An Empirical Study on Importance of Modeling Parameters and Trading Volume-Based Features in Daily Stock Trading Using Neural Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Backgrounds
2.1. Daily Stock Trading
2.2. Related Studies
3. Our Proposed Method
3.1. Problem Formulation
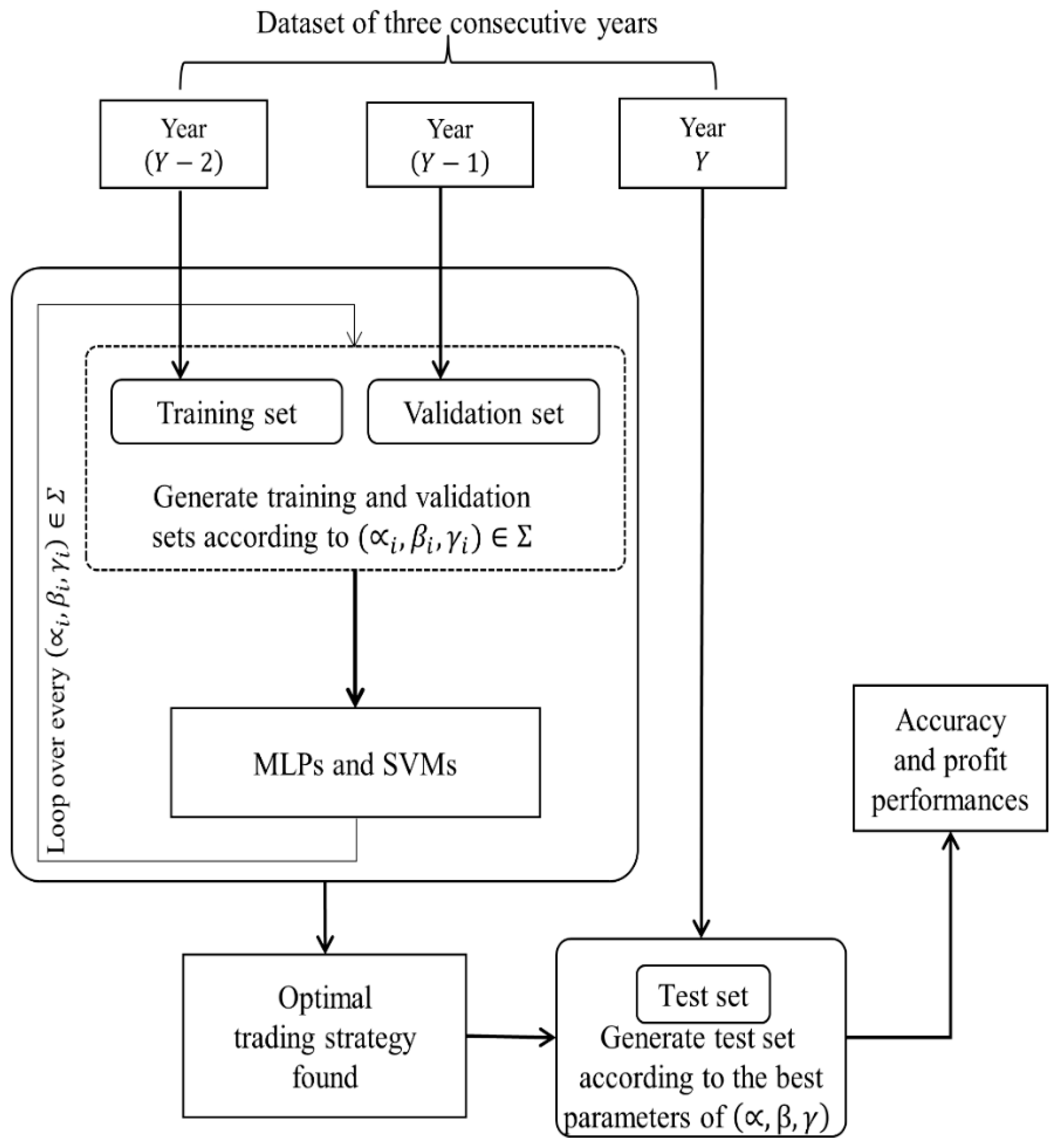
3.2. Overall Framework
3.3. Performace Evaluation
3.3.1. Accuracy
3.3.2. Trading Profit
4. Experimental Results
4.1. Datasets
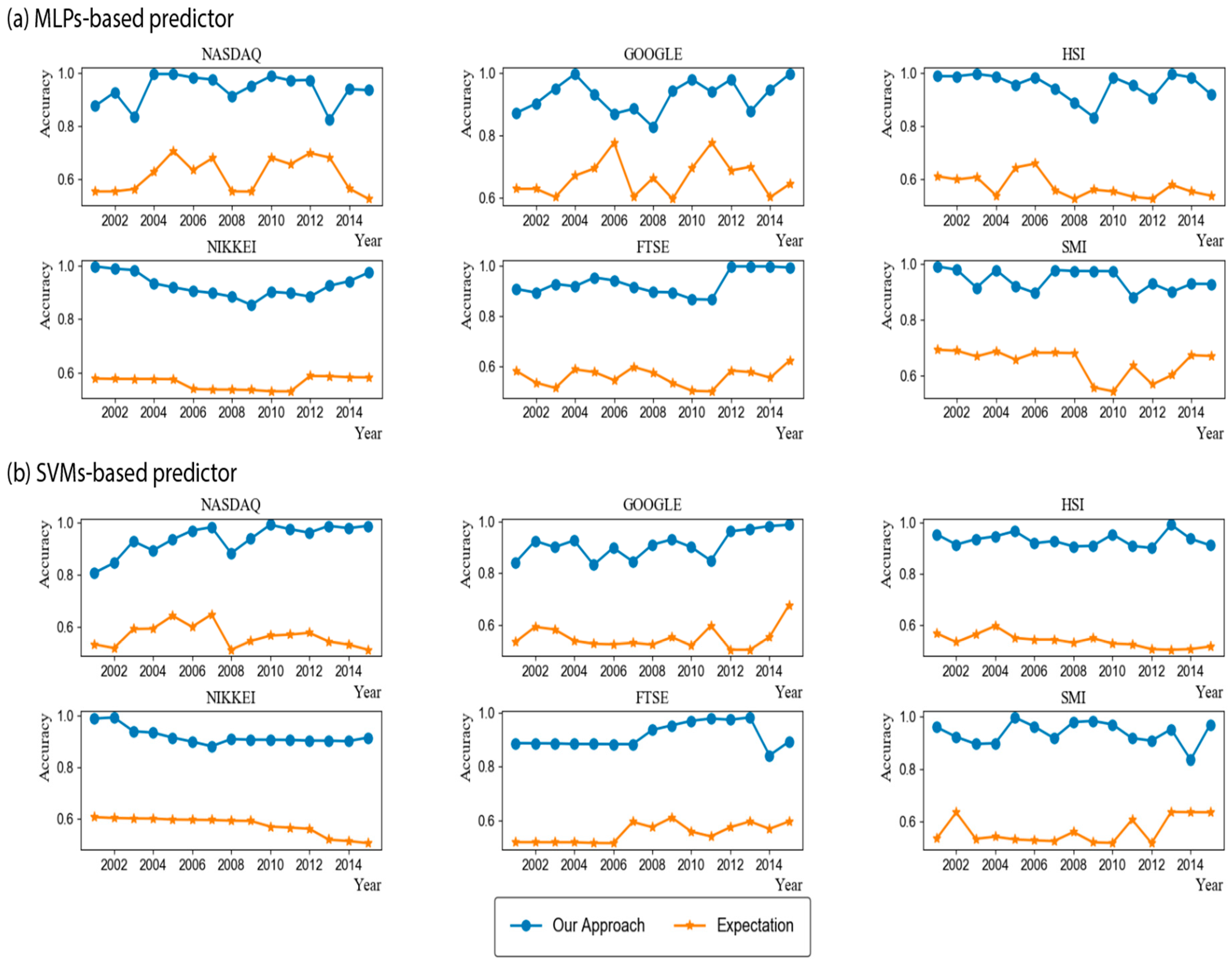
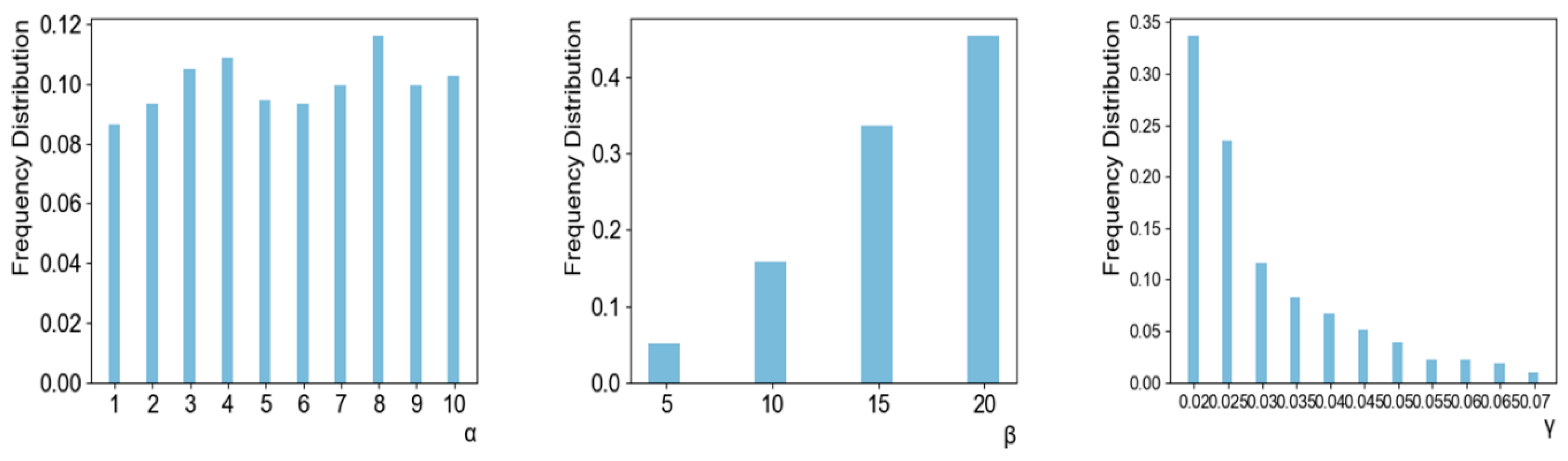
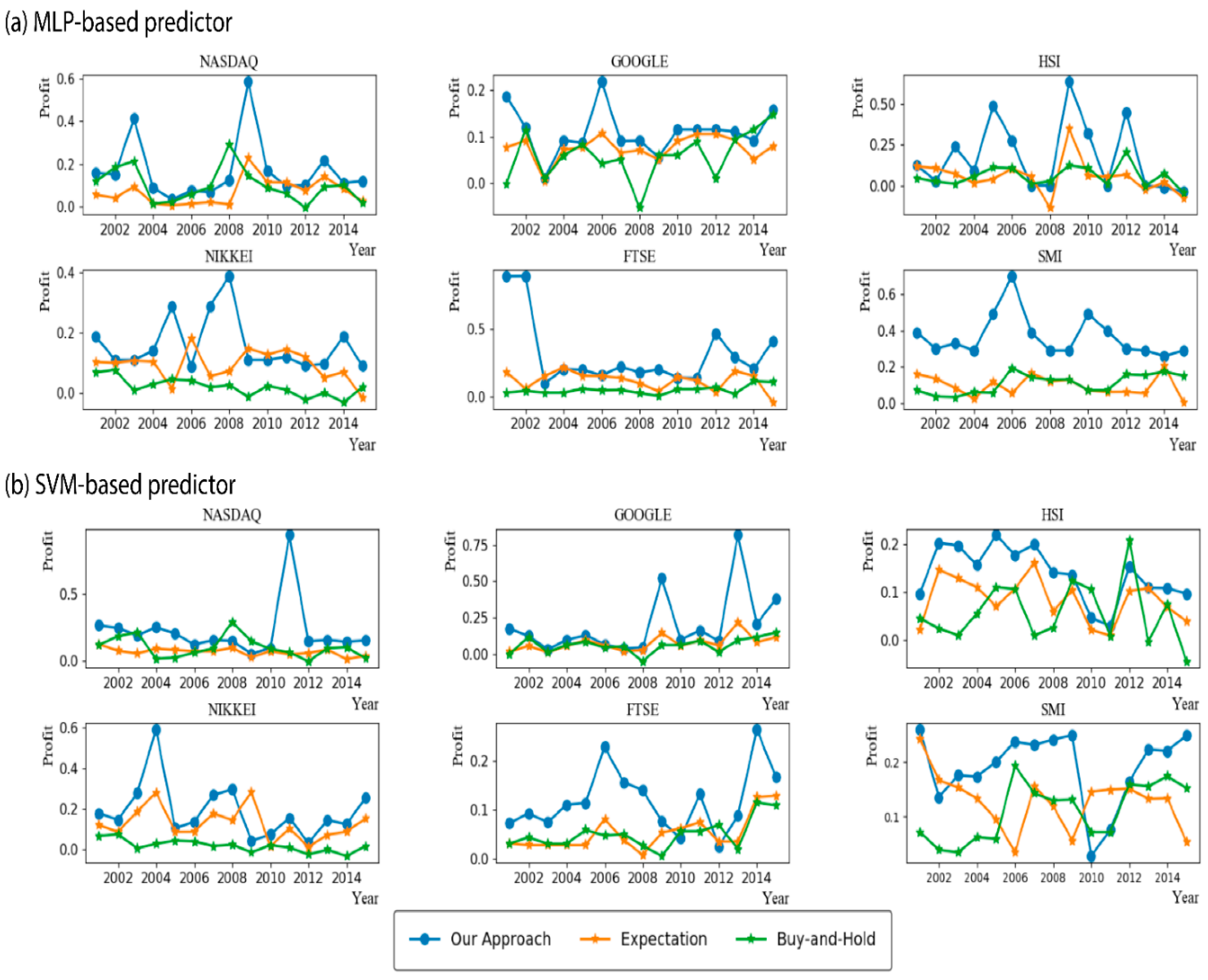
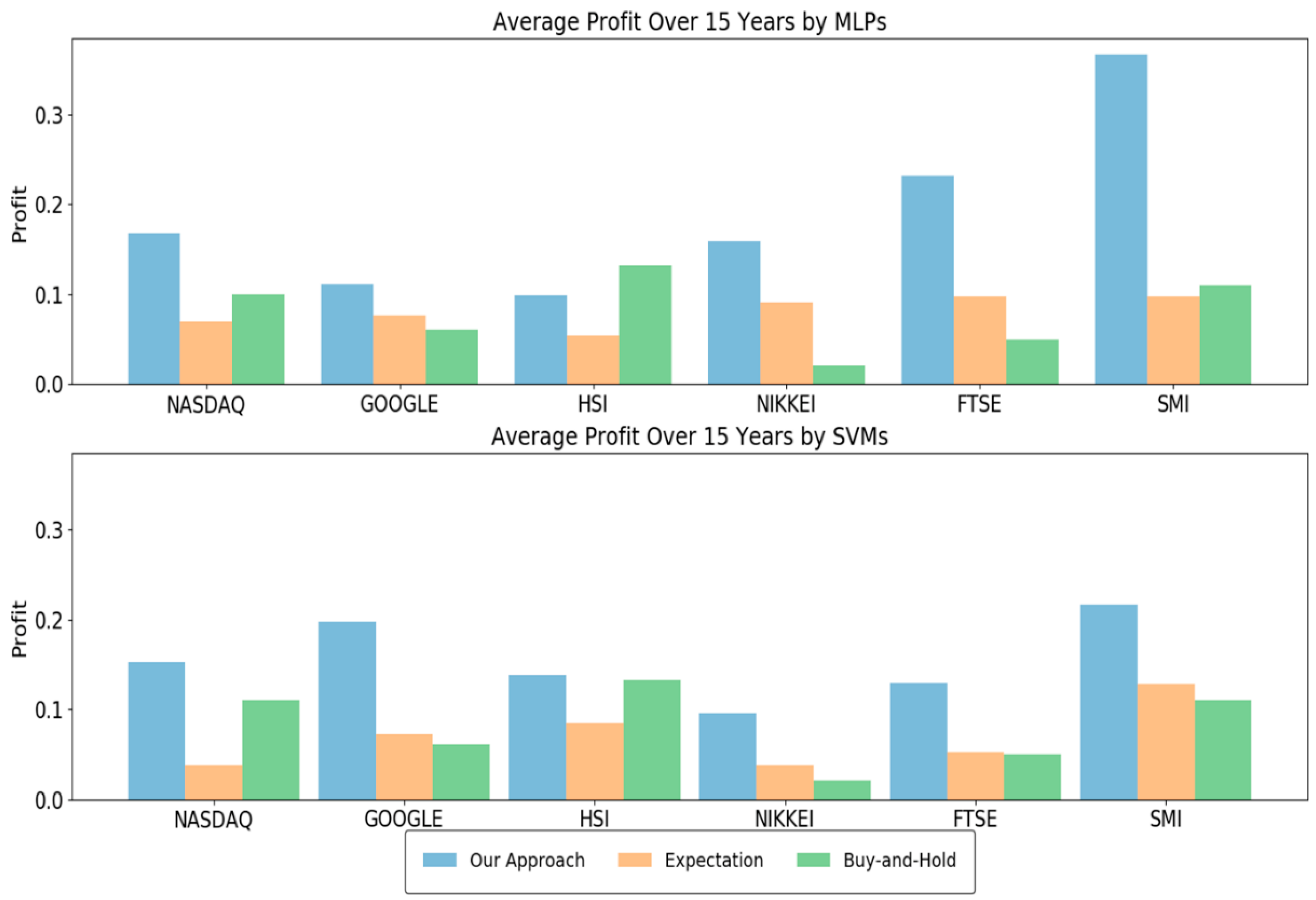
4.2. Performance Analysis
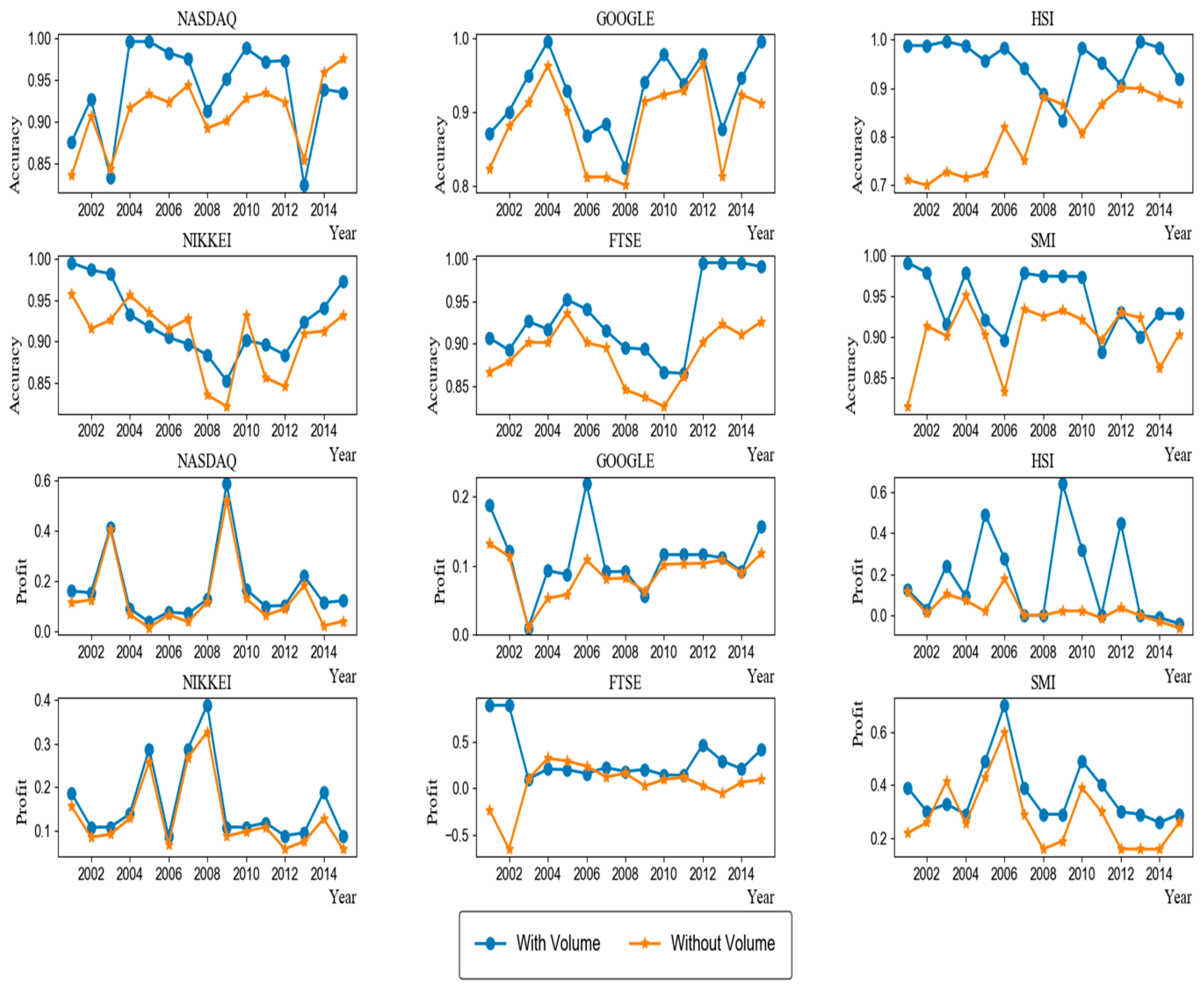
4.3. Usefulness of Trading Volume Information
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Abhyankar, A.; Copeland, L.S.; Wong, W. Uncovering Nonlinear Structure in Real-Time Stock-Market Indexes: The S&P 500, the DAX, the Nikkei 225, and the FTSE-100. J. Bus. Econ. Stat. 1997, 15, 1–14. [Google Scholar]
- He, Y.; Fataliyev, K.; Wang, L. Feature selection for stock market analysis. In International Conference on Neural Information Processing; Springer: Berlin, Germany, 2013. [Google Scholar]
