_Bryant.png)





Qualitative Research Methods for Large Language Models: Conducting Semi-Structured Interviews with ChatGPT and BARD on Computer Science Education

 ,
,
Abstract
:1. Introduction
- What differences can be observed between and within large language models regarding the results of human-like semi-structured interviews for (a) the used model, (b) the used language within the model?
- What are guidelines for (a) conducting such interviews with large language models and for (b) using qualitative content analysis on the large language models’ results?
2. Background
2.1. What Are LLMs?
2.2. Potential Problems in Conducting Qualitative Research
2.3. Existing Work on Qualitative Research Methods with AI and LLMs
2.4. Exemplary Topic: Computer Science Education
- How relevant is computer science for education?
- At what age should computer science be integrated in education?
- What computer science contents should be taught in schools?
- What methods should be used for computer science classes?
- What tools should be used for computer science classes?
- Should computer science be implemented as a separate subject or as an integrative part of other subjects?
3. Methodology
3.1. Research Design
3.2. Participants
3.3. Data Collection
3.4. Data Analysis
3.5. Results
3.5.1. Differences between the LLMs
3.5.2. Differences within the LLMs
4. Discussion
5. Limitations
6. Implications
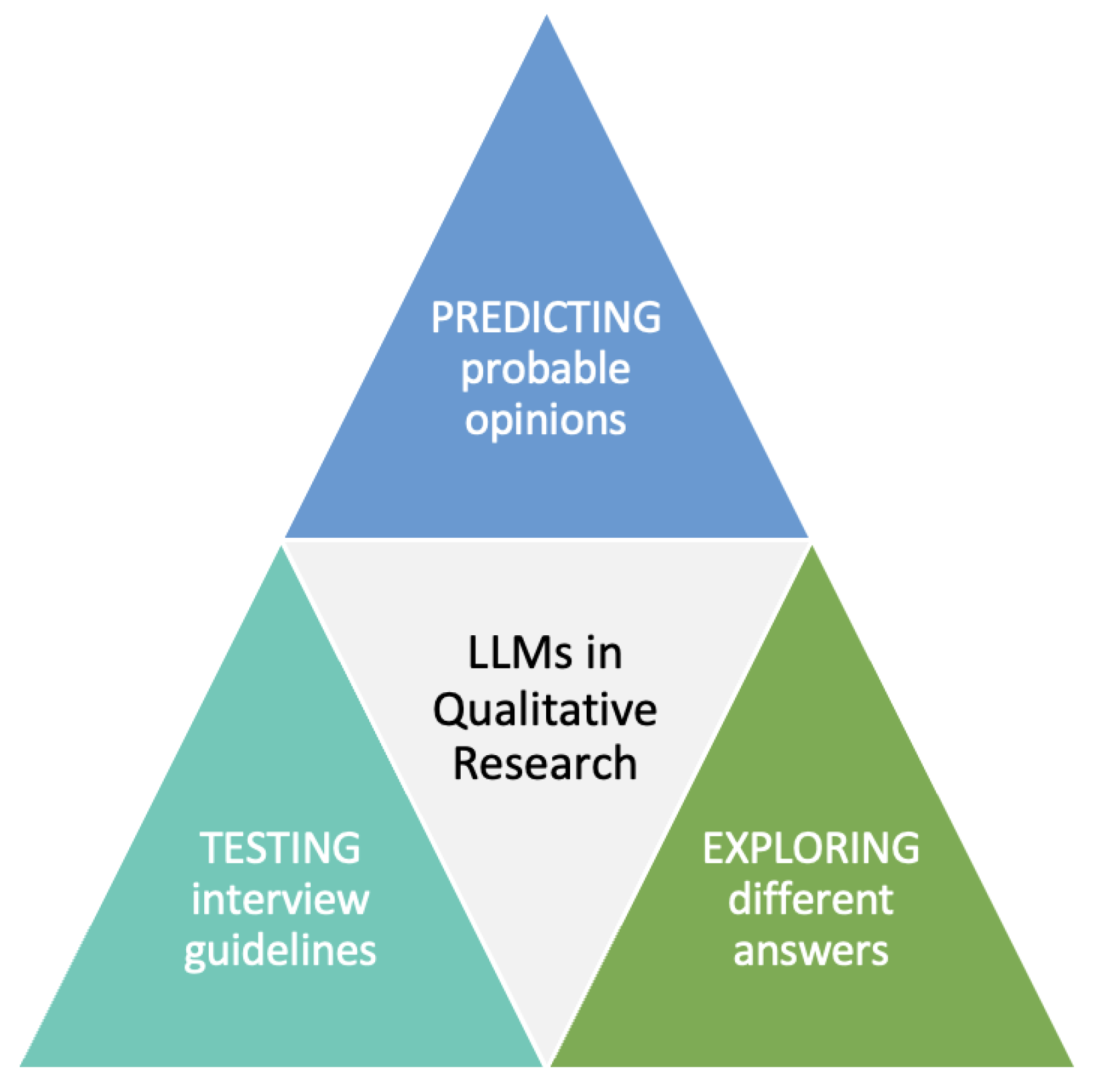
- Due to their unreliable and unpredictable outcomes, it is generally not recommended to employ LLMs for collecting qualitative data intended for academic purposes;
- LLMs can serve as an initial means of obtaining exploratory insights and possible opinions regarding a specific topic;
- If the objective is to provide validity and coherence in the results, at least up to a certain point, it is advisable to conduct multiple iterations of the same interview and to set a low temperature, in order to generate more coherent answers. To avoid ambiguous answers, at least up to a certain point, interviewers should preface each question with the phrase “In your opinion…”;
- LLMs can be effectively employed to evaluate interview guidelines in terms of their clarity and comprehensibility;
- If the objective is to either test interview guidelines or to discover multiple potential opinions, a moderate temperature should be used (here, also different identities could be assigned);
- In cases where the LLM is intended to adopt a specific role, it is important to explicitly state, “Please take on the role of…”. Here, caution must be exercised to prevent the perpetuation of stereotypes.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- Welcome the LLM to the interview, clarify the interview situation and introduce the general topic of Computer Science Education.
- Ask about the LLM’s relation to computer science. Ask how the LLM learned computer science.
- How relevant do you consider computer science as a school subject?
- From what age do you think computer science should be taught?
