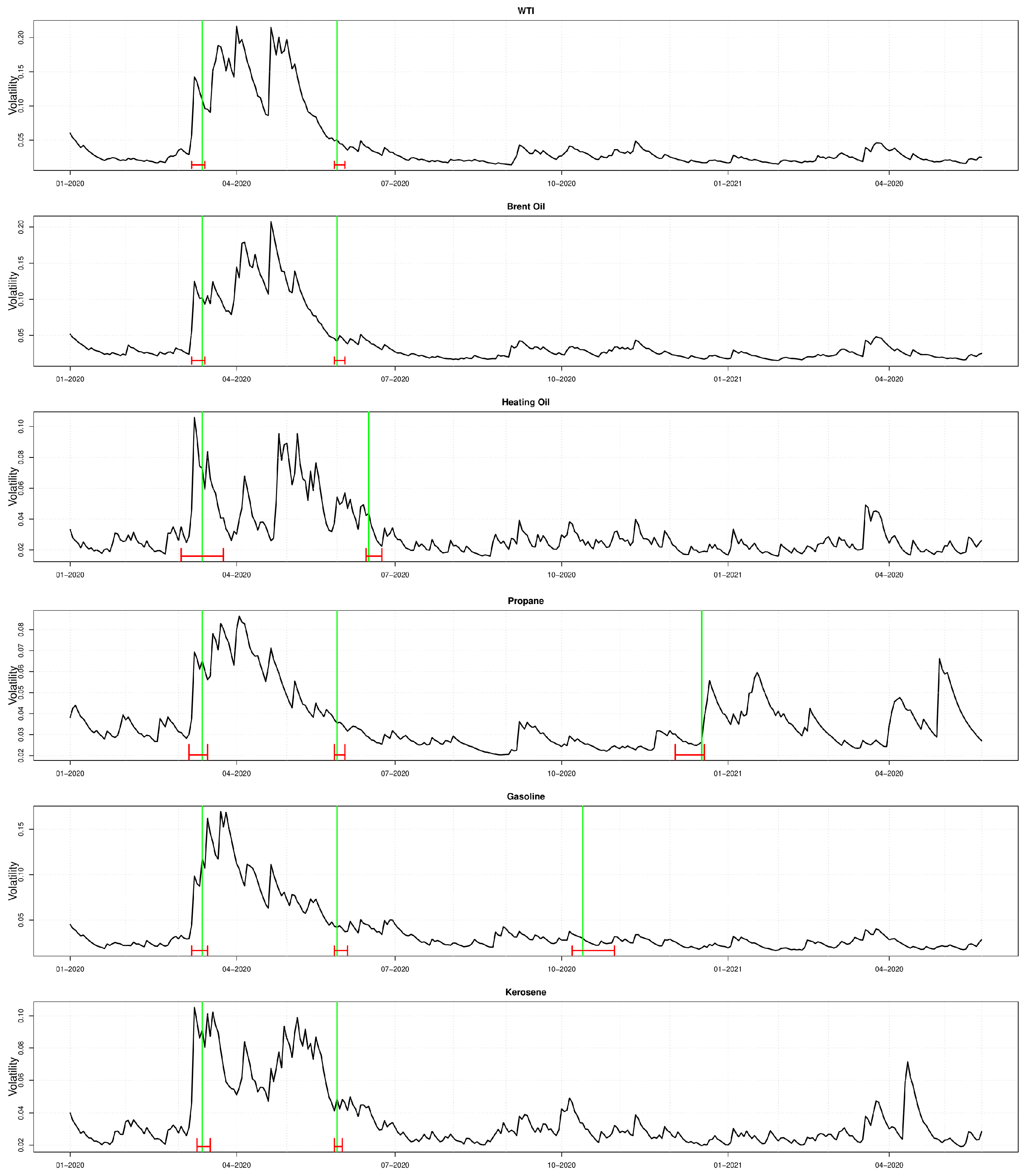
The presence of structural breaks coinciding with the beginning of the COVID-19 outbreak justifies the use of the low-frequency variable “COVID-19 deaths in the US” related to the effects of the pandemic in the univariate step of the DCC-GARCH estimation. The dates of the identified structural beaks are reported in
Table 3, and the plots showing the structural breaks are reported in
Figure 3. In these plots, the black lines are the volatilities estimated with a standard GARCH(1,1) model, the green lines indicate the structural breaks dates, and the red bars represent confidence intervals at 95% level for the dates considered. The plots show three main findings. First, every commodity experiences a strong rise in the volatility level in the midst of the first wave of the pandemic, spanning from March to July 2020. The second finding confirms the presence of structural breaks in all six commodities for the period considered. Third, Propane and Gasoline experienced additional structural breaks at the end of 2020. In particular, for Propane, a structural break in December 2020 marks a period of rising volatility that might be explained by two main factors. Given the main use of this commodity for domestic applications and space heating, it is natural to expect a spike in volatility in winter caused by the potential mismatch between supply and a higher demand of this commodity. Moreover, as reported in
US Government Accountability Office (
2003), a higher volatility in Propane returns might be traced back also to the limited capacity of the distribution system and the resulting bottlenecks in delivering the commodity. This issue, already present in the Propane delivering system, might have been worsened by the restrictions imposed during the second wave, which caused a spike in the demand of this commodity and a simultaneous negative impact on the delivery system. Gasoline instead experienced a