- Pring, M.J. Martin Pring’s Introduction to Technical Analysis; McGraw Hill Professional: New York, NY, USA, 2015. [Google Scholar]
- Kotler, P. Marketing Decision Making: A Model Building Approach; Holt, Rinehart and Winston: New York, NY, USA, 1971. [Google Scholar]
- Chen, J.; Hong, H.; Stein, J.C. Forecasting crashes: Trading volume, past returns, and conditional skewness in stock prices. J. Financ. Econ. 2001, 61, 345–381. [Google Scholar] [CrossRef]
- Yu, L.; Chen, H.; Wang, S.; Lai, K.K. Evolving least squares support vector machines for stock market trend mining. IEEE Trans. Evolut. Comput. 2009, 13, 87–102. [Google Scholar]
- Gallant, A.R.; Rossi, P.E.; Tauchen, G. Stock prices and volume. Rev. Financ. Stud. 1992, 5, 199–242. [Google Scholar] [CrossRef]
- Pacelli, V.; Bevilacqua, V.; Azzollini, M. An artificial neural network model to forecast exchange rates. J. Intell. Learn. Syst. Appl. 2011, 3, 57–69. [Google Scholar] [CrossRef]
- Tino, P.; Schittenkopf, C.; Dorffner, G. Financial volatility trading using recurrent neural networks. IEEE Trans. Neural Netw. 2001, 12, 865–874. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamid, S.A.; Iqbal, Z. Using neural networks for forecasting volatility of S&P 500 Index futures prices. J. Bus. Res. 2004, 57, 1116–1125. [Google Scholar] [Green Version]
- Zhu, M.; Wang, L. Intelligent trading using support vector regression and multilayer perceptrons optimized with genetic algorithms. In Proceedings of the IEEE 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Gupta, S.; Wang, L. Stock forecasting with feedforward neural networks and gradual data sub-sampling. Aust. J. Intell. Inf. Process. Syst. 2010, 11, 14–17. [Google Scholar]
- Cao, L.-J.; Tay, F.E.H. Support vector machine with adaptive parameters in financial time series forecasting. IEEE Trans. Neural Netw. 2003, 14, 1506–1518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitsdorffer, R.; Diederich, J. Prediction of first-day returns of initial public offering in the US stock market using rule extraction from support vector machines. In Rule Extraction from Support Vector Machines; Springer: Berlin, Germany, 2008; pp. 185–203. [Google Scholar]