- In your opinion, what contents should be covered in a school subject of computer science?
- Which methods and tools do you think are useful for this content?
- In your opinion, should this content be taught as a separate subject or integrated into other school subjects?
- Conclude the interview, thank the LLM and farewell.
Appendix B

{kind=link}
{kind=link}
| ChatGPT English | ChatGPT German | BARD | ||||
|---|---|---|---|---|---|---|
| Interview | 1 | 2 | 1 | 2 | 1 | 2 |
| Relevance | Very high | Very high | Very high | Very high | Very high | Very high |
| Age | 4–7 | 11–12 | 10–12 | 6–10 | 5 | 5 |
| Contents | Computation-al Thinking, Web Development, AI and ML, Security and Ethics, Programming Concepts, Data structures and Algorithms, Software, Databases, Networks | Computation-al Thinking, Web Development, AI and ML, Security and Ethics, Hard- and Software, Programming, Algorithms, Data and Information, Cyber-Security, AR, VR, IoT, OS, Robotics, Problem solving | Programming Skills, Network Security, Information Management, AI and Robotics, Fundamentals of Computer Science | Networks, Data Security, Databases, Web Technologies, Fundamentals of Computer Science, Creative and Critical Thinking Skills, Media Literacy, Ethical and Social Issues | Basics of Computer Science, Data Structures, Software, Programming, Project Work, Website-, Game- and App Development, Hardware, AI and ML | Variables, Data Structures, Functions, Arrays, OOP, Algorithms, Loops, Branching, Ethical and Social Implications, Problem solving Strategies, Algorithmic Thinking |
| Methods | Gamification, PBL, Collaborative Learning, Peer Learning, Direct Instruction, Experimental Learning, Flipped Classroom | Gamification, PBL, Collaborative Learning | Independent Work, Project Work, Cooperative Learning Methods | Cooperative Learning Methods, Field Trips, Simulations and Visualizations | Problem Based Learning, Online Courses, Lectures, Project Based Learning, Programming Games and Apps | Problem Based Learning, Online Courses, Lectures, Hands-on-activities, Projects |
| Tools | Scratch, Blockly, Thunkable, Pygame, Online Tools, RasPi, MicroBit, Robotics, Visual Programming Languages, HTML, CSS, Javascript, Python, Java, GitHub, repl.it, Google Colab, Khan Academy, Code.org | Scratch, Blockly, Thunkable, Pygame, Online Tools, RasPi, MicroBit | Online Learning Platforms, Scratch, Python, Java, Visualizations and Simulations, Educational Games, Field Trips | Online Learning Platforms, Scratch, Python, Java, Visualizations and Simulations, Robots and Microcontrollers, Maker Spaces | Scratch, Python, Java, C++, Unity, VR/AR, Coding Games and Apps, Programming Environments, Hardware | Scratch, Python, Java, C++, Unity, VR/AR, Coding Games and Apps, Programming Environments, Online resources, Programming languages, Software development tools |
| Subject | No clear statement | No clear statement | No clear statement | No clear statement | Own Subject | Integrated in other Subjects |
References
- OpenAI. GPT-4 Technical Report. 2023. Available online: http://xxx.lanl.gov/abs/2303.08774 (accessed on 18 July 2023).
