A Comprehensive Study of Activity Recognition Using Accelerometers

 , ,
, ,  ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Summary of Research Directions and Open Questions
- What activities are we interested in? (Section 2.1)
- Are structured models (that model the sequential nature of the data) required for classification? (Section 2.2)
- What are the relevant features in the accelerometer data that are useful for prediction? (Section 2.3)
- How is the time series segmented? (Section 2.4)
- What are the optimal locations of accelerometers for the recognition of various activities? (Section 2.5)
- What are the trade-offs when selecting and configuring the accelerometers (e.g., sampling rate)? (Section 2.6)
- How robust are the predictions within an individual, and across individuals and sensor placements? (Section 2.7)
2.1. Activities
2.2. Structured vs. Unstructured Models
2.3. Survey of Feature Extraction Pipelines
2.4. Segmentation of Accelerometer Data Streams
2.5. Location of Sensors on the Body
2.6. Accelerometer Selection and Configuration
2.7. Methods to Estimate Generalisation Performance
- A single subject over different days, mixed together and cross-validated.
- Multiple subjects over different days, mixed together and cross-validated.
- A single subject on one day used as training data, and data collected for the same subject on another day used as testing data.
- One subject for one day used as training data, and data collected on another subject on another day used as testing data.
2.8. Publically Available Data-Sets
3. Materials and Methods
3.1. Data-Sets Used in This Work
- har
- This was collected by attaching a smart-phone (with accelerometer and gyroscope) in a waist-mounted holder, with 30 participants conducting 6 activities in a controlled laboratory environment. Six activities were annotated in this dataset: walking, walking up stairs, walking down stairs, sitting, standing and lying down. The acceleration was sampled at 50 Hz on triaxial accelerometers and gyroscopes. Since gyroscopes can consume several orders of magnitude more power than accelerometers (c.f. Section 1), we only assess the accelerometer data in our treatment of this work. More details can be found in [4].
- uschad
- This was recorded by 14 subjects (7 male, 7 female) performing 12 activities (walking forward, walking left, walking right, walking upstairs, walking downstairs, running forward, jumping, sitting, standing, sleeping, elevator up, elevator down) in a controlled laboratory environment (with accelerometers and gyroscopes), with ground truth annotation performed by an observer standing nearby. The accelerometer, gyroscope and magnetometer data were sampled at 100 Hz, and data from the Microsoft Kinect accompanies this dataset. In our analysis we do not consider the Microsoft Kinect, magnetometer or gyroscope data, and use only the accelerometer data. More details can be found in [62].
- pamap2
- This contains data of 18 different physical activities (lying, sitting, standing, walking, running, cycling, Nordic walking, watching TV, computer work, car driving, ascending stairs, descending stairs, vacuum cleaning, ironing, folding laundry, house cleaning, playing soccer, rope jumping) performed by 9 subjects wearing 3 inertial measurement units (over the wrist on the dominant arm, on the chest, and on the dominant side’s ankle) and a heart rate monitor. Data were sampled at 100 Hz in this work and we use only the accelerometer data, although magnetometer and gyroscope data are also available. More details can be found in [63].
3.2. Calibration of Raw Accelerometer Data
3.3. Features Used in This Study
3.3.1. Hand-Crafted Features
3.3.2. Sparse Coding and Dictionary Learning
3.3.3. Fixed Dictionaries
3.3.4. Convolutional Sparse Coding
3.3.5. Classification Using Sparse Codes
3.4. Classification Models Used in This Work
3.4.1. Mathematical Notation
3.4.2. Random Forest
3.4.3. Logistic Regression
3.4.4. Multi-Layer Perceptron
3.5. Convolutional Neural Networks
3.6. Recurrent Neural Networks
3.6.1. Conditional Random Fields (CRFs)
3.7. Empirical Experiments in this Work
3.7.1. Sensor Configuration Analysis
3.7.2. Experimentation with iid Classifiers
- RF:
- Ensemble size: ; Max depth of tree: .
- LR:
- L2 regulariser:
- MLP:
- L2 regulariser: Empirically we found values outside of this range performed very poorly, so we concentrated our search space over a smaller interval than with LR.