- Hussain, M.; Wajid, S.K.; Elzaart, A.; Berbar, M. A comparison of SVM kernel functions for breast cancer detection. In Proceedings of the IEEE 2011 Eighth International Conference on Computer Graphics, Imaging and Visualization (CGIV), Singapore, 17–19 August 2011. [Google Scholar]
- Kwon, Y.-K.; Moon, B.-R. Daily stock prediction using neuro-genetic hybrids. In Genetic and Evolutionary Computation—GECCO 2003; Springer: Berlin, Germany, 2003. [Google Scholar]
- Kwon, Y.-K.; Moon, B.-R. A hybrid neurogenetic approach for stock forecasting. IEEE Trans. Neural Netw. 2007, 18, 851–864. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Yang, Z.; Song, Y. Intelligent stock trading system based on improved technical analysis and Echo State Network. Expert Syst. Appl. 2011, 38, 11347–11354. [Google Scholar] [CrossRef]
- Kim, K.-J. Financial time series forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Chang, P.-C.; Liu, C.-H.; Lin, J.-L.; Fan, C.-Y.; Ng, C.S.P. A neural network with a case based dynamic window for stock trading prediction. Expert Syst. Appl. 2009, 36, 6889–6898. [Google Scholar] [CrossRef]
- Fang, Y.; Fataliyev, K.; Wang, L.; Fu, X.; Wang, Y. Improving the genetic-algorithm-optimized wavelet neural network for stock market prediction. In Proceedings of the IEEE 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014. [Google Scholar]
- Roh, T.H. Forecasting the volatility of stock price index. Expert Syst. Appl. 2007, 33, 916–922. [Google Scholar]
- Bhat, A.A.; Kamath, S.S. Automated stock price prediction and trading framework for Nifty intraday trading. In Proceedings of the IEEE 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013. [Google Scholar]
- Dong, G.; Fataliyev, K.; Wang, L. One-step and multi-step ahead stock prediction using backpropagation neural networks. In Proceedings of the IEEE 2013 9th International Conference on Information, Communications and Signal Processing (ICICS), Tainan, Taiwan, 10–13 December 2013. [Google Scholar]