- Google. Bard Experiment. 2023. Available online: https://bard.google.com (accessed on 18 July 2023).
- Shen, Y.; Heacock, L.; Elias, J.; Hentel, K.D.; Reig, B.; Shih, G.; Moy, L. ChatGPT and other large language models are double-edged swords. Radiology 2023, 307, e230163. [Google Scholar] [CrossRef] [PubMed]
- Rillig, M.C.; Ågerstrand, M.; Bi, M.; Gould, K.A.; Sauerland, U. Risks and benefits of large language models for the environment. Environ. Sci. Technol. 2023, 57, 3464–3466. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 18 July 2023).
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 19–27. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Sobieszek, A.; Price, T. Playing games with AIs: The limits of GPT-3 and similar large language models. Minds Mach. 2022, 32, 341–364. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Oppong, S.H. The problem of sampling in qualitative research. Asian J. Manag. Sci. Educ. 2013, 2, 202–210. [Google Scholar]
- Mruck, K.; Breuer, F. Subjectivity and reflexivity in qualitative research—A new FQS issue. Hist. Soc. Res./Hist. Sozialforschung 2003, 28, 189–212. [Google Scholar]
- Chenail, R.J. Interviewing the investigator: Strategies for addressing instrumentation and researcher bias concerns in qualitative research. Qual. Rep. 2011, 16, 255–262. [Google Scholar]
- Higginbottom, G.M.A. Sampling issues in qualitative research. Nurse Res. 2004, 12, 7. [Google Scholar] [CrossRef] [PubMed]
- Whittemore, R.; Chase, S.K.; Mandle, C.L. Validity in qualitative research. Qual. Health Res. 2001, 11, 522–537. [Google Scholar] [CrossRef] [PubMed]
- Thomson, S.B. Qualitative research: Validity. Joaag 2011, 6, 77–82. [Google Scholar]
- Mayring, P. Qualitative content analysis. Companion Qual. Res. 2004, 1, 159–176. [Google Scholar]
- Surmiak, A.D. Confidentiality in Qualitative Research Involving Vulnerable Participants: Researchers’ Perspectives; Forum Qualitative Sozialforschung/Forum: Qualitative Social Research (FQS): Berlin, Germany, 2018; Volume 19. [Google Scholar]
- Laï, M.C.; Brian, M.; Mamzer, M.F. Perceptions of artificial intelligence in healthcare: Findings from a qualitative survey study among actors in France. J. Transl. Med. 2020, 18, 14. [Google Scholar] [CrossRef] [PubMed]
- Haan, M.; Ongena, Y.P.; Hommes, S.; Kwee, T.C.; Yakar, D. A qualitative study to understand patient perspective on the use of artificial intelligence in radiology. J. Am. Coll. Radiol. 2019, 16, 1416–1419. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Siau, K.L. A Qualitative Research on Marketing and Sales in the Artificial Intelligence Age. Available online: https://www.researchgate.net/profile/Keng-Siau-2/publication/325934359_A_Qualitative_Research_on_Marketing_and_Sales_in_the_Artificial_Intelligence_Age/links/5b9733644585153a532634e3/A-Qualitative-Research-on-Marketing-and-Sales-in-the-Artificial-Intelligence-Age.pdf (accessed on 18 July 2023).