3.7.3. Experimentation with Sequential Classifiers
3.7.4. Experimentation with Neural Network Models
- Dropout rate:
- Training epochs:
- Convolutional layer with 64 units, a kernel size of 9 (i.e., 0.3 s), and dropout (selected in cross validation)
- Convolutional layer with 32 units, a kernel size of 9, and dropout (selected in cross validation)
- Flattening layer
- Fully connected with 16 units; ReLU activations and dropout
- Output layer with softmax
- LSTM layer with 64 units and dropout (selected in cross validation)
- LSTM layer with 32 units and dropout (selected in cross validation)
- Flattening layer
- Fully connected with 16 units; ReLU activations and dropout
- Output layer with softmax
4. Results and Discussion
4.1. Validation of Calibration
4.2. Analysis of Sensor Configurations
4.3. LR Performance on HAR
4.4. LR-CRF Performance on HAR
4.5. Overall Impact of CRFs on Predictive Performance
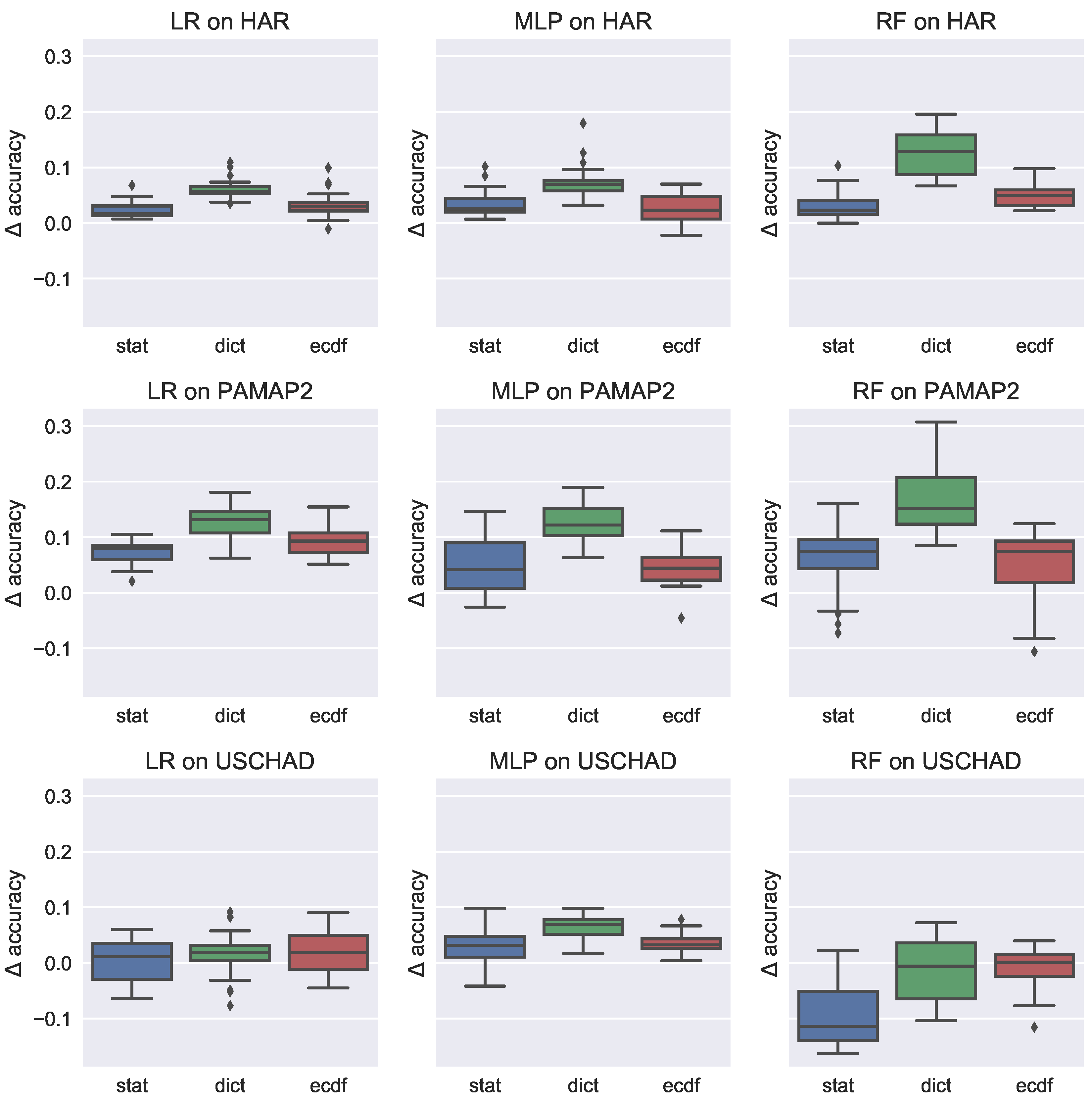
4.6. Comparison between Datasets and Classifiers
4.7. Analysis of CNN and LSTM Models
4.8. Analysis of Misclassification Errors
5. Conclusions
- Context can be delivered to classification models by increasing the sampling rate, selecting wide feature windows for feature extraction, modelling the temporal dependence between features.