- Mittermayer, M.-A. Forecasting intraday stock price trends with text mining techniques. In Proceedings of the IEEE 37th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 5–8 January 2004. [Google Scholar]
- de Oliveira, F.A.; Zárate, L.E.; de Azevedo Reis, M.; Nobre, C.N. The use of artificial neural networks in the analysis and prediction of stock prices. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Anchorage, AK, USA, 9–12 October 2011. [Google Scholar]
- Wang, L. Wavelet neural networks for stock trading and prediction. In Proceedings of the SPIE Defense, Security, and Sensing, Baltimore, MD, USA, 29 April–3 May 2013; Volume 29. [Google Scholar]
- Mubarik, F.; Javid, A. Relationship between stock return, trading volume and volatility: Evidence from Pakistani stock market. Asia Pac. J. Financ. Bank. Res. 2009, 3, 3. [Google Scholar]
- Kanas, A.; Yannopoulos, A. Comparing linear and nonlinear forecasts for stock returns. Int. Rev. Econ. Financ. 2001, 10, 383–398. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, H.; Xu, L.; Li, H. Predicting stock index increments by neural networks: The role of trading volume under different horizons. Expert Syst. Appl. 2008, 34, 3043–3054. [Google Scholar] [CrossRef]








© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dinh, T.-A.; Kwon, Y.-K. An Empirical Study on Importance of Modeling Parameters and Trading Volume-Based Features in Daily Stock Trading Using Neural Networks. Informatics 2018, 5, 36. https://doi.org/10.3390/informatics5030036
Dinh T-A, Kwon Y-K. An Empirical Study on Importance of Modeling Parameters and Trading Volume-Based Features in Daily Stock Trading Using Neural Networks. Informatics. 2018; 5(3):36. https://doi.org/10.3390/informatics5030036
Chicago/Turabian StyleDinh, Thuy-An, and Yung-Keun Kwon. 2018. "An Empirical Study on Importance of Modeling Parameters and Trading Volume-Based Features in Daily Stock Trading Using Neural Networks" Informatics 5, no. 3: 36. https://doi.org/10.3390/informatics5030036
APA StyleDinh, T. -A., & Kwon, Y. -K. (2018). An Empirical Study on Importance of Modeling Parameters and Trading Volume-Based Features in Daily Stock Trading Using Neural Networks. Informatics, 5(3), 36. https://doi.org/10.3390/informatics5030036