structural break in October 2020, marking a period of low volatility that, differently from the other commodities, is maintained for the rest of the sample period. Moreover, the period of structural breaks common to all the six commodities coincides with a growth in deaths due to COVID-19 infections, as shown in
Figure 2, confirming that this variable represents a good proxy for the COVID-19 pandemic trend.
The second part of the empirical application concerns the DCC models estimation and evaluation. In order to estimate the DCC model, the univariate models (GARCH, GJR, GM, and DAGM) are estimated. The estimated coefficients are reported in
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9.
For almost every commodity, the parameters related with the low-frequency variable are significant, meaning that the information conveyed by this variable improves the estimation of the commodities’ volatility. The correlation models (cDCC, DCC-MIDAS, DECO) are estimated using standardized residuals obtained from the univariate model’s estimation. The number of lagged realizations of COVID-19-related deaths in the US used in the long-run equation is
; thus, the correlations are estimated starting from June 2020. The estimated coefficients for the DCC models are reported in
Table 10.
In
Table 11, we report the results of the MCS model based on three robust loss function, namely RMSE, FROB, and EUCL, measuring the distance between the estimated correlation matrix and the proxy of the covariance matrix, computed as the cross-products of
. The models belonging to the SSM are highlighted in gray.
Except for the standard GARCH model entering in the SSM with the FROB loss function, the only models entering in the SSM are represented by the ones using the DAGM as the univariate model. Thus, the inclusion of the weekly low-frequency variable in the univariate model through a mixed-frequency approach improves the conditional covariance’s predictions.