- Classification performance tends to improve when these configurations are independently ‘increased’ (i.e., more context introduced).
- There tends to be a performance plateau for any given dataset (i.e., maximal performance) and our results indicate this can be achieved on several device, feature and classifier configurations.
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A



References
- Biddle, S.; Biddle, S.J.H.; Pearson, N.; Ross, G.M.; Braithwaite, R. Tracking of sedentary behaviours of young people: A systematic review. Prev. Med. 2010, 51, 345–351. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwapisz, J.; Weiss, G.; Moore, S. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Siirtola, P.; Röning, J. Recognizing Human Activities User-Independently on Smartphones Based on Accelerometer Data. Int. J. Int. Multimed. Artif. Intell. 2012, 1, 38–45. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Brezmes, T.; Gorricho, J.L.; Cotrina, J. Activity recognition from accelerometer data on a mobile phone. In Distributed Computing, Artificial Intelligence, Bioinformatics, Soft Computing, and Ambient Assisted Living; Springer: Heidelberg/Berlin, Germany, 2009; pp. 796–799. [Google Scholar]
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the 8th IEEE Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 567–572. [Google Scholar]
- Krishnan, N.; Cook, D. Activity recognition on streaming sensor data. Perv. Mob. Comput. 2014, 10, 138–154. [Google Scholar] [CrossRef] [PubMed]
- Diethe, T.; Twomey, N.; Kull, M.; Flach, P.; Craddock, I. Probabilistic sensor fusion for ambient assisted living. arXiv 2017, arXiv:1702.01209. [Google Scholar]
- Bergmann, J.; McGregor, A. Body-worn sensor design: What do patients and clinicians want? Ann. Biomed. Eng. 2011, 39, 2299–2312. [Google Scholar] [CrossRef] [PubMed]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Diethe, T.R. Sparse Machine Learning Methods With Applications in Multivariate Signal Processing. Ph.D. Thesis, UCL Advances, University College London, London, UK, 2010. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Support Vector Machines; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Quinlan, J. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Williams, C.; Barber, D. Bayesian classification with Gaussian processes. Patt. Anal. Mach. Intell. 1998, 20, 1342–1351. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S. Activity Recognition From User-Annotated Acceleration Data. In Pervasive Computing; Springer: Heidelberg/Berlin, Germany, 2004; pp. 1–17. [Google Scholar]
- Zhu, N.; Diethe, T.; Camplani, M.; Tao, L.; Burrows, A.; Twomey, N.; Kaleshi, D.; Mirmehdi, M.; Flach, P.; Craddock, I. Bridging e-Health and the Internet of Things: The SPHERE Project. Intelli. Syst. IEEE 2015, 30, 39–46. [Google Scholar] [CrossRef]
- Woznowski, P.; Burrows, A.; Diethe, T.; Fafoutis, X.; Hall, J.; Hannuna, S.; Camplani, M.; Twomey, N.; Kozlowski, M.; Tan, B.; et al. SPHERE: A sensor platform for healthcare in a residential environment. In Designing, Developing, and Facilitating Smart Cities; Springer: Heidelberg/Berlin, Germany, 2017; pp. 315–333. [Google Scholar]
- Woznowski, P.; Fafoutis, X.; Song, T.; Hannuna, S.; Camplani, M.; Tao, L.; Paiement, A.; Mellios, E.; Haghighi, M.; Zhu, N.; et al. A Multi-modal Sensor Infrastructure for Healthcare in a Residential Environment. In Proceedings of the 2015 IEEE International Conference on Communication Workshop, London, UK, 8–12 June 2015. [Google Scholar]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity Recognition from Accelerometer Data. In Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligence, Pittsburgh, PA, USA, 9–13 July 2005; Volume 3, pp. 1541–1546. [Google Scholar]