- Longo, L. Empowering qualitative research methods in education with artificial intelligence. In World Conference on Qualitative Research; Springer: Cham, Switzerland, 2019; pp. 1–21. [Google Scholar]
- Christou, P. How to Use Artificial Intelligence (AI) as a Resource, Methodological and Analysis Tool in Qualitative Research? Qual. Rep. 2023, 28, 1968–1980. [Google Scholar]
- Christou, P.A. How to use thematic analysis in qualitative research. J. Qual. Res. Tour. 2023, 1, 79–95. [Google Scholar] [CrossRef]
- Guest, G.; MacQueen, K.M.; Namey, E.E. Applied Thematic Analysis; Sage Publications: Thousand Oaks, CA, USA, 2011. [Google Scholar]
- Olasik, M. “Good morning, ChatGPT, Can We Become Friends?” An Interdisciplinary Scholar’s Experience of ‘Getting Acquainted’ with the OpenAI’s Chat GPT: An Auto Ethnographical Report. Eur. Res. Stud. J. 2023, 26, 269–284. [Google Scholar]
- Martin, J.L. The Ethico-Political Universe of ChatGPT. J. Soc. Comput. 2023, 4, 1–11. [Google Scholar] [CrossRef]
- Schwarz, R.; Hellmig, L.; Friedrich, S. Informatikunterricht in Deutschland–eine übersicht. Inform. Spektrum 2021, 44, 95–103. [Google Scholar] [CrossRef]
- Brinda, T.; Fothe, M.; Friedrich, S.; Koerber, B.; Puhlmann, H.; Röhner, G.; Schulte, C. Grundsätze und Standards für die Informatik in der Schule. Bildungsstandards Informatik für die Sekundarstufe I. Beilage zu LOG IN 2008, 150, 28. [Google Scholar]
- Röhner, G.; Brinda, T.; Denke, V.; Hellmig, L.; Heußer, T.; Pasternak, A.; Schwill, A.; Seiffert, M. Bildungsstandards Informatik für die Sekundarstufe II. Beilage zu LOG IN 2016, 183, 88. [Google Scholar]
- Pasternak, A.; Hellmig, L.; Röhner, G. Standards for Higher Secondary Education for Computer Science in Germany. In Proceedings of the Informatics in Schools. Fundamentals of Computer Science and Software Engineering: 11th International Conference on Informatics in Schools: Situation, Evolution, and Perspectives, ISSEP 2018, St. Petersburg, Russia, 10–12 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 117–128. [Google Scholar]
- Best, A.; Borowski, C.; Büttner, K.; Freudenberg, R.; Fricke, M.; Haselmeier, K.; Herper, H.; Hinz, V.; Humbert, L.; Müller, D.; et al. Kompetenzen für Informatische Bildung im Primarbereich, 2019. Available online: https://dl.gi.de/bitstream/handle/20.500.12116/20121/61-GI-Empfehlung_Kompetenzen_informatische_Bildung_Primarbereich.pdf?sequence=1 (accessed on 18 July 2023).
- Ministerium für Bildung, W.u.K. Rahmenplan für die Sekundarstufe I Regionale Schule, Gesamtschule. Available online: https://www.bildung-mv.de/export/sites/bildungsserver/downloads/unterricht/rahmenplaene_allgemeinbildende_schulen/Informatik/RP_INFO_AHR_5-10.pdf (accessed on 18 July 2023).
- Lehrplan 21. Available online: https://zh.lehrplan.ch/index.php?code=b%7C10%7C0&la=yes (accessed on 18 July 2023).
- für Volksschulen, A.; des Kantons Schwyz, S. Konzept zur Einführung des Modullehrplans «Medien und Informatik» des Lehrplans 21 in der Volksschule. 2016. Available online: https://www.sz.ch/public/upload/assets/27770/AVS_2016_Konzept-zur-Einfuehrung-Medien-und-Informatik_SZ.pdf (accessed on 18 July 2023).
- Berry, M. Computing in the National Curriculum: A Guide for Primary Teachers. 2013. Available online: https://pure.roehampton.ac.uk/ws/files/5138334/CASPrimaryComputing.pdf (accessed on 18 July 2023).
- Technologies: Experiences and Outcomes-Education Scotland. Available online: https://education.gov.scot/media/nqgj0egw/technologies-es-os.pdf (accessed on 18 July 2023).
- The Northern Ireland Assembly. Available online: http://www.niassembly.gov.uk/globalassets/documents/raise/publications/2014/education/3814.pdf (accessed on 18 July 2023).