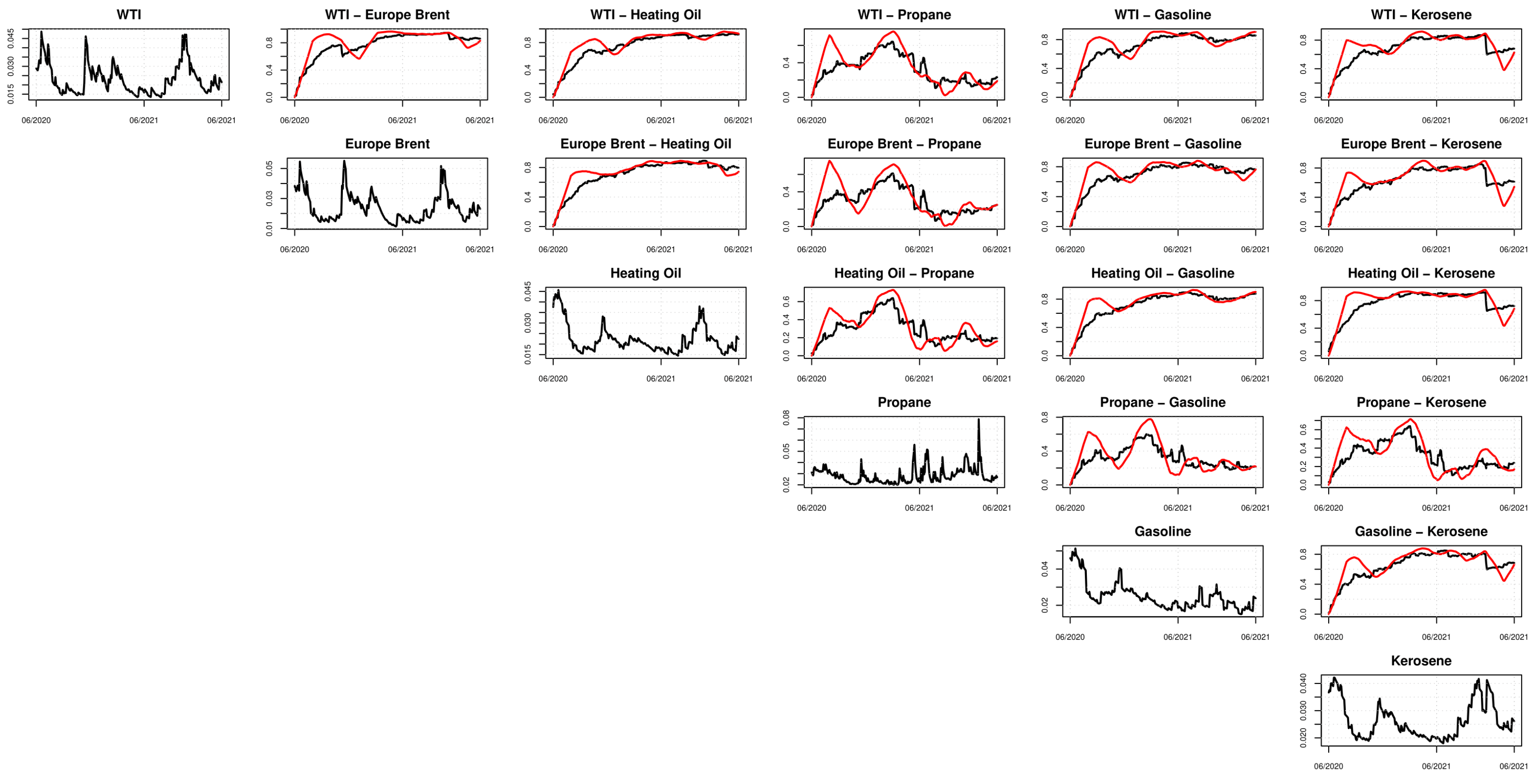
Along with the results of the DCC models estimations, we also present a graphical representation of the correlations estimated with the models entering in the SSM. Plots in
Figure 4,
Figure 5 and
Figure 6 report the time-varying pattern of the estimated correlations. Most of the commodities appear to be highly correlated regardless of the model used. In particular, the DCC-MIDAS model shows that, in general, the correlations increase over time, except for the correlation between Propane and the other commodities. In this case, the correlation reaches its maximum of 0.6 around the end of 2020 and then decreases to 0.3 at the end of the sample period. For the rest of the commodities, as well as for the estimates from the cDDC model (both with the GARCH and DAGM univariate specifications), the correlation is around 0.8. Again, the only exception is found for the Propane, whose correlation with other commodities ranges between 0.4 and 0.5.