- Karantonis, D.M.; Narayanan, M.R.; Mathie, M.; Lovell, N.H.; Celler, B.G. Implementation of a real-time human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 156–167. [Google Scholar] [CrossRef] [PubMed]
- Twomey, N.; Diethe, T.; Flach, P. On the need for structure modelling in sequence prediction. Mach. Learn. 2016, 104, 291–314. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B.H. An introduction to hidden Markov models. ASSP Mag. IEEE 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Nazerfard, E.; Das, B.; Holder, L.B.; Cook, D.J. Conditional random fields for activity recognition in smart environments. In Proceedings of the 1st ACM International Health Informatics Symposium, Arlington, VA, USA, 11–12 November 2010; pp. 282–286. [Google Scholar]
- Lee, S.; Le, H.X.; Ngo, H.Q.; Kim, H.I.; Han, M.; Lee, Y.K. Semi-Markov conditional random fields for accelerometer-based activity recognition. Appl. Intell. 2011, 35, 226–241. [Google Scholar]
- Janidarmian, M.; Roshan Fekr, A.; Radecka, K.; Zilic, Z. A comprehensive analysis on wearable acceleration sensors in human activity recognition. Sensors 2017, 17, 529. [Google Scholar] [CrossRef] [PubMed]
- San-Segundo, R.; Montero, J.M.; Barra-Chicote, R.; Fernández, F.; Pardo, J.M. Feature extraction from smartphone inertial signals for human activity segmentation. Signal Process. 2016, 120, 359–372. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Gupta, P.; Dallas, T. Feature selection and activity recognition system using a single triaxial accelerometer. IEEE Trans. Biomed. Eng. 2014, 61, 1780–1786. [Google Scholar] [CrossRef] [PubMed]
- Hammerla, N.; Kirkham, R.; Andras, P.; Ploetz, T. On Preserving Statistical Characteristics of Accelerometry Data Using Their Empirical Cumulative Distribution. In Proceedings of the 2013 International Symposium on Wearable Computers, Zurich, Switzerland, 8–12 September 2013; pp. 65–68. [Google Scholar]
- Elsts, A.; McConville, R.; Fafoutis, X.; Twomey, N.; Piechocki, R.; Santos-Rodriguez, R.; Craddock, I. On-Board Feature Extraction from Acceleration Data for Activity Recognition. In Proceedings of the International Conference on Embedded Wireless Systems and Networks (EWSN), Madrid, Spain, 14–16 February 2018. [Google Scholar]
- Santos-Rodriguez, R.; Twomey, N. Efficient approximate representations of computationally expensive features. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 25–27 April 2018. [Google Scholar]
- Plötz, T.; Hammerla, N.; Olivier, P. Feature Learning for Activity Recognition in Ubiquitous Computing. In Proceedings of the 22nd Intenational Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain, 19–22 July 2011; pp. 1729–1734. [Google Scholar]
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep Activity Recognition Models with Triaxial Accelerometers. arXiv 2016, arXiv:1511.04664v2. [Google Scholar]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Nurmi, P.; Hammerla, N.; Plötz, T. Using unlabeled data in a sparse-coding framework for human activity recognition. Perv. Mob. Comput. 2014, 15, 242–262. [Google Scholar] [CrossRef]
- Nguyen, T.; Gupta, S.; Venkatesh, S.; Phung, S. A Bayesian Nonparametric Framework for Activity Recognition Using Accelerometer Data. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, 24–28 August 2014; pp. 2017–2022. [Google Scholar]