- National Curriculum in England: Computing Programmes of Study—gov.uk. Available online: https://www.gov.uk/government/publications/national-curriculum-in-england-computing-programmes-of-study (accessed on 13 July 2023).
- Scottish, G. Curriculum for Excellence. 2016. Available online: https://education.gov.scot/media/wpsnskgv/all-experiencesoutcomes18.pdf (accessed on 18 July 2023).
- Kemp, P. After the Reboot: Computing Education in UK Schools; Royal Society: London, UK, 2017. [Google Scholar]
- Digital Technologies—australiancurriculum.edu.au. Available online: https://www.australiancurriculum.edu.au/f-10-curriculum/technologies/digital-technologies/ (accessed on 28 June 2023).
- Information and Communication Technology (ICT) Capability—australiancurriculum.edu.au. Available online: https://www.australiancurriculum.edu.au/f-10-curriculum/general-capabilities/information-and-communication-technology-ict-capability/ (accessed on 28 June 2023).
- General Capabilities—australiancurriculum.edu.au. Available online: https://www.australiancurriculum.edu.au/f-10-curriculum/general-capabilities/ (accessed on 28 June 2023).
- Hub, D.T. State and Territory Curriculum—digitaltechnologieshub.edu.au. Available online: https://www.digitaltechnologieshub.edu.au/understanding-dt/the-dt-curriculum/state-and-territory-curriculum/ (accessed on 28 June 2023).
- Gal-Ezer, J.; Stephenson, C. A tale of two countries: Successes and challenges in K-12 computer science education in Israel and the United States. ACM Trans. Comput. Educ. (TOCE) 2014, 14, 1–18. [Google Scholar] [CrossRef]
- Nager, A.; Atkinson, R.D. The Case for Improving US Computer Science Education. 2016. Available online: https://ssrn.com/abstract=3066335 (accessed on 18 July 2023).
- CSTA. CSTA K-12 Computer Science Standards, Revised 2017. 2017. Available online: https://www.doe.k12.de.us/cms/lib/DE01922744/Centricity/Domain/176/CSTA%20Computer%20Science%20Standards%20Revised%202017.pdf (accessed on 18 June 2023).
- Code.org, CSTA and ECEP Alliance 2022 State of Computer Science Education: Understanding Our National Imperative. 2022. Available online: https://advocacy.code.org/2022_state_of_cs.pdf (accessed on 18 June 2023).
- Tshukudu, E.; Sentance, S.; Adelakun-Adeyemo, O.; Nyaringita, B.; Quille, K.; Zhong, Z. Investigating K-12 Computing Education in Four African Countries (Botswana, Kenya, Nigeria, and Uganda). ACM Trans. Comput. Educ. 2023, 23, 1–29. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dengel, A.; Gehrlein, R.; Fernes, D.; Görlich, S.; Maurer, J.; Pham, H.H.; Großmann, G.; Eisermann, N.D.g. Qualitative Research Methods for Large Language Models: Conducting Semi-Structured Interviews with ChatGPT and BARD on Computer Science Education. Informatics 2023, 10, 78. https://doi.org/10.3390/informatics10040078
Dengel A, Gehrlein R, Fernes D, Görlich S, Maurer J, Pham HH, Großmann G, Eisermann NDg. Qualitative Research Methods for Large Language Models: Conducting Semi-Structured Interviews with ChatGPT and BARD on Computer Science Education. Informatics. 2023; 10(4):78. https://doi.org/10.3390/informatics10040078
Chicago/Turabian StyleDengel, Andreas, Rupert Gehrlein, David Fernes, Sebastian Görlich, Jonas Maurer, Hai Hoang Pham, Gabriel Großmann, and Niklas Dietrich genannt Eisermann. 2023. "Qualitative Research Methods for Large Language Models: Conducting Semi-Structured Interviews with ChatGPT and BARD on Computer Science Education" Informatics 10, no. 4: 78. https://doi.org/10.3390/informatics10040078
APA StyleDengel, A., Gehrlein, R., Fernes, D., Görlich, S., Maurer, J., Pham, H. H., Großmann, G., & Eisermann, N. D. g. (2023). Qualitative Research Methods for Large Language Models: Conducting Semi-Structured Interviews with ChatGPT and BARD on Computer Science Education. Informatics, 10(4), 78. https://doi.org/10.3390/informatics10040078