Our analysis can be particularly useful in a risk management setting. The estimation of the matrix
can be easily exploited to compute well-known risk measures. For example, models that possess good predictive ability of the (conditional) covariance matrix should also yield portfolios with lower variance with respect to less performing models (
Engle and Kelly 2012). The evaluation of the resulting portfolios opens the door to the economic evaluation of the models (as done, for instance, by
Amendola and Candila 2017). Moreover, the high correlation detected among the commodities provides useful information about their role in the portfolio diversification. Furthermore, multivariate GARCH models are widely studied to model the role of commodities for hedging financial risks (
Chang et al. 2011;
Chkili et al. 2014;
Ku et al. 2007;
Silvennoinen and Thorp 2013). Therefore, our methodology can be exploited as a valuable tool to mitigate commodity risks, especially during financial and economic recessions such as the 2008 crisis and the recent COVID-19 pandemic (
Hauser et al. 2020). In particular, the inclusion of the number of weekly deaths caused by COVID-19 used to estimate the correlations allows us to discover the fragility regarding energy markets implied by the increased spillovers effects among commodities. This allows us to connect an increased exposure to spillovers effects from the energy markets to the financial markets. With this respect, our proposed approach can make the risk diversification during the pandemic more effective.
4. Conclusions
The increasing use of energy commodities for speculation and risk diversification purposes has resulted in significant shifts in prices of these assets and requires reliable estimates of their daily volatility and correlations. In this paper, we employed the Dynamic Conditional Correlation (DCC) model with a mixed-frequency approach in the univariate specifications to assess the effects of the COVID-19 pandemic in determining the correlation among energy markets. As in
Candila (
2021b), the DCC model with the GARCH-MIDAS and Double Asymmetric GARCH-MIDAS (DAGM) models as univariate specifications has been applied to six energy commodities, including the low-frequency variable of “weekly deaths in the US related to COVID-19 infection”. This approach allowed us to consider the information deriving from the low-frequency variable in order to estimate daily volatilities eventually driven by the COVID-19 data. Correlations have been estimated relying on three well-known models, namely the corrected DCC (cDCC), DCC-MIDAS, and Dynamic EquiCorrelation (DECO).
Our contribution has been two-fold. On one hand, we extended the current literature on the effects of the COVID-19 pandemic on the energy sector considering six energy commodities (West Texas Intermediate crude oil, Brent crude oil, Heating oil #2, Propane, New York Harbor Conventional Gasoline Regular, and Kerosene-Type Jet Fuel), whereas previous studies mainly focused on oil and natural gas (
De Blasis and Petroni 2021;
Gil-Alana and Monge 2020;
Lin and Su 2021;
Narayan 2020;
Wang and Su 2021). On the other hand, we employed multivariate GARCH models in the energy sector (
Chang et al. 2011;
Chkili et al. 2014;
Ku et al. 2007;
Silvennoinen and Thorp 2013;
Yousfi et al. 2021) within a risk management setting that, for the first time in this strand of literature, considers time series sampled at mixed-frequency. This allowed us to include the number of weekly deaths caused by the COVID-19 in the US for the estimation of daily volatilities and correlations. Overall, we highlighted an increase in the correlations among the commodities studied during the COVID-19 pandemic providing evidence of the contribution of the COVID-19 to the level of systemic commodity risk.
The empirical results showed that correlation models based on the DAGM model deliver better results than those that do not account for the MIDAS component. Moreover, the DAGM specification also provided better correlations estimates with respect to the GARCH-MIDAS model, which does not account for the different effects of positive and negative values of the low-frequency variable on the volatility of the commodities.
In conclusion, the analysis showed that our approach is statistically valuable and superior to other models in estimating correlations among energy commodities. The results matter in a risk management framework, where they can be exploited by investors for portfolio diversification. The results are also relevant to accomplish the requirements of both the microeconomic and macroeconomic regulators. At the microeconomic level, our estimates of the conditional covariance matrix can be exploited for obtaining reliable estimates of well-known risk measures. Moreover, the correct estimation of correlation in energy markets and volatilities has implications in terms of policy targeting for importing and exporting nations as well as in the evaluation of investments through asset pricing techniques. Our analysis suggests to conjecture increasing spillovers effect from the energy markets to the financial markets. This investigation is left for further studies.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}