- Teh, Y.; Jordan, M.I.; Beal, M.J. Hierarchical Dirichlet Processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Siirtola, P.; Laurinen, P.; Haapalainen, E.; Roning, J. Clustering-based activity classification with a wrist-worn accelerometer using basic features. In Proceedings of the Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 95–100. [Google Scholar]
- Keogh, E.; Chu, S.; Hart, D.; Pazzani, M. Segmenting time series: A survey and novel approach. Data Min. Time Series Databases 2004, 57, 1–22. [Google Scholar]
- Fox, E.; Sudderth, E.B.; Jordan, M.I.; Willsky, A.S. An HDP-HMM for systems with state persistence. In Proceedings of the 25th Intenationna Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 312–319. [Google Scholar]
- Maurer, U.; Sudderth, E.B.; Jordan, M.I.; Willsky, A.S. Activity recognition and monitoring using multiple sensors on different body positions. In Proceedings of the International Workshop on Wearable and Implantable Body Sensor Networks (BSN), Cambridge, MA, USA, 3–5 April 2006; pp. 113–116. [Google Scholar]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–19 March 2016; pp. 1–9. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 381–388. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neur. Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Fafoutis, X.; Elsts, A.; Piechocki, R.; Craddock, I. Experiences and Lessons Learned from Making IoT Sensing Platforms for Large-Scale Deployments. IEEE Access 2018, 6, 3140–3148. [Google Scholar] [CrossRef]
- Fafoutis, X.; Vafeas, A.; Janko, B.; Sherratt, R.S.; Pope, J.; Elsts, A.; Mellios, E.; Hilton, G.; Oikonomou, G.; Piechocki, R.; et al. Designing Wearable Sensing Platforms for Healthcare in a Residential Environment. Trans. Perv. Health Technol. 2017, 17. [Google Scholar] [CrossRef]
- Fafoutis, X.; Marchegiani, L.; Elsts, A.; Pope, J.; Craddock, I. Extending the Battery Lifetime of Wearable Sensors with Embedded Machine Learning. In Proceedings of the 4th IEEE World Forum on Internet of Things (IEEE WF-IoT), Singapore, 5–8 February 2018; pp. 269–274. [Google Scholar]
- Khan, A.; Hammerla, N.; Mellor, S.; Plötz, T. Optimising sampling rates for accelerometer-based human activity recognition. Patt. Recognit. Lett. 2016, 73, 33–40. [Google Scholar] [CrossRef]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of posture and motion by accelerometry: A validation study in ambulatory monitoring. Comput. Hum. Behav. 1999, 15, 571–583. [Google Scholar] [CrossRef]
- Twomey, N.; Diethe, T.; Kull, M.; Song, H.; Camplani, M.; Hannuna, S.; Fafoutis, X.; Zhu, N.; Woznowski, P.; Flach, P.; et al. The SPHERE challenge: Activity recognition with multimodal sensor data. arXiv 2016, arXiv:1603.00797. [Google Scholar]
- Casale, P.; Pujol, O.; Radeva, P. Personalization and user verification in wearable systems using biometric walking patterns. Person. Ubiquit. Comput. 2012, 16, 563–580. [Google Scholar] [CrossRef]
- Borazio, M.; Van Laerhoven, K. Using time use with mobile sensor data: A road to practical mobile activity recognition? In Proceedings of the 12th International Conference on Mobile and Ubiquitous Multimedia, Lulea, Sweden, 2–5 December 2013; p. 20. [Google Scholar]
- Huynh, T.; Fritz, M.; Schiele, B. Discovery of activity patterns using topic models. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; pp. 10–19. [Google Scholar]
- Stikic, M.; Schiele, B. ADL recognition based on the combination of RFID and accelerometer sensing. In Proceedings of the 2nd International Conference on Pervasive Computing Technologies for Healthcare, Tampere, Finland, 30 Janury–1 February 2008; pp. 258–263. [Google Scholar] [CrossRef]
- Van Laerhoven, K.; Berlin, E.; Schiele, B. Enabling efficient time series analysis for wearable activity data. In Proceedings of the 2009 International Conference on Machine Learning and Applications, Miami Beach, FL, USA, 13–15 December 2009; pp. 392–397. [Google Scholar]
- Van Laerhoven, K.; Kilian, D.; Schiele, B. Using rhythm awareness in long-term activity recognition. In Proceedings of the 12th IEEE International Symposium on Wearable Computers, Pittsburgh, PA, USA, 28 September–1 October 2008; pp. 63–66. [Google Scholar]
- Borazio, M.; Berlin, E.; Kücükyildiz, N.; Scholl, P.; Laerhoven, K.V. Towards Benchmarked Sleep Detection with Wrist-Worn Sensing Units. In Proceedings of the 2014 IEEE International Conference on Healthcare Informatics, Verona, Italy, 15–17 September 2014; IEEE Computer Society: Washington, DC, USA; pp. 125–134. [Google Scholar]
- Borazio, M.; Van Laerhoven, K. Combining wearable and environmental sensing into an unobtrusive tool for long-term sleep studies. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; pp. 71–80. [Google Scholar]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Patt. Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A Daily Activity Dataset for Ubiquitous Activity Recognition Using Wearable Sensors. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; ACM: New York, NY, USA; pp. 1036–1043. [Google Scholar]
- Reiss, A.; Stricker, D. Creating and Benchmarking a New Dataset for Physical Activity Monitoring. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments, Heraklion, Greece, 6–8 June 2012; pp. 40:1–40:8. [Google Scholar]
- Twomey, N.; Faul, S.; Marnane, W. Comparison of accelerometer-based energy expenditure estimation algorithms. In Proceedings of the 4th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Munich, Germany, 22–25 March 2010; pp. 1–8. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Smith, L.I. A tutorial on principal components analysis. Cornell Univ. USA 2002, 51, 65. [Google Scholar]
- Balan, R.; Casazza, P.G.; Heil, C.; Landau, Z. Density, overcompleteness, and localization of frames. I. Theory. J. Fourier Anal. Appl. 2006, 12, 105–143. [Google Scholar] [CrossRef]
- Bach, F.; Jenatton, R.; Mairal, J.; Obozinski, G. Optimization with sparsity-inducing penalties. Found. Trends Mach. Learn. 2012, 4, 1–106. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.1. Available online: http://cvxr.com/cvx (accessed on 29 May 2018).
- Diethe, T.; Twomey, N.; Flach, P. BDL. NET: Bayesian dictionary learning in Infer. NET. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Salerno, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Haar, A. Zur theorie der orthogonalen funktionensysteme. Math. Ann. 1910, 69, 331–371. [Google Scholar] [CrossRef]
- Mallat, S.; Zhang, Z. Matching pursuit with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Bristow, H.; Eriksson, A.; Lucey, S. Fast convolutional sparse coding. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, Oregon, 25–27 June 2013; pp. 391–398. [Google Scholar]
- Vollmer, C.; Gross, H.M.; Eggert, J. Learning Features for Activity Recognition with Shift-Invariant Sparse Coding. In Artificial Neural Networks and Machine Learning ICANN 2013; Springer: Heidelberg/Berlin, Germany, 2013; Volume 8131, pp. 367–374. [Google Scholar]
- Eggert, J.; Wersing, H.; Korner, E. Transformation-invariant representation and NMF. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; Volume 4, pp. 2535–2539. [Google Scholar]
- Mairal, J.; Ponce, J.; Sapiro, G.; Zisserman, A.; Bach, F.R. Supervised Dictionary Learning. In Advances in Neural Information Processing Systems 21; Koller, D., Schuurmans, D., Bengio, Y., Bottou, L., Eds.; Curran Associates, Inc.: New York, NY, USA, 2009; pp. 1033–1040. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Wadsworth and Brooks: Monterey, CA, USA, 1984. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neur. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lipton, Z.C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Sutton, C.; McCallum, A. An introduction to conditional random fields. Mach. Learn. 2011, 4, 267–373. [Google Scholar] [CrossRef] [Green Version]
- Pearl, J. Reverend Bayes on inference engines: A distributed hierarchical approach. In Proceedings of the Second AAAI Conference on Artificial Intelligence, Pittsburgh, PA, USA, 18–20 August 1982; pp. 133–136. [Google Scholar]
- Hoefel, G.; Elkan, C. Learning a two-stage SVM/CRF sequence classifier. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; ACM: Menlo Park, CA, USA, 2008; pp. 271–278. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Twomey, N.; Diethe, T.; Craddock, I.; Flach, P. Unsupervised learning of sensor topologies for improving activity recognition in smart environments. Neurocomputing 2017, 234, 93–106. [Google Scholar] [CrossRef]
- Chen, Y.; Diethe, T.; Flach, P. ADLTM: A Topic Model for Discovery of Activities of Daily Living in a Smart Home. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Diethe, T.; Twomey, N.; Flach, P. Active transfer learning for activity recognition. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Twomey, N.; Diethe, T.; Flach, P. Bayesian active learning with evidence-based instance selection. In Proceedings of the Workshop on Learning over Multiple Contexts, European Conference on Machine Learning (ECML15), Porto, Portugal, 7–11 September 2015. [Google Scholar]
- Diethe, T.; Twomey, N.; Flach, P. Bayesian Active Transfer Learning in Smart Homes. In Proceedings of the Workshop on Active Learning, International Conference on Machine Learning (ICML15), Lille, France, 10 July 2015. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 16th International Symposium on Wearable Computers (ISWC), Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1. Walking | 24. Kneeling | 47. Queuing in line |
| 2. Ascending stairs | 25. Running | 48. Dusting |
| 3. Descending stairs | 26. Sitting drinking coffee | 49. Ironing |
| 4. Sitting | 27. Eating breakfast | 50. Vacuuming |
| 5. Standing | 28. Eating lunch | 51. Brooming |
| 6. Lying down | 29. Eating dinner | 52. Making the bed |
| 7. Working at computer | 30. Sitting talking on phone | 53. Mopping |
| 8. Walking and talking | 31. Using toilet | 54. Window cleaning |
| 9. Standing and talking | 32. Walking carrying object | 55. Watering plant |
| 10. Sleeping | 33. Washing dishes | 56. Setting table |
| 11. Eating | 34. Picking up canteen food | 57. Stretching |
| 12. Personal care | 35. Lying using computer | 58. Scrubbing |
| 13. Studying | 36. Wiping whiteboard | 59. Folding laundry |
| 14. Household work | 37. Talking at whiteboard | 60. Riding elevator |
| 15. Socialising | 38. Making fire for barbecue | 61. Strength-training |
| 16. Sports | 39. Fanning barbecue | 62. Riding escalator |
| 17. Hobbies | 40. Washing hands | 63. Sit-ups |
| 18. Mass media | 41. Setting the table | 64. Walking left |
| 19. Travelling | 42. Watching TV | 65. Walking right |
| 20. Cycling | 43. Making coffee | 66. Jumping |
| 21. Pushing shopping cart | 44. Attending presentation | 67. Nordic walking |
| 22. Driving car | 45. Standing eating | 68. Playing soccer |
| 23. Brushing teeth | 46. Standing drinking coffee | 69. Rope jumping |
| # | Reference | Mean Duration | Data Formats | # Instances | # Attributes | Subjects | # Activities | Activities | Type | Placement | Sampling Rate (Hz) | Labels | Range | Setting (Lab/Wild) | Notes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [4] | 7 min | raw, T, F | 10,299 | 561 | 30 | 6 | 1–6 | 3-axis (Smartphone) | W | 50 | Video | N/K | lab | Samsung Galaxy S2 |
| 2 | [53] | 41 min | raw | N/A | N/A | 15 | 7 | 1–3, 5, 7–9 | 3-axis (BeaStreamer) | C | 52 | Self | g | wild | |
| 3 | [54] | 13 days | raw | N/A | N/A | 17 | 11 | 7, 10–19 | 2-axis (BodyMedia Senswear) | U | 1 | Automatic | N/K | wild | Labels given by sensor |
| 4 | [55] | 7 days | T | 773,817 | 12 | 1 | 37 | 1, 9, 12, 13, 20–47 | 3-axis (Porcupine) | W, L | 2.5 | Self | g | wild | |
| 5 | [56] | 20 min | raw | N/A | N/A | 12 | 10 | 33, 48–56 | 3-axis (Porcupine) | L | 100 | Video | g | lab | |
| 6 | [57] | 2 h | raw | N/A | N/A | 1 | 3 | 1–3 | 3-axis (Porcupine) | L | 100 | N/K | g | lab | Includes strap loosening |
| 7 | [58] | 14 days | raw | N/A | N/A | 17 | 11 | 7, 10–19 | 2-axis (BodyMedia Senswear) | U | 1 | Self | N/K | wild | |
| 8 | [59] | 9 h | raw | N/A | N/A | 42 | 1 | 10 | 3-axis (Porcupine) | L | 100 | Polysom- nography | g | lab | Sleep study |
| 9 | [60] | 1 day | raw | N/A | N/A | 8 | 1 | 10 | 3-axis (SleepTracker) | L | 100 | Video | N/K | lab | Sleep study |
| 10 | [61] | 2 h | raw | N/A | N/A | 4 | 17 | 1, 4–6 | 3-axis | U, L, C, W, B (12 total) | 30 | N/K | lab | 4 activities, 13 “gestures” | |
| 11 | [62] | 6 h | raw | N/A | N/A | 14 | 12 | 1–5, 10, 25, 60, 64–66 | 3-axis MotionNode | W | 100 | Observer | g | lab | |
| 12 | [63] | 1 h | raw | N/A | N/A | 9 | 18 | 1–7, 14, 20, 22, 25, 42, 49, 50, 59, 67–69 | 3-axis Colibri | L, C, A | 100 | Observer | ± 16 g, ± 6 g | lab | 2 different sensors |
| 13 | [52] | 10 h | raw | N/A | N/A | 10 | 21 | 1–7, 14, 20, 22, 25, 42, 49, 50, 59, 67–69 | 3-axis | A | 25 | Video | g | controlled | Some missing data |
| j | q | k | |||
|---|---|---|---|---|---|
| 2 | 4 | 64 | 0:128 | 0:8 | |
| 3 | 8 | 32 | 0:64 | 0:16 | |
| 4 | 16 | 16 | 0:32 | 0:32 | |
| 5 | 32 | 8 | 0:16 | 0:64 | |
| 6 | 64 | 4 | 0:8 | 0:128 |
| HAR | PAMAP | USCHAD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | iid | CRF | Model | iid | CRF | Model | iid | CRF | ||
| stat-LR | 0.937 | 0.950 | stat-LR | 0.850 | 0.910 | stat-LR | 0.864 | 0.899 | ||
| ecdf-LR | 0.940 | 0.964 | ecdf-LR | 0.690 | 0.791 | ecdf-LR | 0.778 | 0.839 | ||
| CNN | 0.940 | 0.950 | CNN | 0.731 | 0.740 | CNN | 0.771 | 0.776 | ||
| LSTM | 0.917 | 0.966 | LSTM | 0.816 | 0.842 | LSTM | 0.831 | 0.899 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Twomey, N.; Diethe, T.; Fafoutis, X.; Elsts, A.; McConville, R.; Flach, P.; Craddock, I. A Comprehensive Study of Activity Recognition Using Accelerometers. Informatics 2018, 5, 27. https://doi.org/10.3390/informatics5020027
Twomey N, Diethe T, Fafoutis X, Elsts A, McConville R, Flach P, Craddock I. A Comprehensive Study of Activity Recognition Using Accelerometers. Informatics. 2018; 5(2):27. https://doi.org/10.3390/informatics5020027
Chicago/Turabian StyleTwomey, Niall, Tom Diethe, Xenofon Fafoutis, Atis Elsts, Ryan McConville, Peter Flach, and Ian Craddock. 2018. "A Comprehensive Study of Activity Recognition Using Accelerometers" Informatics 5, no. 2: 27. https://doi.org/10.3390/informatics5020027
APA StyleTwomey, N., Diethe, T., Fafoutis, X., Elsts, A., McConville, R., Flach, P., & Craddock, I. (2018). A Comprehensive Study of Activity Recognition Using Accelerometers. Informatics, 5(2), 27. https://doi.org/10.3390/informatics5020027